论文笔记:Large Language Models for Next Point-of-Interest Recommendation
SIGIR 2024
1 intro
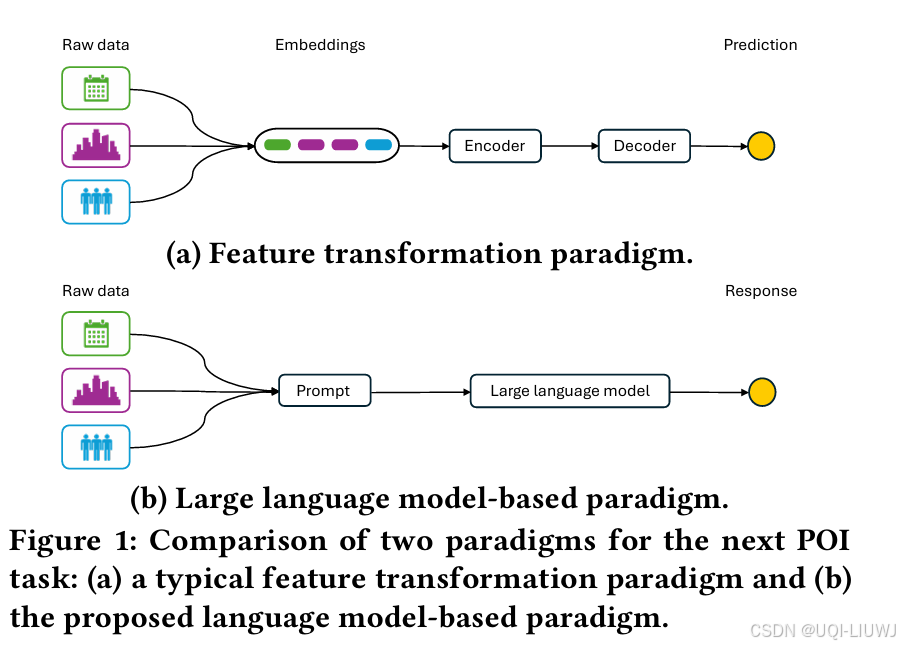
- 传统的基于数值的POI推荐方法在处理上下文信息时存在两个主要限制
- 需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失
- 仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解
- ——>使用预训练的大语言模型来进行推荐
- 允许在原始格式下保留异构的LBSN数据,从而避免上下文信息的丢失
- 能够通过包含常识知识来理解上下文信息的内在含义
2 方法
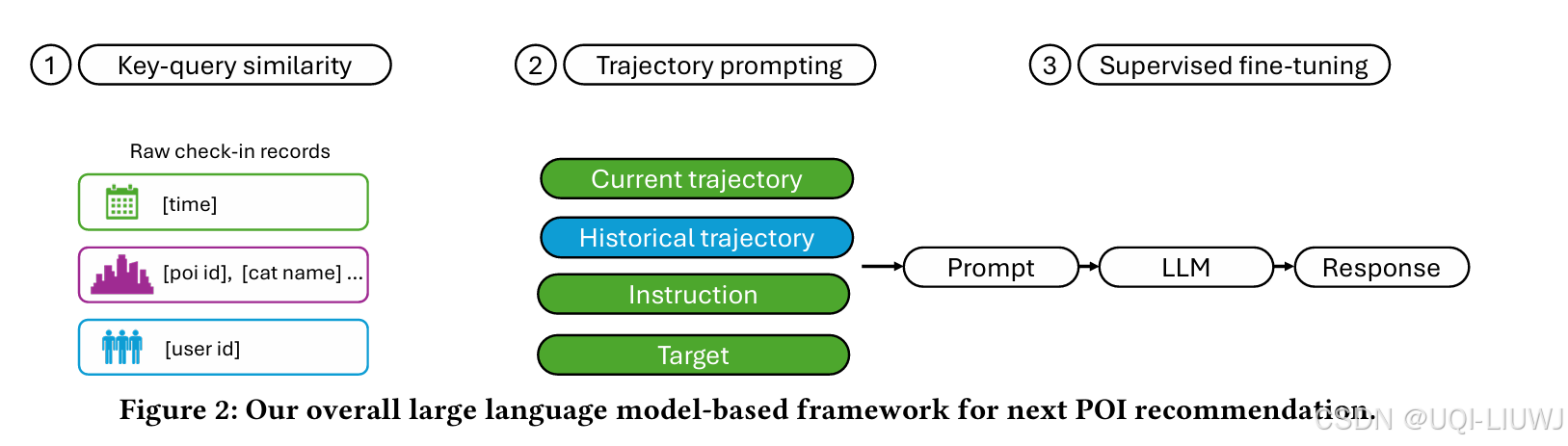
2.1 轨迹提示

-
当前轨迹块(current trajectory block)
-
当前轨迹块中只包含当前用户的一条轨迹,且不含最后一个签到点
-
-
历史轨迹块(historical trajectory block)
-
在当前轨迹块和历史轨迹块中,为每条签到记录生成一个句子
