阿里巴巴ROLL:大规模强化学习优化的高效易用解决方案
阿里巴巴ROLL:大规模强化学习优化的高效易用解决方案
在强化学习(RL)推动大语言模型(LLM)发展的浪潮中,训练框架面临效率、扩展性和易用性的多重挑战。阿里巴巴推出的 ROLL 框架,通过模块化设计与关键技术创新,为大规模 RL 优化提供了高效且用户友好的解决方案,特别是针对agentic rl进行了特有的工程设计,一起来深入了解这一创新性成果吧!
论文标题
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
来源
https://github.com/alibaba/ROLL
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁

研究背景与现有挑战
RL 在 LLMs 领域的应用突破与发展现状
强化学习(RL)在大语言模型(LLMs)领域的应用已取得显著成功,其中以人类反馈强化学习(RLHF)为典型代表,该技术率先推动了 LLMs 在参考对齐、推理增强及agent tool use等方面的技术发展。众多领先 LLMs 如 OpenA1I o4、QwQ、Seed1.5-thinking 和 Deepseek-R1 等,均借助 RL 在编码、数学问题求解及工具应用等一系列 AI 任务中实现了卓越性能。
现有 LLM 的 RL 优化算法主要包含三大范式:
- 人类反馈强化学习(RLHF):早期通过直接从人类奖励中学习、从动作建议中学习或从动作批评中学习等方式,引导 LLMs 符合人类偏好。
- 可验证奖励强化学习(RLVR):在数学、代码等推理任务中,通过规则验证、沙盒执行等方式判断结果正确性,以获取可验证的奖励信号。
- 多轮agent交互强化学习:针对更真实的agent场景,如管理终端、遍历网页界面等,LLM agent需执行一系列动作来完成任务,近期如火如荼的LLM Tool RL也是多轮交互的特例。
现有 RL 训练框架面临的核心挑战
多模型与多阶段流程的协同管理难题
标准 RL 训练工作流程通常涉及 Actor、Critic、Ref 和 Reward 四大模型,每个训练迭代包含生成、推理和训练三个阶段。以生成阶段为例,Actor模型需基于批量输入提示生成响应,在agentic RL 场景下还需与环境进行多轮交互;推理阶段则依赖 Critic、Ref 和 Reward 模型对生成的响应进行评估,计算监督信号或奖励估计;训练阶段再依据推理阶段获得的奖励信号,对 Actor 和 Critic 模型的参数进行更新。这种多模型、多阶段的训练范式,对系统的协调管理能力提出了极高要求。
效率、可扩展性与可用性的三重瓶颈
尽管已有 Harper 等人(2025)、Hu 等人(2024)等提出了多种系统框架,但大多采用单一控制器、 colocatioin( colocatioin 指将不同阶段的 LLM 放置在同一资源池)或分离架构等经典系统设计方法,这些方法在实际应用中仍存在明显不足。例如,在大规模 GPU 集群中进行训练时,现有框架难以高效利用异构硬件资源,导致训练效率低下;当模型规模扩大到数百亿参数级别时,可扩展性问题凸显,训练过程容易因资源分配不合理而中断;同时,复杂的系统架构也增加了用户的使用门槛,难以满足不同用户群体对灵活控制训练工作流的需求。
