7.2.2_折半查找
知识总览:
折半查找算法思想:
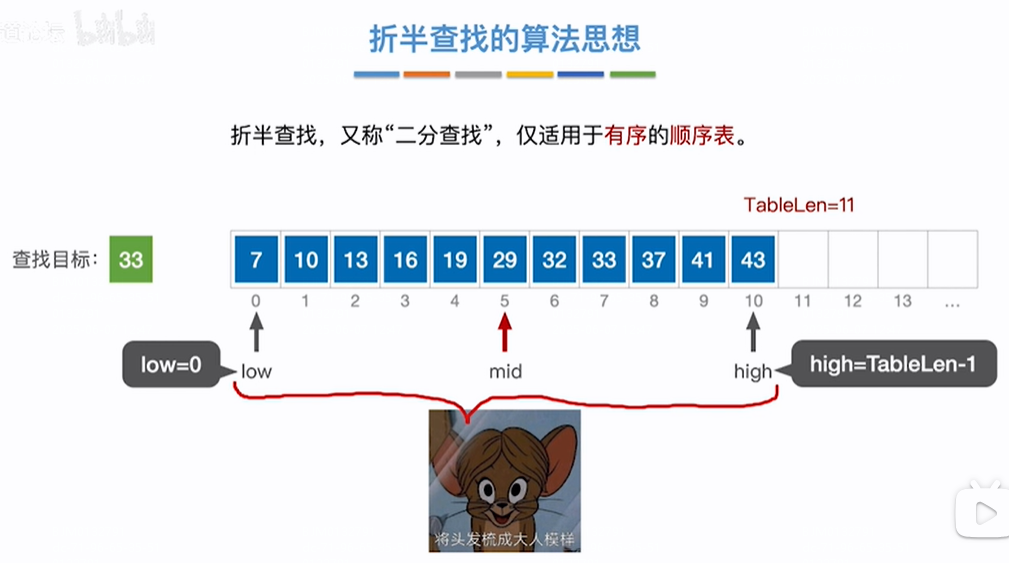
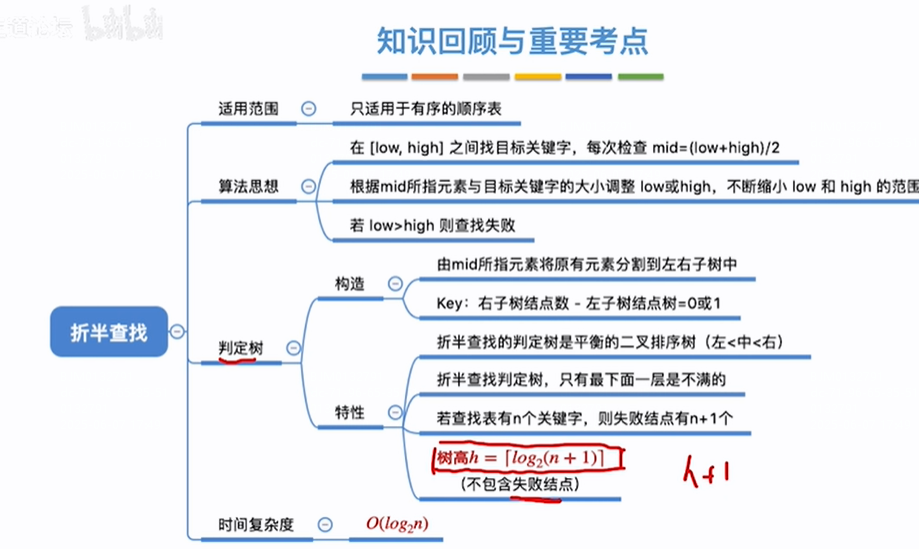
适用于有序(递增或递减)的顺序表(要查找的一组数据是存放在数组中的)。
如果是递增序列,low=index为0位置,high=tablelength-1位置(数组最后一个位置),mid=(low+high)/2 <目标值,往右开始找(右边数列都>中间值),low=mid+1,high不变,(low+high)/2 >目标值(左边数列都<中间值),往左开始找,low不变high=mid-1,即将数组分成了两半,递减序列类似【注意low+high指的是index索引值相加不是索引对应的值相加,low的位置<=high的位置,如果low>high则查找失败】
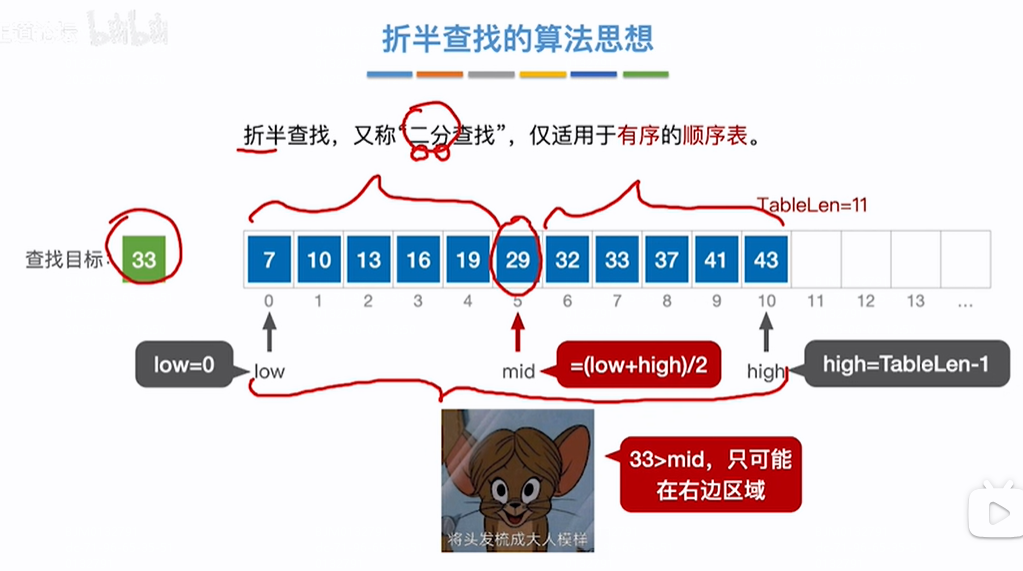
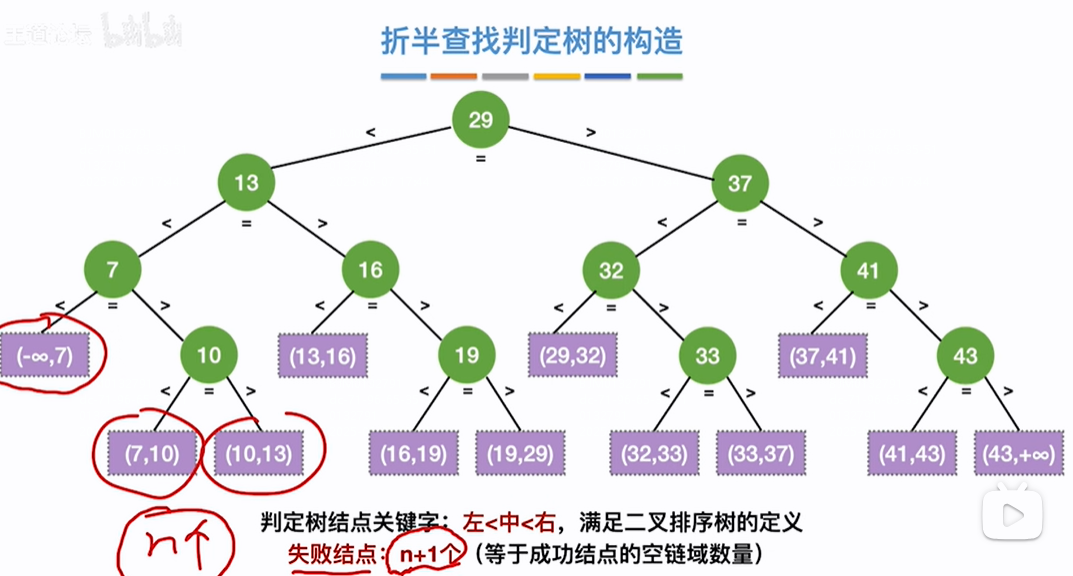
