设备驱动与文件系统:04 从生磁盘到文件
从磁盘到文件的抽象:建立字符流与盘块号的映射
好,开始探讨的核心内容是如何从磁盘到文件进行抽象,也就是研究从磁盘到文件这一层抽象的具体实现过程。
上一课,我们已经讲了一些抽象内容,包括生磁盘的使用方式以及操作系统驱动磁盘的原理,即如何从一个盘块号最终实现对磁盘的读写操作。并且,我们也提到了多个进程发出盘块号后,最终都能将数据存储到磁盘的柱面、磁头、扇区中。
但上一课也留下了一个关键问题:盘块号从哪里来?我们使用磁盘真的是直接用盘块号吗? 实际上,这并不符合我们的直观想法,我们在使用磁盘时,往往是通过文件来进行的,这样更加自然,也更符合用户的认知习惯,能让用户使用起来更加方便。所以,这节课我们就要深入讲解如何从生磁盘抽象出文件,反过来,也就是如何从文件得到盘块号。因为一旦得到盘块号,就能与上一讲的内容衔接起来,形成一个完整的体系,从而实现文件在磁盘上的读写操作。因此,这一讲的核心关键就在于从文件怎么得到盘块号,以及从盘块号怎么抽象成文件。
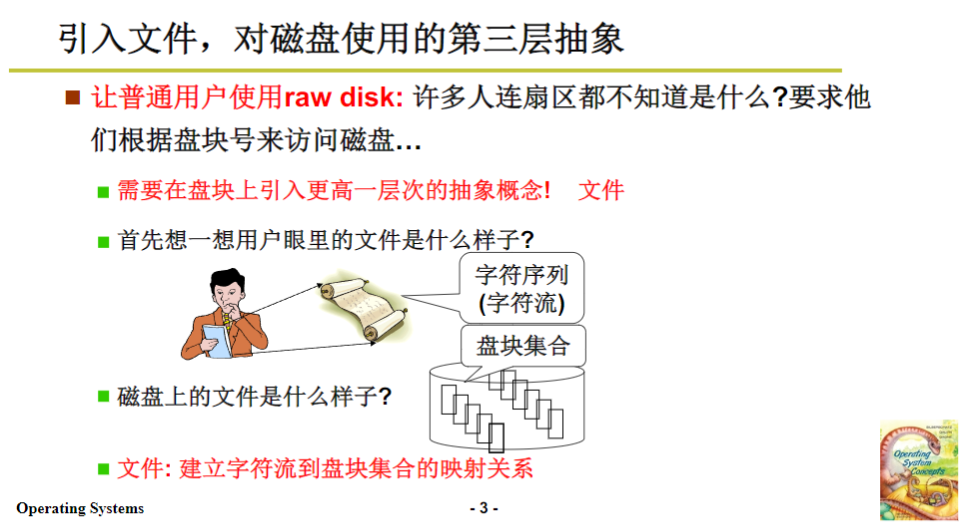
人们用文件的方式使用磁盘,也有特定的名称。上一课讲的是生磁盘(raw disk),这一讲则是熟磁盘(cook disk),也就是我们常说的对磁盘进行“煮熟”处理。引入文件,是对磁盘使用的第三层抽象。之所以进行这一层抽象,是因为引入更高一层的抽象后,使用起来会更加方便。如果让普通用户使用生磁盘,他们需要了解盘块号等复杂概念,而这些概念对于普通用户来说理解成本较高,操作系统便引入了文件这个更高层次的概念,将这些复杂细节隐藏起来。有了文件后,用户在使用、操纵和读写信息时,会变得更加直观和自然。
那么,这个故事该从哪里开始讲起呢?我们需要先弄清楚用户眼里的文件到底是什么样子。在现实生活中,文件非常常见,一本书、一张纸或几张纸,都可以看作是文件。在这些文件中,我们通常是一行一行往下阅读,从本质上来说,这种二维的组织形式,如果将纸张足够放大,其实就是一行内容一直往后延伸,文件的核心就是一个字符流。人们并不关心文件存放的位置和来源,在我们眼中,文件被抽象成了一堆字符组成的流。当然,用户眼里的文件是一个抽象概念,在计算机中,这些文件最终要存储在磁盘上。而磁盘是由一堆盘块组成的,所以磁盘上的文件就是由这些盘块拼接而成,不同的盘块存放文件的不同部分。由此可见,这节课的核心内容就是要建立一个从字符流到盘块的映射关系,这也呼应了我们一开始所说的,从文件得到盘块号是这一讲的核心。
