【论文阅读】:Weighted Graph Cuts without Eigenvectors:A Multilevel Approach
Inderjit S. Dhillon, Yuqiang Guan, and Brian Kulis
vol 29, TPAMI 2007
Abstract
我们讨论了谱聚类和核 k -means 的目标函数之间的等效性。一般加权核 k-means 目标在数学上等同于加权图聚类目标。我们利用这种等效性开发了一种快速的高质量多级算法,该算法直接优化了各种加权图聚类目标,这样就不需要对图聚类问题进行任何特征向量计算。我们的多级算法通过使用核 K-Means 来优化加权图切割,从而消除了此限制。
1. Introduction
kernel k-means 算法是标准 k-means 算法的泛化。通过将数据隐式映射到更高维空间,kernel k-means 可以发现在输入空间中可非线性分离的集群。与标准 k-means 相比,这允许在给定相似性值的正确定矩阵的情况下进行数据聚类。
另一方面,图聚类算法专注于对图的节点进行聚类。谱方法已被有效地用于解决许多图聚类目标,包括比率切割Ratio Cut和归一化切割Normalized Cut。
核 k-means 目标的加权形式在数学上等同于一般加权图聚类目标。这种等价具有直接的含义:我们可以使用加权核 k-means 算法来局部优化许多图聚类目标,相反,可以采用谱方法用于加权核 k-means。在特征向量计算令人望而却步的情况下,加权核 k-means 算法可能比谱方法更可取。
在我们开发一种新的多级聚类算法时,突出了在我们的分析中使用核的好处。在多级算法中,输入图被逐层反复粗化,直至仅剩下少量节点。首先对粗化后的图进行初始聚类,然后随着图逐层解粗化,对该聚类进行细化。这些方法非常快,并且可以提供高质量的分区。然而,早期的多级方法强制簇具有几乎相等的大小,并且都基于优化 Kernighan-Lin目标。相比之下,我们的多级算法消除了相同簇大小的限制,并在细化阶段使用加权核 k-means 算法直接优化各种加权图切割。
就我个人而言,主要关注加权 kernel k-means和Spectral Clustering的转化关系,较不关心它的高速谱聚类算法
2. Kernel k-means
给定一组向量 ( a 1 , a 2 , … , a n ) (a_{1}, a_{2}, \ldots, a_{n}) (a1,a2,…,an),k-means算法旨在找到簇 ( π 1 , π 2 , … , π k ) (\pi_{1}, \pi_{2}, \ldots, \pi_{k}) (π1,π2,…,πk),以最小化目标函数
D ( { π c } c = 1 k ) = ∑ c = 1 k ∑ a i ∈ π c ∥ a i − m c ∥ 2 \mathcal{D} (\{\pi_{c}\}_{c=1}^{k} )=\sum_{c=1}^{k} \sum_{a_{i} \in \pi_{c}}\| a_{i}-m_{c} \|^2 D({πc}c=1k)=c=1∑kai∈πc∑∥ai−mc∥2
其中 ( m c = ∑ a i ∈ π c a i ∣ π c ∣ ) (m_{c} = \frac{\sum_{a_{i} \in \pi_{c}} a_{i}}{\left|\pi_{c}\right|}) (mc=∣πc∣∑ai∈πcai)表示第 c个簇的均值质心。
标准k-means算法的一个缺点是,簇只能通过超平面进行分离;这是因为该算法使用平方欧氏距离作为度量。为了允许非线性分离,核k均值算法首先使用函数 ϕ \phi ϕ将数据点映射到更高维的特征空间,然后在该特征空间中应用k-means算法。
核k均值的目标可以表示为最小化以下函数:
D ( { π c } c = 1 k ) = ∑ c = 1 k ∑ a i ∈ π c ∥ ϕ ( a i ) − m c ∥ 2 , \mathcal{D}\left(\left\{\pi_{c}\right\}_{c=1}^{k}\right)=\sum_{c=1}^{k} \sum_{a_{i} \in \pi_{c}}\left\| \phi\left(a_{i}\right)-m_{c}\right\| ^{2}, D({πc}c=1k)=c=1∑kai∈πc∑∥ϕ(ai)−mc∥2,
其中 m c = ∑ a i ∈ π c ϕ ( a i ) ∣ π c ∣ m_{c}=\frac{\sum_{a_{i} \in \pi_{c}} \phi\left(a_{i}\right)}{\left|\pi_{c}\right|} mc=∣πc∣∑ai∈πcϕ(ai)。
距离度量 ∥ ϕ ( a i ) − m c ∥ 2 \left\|\phi(a_{i})-m_{c}\right\|^{2} ∥ϕ(ai)−mc∥2可展开为
ϕ ( a i ) ⋅ ϕ ( a i ) − 2 ∑ a j ∈ π c ϕ ( a i ) ⋅ ϕ ( a j ) ∣ π c ∣ + ∑ a j , a l ∈ π c ϕ ( a j ) ⋅ ϕ ( a l ) ∣ π c ∣ 2 . \phi\left(a_{i}\right) \cdot \phi\left(a_{i}\right) - \frac{2 \sum_{a_{j} \in \pi_{c}} \phi\left(a_{i}\right) \cdot \phi\left(a_{j}\right)}{\left|\pi_{c}\right|} + \frac{\sum_{a_{j}, a_{l} \in \pi_{c}} \phi\left(a_{j}\right) \cdot \phi\left(a_{l}\right)}{\left|\pi_{c}\right|^{2}}. ϕ(ai)⋅ϕ(ai)−∣πc∣2∑aj∈πcϕ(ai)⋅ϕ(aj)+∣πc∣2∑aj,al∈πcϕ(aj)⋅ϕ(al).
