Python Day45
Task:
1.tensorboard的发展历史和原理
2.tensorboard的常见操作
3.tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
1. TensorBoard 的发展历史和原理
1.1 发展历史
TensorBoard 最早是作为 TensorFlow 生态系统的一部分,由 Google Brain 团队于 2015 年左右首次发布。它旨在解决深度学习模型训练过程中缺乏直观反馈的问题。在 TensorBoard 出现之前,开发者通常只能通过打印命令行日志来监控训练进度,这种方式效率低下且难以发现深层次的问题。
- 早期 (2015-2017): 严格绑定于 TensorFlow,通过
tf.summaryAPI 收集数据。其核心思想是将训练过程中的各种信息(如损失、准确率、权重分布、计算图等)序列化并写入特殊的事件文件 (event files)。TensorBoard 服务读取这些文件并在浏览器中可视化。 - 独立化与通用化 (2018-至今): 随着 PyTorch 等其他深度学习框架的兴起,以及社区对通用可视化工具的需求,TensorBoard 被设计为可以独立于 TensorFlow 运行。
torch.utils.tensorboard.SummaryWriter的引入,使得 PyTorch 用户也能非常方便地将训练数据写入 TensorBoard 兼容的事件文件。现在,它已经成为一个事实上的跨框架的机器学习可视化标准。
核心解决的问题:
- 不透明性: 深度学习模型训练过程是一个“黑箱”,难以实时了解内部状态。
- 调试困难: 当模型不收敛或效果不佳时,难以定位问题。
- 比较困难: 不同实验(不同超参数、不同模型)的结果难以直观比较。
1.2 工作原理
TensorBoard 的核心原理是 事件文件 (Event Files) 和 数据收集与可视化分离。
-
数据收集 (SummaryWriter):
- 在训练代码中,你需要创建一个
SummaryWriter对象(例如,torch.utils.tensorboard.SummaryWriter或tf.summary.create_file_writer)。 - 这个
SummaryWriter对象负责将你在训练过程中想要监控的数据(如标量、图像、直方图、模型图等)记录下来。 - 当你调用
writer.add_scalar(),writer.add_image(),writer.add_graph(),writer.add_histogram()等方法时,这些数据会被序列化成一个特定的协议缓冲区 (Protocol Buffer) 格式,并写入到指定的日志目录下的 事件文件 (.tfevents 文件) 中。 - 每个事件文件通常包含一个或多个
Event消息,每个Event消息又包含一个Summary消息,Summary消息里就是具体的数据(如一个标量值、一张图片等)。 - 为了性能,数据通常不会立即写入磁盘,而是先缓冲起来,然后批量写入或在
writer.flush()时写入。
- 在训练代码中,你需要创建一个
-
数据读取与可视化 (TensorBoard Web 服务):
- 当你在命令行中运行
tensorboard --logdir <your_log_directory>命令时,TensorBoard 服务会启动一个本地 Web 服务器。 - 这个服务会扫描
<your_log_directory>及其子目录,查找所有的.tfevents文件。 - 它会解析这些事件文件,提取出其中记录的各种数据。
- 通过 WebSocket 和 RESTful API,浏览器端的 TensorBoard 前端(一个基于 React/TypeScript 的单页应用)会请求这些数据。
- 前端收到数据后,使用 D3.js 等库将数据渲染成各种图表和可视化组件,呈现在用户面前。
- 当你在命令行中运行
核心概念:
- Log Directory (日志目录): 指定的用于保存事件文件的根目录。TensorBoard 会扫描此目录及其子目录。
- Event Files (事件文件): 存储训练过程中所有日志数据的二进制文件,通常以
.tfevents结尾。 - Summary (摘要): 对训练过程中某个特定事件或数据点的抽象表示,可以是标量、图像、直方图、文本等。
- Tag (标签): 用于标识不同数据流的字符串,例如 “train/loss”, “val/accuracy”, “weights/fc_layer”。在 TensorBoard 界面中,不同的 Tag 会生成不同的图表。
- Step (步数): 通常是训练的迭代次数或 epoch 数,作为 X 轴的值,表示数据记录的时间点或训练进度。
2. TensorBoard 的常见操作
2.1 启动 TensorBoard
在命令行中导航到你的项目根目录或日志文件所在的父目录,然后运行:
tensorboard --logdir runs # 假设你的日志文件都在 'runs' 目录下
或者,如果你想指定一个特定的日志目录:
tensorboard --logdir path/to/your/logs
然后打开浏览器,访问命令行中显示的地址,通常是 http://localhost:6006。
2.2 常见面板与操作
TensorBoard 界面包含多个面板,每个面板对应一种数据类型:
-
Scalars (标量):
- 用途: 监控随时间变化的单一数值指标,如损失 (loss)、准确率 (accuracy)、学习率 (learning rate) 等。