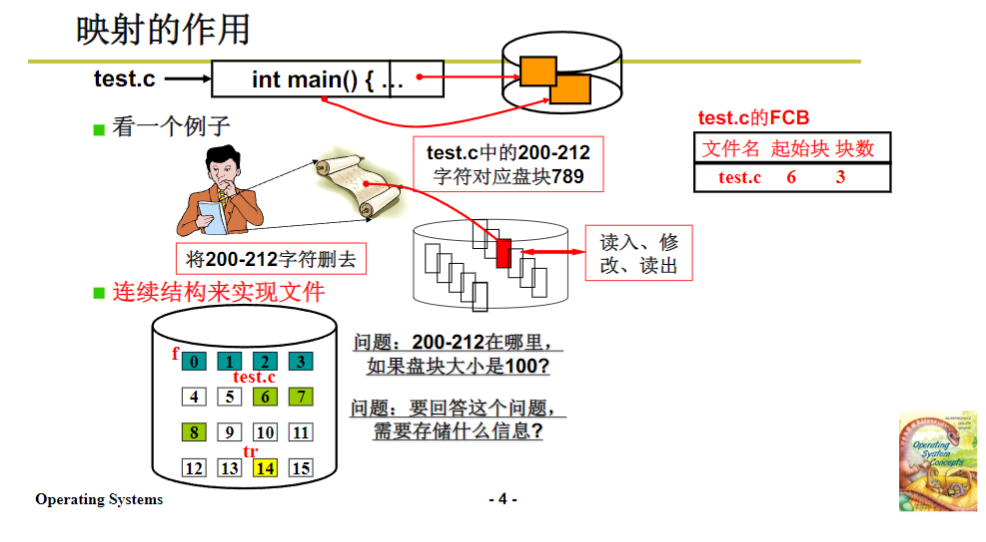
为了更好地理解这个映射关系,我们来举个例子。假设我们读取一个test.c文件,这是一个用C语言编写的代码文件。在读取过程中,我们发现其中200 - 212这一段字符可能存在错误,需要对其进行改写。在我们的认知里,test.c文件是一个连续的字符流,从0字符开始,长度理论上可以是无穷无尽的。我们想要对200 - 212这部分字符进行操作,就需要找到它们在磁盘上对应的盘块号,这就是一个映射过程。当我们找到789这个映射(假设对应盘块号)后,就可以按照上一课讲的内容,将盘块号发送到电梯队列,经过一系列操作,将数据读取到内存缓冲区,进行修改后,再通过电梯队列写回磁盘。这样,从用户的角度来看,原来的字符流中特定部分就被修改了,而这一切操作的背后,就是映射关系在起作用。
操作系统负责维护这个映射关系,确切地说,操作系统封装并隐藏了这个映射过程。在用户眼中,他们面对的只是一个字符流,可以随意对其进行各种操作,如删除特定字符段、增加字符、拷贝字符等。当用户发出这些操作请求时,操作系统会负责解释请求,通过查找映射关系,确定字符流位置对应的盘块号,然后发出磁盘读写请求,将请求放入电梯队列,最终实现用户的操作需求。
接下来,我们来探讨一下文件存储的不同结构,因为不同的结构代表了不同的映射关系。
连续存放结构
第一种结构是连续存放。以test.c文件为例,操作系统会将文件一块一块连续地存储在磁盘上。假设每个盘块能存放100个字节的内容,那么0 - 99个字符就会存放在第6个盘块,100 - 199个字符存放在第7个盘块。如果我们要确定200 - 212个字符所在的盘块号,通过简单计算(200÷100,再加上初始盘块号6),就可以得出其在第8号盘块。
