第4天:RNN应用(心脏病预测)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Pytorch
(二)具体步骤
1. 代码
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns # 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 导入数据
df = pd.read_csv("./data/heart.csv")
print(df) # 构建数据集
# 标准化
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split X = df.iloc[:, :-1]
y = df.iloc[:, -1] # 将第一列特征标准化为标准正态分布,注意,标准化是针对第一列而言的。
sc = StandardScaler()
X = sc.fit_transform(X) # 划分数据集
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1) X_train = X_train.unsqueeze(1)
X_test = X_test.unsqueeze(1)
print("训练集大小:", X_train.shape, y_train.shape) from torch.utils.data import TensorDataset, DataLoader train_dl = DataLoader(TensorDataset(X_train, y_train), batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test), batch_size=64, shuffle=False) # 构建模型
"""
RNN模型类,用于心脏病预测 Attributes: rnn0: RNN层,处理序列数据 fc0: 全连接层,将RNN输出降维到50维 fc1: 最终全连接层,输出2分类结果
"""
class model_rnn(nn.Module): def __init__(self): super(model_rnn, self).__init__() self.rnn0 = nn.RNN( input_size=13, hidden_size=200, num_layers=1, batch_first=True, ) self.fc0 = nn.Linear(200, 50) self.fc1 = nn.Linear(50, 2) """ 前向传播函数 Args: x: 输入张量,形状为(batch_size, seq_len, input_size) Returns: 输出张量,形状为(batch_size, 2),表示两个类别的得分 """ def forward(self, x): out, _ = self.rnn0(x) # 取最后一个时间步的输出作为特征 out = out[:, -1, :] out = self.fc0(out) out = self.fc1(out) return out model = model_rnn().to(device)
print(model) print(model(torch.rand(30, 1, 13).to(device)).shape) # 训练
"""
训练函数,执行一个epoch的训练 Args: dataloader: 数据加载器 model: 神经网络模型 loss_fn: 损失函数 optimizer: 优化器 Returns: 平均训练准确率和损失值
"""
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) num_batches = len(dataloader) train_loss, train_acc = 0, 0 for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() train_acc += (pred.argmax(1) == y).type(torch.float).sum().item() train_loss += loss.item() train_acc /= size train_loss /= num_batches return train_acc,train_loss """
测试函数,评估模型性能 Args: dataloader: 数据加载器 model: 神经网络模型 loss_fn: 损失函数 Returns: 平均测试准确率和损失值
"""
def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) test_loss, test_acc = 0, 0 with torch.no_grad(): for imgs, target in dataloader: imgs, target = imgs.to(device), target.to(device) target_pred = model(imgs) loss = loss_fn(target_pred, target) test_loss += loss.item() test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() test_acc /= size test_loss /= num_batches return test_acc, test_loss loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-4
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)
