【论文解读】MemGPT: 迈向为操作系统的LLM
1st author: Charles Packer
paper
- MemGPT
- [2310.08560] MemGPT: Towards LLMs as Operating Systems
code: letta-ai/letta: Letta (formerly MemGPT) is the stateful agents framework with memory, reasoning, and context management.
这个项目现在已经转化为 Letta ,一个 16.7K star 的开源项目。Charles Packer 现在是 Letta 的联合创始人兼 CEO, 官网: Letta.
1. 思想
LLM 的核心瓶颈之一是其有限的上下文窗口 (Context Window),这限制了其在长程对话、复杂文档分析等任务中的应用。现有方法如直接扩展上下文长度面临计算成本的平方级增长和“大海捞针” (Lost in the Middle) 的问题;而朴素的 RAG (Retrieval Augmented Generation) 虽能引入外部知识,但缺乏对上下文的动态、智能管理。
MemGPT 借鉴传统操作系统 (OS) 中虚拟内存管理的核心思想,提出一种分层记忆系统 (Hierarchical Memory System)。它不试图无限扩展 LLM 的“物理内存” (即实际的上下文窗口),而是赋予 LLM 一种“虚拟内存”的错觉,使其能够智能地在快速但有限的“主上下文” (Main Context,类比 RAM) 和慢速但海量的“外部上下文” (External Context,类比磁盘) 之间进行信息的换入换出 (Paging)。
核心思想:将 LLM 自身视为一个能够通过函数调用 (Function Calling) 主动管理其认知资源的智能体,而非仅仅是被动的信息处理器。这是一种从“LLM as a model”到“LLM as an agent/OS kernel”的范式转变。
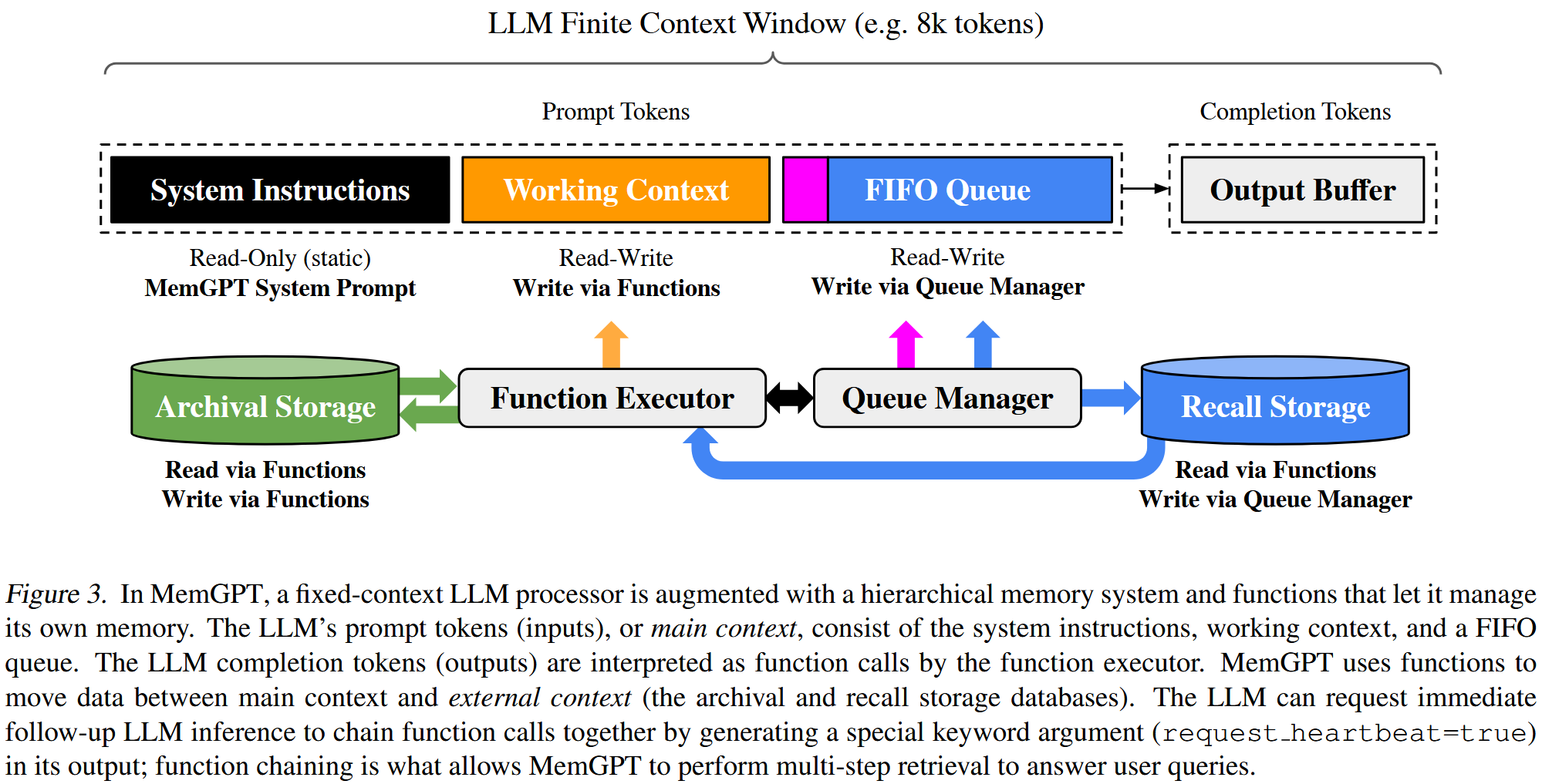
2. 方法
MemGPT的将LLM的上下文窗口视为一种宝贵且有限的资源,并赋予LLM通过“函数调用”(Function Calling)来自主管理这块“内存”的能力。
其架构包含两个主要层级:
-
主上下文 (Main Context / RAM): LLM的实际输入提示(prompt tokens)。它被划分为:
- 系统指令 (System Instructions): 静态的、只读的,定义了MemGPT的控制流、记忆层级用途及函数调用规范(如同OS内核指令)。
- 工作上下文 (Working Context): 固定大小的读写区域,用于存储LLM认为当前任务最关键的事实、状态、中间结论(如同CPU寄存器或高速缓存)。
- FIFO队列 (FIFO Queue): 滚动存储最近的对话历史、系统消息(如内存压力警告)、函数调用及返回结果(如同最近使用的页面缓存)。队首通常是一个对已移除消息的递归摘要。
-
外部上下文 (External Context / Disk): 存储在LLM上下文窗口之外的任何信息。