Agentic RL 场景下的特殊挑战
在多轮agent交互场景中,环境执行速度缓慢、从动作中获取奖励反馈困难,以及环境与 LLMs 之间复杂的交互关系,共同构成了 RL 优化应用于 LLMs 的重大挑战。例如,在网页界面遍历等任务中,LLM agent需要与环境进行多轮交互,每一轮交互都可能涉及大量的 CPU 资源消耗,而现有框架往往无法高效处理这种复杂的交互逻辑,导致训练效率大幅下降。
强化学习(RL)在推动大语言模型(LLMs)发展中取得显著成功,促使高效 RL 训练框架不断发展。然而,这些框架需要协调管理多个模型和多阶段流程,在效率、可扩展性和可用性方面面临挑战。阿里巴巴推出 ROLL框架,这是一个专为大规模学习的强化学习优化设计的高效、可扩展且用户友好的库,旨在应对这些挑战。
针对不同用户群体的核心特性
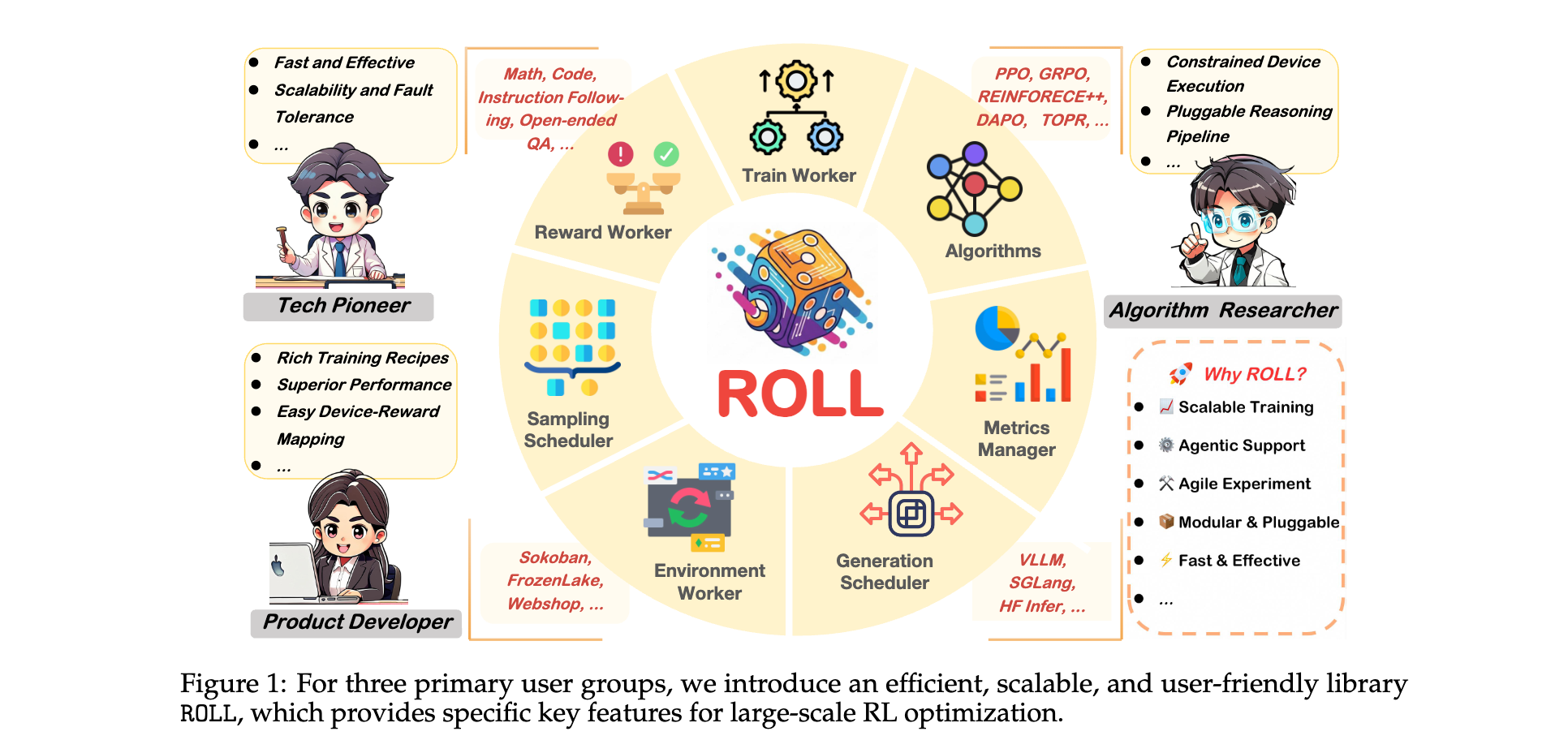
Tech Pioneer
对于追求在LLM社区中领先地位并拥有大规模GPU集群的Tech Pioneer,ROLL具有以下优势:
- 快速且具成本效益:充分利用高性能硬件资源,加速RL训练,大幅降低训练成本和时间。
- 可扩展性与容错性:支持广泛的LLM训练和服务优化技术,能够在数千个GPU上对总参数超过200B的混合专家(MoE)模型进行持续约两周的训练而不中断,并具有高效的检查点和恢复机制。
- 灵活的硬件使用:支持在各种硬件类型上运行RL训练,用户可以选择 colocatioin或分离架构,并配置同步或异步执行模式,充分利用不同硬件架构的优势。
Product Developer
Product Developer拥有足够的GPU来为内部LLM进行RL训练,他们关注于配置任务和奖励以增强LLM的人类对齐、推理能力、工具使用和业务指标。ROLL为他们提供了:
- 多样化且可扩展的奖励/环境:实现了一组全面的reward worker和environment worker,开发者可以在现有实现的基础上轻松自定义自己的奖励和环境。
- 复合的sample-reward路由机制:提供用户友好的api来控制不同任务的prompt采样比例,并动态将每个样本路由到相应的reward worker,使开发者能够优化模型在混合领域任务中的性能。
- 轻量级的device-reward mapping:方便的device-reward mapping,便于配置reward worker的device mapping,将奖励计算与LLM多任务RL训练中的其他计算工作负载隔离,防止干扰和性能瓶颈。
- 丰富的训练设置:提供各种开箱即用的RL算法、LLM、任务和数据集,减少开发新训练功能所需的工程工作量。
- 卓越的性能:包含一组经过调优的训练配置,在许多任务上都能达到令人满意的性能,减轻了繁琐的超参数搜索负担。
Algorithm Researcher
大多数算法研究者只能使用有限数量的GPU,他们需要对LLM的RL训练的每个组件进行灵活、细粒度的控制,以便高效地实验新想法。ROLL非常适合这一目的,提供了以下关键功能:
- 受限设备执行:通过一组内存优化技术,包括单GPU设置,实现了在受限GPU资源上的高效训练,使算法研究者能够在不需要大量高级GPU的情况下进行多次试错实验并获得及时反馈。
