Redis上篇--知识点总结
Redis上篇–解析
本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。
1. 基本介绍
Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 value 就是指Redis的数据类型,可以是String,也可以是List、Hash、Set、 Zset 的数据类型。Redis通常被用作数据库、缓存、消息中间件和实时数据处理引擎。它以速度极快、支持丰富的数据结构而闻名,是现代应用架构中非常流行的组件。
它的核心特点我们需要了解一下:
- 内存存储 (In-Memory):
- 数据主要存储在内存 (RAM) 中,这是 Redis 速度惊人的根本原因(读写操作通常在微秒级别)。
- 它也提供可选的持久化机制,可以将数据异步或同步保存到磁盘,防止服务器重启后数据丢失。
- 丰富的数据结构 (Data Structures):
- 不仅仅是简单的 Key-Value 字符串!Redis 支持多种高级数据结构:
- Strings: 最基本类型,可以存储文本、数字、二进制数据(如图片片段)。
- Lists: 有序的元素集合,可在头部或尾部插入/删除,适合实现队列、栈、时间线。
- Sets: 无序的唯一元素集合,支持交集、并集、差集等操作,适合标签、共同好友。
- Sorted Sets (ZSets): 带分数的有序唯一元素集合,元素按分数排序,完美适用于排行榜、优先级队列。
- Hashes: 存储字段-值对的集合,非常适合表示对象(如用户信息:
field: name, value: "Alice"; field: age, value: 30)。 - Bitmaps / HyperLogLogs / Geospatial Indexes: 特殊用途的数据结构,用于位操作、基数统计(去重计数)、地理位置计算等。
- 不仅仅是简单的 Key-Value 字符串!Redis 支持多种高级数据结构:
- 高性能与低延迟:
- 内存访问 + 单线程架构 (核心命令执行是单线程,避免了锁竞争) + 高效的网络 I/O 模型 (epoll/kqueue) 使其拥有极高的吞吐量和极低的延迟。
- 持久化 (Persistence):
- RDB (Redis Database File): 在指定时间间隔生成整个数据集的内存快照。恢复快,文件紧凑。适合备份和灾难恢复。
- AOF (Append-Only File): 记录所有修改数据库状态的命令。更安全(最多丢失一秒数据),文件可读性强,但文件通常更大,恢复可能比 RDB 慢。可以同时开启或选择其一。
- 原子操作与事务:
- 所有单条命令的执行都是原子的。
- 支持简单的事务 (
MULTI/EXEC),可以将一组命令打包执行(但不支持回滚 - 命令语法错误会导致整个事务不执行,运行时错误不影响其他命令执行)。 - Lua 脚本: 可以执行复杂的、需要多个命令且保证原子性的操作。
其实还有像发布订阅、集群架构本节就不赘述了。
典型应用场景
- 缓存 (Caching): 最常见的用途。将频繁访问的热点数据(如数据库查询结果、页面片段、会话信息)存储在 Redis 中,显著减轻后端数据库压力,提升应用响应速度。
- 会话存储 (Session Store): 存储用户会话信息,易于在多服务器或微服务架构中实现会话共享。
- 排行榜/计数器 (Leaderboards / Counters): 利用 Sorted Sets 可以非常高效地实现实时排行榜。利用
INCR等命令实现高并发下的计数器(如点赞数、浏览量)。 - 实时系统 (Real-time Systems):
- 消息队列 (Message Queue): 利用 Lists 或 Streams (一种更强大的持久化消息队列数据结构) 实现简单的消息队列。
- 实时分析: 处理实时事件流(如用户活动跟踪、监控数据)。
- 地理空间应用 (Geospatial): 存储地理位置坐标,执行附近位置查询、距离计算等。
- 速率限制 (Rate Limiting): 限制用户 API 调用频率或操作次数。
- 分布式锁 (Distributed Lock): 利用 Redis 的原子操作实现简单的跨进程/跨机器的互斥锁。
// 对应的数据类型作用场景:
String可以用来做缓存、计数器、限流、分布式锁、分布式Session等。
Hash可以用来存储复杂对象。List可以用来做消息队列、排行榜、计数器、最近访问记录等。
Set可以用来做标签系统、好友关系、共同好友、排名系统、订阅关系等。
Zset可以用来做排行榜、最近访问记录、计数器、好友关系等。
Geo可以用来做位置服务、物流配送、电商推荐、游戏地图等。
HyperLogLog可以用来做用户去重、网站UV统计、广告点击统计、分布式计算等。
Bitmaps可以用来做在线用户数统计、黑白名单统计、布隆过滤器等。
看了这么大几点,就可以知道Redis相当牛逼了。都说Redis快,仅仅是因为内存操作吗?接下来看一下它为什么这么快!