- PyTorch 代码:
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter('runs/my_experiment') # ... 训练循环中 ... writer.add_scalar('Loss/train', train_loss, global_step=epoch) writer.add_scalar('Accuracy/validation', val_accuracy, global_step=epoch) writer.add_scalar('Learning Rate', optimizer.param_groups[0]['lr'], global_step=epoch) # ... writer.close() - 效果: 生成折线图,可以对比不同实验、不同标签的曲线。
-
Graphs (计算图):
- 用途: 可视化模型的计算图(网络结构),帮助理解数据流和操作依赖。
- PyTorch 代码:
import torch import torch.nn as nn from torch.utils.tensorboard import SummaryWriterclass MyModel(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3, 16, 3, 1, 1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(2, 2)self.fc = nn.Linear(16 * 16 * 16, 10) # 假设输入是 3x32x32def forward(self, x):x = self.pool(self.relu(self.conv(x)))x = x.view(-1, 16 * 16 * 16) # Flattenreturn self.fc(x)writer = SummaryWriter('runs/model_graph') model = MyModel() dummy_input = torch.randn(1, 3, 32, 32) # 注意:需要一个虚拟输入 writer.add_graph(model, dummy_input) writer.close() - 效果: 展示模型的前向传播路径,每个节点代表一个操作或一个层。
-
Histograms (直方图):
- 用途: 可视化张量(如权重、偏置、激活值、梯度)的分布随时间的变化。
- PyTorch 代码:
# ... 训练循环中 ... # 每隔几个 epoch 记录一次 if epoch % 5 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step=epoch)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step=epoch) - 效果: 显示堆叠的直方图,可以观察到权重是否收敛、是否出现梯度消失/爆炸等问题。
-
Distributions (分布):
- 用途: 另一种可视化张量分布的方式,通常以更平滑的曲线表示。
- PyTorch 代码: 同 Histograms,
add_histogram也会在 Distributions 面板中显示。
-
Images (图像):
- 用途: 记录图像数据,如输入图像、特征图、生成图像等。
- PyTorch 代码:
import torchvision import numpy as np# ... 训练循环外,或某个 epoch 开始时 ... # 从 DataLoader 获取一批图像 dataiter = iter(train_loader) images, labels = next(dataiter)# 添加一批图像(最多 64 张) img_grid = torchvision.utils.make_grid(images) writer.add_image('CIFAR10 Images', img_grid, global_step=0)# 添加单张图片 # writer.add_image('Single Image Example', images[0], global_step=0) - 效果: 显示图像网格或单张图片,可用于检查数据预处理、模型输出等。
-
Text (文本):
- 用途: 记录任意文本信息,如实验描述、超参数、日志摘要等。
- PyTorch 代码:
writer.add_text('Experiment Details', 'This is a test run with a simple CNN on CIFAR10. Learning rate: 0.001', global_step=0) writer.add_text('Hyperparameters', '```\nEpochs: 10\nBatch Size: 64\nOptimizer: Adam\n```', global_step=0) # 支持Markdown - 效果: 显示格式化的文本内容。
-
Projector (投影仪):
- 用途: 可视化高维数据(如词嵌入、图像特征)在低维空间(2D/3D)的投影。
- PyTorch 代码:
