图卷积网络:从理论到实践
图卷积网络(Graph Convolutional Networks, GCNs)彻底改变了基于图的机器学习领域,使得深度学习能够应用于非欧几里得结构,如社交网络、引文网络和分子结构。本文将解释GCN的直观理解、数学原理,并提供代码片段帮助您理解和实现基础的GCN。
图表示法基础
定义图G = (V, E),其中:
- V V V:节点集合
- E E E:边集合
- A ∈ R N × N A \in \mathbb{R}^{N \times N} A∈RN×N:邻接矩阵
- X ∈ R N × F X \in \mathbb{R}^{N \times F} X∈RN×F:节点特征矩阵
其中, N N N是节点数量, F F F是每个节点的输入特征数量。
邻接矩阵
邻接矩阵是表示图中节点之间连接(边)的一种方式。
- 对于具有 N N N个节点的图, A A A是一个 N × N N \times N N×N的矩阵。
- 如果节点 i i i和节点 j j j之间有边,则 A i j = 1 A_{ij} = 1 Aij=1(如果带权重,则为边的权重);否则 A i j = 0 A_{ij} = 0 Aij=0。
- 在无向图中, A A A是对称的( A i j = A j i A_{ij} = A_{ji} Aij=Aji)。
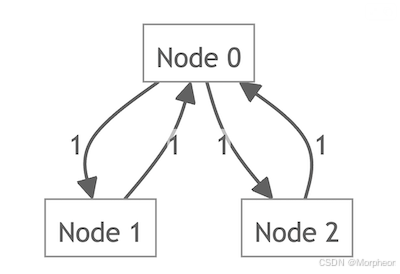
- 例如,一个3节点图,其中节点0连接到节点1和2:
A = [ 0 1 1 1 0 0 1 0 0 ] A = \begin{bmatrix} 0 & 1 & 1 \\ 1 & 0 & 0 \\ 1 & 0 & 0 \end{bmatrix} A= 011100100
节点特征矩阵
节点特征矩阵存储图中每个节点的特征(属性)。
- N N N是节点数量, F F F是每个节点的特征数量。
- 每一行 X i X_i Xi是节点 i i i的特征向量。
- 例如,如果每个节点有3个特征(比如年龄、收入和组别),共有4个节点:
X = [ 23 50000 1 35 60000 2 29 52000 1 41 58000 3 ] X = \begin{bmatrix} 23 & 50000 & 1 \\ 35 & 60000 & 2 \\ 29 & 52000 & 1 \\ 41 & 58000 & 3 \end{bmatrix} X= 23352941500006000052000580001213 - 这些特征是GCN用来学习的输入。
两者共同构成了图卷积网络的基本输入:
- 邻接矩阵 A A A描述了节点如何连接。
- 节点特征矩阵 X X X描述了每个节点的特征。
GCN层公式(Kipf & Welling, 2016)
GCN层的核心公式如下:
H ( l + 1 ) = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma(\tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} W^{(l)}) H(l+1)=σ(D~−1/2A~D~−1/2H(l)W(l))
这个公式包含了很多信息,我们将在下面详细解析:
输入:
- H ( l ) H^{(l)} H(l):上一层的节点特征(对于第一层, H ( 0 ) = X H^{(0)} = X H(0)=X,即输入特征)
- A ~ = A + I \tilde{A} = A + I A~=A+I:添加了自环的邻接矩阵( I I I是单位矩阵)。图中的自环是指节点与自身相连的边。在邻接矩阵中,节点 i i i的自环表示为 A ~ i i = 1 \tilde{A}_{ii} = 1 A~ii=1。添加自环后,我们得到新矩阵: A ~ = A + I \tilde{A} = A + I A~=A+I。这一步很重要,因为我们希望在聚合时保留节点自身的特征。否则,节点只能从邻居获取信息,而丢失了自身特征。
- D ~ \tilde{D} D~: A ~ \tilde{A} A~的对角度矩阵(包含每个节点的连接数,包括自环)
- W ( l ) W^{(l)} W(l):第 l l l层的可训练权重矩阵
- σ \sigma σ:非线性激活函数(如ReLU)
关键操作:
- 消息传递:
- A ~ H ( l ) \tilde{A}H^{(l)} A~H(l):每个节点聚合其邻居的特征向量
- 添加自环( A ~ = A + I \tilde{A} = A + I A~=A+I)确保节点在聚合时包含自身特征
- 归一化:防止特征尺度在层间变化过大,通过节点度进行归一化有助于训练稳定性
- D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2:这步称为对称归一化或重归一化技巧。