- 可插拔的训练pipeline:以适当的粒度抽象RL训练pipeline的每个阶段,实现新想法的敏捷实验。研究者可以灵活地编排各个阶段的执行,便于实现和自定义各种RL算法。
- 透明的实验:提供透明的日志记录和监控功能,便于跟踪和分析每个实验。
- 公平的学术基线:提供经典算法、模型和任务,便于在标准基准上进行公平的基线比较。
Specifications for Agentic RL
随着Agentic RL的兴起,ROLL配备了以下功能,以实现可扩展的Agentic RL训练:
- 可扩展的多轮agent-env交互:受RAGEN启发,支持agent与env之间的多轮交互,可扩展到长周期任务。
- 样本级可扩展环境:可以方便、灵活地进行env scaling,用户可根据env负载情况灵活扩展env的数据,采样足够的训练轨迹,实现高吞吐量的rollout。
- 异步并行的agent-env交互:通过样本级环境管理,env粒度上执行env step和Actor geneate。通过env scaling实现并行环境执行,减少GPU空闲时间,最大化资源利用率。
这一特性应该是社区目前强烈需要的了,借助异步并行可扩展的env采样,可将目前的多轮工具调用/game通过统一的env范式描述,且保持了异步并行高效。
框架设计
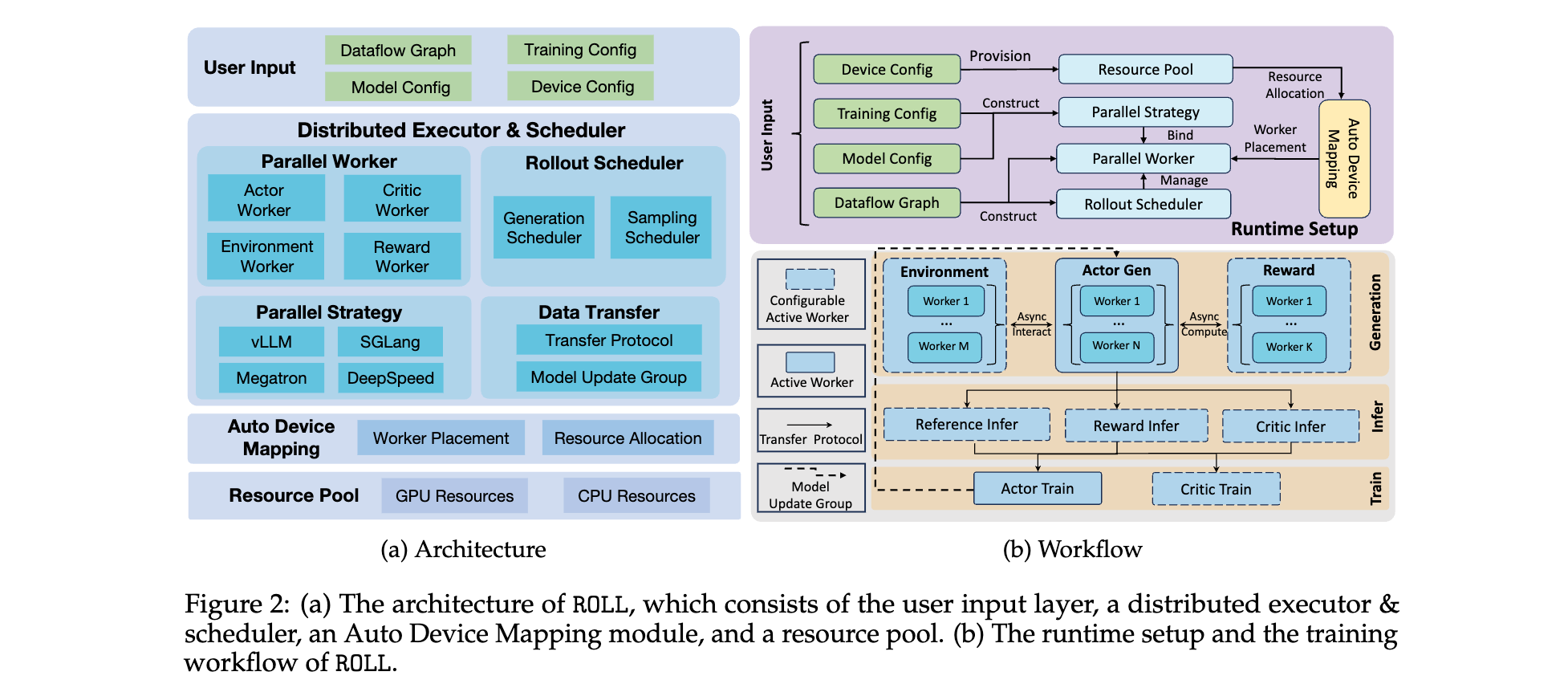
系统架构与模块
如图2a所示,ROLL的架构以用户定义的RL数据流图及其关联配置作为输入。基于该输入,分布式执行器和调度器对工作器(Worker)和调度器进行编排。AutoDeviceMapping模块管理资源池中的资源,并将工作器和调度器高效绑定至分配的资源。
- Parallel Worker:Parallel Worker是一组资源(即Ray中的PlacementGroup)的所有者。ROLL使用Cluster表示RL训练中具有相同角色(如ActorTrain、CriticInfer Model)的Parallel Worker集合,以简化对这些Worker的集中管理。ROLL提供多种类型的Parallel Worker:Actor Worker可实例化为ActorTrain/ActorInfer/Ref;Critic Worker实现Critic功能;Reward Worker计算奖励,支持rule-based verification、sandbox execution和LLM as Judge等多种奖励计算方法;Environment Worker支持各类环境与LLM的多轮交互。
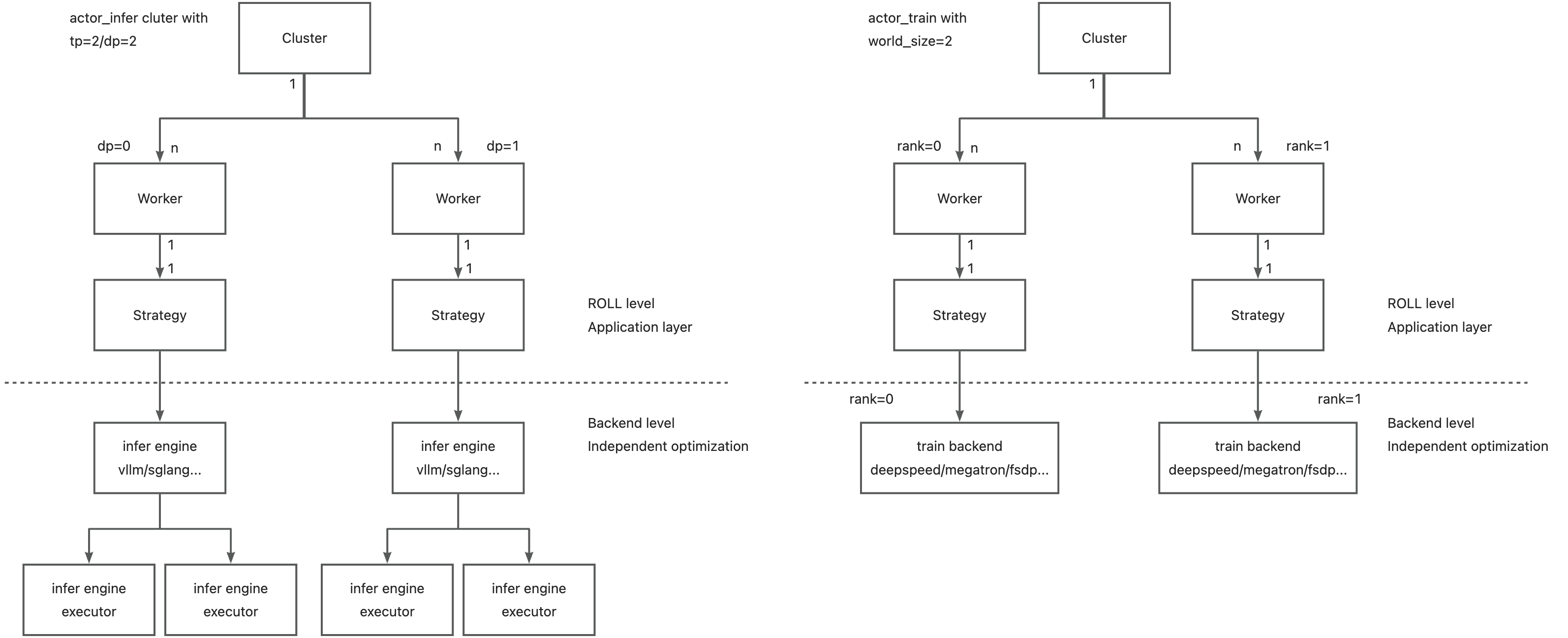
- Parallel Strategy:ROLL的RL训练涵盖训练、推理和生成阶段。通过集成MegatronCore和DeepSpeed,ROLL支持包括DP、TP、PP、CP、EP在内的高级5D并行策略。此外,借助DeepSpeed,ROLL还支持ZeRO2、ZeRO3和ZeRO-offload等技术,并提供梯度检查点和卸载策略以降低GPU内存消耗,实现资源受限设备上的高效执行。对于推理和生成阶段,ROLL集成vLLM和SGLang,以加速TP、EP和PP等并行计算。