并发编程 - go版
1.并发编程基础概念
进程和线程
A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发执行。
并发和并行
A. 多线程程序在一个核的cpu上运行,就是并发。B. 多线程程序在多个核的cpu上运行,就是并行。
并发
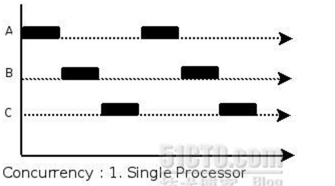
并行

goroutine 只是由官方实现的超级"线程池"。
每个实力4~5KB的栈内存占用和由于实现机制而大幅减少的创建和销毁开销是go高并发的根本原因。
进程:程序执行所用的内存空间。
线程:程序执行者。
协程:就是比线程更小的线程。(开销小、体量小)
并发:多线程程序执行, 但是吧cpu只有一个核,一段时间内,只能执行一个线程。
并行:多线程程序执行,cpu有多个核,每个核对不同程序的调用是可以同时进行的。
为什么说go支持并发?
1.因为 go 中的 goroutine(由go在语言层面实现的线程池 ):
我们在类似于java语言层面要实现线程,
1.1首先创建一个线程来执行任务;
1.2 线程池的存在,就是里面有一组可复用线程,我们直接把任务交给线程池,它帮我们选出空闲线程来执行。在这个层面上,go已经语言层面已经遥遥领先,如次,简化多线程程序开发。
2.以及协程: 一种比线程更小,可以被用户调度的线程。看协程的定义我们知道,创建一个协程所用的开销(创建、管理啥的)所用的内存是比线程更小。
3.还有就是其余编程语言并发模型是共享内存模型,比如java,线程通信通过共享内存实现的,我们无法保证操作是原子性的,因此需要设计同步机制,但是go通过channel来实现协程通信,就解决了如上问题。
因此,综上所述,说go默认支持高并发。
2.Goroutine
嗯,我们要在go语言启用协程是十分简单的。
原先。
func main() {hello()fmt.Println("main goroutine done")
}func hello() {fmt.Println("Hello Goroutine!")
}
把函数的执行交给协程来管理。
func main() {go hello()fmt.Println("main goroutine done")
}func hello() {fmt.Println("Hello Goroutine!")
}PS : go 关键字,必须跟着函数调用。
但是,我们发现实际调用时,go 关键字后面的hello程序并未执行,这是因为main函数的执行,也是由一个协程来执行的。当main函数结束时,main 协程也会结束,在里面执行的协程也会强制终结。可能hello 协程,刚创建还没执行就寄了。
因此,我们可以如下修改。延长main()函数的执行时间。
func main() {go hello()fmt.Println("main goroutine done")time.Sleep(time.Second)
}func hello() {fmt.Println("Hello Goroutine!")
}按照官方的说法,协程(goroutine)的调度是由GPM控制的。GPM是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
- 1.G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
- 2.P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等,当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
- 3.M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
因此,但从线程调度来讲,相比其他语言(如:Java),go可以使用户自己调度线程。
3.runtime包
runtime包提供和go运行时环境的互操作,如制go协程的函数。它也包括用于reflect包的低层次类型信息;参见reflect报的文档获取运行时类型系统的可编程接口。
runtime.Gosched()
Gosched使当前go协程放弃处理器,以让其它go程运行。暂时停止该go协程的处理。它不会终结当前go协程,因此当前go协程未来会恢复执行。
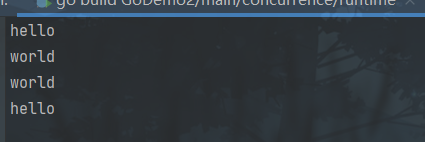
