triton学习笔记6: Fused Attention
这是之前的学习笔记
- triton puzzles part1
- triton puzzles part2
- triton puzzles part3
- triton tutorials part1
- triton tutorials: part2
Fused Attention主要描述的是Flash Attention系列,v1在triton学习笔记2: 循环优化术 中已经提过,本篇顺着官网的实现学习v2和v3, flash decoding/flash decoding++相关的知识
Flash Attention v2
Flash Attention v1和Flash Attention v2的计算逻辑
flash attention v1

flash attention v2

Flash attention v2相比flash attention,主要优化的地方在于:
- 减少大量非matmul的冗余计算,增加Tensor Cores运算比例
- diag的rescale次数要比flash attention v1少,不用每次都写HBM了
- seqlen维度并行优化
-
从图中可以看出flash attention v2和HBM交换IO的次数要少于flash attention v1
-
外部循环是先load Q,那么就可以把不同的query块的Attention分配不同thread block进行计算,这些thread block之间是不需要通信的。
-
backward pass不改变循环顺序的原因:调换循环顺序后,会导致需要通信的操作增加:1 -> 2。原先只有dQi需要通信,如果调换循环顺序,会导致dV,dK需要通信。因此,采用先K,V再Q的顺序,会稍微更快一些。
- 更好的Warp Partitioning策略,避免Split-K
官网代码
"""
Fused Attention
===============This is a Triton implementation of the Flash Attention v2 algorithm from Tri Dao (https://tridao.me/publications/flash2/flash2.pdf)Credits: OpenAI kernel teamExtra Credits:* Original flash attention paper (https://arxiv.org/abs/2205.14135)
* Rabe and Staats (https://arxiv.org/pdf/2112.05682v2.pdf)"""import pytest
import torch
import osimport triton
import triton.language as tl
from triton.tools.tensor_descriptor import TensorDescriptorDEVICE = triton.runtime.driver.active.get_active_torch_device()def is_hip():return triton.runtime.driver.active.get_current_target().backend == "hip"def is_cuda():return triton.runtime.driver.active.get_current_target().backend == "cuda"def supports_host_descriptor():return is_cuda() and torch.cuda.get_device_capability()[0] >= 9def is_blackwell():return is_cuda() and torch.cuda.get_device_capability()[0] == 10@triton.jit
def _attn_fwd_inner(acc, l_i, m_i, q, #desc_k, desc_v, #offset_y, dtype: tl.constexpr, start_m, qk_scale, #BLOCK_M: tl.constexpr, HEAD_DIM: tl.constexpr, BLOCK_N: tl.constexpr, #STAGE: tl.constexpr, offs_m: tl.constexpr, offs_n: tl.constexpr, #N_CTX: tl.constexpr, warp_specialize: tl.constexpr):# range of values handled by this stageif STAGE == 1:lo, hi = 0, start_m * BLOCK_Melif STAGE == 2:lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_Mlo = tl.multiple_of(lo, BLOCK_M)# causal = Falseelse:lo, hi = 0, N_CTXoffsetkv_y = offset_y + lo# loop over k, v and update accumulatorfor start_n in tl.range(lo, hi, BLOCK_N, warp_specialize=warp_specialize):start_n = tl.multiple_of(start_n, BLOCK_N)# -- compute qk ----k = desc_k.load([offsetkv_y, 0]).Tqk = tl.dot(q, k)if STAGE == 2:mask = offs_m[:, None] >= (start_n + offs_n[None, :])qk = qk * qk_scale + tl.where(mask, 0, -1.0e6)m_ij = tl.maximum(m_i, tl.max(qk, 1))qk -= m_ij[:, None]else:m_ij = tl.maximum(m_i, tl.max(qk, 1) * qk_scale)qk = qk * qk_scale - m_ij[:, None]p = tl.math.exp2(qk)# -- compute correction factoralpha = tl.math.exp2(m_i - m_ij)l_ij = tl.sum(p, 1)# -- update output accumulator --acc = acc * alpha[:, None]# prepare p and v for the dotv = desc_v.load([offsetkv_y, 0])p = p.to(dtype)# note that this non transposed v for FP8 is only supported on Blackwellacc = tl.dot(p, v, acc)# update m_i and l_i# place this at the end of the loop to reduce register pressurel_i = l_i * alpha + l_ijm_i = m_ijoffsetkv_y += BLOCK_Nreturn acc, l_i, m_idef _host_descriptor_pre_hook(nargs):BLOCK_M = nargs["BLOCK_M"]BLOCK_N = nargs["BLOCK_N"]HEAD_DIM = nargs["HEAD_DIM"]if not isinstance(nargs["desc_q"], TensorDescriptor):returnnargs["desc_q"].block_shape = [BLOCK_M, HEAD_DIM]nargs["desc_v"].block_shape = [BLOCK_N, HEAD_DIM]nargs["desc_k"].block_shape = [BLOCK_N, HEAD_DIM]nargs["desc_o"].block_shape = [BLOCK_M, HEAD_DIM]if is_hip():NUM_STAGES_OPTIONS = [1]
elif supports_host_descriptor():NUM_STAGES_OPTIONS = [2, 3, 4]
else:NUM_STAGES_OPTIONS = [2, 3, 4]configs = [triton.Config({'BLOCK_M': BM, 'BLOCK_N': BN}, num_stages=s, num_warps=w, pre_hook=_host_descriptor_pre_hook) \for BM in [64, 128]\for BN in [64, 128]\for s in NUM_STAGES_OPTIONS \for w in [4, 8]\
