【AI论文】硬测试:为大型语言模型(LLM)编程合成高质量测试用例
摘要:验证器在大型语言模型(LLM)推理中起着至关重要的作用,这是强化学习等后训练技术所需要的。 然而,对于困难的编码问题,很难找到可靠的验证者,因为一个伪装得很好的错误解决方案可能只能通过仔细的人工编写的难以合成的边缘案例来检测。 为了解决这个问题,我们提出了HARDTESTGEN,这是一种使用LLM进行高质量测试合成的管道。 通过这条管道,我们策划了一个全面的竞争性编程数据集HARDTESTS,其中有47k个问题和合成高质量测试。 与现有测试相比,HARDTESTGEN测试在评估LLM生成的代码时,精确度提高了11.3个百分点,召回率提高了17.5个百分点。 对于更困难的问题,精度的提高可以高达40点。 通过下游代码生成性能的衡量,HARDTESTS也被证明在模型训练方面更有效。 我们将在Github。Huggingface链接:Paper page,论文链接:2505.24098
研究背景和目的
研究背景
随着大型语言模型(LLMs)在自然语言处理任务中的显著进步,其在代码生成和编程辅助领域的应用也日益广泛。LLMs通过强化学习等后训练技术,能够显著提升其推理能力,从而在数学和编程奥林匹克竞赛等挑战性问题上接近甚至超越人类表现。然而,这些后训练技术的有效性高度依赖于可靠的验证器(verifiers),用于评估模型生成的代码解决方案的正确性。
在编程领域,验证代码正确性的传统方法主要依赖于测试用例。然而,现有的测试用例数据集存在诸多不足:一是数据集规模有限,难以覆盖所有可能的代码路径和边界情况;二是测试用例质量参差不齐,许多测试用例过于简单,无法有效检测出代码中的潜在错误;三是对于某些复杂的编程问题,编写高质量的测试用例需要深厚的专业知识和大量的时间投入。
此外,随着在线编程竞赛和开源代码库的兴起,大量的编程问题和相应的代码解决方案被公开。然而,这些资源中的测试用例往往也是专有的,难以直接获取和利用。因此,如何合成高质量、全面的测试用例,以支持LLMs在代码生成任务中的后训练,成为了一个亟待解决的问题。
研究目的
本研究旨在提出一种基于大型语言模型(LLMs)的高质量测试用例合成管道——HARDTESTGEN,并利用该管道构建一个包含47,000个编程问题和合成高质量测试用例的综合数据集——HARDTESTS。具体而言,本研究的目的包括:
-
开发高质量测试用例合成管道:通过利用LLMs的强大语言理解和生成能力,合成能够全面覆盖代码路径和边界情况的高质量测试用例。
-
构建综合编程数据集:策划一个包含大量编程问题和相应高质量测试用例的数据集,以支持LLMs在代码生成任务中的训练和评估。
-
评估测试用例质量:通过比较HARDTESTGEN合成的测试用例与现有测试用例在评估LLM生成代码时的精确度和召回率,验证HARDTESTGEN的有效性。
-
探索测试用例质量对LLM后训练的影响:研究高质量测试用例在LLM后训练中的作用,特别是在强化学习和自蒸馏等场景下对模型性能的提升效果。
研究方法
1. HARDTESTGEN管道设计
HARDTESTGEN管道的设计核心在于利用LLMs生成高质量、全面的测试用例。具体而言,该管道包括以下几个关键步骤:
-
问题理解与分析:首先,对编程问题进行深入理解,提取问题的关键信息和约束条件。
-
测试用例生成策略:根据问题的特性和约束条件,设计多种测试用例生成策略,包括直接生成输入、生成常规输入和生成攻击性输入(即专门设计用于触发代码中潜在错误的输入)。
-
利用LLMs生成测试用例:通过提示工程(prompt engineering),引导LLMs根据给定的测试用例生成策略,生成具体的测试用例输入。同时,利用现有的正确代码解决方案(oracle programs)生成相应的输出,从而构成完整的测试用例。
-
测试用例过滤与验证:对生成的测试用例进行过滤和验证,确保它们符合问题的约束条件,并且能够有效检测出代码中的潜在错误。
2. HARDTESTS数据集构建
利用HARDTESTGEN管道,我们从多个在线编程竞赛平台(如Codeforces、AtCoder等)和开源代码库中收集了大量的编程问题,并为每个问题合成了高质量的测试用例。最终构建的数据集HARDTESTS包含47,000个编程问题和相应的测试用例,涵盖了广泛的难度级别和编程主题。
3. 测试用例质量评估
为了评估HARDTESTGEN合成的测试用例的质量,我们采用了精确度和召回率作为评估指标。具体而言,我们使用LLMs生成的代码解决方案和人工编写的代码解决方案作为候选程序,分别使用HARDTESTGEN合成的测试用例和现有测试用例进行评估。通过比较不同测试用例集在评估候选程序时的精确度和召回率,验证HARDTESTGEN的有效性。