# embeddings: 形状为 (N, D) 的张量,N 是样本数,D 是维度 # labels: 形状为 (N,) 的列表或张量,对应每个样本的标签 # images: 形状为 (N, C, H, W) 的张量,用于在投影点上显示图像 # writer.add_embedding(embeddings, metadata=labels, label_img=images, global_step=epoch) - 效果: 交互式 3D 散点图,可以观察不同类别样本的聚类情况。
-
HParams (超参数):
- 用途: 管理和比较不同超参数组合的实验结果,非常适合超参数调优。
- PyTorch 代码:
from tensorboard.plugins.hparams import api as hp# 定义超参数 HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32])) HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2)) HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))METRIC_ACCURACY = 'accuracy' METRIC_LOSS = 'loss'# 在训练开始前定义 HParams with SummaryWriter('runs/hparam_tuning') as writer:writer.add_hparams({HP_NUM_UNITS: 32,HP_DROPOUT: 0.1,HP_OPTIMIZER: 'adam'},{METRIC_ACCURACY: final_accuracy,METRIC_LOSS: final_loss},run_name='run_1' # 每个 HParam 运行需要一个唯一的名称) - 效果: 一个表格界面,列出所有实验的超参数及其对应的指标,支持排序和过滤。
3. TensorBoard 在 CIFAR 上的实战:MLP 和 CNN 模型
我们将为 MLP 和 CNN 模型在 CIFAR-10 数据集上训练过程进行 TensorBoard 监控。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # 进度条# 1. 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 2. 数据准备
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到 [-1, 1]
])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 辅助函数:显示图像网格
def imshow(img_tensor):img_tensor = img_tensor / 2 + 0.5 # 反归一化npimg = img_tensor.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# 3. 模型定义# 3.1 MLP 模型
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将 32x32x3 图像展平为 3072self.fc1 = nn.Linear(32 * 32 * 3, 512)self.relu1 = nn.ReLU()self.fc2 = nn.Linear(512, 256)self.relu2 = nn.ReLU()self.fc3 = nn.Linear(256, 10) # 10 个类别def forward(self, x):x = self.flatten(x)x = self.relu1(self.fc1(x))x = self.relu2(self.fc2(x))x = self.fc3(x)return x# 3.2 CNN 模型 (简单卷积网络)
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 32x32x32self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 16x16x32self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 16x16x64self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 8x8x64self.fc1 = nn.Linear(64 * 8 * 8, 256)self.relu3 = nn.ReLU()self.fc2 = nn.Linear(256, 10)def forward(self, x):x = self.pool1(self.relu1(self.conv1(x)))x = self.pool2(self.relu2(self.conv2(x)))x = x.view(-1, 64 * 8 * 8) # 展平x = self.relu3(self.fc1(x))x = self.fc2(x)return x# 4. 训练函数