]
if "PYTEST_VERSION" in os.environ:# Use a single config in testing for reproducibilityconfigs = [triton.Config(dict(BLOCK_M=64, BLOCK_N=64), num_stages=2, num_warps=4, pre_hook=_host_descriptor_pre_hook),]def keep(conf):BLOCK_M = conf.kwargs["BLOCK_M"]BLOCK_N = conf.kwargs["BLOCK_N"]return not (torch.cuda.get_device_capability()[0] == 9 and BLOCK_M * BLOCK_N < 128 * 128 and conf.num_warps == 8)def prune_invalid_configs(configs, named_args, **kwargs):N_CTX = kwargs["N_CTX"]# Filter out configs where BLOCK_M > N_CTXreturn [conf for conf in configs if conf.kwargs.get("BLOCK_M", 0) <= N_CTX]@triton.jit
def _maybe_make_tensor_desc(desc_or_ptr, shape, strides, block_shape):if isinstance(desc_or_ptr, tl.tensor_descriptor):return desc_or_ptrelse:return tl.make_tensor_descriptor(desc_or_ptr, shape, strides, block_shape)@triton.autotune(configs=list(filter(keep, configs)), key=["N_CTX", "HEAD_DIM", "FP8_OUTPUT", "warp_specialize"],prune_configs_by={'early_config_prune': prune_invalid_configs})
@triton.jit
def _attn_fwd(sm_scale, M, #Z, H, desc_q, desc_k, desc_v, desc_o, N_CTX, #HEAD_DIM: tl.constexpr, #BLOCK_M: tl.constexpr, #BLOCK_N: tl.constexpr, #FP8_OUTPUT: tl.constexpr, #STAGE: tl.constexpr, #warp_specialize: tl.constexpr, #):dtype = tl.float8e5 if FP8_OUTPUT else tl.float16tl.static_assert(BLOCK_N <= HEAD_DIM)start_m = tl.program_id(0)off_hz = tl.program_id(1)off_z = off_hz // Hoff_h = off_hz % Hy_dim = Z * H * N_CTXdesc_q = _maybe_make_tensor_desc(desc_q, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],block_shape=[BLOCK_M, HEAD_DIM])desc_v = _maybe_make_tensor_desc(desc_v, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],block_shape=[BLOCK_N, HEAD_DIM])desc_k = _maybe_make_tensor_desc(desc_k, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],block_shape=[BLOCK_N, HEAD_DIM])desc_o = _maybe_make_tensor_desc(desc_o, shape=[y_dim, HEAD_DIM], strides=[HEAD_DIM, 1],block_shape=[BLOCK_M, HEAD_DIM])offset_y = off_z * (N_CTX * H) + off_h * N_CTXqo_offset_y = offset_y + start_m * BLOCK_M# initialize offsetsoffs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)offs_n = tl.arange(0, BLOCK_N)# initialize pointer to m and lm_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)# load scalesqk_scale = sm_scaleqk_scale *= 1.44269504 # 1/log(2)# load q: it will stay in SRAM throughoutq = desc_q.load([qo_offset_y, 0])# stage 1: off-band# For causal = True, STAGE = 3 and _attn_fwd_inner gets 1 as its STAGE# For causal = False, STAGE = 1, and _attn_fwd_inner gets 3 as its STAGEif STAGE & 1:acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, #desc_k, desc_v, #offset_y, dtype, start_m, qk_scale, #BLOCK_M, HEAD_DIM, BLOCK_N, #4 - STAGE, offs_m, offs_n, N_CTX, #warp_specialize)# stage 2: on-bandif STAGE & 2:# barrier makes it easier for compielr to schedule the# two loops independentlyacc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, #desc_k, desc_v, #offset_y, dtype, start_m, qk_scale, #BLOCK_M, HEAD_DIM, BLOCK_N, #2, offs_m, offs_n, N_CTX, #warp_specialize)# epiloguem_i += tl.math.log2(l_i)acc = acc / l_i[:, None]m_ptrs = M + off_hz * N_CTX + offs_mtl.store(m_ptrs, m_i)desc_o.store([qo_offset_y, 0], acc.to(dtype))@triton.jit
def _attn_bwd_preprocess(O, DO, #Delta, #Z, H, N_CTX, #BLOCK_M: tl.constexpr, HEAD_DIM: tl.constexpr #):off_m = tl.program_id(0) * BLOCK_M + tl.arange(0, BLOCK_M)off_hz = tl.program_id(1)off_n = tl.arange(0, HEAD_DIM)# loado = tl.load(O + off_hz * HEAD_DIM * N_CTX + off_m[:, None] * HEAD_DIM + off_n[None, :])do = tl.load(DO + off_hz * HEAD_DIM * N_CTX + off_m[:, None] * HEAD_DIM + off_n[None, :]).to(tl.float32)delta = tl.sum(o * do, axis=1)# write-backtl.store(Delta + off_hz * N_CTX + off_m, delta)# The main inner-loop logic for computing dK and dV.