因此,在此计算中仅使用内积。因此,给定一个核矩阵 K K K(其中 K i j = ϕ ( a i ) ⋅ ϕ ( a j ) K_{i j} = \phi(a_{i}) \cdot \phi(a_{j}) Kij=ϕ(ai)⋅ϕ(aj)),无需知道 ϕ ( a i ) \phi(a_{i}) ϕ(ai)和 ϕ ( a j ) \phi(a_{j}) ϕ(aj) 的显式表示即可计算点与质心之间的距离。可以证明,任何半正定矩阵 K K K都可以视为核矩阵[1]。
[1] Introduction to SVM: And Other Kernel-Based Learning Methods. 2020
核函数通常用于将原始点映射到内积。常用的核函数见下表,其中 κ ( a i , a j ) = K i j \kappa(a_{i}, a_{j})=K_{i j} κ(ai,aj)=Kij。
表1
| 多项式核函数 | κ ( a i , a j ) = ( a i ⋅ a j + c ) d \kappa(a_i, a_j) = (a_i \cdot a_j + c)^d κ(ai,aj)=(ai⋅aj+c)d |
|---|---|
| sigmoid核函数 | κ ( a i , a j ) = tanh ( c ( a i ⋅ a j ) + θ ) \kappa(a_i, a_j) = \tanh\left(c(a_i \cdot a_j) + \theta\right) κ(ai,aj)=tanh(c(ai⋅aj)+θ) |
| 高斯核函数 | κ ( a i , a j ) = exp ( − ∣ a i − a j ∣ 2 2 α 2 ) \kappa(a_i, a_j) = \exp(-\frac{|a_i - a_j |^2} {2 \alpha^2} ) κ(ai,aj)=exp(−2α2∣ai−aj∣2) |
2.1 Weighted Kernel k-means
我们现在介绍Kernel k-means目标函数的加权版本:
目标函数可表示为:
D ( { π c } c = 1 k ) = ∑ c = 1 k ∑ a i ∈ π c w i ∥ ϕ ( a i ) − m c ∥ 2 , \mathcal{D}\left(\left\{\pi_{c}\right\}_{c=1}^{k}\right)=\sum_{c=1}^{k} \sum_{a_{i} \in \pi_{c}} w_{i}\left\| \phi\left(a_{i}\right)-m_{c}\right\| ^{2}, D({πc}c=1k)=c=1∑kai∈πc∑wi∥ϕ(ai)−mc∥2,
其中
m c = ∑ a i ∈ π c w i ϕ ( a i ) ∑ a i ∈ π c w i , m_{c}=\frac{\sum_{a_{i} \in \pi_{c}} w_{i} \phi\left(a_{i}\right)}{\sum_{a_{i} \in \pi_{c}} w_{i}}, mc=∑ai∈πcwi∑ai∈πcwiϕ(ai),
且节点权重 w i w_{i} wi 为非负值。需注意, m c m_{c} mc表示“最优”簇代表,因为
m c = argmin z ∑ a i ∈ π c w i ∥ ϕ ( a i ) − z ∥ 2 . m_{c}=\underset{z}{\text{argmin}} \sum_{a_{i} \in \pi_{c}} w_{i}\left\| \phi\left(a_{i}\right)-z\right\| ^{2} . mc=zargminai∈πc∑wi∥ϕ(ai)−z∥2.
与之前一样,我们仅使用内积来计算距离,因为 ∥ ϕ ( a i ) − m c ∥ 2 \|\phi(a_{i})-m_{c}\|^{2} ∥ϕ(ai)−mc∥2等于
ϕ ( a i ) ⋅ ϕ ( a i ) − 2 ∑ a j ∈ π c w j ϕ ( a i ) ⋅ ϕ ( a j ) ∑ a j ∈ π c w j + ∑ a j , a l ∈ π c w j w l ϕ ( a j ) ⋅ ϕ ( a l ) ( ∑ a j ∈ π c w j ) 2 (1) \phi\left(a_{i}\right) \cdot \phi\left(a_{i}\right) - \frac{2 \sum_{a_{j} \in \pi_{c}} w_{j} \phi\left(a_{i}\right) \cdot \phi\left(a_{j}\right)}{\sum_{a_{j} \in \pi_{c}} w_{j}} + \frac{\sum_{a_{j}, a_{l} \in \pi_{c}} w_{j} w_{l} \phi\left(a_{j}\right) \cdot \phi\left(a_{l}\right)}{\left(\sum_{a_{j} \in \pi_{c}} w_{j}\right)^{2}} \tag{1} ϕ(ai)⋅ϕ(ai)−∑aj∈πcwj2∑aj∈πcwjϕ(ai)⋅ϕ(aj)+(∑aj∈πcwj)2∑aj,al∈πcwjwlϕ(aj)⋅ϕ(al)(1)
使用核矩阵 K K K,上述表达式可改写为
K i i − 2 ∑ a j ∈ π c w j K i j ∑ a j ∈ π c w j + ∑ a j , a l ∈ π c w j w l K j l ( ∑ a j ∈ π c w j ) 2 . (2) K_{i i} - \frac{2 \sum_{a_{j} \in \pi_{c}} w_{j} K_{i j}}{\sum_{a_{j} \in \pi_{c}} w_{j}} + \frac{\sum_{a_{j}, a_{l} \in \pi_{c}} w_{j} w_{l} K_{j l}}{\left(\sum_{a_{j} \in \pi_{c}} w_{j}\right)^{2}} . \tag{2} Kii−∑aj∈πcwj2∑aj∈πcwjKij+(∑aj∈πcwj)2∑aj,al∈πcwjwlKjl.(2)
2.2 Kernel k-means 计算复杂度
可以证明,只要K是半正定的(从而可以将其解释为格拉姆矩阵),Kernel k-means就会单调收敛。