查找33成功过程:如下所示递增序列,low和high指针,low指针指向数组index=0位置,high指针指向数组index=TableLength-1顺序表长度-1位置即数组存放的最后一个数据的位置=10,第一轮,mid=(low+high)/2=(0+10)/2=5,即index=5的位置=29<目标值33,则从右开始找,low=mid+1=6,high不变=10,第二轮,mid=(low+high)/2=(6+10)/2=8,即值为37 >目标值33,则从左找,low不变=6,high=mid-1=7,第三轮mid=(low+high)/2=(6+7)/2=6,即值=32<目标值33,则从右找,low=mid+1=7位置,high不变=7,第4轮mid=(low+high)/2=(7+7)/2=7,即值=33=目标值33结束
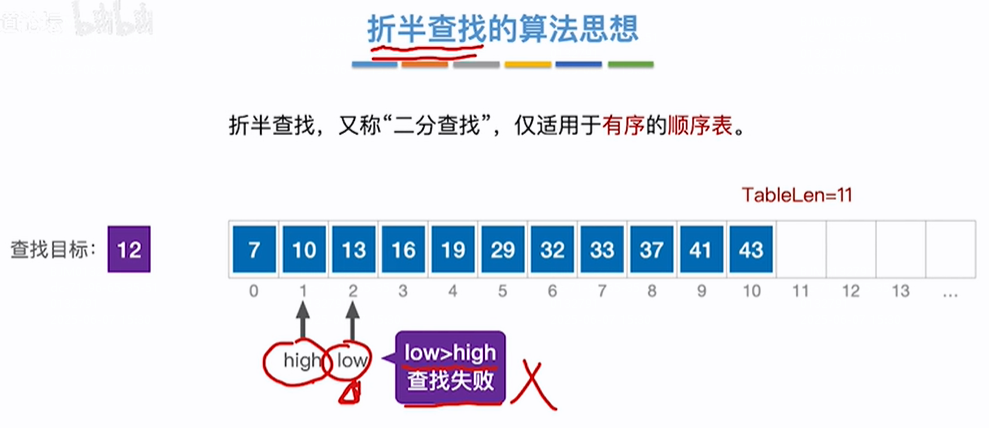