- 如果没有归一化,具有许多连接(高度数)的节点在聚合后会有更大的特征值,这可能导致数值不稳定和训练困难。
- D ~ \tilde{D} D~:度矩阵(对角矩阵,其中 D ~ i i = ∑ j A ~ i j \tilde{D}_{ii} = \sum_j \tilde{A}_{ij} D~ii=∑jA~ij)
- D ~ − 1 / 2 \tilde{D}^{-1/2} D~−1/2:度矩阵的逆平方根
- 左乘( D ~ − 1 / 2 A ~ \tilde{D}^{-1/2} \tilde{A} D~−1/2A~):将每一行除以节点度数的平方根。这归一化了每个节点发出消息的影响。
- 右乘( ⋅ D ~ − 1 / 2 \cdot \tilde{D}^{-1/2} ⋅D~−1/2):将每一列除以节点度数的平方根。这归一化了每个节点接收消息的影响。
考虑一个简单的3节点图:
节点0连接到节点1
节点1连接到节点0和2
节点2连接到节点1
添加自环后:
A = [[1, 1, 0],[1, 1, 1],[0, 1, 1]]D = [[2, 0, 0],[0, 3, 0],[0, 0, 2]] # 度数:2, 3, 2D^(-1/2) = [[1/√2, 0, 0 ],[0, 1/√3, 0 ],[0, 0, 1/√2]]
归一化后的矩阵为:
D^(-1/2)AD^(-1/2) = [[1/2, 1/√6, 0 ],[1/√6, 1/3, 1/√6 ],[0, 1/√6, 1/2 ]]
在每一层,节点都会聚合来自其邻居(包括自身)的信息。网络越深,信息传播得越远。每个节点的新表示是其自身特征和邻居特征的加权平均。权重通过训练过程学习得到。归一化确保具有许多邻居的节点不会主导学习过程。
在社交网络中,每个人(节点)都有一些特征(如年龄、兴趣等),GCN层让每个人根据其朋友的信息更新自己的理解。归一化确保受欢迎的人(有很多朋友)不会主导学习过程。
在Cora数据集上实现节点分类的GCN
Cora数据集是一个引文网络,其中节点代表学术论文,边代表引用关系。每篇论文都有一组特征(如作者、标题、摘要)和一个标签(如论文主题)。总共有2,780篇论文(节点)和5,429条引用(边)。每篇论文由一个二进制词向量表示,表示1,433个唯一词典单词的存在(1)或不存在(0)。论文被分为7个类别(如神经网络、概率方法等)。目标是根据每篇论文的特征和引用关系预测其类别。
模型架构
GCN模型有2层:
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16) # 输入到隐藏层self.conv2 = GCNConv(16, dataset.num_classes) # 隐藏层到输出
第一层GCN将输入特征(1,433维)降维到16维。第二层GCN将16维降维到7维(类别数)。
前向传播函数
def forward(self):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index) # 第一层GCNx = F.relu(x) # 非线性激活x = F.dropout(x, training=self.training) # 可选的dropoutx = self.conv2(x, edge_index) # 第二层GCNreturn F.log_softmax(x, dim=1) # 每个类别的对数概率
x = self.conv1(x, edge_index) 做了几件事:它向图中添加自环,计算归一化邻接矩阵 D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2,与输入特征和权重 H ( l ) W ( l ) H^{(l)} W^{(l)} H(l)W(l)相乘,并应用归一化和聚合。基本上,所有复杂的数学运算都由GCNConv层处理了。F.relu(x)应用ReLU激活函数,F.dropout(x, training=self.training)应用dropout来防止过拟合。第二层GCN x = self.conv2(x, edge_index) 做同样的事情,但是使用不同的权重 H ( l ) W ( l ) H^{(l)} W^{(l)} H(l)W(l)。
训练过程
model = GCN()
data = dataset[0] # 获取第一个图对象
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)model.train()
for epoch in range(200):optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()