@triton.jit
def _attn_bwd_dkdv(dk, dv, #Q, k, v, sm_scale, #DO, #M, D, ## shared by Q/K/V/DO.stride_tok, stride_d, #H, N_CTX, BLOCK_M1: tl.constexpr, #BLOCK_N1: tl.constexpr, #HEAD_DIM: tl.constexpr, ## Filled in by the wrapper.start_n, start_m, num_steps, #MASK: tl.constexpr):offs_m = start_m + tl.arange(0, BLOCK_M1)offs_n = start_n + tl.arange(0, BLOCK_N1)offs_k = tl.arange(0, HEAD_DIM)qT_ptrs = Q + offs_m[None, :] * stride_tok + offs_k[:, None] * stride_ddo_ptrs = DO + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d# BLOCK_N1 must be a multiple of BLOCK_M1, otherwise the code wouldn't work.tl.static_assert(BLOCK_N1 % BLOCK_M1 == 0)curr_m = start_mstep_m = BLOCK_M1for blk_idx in range(num_steps):qT = tl.load(qT_ptrs)# Load m before computing qk to reduce pipeline stall.offs_m = curr_m + tl.arange(0, BLOCK_M1)m = tl.load(M + offs_m)qkT = tl.dot(k, qT)pT = tl.math.exp2(qkT - m[None, :])# Autoregressive masking.if MASK:mask = (offs_m[None, :] >= offs_n[:, None])pT = tl.where(mask, pT, 0.0)do = tl.load(do_ptrs)# Compute dV.ppT = pTppT = ppT.to(tl.float16)dv += tl.dot(ppT, do)# D (= delta) is pre-divided by ds_scale.Di = tl.load(D + offs_m)# Compute dP and dS.dpT = tl.dot(v, tl.trans(do)).to(tl.float32)dsT = pT * (dpT - Di[None, :])dsT = dsT.to(tl.float16)dk += tl.dot(dsT, tl.trans(qT))# Increment pointers.curr_m += step_mqT_ptrs += step_m * stride_tokdo_ptrs += step_m * stride_tokreturn dk, dv# the main inner-loop logic for computing dQ
@triton.jit
def _attn_bwd_dq(dq, q, K, V, #do, m, D,# shared by Q/K/V/DO.stride_tok, stride_d, #H, N_CTX, #BLOCK_M2: tl.constexpr, #BLOCK_N2: tl.constexpr, #HEAD_DIM: tl.constexpr,# Filled in by the wrapper.start_m, start_n, num_steps, #MASK: tl.constexpr):offs_m = start_m + tl.arange(0, BLOCK_M2)offs_n = start_n + tl.arange(0, BLOCK_N2)offs_k = tl.arange(0, HEAD_DIM)kT_ptrs = K + offs_n[None, :] * stride_tok + offs_k[:, None] * stride_dvT_ptrs = V + offs_n[None, :] * stride_tok + offs_k[:, None] * stride_d# D (= delta) is pre-divided by ds_scale.Di = tl.load(D + offs_m)# BLOCK_M2 must be a multiple of BLOCK_N2, otherwise the code wouldn't work.tl.static_assert(BLOCK_M2 % BLOCK_N2 == 0)curr_n = start_nstep_n = BLOCK_N2for blk_idx in range(num_steps):kT = tl.load(kT_ptrs)vT = tl.load(vT_ptrs)qk = tl.dot(q, kT)p = tl.math.exp2(qk - m)# Autoregressive masking.if MASK:offs_n = curr_n + tl.arange(0, BLOCK_N2)mask = (offs_m[:, None] >= offs_n[None, :])p = tl.where(mask, p, 0.0)# Compute dP and dS.dp = tl.dot(do, vT).to(tl.float32)ds = p * (dp - Di[:, None])ds = ds.to(tl.float16)# Compute dQ.# NOTE: We need to de-scale dq in the end, because kT was pre-scaled.dq += tl.dot(ds, tl.trans(kT))# Increment pointers.curr_n += step_nkT_ptrs += step_n * stride_tokvT_ptrs += step_n * stride_tokreturn dq@triton.jit