查找12失败过程:如下所示递增序列,low和high指针,low指针开始指向数组index=0,high指针指向数组存放的最后一个数据的位置=10,第一轮,mid=(low+high)/2 =(0+10)/2=5,即值为29>目标值12,往左开始找,low不变=0,high=mid-1=4,第二轮mid=(low+high)/2=(0+4)/2=2,即值=13 >目标值12,则从左找,low不变=0,high=mid-1=1,第三轮,mid=(low+high)/2=(0+1)/2=0,即值=7<目标值12,则从右找,high不变=1,low=mid+1=1,第四轮mid=(low+high)/2=(1+1)/2=1即值=10<目标值12,则从右找,high不变=1,low=mid+1=2,此时low在high前边即low>high,查找失败
代码实现:
如下为顺序表(数组)基于升序的情况的代码,如果是链表结构的那么不能快速找到中间元素,所以二分查找不可能基于链表实现
大概流程:让low=0指向顺序表最头位置,high=L.TableLen-1指向顺序表最尾元素,在low<=high情况下进行while循环,取中间索引,中间索引对应元素mid==目标值key成功直接return,中间索引对应元素>目标值key,往左找high变low不变,high=mid-1,进行下一轮循环,中间索引对应元素mid<目标值key,往右找low变high不变,low=mid+1,进行下一轮循环,直到中间元素的值==目标值return,或者遍历完后low>high时退出while循环,return -1查找失败
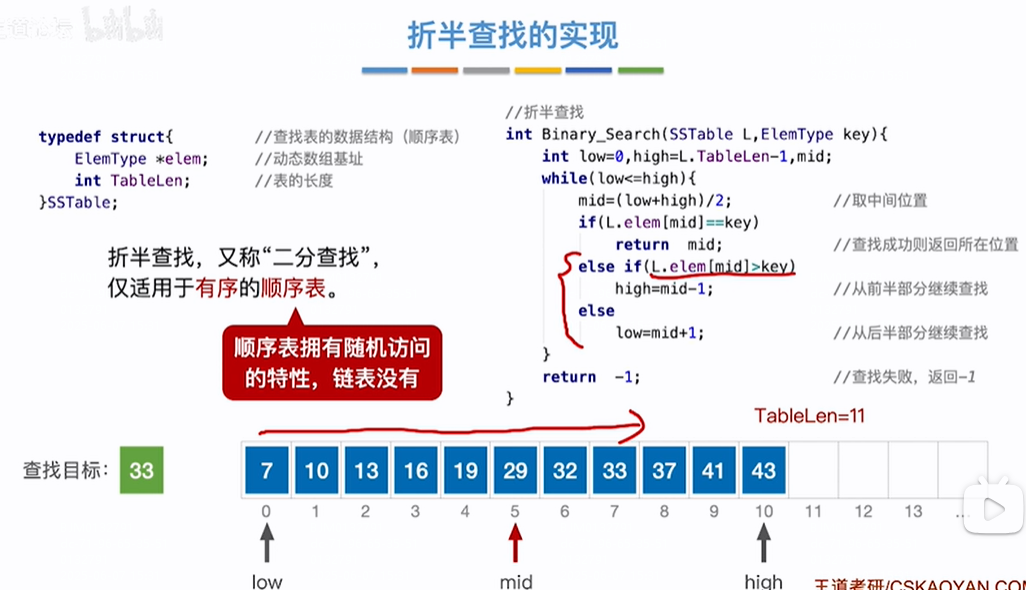
查找效率分析:
查找成功概率:一共有11个数,每个数被查找的概率相同记为1/11,查找成功过程如下:第一层有1个数,和该树比较1次,第2层有2个数,如13,需要先和29比较再和13比较即比较2次,37同,则2次*2个数,第3层4个数,每个数都需要比较3次,如10,需要先和29、13比较再和10比较即比较3次,剩余数同级3次*4个数,其他层也同则平均查找长度=各个关键字比较次数之和X每个关键字查找概率即ASL(成功)=(1*1+2*2+3*4+4*4)/11=3