-
对每条签到记录 𝑞 = (𝑢,𝑝,𝑐,𝑡,𝑔),构造句子为:
-
在 [time],用户 [user id] 访问了 POI 编号 [poi id],该地点属于 [poi category name] 类别,其类别 ID 为 [category id]。
-
为节省 token 数量,没有将地理坐标(geo-coordinates)包含在句子中
-
同时论文发现,未经特别地图数据微调的 LLM 无法很好地理解坐标信息
-
-
-
历史轨迹块则可以包含来自当前用户及其他行为相似用户的多条轨迹,以应对轨迹短和冷启动问题
-
-
指令块(instruction block)
-
指令块用于引导模型关注目标任务,并提醒 POI ID 的取值范围
-
-
目标块(target block)
-
目标块用于微调和评估阶段,包含要预测的签到记录(时间戳、用户 ID、POI ID),但在推理阶段不会作为输入
-
作者尝试将 POI 类别信息加入指令块和目标块,希望模型更关注 POI ID 与类别之间的关系,但实验显示效果提升不明显,可能模型已隐式学会这种关系。
-
2.2 键-查询对相似性计算
- 为了从用户历史轨迹及其他用户轨迹中挖掘行为模式,提出了适用于自然语言轨迹格式的键-查询对相似度计算框架