def train_model(model, model_name, num_epochs=10, lr=0.001):print(f"\n--- Training {model_name} ---")writer = SummaryWriter(f'runs/{model_name}_CIFAR10')model.to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=lr)# 记录模型计算图 (Graph) 和输入图像 (Images)dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图img_grid = torchvision.utils.make_grid(images[:16]) # 取前16张图writer.add_image(f'{model_name}/Input Images', img_grid, global_step=0) # 添加输入图像for epoch in range(num_epochs):model.train()running_loss = 0.0correct_train = 0total_train = 0# 添加学习率writer.add_scalar('Learning Rate', optimizer.param_groups[0]['lr'], global_step=epoch)for i, (inputs, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs} Training")):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_train += labels.size(0)correct_train += (predicted == labels).sum().item()# 每隔 100 批次记录一次训练损失和准确率if i % 100 == 99:train_loss_batch = running_loss / 100train_accuracy_batch = 100 * correct_train / total_trainwriter.add_scalar(f'{model_name}/Loss/Train_Batch', train_loss_batch, global_step=epoch * len(train_loader) + i)writer.add_scalar(f'{model_name}/Accuracy/Train_Batch', train_accuracy_batch, global_step=epoch * len(train_loader) + i)running_loss = 0.0correct_train = 0total_train = 0# 记录每个 epoch 的训练损失和准确率# 为了简洁,这里只记录验证集的,如果需要,可以在循环外累加整个epoch的训练指标再记录。# 评估模型model.eval()val_loss = 0.0correct_val = 0total_val = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).sum().item()epoch_val_loss = val_loss / len(test_loader)epoch_val_accuracy = 100 * correct_val / total_valprint(f"Epoch {epoch+1}, Val Loss: {epoch_val_loss:.4f}, Val Acc: {epoch_val_accuracy:.2f}%")writer.add_scalar(f'{model_name}/Loss/Validation', epoch_val_loss, global_step=epoch)writer.add_scalar(f'{model_name}/Accuracy/Validation', epoch_val_accuracy, global_step=epoch)# 记录模型参数直方图 (Histograms)if (epoch + 1) % 2 == 0: # 每隔2个epoch记录一次for name, param in model.named_parameters():writer.add_histogram(f'{model_name}/Weights/{name}', param, global_step=epoch)if param.grad is not None:writer.add_histogram(f'{model_name}/Gradients/{name}', param.grad, global_step=epoch)print(f"--- Training {model_name} Finished ---")writer.close()# 5. 执行训练
mlp_model = MLP()
train_model(mlp_model, "MLP", num_epochs=5) # 可以尝试增加 epoch 数cnn_model = SimpleCNN()
train_model(cnn_model, "CNN", num_epochs=5) # 可以尝试增加 epoch 数print("\n--- TensorBoard logs are generated in 'runs' directory ---")
print("To view them, run: tensorboard --logdir runs")
print("Then open your browser to http://localhost:6006")
运行上述代码后,在命令行中执行 tensorboard --logdir runs,然后访问 http://localhost:6006。
效果展示 (你会在 TensorBoard 界面看到以下内容):
-
Scalars 面板:
MLP/Loss/Train_Batch和CNN/Loss/Train_Batch:显示训练过程中批次损失的波动曲线。MLP/Accuracy/Train_Batch和CNN/Accuracy/Train_Batch:显示训练过程中批次准确率的波动曲线。MLP/Loss/Validation和CNN/Loss/Validation:显示每个 epoch 验证集损失的平滑曲线。MLP/Accuracy/Validation和CNN/Accuracy/Validation:显示每个 epoch 验证集准确率的平滑曲线。Learning Rate:显示学习率的变化(这里是恒定的)。- 你可以通过勾选不同的曲线,方便地比较 MLP 和 CNN 在损失和准确率上的表现。通常 CNN 会表现更好。
-
Graphs 面板:
MLP_CIFAR10和CNN_CIFAR10两个图。点击它们可以看到 MLP 和 CNN 的详细网络结构图,包括各个层的连接关系。
-
Images 面板:
MLP/Input Images和CNN/Input Images:显示训练开始时记录的 CIFAR-10 输入图像的网格。可以检查数据是否正确加载和预处理。
-
Histograms/Distributions 面板:
MLP/Weights/...和CNN/Weights/...:显示模型权重(如fc1.weight,conv1.weight等)在不同 epoch 时的分布直方图。你可以观察权重是否在训练过程中正常变化,是否出现梯度消失/爆炸的迹象(虽然这个简单模型可能不明显)。MLP/Gradients/...和CNN/Gradients/...:显示梯度分布的直方图,同样用于诊断训练问题。
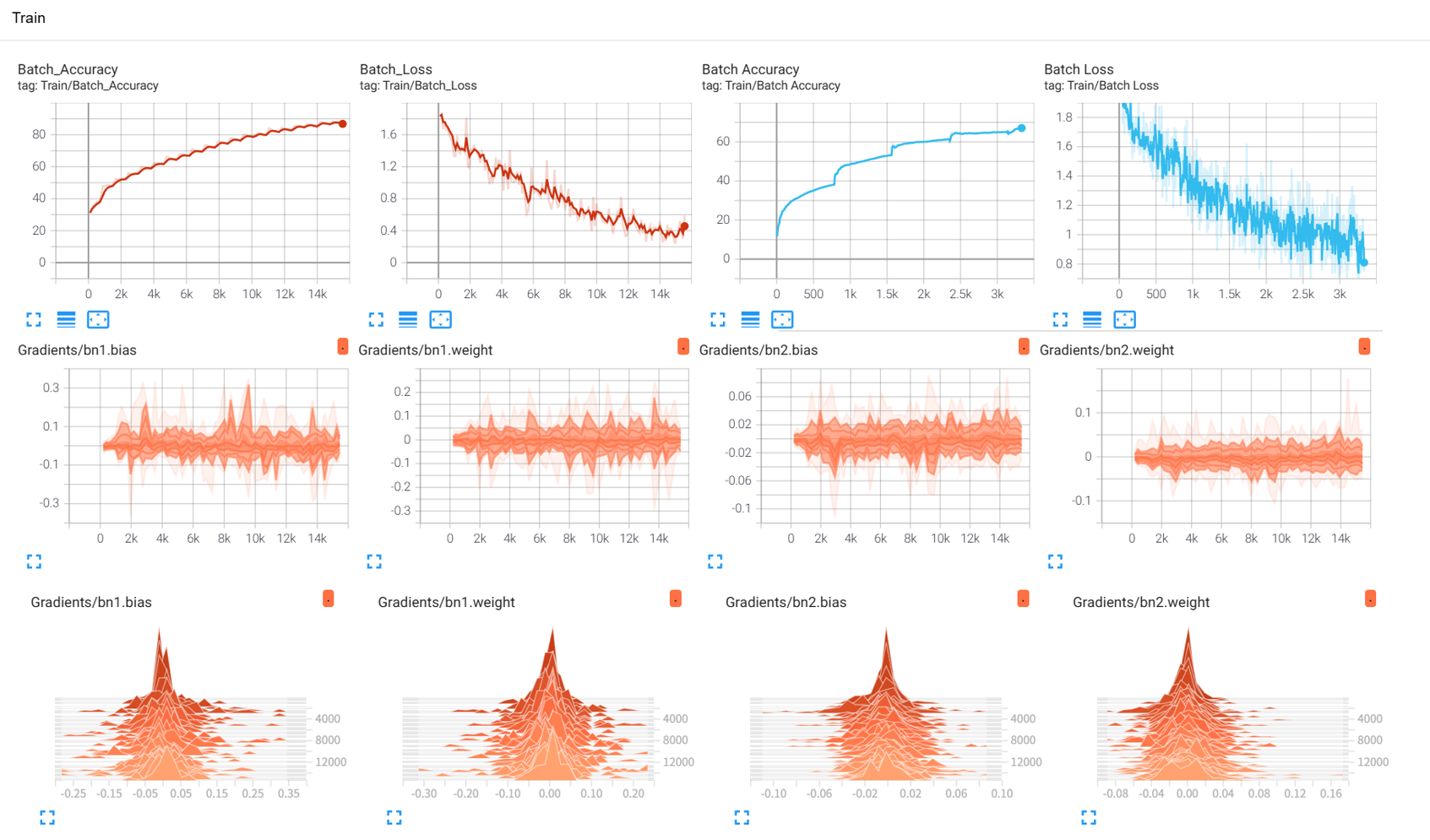
作业:对 ResNet18 在 CIFAR10 上采用微调策略下,用 TensorBoard 监控训练过程。
微调策略:
- 加载预训练的
resnet18模型。 - 冻结除了最后一层分类器之外的所有层(可选,但通常推荐对特征提取层使用较小的学习率或直接冻结)。
- 替换 ResNet18 的原始分类头(通常是全连接层
fc),使其适应 CIFAR-10 的 10 个类别。 - 只训练新的分类头(或以更小的学习率训练整个模型)。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
from tensorboard.plugins.hparams import api as hp # 用于 HParams# 1. 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 2. 数据准备 (针对预训练模型需要特定的归一化)
# ImageNet 的均值和标准差,因为 ResNet18 是在 ImageNet 上预训练的
# CIFAR-10 图像大小是 32x32,ResNet 通常期望 224x224
# 所以需要进行 Resize
transform_train = transforms.Compose([transforms.Resize(224), # 调整图像大小到 224x224transforms.RandomHorizontalFlip(), # 数据增强transforms.RandomCrop(224, padding=4), # 数据增强transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])transform_test = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 3. 模型定义与微调
def get_resnet_model(num_classes=10, pretrained=True, freeze_features=True):model = torchvision.models.resnet18(pretrained=pretrained)if freeze_features:# 冻结所有预训练层的参数for param in model.parameters():param.requires_grad = False# 替换最后一层全连接层 (分类器)# ResNet18 的 FC 层输入特征数是 512num_ftrs = model.fc.in_featuresmodel.fc = nn.Linear(num_ftrs, num_classes) # 新的 FC 层默认 require_grad=Truereturn model# 4. 超参数定义 (用于 HParams 插件)
HP_LR = hp.HParam('learning_rate', hp.Discrete([0.001, 0.0005])) # 尝试不同学习率
HP_BATCH_SIZE = hp.HParam('batch_size', hp.Discrete([64]))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['Adam']))
HP_FREEZE = hp.HParam('freeze_features', hp.Discrete([True])) # 是否冻结特征提取层METRIC_ACCURACY = 'accuracy'
METRIC_LOSS = 'loss'# 5. 训练函数