def _attn_bwd(Q, K, V, sm_scale, #DO, #DQ, DK, DV, #M, D,# shared by Q/K/V/DO.stride_z, stride_h, stride_tok, stride_d, #H, N_CTX, #BLOCK_M1: tl.constexpr, #BLOCK_N1: tl.constexpr, #BLOCK_M2: tl.constexpr, #BLOCK_N2: tl.constexpr, #BLK_SLICE_FACTOR: tl.constexpr, #HEAD_DIM: tl.constexpr):LN2: tl.constexpr = 0.6931471824645996 # = ln(2)bhid = tl.program_id(2)off_chz = (bhid * N_CTX).to(tl.int64)adj = (stride_h * (bhid % H) + stride_z * (bhid // H)).to(tl.int64)pid = tl.program_id(0)# offset pointers for batch/headQ += adjK += adjV += adjDO += adjDQ += adjDK += adjDV += adjM += off_chzD += off_chz# load scalesoffs_k = tl.arange(0, HEAD_DIM)start_n = pid * BLOCK_N1start_m = start_nMASK_BLOCK_M1: tl.constexpr = BLOCK_M1 // BLK_SLICE_FACTORoffs_n = start_n + tl.arange(0, BLOCK_N1)dv = tl.zeros([BLOCK_N1, HEAD_DIM], dtype=tl.float32)dk = tl.zeros([BLOCK_N1, HEAD_DIM], dtype=tl.float32)# load K and V: they stay in SRAM throughout the inner loop.k = tl.load(K + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d)v = tl.load(V + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_d)num_steps = BLOCK_N1 // MASK_BLOCK_M1dk, dv = _attn_bwd_dkdv(dk, dv, #Q, k, v, sm_scale, #DO, #M, D, #stride_tok, stride_d, #H, N_CTX, #MASK_BLOCK_M1, BLOCK_N1, HEAD_DIM, #start_n, start_m, num_steps, #MASK=True #)start_m += num_steps * MASK_BLOCK_M1num_steps = (N_CTX - start_m) // BLOCK_M1# Compute dK and dV for non-masked blocks.dk, dv = _attn_bwd_dkdv( #dk, dv, #Q, k, v, sm_scale, #DO, #M, D, #stride_tok, stride_d, #H, N_CTX, #BLOCK_M1, BLOCK_N1, HEAD_DIM, #start_n, start_m, num_steps, #MASK=False #)dv_ptrs = DV + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_dtl.store(dv_ptrs, dv)# Write back dK.dk *= sm_scaledk_ptrs = DK + offs_n[:, None] * stride_tok + offs_k[None, :] * stride_dtl.store(dk_ptrs, dk)# THIS BLOCK DOES DQ:start_m = pid * BLOCK_M2end_n = start_m + BLOCK_M2MASK_BLOCK_N2: tl.constexpr = BLOCK_N2 // BLK_SLICE_FACTORoffs_m = start_m + tl.arange(0, BLOCK_M2)q = tl.load(Q + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d)dq = tl.zeros([BLOCK_M2, HEAD_DIM], dtype=tl.float32)do = tl.load(DO + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_d)m = tl.load(M + offs_m)m = m[:, None]# Compute dQ for masked (diagonal) blocks.# NOTE: This code scans each row of QK^T backward (from right to left,# but inside each call to _attn_bwd_dq, from left to right), but that's# not due to anything important. I just wanted to reuse the loop# structure for dK & dV above as much as possible.num_steps = BLOCK_M2 // MASK_BLOCK_N2dq = _attn_bwd_dq(dq, q, K, V, #do, m, D, #stride_tok, stride_d, #H, N_CTX, #BLOCK_M2, MASK_BLOCK_N2, HEAD_DIM, #start_m, end_n - num_steps * MASK_BLOCK_N2, num_steps, #MASK=True #)end_n -= num_steps * MASK_BLOCK_N2# stage 2num_steps = end_n // BLOCK_N2dq = _attn_bwd_dq(dq, q, K, V, #do, m, D, #stride_tok, stride_d, #H, N_CTX, #BLOCK_M2, BLOCK_N2, HEAD_DIM, #start_m, end_n - num_steps * BLOCK_N2, num_steps, #MASK=False #)# Write back dQ.dq_ptrs = DQ + offs_m[:, None] * stride_tok + offs_k[None, :] * stride_ddq *= LN2tl.store(dq_ptrs, dq)class _attention(torch.autograd.Function):@staticmethoddef forward(ctx, q, k, v, causal, sm_scale, warp_specialize=True):# shape constraintsHEAD_DIM_Q, HEAD_DIM_K = q.shape[-1], k.shape[-1]# when v is in float8_e5m2 it is transposed.HEAD_DIM_V = v.shape[-1]assert