ROLL将训练、推理加速框架统一在Stratey层,默认实现下,用户可通过配置一键切换不同的train和infer backend,不涉及worker层面如loss代码的修改。Worker根据配置需要构造对应的Strategy即可开箱即用megatron/deepspeed/vllm/sglang engine。当然Worker内也可以自行初始化backend,实现对deepspeed/megatron更细粒度的直接控制。ROLL Stratey的设计解耦了Worker层面的用户计算和backend层面的工程优化,期望能为不同使用需求的用户提供更好的使用体验。下图描述了Cluster/Worker/Strategy的层级关系,以一个统一的视角对待各backend,各backend可独立开展工程优化。
- Rollout Scheduler:Rollout Scheduler允许用户在生成阶段以单个样本为粒度调度每个请求的生命周期,可根据当前资源可用性(actor infer的负载)和响应生成进度动态添加或中止请求。当然直接调用actor.generate即可使用原始的batch dp的方式完成rollout。用户可根据需要使用。
- Data Transfer:ROLL复用了HybridFlow中引入的传输协议(Transfer Protocol),以在不同阶段对输入输出数据进行重新分片。ModelUpdateGroup通过NCCL通信后端实现训练与生成/推理阶段之间的参数快速同步,即使在 actor_train/infer colocatioin训练场景中也能高效运行。
- AutoDeviceMapping:AutoDeviceMapping模块协调ResourcePool中的CPU和GPU资源,并将其绑定至Worker。ResourcePool在ray 的placement_group和bundle的基础上,实现了灵活方法的将Worker指定放置到特定GPU的功能。
系统工作流程
运行时设置
ROLL根据提供的设备配置准备包含GPU和CPU资源的资源池。在RL dataflow的引导下,创建Rollout Scheduler和多个Parallel Worker。Rollout Scheduler负责管理生成阶段每个prompt样本请求的生命周期。根据训练和模型配置,ROLL实例化Parallel Strategy,以确定每个Parallel Worker的并行策略和执行后端。Parallel Worker创建完成后,ROLL按照用户指定的设备映射配置,通过AutoDeviceMapping从资源池为各Parallel Worker分配资源。
训练迭代
在生成阶段,首先通过Rollout Scheduler采集rollout batch size数量的responses。在此过程中,Actor模型可能与Environment Worker交互,在agentic rl任务中执行多轮环境交互,并调用Reward Worker计算奖励信号。支持动态采样过滤等高级采样技术。推理阶段涉及Critic、Reward和Ref模型的前向传播(若RL dataflow中激活),传输协议将生成阶段的响应分片并输入至各激活的Parallel Worker。训练阶段中,Critic和Actor模型利用生成阶段的样本和推理阶段的奖励信号更新参数,Actor模型还通过ModelUpdateGroup在后续迭代中与生成阶段同步参数。
