论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
摘要翻译
自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。相比之下,端到端自动驾驶系统因其完全数据驱动的训练过程有望避免误差累积,但其 “黑箱” 特性往往导致透明度不足,使得决策的验证和追溯复杂化。最近,大型语言模型(LLMs)已展现出上下文理解、逻辑推理和生成答案等能力。一个自然的想法是利用这些能力为自动驾驶赋能。通过将 LLM 与基础视觉模型相结合,有望实现当前自动驾驶系统所缺乏的开放世界理解、推理和小样本学习能力。本文系统综述了用于自动驾驶的(视觉)大型语言模型((V) LLM4Drive)的研究路线,评估了当前的技术进展状态,明确概述了该领域的主要挑战和未来方向。为了方便学术界和工业界的研究人员,我们通过指定链接(GitHub - Thinklab-SJTU/Awesome-LLM4AD)提供该领域最新进展的实时更新以及相关开源资源。
总结
1. 背景
- 传统模块化系统:由感知、预测、规划等独立模块组成,虽在多种场景中提供可靠性和安全性,但存在信息丢失、计算冗余和模块间误差累积等问题。
- 端到端系统:通过消除模块间的集成误差和减少冗余计算,增强了视觉和感官信息的表达,但决策过程缺乏透明度(“黑箱” 问题),解释和验证困难。
- LLMs 的潜力:凭借强大的上下文理解、推理和生成能力,结合多模态模型(如图像、文本、点云等),可提升系统的泛化能力,支持零 / 小样本学习,有望解决自动驾驶的长尾问题并提供决策解释。
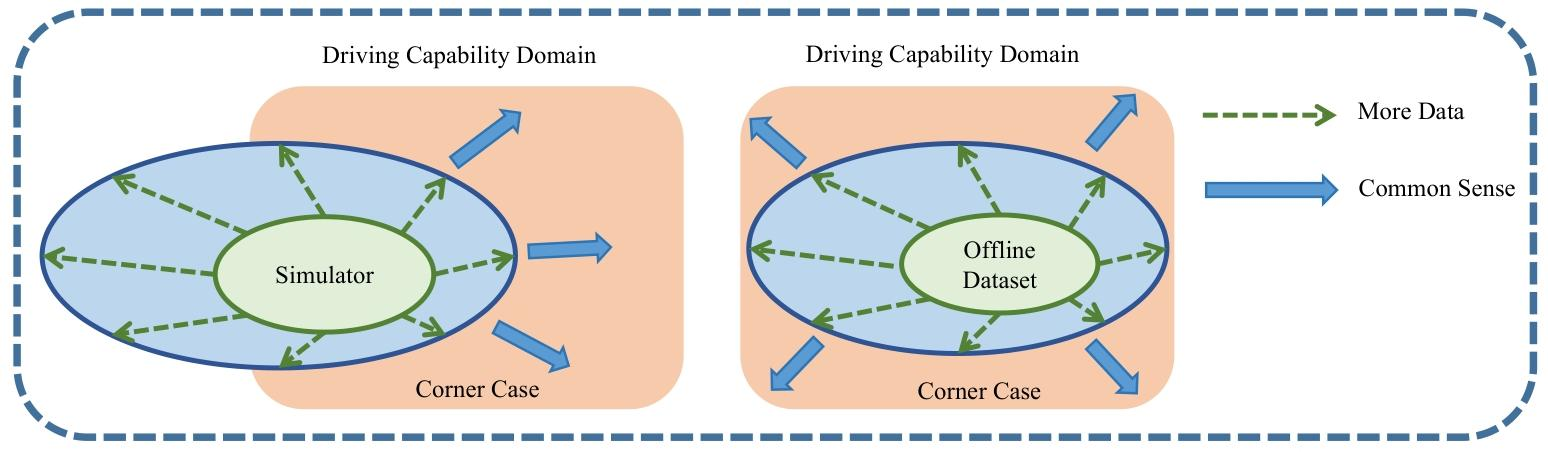
2. 动机
- 数据与仿真的局限性:传统方法依赖大量数据和仿真,但仿真与现实存在差距(sim2real gap),且离线数据难以覆盖自动驾驶的长尾场景。