4. 测试用例质量对LLM后训练的影响研究
为了探索测试用例质量对LLM后训练的影响,我们设计了三种后训练场景:教师蒸馏(teacher-distillation)、自蒸馏(self-distillation)和强化学习(reinforcement learning)。在每种场景下,我们分别使用高质量测试用例和低质量测试用例进行训练,并比较训练后模型在代码生成任务上的性能表现。
研究结果
1. 测试用例质量评估结果
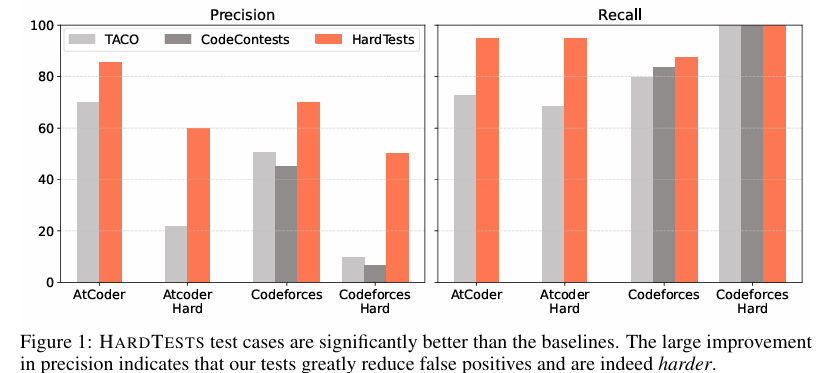
实验结果表明,与现有测试用例相比,HARDTESTGEN合成的测试用例在评估LLM生成代码时具有更高的精确度和召回率。具体而言,在评估Qwen2.5-Coder-7B、Qwen2.5-Coder-14B和GPT-4o等LLMs生成的代码时,HARDTESTGEN测试用例的精确度平均提高了11.3个百分点,召回率平均提高了17.5个百分点。对于更困难的编程问题,精确度的提升甚至可以达到40个百分点。
2. 测试用例质量对LLM后训练的影响
在教师蒸馏场景下,使用高质量测试用例进行训练的模型在下游代码生成任务上的性能表现优于使用低质量测试用例进行训练的模型。这表明高质量测试用例能够提供更准确的反馈信号,从而指导模型学习到更好的代码生成策略。
在自蒸馏场景下,高质量测试用例同样表现出色。使用高质量测试用例进行自蒸馏的模型在保持较高精确度的同时,召回率也有显著提升。这表明高质量测试用例能够帮助模型更好地识别并纠正自身的错误。
在强化学习场景下,高质量测试用例对模型性能的提升效果尤为显著。使用HARDTESTGEN测试用例进行强化学习的模型在代码生成任务上的性能表现远优于使用现有测试用例进行训练的模型。这表明高质量测试用例能够提供更丰富的奖励信号,从而引导模型探索到更优的代码生成路径。
研究局限
尽管HARDTESTGEN管道和HARDTESTS数据集在合成高质量测试用例和支持LLM后训练方面表现出了显著优势,但本研究仍存在一些局限性:
-
测试用例的完全性:尽管我们设计了多种测试用例生成策略,但仍难以保证生成的测试用例能够完全覆盖所有可能的代码路径和边界情况。特别是对于某些复杂的编程问题,可能需要更深入的领域知识和更复杂的测试用例生成策略。
-
LLMs的局限性:本研究依赖于LLMs的语言理解和生成能力来合成测试用例。然而,LLMs本身也存在一定的局限性,如对复杂逻辑的理解不足、对特定领域知识的缺乏等。这些局限性可能影响到测试用例的质量和有效性。
-
评估指标的局限性:本研究采用了精确度和召回率作为评估测试用例质量的指标。然而,这些指标可能无法全面反映测试用例在评估代码正确性方面的效果。例如,某些测试用例可能具有很高的精确度,但召回率较低,即它们只能检测出部分错误代码;而另一些测试用例则可能具有相反的特点。因此,未来研究可以考虑采用更全面的评估指标来评估测试用例的质量。
-
数据集的多样性:尽管HARDTESTS数据集涵盖了广泛的难度级别和编程主题,但仍可能存在一定的数据偏差。例如,某些编程主题或难度级别的问题可能被过度表示,而其他主题或难度级别的问题则可能被低估。这种数据偏差可能影响到模型在不同场景下的泛化能力。
未来研究方向
基于本研究的结果和局限性,未来的研究可以沿着以下几个方向展开:
-
改进测试用例生成策略:探索更先进的测试用例生成策略,以提高测试用例的完全性和有效性。例如,可以结合形式化验证技术来生成更具保证性的测试用例;或者利用对抗性训练等方法来生成能够触发代码中潜在错误的攻击性输入。
-
提升LLMs的性能:针对LLMs在理解复杂逻辑和特定领域知识方面的局限性,未来的研究可以致力于提升LLMs的性能。例如,可以通过引入更多的领域知识、优化模型结构或训练算法等方式来提高LLMs在代码生成任务上的表现。
-
开发更全面的评估指标:为了更全面地评估测试用例的质量,未来的研究可以开发更全面的评估指标。例如,可以考虑引入代码覆盖率、错误检测率等指标来评估测试用例在评估代码正确性方面的效果;或者结合人工评估的方式来验证测试用例的有效性。
-
增强数据集的多样性:为了减少数据集偏差对模型泛化能力的影响,未来的研究可以致力于增强数据集的多样性。例如,可以从更多的在线编程竞赛平台和开源代码库中收集编程问题;或者通过数据增强技术来扩充数据集的规模和多样性。
-
探索测试用例在模型训练中的其他应用:除了后训练场景外,未来的研究还可以探索测试用例在模型训练中的其他应用。例如,可以将测试用例作为模型训练的一部分,通过在线学习或持续学习的方式来不断优化模型的代码生成能力;或者利用测试用例来指导模型的架构设计或超参数调整等。