机器学习KNN算法全解析:从原理到实战
大家好!今天我们来聊聊机器学习中的"懒人算法"——KNN(K-Nearest Neighbors,K近邻)算法。这个算法就像个"墙头草",它不学习模型参数,而是直接根据邻居的"投票"来做决策,是不是很有趣?让我们一起来揭开它的神秘面纱吧!
📚 一、算法简介:近朱者赤,近墨者黑
KNN(K-Nearest Neighbors,K最近邻)是最直观的机器学习算法之一,核心思想就是“物以类聚”:一个样本的类别由其最近的K个邻居决定。比如要判断新同学是“学霸”还是“学渣”,只需看他最常一起玩的K个朋友属于哪类。
算法流程:
- 算距离:计算测试样本与所有训练样本的距离(常用欧氏距离📏);
- 找邻居:选取距离最小的K个样本;
- 数票数:统计K个邻居中各类别的数量;
- 做决策:将测试样本归为票数最多的类别(分类)或邻居的平均值(回归)
💡举个例子:
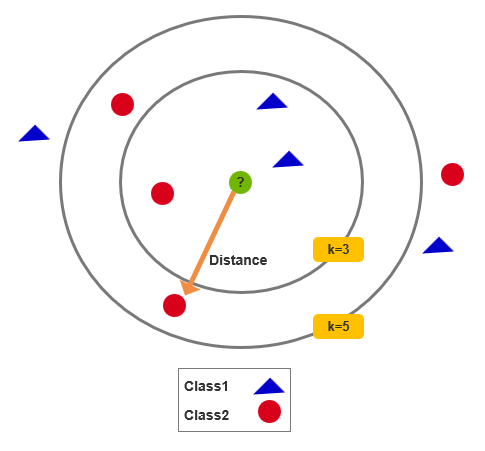
图中绿点待分类,选K=3时,附近2个▲1个● → 归为▲;若K=5,附近3个●2个▲ → 归为●。由此看出K值不同导致分类结果变化。
🌟二、 算法特点:简单粗暴但有效
KNN算法有以下显著特点:
| 优点 | 缺点 |
|---|---|
| ✅ 理论简单,无需训练(惰性学习) | ❌ 计算量大,样本多时慢如蜗牛🐌 |
| ✅ 天然支持多分类问题 | ❌ 样本不平衡时,大类别易“霸凌”小类 |
| ✅ 对异常值不敏感 | ❌ 需要确定合适的K值,特征重要性无区分,所有特征平等对待 |
| ✅ 无需数据分布假设(非参数模型) | ❌ 计算复杂度高,需要大量内存存储全部数据 |
🔍 三、K值的选择:艺术与科学的结合
K值的选择对KNN的性能影响很大:
- K太小:模型复杂,容易过拟合(对噪声敏感),如:邻居中偶然混入一个“学渣”,就把学霸误判了
- K太大:模型简单,容易欠拟合(边界模糊),如:参考全校学生成绩,本地化信息丢失
选择K值的常用方法:
- 经验法:通常取√N(N为样本数)的整数部分
- 交叉验证:尝试不同的K值,选择验证集上表现最好的
- 肘部法则:观察误差随K值变化的曲线,选择"拐点"
🛠️ 四、应用场景:哪里需要"找朋友"
KNN算法在以下场景中表现出色:
- 推荐系统:根据用户相似度推荐商品/电影
- 图像识别:手写数字识别(如MNIST数据集)、人脸识别,通过像素距离找相似图片
- 金融风控:信用卡欺诈检测
- 文本分类:垃圾邮件过滤
- 医疗诊断:根据症状相似度辅助诊断
- 司法辅助:案件推送,相似案情判决参考
💻 五、代码实战:手把手教你用Python实现KNN
让我们用Python的scikit-learn库来实现一个简单的KNN分类器:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report# 1. 加载数据集(使用鸢尾花数据集)
iris = datasets.load_iris()
X = iris.data # 特征
y = iris.target # 标签# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 创建KNN分类器(这里K=3)
knn = KNeighborsClassifier(n_neighbors=3)# 4. 训练模型(KNN没有显式的训练过程,这里只是存储数据)
knn.fit(X_train, y_train)# 5. 预测
y_pred = knn.predict(X_test)# 6. 评估模型
print("准确率:", accuracy_score(y_test, y_pred))
print("\n分类报告:\n", classification_report(y_test, y_pred))# 可视化决策边界(简化版,仅适用于2D特征)
def plot_decision_boundaries(X, y, model, title):# 创建网格点x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# 预测每个网格点的类别Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)# 绘制决策边界和数据点plt.contourf(xx, yy, Z, alpha=0.4)plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')plt.title(title)plt.show()# 由于鸢尾花数据集有4个特征,我们选择前两个特征进行可视化
plot_decision_boundaries(X_train[:, :2], y_train, knn, "KNN决策边界 (K=3)")代码说明:
- 我们使用了经典的鸢尾花数据集
- 创建了一个K=3的KNN分类器
- 计算了模型在测试集上的准确率
- 绘制了决策边界(虽然原始数据是4维的,我们只用了前两维可视化)
📌六、 API详解:scikit-learn中的KNN
scikit-learn提供了非常方便的KNN实现:
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor# 分类器
knn_classifier = KNeighborsClassifier(n_neighbors=5, # K值weights='uniform', # 权重('uniform'或'distance')algorithm='auto', # 计算最近邻的算法p=2, # 距离度量参数(Minkowski距离的p值)metric='minkowski' # 距离度量
)# 回归器
knn_regressor = KNeighborsRegressor(n_neighbors=5,weights='uniform',algorithm='auto',p=2,metric='minkowski'
)常用参数:
n_neighbors:邻居数量Kweights:投票权重('uniform'表示等权重,'distance'表示距离越近权重越大)algorithm:计算最近邻的算法('auto'、'ball_tree'、'kd_tree'、'brute')p:距离度量参数(p=1为曼哈顿距离,p=2为欧氏距离)
💡 七、优化技巧:让KNN更强大
-
特征缩放:KNN对特征尺度敏感,建议标准化数据
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) -
距离度量选择:根据数据特点选择合适的距离度量
-
降维处理:对高维数据使用PCA等方法降维
-
KD树/球树:对于高维数据,使用KD树或球树加速搜索
🎯 八、总结:KNN的魅力与局限
KNN算法就像一个聪明的邻居顾问,它不建立复杂的模型,而是直接参考周围人的意见。虽然简单,但在很多场景下都能表现出色。不过,它也有自己的局限性,特别是在处理大规模或高维数据时。
适用场景:
- 数据量不大
- 特征维度不高
- 需要快速原型开发
不适用场景:
- 数据量非常大
- 特征维度很高
- 需要实时预测
希望这篇文章能帮助你理解KNN算法的精髓!下次当你需要解决分类或回归问题时,不妨考虑一下这个"懒惰但聪明"的算法吧!😉
📌 关注我,获取更多机器学习干货!如果你有任何问题或想看的算法,欢迎在评论区留言哦!👇
拓展阅读
1、机器学习大揭秘:从原理到实战,一篇搞定!
2、机器学习算法大分类,一篇读懂监督、无监督、半监督和强化学习!
3、深度学习数据集探秘:从炼丹到实战的进阶之路