显然,算法的瓶颈在于步骤2,即距离 d ( a i , m c ) d(a_{i}, m_{c}) d(ai,mc)的计算。第一项 K i i K_{i i} Kii对于 a i a_{i} ai是常数,不影响 a i a_{i} ai到簇的分配。第二项对每个数据点需要 O ( n ) \mathcal O(n) O(n)计算量,导致每次迭代的时间复杂度为 O ( n 2 ) \mathcal O(n^{2}) O(n2)。第三项对簇 c c c是固定的,因此在每次迭代中可以计算一次并存储;对所有簇而言,这需要 O ( ∑ c ∣ π c ∣ 2 ) = O ( n 2 ) \mathcal O(\sum_{c}|\pi_{c}|^{2})=O(n^{2}) O(∑c∣πc∣2)=O(n2)次操作。因此,每次迭代的复杂度为 O ( n 2 ) \mathcal O(n^{2}) O(n2)次标量运算。然而,对于稀疏矩阵 K K K,每次迭代的复杂度可优化为 O ( n z ) \mathcal O(nz) O(nz)次操作,其中 z z z为矩阵的行非零元素数。若总迭代次数为 τ \tau τ,则当输入为数据向量时,算法的时间复杂度为 O ( n 2 ( τ + m ) ) \mathcal O(n^{2}(\tau+m)) O(n2(τ+m));当输入为正定矩阵时,时间复杂度为 O ( n z ⋅ τ ) \mathcal O(nz \cdot \tau) O(nz⋅τ)。
3. EQUIVALENCE OF THE OBJECTIVES
我们已经知道谱聚类的图划分目标,详见A Tutorial on Spectral Clustering
3.1 Weighted Kernel k-Means as Trace Maximization
设 s c s_{c} sc为簇 c c c中的权重之和,即 s c = ∑ a i ∈ π c w i s_{c} = \sum_{a_{i} \in \pi_{c}} w_{i} sc=∑ai∈πcwi。定义 n × k n \times k n×k矩阵 Z Z Z 如下:
Z i c = { 1 s c 1 / 2 if a i ∈ π c , 0 else . Z_{i c} = \begin{cases} \frac{1}{s_{c}^{1/2}} & \text{if} \ \ a_{i} \in \pi_{c}, \\ 0 & \text{else}. \end{cases} Zic={sc1/210if ai∈πc,else.
显然,矩阵 Z Z Z的各列彼此正交,因为它们表示不相交的簇成员关系。假设 Φ \Phi Φ是由所有 ϕ ( a i ) \phi(a_{i}) ϕ(ai)向量( i = 1 , … , n i=1, \ldots, n i=1,…,n)构成的矩阵, W W W是权重对角矩阵。矩阵 Φ W Z Z T \Phi W Z Z^{T} ΦWZZT的第 i i i列等于包含 a i a_{i} ai的簇的均值向量。因此,Weighted Kernel k-Means目标函数可表示为:
D ( { π c } c = 1 k ) = ∑ c = 1 k ∑ a i ∈ π c w i ∥ ϕ ( a i ) − m c ∥ 2 = ∑ i = 1 n w i ∥ Φ ⋅ i − ( Φ W Z Z T ) ⋅ i ∥ 2 , \mathcal{D}\left(\left\{\pi_{c}\right\}_{c=1}^{k}\right) = \sum_{c=1}^{k} \sum_{a_{i} \in \pi_{c}} w_{i}\left\| \phi\left(a_{i}\right)-m_{c}\right\|^{2} = \sum_{i=1}^{n} w_{i}\left\| \Phi_{\cdot i} - \left(\Phi W Z Z^{T}\right)_{\cdot i}\right\|^{2}, D({πc}c=1k)=c=1∑kai∈πc∑wi∥ϕ(ai)−mc∥2=i=1∑nwi Φ⋅i−(ΦWZZT)⋅i 2,
其中 Φ ⋅ i \Phi_{\cdot i} Φ⋅i表示矩阵 Φ \Phi Φ的第 i i i列。令 Y ~ = W 1 / 2 Z \tilde{Y} = W^{1/2} Z Y~=W1/2Z,注意到 Y ~ \tilde{Y} Y~是正交矩阵( Y ~ T Y ~ = I k \tilde{Y}^{T} \tilde{Y} = I_{k} Y~TY~=Ik)。因此:
D ( { π c } c = 1 k ) = ∑ i = 1 n w i ∥ Φ ⋅ i − ( Φ W 1 / 2 Y ~ Y ~ T W − 1 / 2 ) ⋅ i ∥ 2 = ∑ i = 1 n ∥ Φ ⋅ i w i 1 / 2 − ( Φ W 1 / 2 Y ~ Y ~ T ) ⋅ i ∥ 2 = ∥ Φ W 1 / 2 − Φ W 1 / 2 Y ~ Y ~ T ∥ F 2 . \begin{aligned} \mathcal{D}\left(\left\{\pi_{c}\right\}_{c=1}^{k}\right) & = \sum_{i=1}^{n} w_{i}\left\| \Phi_{\cdot i} - \left(\Phi W^{1/2} \tilde{Y} \tilde{Y}^{T} W^{-1/2}\right)_{\cdot i}\right\|^{2} \\ & = \sum_{i=1}^{n} \left\| \Phi_{\cdot i} w_{i}^{1/2} - \left(\Phi W^{1/2} \tilde{Y} \tilde{Y}^{T}\right)_{\cdot i}\right\|^{2} \\ & = \left\| \Phi W^{1/2} - \Phi W^{1/2} \tilde{Y} \tilde{Y}^{T} \right\|_{F}^{2}. \end{aligned} D({πc}c=1k)=i=1∑nwi Φ⋅i−(ΦW1/2Y~Y~TW−1/2)⋅i 2=i=1∑n Φ⋅iwi1/2−(ΦW1/2Y~Y~T)⋅i 2= ΦW1/2−ΦW1/2Y~Y~T F2.