func main() {go func(s string) {for i := 0; i < 2; i++ {fmt.Println(s)}}("world")// 主协程for i := 0; i < 2; i++ {fmt.Println("hello")runtime.Gosched()}
}
当我们运行此代码时,执行一次 "hello"。之后中断主协程,执行其他协程。之后,再次执行该go协程。
runtime.Goexit()
Goexit终止调用它的go协程。其它go协程不会受影响。Goexit会在终止该go协程前执行所有defer的函数。在程序的main go协程调用本函数,会终结 main函数的go协程,而不会让main返回。因为main函数没有返回,程序会继续执行其它的go程。如果所有其它go协程都退出了,程序就会崩溃。
区别于,main函数执行完毕,main 协程结束。会自动终结函数内开启的所有协程。
func main() {go func() {defer fmt.Println("A.defer")func() {defer fmt.Println("B.defer")// 结束协程runtime.Goexit()defer fmt.Println("C.defer")fmt.Println("B")}()fmt.Println("A")}()for {}
}
runtime.GOMAXPROCS()
GOMAXPROCS设置可同时执行的最大CPU数,并返回先前的设置。 若 n < 1,它就不会更改当前设置。本地机器的逻辑CPU数可通过 NumCPU 查询。本函数在调度程序优化后会去掉。
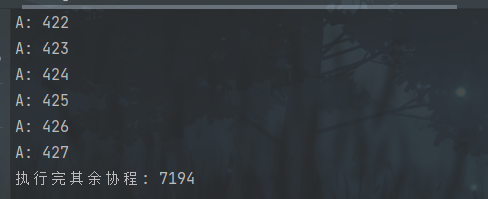
我们看下面代码: 用来验证并行。
当我们设置go程序并发时占用的cpu核数为1时。我们得出的时间纳秒差。
PS: 下面出现的差是不定的。
var atime int64
var btime int64func a() {for i := 1; i < 1000; i++ {fmt.Println("A:", i)}
}
func b() {for i := 1; i < 1000; i++ {fmt.Println("B:", i)}}func main() {runtime.GOMAXPROCS(1)atime = time.Now().UnixMicro() // 获取当前时间纳秒值go a()go b()runtime.Gosched()btime = time.Now().UnixMicro()fmt.Println(btime - atime)
}
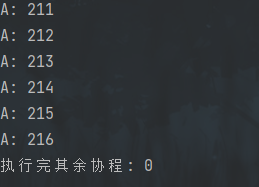
当我们,设置执行该程序的cpu核数为2时。执行时间,大概率是0或者是接近于0的数。
var atime int64
var btime int64func a() {for i := 1; i < 1000; i++ {fmt.Println("A:", i)}
}
func b() {for i := 1; i < 1000; i++ {fmt.Println("B:", i)}}func main() {runtime.GOMAXPROCS(2)atime = time.Now().UnixMicro()go a()go b()runtime.Gosched()btime = time.Now().UnixMicro()fmt.Println("执行完其余协程:", btime-atime)
}
4. channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
- channel: 在go中,用于协程之间的通信。
- 共享内存模型: 在共享内存模型中,多个线程可以访问和修改同一个变量或数据结构。由于线程是并发执行的,它们之间的执行顺序是不确定的。如果没有适当的同步机制来保证原子性和可见性,就有可能导致数据的不一致性和意料之外的结果。
- CSP模型: CSP 模型通过强调通过通信来共享数据,而不是直接共享内存,可以避免一些线程安全问题。
channel操作
通道创建、发送、接受、关闭通道。
// 声明通道,这时候,不能用的,需要make创建
var ch chan int// 创建指定大小的通道
ints := make(chan int,10)// 发送: 向ch通道发送10
ch <- 10 // 接受:接受来自ch通道的值
x := <-ch// 关闭通道
close(ch)关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