在这种连续存放结构下,映射表中只需要存放文件的起始盘块号,如test.c文件的起始盘块号6。有了这个起始盘块号,再结合每个盘块能存放的字符数(这是操作系统初始化时确定的参数,例如Linux 0.11中一个盘块大小为1K,由两个512字节的扇区组成),就可以根据字符流中的位置计算出对应的盘块号,从而建立起映射关系。这样,我们对文件的读写操作就转化为了对字符流中特定字符的操作,操作系统会负责将这些操作转换为对磁盘盘块的读写。
连续存放结构的优点是读写速度快,适合直接读写操作,因为计算盘块号的过程简单直接,中间没有额外的复杂操作。但它的缺点也很明显,不适合文件的动态增长。当文件不断增加内容,例如test.c文件增长到需要第14个盘块时,如果要保证连续存放,可能会覆盖掉其他文件的空间,或者需要将整个文件挪动到一个更大的连续空间,这不仅操作不便,而且非常浪费时间,需要对整个文件进行拷贝、重新读取和写入操作。所以,这种结构比较适合像词典文件这类几乎不再变化的文件存储,因为它们适合顺序读取和查找;而对于像Word报告这类不断进行增删改操作的动态变化文件,就不太适用。
链式存放结构
除了连续存放结构,还有链式存放结构。同样以test.c文件为例,第一块数据存放在某个盘块(假设为1号盘块),在第一块的末尾会记录下第二块数据所在的盘块号(假设为10号盘块),第二块的末尾再记录第三块的盘块号(假设为17号盘块),以此类推,形成类似数据结构中链表的形式。
在链式存放结构下,映射表中依然存放文件的第一个盘块号,如1号盘块。当我们要查找200 - 212个字符所在的盘块时,先根据计算确定其在逻辑上的第二块(因为200÷100 = 2,从0开始计数),然后读取第一块盘块的数据,获取到第二块盘块的号10,再读取10号盘块,获取到第三块盘块号17,最后读取17号盘块,就能找到200 - 212个字符。
这种链式存放结构的优点是适合文件的动态增长,因为只需要找到最后一个盘块,再链接上新的空闲盘块即可,不需要移动前面已有的数据。但它的缺点是读写速度较慢,每次读写都需要沿着链表依次读取盘块,相比连续存放结构,增加了很多额外的读取操作。所以,链式存放结构是存储起来相对较慢,但动态变化操作比较快,与连续存放结构形成了鲜明对比。
索引存放结构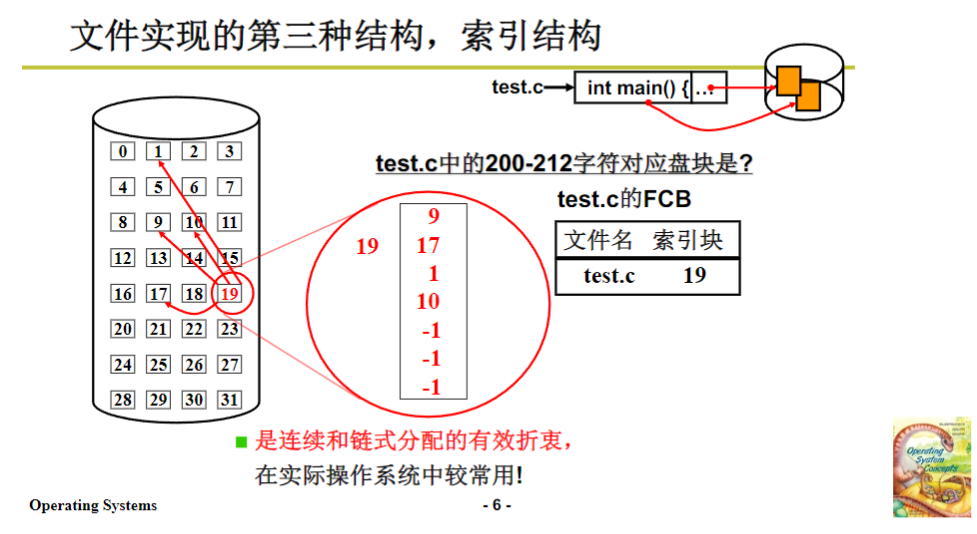