关键功能的技术支撑
Single-Controller Pipeline:ROLL遵循HybridFlow的混合编程模型,在单一控制器内实现RLHF、RLVR和Agentic RL的训练pipeline,简化RL训练工作流的开发与管理。
Worker Abstraction for RL Pipeline:Parallel Worker和Rollout Scheduler的抽象使用户能够通过参考提供的训练工作流示例,以最小的工程成本定义和实验新的pipeline。其中,Actor Worker、Critic Worker、Reward Worker和Environment Worker封装了RL训练中的不同角色,清晰的抽象使用户可专注于开发和自定义单个组件,而无需重构整个代码库。并且Stratey的设计解耦了Worker层面的用户计算和backend层面的工程优化,用户可根据需要方便的进行scale,而不修改Worker层面的业务计算。
Optimized LLM Execution:ROLL充分利用DeepSpeed、Megatron、vLLM和SGLang等现有LLM执行引擎的高级功能,以支持大规模GPU集群和资源受限设备环境下的RL优化。
User-defined Device Mapping:AutoDeviceMapping模块支持灵活的用户定义设备映射,允许单个设备被不同阶段的多个LLM共享。这一能力源于两方面:基于Ray实现设备与工作器的绑定及多工作器共享同一设备;ModelUpdateGroup支持跨阶段模型同步,通过分桶广播方式提升参数传输速度,相比传统RL系统支持更灵活的设备分配策略。
Sample-level Rollout Lifecycle Control:Rollout Scheduler提供样本级的rollout生命周期控制,可通过异步奖励计算、动态请求添加和主动请求中止等机制加速动态采样,解决生成阶段的长尾问题并优化资源利用率。
Sample-Wise Management of Rewards and Environments:ROLL可根据负载规模部署多个Reward Worker和Environment Worker,通过样本级控制灵活路由样本,并利用AutoDeviceMapping分配硬件资源,实现异步奖励计算和并行环境交互,避免性能瓶颈。
值得一提的是,对于Agentic RL,包括多轮工具调用:(1) ROLL对EnvironmentWorker的抽象,将env部署到ray.Actor上,天然具备env scaling能力;(2) 考虑到ray.Actor对进程资源的消耗,ROLL提供 thread env能力,在ray.Actor中可创建指定个数的env实例,用户可根据env负载情况自行设置; (3) 并且,ROLL在env粒度上描述rl rollout loop,最大化地将描述空间留给用户,用户可以随心所欲地控制agent与env的交互过程,不必受限于工程实现,相信这种不受限的"骚"操作能力能激发社区更多优秀的idea, 一起ROLL起来!!!