- 回忆存储 (Recall Storage): 存储完整的对话历史和事件。
- 档案存储 (Archival Storage): 存储更持久、可能更结构化的信息,如大型文档。


运作机制:
- 事件触发: 用户输入、系统警告(如主上下文接近上限,产生“内存压力”)或预设的定时事件会触发LLM进行推理。
- LLM决策与函数调用: LLM根据系统指令和当前上下文,决定是否需要以及如何管理其记忆。例如:
- 当FIFO队列过长,触发“内存压力”警告,LLM可以调用函数将队列中的重要信息存入“工作上下文”或“档案存储”。
- 当需要回忆过去的对话细节或查询文档时,LLM调用函数从“回忆存储”或“档案存储”中检索信息,并将其加载到“主上下文”中。
- 当“工作上下文”中的信息过时或不再相关,LLM可以更新或移除它们。
- 上下文更新与迭代: 函数执行的结果(包括成功信息或错误信息)会反馈给LLM,更新其主上下文,并可能触发后续的函数调用链(例如,分页查询)。这种反馈循环使LLM能从其行为中学习并调整策略。
这种设计使得LLM自身成为记忆管理的“调度员”,而非依赖外部固定逻辑。思想体现在对有限资源的优化分配,尽管本文未明确给出优化目标函数,但其行为模式隐含了最大化任务效用和最小化信息丢失的意图。
3. 优势
MemGPT 的优势在于其赋予 LLM 自主管理上下文的能力,而非依赖固定的上下文窗口或外部的启发式规则。
- 动态上下文管理: LLM 根据当前任务需求和内存状态,主动决定哪些信息保留在昂贵但快速的主上下文,哪些信息分页到廉价但慢速的外部上下文。这比固定长度上下文或简单的 RAG 中的固定数量检索块更为灵活和高效。
- “无限”上下文的错觉: 通过有效的换入换出机制,即使底层 LLM 的物理上下文窗口有限,MemGPT 也能处理远超此限制的信息量,实现类似操作系统提供的虚拟内存效果。
- 自我编辑与反思: LLM 可以通过函数调用修改其工作上下文中的信息,实现对自身知识和状态的更新和纠错,例如在对话中更新用户偏好或修正先前的事实。
- 与工具使用范式的自然融合: 函数调用是 LLM 作为智能体与外部世界交互的核心。MemGPT 将内存管理也纳入函数调用的框架,统一了 LLM 的能力接口。
- 可解释性与可控性: 通过观察 LLM 的函数调用序列,可以部分理解其“思考”过程和记忆管理策略。
4. 实验
在两个对长上下文有强需求的领域进行了评估:
-
长程对话 (Conversational Agents):
- 任务:
深度记忆检索 (Deep Memory Retrieval, DMR): 测试代理是否能回忆起早期对话中的特定细节。对话开启者 (Conversation Opener): 测试代理能否基于长期积累的用户信息生成个性化和引人入胜的开场白。
- 结果: 相比固定上下文的基线模型 (包括 GPT-4),MemGPT 在 DMR 任务上准确率和 ROUGE-L 分数均大幅领先。在对话开启任务上,MemGPT 生成的开场白与人类标注的黄金标准相似度更高。这表明 MemGPT 能有效维护和利用长期记忆。
- 任务:
-
文档分析 (Document Analysis):
- 任务:
多文档问答 (Multi-Document QA): 在多个文档中检索信息回答问题。嵌套键值检索 (Nested Key-Value Retrieval): 需要进行多步查找,一个键的值可能是另一个键,直至找到最终值。
- 结果: 在多文档问答中,随着文档数量增加,基线模型性能因上下文截断而下降,而 MemGPT 通过分页检索能保持稳定性能。在嵌套键值检索任务中,MemGPT (尤其基于 GPT-4) 能
完成多跳查找,显著优于基线模型。这证明了 MemGPT 在需要跨多个信息片段进行推理的任务中的优势。
- 任务:
- 关键发现:
- 性能很大程度上依赖于底层 LLM 的函数调用能力和遵循指令的准确性。GPT-4 作为底层模型时,效果远好于 GPT-3.5。
- 传统的上下文扩展方法 (如简单增加窗口长度) 即使能容纳更多信息,也可能因“大海捞针”问题导致性能下降。MemGPT 通过让 LLM 主动检索和聚焦相关信息,缓解了此问题。
5. 总结
-
核心贡献: 提出了一种由 LLM 自主管理的分层记忆系统,通过模拟操作系统的虚拟内存和分页机制,在固定物理上下文的限制下,赋予 LLM 处理和回忆远超其窗口容量信息的能力。这不仅仅是 RAG 的简单扩展,而是将 LLM 提升为认知资源的主动管理者。
-
数学视角: 其本质是将上下文窗口视为一种有限的、可管理的资源 C m a x C_{max} Cmax。LLM 的任务是在每个时间步 t t t 决定哪些信息片段 I k I_k Ik (来自历史、文档等) 应该被加载到 C t ⊆ C m a x C_t \subseteq C_{max} Ct⊆Cmax 中,以最大化任务效用函数 U ( C t , task ) U(C_t, \text{task}) U(Ct,task)。MemGPT 通过函数调用赋予 LLM 这种决策能力,而非依赖外部启发式算法。
-
与RAG的异同: MemGPT可以视为一种更智能、更主动的检索增强生成(RAG)。传统RAG通常在LLM调用前由外部逻辑完成检索,而MemGPT是LLM 自身 决定何时检索、检索什么、以及如何将检索结果整合进其工作记忆。
-
展望:
- LLM Agent 的基石: 对于需要长期记忆、持续学习和适应环境的自主智能体 (Agent),MemGPT 提供的记忆管理框架是至关重要的。它为构建更持久、更有状态的 LLM 应用奠定了基础。
- 从“模型”到“系统”: MemGPT 代表了从将 LLM 视为单纯的“模型”到将其视为复杂“信息处理系统”核心部件的转变。这预示着未来 LLM 的研究可能更多地借鉴系统工程、操作系统设计等领域的思想。
- 可解释性与控制性的新维度: 通过分析 LLM 的记忆管理决策 (即其函数调用序列),可以间接洞察其“注意力分配”和“知识组织”策略,为理解和控制 LLM 的行为提供了新的途径。
- 潜在的“元学习”: 未来的工作可以探索让 LLM 学习更优的内存管理策略,例如,通过强化学习使其能够根据任务类型和历史经验动态调整其分页、总结和遗忘行为。
-
局限:
- 当前实现依赖于 LLM 强大的函数调用和指令遵循能力,这对模型本身提出了较高要求。
- 内存操作 (尤其是与外部存储的交互) 会引入额外的延迟。
- 如何设计最优的系统指令 (prompt engineering for memory management) 仍是一个挑战。