2. '快’的原因
Redis 可以达到极高的性能(官方测试读速度约 11 万次 / 秒,写速度约 8 万次 / 秒),快自然有快的道理
2.1 内存
基于内存操作
Redis将所有数据存储在内存中,避免了传统数据库的磁盘I/O瓶颈,内存的读写速度远高于磁盘,这使得Redis能够实现超高的响应速度。
节选一下别人的对比:内存的读写速度,和磁盘读写速度的对比
- 最快情况下, 固态 硬盘 速度,大致是 内存速度的 百分之一,
- 最慢情况下, 机械 硬盘 速度,大致是 内存速度的 万分之一,
内存读写速度可以达到每秒数百GB,在微秒级别,而磁盘(特别机械硬盘) 读写速度通常只有数十MB,在毫秒级别, 是数千倍的差距。
对比与传统的关系型数据库比如说MySQL,需要从磁盘加载数据到内存缓冲区才能操作,Redis不需要这个步骤,就避免了磁盘 I/O 的延迟。
+++
2.2 高性能数据结构
高效的数据结构
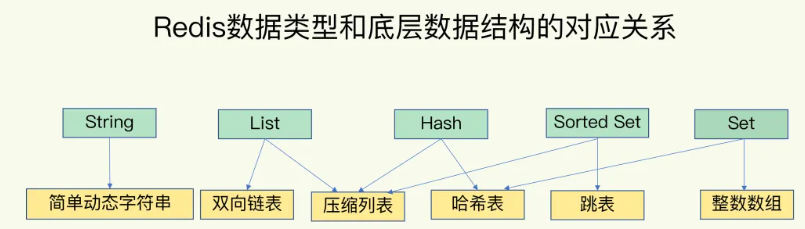
我们都知道Redis向我们用户提供了value为string, list, hash, set, zset五种基本数据类型来使用,还有几种高级的数据结构例如geo, bitmap, hyperloglog。本文就只看基本的数据类型了。
本节分析一下底层实现,这些数据类型底层实现有如下这么些:
sds( 简单动态字符串)
ziplist(压缩列表)
linkedlist(双端链表)
hashtable(字典)
skiplist(跳表)
这些底层结构能够在内存中高效地存储和操作数据,为Redis的快速性能提供了坚实的基础。这里附上别人的图:【来自参考1】
2.2.1 sds
首先就是大家最为熟知的string类型了:它的底层实现是基于sds的。在这之前,我们需要知道这样一件事,Redis中所有数据均通过redisObject结构体封装
typedef struct redisObject {unsigned type:4; // 数据类型(如String、List)unsigned encoding:4; // 编码方式(int/embstr/raw)unsigned lru:24; // LRU缓存淘汰信息int refcount; // 引用计数(用于共享和内存回收)void *ptr; // 指向实际数据的指针
} robj;
/*
type:标识数据类型(String固定为OBJ_STRING)。
encoding:决定ptr指向的数据结构,String有三种可能编码:
OBJ_ENCODING_INT:整数类型。
OBJ_ENCODING_EMBSTR:短字符串(≤44字节)。
OBJ_ENCODING_RAW:长字符串(>44字节)
*/
当前字符串的值可表示为64位有符号整数 long (-9223372036854775807至9223372036854775807 很大就是了),表示为int编码,直接存储整数。
如果不能表示为整数,字符串长度 ≤44字节的时候,为**EMBSTR编码:连续内存的短字符串**,此时,redisObject和SDS分配在单块连续内存中,这样可以减少内存碎片,提升CPU缓存命中率。redisObject固定占16字节,SDS头部(sdshdr8)占3字节(len、alloc、flags各1字节),总内存分配单元为64字节(Redis内存分配器jemalloc的最小单位),所以剩余空间:64 - 16 - 3 - 1(结束符\0) = 44字节。
如果超过了44字节,redisObject和SDS分两次分配内存(不连续),ptr指向独立的SDS结构。
那么这个SDS(Simple Dynamic String)到底是什么个情况呢?SDS是Redis自定义的动态字符串结构,解决了C原生字符串的缺陷(缓冲区溢出、长度计算O(n)、二进制不安全)
struct __attribute__((__packed__)) sdshdr8 {uint8_t len; // 已用长度 1字节 uint8_t alloc; // 总分配容量(不包括头部和\0) 1字节unsigned char flags;// 标识SDS类型(sdshdr8/16/32/64) 1字节char buf[]; // 实际数据(柔性数组)