def train_finetuned_resnet(hparams):# 根据 HParams 选择配置learning_rate = hparams[HP_LR]batch_size = hparams[HP_BATCH_SIZE]optimizer_name = hparams[HP_OPTIMIZER]freeze_features = hparams[HP_FREEZE]# TensorBoard SummaryWriter for this run# run_name 包含超参数值,方便 TensorBoard 区分run_name = f"lr={learning_rate}_bs={batch_size}_freeze={freeze_features}"writer = SummaryWriter(f'runs/ResNet18_Finetuning/{run_name}')print(f"\n--- Starting run: {run_name} ---")# 记录 HParamswriter.add_hparams({HP_LR: learning_rate,HP_BATCH_SIZE: batch_size,HP_OPTIMIZER: optimizer_name,HP_FREEZE: freeze_features},{}, # metrics will be added at the endrun_name=run_name)model = get_resnet_model(num_classes=10, pretrained=True, freeze_features=freeze_features)model.to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 也可以使用学习率调度器scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)num_epochs = 10 # 适当增加 epoch 数# 记录模型计算图 (Graph) 和输入图像 (Images)dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images)img_grid = torchvision.utils.make_grid(images[:16]) # 取前16张图writer.add_image('ResNet18/Input Images', img_grid, global_step=0)best_val_accuracy = 0.0for epoch in range(num_epochs):model.train()running_loss = 0.0correct_train = 0total_train = 0current_lr = optimizer.param_groups[0]['lr']writer.add_scalar('ResNet18/Learning Rate', current_lr, global_step=epoch)for i, (inputs, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs} Training")):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_train += labels.size(0)correct_train += (predicted == labels).sum().item()if i % 100 == 99: # 每 100 个 batch 记录一次train_loss_batch = running_loss / 100train_accuracy_batch = 100 * correct_train / total_trainwriter.add_scalar('ResNet18/Loss/Train_Batch', train_loss_batch, global_step=epoch * len(train_loader) + i)writer.add_scalar('ResNet18/Accuracy/Train_Batch', train_accuracy_batch, global_step=epoch * len(train_loader) + i)running_loss = 0.0correct_train = 0total_train = 0scheduler.step() # 学习率调度# 评估模型model.eval()val_loss = 0.0correct_val = 0total_val = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).sum().item()epoch_val_loss = val_loss / len(test_loader)epoch_val_accuracy = 100 * correct_val / total_valprint(f"Epoch {epoch+1}, Val Loss: {epoch_val_loss:.4f}, Val Acc: {epoch_val_accuracy:.2f}%")writer.add_scalar('ResNet18/Loss/Validation', epoch_val_loss, global_step=epoch)writer.add_scalar('ResNet18/Accuracy/Validation', epoch_val_accuracy, global_step=epoch)# 记录模型参数直方图 (Histograms)if (epoch + 1) % 2 == 0: # 每隔 2 个 epoch 记录一次for name, param in model.named_parameters():if 'bn' not in name: # 跳过BN层,因为参数太多writer.add_histogram(f'ResNet18/Weights/{name}', param, global_step=epoch)if param.grad is not None:writer.add_histogram(f'ResNet18/Gradients/{name}', param.grad, global_step=epoch)# 保存最佳模型if epoch_val_accuracy > best_val_accuracy:best_val_accuracy = epoch_val_accuracytorch.save(model.state_dict(), f'./models/resnet18_cifar10_best_{run_name}.pth')print(f"Saved best model with accuracy: {best_val_accuracy:.2f}%")# 训练结束后,更新 HParams 中的指标writer.add_hparams(hparams,{METRIC_ACCURACY: best_val_accuracy,METRIC_LOSS: epoch_val_loss, # 记录最后一个 epoch 的损失},run_name=run_name)print(f"--- Training {run_name} Finished, Best Val Acc: {best_val_accuracy:.2f}% ---")writer.close()# 6. 执行训练循环 (HParams)
# 确保 'models' 目录存在
import os
os.makedirs('./models', exist_ok=True)# 注册 HParams 定义
with SummaryWriter('runs/ResNet18_Finetuning/hparam_config') as w:w.add_hparams({h.name: h.description for h in [HP_LR, HP_BATCH_SIZE, HP_OPTIMIZER, HP_FREEZE]},{METRIC_ACCURACY: hp.Metric(METRIC_ACCURACY, display_name='Accuracy'),METRIC_LOSS: hp.Metric(METRIC_LOSS, display_name='Loss')})# 运行所有超参数组合
# 这里只运行一个组合,你可以遍历 HP_LR.domain.values 来尝试不同学习率
# 或者使用 itertools.product 组合所有超参数
for lr in HP_LR.domain.values:hparams = {HP_LR: lr,HP_BATCH_SIZE: 64,HP_OPTIMIZER: 'Adam',HP_FREEZE: True}train_finetuned_resnet(hparams)print("\n--- TensorBoard logs are generated in 'runs' directory ---")
print("To view them, run: tensorboard --logdir runs")
print("Then open your browser to http://localhost:6006")
运行上述代码后,在命令行中执行 tensorboard --logdir runs,然后访问 http://localhost:6006。
效果展示 (你会在 TensorBoard 界面看到以下内容):
-
Scalars 面板:
ResNet18/Loss/Train_Batch和ResNet18/Accuracy/Train_Batch:显示训练过程中批次损失和准确率的波动曲线。ResNet18/Loss/Validation和ResNet18/Accuracy/Validation:显示每个 epoch 验证集损失和准确率的平滑曲线。你会发现 ResNet18 的收敛速度更快,且准确率明显高于之前的 MLP 和 CNN。ResNet18/Learning Rate:显示学习率的变化(这里使用了 StepLR,所以会看到阶梯状下降)。
-
Graphs 面板:
ResNet18_Finetuning/...:点击它,你会看到 ResNet18 的复杂网络结构图,包括其大量的残差块 (Residual Blocks)。
-
Images 面板:
ResNet18/Input Images:显示经过Resize和Normalize后的 CIFAR-10 输入图像的网格。
-
Histograms/Distributions 面板:
ResNet18/Weights/...和ResNet18/Gradients/...:显示 ResNet18 各层(特别是你没有冻结的fc层以及未冻结的 BN 层)的权重和梯度分布直方图。由于预训练,初始权重分布会很健康。
-
HParams 面板:
- 这个面板非常关键。它会显示你运行的每个超参数组合(这里是不同学习率的组合)及其对应的最终准确率和损失。
- 你可以通过勾选不同的
HParam和Metrics来筛选和比较实验结果,例如,看哪个学习率取得了最高的准确率。