由于 trace ( A B ) = trace ( B A ) \text{trace}(AB) = \text{trace}(BA) trace(AB)=trace(BA)、 trace ( A T A ) = ∥ A ∥ F 2 \text{trace}(A^T A) = \|A\|_F^2 trace(ATA)=∥A∥F2且 trace ( A + B ) = trace ( A ) + trace ( B ) \text{trace}(A + B) = \text{trace}(A) + \text{trace}(B) trace(A+B)=trace(A)+trace(B),我们可以将 D ( { π c } c = 1 k ) D(\{\pi_c\}_{c=1}^k) D({πc}c=1k)改写为:
= trace ( W 1 / 2 Φ T Φ W 1 / 2 − W 1 / 2 Φ T Φ W 1 / 2 Y ~ Y ~ T − Y ~ Y ~ T W 1 / 2 Φ T Φ W 1 / 2 + Y ~ Y ~ T W 1 / 2 Φ T Φ W 1 / 2 Y ~ Y ~ T ) = \text{trace}\left( W^{1/2}\Phi^T\Phi W^{1/2} - W^{1/2}\Phi^T\Phi W^{1/2}\tilde{Y}\tilde{Y}^T - \tilde{Y}\tilde{Y}^T W^{1/2}\Phi^T\Phi W^{1/2} + \tilde{Y}\tilde{Y}^T W^{1/2}\Phi^T\Phi W^{1/2}\tilde{Y}\tilde{Y}^T \right) =trace(W1/2ΦTΦW1/2−W1/2ΦTΦW1/2Y~Y~T−Y~Y~TW1/2ΦTΦW1/2+Y~Y~TW1/2ΦTΦW1/2Y~Y~T)
= trace ( W 1 / 2 Φ T Φ W 1 / 2 ) − trace ( Y ~ T W 1 / 2 Φ T Φ W 1 / 2 Y ~ ) . = \text{trace}\left( W^{1/2}\Phi^T\Phi W^{1/2} \right) - \text{trace}\left( \tilde{Y}^T W^{1/2}\Phi^T\Phi W^{1/2}\tilde{Y} \right). =trace(W1/2ΦTΦW1/2)−trace(Y~TW1/2ΦTΦW1/2Y~).
我们注意到核矩阵 K K K等于 Φ T Φ \Phi^T \Phi ΦTΦ,且 trace ( W 1 / 2 K W 1 / 2 ) \text{trace} (W^{1/2} K W^{1/2}) trace(W1/2KW1/2)是一个常数。因此,weighted kernel k-means的最小化等价于
max Y ~ trace ( Y ~ T W 1 / 2 K W 1 / 2 Y ~ ) , (3) \max_{\tilde{Y}} \text{trace}\left(\tilde{Y}^T W^{1/2} K W^{1/2} \tilde{Y}\right), \tag{3} Y~maxtrace(Y~TW1/2KW1/2Y~),(3)
其中 Y ~ \tilde{Y} Y~是正交矩阵。
3.2 Ratio Assosicate
最容易转化为迹最大化的目标是Ratio Assosicate。最小化类间Cut等价于最大化类内Link:
max { ∑ c = 1 k links ( V c , V c ) ∣ V c ∣ = ∑ c = 1 k x c T A x c x c T x c = ∑ c = 1 k x ~ c T A x ~ c } , \max \left\{ \sum_{c=1}^{k} \frac{\text{links}(\mathcal{V}_{c}, \mathcal{V}_{c})}{|\mathcal{V}_{c}|} = \sum_{c=1}^{k} \frac{x_{c}^{T} A x_{c}}{x_{c}^{T} x_{c}} = \sum_{c=1}^{k} \tilde{x}_{c}^{T} A \tilde{x}_{c} \right\}, max{c=1∑k∣Vc∣links(Vc,Vc)=c=1∑kxcTxcxcTAxc=c=1∑kx~cTAx~c},
其中 A A A为图的邻接矩阵, x ~ c = x c / ( x c T x c ) 1 / 2 \tilde{x}_{c} = x_{c} / (x_{c}^{T} x_{c})^{1/2} x~c=xc/(xcTxc)1/2。上述内容可写为最大化 trace ( X ~ T A X ~ ) \text{trace}(\tilde{X}^{T} A \tilde{X}) trace(X~TAX~)。由此可知,若 K = A K = A K=A且 W = I W = I W=I,则weighted kernel k-means的迹最大化问题与Ratio Assosicate的迹最大化问题相等。
3.3 Ratio Cut
类似地,
min { ∑ c = 1 k x c T ( D − A ) x c x c T x c = ∑ c = 1 k x ~ c T ( D − A ) x ~ c = ∑ c = 1 k x ~ c T L x ~ c } , \min \left\{ \sum_{c=1}^{k} \frac{x_c^T (D - A) x_c}{x_c^T x_c} = \sum_{c=1}^{k} \tilde{x}_c^T (D - A) \tilde{x}_c = \sum_{c=1}^{k} \tilde{x}_c^T L \tilde{x}_c \right\}, min{c=1∑kxcTxcxcT(D−A)xc=c=1∑kx~cT(D−A)x~c=c=1∑kx~cTLx~c},
其中矩阵 L = D − A L = D - A L=D−A称为图的拉普拉斯矩阵。因此,我们可以将该问题表示为最小化 trace ( X ~ T L X ~ ) \text{trace}(\tilde{X}^T L \tilde{X}) trace(X~TLX~)。考虑矩阵 I − L I - L I−L,并注意到 trace ( X ~ T ( I − L ) X ~ ) = trace ( X ~ T X ~ ) − trace ( X ~ T L X ~ ) \text{trace}(\tilde{X}^T (I - L) \tilde{X}) = \text{trace}(\tilde{X}^T \tilde{X}) - \text{trace}(\tilde{X}^T L \tilde{X}) trace(X~T(I−L)X~)=trace(X~TX~)−trace(X~TLX~)。由于 X ~ \tilde{X} X~是正交矩阵, trace ( X ~ T X ~ ) = k \text{trace}(\tilde{X}^T \tilde{X}) = k trace(X~TX~)=k,因此最大化 trace ( X ~ T ( I − L ) X ~ ) \text{trace}(\tilde{X}^T (I - L) \tilde{X}) trace(X~T(I−L)X~)等价于最小化 trace ( X ~ T L X ~ ) \text{trace}(\tilde{X}^T L \tilde{X}) trace(X~TLX~)。