};
基于这种结构,相比于c语言的字符串,我们可以O(1)复杂度获取字符串长度:直接读取len字段;C语言字符串是使用char数组存储,以’\0’作为字符串结束,比如字符串”Redis“在C语言中存储结构就是这个样子的:
Redis'\0'
C语言字符串这种特殊规定,就导致无法存储特殊字符。如果某个字符串中间包含’\0’字符,读取字符串的时候就无法读取到完整字符,遇到’\0’就结束了,此外呢,C字符串不记录自身的长度,每次增长或缩短一个字符串,都要对底层的字符数组进行一次内存重分配操作。如果在 append 操作之前没有通过内存重分配来扩展底层数据的空间大小,就会产生缓存区溢出;如果进行 trim 操作之后没有通过内存重分配来释放不再使用的空间,就会产生内存泄漏。
而Redis的这种结构就很好了,二进制安全,依赖len而非\0判断结束,可存储图片等二进制数据;
另外还涉及到扩容问题,Redis的SDS中,如果新增的拼接字符串长度小于未使用空间,就不用扩容了;
此外,惰性空间释放:缩短字符串时不立即回收内存,只是简单的修改sdshdr 头中的 Len 字段就可以了。
2.2.2 zipList
Redis的压缩列表(ziplist)是一种极致内存优化的紧凑型数据结构,用于在小数据量场景下高效存储列表、哈希和有序集合。它通过精巧的设计实现了O(1)头部操作和高效内存利用,是Redis早期核心数据结构之一(Redis 7.0后逐渐被listpack替代,但理解其设计仍有重要意义)
// ziplist的数据结构
typedef struct {uint32_t zlbytes; // 4字节 整个压缩列表占用的内存字节数(uint32_t)uint32_t zltail; // 最后一个entry的偏移量(实现O(1)尾部访问)uint16_t zllen; // entry数量(当≥65535时需遍历计算)entry* entries; // 实际存储的节点列表uint8_t zlend; // 结束标志(0xFF)
} ziplist;
// 其结点的数据结构
struct entry {uint8_t prevlen; // 前驱节点长度(1或5字节)uint8_t encoding; // 数据编码方式(字节数组或整数)optional uint8_t data[]; // 实际数据
};
压缩列表以一种紧凑的方式存储数据,将多个元素紧密地排列在一起,节省了存储空间。在压缩列表中,相邻的元素可以共享同一个内存空间。这里附上【尼恩】的示意图:
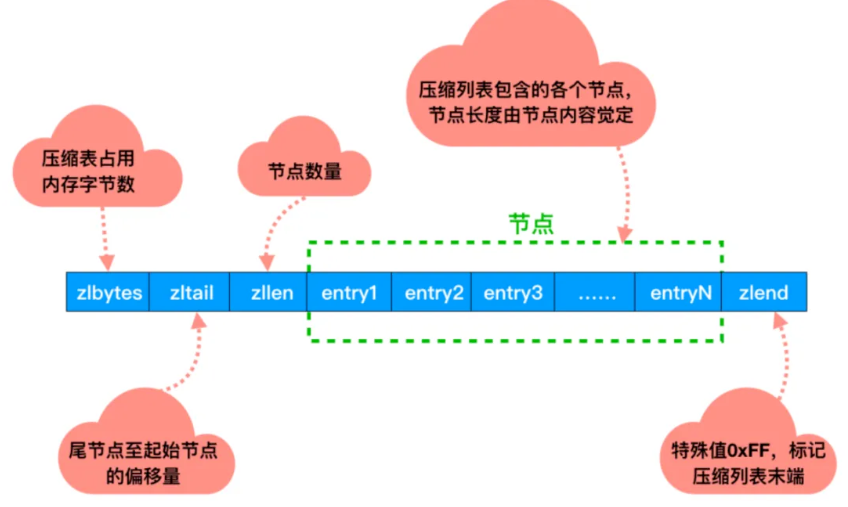
他的优点:紧凑存储,无额外指针(相比链表节省 20%-30% 内存);通过 zltail 快速定位尾部,支持 O(1) 时间的尾插/尾删;
但是,插入/删除需移动后续节点,时间复杂度 O(N);会有连锁更新风险。
Redis 的压缩列表(Ziplist)与传统双向链表在数据结构设计、性能和应用场景上存在如下差异:
第一,从结构设计上来说
| 特性 | 压缩列表(Ziplist) | 传统双向链表 |
|---|---|---|
| 存储方式 | 连续内存块,通过偏移量定位节点 | 离散内存块,每个节点包含前驱/后继指针 |
| 节点结构 | 无指针,包含 prevlen(前驱长度)+ encoding(编码类型)+ 数据内容 | 包含前驱指针、后继指针及数据内容 |
| 头部元数据 | zlbytes(总字节数)、zltail(尾节点偏移)、zllen(节点数量)、zlend(结束符) | 通常仅记录头尾指针和节点数量 |
| 内存布局 | 紧凑存储,无额外指针开销 | 逻辑上是相邻的 |
第二,内存效率对比
| 维度 | 压缩列表 | 双向链表 |
|---|---|---|
| 内存占用 | 极低(无指针,变长编码优化) | 较高(每个节点需 2 个指针,占 16 字节) |
| 空间利用率 | 高(紧凑存储减少碎片) | 低(易产生内存碎片) |
| 适用数据规模 | 小数据场景(元素数量 ≤ 512,单元素 ≤ 64 字节) | 大数据场景(无严格限制) |
第三,操作性能对比
| 操作类型 | 压缩列表 | 双向链表 |