实验验证
RLVR Pipeline实验
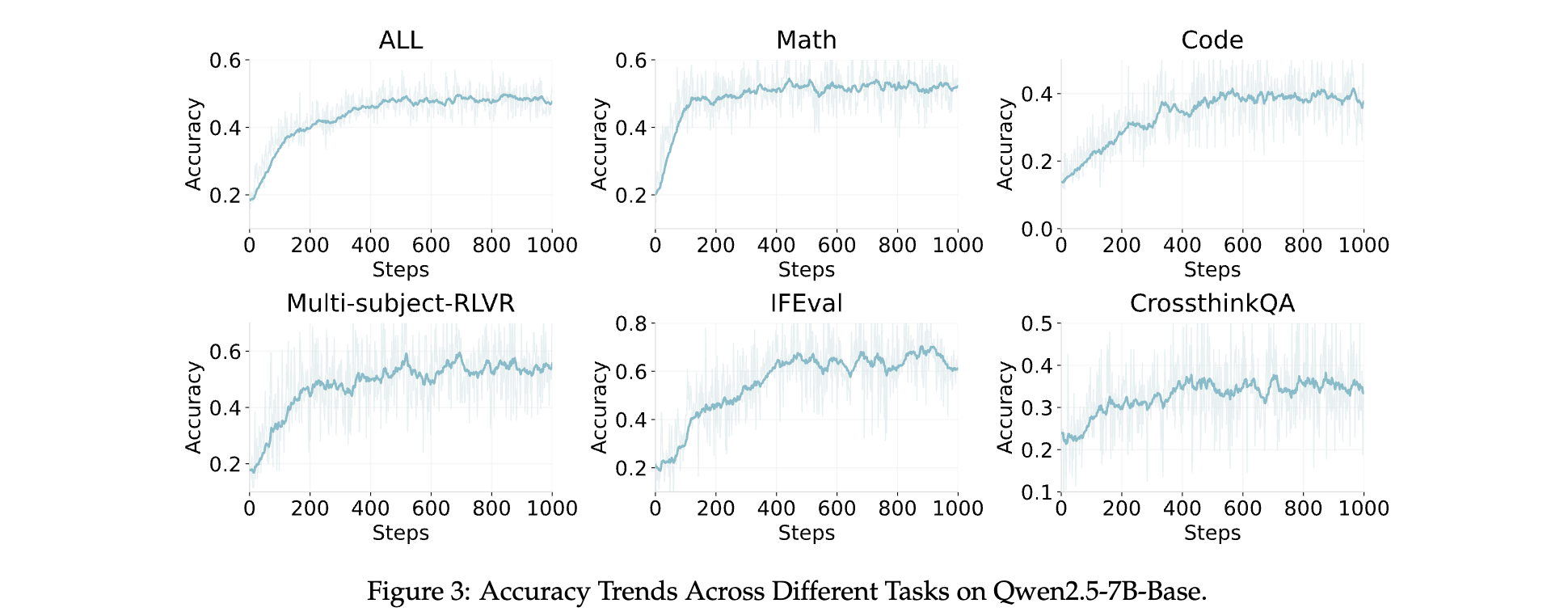
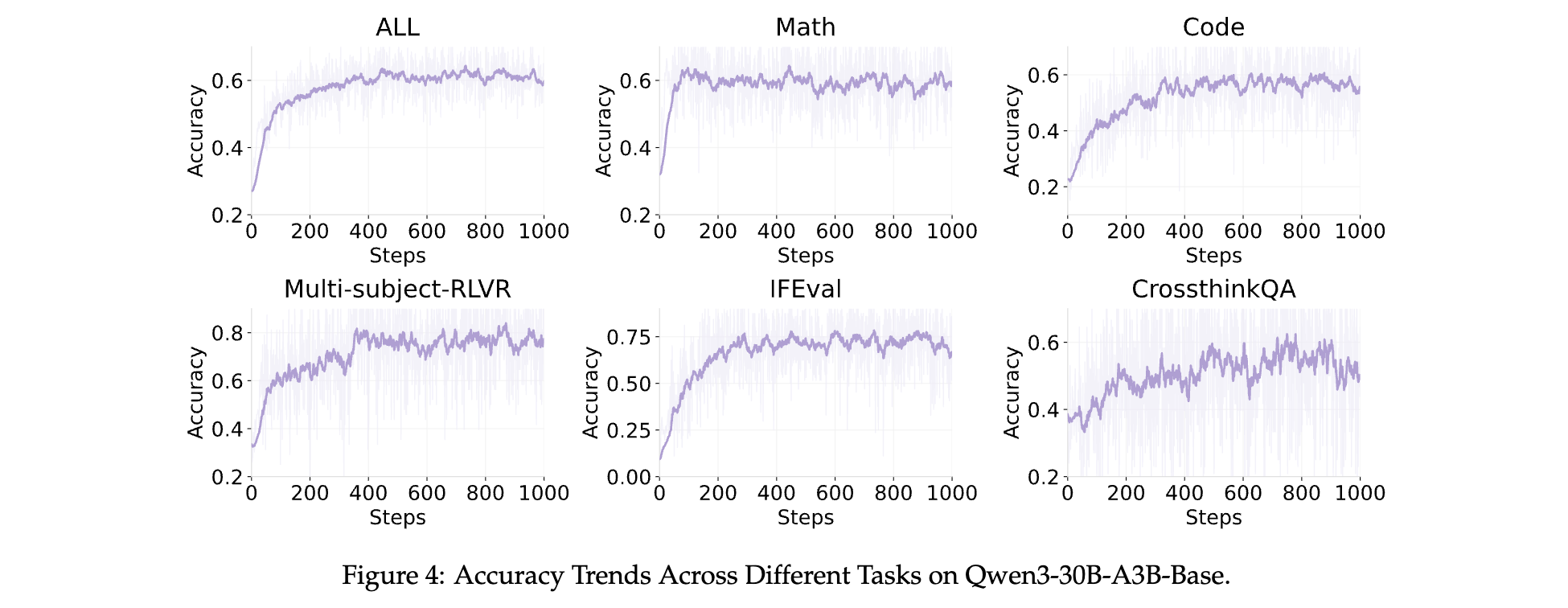
在 RLVR pipeline实验中,使用来自数学、代码和通用领域的数据集,对 Qwen2.5-7B-base 和 Qwen3-30B-A3B-base 两个 LLM 进行实验。结果显示,Qwen2.5-7B-Base 模型的平均准确率从 0.18 提高到 0.52,提高了 2.89 倍;Qwen3-30B-A3B-Base 模型的准确率从 0.27 提高到 0.62,提高了 2.30 倍。尽管 Qwen3-30B-A3B-Base 模型采用混合专家架构,训练期间的准确率波动较大,但仍呈现明显的上升趋势,最终取得更好的性能。
