LlamaIndex 工作流简介以及基础工作流
什么是工作流?
工作流是一种由事件驱动、基于步骤的应用程序执行流程控制方式。
你的应用程序被划分为多个称为“步骤(Steps)”的部分,这些步骤由“事件(Events)”触发,并且它们自身也会发出事件,从而触发后续的步骤。通过组合使用步骤和事件,你可以创建出任意复杂的流程,以封装逻辑,使你的应用程序更易于维护和理解。一个步骤可以是一行代码,也可以是一个复杂的智能体(agent),它可以拥有任意的输入和输出,并通过事件进行传递。
示例
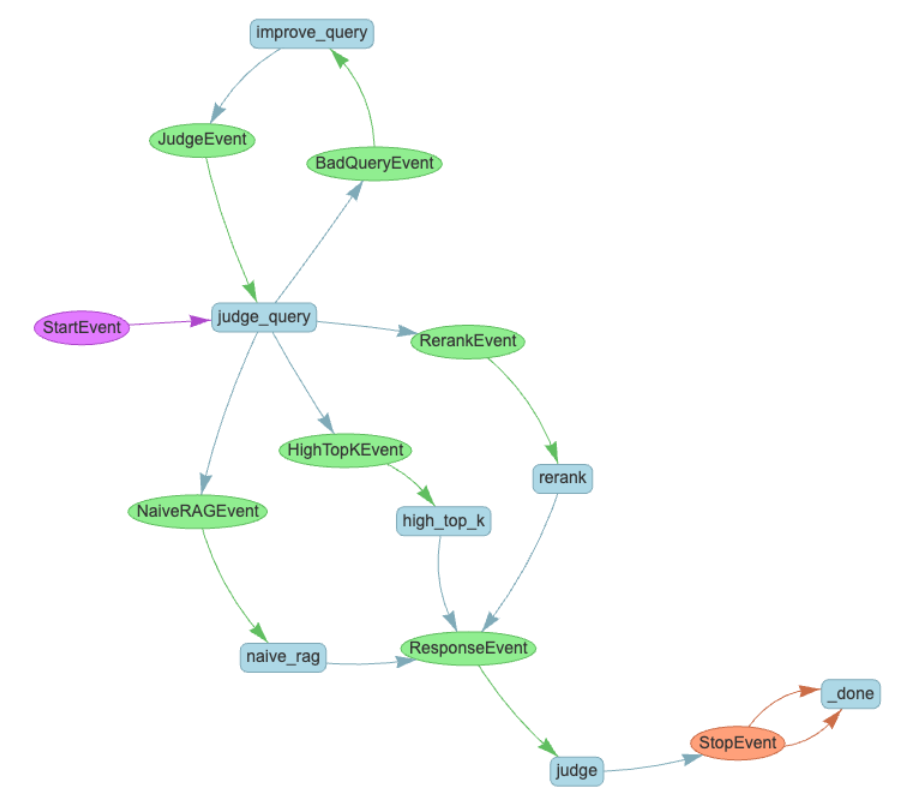
在这张示意图中,你可以看到一个中等复杂度的工作流。该工作流的设计目的是接收一个查询,然后选择性地对其进行优化,并使用三种不同的RAG(检索增强生成)策略来尝试回答这个查询。LLM(大语言模型)会从这三种策略中分别获取答案,并判断哪一个是“最佳”答案,然后将其返回。我们可以将这个流程拆解如下:
该工作流由一个 StartEvent(开始事件) 触发。
-
一个名为 judge_query 的步骤会判断当前查询的质量是否达标。如果不符合要求,则会生成一个 BadQueryEvent(低质量查询事件)。
-
BadQueryEvent 将触发一个名为 improve_query(优化查询) 的步骤,尝试对查询进行改进,之后会触发一个 JudgeEvent(判断事件)。
-
JudgeEvent 将再次触发 judge_query 步骤,从而形成一个循环,直到查询被认为具有足够的质量为止。这种机制被称为“反思(Reflection)”,是 Workflows 让代理型(agentic)应用程序易于实现的关键部分。
如果查询被认为具有足够高的质量,则会同时生成三个事件:
-
NaiveRAGEvent
-
HighTopKEvent
-
RerankEvent
这三个事件将并行触发三个对应步骤,每个步骤运行一种不同的 RAG 策略。
每个查询步骤都会生成一个 ResponseEvent(响应事件)。当一个 ResponseEvent 被触发时,它会激活名为 judge_response(判断响应) 的步骤,并等待接收全部三种响应结果。
最后,judge_response 会从中挑选出“最佳”响应,并通过一个 StopEvent(结束事件) 将其返回给用户。
为什么要使用工作流?