综上所述,我们得出了与比率割等价的迹最大化问题:最小化比率割等价于最大化迹 ( X ~ T ( I − L ) X ~ ) (\tilde{X}^{T}(I-L) \tilde{X}) (X~T(I−L)X~)。此时的等价条件变为: W = I W=I W=I, K = I − L K=I-L K=I−L。需要注意的是,尽管拉普拉斯 L L L是半正定的,但 I − L I-L I−L可能是不定的。我们将在4.4节讨论如何处理这一问题。
3.4 Normalized Cut
类似地,直接上结论:
上述内容可改写为 trace ( Y T D − 1 / 2 A D − 1 / 2 Y ) \text{trace}(Y^{T}D^{-1/2}AD^{-1/2}Y) trace(YTD−1/2AD−1/2Y),其中 Y = D 1 / 2 X ^ Y = D^{1/2}\hat{X} Y=D1/2X^且为正交矩阵。在此情形下,我们设置加权核k均值权重矩阵 W = D W=D W=D,核矩阵 K = D − 1 A D − 1 K=D^{-1}AD^{-1} K=D−1AD−1。可以验证,此时 Y = Y ~ Y = \tilde{Y} Y=Y~;因此,加权核k均值与归一化割的目标函数完全等价。若矩阵 K K K为正定矩阵,我们即可通过加权核k均值迭代最小化归一化割。
3.5 Spectral Connection
线性代数中的一个标准结论指出,若放宽迹最大化问题,允许Y为任意正交矩阵,则最优Y的形式为 V k Q V_kQ VkQ,其中 V k V_k Vk由 W − 1 / 2 A W − 1 / 2 W^{-1/2}AW^{-1/2} W−1/2AW−1/2的前k个主特征向量组成,Q为任意 k × k k×k k×k正交矩阵。由于这些特征向量并非指示向量,因此需要对特征向量进行后处理(或舍入)以获得离散聚类。几乎所有谱聚类目标都可视为一般迹最大化问题的特例。相应的谱算法通过计算并使用 W − 1 / 2 A W − 1 / 2 W^{-1/2}AW^{-1/2} W−1/2AW−1/2的前 k k k个主特征向量。我们提出的等价性表明,谱解法并非必需,目标函数可通过核k均值直接优化。
谱方法通常表现良好,因为它们通过松弛原始聚类目标计算全局最优解。然而,这些方法在超大规模图上的计算成本极高。相比之下,核 k k k-means算法速度快,但容易陷入较差的局部极小值,且对初始划分敏感。因此我们将利用上述分析开发一种快速多层算法,以克服这些问题。在开发该算法之前,我们先简要说明如何为图聚类强制实现正定性。
3.6 Enforcing Positive Definiteness
对于加权图关联问题,我们定义矩阵 K = W − 1 A W − 1 K = W^{-1}AW^{-1} K=W−1AW−1以映射到加权核k均值算法。然而,当 A A A为任意邻接矩阵时, W − 1 A W − 1 W^{-1}AW^{-1} W−1AW−1未必是正定的,因此核k-means算法不一定会收敛。在本节中,我们将展示如何通过向 K K K引入适当的对角移位来避免这一问题,并简要讨论这种对角移位对加权核k-means算法实际性能的影响。
给定矩阵 A A A,定义 K ′ = σ W − 1 + W − 1 A W − 1 K' = \sigma W^{-1} + W^{-1}AW^{-1} K′=σW−1+W−1AW−1,其中 σ \sigma σ是一个足够大的正常数,以确保 K ′ K' K′为正定矩阵。由于 W − 1 W^{-1} W−1是正定对角矩阵,添加 σ W − 1 \sigma W^{-1} σW−1会向 W − 1 A W − 1 W^{-1}AW^{-1} W−1AW−1的对角线引入正元素。
在(3)中用 (K’) 替代 (K),可得
trace ( Y ~ T W 1 / 2 K ′ W 1 / 2 Y ~ ) = trace ( Y ~ T W 1 / 2 σ W − 1 W 1 / 2 Y ~ ) + trace ( Y ~ T W − 1 / 2 A W − 1 / 2 Y ~ ) = σ k + trace ( Y ~ T W − 1 / 2 A W − 1 / 2 Y ~ ) . \text{trace}\left(\tilde{Y}^T W^{1/2}K'W^{1/2}\tilde{Y}\right) = \text{trace}\left(\tilde{Y}^T W^{1/2}\sigma W^{-1}W^{1/2}\tilde{Y}\right) + \text{trace}\left(\tilde{Y}^T W^{-1/2}AW^{-1/2}\tilde{Y}\right) = \sigma k + \text{trace}\left(\tilde{Y}^T W^{-1/2}AW^{-1/2}\tilde{Y}\right). trace(Y~TW1/2K′W1/2Y~)=trace(Y~TW1/2σW−1W1/2Y~)+trace(Y~TW−1/2AW−1/2Y~)=σk+trace(Y~TW−1/2AW−1/2Y~).
因此,使用 K ′ K' K′时的maximizer Y ~ \tilde{Y} Y~与(4)中的加权关联问题的maximizer一致,只不过 K ′ K' K′ 被构造为正定矩阵。对 K ′ K' K′执行加权核k-means算法可实现加权关联目标的单调优化。
下表总结了各种图目标的权重和正定核。尽管添加对角移位不会改变全局最优解,但需要注意的是,过大的移位可能导致算法生成的簇质量下降。这是因为随着 σ \sigma σ增大,点会变得更接近其当前质心,而远离其他质心。
表2
| 优化目标 | 节点权重 | Kernel |
|---|---|---|
| Ratio Assoc. | 1 for each node | K = σ I + A K=\sigma I+A K=σI+A |
| Ratio Cut | 1 for each node | K = σ I − L K=\sigma I-L K=σI−L |
| Kernighan-Lin | 1 for each node | K = σ I − L K=\sigma I-L K=σI−L |
| Norm. Cut | Degree of the node | K = σ D − 1 + D − 1 A D − 1 K=\sigma D^{-1}+D^{-1} A D^{-1} K=σD−1+D−1AD−1 |
4 THE MULTILEVEL ALGORITHM
通常,优化加权图聚类目标的最佳算法采用谱聚类方法。在本节中,我们利用 4.2 节中的理论等价性,开发了一种新的基于核的多层聚类算法。
我们的多层算法框架与Metis [2](一种用于优化Kernighan-Lin目标的流行多层图聚类算法)类似。图1给出了该多层框架的图形化概述。我们假设给定一个输入图 G 0 = ( V 0 , E 0 , A 0 ) G_{0}=(V_{0}, E_{0}, A_{0}) G0=(V0,E0,A0)以及所需的划分数目。下面,我们从三个阶段描述我们的多层算法:粗化、基础聚类和细化。
[2] G. Karypis and V. Kumar, A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs.