查找失败概率:如下除了成功的关键字之外剩余的紫色范围节点为查找失败情况,即共有12个紫色范围节点即共有12个失败情况,每个失败节点被查找的概率相同记为1/12,查找失败过程如下:第4层有4个紫色失败范围节点,每个节点都需要经过3次比较就能找到失败的紫色范围节点,如(-∞,7)失败节点需要比较29、13、7三次关键字得到,(13,16)失败节点需要比较29、13、16三次关键字得到,其他同。即4个失败节点需要比较3*4次,第5层有8个紫色失败范围节点,每个节点都需要经过3次比较就能找到失败的紫色范围节点,如(7,10)需要比较29、7、3、10四次关键字才能得到失败节点(7,10),其他同也是4次一共这些失败节点需要比较4*8=32次,则平均查找长度=所有节点比较次数之和*被查找的概率=(4*3+8*4)/12=11/3,
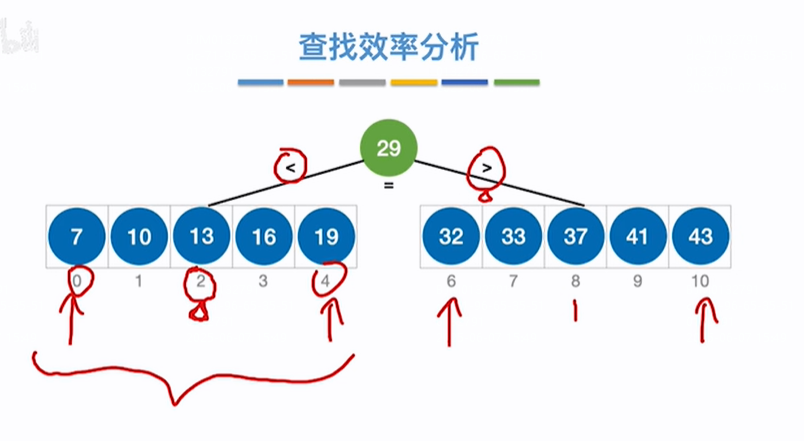
