Python----目标检测(yolov5-7.0安装及训练细胞)
一、下载项目代码
yolov5代码源
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
yolov5-7.0代码源
Release v7.0 - YOLOv5 SOTA Realtime Instance Segmentation · ultralytics/yolov5 · GitHub
二、创建虚拟环境
创建一个3.8版本的环境
conda create -n yolov5-7.0 python=3.8激活环境
conda activate yolov5-7.0安装环境
pip install -r requirements.txt使用GPU训练
import torchprint(torch.__version__)
print(torch.cuda.is_available())pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118pip install psutil PyYAML requests scipy thop tqdm pandas seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
三、准备数据集

data_cell/
├── train/
│ ├── images/ # 存放训练图片
│ └── labels/ # 存放训练标签
├── valid/
│ ├── images/ # 存放验证图片
│ └── labels/ # 存放验证标签
├── test/
│ ├── images/ # 存放测试图片
│ └── labels/ # 存放测试标签
├── data.yaml # 配置文件
│
└── custom_yolov5s.yaml修改data .yaml 修改路径为绝对路径
train: /home/YoloV_/yolov5-7.0/data_cell/train/images
val: /home/YoloV_/yolov5-7.0/data_cell/valid/imagesnc: 3
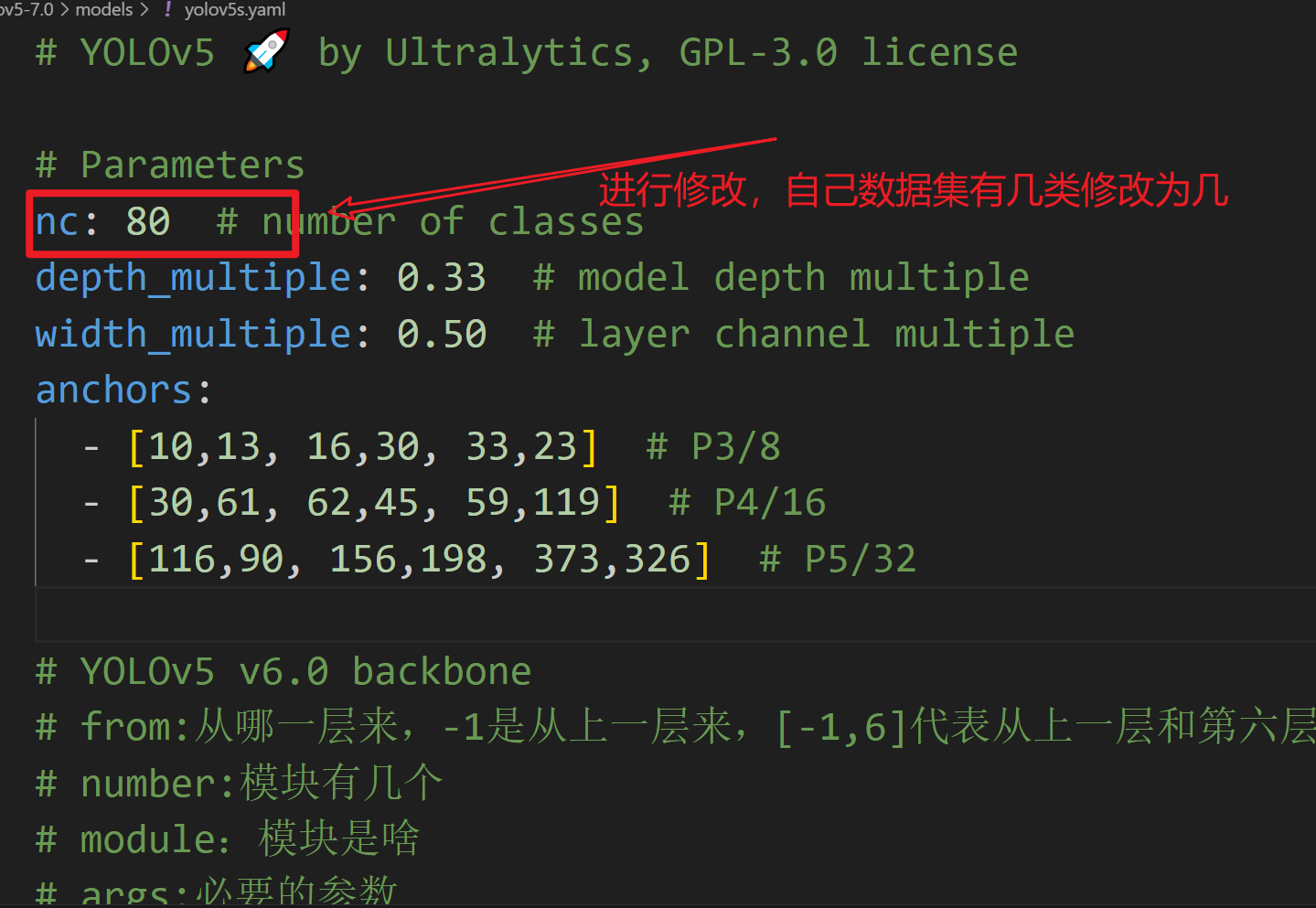
names: ['Platelets', 'RBC', 'WBC']关于模型的配置文件 custom_yolov5s.yaml,这个文件可以从 项目models文件夹中拷贝一份修改即可
四、运行训练脚本
建议在终端运行,也可以在train.py运行,但需要进行修改
python train.py --weights yolov5s.pt --data ./data_cell/data.yaml --epochs 300 --batch-size 16| 参数 | 说明 | 推荐值/示例 | 注意事项 |