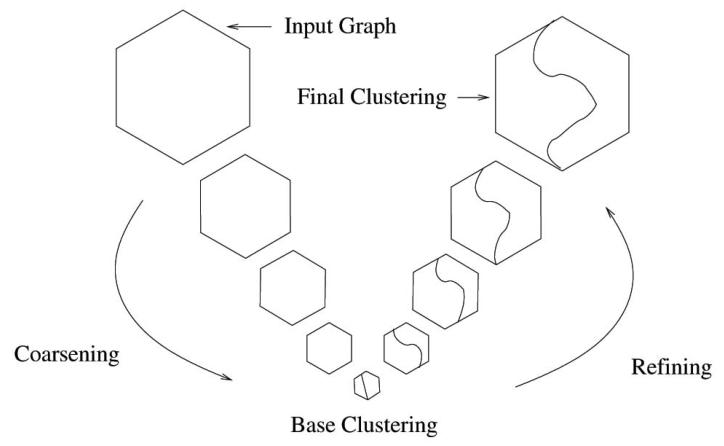
4.1 粗化
从初始图 G 0 G_0 G0开始,粗化阶段反复将图转换为越来越小的图,使得 ∣ V 0 ∣ > ∣ V 1 ∣ > … > ∣ V m ∣ |V_0| > |V_1| > \ldots > |V_m| ∣V0∣>∣V1∣>…>∣Vm∣。将图从 G i G_i Gi粗化为 G i + 1 G_{i+1} Gi+1时, G i G_i Gi中的节点集被合并为 G i + 1 G_{i+1} Gi+1中的超节点。当将一组节点合并为单个超节点时,超节点的出边权重取原始节点出边权重之和。
重边粗化(heavy edge coarsing)。该方法步骤如下:给定一个图,初始时所有节点均为未标记状态。随机顺序遍历每个顶点 x x x,若 x x x未标记,则将其与所有未标记邻居(这里的邻居是指那些有边连出去的点)中边权重最大的顶点 y y y合并,然后标记 x x x和 y y y。若 x x x的所有邻居均已标记,则仅标记 x x x而不进行合并。当所有顶点均被标记时,粗化过程完成。
这种粗化过程对Kernighan-Lin目标效果良好,但我们将其推广为最大割粗化过程,使其能有效适用于更广泛的目标类别。给定顶点 x x x,找到最大化以下目标的未标记 y y y:
max y e ( x , y ) w ( x ) + e ( x , y ) w ( y ) , \max_{y}\frac{e(x, y)}{w(x)} + \frac{e(x, y)}{w(y)}, ymaxw(x)e(x,y)+w(y)e(x,y),
其中 e ( x , y ) e(x, y) e(x,y)表示顶点 x , y x,y x,y的边权重, w ( x ) w(x) w(x)为表2中定义的顶点权重。在归一化割场景中,顶点的权重为其度数,此时(5)式退化为 x x x与 y y y之间的归一化割;对于比率割问题,由于所有顶点权重均为1,上式简化为最重边准则。
4.2 基础聚类
最终,图会被粗化到只剩下极少数节点。我们通过一个参数来指定期望的最粗化图的大小;在实验中,当图的节点数少于 5 ∗ k 5*k 5∗k时(k为期望的簇数),我们停止粗化。此时,我们对最粗化的图直接进行基础聚类。
一种基础聚类方法是Metis的区域增长算法。该算法通过选择随机顶点并以广度优先的方式在顶点周围扩展区域来形成簇,从而对基础图进行聚类。由于生成的簇的质量取决于初始顶点的选择,因此该算法会使用不同的起始顶点运行多次,并选择最佳的聚类结果。这种基础聚类方法效率极高,不过它倾向于生成大小几乎相等的簇。
另外,我们发现一种先进的谱聚类算法可以提供有效的基础聚类 [3]。该谱算法将归一化割算法推广到可处理任意权重的情况。因此,基础聚类可以针对不同的图聚类目标进行优化。由于最粗化的图明显小于输入图,因此谱方法在速度上是可行的。
[3] Dhillon, Y. Guan, and B. Kulis, A Unified View of Kernel k-Means, Spectral Clustering and Graph Cuts, Technical Report.
Ours
除了区域增长和谱聚类方法外,我们还测试了第三种基础聚类方法:二分法。在这种方法中,我们将最粗化的图二等分为两个簇,然后将这两个簇再细分为四个簇,依此类推,直到获得 k 个簇。在对一个簇进行二分时,我们运行 k = 2 k=2 k=2的多层算法,将图粗化到最低 20 20 20个节点的层级,并在最底层使用随机初始化的kernel k-means算法。区域增长和二分法无需计算特征向量,这使得它们比谱初始化方法更简单且更具吸引力。