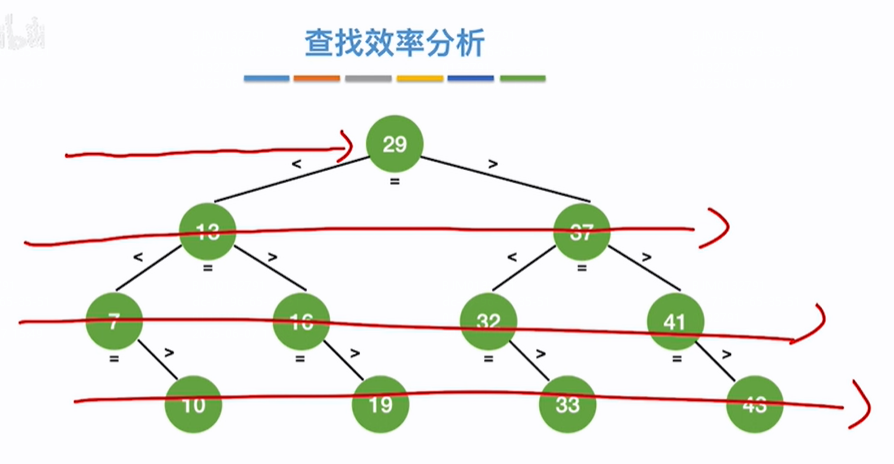
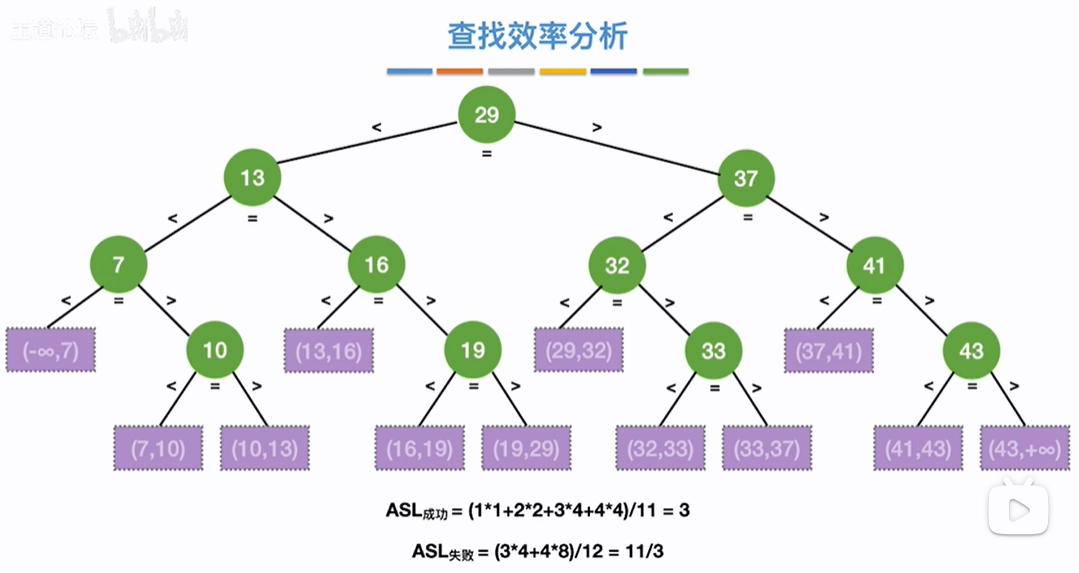
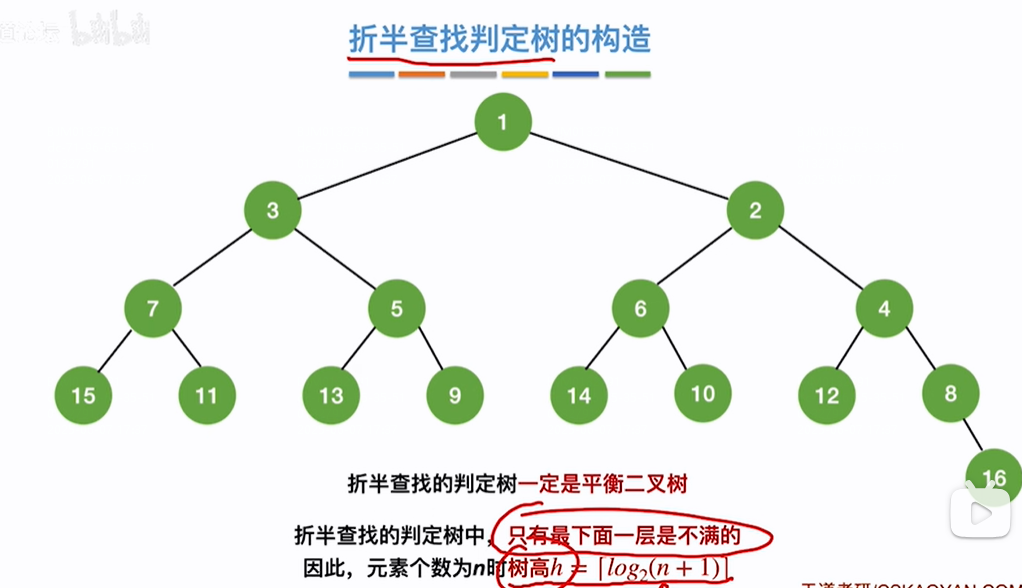
折半查找判定树的构造:
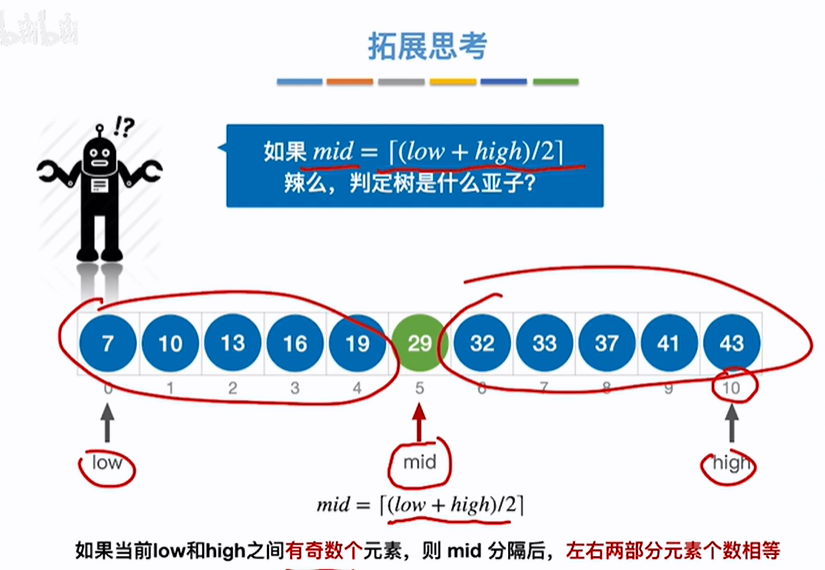
如果是奇数个元素,刨除mid元素之后以mid元素为根节点,左右子树能刚好平分剩余元素,即左右子树元素个数相等
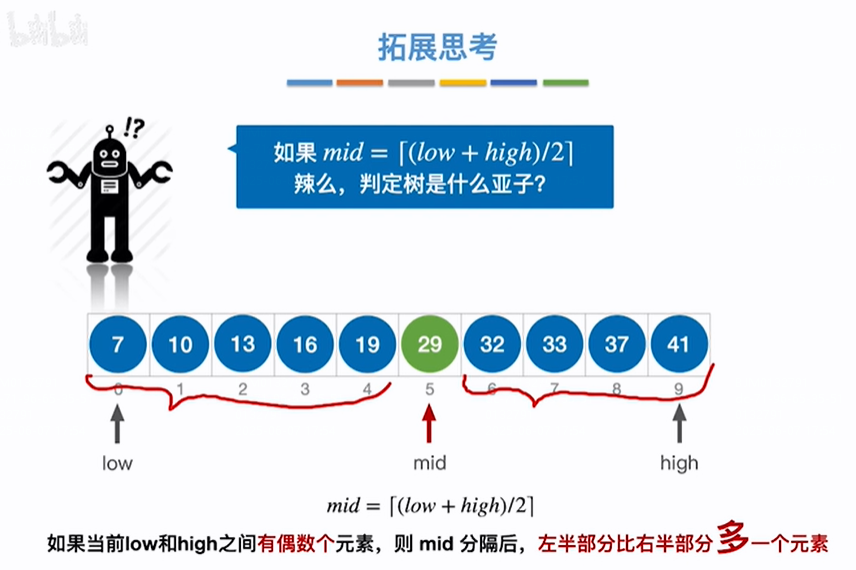
如果是偶数个元素,刨除mid元素之后以mid元素为根节点,左子树就会比右子树少一个元素,少一个是因为mid的索引位置=(low+high)/2向下取整了,即mid会占用左子树的一个元素,所以左子树元素比右子树少一个
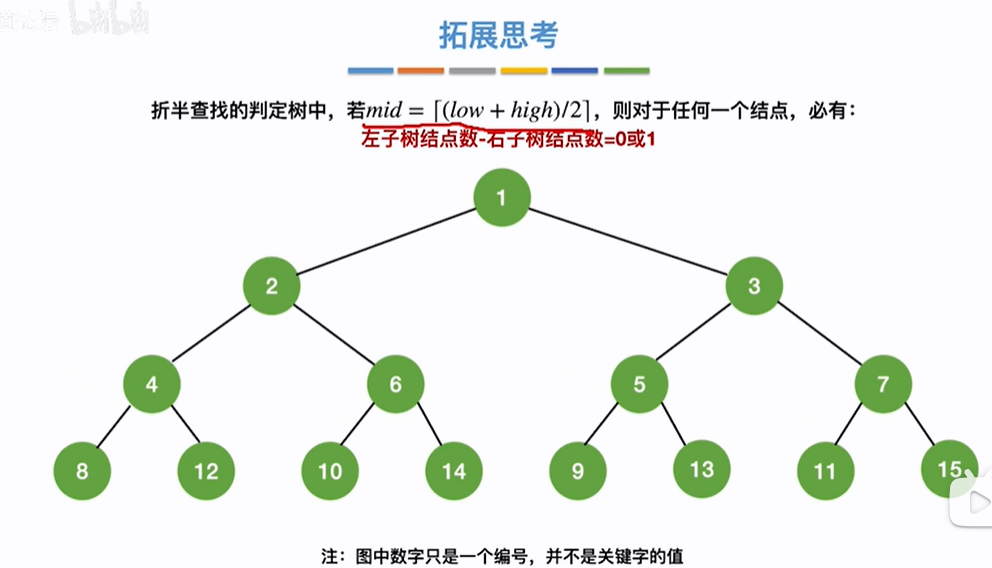
即左右子树元素个数要不相等,要不左子树比右子树元素少一个(只能最多少一个),不可能左子树比右子树个数多