epochs = 50 train_loss = []
train_acc = []
test_loss = []
test_acc = [] for epoch in range(epochs): model.train() epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt) model.eval() epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) train_acc.append(epoch_train_acc) train_loss.append(epoch_train_loss) test_acc.append(epoch_test_acc) test_loss.append(epoch_test_loss) lr = opt.state_dict()['param_groups'][0]['lr'] template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}') print(template.format(epoch, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr)) print("="*20, 'Done', "="*20) # 评估模型
import matplotlib.pyplot as plt
from datetime import datetime import warnings
warnings.filterwarnings("ignore") current_time = datetime.now() plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 200 epochs_range = range(epochs) # 可视化训练过程中的准确率和损失曲线
# 包含训练集和测试集的对比曲线
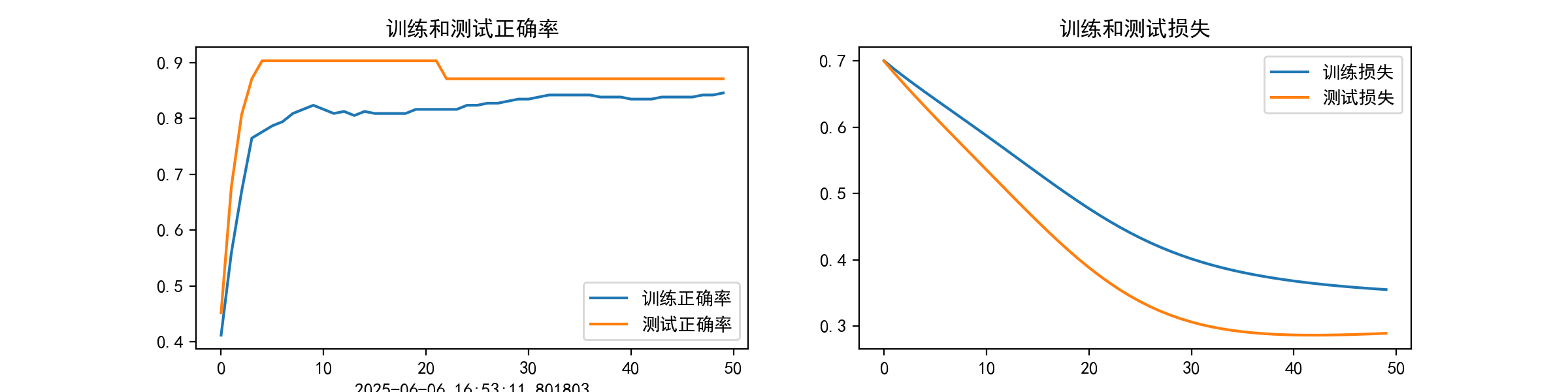
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='训练正确率')
plt.plot(epochs_range, test_acc, label='测试正确率')
plt.legend(loc='lower right')
plt.title('训练和测试正确率')
plt.xlabel(current_time) plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='训练损失')
plt.plot(epochs_range, test_loss, label='测试损失')
plt.legend(loc='upper right')
plt.title('训练和测试损失')
plt.show() # 混淆矩阵
print("====================输入数据shape================")
print("X_test.shape:", X_test.shape)
print("y_test.shape:", y_test.shape)
pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print("\n===================输出数据shape===============")
print("pred.shape:", pred.shape) from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
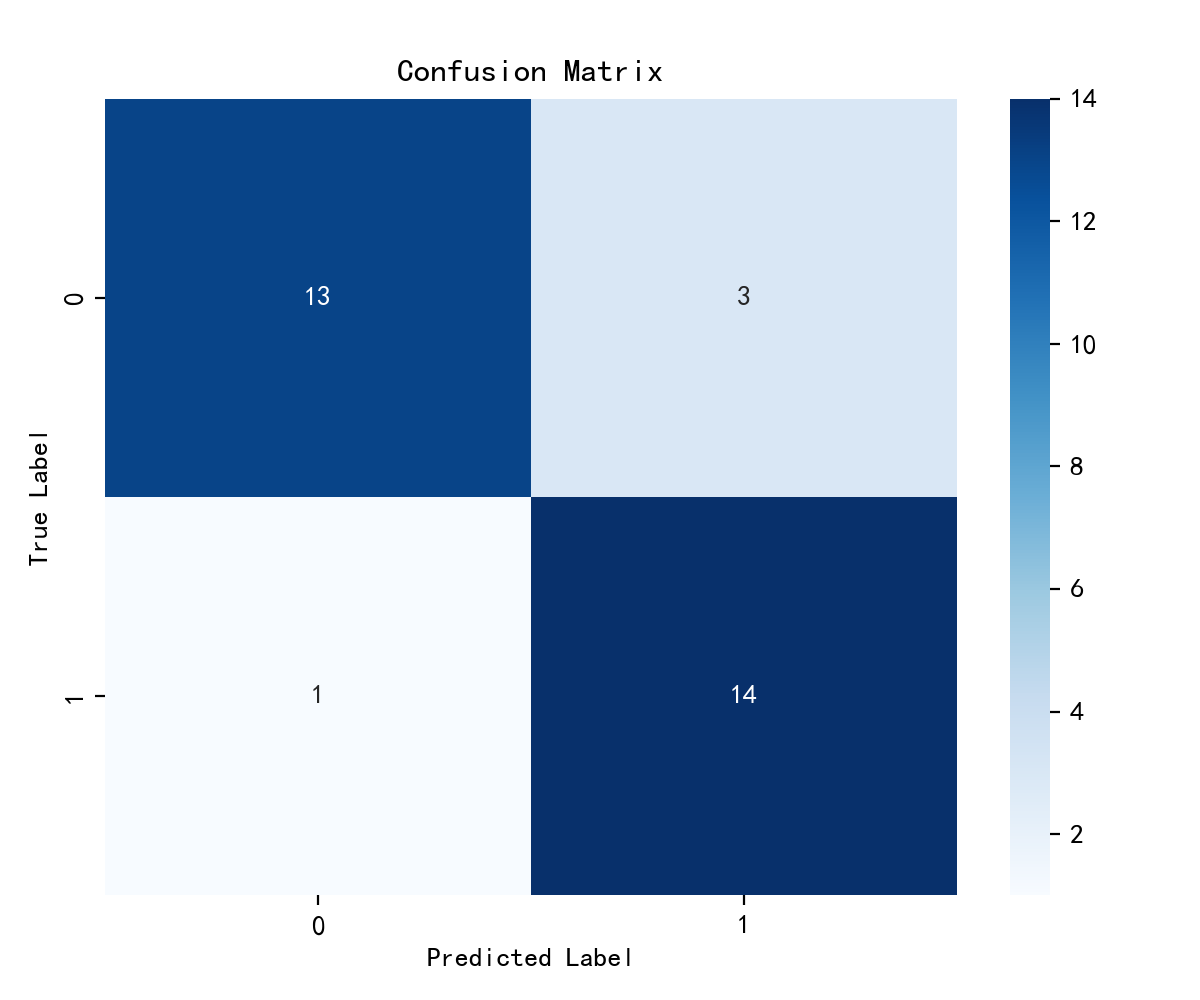
#计算混淆矩阵
# 生成混淆矩阵并可视化
# 显示分类结果的混淆矩阵热力图
cm = confusion_matrix(y_test, pred) plt.figure(figsize=(6, 5))
plt.suptitle("")
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix", fontsize=12)
plt.xlabel("Predicted Label", fontsize=10)
plt.ylabel("True Label", fontsize=10) plt.tight_layout()
plt.show() # 心脏病预测
test_X = X_test[0].unsqueeze(1)
pred = model(test_X.to(device)).argmax(1).item()
print("预测结果为:", pred)
print("=="*20)
print("0:不会患心脏病")
print("1:会患心脏病")
结果:
设备: cudaage sex cp trestbps chol fbs ... exang oldpeak slope ca thal target
0 63 1 3 145 233 1 ... 0 2.3 0 0 1 1
1 37 1 2 130 250 0 ... 0 3.5 0 0 2 1
2 41 0 1 130 204 0 ... 0 1.4 2 0 2 1
3 56 1 1 120 236 0 ... 0 0.8 2 0 2 1
4 57 0 0 120 354 0 ... 1 0.6 2 0 2 1
.. ... ... .. ... ... ... ... ... ... ... .. ... ...
298 57 0 0 140 241 0 ... 1 0.2 1 0 3 0
299 45 1 3 110 264 0 ... 0 1.2 1 0 3 0
300 68 1 0 144 193 1 ... 0 3.4 1 2 3 0