|---|---|---|
| 随机访问 | O(n)(需遍历节点) | O(n)(需遍历指针链) |
| 头尾插入/删除 | O(1)(通过 zltail 快速定位) | O(1)(直接操作头尾指针) |
| 中间插入/删除 | O(n)(需移动后续节点,可能触发连锁更新) | O(n)(需遍历到节点位置,但指针操作快) |
2.2.3 双向链表
Redis中的双端链表是一种优化后的数据结构,专门用于存储有序的元素集合。Redis双端链表具备双向链接的特性,即每个节点都包含指向前一个节点和后一个节点的指针。
这里附上别人的Redis双向链表的示意图:
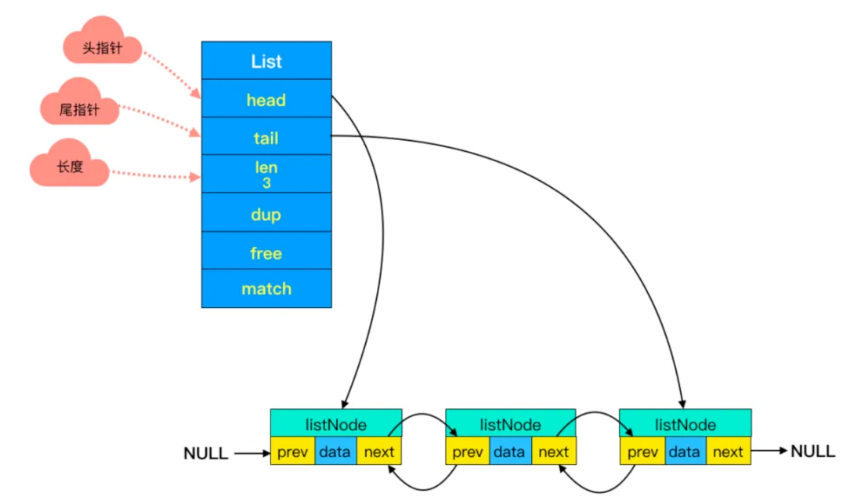
可以看到每个节点包含 前驱指针、后继指针 和 数据值,支持从头部或尾部向中间遍历;头节点的 prev 和尾节点的 next 均指向 NULL,避免循环引用;List结构中还有长度字段:len 属性直接记录节点数,避免遍历统计;还存有头指针、尾指针,方便从头或者尾部开始遍历链表。
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 头部插入/删除 | O(1) | 直接调整头指针及相邻节点指针 |
| 尾部插入/删除 | O(1) | 同上 |
| 按索引访问 | O(n) | 需从头或尾遍历(平均一半节点) |
| 按值查找 | O(n) | 顺序遍历,无哈希索引 |
| 遍历全部节点 | O(n) | 需访问每个节点 |
再在这里与2.2.3小节的压缩列表对比一下:
| 场景 | 双向链表 | 压缩列表 |
|---|---|---|
| 大型列表 | ✅ 稳定O(1)操作 | ❌ 插入可能触发O(n²)连锁更新 |
| 小型列表 | ❌ 内存开销大 | ✅ 内存节省80%+ |
| 频繁头尾操作 | ✅ 直接指针修改 | ✅ 尾部快,头部需移动数据 |
| 中间位置修改 | ✅ O(1)指针操作 | ❌ O(n)数据移动 |
| 二进制安全 | ✅ 无特殊限制 | ✅ 支持 |
| 内存碎片 | ❌ 高(节点离散分配) | ✅ 极低(连续内存) |
2.2.4 渐进式扩容 双哈希结构
通过Redis源码,我们可以看到dict的定义如下:
typedef struct dict {dictType *type; // 类型特定函数void *privdata; // 私有数据dictht ht[2]; // 双哈希表(用于渐进式rehash)long rehashidx; // rehash进度索引
} dict;typedef struct dictht {dictEntry **table; // 桶数组unsigned long size; // 桶数量unsigned long sizemask; // size-1(用于位运算)unsigned long used; // 已用节点数
} dictht;typedef struct dictEntry {void *key; // 键(SDS)union { // 值(联合体)void *val;uint64_t u64;int64_t s64;} v;struct dictEntry *next; // 链地址法解决冲突
} dictEntry;
从上述结构体我们可以推断出其具体结构:
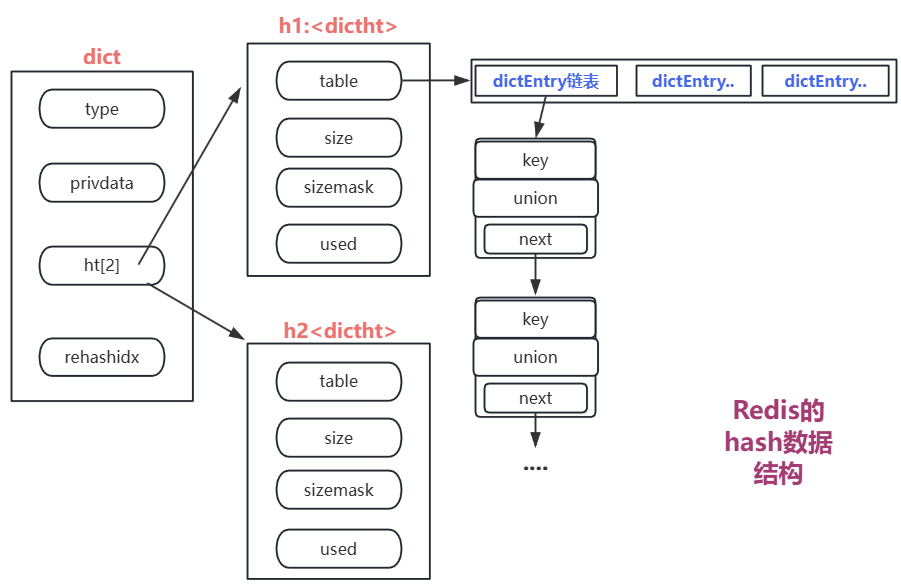
可以看到,redis处理哈希冲突的方式是链地址法,当多个键值对映射到同一个哈希表数组索引时,这些键值对会以链表的形式存储,链表的每个节点包含键值对。(这种查找插入的速度都不慢,hash表的数据结构我这里就不解释了,我们知道Redis的hash表如上图所示就行了)
| 操作 | 平均复杂度 | 最坏复杂度 | 场景 |
|---|---|---|---|
| HSET/HGET | O(1) | O(n) | 哈希冲突严重 |
| HGETALL | O(n) | O(n) | 全量遍历 |
| HDEL | O(1) | O(n) | 需链表删除 |
随着数据量的增长,Redis 的哈希表需要扩容存储能力。但扩容操作本身可能会非常耗时,导致服务阻塞。所以就有了上面的ht[2]这个东西了!!