构造判定树(如下最后4张图):按照右子树比左子树最多多一个元素、左子树不可能比右子树元素多原则,假如是1个元素,就1个元素(图1),如果是2个元素,2就放到右子树(图2),如果是3个元素,此时3不能再放到右子树,因为右比左就多俩了,要放到左子树(图3),如果是4个元素(最后一张图)放到右子树且放到大右子树下边的小右子树(因为要右比左多,不能左比右多,所以不能放到2的左子树位置,要把4放到2的右子树位置),5个元素放到大左子树3下边的右子树位置5(因为右比左多不能左比右多,所以把5放到大左3下边的小右,不能放到3的左子树),依次类推。。。。。。(个人理解)
注意:这些只是元素序号不代表序号的值,序号的值依然满足如果是递增序列右子树始终比左子树值大
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
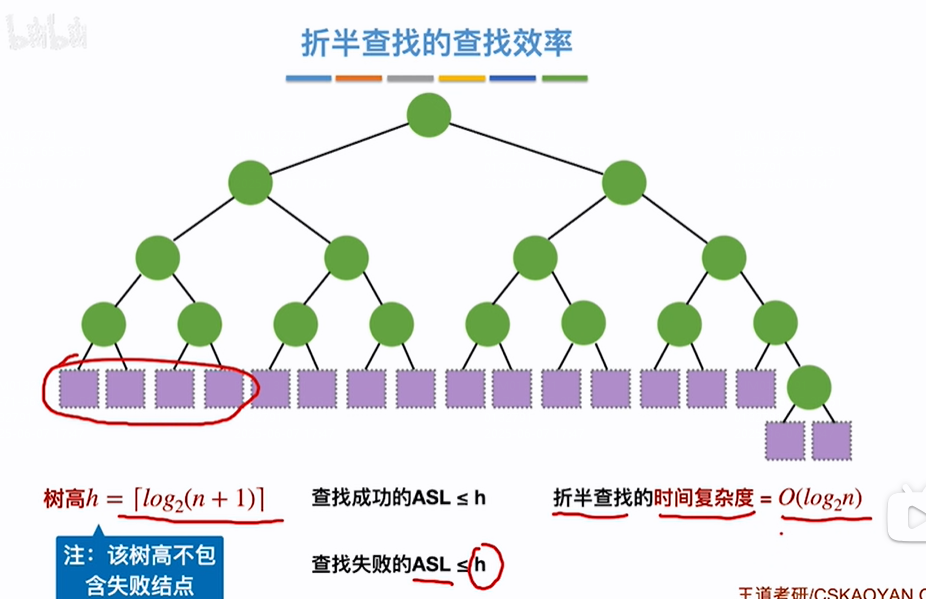
折半查找判定树树高:
折半查找判定树一定是平衡二叉树(啥叫平衡二叉树来着???)