HEAD_DIM_Q == HEAD_DIM_K and HEAD_DIM_K == HEAD_DIM_Vassert HEAD_DIM_K in {16, 32, 64, 128, 256}o = torch.empty_like(q)stage = 3 if causal else 1extra_kern_args = {}# Tuning for AMD targetif is_hip():waves_per_eu = 3 if HEAD_DIM_K <= 64 else 2extra_kern_args = {"waves_per_eu": waves_per_eu, "allow_flush_denorm": True}M = torch.empty((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)if supports_host_descriptor():# Note that on Hopper we cannot perform a FP8 dot with a non-transposed second tensory_dim = q.shape[0] * q.shape[1] * q.shape[2]dummy_block = [1, 1]desc_q = TensorDescriptor(q, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)desc_v = TensorDescriptor(v, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)desc_k = TensorDescriptor(k, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)desc_o = TensorDescriptor(o, shape=[y_dim, HEAD_DIM_K], strides=[HEAD_DIM_K, 1], block_shape=dummy_block)else:desc_q = qdesc_v = vdesc_k = kdesc_o = odef alloc_fn(size: int, align: int, _):return torch.empty(size, dtype=torch.int8, device="cuda")triton.set_allocator(alloc_fn)def grid(META):return (triton.cdiv(q.shape[2], META["BLOCK_M"]), q.shape[0] * q.shape[1], 1)ctx.grid = gridif is_cuda() and warp_specialize:extra_kern_args["maxnreg"] = 80_attn_fwd[grid](sm_scale, M, #q.shape[0], q.shape[1], #desc_q, desc_k, desc_v, desc_o, #N_CTX=q.shape[2], #HEAD_DIM=HEAD_DIM_K, #FP8_OUTPUT=q.dtype == torch.float8_e5m2, #STAGE=stage, #warp_specialize=warp_specialize, #**extra_kern_args)ctx.save_for_backward(q, k, v, o, M)ctx.sm_scale = sm_scalectx.HEAD_DIM = HEAD_DIM_Kctx.causal = causalreturn o@staticmethoddef backward(ctx, do):q, k, v, o, M = ctx.saved_tensorsassert do.is_contiguous()assert q.stride() == k.stride() == v.stride() == o.stride() == do.stride()dq = torch.empty_like(q)dk = torch.empty_like(k)dv = torch.empty_like(v)BATCH, N_HEAD, N_CTX = q.shape[:3]PRE_BLOCK = 128NUM_WARPS, NUM_STAGES = 4, 5BLOCK_M1, BLOCK_N1, BLOCK_M2, BLOCK_N2 = 32, 128, 128, 32BLK_SLICE_FACTOR = 2RCP_LN2 = 1.4426950408889634 # = 1.0 / ln(2)arg_k = karg_k = arg_k * (ctx.sm_scale * RCP_LN2)PRE_BLOCK = 128assert N_CTX % PRE_BLOCK == 0pre_grid = (N_CTX // PRE_BLOCK, BATCH * N_HEAD)delta = torch.empty_like(M)_attn_bwd_preprocess[pre_grid](o, do, #delta, #BATCH, N_HEAD, N_CTX, #BLOCK_M=PRE_BLOCK, HEAD_DIM=ctx.HEAD_DIM #)grid = (N_CTX // BLOCK_N1, 1, BATCH * N_HEAD)_attn_bwd[grid](q, arg_k, v, ctx.sm_scale, do, dq, dk, dv, #M, delta, #q.stride(0), q.stride(1), q.stride(2), q.stride(3), #N_HEAD, N_CTX, #BLOCK_M1=BLOCK_M1, BLOCK_N1=BLOCK_N1, #BLOCK_M2=BLOCK_M2, BLOCK_N2=BLOCK_N2, #BLK_SLICE_FACTOR=BLK_SLICE_FACTOR, #HEAD_DIM=ctx.HEAD_DIM, #num_warps=NUM_WARPS, #num_stages=NUM_STAGES #)return dq, dk, dv, None, None, None, Noneattention = _attention.apply@pytest.mark.parametrize("Z", [1, 4])
@pytest.mark.parametrize("H", [2, 48])
@pytest.mark.parametrize("N_CTX", [128, 1024, (2 if is_hip() else 4) * 1024])
@pytest.mark.parametrize("HEAD_DIM", [64, 128])
@pytest.mark.parametrize("causal", [True]) # FIXME: Non-causal tests do not pass at the moment.