Agentic Pipeline实验
在三个不同环境中进行了实验:
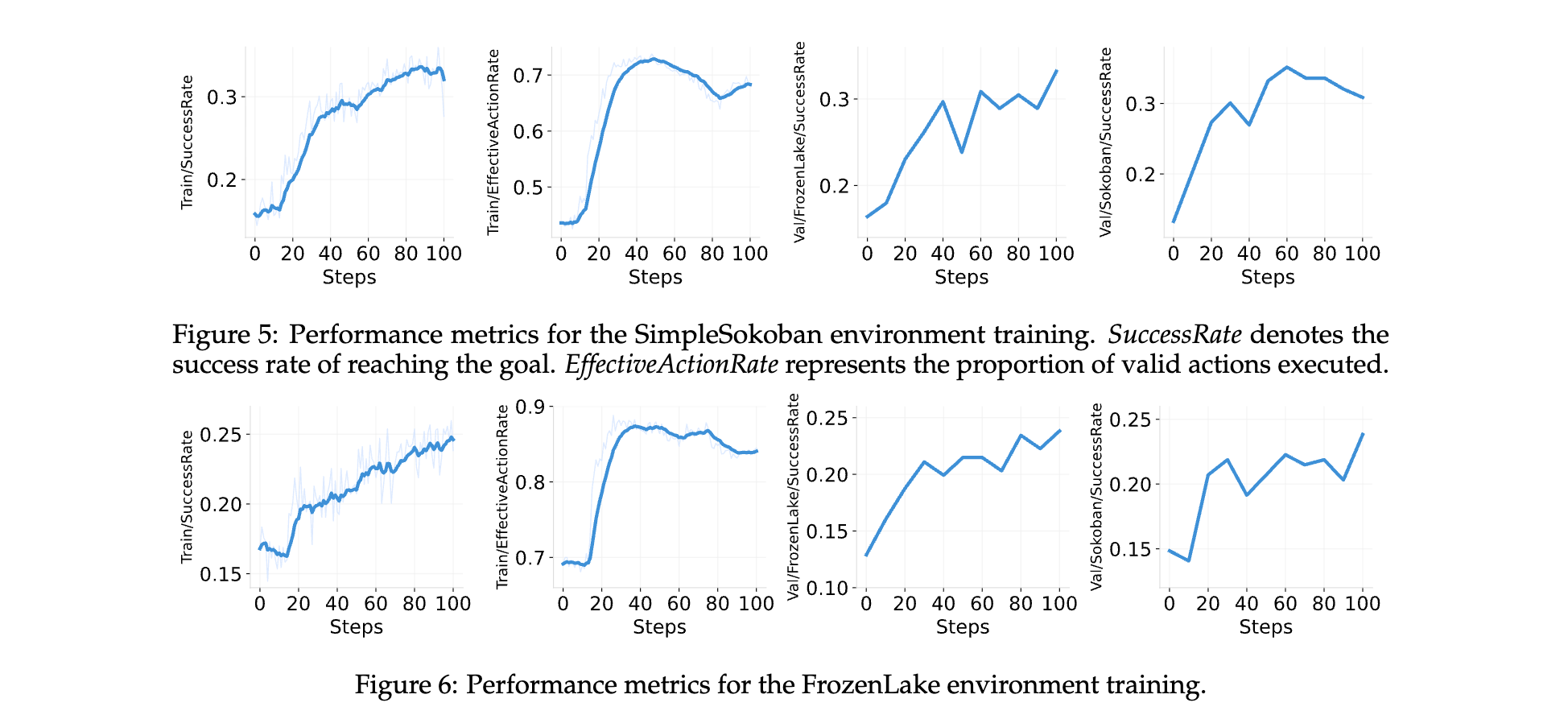
Sokoban 环境
模型在训练中的成功率从 16.8% 提高到 26.0%,验证环境中的成功率从 13.3% 提高到 35.2%,有效行动的比例从 43.6% 提高到 73.4%,并且这些收益很好地推广到了 FrozenLake 环境。
FrozenLake 环境
训练中的成功率从 16.8% 提高到峰值 26.0%,提高了 55%,有效行动的比例从 69.1% 提高到峰值 88.8%,验证集上的成功率从 12.9% 提高到最大值 23.8%,同时模型还表现出跨环境迁移学习能力。