- LLMs 的补充作用:利用 LLMs 内置的常识知识,可缩小数据缺口,提升系统在复杂场景下的推理能力,推动自动驾驶向人类专家水平靠近。
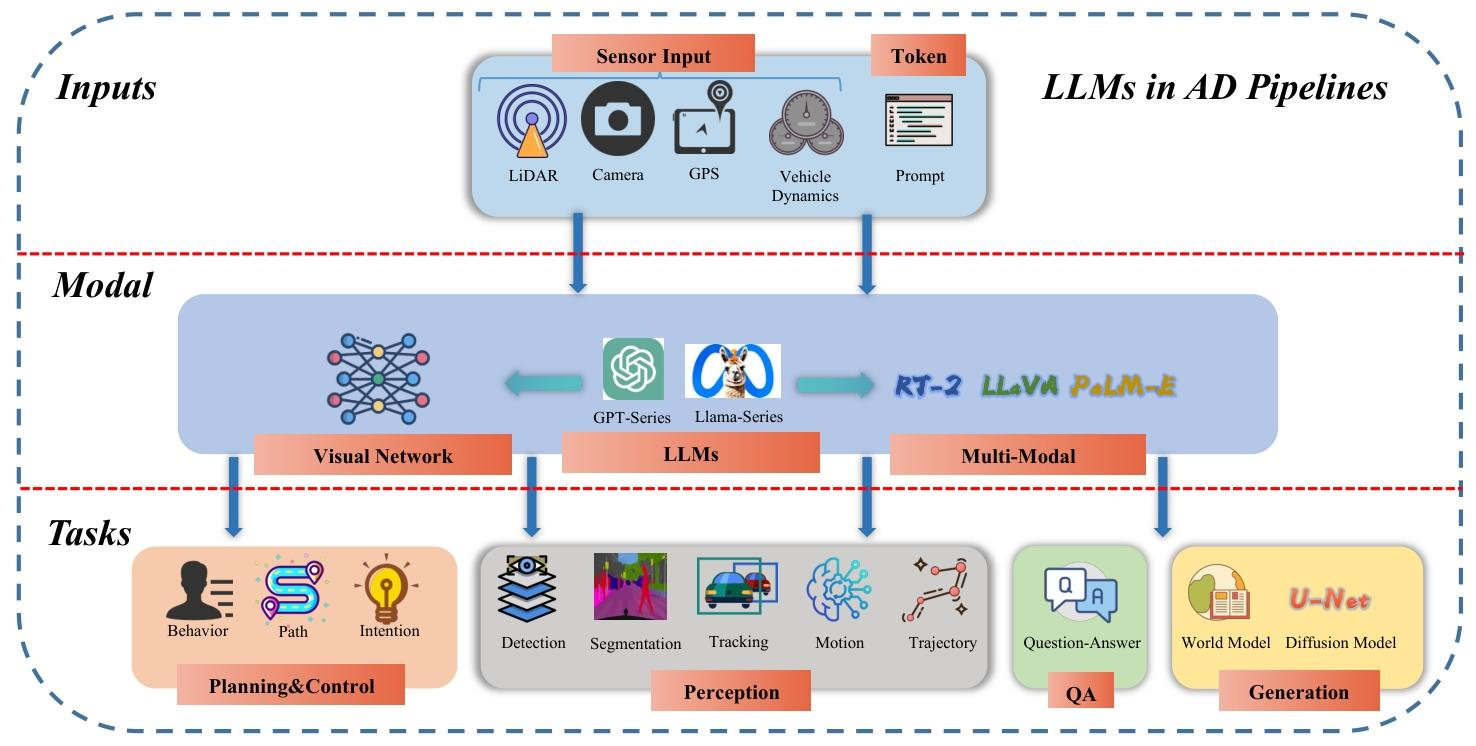
3. 应用场景
- 规划与控制
- 微调预训练模型:如 MTDGPT 将多任务决策转化为序列建模问题;DriveGPT4 基于多模态 LLM 生成控制信号并解释决策。
- 提示工程:如 DiLu 通过记忆模块和 LLM 推理实现闭环驾驶;SurrealDriver 利用人类驾驶行为描述作为提示开发 “教练代理”。
- 感知:LLMs 通过跨模态特征融合(如 PromptTrack 的语言提示与 3D 检测结合)或提示推理(如 HiLM-D 的风险目标定位)提升感知能力,尤其在数据稀缺场景下表现突出。
- 问答(QA):涵盖传统 QA(如 Tang 等人的领域知识蒸馏)和视觉 QA(如 DriveLM 的图结构推理),支持实时场景理解和用户交互。
- 生成:利用扩散模型(如 DriveDreamer、DrivingDiffusion)生成驾驶视频、交通场景或轨迹,用于数据增强和场景仿真,降低数据收集成本。
4. 数据集与评估基准
- 数据集:如 BDD-X、NuScenes-QA、LingoQA 等,提供多模态标注(文本描述、QA 对、3D 边界框等),支持 LLMs 在自动驾驶中的训练和评估。
- 评估基准:包括 LangAuto(CARLA-based)、LingoQA、DriveSim 等,覆盖场景理解、决策逻辑、安全性等多维度评估。
5. 挑战与未来方向
- 挑战:计算效率(LLMs 推理时间长)、实时性要求、可解释性不足、数据质量(标注成本高)、安全性(对抗攻击)和伦理问题(隐私、偏见)。