|---|---|---|---|
--img | 输入图片的尺寸(宽度和高度) | 640(默认) | 必须是 32 的倍数(如 320, 416, 640),更大的尺寸会提高精度但增加计算负担。 |
--batch | 每个批次的样本数(batch size) | 16(取决于 GPU 显存) | 显存不足时减小(如 4/8),可用 --batch-size 或 -b 指定。 |
--epochs | 训练的总轮次(所有数据训练一遍为一轮) | 100(小数据集可 300+) | 轮次太少可能欠拟合,太多可能过拟合,需观察 val_loss 变化。 |
--data | 数据集配置文件的路径(.yaml 文件) | data/custom.yaml | 文件需包含 train/val 路径和类别信息(nc、names)。 |
--cfg | 模型结构配置文件(如 yolov5s.yaml) | models/yolov5s.yaml | 如果使用预训练权重(--weights),此参数可省略(自动匹配模型结构)。 |
--name | 训练结果的保存目录名称(默认 exp,后续会递增 exp2, exp3) | --name my_train | 结果保存在 runs/train/<name> 下。 |
--weights | 初始化权重文件路径(.pt 文件) | yolov5s.pt(预训练) | 不指定时默认从头训练;推荐用预训练权重加速收敛(如 --weights yolov5s.pt)。 |
--nosave | 仅保存最终的模型(last.pt 和 best.pt),不保存中间 checkpoint | --nosave | 节省磁盘空间,但无法从中间轮次恢复训练。 |
--cache | 缓存数据集到内存或磁盘(ram/disk)以加速训练 | --cache ram | 需要足够的内存或磁盘空间,小数据集推荐 ram,大数据集用 disk 或关闭(默认 None)。 |
--device | 指定训练设备(GPU/CPU) | --device 0(GPU 0) | 多 GPU 用逗号分隔(如 --device 0,1),CPU 训练用 --device cpu。 |
--workers | 数据加载的线程数(Dataloader workers) | 8(根据 CPU 核心数调整) | 线程过多可能导致内存溢出,Linux 下可设更高(如 16),Windows 建议 ≤8。 |
--hyp | 超参数配置文件路径(如学习率、数据增强等) | data/hyps/hyp.scratch-low.yaml | 修改超参数需谨慎,新手建议用默认文件。 |
--resume | 从之前的训练中断处继续(需指定 last.pt 路径) | --resume runs/train/exp/weights/last.pt | 会自动加载优化器状态和轮次信息。 |