为了在扩容过程中避免阻塞服务,Redis 设计了双哈希表结构 dict.ht,其中包含两个哈希表:
- ht[0]:主哈希表,用于存储当前所有数据,并处理客户端的读写请求。
- ht[1]:备用哈希表,用于扩容操作。
扩容的流程大概如下:
当哈希表负载因子超过阈值(元素数/桶数)≥ 1 且未执行 BGSAVE/BGREWRITEAOF,或负载因子 ≥ 5 时,触发扩容。Redis 会创建一个容量为原表两倍的新哈希表(ht[1]),并通过分批次迁移数据实现无阻塞扩容。具体步骤为:
首先,初始化新表:分配 ht[1] 的内存空间,设置其 sizemask 和 used 字段,将旧表(ht[0])的 rehashidx 置为 0,标记扩容开始;
其次,渐进迁移:处理客户端请求时,迁移 ht[0] 中 rehashidx 对应的一个哈希桶的所有键值对到 ht[1],并递增 rehashidx,在这个过程中,查询操作就同时搜索 ht[0] 和 ht[1],新增操作直接写入 ht[1],删除/更新操作如果所在桶若未迁移,在 ht[0] 执行;若已迁移则在 ht[1] 执行。
同时呢,还会有定时辅助迁移:即使无操作,Redis 也会在 serverCron 中触发 1ms 的迁移任务,每次最多迁移 10 个桶,确保空闲时完成扩容;
最后完成收尾:当 ht[0] 的所有数据迁移完成后,释放其内存,将 ht[1] 设为新的 ht[0],并重置 rehashidx 为 -1。
2.2.5 跳跃表
跳跃表(Skip List)是一种基于有序链表的随机化数据结构,通过多层索引实现高效查找、插入和删除操作,平均时间复杂度为 O(log n)。Redis 的有序集合(Sorted Set)就是采用跳跃表作为其核心数据结构。那么它长什么样子呢
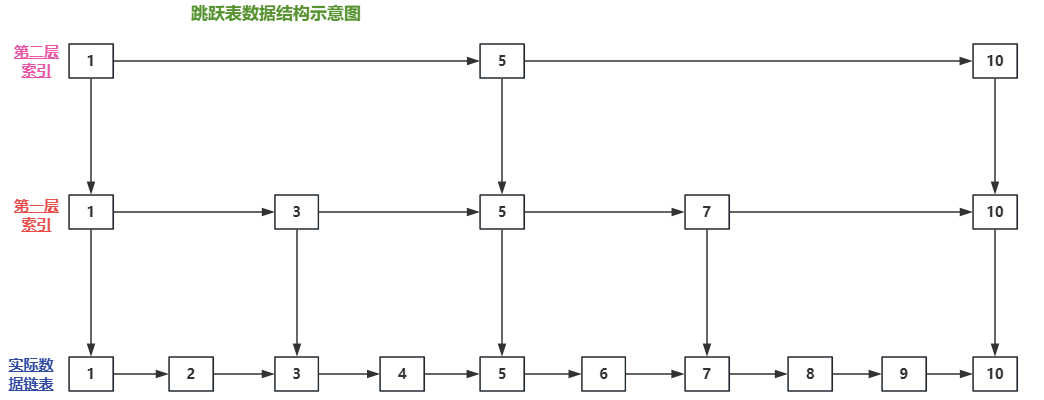
跳表的做法就是给链表做索引,而且是分层索引,可以有多层,层级越多占用 的空间肯定是越多的;
跳表通过维护多级索引,每个级别的索引都是原始链表的子集,用于快速定位元素。
每个节点在不同级别的索引中都有一个指针,通过这些指针,可以在不同级别上进行快速查找,从而提高了查找效率。
比如说在上面的图中,查找元素8,就可以按照下面的顺序去查找:
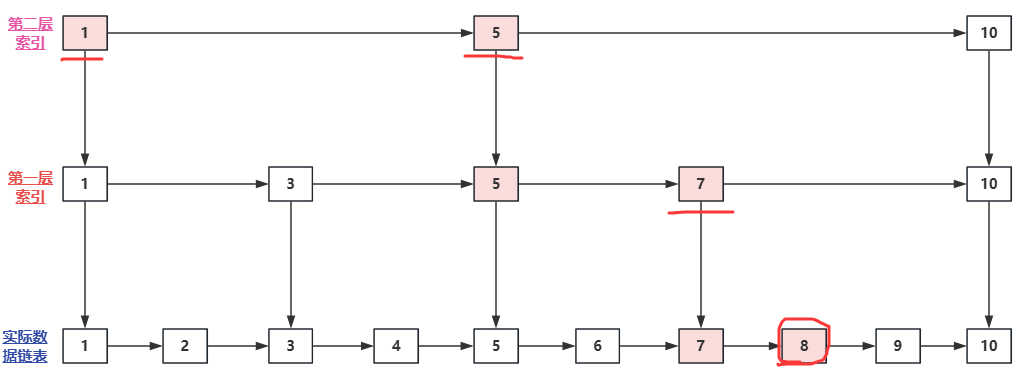
只用找1 5 7 8,就可以了。
可以很直观地看到查找算法看起来挺简单的,难点就是插入、删除元素的时候,索引该如何去维护。跳跃表实现见后续文章吧,本文只做Redis数据结构的简要概括。下面附上一张Redis中skipList的数据结构,来自参考3:
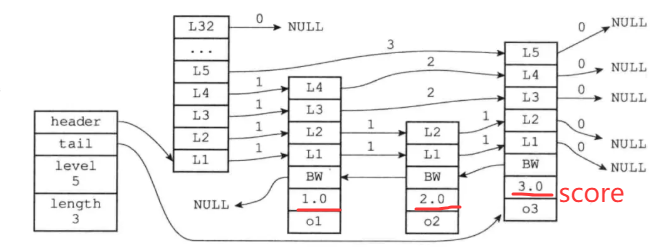
header:指向跳跃表的表头节点
tail:指向跳跃表的表尾节点
level:记录目前跳跃表内,层数最大的那个节点层数(表头节点的层数不计算在内)
length:记录跳跃表的长度,也就是跳跃表目前包含节点的数量(表头节点不计算在内)
同时在跳跃表中,score值有序
| 特性 | 经典跳跃表 | Redis 跳跃表 |
|---|---|---|
| 排序依据 | 单键值 | 分值(score)+成员(ele) |
| 跨度设计 | 无 | 有(支持排名计算) |
| 遍历方向 | 单向 | 双向链表,方便以倒序方式获取一个范围内的元素。 |
| 头节点 | 仅存指针 | 存储最大层数 |
| 层数上限 | 无硬性限制 | 固定 32 层 |
Redis 为什么采用跳跃表而不用平衡树?【copy自参考3】
- 从内存占用上来比较,跳表比平衡树更灵活一些。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
2.3 单线程、多路复用
Redis 的单线程设计是其高性能的核心支柱,但它并非字面意义上的“只有一个线程”。Redis 的工作线程(主线程)串行处理所有客户端命令,但存在辅助线程处理异步任务
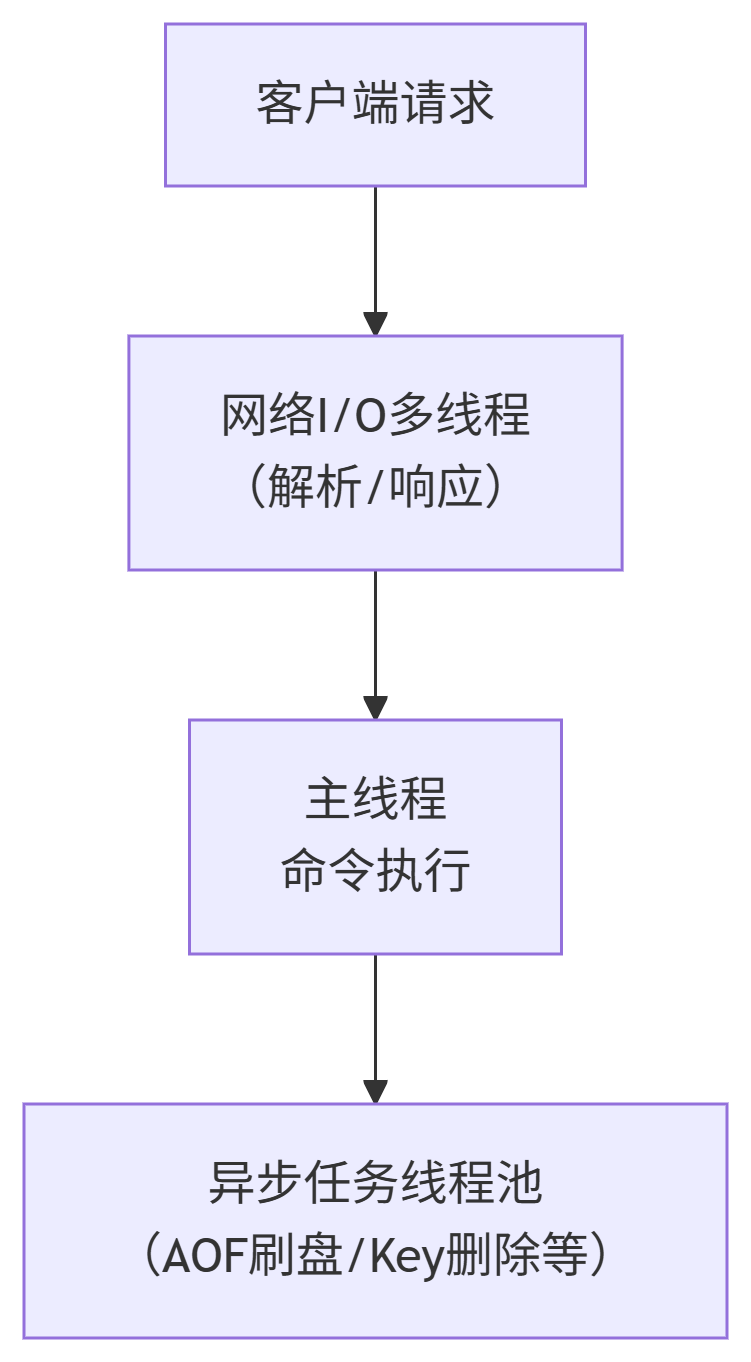
为什么坚持核心单线程呢?这可能是一种取舍,如果是多线程的话,需要考虑 共享数据结构需加锁(如 Mutex)、线程上下文切换需要消耗 CPU 周期、线程安全编程难度高一些。
如果采用单线程的话,天然无锁,可以保证操作的原子性;因为是单线程嘛,所以就没有县城上下文切换了;代码就更简单易懂了,也容易维护嘛。
单线程肯定会有不足的:比如说执行了慢命令,(如 KEYS *)会阻塞所有后续请求;单线程无法充分利用多核cpu。
所以可以得出:CPU 并不是Redis的瓶颈 → 避免锁/切换开销 → 单线程更高效
因为Redis使用内存存储数据,所以数据访问非常迅速,不会成为性能瓶颈。此外,Redis的数据操作大多数都是简单的键值对操作,不包含复杂计算和逻辑,因而CPU开销很小。相反,Redis的瓶颈在于内存的容量和网络的带宽,这些问题无法通过增加CPU核心来解决。
Redis 6.x开始引入了多线程, 但是多线程仅仅是在 处理网络IO,Redis 核心命令执行依然是单线程,确保性能和一致性。
+++
那么,现在说一下Redis 的网络 I/O 处理,采用 事件驱动的 Reactor 模式,结合 I/O 多路复用技术 和 渐进式多线程优化:
Redis 采用 Reactor 模式作为网络模型的基础架构,在这一模式下,Redis 通过一个主事件循环(Event Loop) 持续监听并分发网络事件。
首先,事件分发器:基于 I/O 多路复用技术(如 Linux 的 epoll)实现,负责监控所有客户端连接的 Socket 文件描述符(FD);
然后,事件处理器:为不同事件(如连接、读、写)绑定对应的回调函数。例如:连接事件触发 accept 处理器,创建新客户端连接;读事件触发命令请求处理器,解析并执行 Redis 命令;写事件触发响应回复处理器,将结果返回客户端。
通过 I/O 多路复用,单一线程可同时监听数万个 Socket,仅当 Socket 真正发生读写事件时才触发回调,避免了线程空转和阻塞,这种设计使得 Redis 在单线程下仍能高效处理高并发请求,尤其适合内存操作快速完成的场景
尽管单线程模型简化了数据一致性管理,但网络 I/O 瓶颈在高并发场景下逐渐显现。为此,Redis 从 6.0 版本开始引入渐进式多线程优化:新增的 I/O 线程仅负责网络数据的读取与发送,而命令解析与数据操作仍由主线程单线程执行,这种设计确保了核心数据操作的原子性,避免多线程竞争。
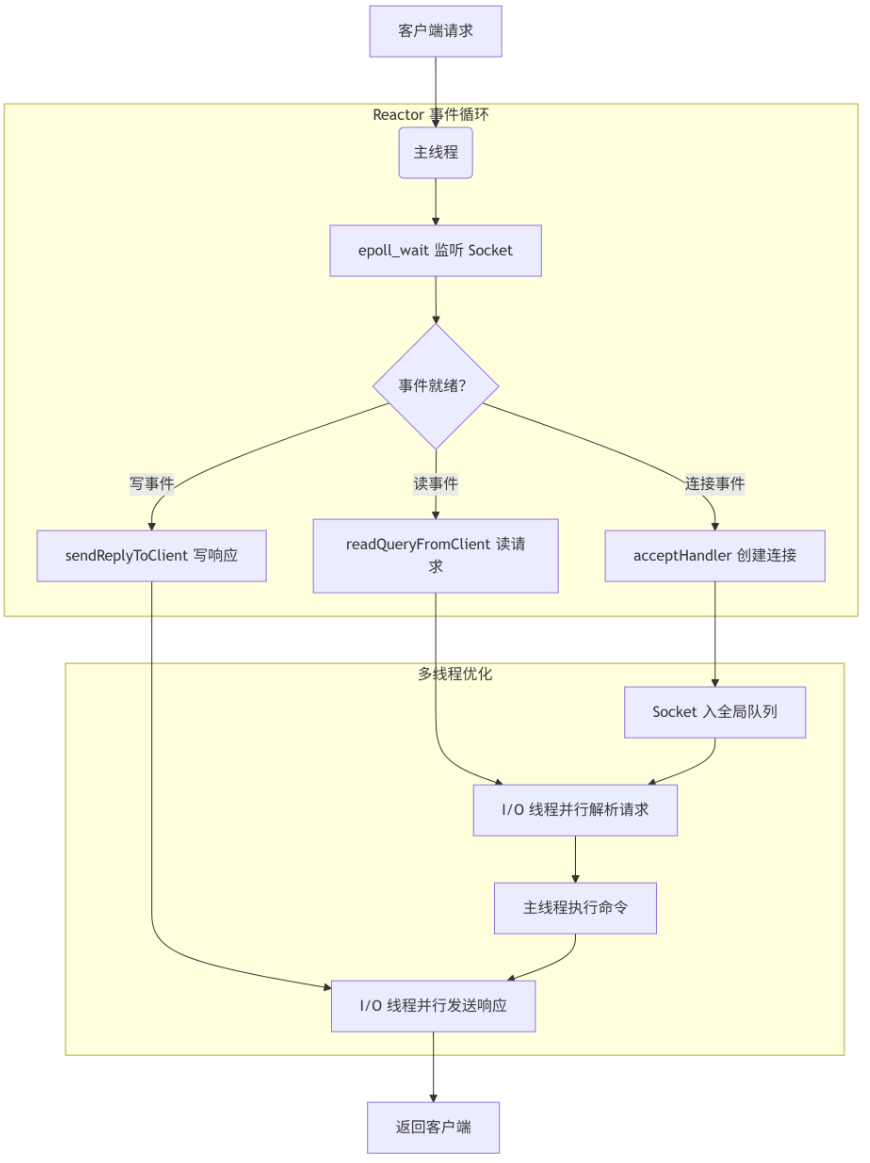
主要流程:
1. 主线程接收新连接,将 Socket 分配至全局队列;
2. I/O 线程池并行读取请求数据并解析为命令(若启用 io-threads-do-reads),或并行发送响应结果;
3. 主线程按顺序执行所有命令,再将结果写入缓冲区供 I/O 线程发送
【用户可通过 io-threads 参数设置线程数(建议为 CPU 核数的 1~1.5 倍),并通过 io-threads-do-reads 控制是否启用读并行化,在高并发网络场景下,此优化可提升吞吐量 40%~50%,同时避免核心逻辑的锁竞争】
2.4 异步持久化机制
单机的Redis速度已经独步天下了,倘若遇到系统错误,导致Redis应用程序中断了,由于数据是在内存里面,那不就全部丢失了吗?阁下该如何应对!这就需要 说到Redis的持久化机制了。
Redis的持久化机制包含RDB和AOF两种方式,其核心设计原则是最大化性能,因此持久化操作本质是异步的(主线程非阻塞);
- 首先说一下RDB(Redis Database):
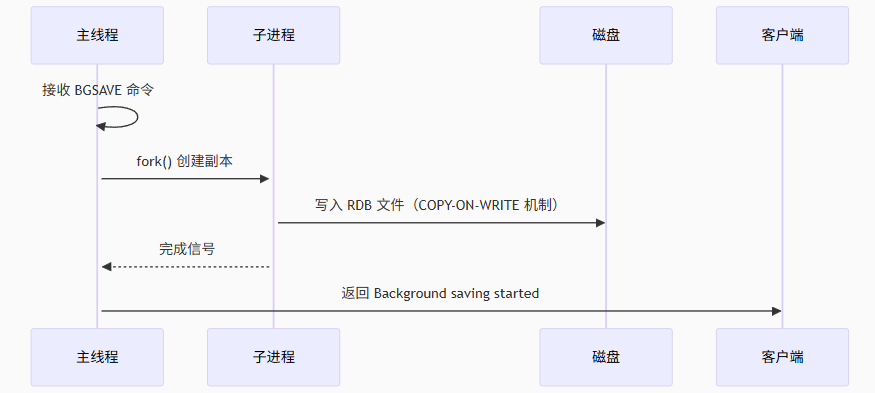
它是将内存中的数据以二进制格式生成全量快照(Snapshot),写入 dump.rdb 文件,通过 fork 子进程完成持久化,主进程继续处理请求,仅 fork 操作短暂阻塞(约 1-100ms)。那么其触发方式是什么样子的呢?