- 未来方向:轻量级 LLMs 优化、多模态融合(视觉 - 语言 - 传感器)、边缘计算部署、标准化评估指标、安全对齐(如形式化验证)和伦理框架建设。
一、相关技术方法
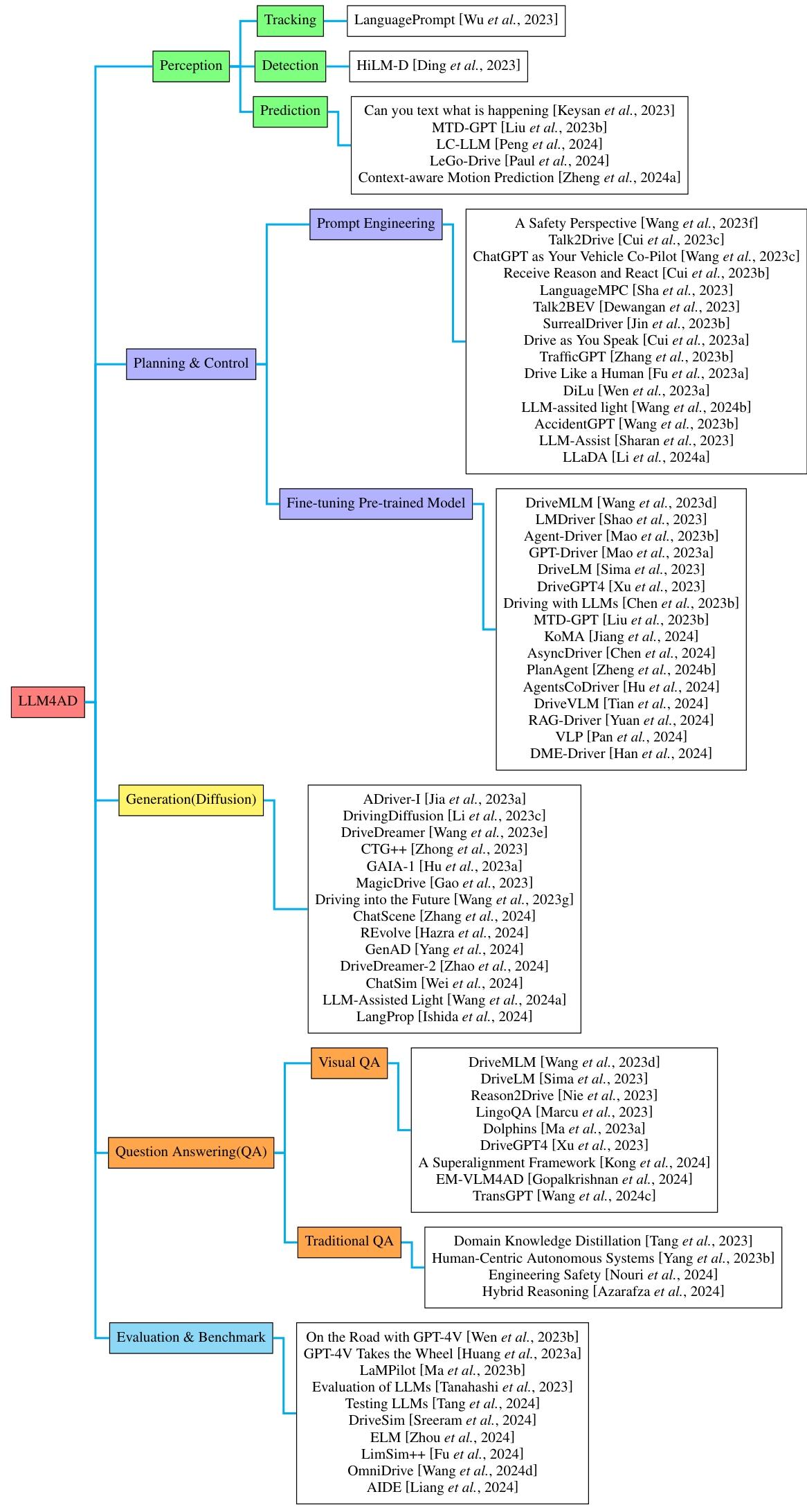
1. 规划与控制方法
- 微调预训练模型
- 核心思路:在预训练 LLMs 基础上,针对驾驶场景(如无信号交叉口决策、轨迹预测)进行微调,将驾驶任务转化为序列建模或语言生成问题。
- 代表方法:MTDGPT 通过混合多任务数据集训练处理复杂决策;Agent-Driver 引入工具库和认知记忆增强推理;RAG-Driver 结合检索增强上下文学习,实现可解释的端到端驾驶。
- 提示工程
- 核心思路:通过设计特定提示(如 “思维链”、安全准则)激活 LLMs 的推理能力,无需大规模训练。
- 代表方法:DiLu 利用记忆模块记录经验,通过多轮 QA 实现推理和反思;TrafficGPT 融合 ChatGPT 与交通基础模型,处理复杂交通问题;LanguageMPC 将 LLMs 与低级控制器结合,通过参数矩阵适应优化控制。
2. 感知方法
- 跨模态融合:如 PromptTrack 将语言提示作为语义线索,融合到 3D 检测和跟踪任务中;LC-LLM 利用 LLMs 理解复杂场景,提升车道变更预测的可解释性。
- 提示推理:如 HiLM-D 将高分辨率视觉信息输入多模态 LLMs,实现风险目标定位和意图预测;Context-aware Motion Prediction 结合 GPT-4V 的场景描述与传统模型,增强运动预测准确性。
3. 问答与生成方法
- 问答
- 传统 QA:通过 “聊天” 与 LLMs 构建领域知识本体(如 Tang 等人的交通规则蒸馏),支持实时交互和干预。