我们使用带权重衰减的Adam优化器。Adam是一种自适应学习率优化算法,它结合了AdaGrad和RMSProp的优点。它维护每个参数的学习率,并使用梯度的移动平均和梯度平方的移动平均。由于稀疏梯度在GNN中很常见,使用Adam是合理的。
它有两个主要参数:lr是学习率,weight_decay是L2正则化参数。权重衰减通过向损失函数添加惩罚项来防止过拟合,并将模型权重推向较小的值,防止任何单个权重变得过大。使用L2时,原始损失 L ( θ ) L(\theta) L(θ)变为 L ( θ ) + λ ∑ θ i 2 L(\theta) + \lambda \sum \theta_i^2 L(θ)+λ∑θi2,其中 λ \lambda λ是权重衰减参数。weight_decay=5e-4意味着 λ = 0.0005 \lambda = 0.0005 λ=0.0005。它通过保持权重较小来防止过拟合,并使模型对未见过的数据更具泛化能力。
loss = F.nll_loss(...)是负对数似然损失(NLL),通常用于分类任务。它衡量模型的预测概率与真实标签的匹配程度。对于单个样本,它表示为 − log ( p 真实类别 ) -\log(p_{\text{真实类别}}) −log(p真实类别)。如果模型对正确类别100%确信,则损失为0。data.train_mask是一个布尔掩码,指示哪些节点在训练集中。data.y是每个节点的标签。我们只使用train_mask为True的节点进行训练。val_mask用于验证的节点,test_mask用于最终评估的节点。
与许多图数据集一样,标签仅对节点的一个小子集可用,模型通过有监督损失从标记节点学习,并通过图结构从未标记节点学习。因此,这是半监督学习。在Cora数据集中,总共有2,708个节点,其中约140个节点(5%)用于训练,500个用于验证,1000个用于测试。GCN假设相连的节点可能相似。这被称为同质性假设,它被编码到学习算法中。GCN的消息传递直接编码了这些偏差。
模型评估
model.eval()
pred = model().argmax(dim=1) # 获取预测类别
correct = pred[data.test_mask] == data.y[data.test_mask]
accuracy = int(correct.sum()) / int(data.test_mask.sum())
完整代码如下。首先,安装必要的包:
pip install torch-geometric
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv# 加载数据
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset[0]# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)# 训练循环
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)for epoch in range(200):model.train()optimizer.zero_grad()out = model()loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()if epoch % 20 == 0:print(f'Epoch {epoch}, Loss: {loss.item():.4f}')# 评估
model.eval()
pred = model().argmax(dim=1)
correct = pred[data.test_mask] == data.y[data.test_mask]
accuracy = int(correct.sum()) / int(data.test_mask.sum())
print(f'测试准确率: {accuracy:.4f}')
运行结果:
Epoch 0, Loss: 1.9515
Epoch 20, Loss: 0.1116
Epoch 40, Loss: 0.0147
Epoch 60, Loss: 0.0142
Epoch 80, Loss: 0.0166
Epoch 100, Loss: 0.0155
Epoch 120, Loss: 0.0137
Epoch 140, Loss: 0.0124
Epoch 160, Loss: 0.0114
Epoch 180, Loss: 0.0107
测试准确率: 0.8100
我们可以看到,模型在只看到少量标记节点的情况下就能达到相当不错的准确率(81%)。这展示了图结构与节点特征结合的力量。在下一篇博客中,我们将介绍EvolveGCN,这是一个可以处理动态图数据的动态GCN模型。