- 当前轨迹块中的轨迹被视为Key
- 所有结束时间早于该 Key 的轨迹被视为Query
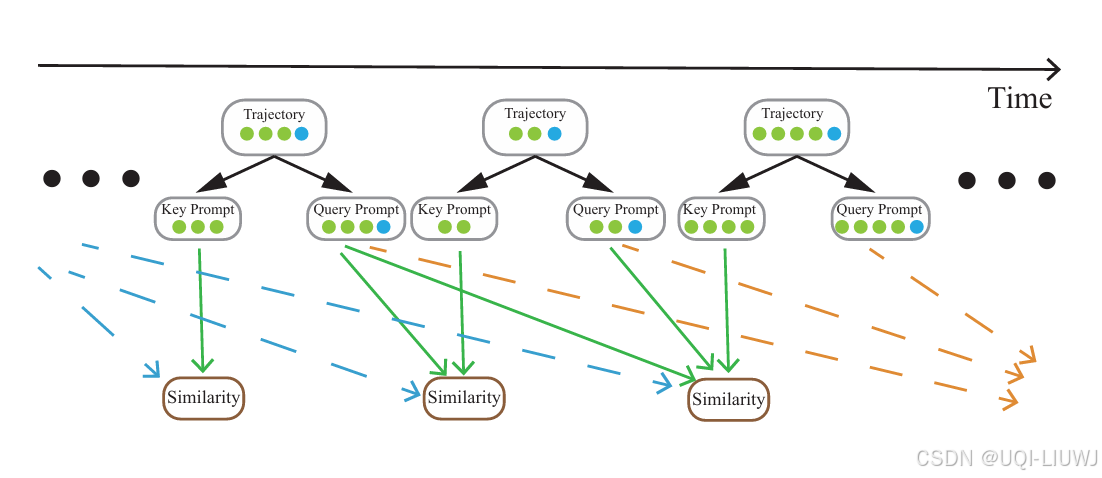
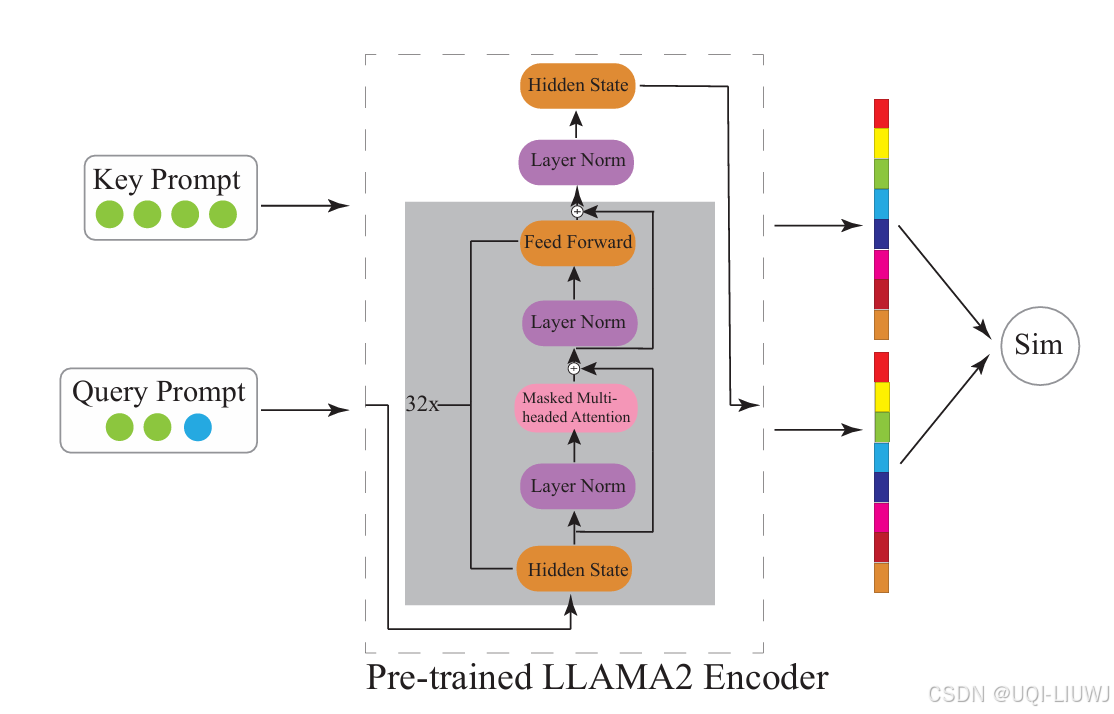
- 计算所有 Key-Query 对的相似度,并从中选出与 Key 相似度较高的 Query,将其用于生成历史轨迹块内容
- 每个 Key 和 Query prompt 输入到 LLM 编码器中,提取最后一层的表示向量
- 对每组 Key 和 Query 计算余弦相似度,提取最高的top-k个Query
2.3 监督微调
在训练集中,将提示中的 <question> 部分送入预训练 LLM,而 <answer> 部分作为监督信号进行微调
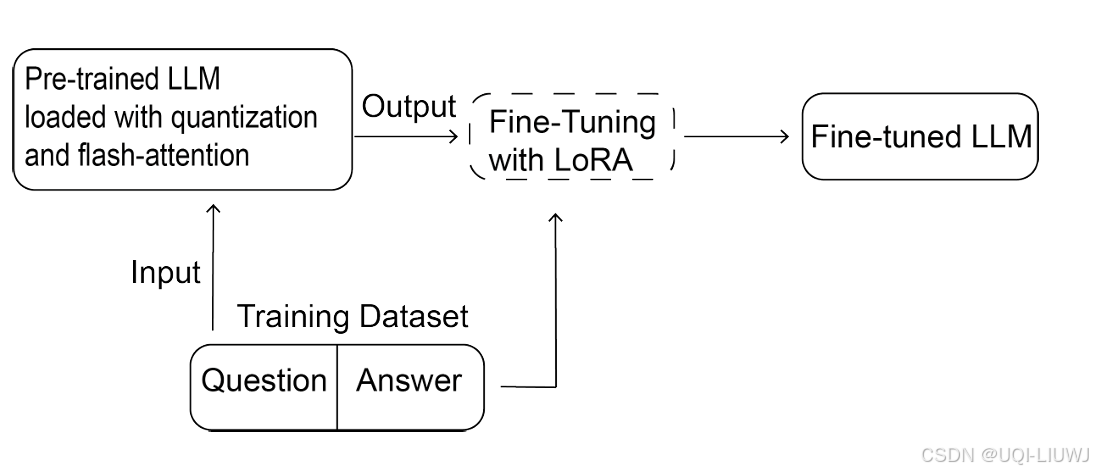
LoRA+NormalFloat 4-bit量化+FlashAttention
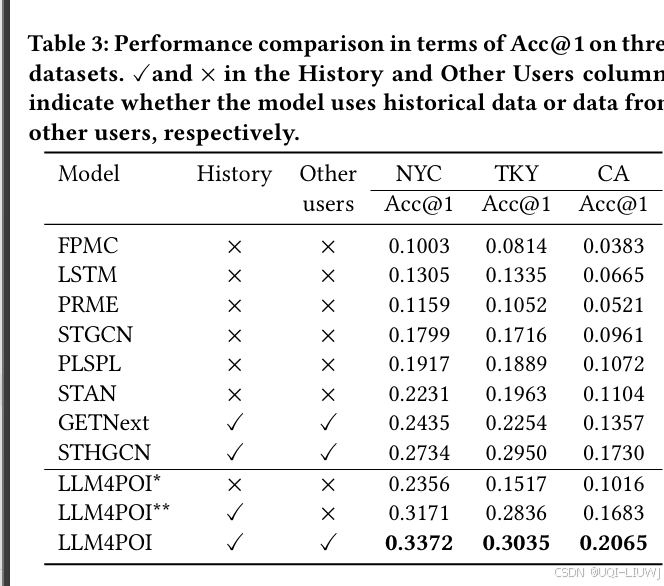
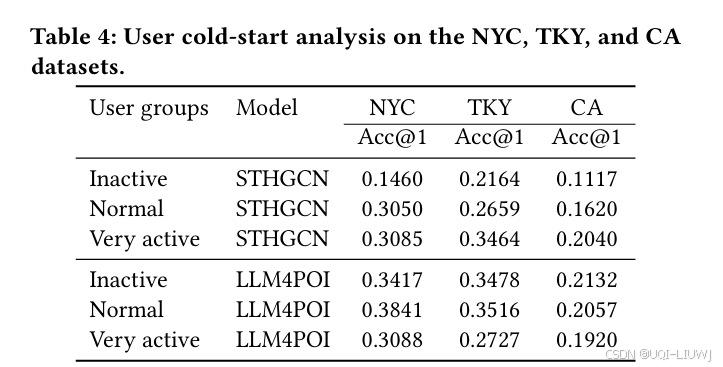
3 实验