@pytest.mark.parametrize("warp_specialize", [False, True] if is_blackwell() else [False])
def test_op(Z, H, N_CTX, HEAD_DIM, causal, warp_specialize, dtype=torch.float16):torch.manual_seed(20)q = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())k = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())v = (torch.empty((Z, H, N_CTX, HEAD_DIM), dtype=dtype, device=DEVICE).normal_(mean=0.0, std=0.5).requires_grad_())sm_scale = 0.5dout = torch.randn_like(q)# reference implementationM = torch.tril(torch.ones((N_CTX, N_CTX), device=DEVICE))p = torch.matmul(q, k.transpose(2, 3)) * sm_scaleif causal:p[:, :, M == 0] = float("-inf")p = torch.softmax(p.float(), dim=-1).half()# p = torch.exp(p)ref_out = torch.matmul(p, v)ref_out.backward(dout)ref_dv, v.grad = v.grad.clone(), Noneref_dk, k.grad = k.grad.clone(), Noneref_dq, q.grad = q.grad.clone(), None# triton implementationtri_out = attention(q, k, v, causal, sm_scale, warp_specialize).half()tri_out.backward(dout)tri_dv, v.grad = v.grad.clone(), Nonetri_dk, k.grad = k.grad.clone(), Nonetri_dq, q.grad = q.grad.clone(), None# comparetorch.testing.assert_close(ref_out, tri_out, atol=1e-2, rtol=0)rtol = 0.0# Relative tolerance workaround for known hardware limitation of CDNA2 GPU.# For details see https://pytorch.org/docs/stable/notes/numerical_accuracy.html#reduced-precision-fp16-and-bf16-gemms-and-convolutions-on-amd-instinct-mi200-devicesif torch.version.hip is not None and triton.runtime.driver.active.get_current_target().arch == "gfx90a":rtol = 1e-2torch.testing.assert_close(ref_dv, tri_dv, atol=1e-2, rtol=rtol)torch.testing.assert_close(ref_dk, tri_dk, atol=1e-2, rtol=rtol)torch.testing.assert_close(ref_dq, tri_dq, atol=1e-2, rtol=rtol)try:from flash_attn.flash_attn_interface import \flash_attn_qkvpacked_func as flash_attn_funcHAS_FLASH = True
except BaseException:HAS_FLASH = FalseTORCH_HAS_FP8 = hasattr(torch, 'float8_e5m2')
BATCH, N_HEADS, HEAD_DIM = 4, 32, 64
# vary seq length for fixed head and batch=4
configs = []
for mode in ["fwd", "bwd"]:for causal in [True, False]:for warp_specialize in [True, False]:if mode == "bwd" and not causal:continueconfigs.append(triton.testing.Benchmark(x_names=["N_CTX"],x_vals=[2**i for i in range(10, 15)],line_arg="provider",line_vals=["triton-fp16"] + (["triton-fp8"] if TORCH_HAS_FP8 else []) +(["flash"] if HAS_FLASH else []),line_names=["Triton [FP16]"] + (["Triton [FP8]"] if TORCH_HAS_FP8 else []) +(["Flash-2"] if HAS_FLASH else []),styles=[("red", "-"), ("blue", "-"), ("green", "-")],ylabel="TFLOPS",plot_name=f"fused-attention-batch{BATCH}-head{N_HEADS}-d{HEAD_DIM}-{mode}-causal={causal}-warp_specialize={warp_specialize}",args={"H": N_HEADS,"BATCH": BATCH,"HEAD_DIM": HEAD_DIM,"mode": mode,"causal": causal,"warp_specialize": warp_specialize,},))@triton.testing.perf_report(configs)
def bench_flash_attention(BATCH, H, N_CTX, HEAD_DIM, causal, warp_specialize, mode, provider, device=DEVICE):assert mode in ["fwd", "bwd"]dtype = torch.float16if "triton" in provider:q = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)k = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)v = torch.randn((BATCH, H, N_CTX, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)if mode == "fwd" and "fp8" in provider:q = q.to(torch.float8_e5m2)k = k.to(torch.float8_e5m2)v = v.permute(0, 1, 3, 2).contiguous()v = v.permute(0, 1, 3, 2)v = v.to(torch.float8_e5m2)sm_scale = 1.3fn = lambda: attention(q, k, v, causal, sm_scale, warp_specialize)if mode == "bwd":o = fn()do = torch.randn_like(o)fn = lambda: o.backward(do, retain_graph=True)ms = triton.testing.do_bench(fn)if provider == "flash":qkv = torch.randn((BATCH, N_CTX, 3, H, HEAD_DIM), dtype=dtype, device=device, requires_grad=True)fn = lambda: flash_attn_func(qkv, causal=causal)if mode == "bwd":o = fn()do = torch.randn_like(o)fn = lambda: o.backward(do, retain_graph=True)ms = triton.testing.do_bench(fn)flops_per_matmul = 2.0 * BATCH * H * N_CTX * N_CTX * HEAD_DIMtotal_flops = 2 * flops_per_matmulif causal:total_flops *= 0.5if mode == "bwd":total_flops *= 2.5 # 2.0(bwd) + 0.5(recompute)return total_flops * 1e-12 / (ms * 1e-3)if __name__ == "__main__":# only works on post-Ampere GPUs right nowbench_flash_attention.run(save_path=".", print_data=True)义了 `_attn_fwd_inner` 函数,这是Fused Attention的核心逻辑,负责执行注意力计算的主要部分。它采用分阶段的方式处理数据,以优化内存访问和计算效率。
官网的代码定义了 _attn_fwd_inner 函数,这是Fused Attention的核心逻辑,负责执行注意力计算的主要部分。它采用分阶段的方式处理数据,以优化内存访问和计算效率。
使用 triton.jit 装饰器定义了 _attn_fwd 函数,这是前向传播的主要函数。它初始化了必要的变量,如累积器acc、中间变量l_i和m_i,并调用 _attn_fwd_inner 来执行核心计算。定义了 _attn_bwd_preprocess、_attn_bwd_dkdv 和 _attn_bwd_dq 函数,分别用于反向传播的预处理、计算dK和dV的梯度、以及计算dQ的梯度。
_attn_bwd 函数整合了反向传播的各个部分,负责整体的反向传播流程。
_attention 类继承自 torch.autograd.Function,它封装了前向和反向传播逻辑,使得这个Fused Attention操作可以无缝集成到PyTorch的自动求导系统中。