可以自动触发(默认异步),在配置文件里面配置 save m n:如 save 900 1 表示 900 秒内至少 1 次键修改时触发;从节点全量复制时自动触发。
也可以手动触发,就需要命令的形式了,SAVE:同步阻塞主线程,生成快照(不推荐生产环境使用);BGSAVE:异步生成快照,通过子进程完成(默认方式)。
这种方式快速生成快照,对性能影响较小,此外呢,文件体积较小,适合备份和灾难恢复。但是,如果是 Redis 服务器在两次快照之间崩溃,可能会丢失部分数据
- 第二种方式AOF(Append-Only File)
它是将 Redis 执行的所有写命令(如SET、INCR)追加到日志文件(默认名为appendonly.aof),同时在AOF 文件过大时,通过BGREWRITEAOF命令对日志进行瘦身(合并重复命令):创建一个新的AOF文件来替代现有的AOF文件,新旧两个文件所保存的数据库状态是相同的,但 新 AOF文件 去掉 老的 冗余命令,通常体积会较旧AOF文件小很多,达到压缩 AOF 文件体积的目的。
重写瘦身触发方式:【1】手动:BGREWRITEAOF 命令。【2】自动:满足 auto-aof-rewrite-percentage(默认 100%)和 auto-aof-rewrite-min-size(默认 64MB)条件时触发。
这个重写操作是异步的吗?Redis是利用子线程进行复制拷贝,总结来说就是 一个拷贝,两处日志。复制过程 不会卡主线程,整个过程是让子进程干活,主线程继续服务用户。两处日志分别指:【1】主线程正常处理新操作,把命令记录到 AOF 缓冲区 ,异步刷新到 原来的AOF日志里(比如每秒刷一次磁盘) 【2】同时,新操作还会被额外记录到 AOF重做缓冲区,等小弟整理完旧日志后,这些新操作会被追加到新的AOF文件里,保证数据不丢失
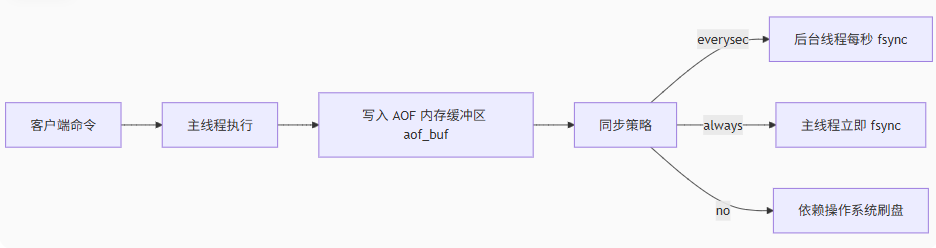
那么AOF这种方式的异步点在哪里呢?
写操作:主线程将命令追加到 aof_buf 内存缓冲区(非阻塞)
刷盘策略:根据配置异步刷盘
appendfsync always # 同步写盘(强一致,性能差)
appendfsync everysec # 每秒异步刷盘(推荐-默认)
appendfsync no # 依赖操作系统刷盘
这种持久化方式数据安全性高(最多丢失 1 秒数据),支持命令级恢复,但是文件体积大,恢复速度慢,因为是很多命令嘛。
那么Redis是采用哪种方式呢?是同时开启 RDB 和 AOF喔,利用 RDB 的快速恢复能力和 AOF 的数据安全性,重启时,优先加载RDB恢复数据,再重放AOF增量操作。
end. 参考
- https://mp.weixin.qq.com/s/pFwnTOQSovy_nMrg0QQk-Q 【尼恩—Redis 为啥那么快?怎么实现 100W并发?说出 这 6大架构,面试官跪 了】
- https://www.cnblogs.com/yidengjiagou/p/17239149.html 【为什么Redis不直接使用C语言的字符串?】
- https://mp.weixin.qq.com/s?__biz=MzkxNzIyMTM1NQ==&mid=2247501801&idx=1&sn=36ec0db469080065aac9ff6f15900f08&scene=21#wechat_redirect 【尼恩-跳跃表】