但是协程之间通道遍历取值,如果不关闭通道,遍历的时候会报异常而寄。
1.对一个关闭的通道再发送值就会导致panic。2.对一个关闭的通道进行接收会一直获取值直到通道为空。3.对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。4.关闭一个已经关闭的通道会导致panic。无缓冲的通道
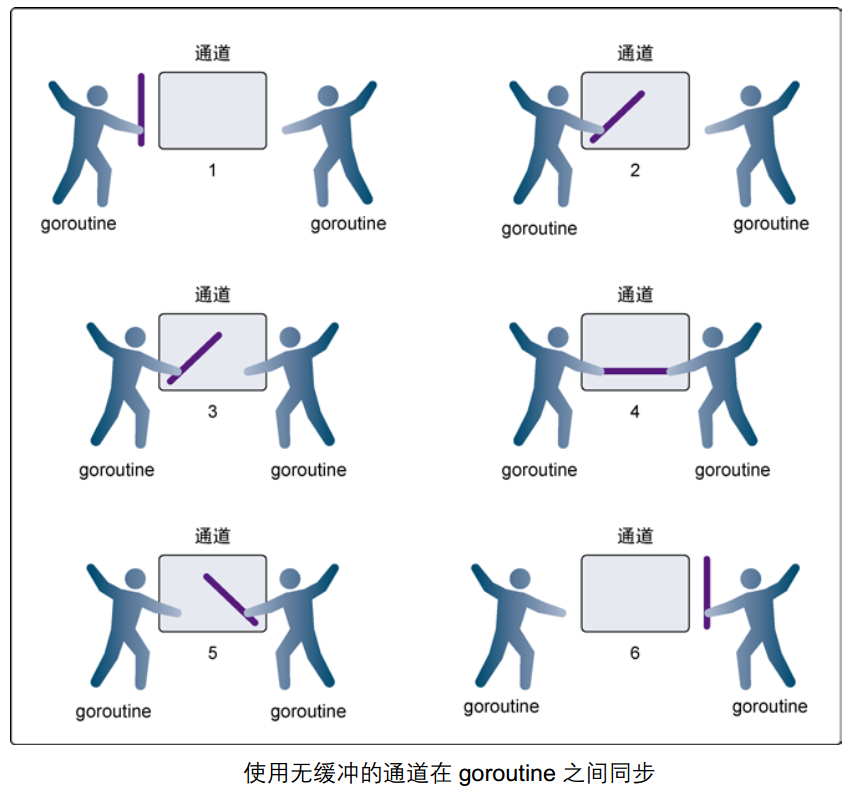
无缓冲通道又称为被阻塞的通道。
func main() {ch := make(chan int)ch <- 10fmt.Println("发送成功")
}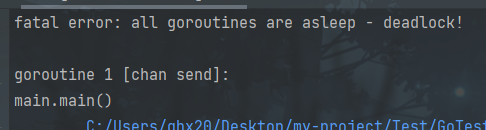
至于为什么执行上面代码,会报这个错误,原因在于,ch := make(chan int),创建是个无缓冲通道。而,
无缓冲通道的发送操作会被阻塞,直到另一个协程在给通道上执行接受操作,这时值才能发送成功。
使用无缓冲通道操作进行通信时将导致发送和接受的协程同步化。(无缓冲通道使用时,有发送,就必须有接受)。因此,无缓冲通道也被称为同步通道。
这个,无缓冲通道说白了,没有实际存储容量,就像快递员一样,接受了快递(数据),必须要送到接受者手里。到最后,不能自己持有。
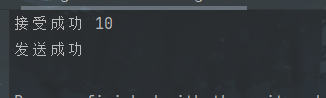
func main() {ch := make(chan int)go recv(ch)ch <- 10fmt.Println("发送成功")
}func recv(c chan int) {recvData := <-cfmt.Println("接受成功", recvData)
}
有缓冲通道
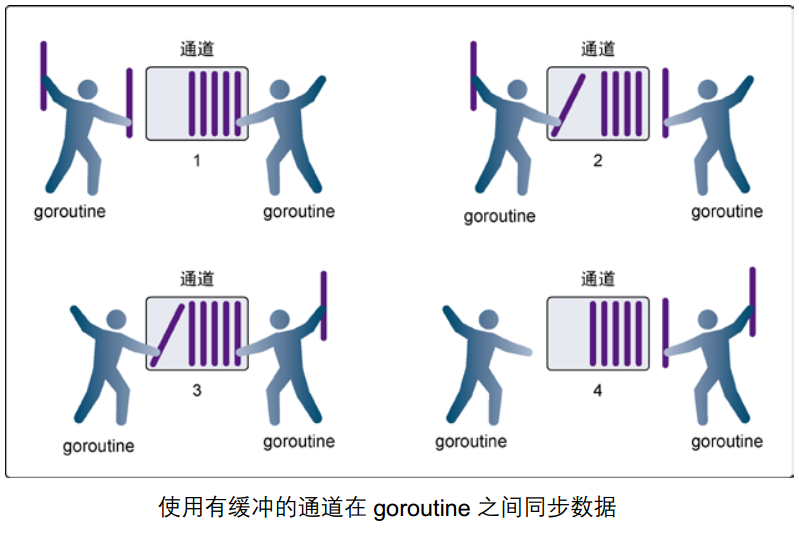
顾名思义,对比无缓冲通道创建时,是有实际存储值的。就像快递柜一样。快递员把快递放到快递柜里,但是接受者,还没拿到(但这个过程没有阻塞)。假如,当有下个快递来临时(假如,快递柜只有1个位置) 。那么,没有人接受,快递柜没位置会再次阻塞。
我们可以通过使用make创建通道时,指定容量,就是有缓冲的通道。
func main() {ch := make(chan int, 1) // 创建一个容量为1的有缓冲区通道ch <- 10fmt.Println("发送成功")
}func main() {ints := make(chan int, 5)ints <- 1fmt.Println(len(ints), cap(ints)) // 1 5
}只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。
我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
看到这,嗯,channel 专门用于协程之间通信,就是一个临时的容器,当容器,为0时,你可以往里面输入元素,但是要接着有输出;当容量大于0时,你可以往里面存储东西,这时候不用输出,但是达到channel 容量顶峰时,你在想存入,必须把之前存入的输出。
close()
close关闭通道,下次取值变为0,false
func main() {ch := make(chan int)go recv(ch)ch <- 10fmt.Println("发送成功")
}func recv(c chan int) {recvData := <-cfmt.Println("接受成功", recvData)close(c)data, ok := <-cfmt.Println(data, ok)
}
从通道遍历取值
func main() {var ch1 = make(chan int)go func() {for i := 0; i < 10000; i++ {ch1 <- ifmt.Println("B send", i)}close(ch1)}()for i := range ch1 {fmt.Println("B recv", i)}}
单向通道
func main() {ch1 := make(chan int)go counter(ch1)printer(ch1)
}func counter(out chan<- int) { // 只能发送for i := 0; i < 100; i++ {out <- i * i}close(out)
}func printer(in <-chan int) { // 只能接受for i := range in {fmt.Println(i)}
}