301 57 1 0 130 131 0 ... 1 1.2 1 1 3 0
302 57 0 1 130 236 0 ... 0 0.0 1 1 2 0[303 rows x 14 columns]
训练集大小: torch.Size([272, 1, 13]) torch.Size([272])
model_rnn((rnn0): RNN(13, 200, batch_first=True)(fc0): Linear(in_features=200, out_features=50, bias=True)(fc1): Linear(in_features=50, out_features=2, bias=True)
)
torch.Size([30, 2])
Epoch: 0, Train_acc:41.2%, Train_loss:0.700, Test_acc:45.2%, Test_loss:0.700, Lr:1.00E-04
Epoch: 1, Train_acc:55.9%, Train_loss:0.688, Test_acc:67.7%, Test_loss:0.682, Lr:1.00E-04
Epoch: 2, Train_acc:66.9%, Train_loss:0.676, Test_acc:80.6%, Test_loss:0.664, Lr:1.00E-04
Epoch: 3, Train_acc:76.5%, Train_loss:0.664, Test_acc:87.1%, Test_loss:0.648, Lr:1.00E-04
Epoch: 4, Train_acc:77.6%, Train_loss:0.653, Test_acc:90.3%, Test_loss:0.631, Lr:1.00E-04
Epoch: 5, Train_acc:78.7%, Train_loss:0.642, Test_acc:90.3%, Test_loss:0.615, Lr:1.00E-04
Epoch: 6, Train_acc:79.4%, Train_loss:0.631, Test_acc:90.3%, Test_loss:0.599, Lr:1.00E-04
Epoch: 7, Train_acc:80.9%, Train_loss:0.620, Test_acc:90.3%, Test_loss:0.583, Lr:1.00E-04
Epoch: 8, Train_acc:81.6%, Train_loss:0.609, Test_acc:90.3%, Test_loss:0.567, Lr:1.00E-04
Epoch: 9, Train_acc:82.4%, Train_loss:0.598, Test_acc:90.3%, Test_loss:0.552, Lr:1.00E-04
Epoch:10, Train_acc:81.6%, Train_loss:0.587, Test_acc:90.3%, Test_loss:0.536, Lr:1.00E-04
Epoch:11, Train_acc:80.9%, Train_loss:0.576, Test_acc:90.3%, Test_loss:0.520, Lr:1.00E-04
Epoch:12, Train_acc:81.2%, Train_loss:0.565, Test_acc:90.3%, Test_loss:0.504, Lr:1.00E-04
Epoch:13, Train_acc:80.5%, Train_loss:0.554, Test_acc:90.3%, Test_loss:0.489, Lr:1.00E-04
Epoch:14, Train_acc:81.2%, Train_loss:0.542, Test_acc:90.3%, Test_loss:0.473, Lr:1.00E-04
Epoch:15, Train_acc:80.9%, Train_loss:0.531, Test_acc:90.3%, Test_loss:0.458, Lr:1.00E-04
Epoch:16, Train_acc:80.9%, Train_loss:0.520, Test_acc:90.3%, Test_loss:0.443, Lr:1.00E-04
Epoch:17, Train_acc:80.9%, Train_loss:0.509, Test_acc:90.3%, Test_loss:0.428, Lr:1.00E-04
Epoch:18, Train_acc:80.9%, Train_loss:0.498, Test_acc:90.3%, Test_loss:0.414, Lr:1.00E-04
Epoch:19, Train_acc:81.6%, Train_loss:0.488, Test_acc:90.3%, Test_loss:0.401, Lr:1.00E-04
Epoch:20, Train_acc:81.6%, Train_loss:0.477, Test_acc:90.3%, Test_loss:0.388, Lr:1.00E-04
Epoch:21, Train_acc:81.6%, Train_loss:0.468, Test_acc:90.3%, Test_loss:0.376, Lr:1.00E-04
Epoch:22, Train_acc:81.6%, Train_loss:0.458, Test_acc:87.1%, Test_loss:0.365, Lr:1.00E-04
Epoch:23, Train_acc:81.6%, Train_loss:0.449, Test_acc:87.1%, Test_loss:0.355, Lr:1.00E-04
Epoch:24, Train_acc:82.4%, Train_loss:0.441, Test_acc:87.1%, Test_loss:0.346, Lr:1.00E-04