4.3 细化
算法的最后一个阶段是细化阶段。给定图 G i G_i Gi,我们构造图 G i − 1 G_{i-1} Gi−1。 G i G_i Gi中的聚类通过以下方式诱导 G i − 1 G_{i-1} Gi−1中的聚类:如果 G i G_i Gi中的某个超节点属于簇 c c c,则 G i − 1 G_{i-1} Gi−1中由该超节点分裂出的所有原始节点均属于簇 c c c。这为图 G i − 1 G_{i-1} Gi−1提供了初始聚类,随后通过细化算法对其进行优化。需要注意的是,我们也会对最粗化的图运行细化算法。当对原始图 G 0 G_0 G0完成细化后,多层算法终止。由于每一层都有良好的初始聚类,细化过程通常收敛非常快,使得该过程效率极高。
我们的多层算法在细化步骤中使用weighted kernel k-means算法。根据待优化的图聚类目标,我们可以在细化的每个步骤中,结合当前层的邻接矩阵设置权重和核矩阵。除最粗化层外,加权核k 均值的初始化均采用前一层诱导的聚类结果。
我们已通过多种方式对加权核k均值算法的实现进行了优化,以实现最高效率。例如,我们发现仅对加权核k均值算法使用“边界”点可显著加快计算速度,同时几乎不会降低聚类质量。在运行核k均值算法时,一次迭代中从一个簇交换到另一个簇的大多数点都位于簇边界上;也就是说,这些节点包含与另一个簇中节点相连的边。在加权核k均值算法中确定将哪些点从一个簇移动到另一个簇时,我们可以选择仅考虑这些边界点以加快计算速度。
此外,我们可以高效地计算核空间中的距离。我们可以预先计算每个簇的 w ( V c ) w(V_{c}) w(Vc)和簇内连接权重 l i n k s ( V c , V c ) links(V_{c}, V_{c}) links(Vc,Vc)以节省计算时间(见4.2节末尾),并且无需显式构造核矩阵或使用任何浮点除法即可比较距离(因此,如果初始边权重为整数,我们的代码仅使用整数运算)。
4.4 Local Search
运行标准批量核k均值算法时,一个常见问题是该算法容易陷入质量较差的局部极小值。针对这一问题,一种有效的解决技术是通过结合增量策略进行局部搜索。增量核k均值算法的一个步骤是尝试将单个点从一个簇移动到另一个簇,以改善目标函数。对于单次移动,我们寻找能使目标函数值降幅最大的移动;对于连续移动,我们寻找这样的移动序列。使用局部搜索得到的局部极小值集合是使用批量算法得到的局部极小值集合的超集。这通常能使算法找到更好的局部极小值。文献[4]表明,增量k均值算法可以高效实现,且这种实现方式可以轻松扩展到加权核k均值算法。在实践中,我们交替使用标准批量更新和增量更新。更多细节见文献[4]。
I.S. Dhillon, Y. Guan, and J. Kogan, “Iterative Clustering of High Dimensional Text Data Augmented by Local Search,” Proc. 2002
5 实验
5.1 Compare with Graph Clustering
在本节中,我们将展示一系列实验以验证我们称为 Graclus 的多层算法的效率和有效性。图聚类问题出现在各种现实生活中的模式识别应用中;我们研究了基因网络分析、社交网络分析和图像分割领域的问题。这些应用通常没有真实的聚类标签,但提供了实际中常见的大规模聚类问题案例。
表3: 运行时间(Sec.)