另一种常见的结构是索引存放结构。索引,英文为index,在之前讲文件视图读写日记时提到的inode,其实就是索引结构下的一种实现,其中的“i”就对应这里的index。在索引结构中,会有专门的一块磁盘空间用于存放索引信息,这个索引信息就如同目录一样,记录着文件不同部分(逻辑块)对应的实际盘块号。例如,0 - 99个字符存放在第9号盘块,100 - 199个字符存放在第17号盘块,这些对应关系都会记录在索引表中。
当我们要查找200 - 212个字符所在的盘块时,首先根据文件的fcb(file control block,文件控制块,也可称为inode)读取索引块的内容,然后在索引表中查找,确定200 - 212个字符对应的盘块号,最后读取该盘块的数据。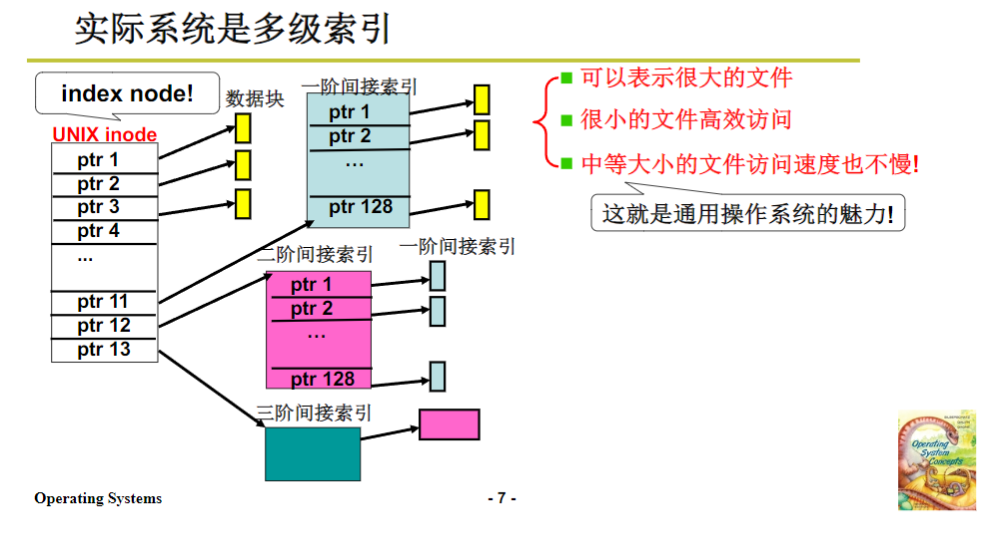
在实际系统中,常常会采用多级索引的方式。对于小文件,索引节点中的部分信息可以直接对应数据块,在open文件时,这些信息会被读入内存,这样在读写小文件时,不需要启动磁盘读取操作,就能直接确定盘块号,速度非常快,与连续存放结构的读写效率相当;对于中等大小的文件,通过一层链接读取一次索引块,就能获取到盘块号;对于特别大的文件,则可能需要读取两层或更多层的索引块。这种多级索引方式能够很好地适应不同大小的文件,既适合文件的增长,读写速度也相对较快,因此在现实生活中被广泛应用,几乎所有的Unix系统和Linux系统的文件系统,都是基于索引结构进行改造的。
总结与思考
讲到这里,我们来总结一下这节课的内容。我们对磁盘的使用不再使用生磁盘和盘块号,而是使用字符流。操作系统为了实现这种转变,设计了相应的结构和映射表。通过顺序结构、链式结构、索引结构等不同的存储结构,操作系统维护着相关信息,主要是索引信息和fcb信息。根据这些信息,操作系统能够将用户对字符流中任意位置的读写操作,计算出对应的盘块号,然后将盘块号放入电梯队列,在磁盘中断时取出,计算出柱面、磁头、扇区(c h s)信息,通过输出操作发送到磁盘控制器,完成整个读写过程。
最后,我们来思考一个问题:如果像专门给词霸这样的词典来设计存储方式,采用哪种方式好呢?其实,我们之前已经提到过,顺序存放结构比较适合,因为词典文件内容相对固定,几乎不再变化,顺序结构的快速读写和适合查找的特点能够很好地满足其需求。