Epoch:25, Train_acc:82.4%, Train_loss:0.433, Test_acc:87.1%, Test_loss:0.337, Lr:1.00E-04
Epoch:26, Train_acc:82.7%, Train_loss:0.426, Test_acc:87.1%, Test_loss:0.329, Lr:1.00E-04
Epoch:27, Train_acc:82.7%, Train_loss:0.419, Test_acc:87.1%, Test_loss:0.322, Lr:1.00E-04
Epoch:28, Train_acc:83.1%, Train_loss:0.413, Test_acc:87.1%, Test_loss:0.316, Lr:1.00E-04
Epoch:29, Train_acc:83.5%, Train_loss:0.407, Test_acc:87.1%, Test_loss:0.311, Lr:1.00E-04
Epoch:30, Train_acc:83.5%, Train_loss:0.402, Test_acc:87.1%, Test_loss:0.306, Lr:1.00E-04
Epoch:31, Train_acc:83.8%, Train_loss:0.397, Test_acc:87.1%, Test_loss:0.302, Lr:1.00E-04
Epoch:32, Train_acc:84.2%, Train_loss:0.392, Test_acc:87.1%, Test_loss:0.299, Lr:1.00E-04
Epoch:33, Train_acc:84.2%, Train_loss:0.388, Test_acc:87.1%, Test_loss:0.296, Lr:1.00E-04
Epoch:34, Train_acc:84.2%, Train_loss:0.384, Test_acc:87.1%, Test_loss:0.294, Lr:1.00E-04
Epoch:35, Train_acc:84.2%, Train_loss:0.381, Test_acc:87.1%, Test_loss:0.292, Lr:1.00E-04
Epoch:36, Train_acc:84.2%, Train_loss:0.378, Test_acc:87.1%, Test_loss:0.290, Lr:1.00E-04
Epoch:37, Train_acc:83.8%, Train_loss:0.375, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
Epoch:38, Train_acc:83.8%, Train_loss:0.373, Test_acc:87.1%, Test_loss:0.288, Lr:1.00E-04
Epoch:39, Train_acc:83.8%, Train_loss:0.370, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:40, Train_acc:83.5%, Train_loss:0.368, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:41, Train_acc:83.5%, Train_loss:0.366, Test_acc:87.1%, Test_loss:0.286, Lr:1.00E-04
Epoch:42, Train_acc:83.5%, Train_loss:0.364, Test_acc:87.1%, Test_loss:0.286, Lr:1.00E-04
Epoch:43, Train_acc:83.8%, Train_loss:0.363, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:44, Train_acc:83.8%, Train_loss:0.361, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:45, Train_acc:83.8%, Train_loss:0.360, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:46, Train_acc:83.8%, Train_loss:0.358, Test_acc:87.1%, Test_loss:0.287, Lr:1.00E-04
Epoch:47, Train_acc:84.2%, Train_loss:0.357, Test_acc:87.1%, Test_loss:0.288, Lr:1.00E-04
Epoch:48, Train_acc:84.2%, Train_loss:0.356, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
Epoch:49, Train_acc:84.6%, Train_loss:0.355, Test_acc:87.1%, Test_loss:0.289, Lr:1.00E-04
==================== Done ====================
====================输入数据shape================
X_test.shape: torch.Size([31, 1, 13])
y_test.shape: torch.Size([31])===================输出数据shape===============
pred.shape: (31,)
预测结果为: 0
========================================
0:不会患心脏病
1:会患心脏病