| Dataset | spectral | graclusS0 | graclusS20 | graclusKO | graclusK20 |
|---|---|---|---|---|---|
| add32 | 37.86 | 2.25 | 2.43 | .02 | .02 |
| finance256 | 636.82 | 2.33 | 2.34 | .23 | .32 |
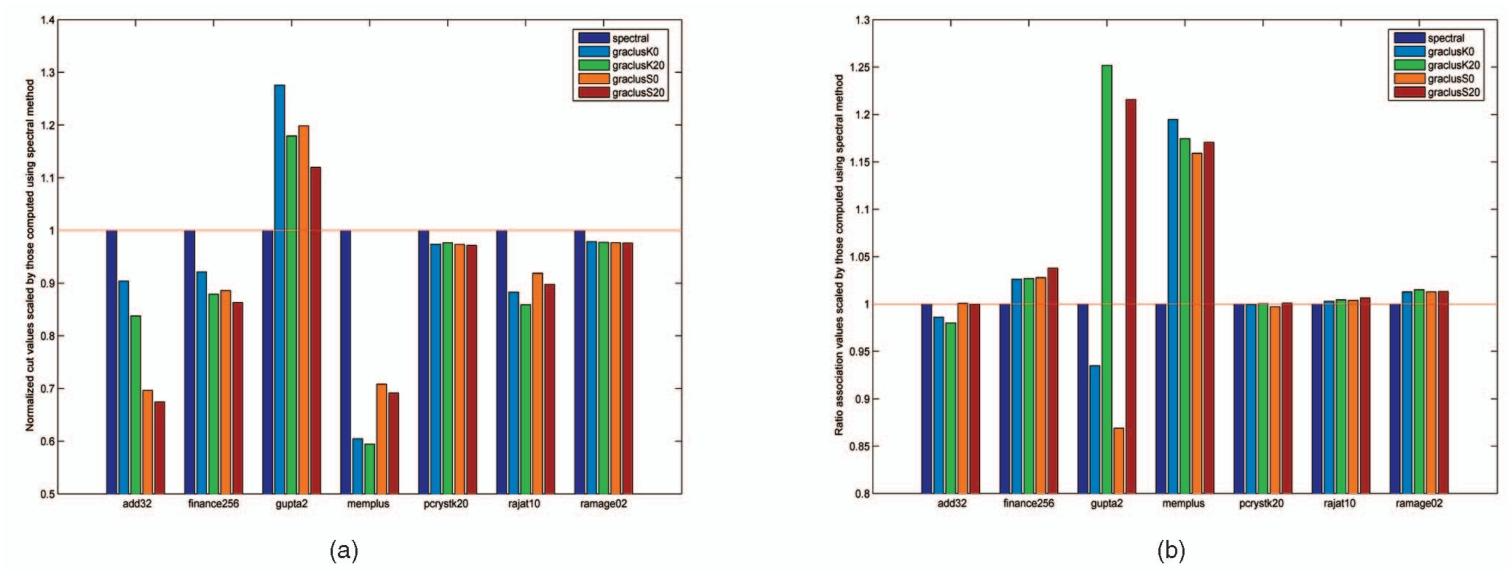 图5: 局部搜索和不同基础聚类方法的效果。图中每个五条形组的所有值均通过谱方法生成的对应值进行归一化。请注意,在(a)中,水平线以下的条形表示 Graclus 表现更好;在(b)中,水平线以上的条形表示 Graclus 表现更好。图 5 针对 128 个簇,从(a)归一化割和(b)Ratio Associate值两方面对谱方法和 Graclus 进行了质量比较。
图5: 局部搜索和不同基础聚类方法的效果。图中每个五条形组的所有值均通过谱方法生成的对应值进行归一化。请注意,在(a)中,水平线以下的条形表示 Graclus 表现更好;在(b)中,水平线以上的条形表示 Graclus 表现更好。图 5 针对 128 个簇,从(a)归一化割和(b)Ratio Associate值两方面对谱方法和 Graclus 进行了质量比较。