只有最下一层是不满的类似完全二叉树,其树高h和完全二叉树求法类似,log2n直接反映折半查找的时间复杂度
折半查找判定树符合二叉排序树,并且是平衡的二叉排序树,即左子树关键字的值<中间节点<右子树关键字的值,
有n个成功节点的判定树,失败节点个数=空链域的数量=n+1,即把失败节点都挂到成功节点的空链域上了(有n个节点的二叉树,会有n+1个空链域)
折半查找查找效率:
不考虑失败元素,对于含有n个元素的顺序表所对应的折半查找的判定树的树高h=log2(n+1)【考虑失败元素,则树高h=log2(n+1)+1即h+1】向上取整,不管是查找成功还是失败,查找对比的次数一定不会超过树高h,则折半查找的即对比次数的时间复杂度为O(log2(n)),比顺序查找O(n)要好
知识回顾:
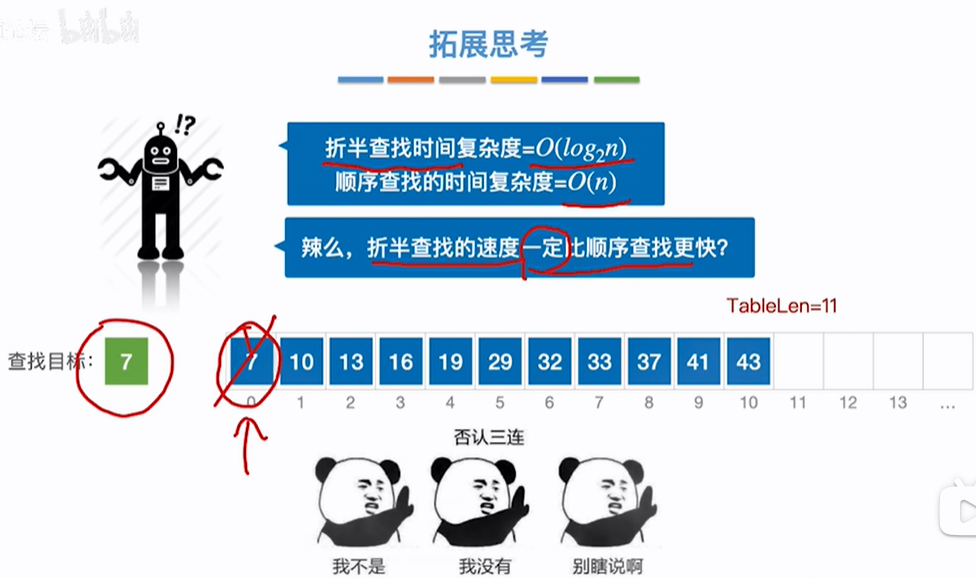
拓展思考:
折半查找一定比顺序查找更优秀吗?不是,比如下边顺序表中index=0的位置是7,要找目标值7顺序查找第一次比较就找到了,折半查找要比较好几次
mid=(low+high)/2向上取整判定树是什么样子,上边是mid向下取整的例子,实际mid向上取整会导致判定树的左子树比右子树最多多一个元素(如下最后一张图),即正好和mid向下取整相反,则实际构造判定树时mid向上或向下取整会影响判定树的形态
。。。。。。。。。。纯属个人理解瞎写。。。。。。。