随着生成式人工智能应用变得越来越复杂,管理和控制应用程序中的数据流动与执行流程也变得愈发困难。工作流(Workflows)提供了一种管理这种复杂性的方法,它通过将整个应用程序拆分为更小、更易于管理的模块来实现对流程的有效控制。
其他框架以及 LlamaIndex 本身此前曾尝试使用有向无环图(DAGs)来解决这一问题,但相比工作流(Workflows),这种方法存在一些局限性:
-
类似循环和分支的逻辑需要被编码到图的边(edges)中,这使得整个结构难以阅读和理解。
-
在 DAG 中节点之间传递数据时,可选值、默认值以及具体应传递哪些参数等问题带来了额外的复杂性。
-
对于正在开发复杂、具有循环和分支结构的 AI 应用程序的开发者来说,DAG 的使用方式不够自然。
Workflows 所采用的基于事件的模式和原生 Python 的方式有效解决了上述问题。
对于简单的 RAG 流程和线性演示,我们并不要求你一定使用 Workflows。但随着你的应用程序复杂度不断增加,我们希望你能选择 Workflows 来应对这种复杂性。
基础工作流
安装SDK
工作流(Workflows)已内置于 LlamaIndex 核心中,因此要使用它们,你只需安装 LlamaIndex 即可。
pip install llama-index-core在开发过程中,你可能会发现可视化你的工作流非常有帮助;你可以通过安装我们内置的可视化工具来实现这一点:
pip install llama-index-utils-workflow -i https://mirrors.aliyun.com/pypi/simple/依赖的组件
工作流所需的最低依赖项包括:
from llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,
)单步骤工作流
一个工作流通常通过一个继承自 Workflow 的类来实现。该类可以定义任意数量的步骤,每个步骤都是一个使用 @step 装饰的方法。以下是可能的最简单的工作流示例:
import asynciofrom llama_index.core.workflow import Workflow, StartEvent, StopEvent, stepclass MyWorkflow(Workflow):@stepasync def my_step(self, ev: StartEvent)-> StopEvent:# do something herereturn StopEvent(result="hello world")async def run_workflow():w = MyWorkflow(timeout=10, verbose=False)result = await w.run()print(result)if __name__ == '__main__':asyncio.run(run_workflow())这将只是向控制台打印 “Hello, World!”。
在这段代码中,我们:
-
定义了一个继承自 Workflow 的类 MyWorkflow
-
使用 @step 装饰器定义了一个名为 my_step 的步骤方法
-
该步骤接收一个参数 ev,它是 StartEvent 的一个实例
-
步骤返回一个 StopEvent,并附带结果 "Hello, world!"
-
我们创建了一个 MyWorkflow 实例,设置超时时间为 10 秒,并关闭了详细输出
-
最后运行该工作流并打印其结果
步骤的类型注解
类型注解(例如 ev: StartEvent)以及返回类型注解(如 -> StopEvent)对于工作流的运作方式至关重要。这些类型决定了哪些事件类型会触发对应的步骤。诸如可视化工具(见下文)之类的工具也依赖这些类型注解来判断会生成哪些类型的事件,从而确定控制流接下来的走向。
类型注解是在编译时进行验证的,因此如果你发布了某个事件,但没有任何步骤会消费该事件类型,你将会收到一条错误信息。
启动事件与停止事件
StartEvent 和 StopEvent 是用于启动和终止工作流的特殊事件。
-
任何接受 StartEvent 的步骤都会由 run 命令触发执行。
-
触发一个 StopEvent 将会结束整个工作流的执行,并返回最终结果,即使还有其他步骤尚未执行。
在普通 Python 中运行工作流
工作流默认是异步的,因此你需要使用 await 来获取 run 命令的结果。这在 Notebook 环境中可以正常运行;而在普通的 Python 脚本中,你需要导入 asyncio 并将你的代码封装在一个 async 函数中,如下所示:
async def run_workflow():w = MyWorkflow(timeout=10, verbose=False)result = await w.run()print(result)if __name__ == '__main__':asyncio.run(run_workflow())可视化工作流
工作流的一大特色是其内置的可视化工具,我们已经在前面安装好了。现在让我们来可视化一下刚刚创建的简单工作流:
from llama_index.core.workflow import Workflow, StartEvent, StopEvent, step
from llama_index.utils.workflow import draw_all_possible_flowsclass MyWorkflow(Workflow):@stepasync def my_step(self, start: StartEvent)-> StopEvent:# do something herereturn StopEvent(result="hello world")draw_all_possible_flows(MyWorkflow, filename="basic_workflow.html")这将在当前目录下生成一个名为 basic_workflow.html 的文件。用浏览器打开该文件,即可查看工作流的交互式可视化表示。它看起来会类似于这样:
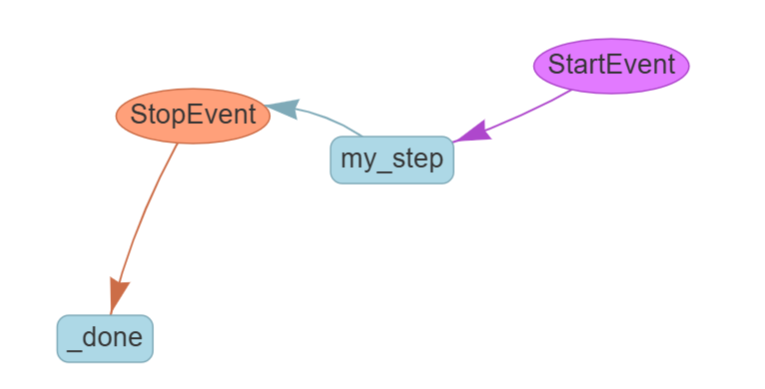
当然,只有一个步骤的工作流并没有太大用处!下面我们来定义一个包含多个步骤的工作流。
自定义事件
多个步骤可以通过定义自定义事件来实现,这些事件可以由某个步骤发出,并触发其他步骤。下面我们来定义一个简单的三步工作流。
我们像之前一样引入所需的模块,并新增一个用于 Event 的导入:
from llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,
)
from llama_index.utils.workflow import draw_all_possible_flows现在我们定义两个自定义事件:FirstEvent 和 SecondEvent。这些类可以具有任意的名称和属性,但必须继承自 Event:
class FirstEvent(Event):first_output: strclass SecondEvent(Event):second_output: str定义工作流
现在我们来定义工作流本身。我们通过为每个步骤指定输入类型和输出类型来实现这一点。
-
step_one 接收一个 StartEvent,并返回一个 FirstEvent
-
step_two 接收一个 FirstEvent,并返回一个 SecondEvent
-
step_three 接收一个 SecondEvent,并返回一个 StopEvent
class MyWorkflow(Workflow):@stepasync def step_one(self, ev: StartEvent)-> FirstEvent:print(ev.first_input)return FirstEvent(first_output="完成第一步...")@stepasync def step_two(self, ev: FirstEvent)-> SecondEvent:print(ev.first_output)return SecondEvent(second_output="完成第二步...")@stepasync def step_three(self, ev: SecondEvent)-> StopEvent:print(ev.second_output)return StopEvent(result="工作流完成!")# 运行工作流
async def run_workflow():w = MyWorkflow(timeout=10, verbose=False)result = await w.run(first_input="开始工作流...")print(result)if __name__ == '__main__':asyncio.run(run_workflow())运行结果:
开始工作流...
完成第一步...
完成第二步...
工作流完成!我们还可以使用可视化工具来查看该工作流中的所有可能流程:
from llama_index.utils.workflow import draw_all_possible_flowsdraw_all_possible_flows(MyWorkflow, filename="multi_step_workflow.html")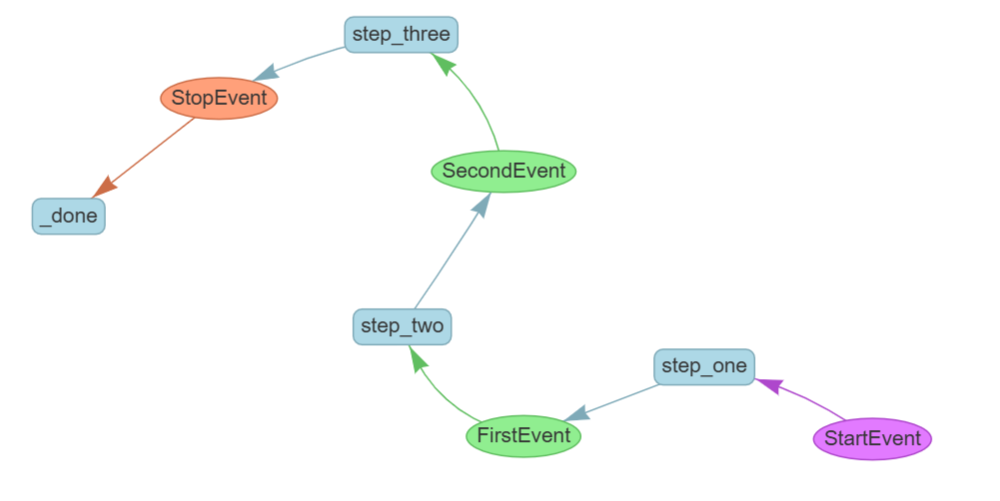
完整代码
import asynciofrom llama_index.core.workflow import (StartEvent,StopEvent,Workflow,step,Event,
)
from llama_index.utils.workflow import draw_all_possible_flows# 第一个事件
class FirstEvent(Event):first_output: str# 第二个事件
class SecondEvent(Event):second_output: strclass MyWorkflow(Workflow):@stepasync def step_one(self, ev: StartEvent)-> FirstEvent:"""第一步"""print(ev.first_input)return FirstEvent(first_output="完成第一步...")@stepasync def step_two(self, ev: FirstEvent)-> SecondEvent:"""第二步"""print(ev.first_output)return SecondEvent(second_output="完成第二步...")@stepasync def step_three(self, ev: SecondEvent)-> StopEvent:"""第三步"""print(ev.second_output)return StopEvent(result="工作流完成!")# 运行工作流
async def run_workflow():w = MyWorkflow(timeout=10, verbose=False)result = await w.run(first_input="开始工作流...")print(result)if __name__ == '__main__':asyncio.run(run_workflow())# 工作流可视化工具
draw_all_possible_flows(MyWorkflow, filename="multi_step_workflow.html")