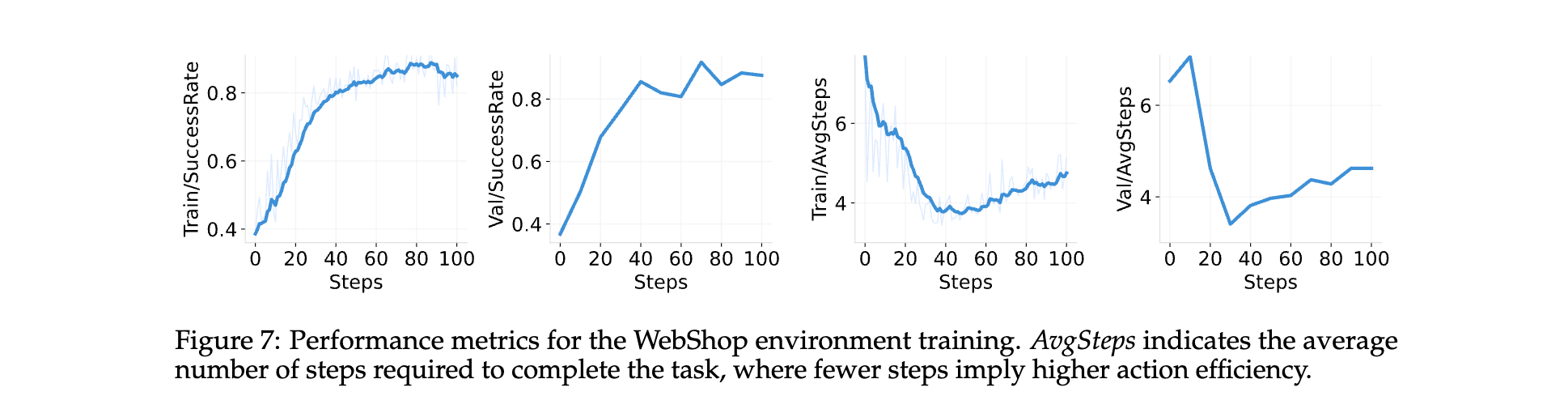
WebShop 环境
任务成功率在训练和验证环境中都从 37% 提高到 85% 以上,每集的平均行动次数从 7 次以上减少到 4 次左右,表明 LLM 学会了更高效地完成任务。
结论
ROLL 库为大规模 LLM 的 RL 训练提供了一个全面的解决方案,通过其核心模块和关键特性,满足了Tech Pioneer、Product Developer和Algorithm Researcher的不同需求。实验结果充分证明了 ROLL 在加速和扩展 LLM 的 RL 训练方面的有效性,为 RL 在 LLM 领域的进一步应用和发展奠定了坚实的基础。
一起ROLL起来!!!
ROLL ROLL ROLL!!!