- 视觉 QA:如 DriveMLM 利用多视图图像和点云生成高层决策命令;EM-VLM4AD 设计轻量级多帧视觉语言模型,提升问答效率。
- 生成
- 扩散模型:如 DriveDreamer 基于文本、图像和 HD 地图生成驾驶视频;CTG++ 通过 LLMs 将用户查询转化为损失函数,驱动扩散模型生成可控交通场景。
- 场景仿真:ChatScene 利用 LLMs 生成安全关键场景,提升自动驾驶系统的鲁棒性;GenAD 利用网络数据和时间推理块,实现零样本场景泛化。
4. 评估与基准
- 仿真环境:如 CARLA、nuPlan、HighwayEnv,用于测试 LLMs 在闭环驾驶中的性能(如碰撞率、轨迹拟合度)。
- 指标体系:涵盖传统指标(如 L2 误差、mAP)和语言评估指标(如 BLEU-4、ChatGPT 评分),但缺乏统一标准,需进一步标准化。
二、评价指标
1. 传统指标
- 规划与控制:轨迹跟踪误差(RMSE)、碰撞率、速度方差(SV)、时间效率(TE)。
- 感知:mAP(平均精度均值)、3D检测准确率、目标定位误差(L2误差)。
2. 语言与多模态指标
- 问答:BLEU-4、METEOR、CIDEr、SPICE(用于评估生成文本的语义准确性)。
- 生成:FID(Fréchet Inception Distance)、CLIP分数(用于评估生成图像/视频的质量)。
3. 综合指标
- 实时性:推理速度(如LLM-MPC在Jetson Orin上5.52秒/次)、控制频率(如MPC保持20Hz)。
- 安全性:碰撞时间(TTC)、违规处罚(IP)、形式化验证通过率。
三、数据集

四、亟待解决的核心问题
1. 计算效率与实时性瓶颈
- 挑战:LLM推理延迟高(如GPT-4V在复杂场景中需数秒),难以满足自动驾驶20Hz以上的控制频率需求。
- 解决方案:
- 异步架构:如AsyncDriver将LLM推理与实时规划解耦,通过低频率高层决策指导高频控制。
- 模型压缩:结合量化(如INT8量化)和知识蒸馏(如CoT-Drive),在保持性能的同时减少计算量。
2. 多模态融合的动态适应性
- 挑战:静态融合方法无法应对数据分布变化(如传感器故障、极端天气),导致性能下降。
- 解决方案:
- 动态融合机制:如DynMM通过门控函数动态选择模态组合,QMF利用不确定性估计实现质量感知融合。
- 跨模态对齐:如3D MLLM架构通过稀疏查询统一视觉与语言的3D表示,提升场景理解一致性。
3. 数据质量问题
- 挑战:合成数据的真实性不足(如纹理、物理特性差异),导致模型在真实场景中泛化能力弱。
- 解决方案:
- 生成式仿真优化:如ChatSim结合神经渲染与扩散模型,提升场景的视觉和物理真实性。
- 域适应技术:通过对抗训练(如CycleGAN)或元学习,缩小合成数据与真实数据的分布差异。
4. 可解释性与安全验证
- 挑战:LLM的“黑箱”特性导致决策逻辑难以追溯,且存在幻觉问题(如错误识别障碍物)。
- 解决方案:
- 可解释性增强:如DriveGPT4通过自然语言生成决策依据,GenFollower结合思维链(CoT)提示输出显式推理过程。
- 形式化验证:如Hybrid Reasoning框架将LLM决策与传统控制器结合,通过逻辑推理验证安全性。
5. 伦理与社会接受度
- 挑战:自动驾驶系统的决策可能引发伦理争议(如紧急避险时的优先级选择),且用户对AI驾驶的信任度不足。
- 解决方案:
- 伦理框架设计:建立多利益相关方参与的评估体系,如SurrealDriver通过人类用户实验评估驾驶行为的人性化程度。
- 透明交互界面:如Tang等人的领域知识蒸馏系统,通过实时问答增强用户对系统的理解与控制。