性能测试部分使用 pytest 参数化测试来验证Fused Attention的正确性,并与参考实现进行比较。同时,通过 triton.testing.perf_report 进行性能测试,比较Fused Attention与Flash Attention等其他实现的性能。
Flash Attention v3
背景知识
- 注意力机制瓶颈:Transformer 架构中的注意力机制由于其计算复杂度与序列长度呈二次关系,成为大型语言模型和长文本应用的瓶颈。
- FlashAttention 前作:之前的工作(如 FlashAttention 和 FlashAttention-2)通过减少内存读写和融合操作来加速注意力计算,但在新型 GPU(如 H100)上的利用率仍有提升空间。
FlashAttention-3 的优化技术
- 异步执行和 warp 专业化:利用 Tensor Cores 和 TMA 的异步特性,通过将数据生产和消费的 warp 分离,实现计算与数据传输的重叠。
- GEMM 和 softmax 指令重叠:在 softmax 计算的同时执行矩阵乘法(GEMM),通过重新设计算法以减少依赖关系,实现指令的并行执行。
- 低精度计算支持:利用 Hopper GPU 的 FP8 支持,通过块量化和不连贯处理技术,在保持准确性的同时提高计算效率。
研究方法
- 异步计算利用:通过 warp 专业化的软件流水线方案,将数据生产和消费的 warp 分离,以隐藏内存和指令发布延迟。
- 指令重叠:在算法中重叠 softmax 和 GEMM 指令,通过 pingpong 调度方式在不同 warp group 间交替执行 softmax 和 GEMM。
- 低精度优化:使用块量化和不连贯处理技术,通过在块级别进行量化和使用随机正交矩阵来减少量化误差。
实验和结果
- 性能提升:在 H100 GPU 上,FlashAttention-3 在 FP16 精度下实现了 1.5-2.0 倍于 FlashAttention-2 的速度提升,达到高达 740 TFLOPs/s(75% 的利用率)。在 FP8 精度下接近 1.2 PFLOPs/s。
- 准确性验证:FP8 的 FlashAttention-3 在数值误差上比基线 FP8 注意力低 2.6 倍。
- 与 cuDNN 的比较:在长序列情况下,FlashAttention-3 的 FP16 表现优于 NVIDIA cuDNN 库的实现。
关键结论
- FlashAttention-3 通过利用现代 GPU 的异步特性和低精度计算能力,显著提高了注意力机制的计算效率。
- 在 FP16 和 FP8 精度下均实现了显著的性能提升,同时保持或提高了计算准确性。
- 该方法在长序列长度下表现优异,能够处理大规模的 Transformer 模型。
方法细节和观点
- 异步和 warp 专业化:通过将线程分成生产者和消费者角色,生产者负责数据加载,消费者负责计算,从而实现数据传输和计算的并行。
- 指令重叠:在消费者 warpgroup 中,通过 pingpong 调度方式,使得一个 warpgroup 的 softmax 计算与另一个 warpgroup 的 GEMM 操作并行进行。
- 低精度计算:FP8 的使用需要特殊的布局转换和量化技术,以适应 Tensor Cores 的要求,并减少量化带来的误差。
现象
- 硬件特性利用:FlashAttention-3 深入利用了 Hopper GPU 的硬件特性,如 Tensor Cores 的异步执行和 TMA 的内存加载能力。
- 性能对比:与前代 FlashAttention 算法相比,FlashAttention-3 在不同序列长度和精度下均显示出显著的性能优势。
总结
- 创新点:FlashAttention-3 通过异步执行、指令重叠和低精度计算支持,在 GPU 上实现了更快且更准确的注意力计算。
- 意义:该方法对于长序列长度和大规模 Transformer 模型的训练和推理具有重要意义,能够提高处理效率并降低计算资源消耗。
- 未来工作:作者提到将优化 LLM 推理、集成持久内核设计到 FP8 内核中,并进一步研究低精度注意力在大规模训练中的影响。
FlashDecoding
Flash decoding主要优化的地方是split-k/v:
- 首先,将K/V切分成更小的块,比如5块;
- 然后在这些K/V块上,使用标准FlashAttention进行计算,得到所有小块的局部结果
- 最后,使用一个额外的kernel做全局的reduce,得到正确输出
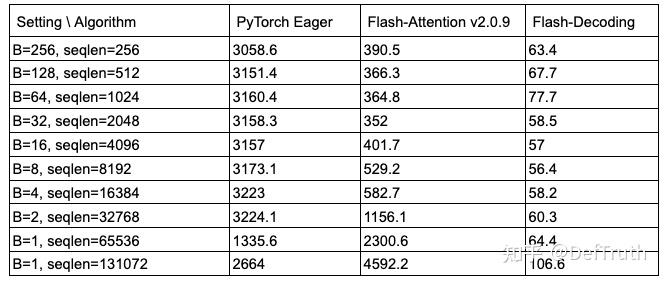
FlashDecoding++
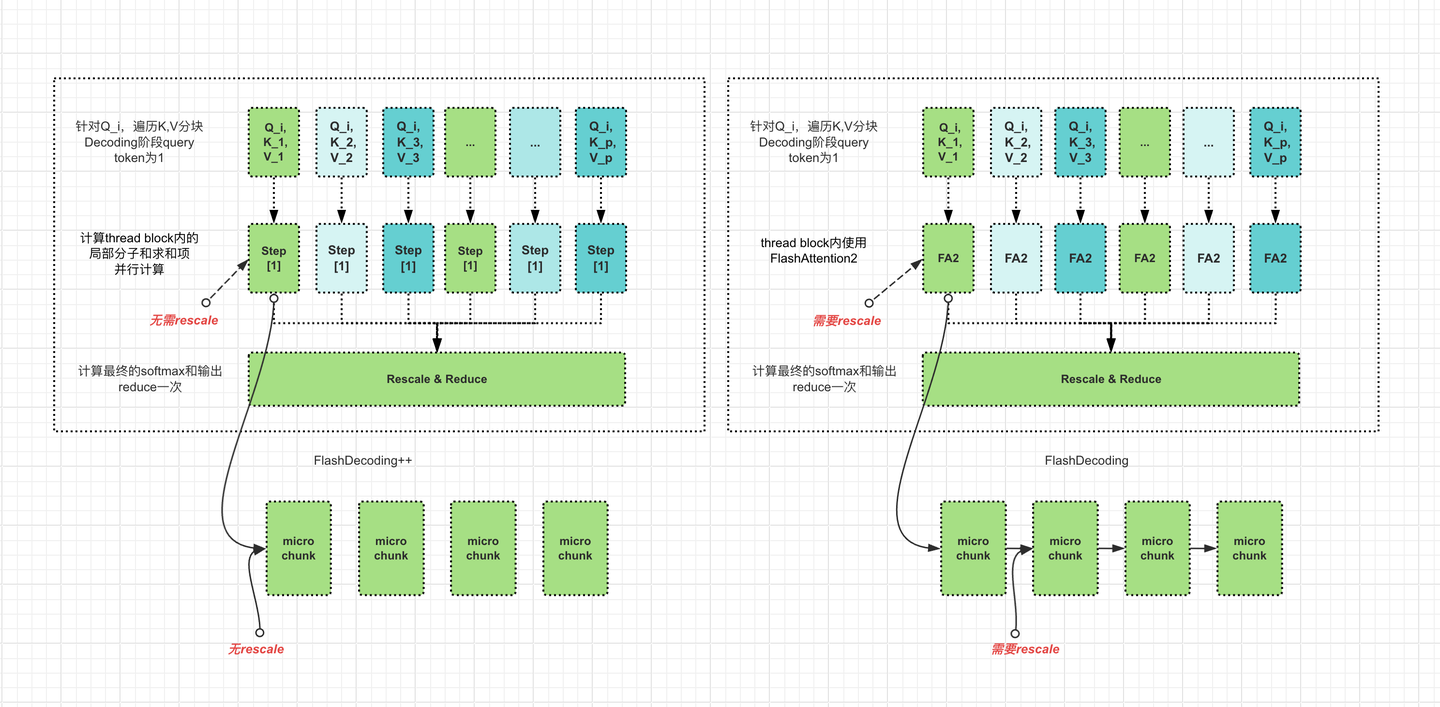
- 在FlashDecoding的基础上预估一个合理的数代替每行的最大值防止溢出,如果溢出则Fallback到FlashDecoding的计算,这样就没有顺序依赖了,并且无需额外的rescale,且可以进行并行计算。
Reference
-
Flash decoding/Flash decoding++: https://zhuanlan.zhihu.com/p/696075602
-
Flash Attention v1/v2/v3: https://zhuanlan.zhihu.com/p/668888063
-
Flash Attention: https://arxiv.org/pdf/2205.14135
-
https://zhuanlan.zhihu.com/p/691623115