--evolve | 启用超参数进化(自动优化超参数) | --evolve 300(迭代 300 次) | 计算成本高,适合大型项目或调优阶段。 |
--single-cls | 将所有类别视为单一类别(适用于二分类问题) | --single-cls | 标注文件中的类别 ID 会被强制设为 0。 |
| 模型 | 参数量 | 速度 | 精度 |
|---|---|---|---|
yolov5n | 1.9M | ⚡ 最快 | 低 |
yolov5s | 7.2M | 快 | 中 |
yolov5m | 21.2M | 中等 | 较高 |
yolov5l | 46.5M | 较慢 | 高 |
yolov5x | 86.7M | 🐢 最慢 | 最高 |
五、模型验证
在模型训练过程中就会进行模型验证,如果愿意也可以输入指令再次验证
python val.py --weights ./runs/train/exp/weights/best.pt --data ./data_cell/data.yaml 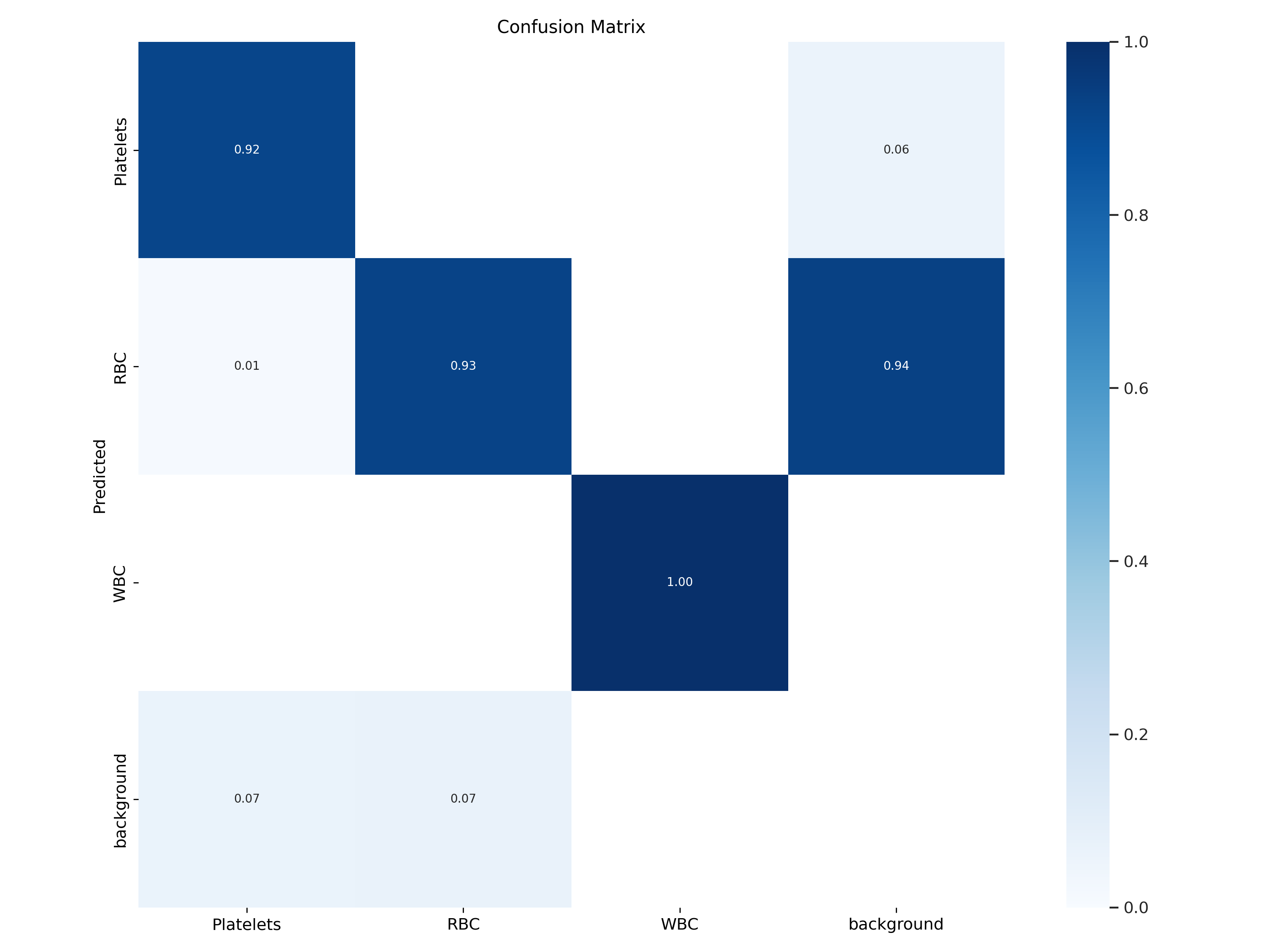
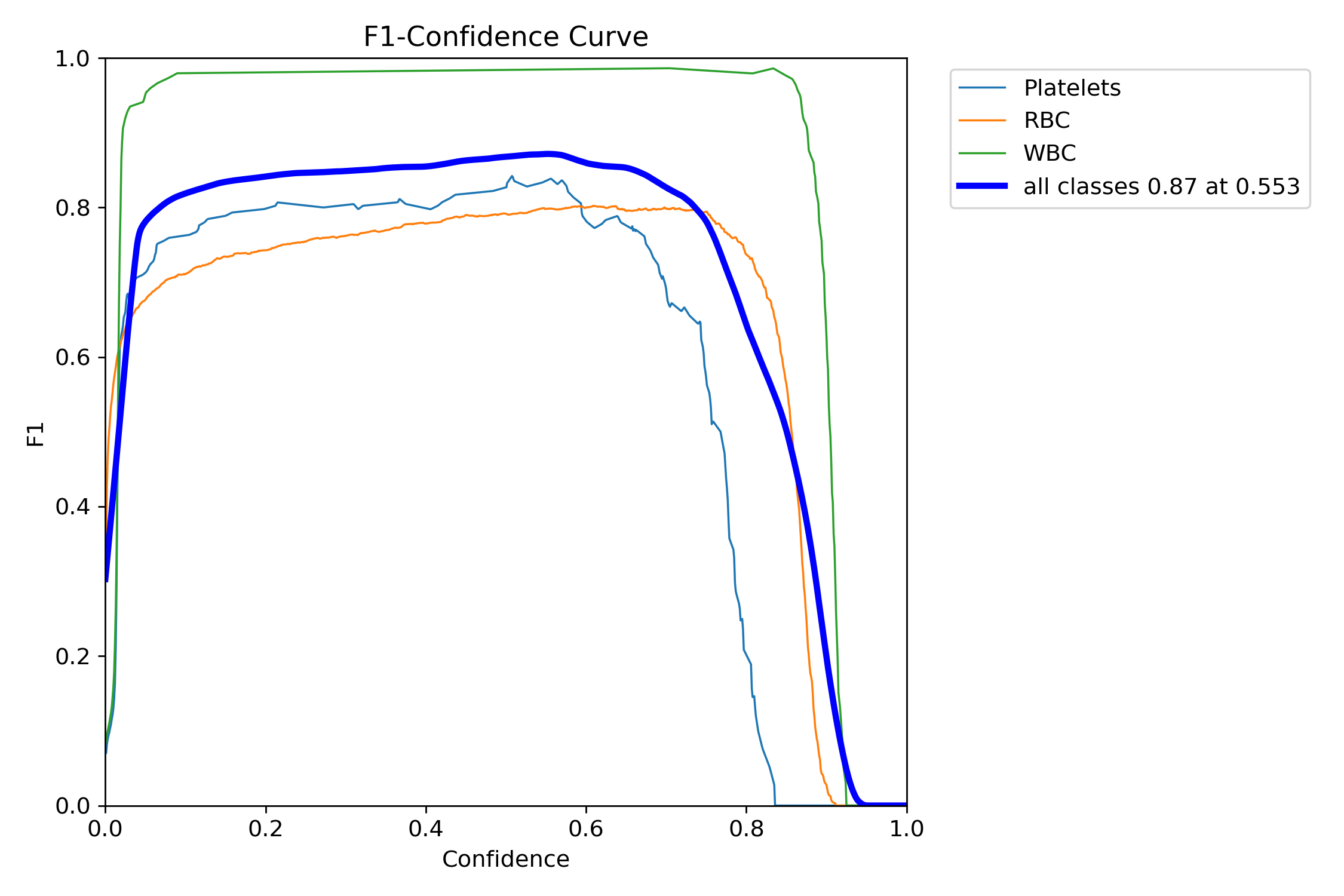
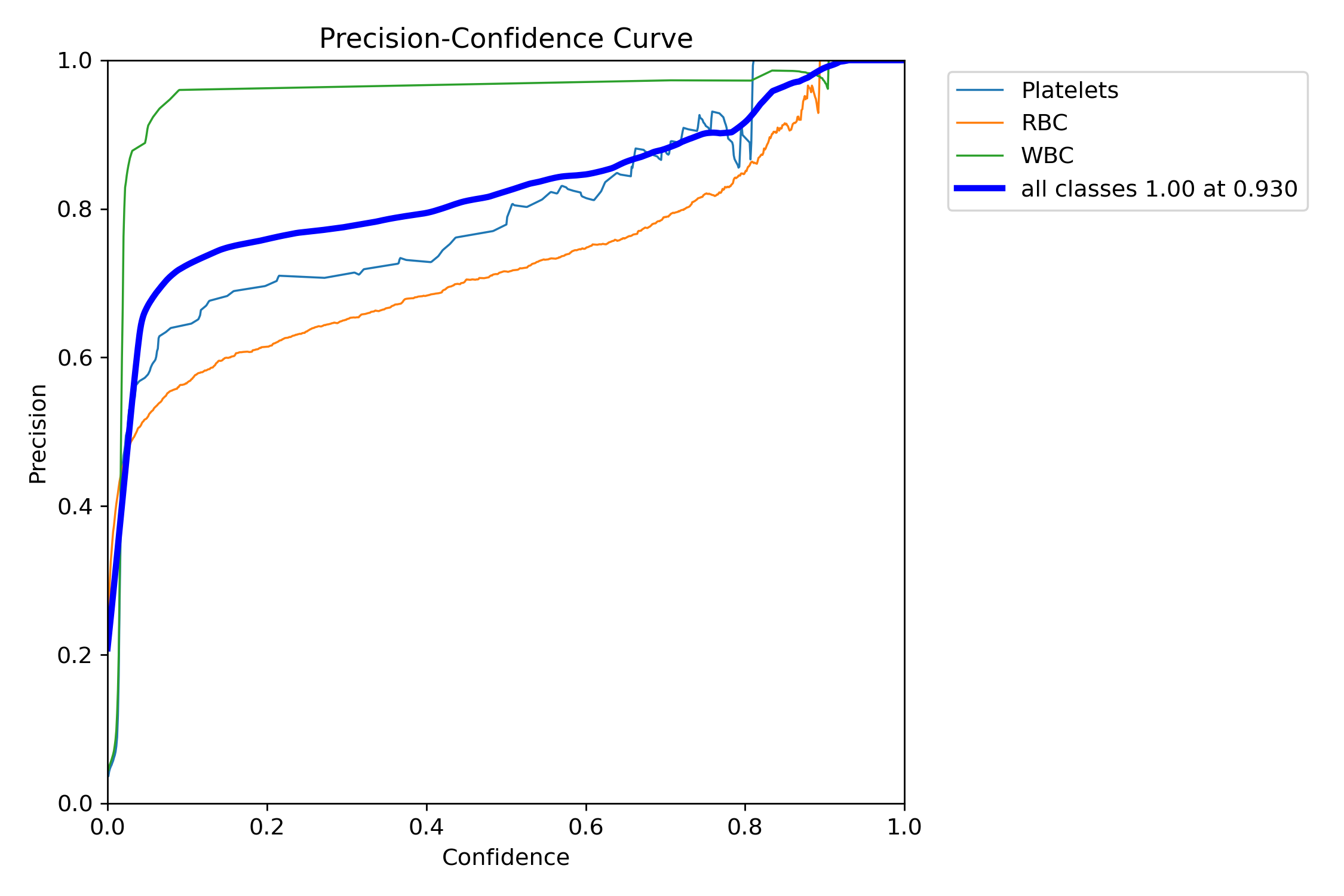
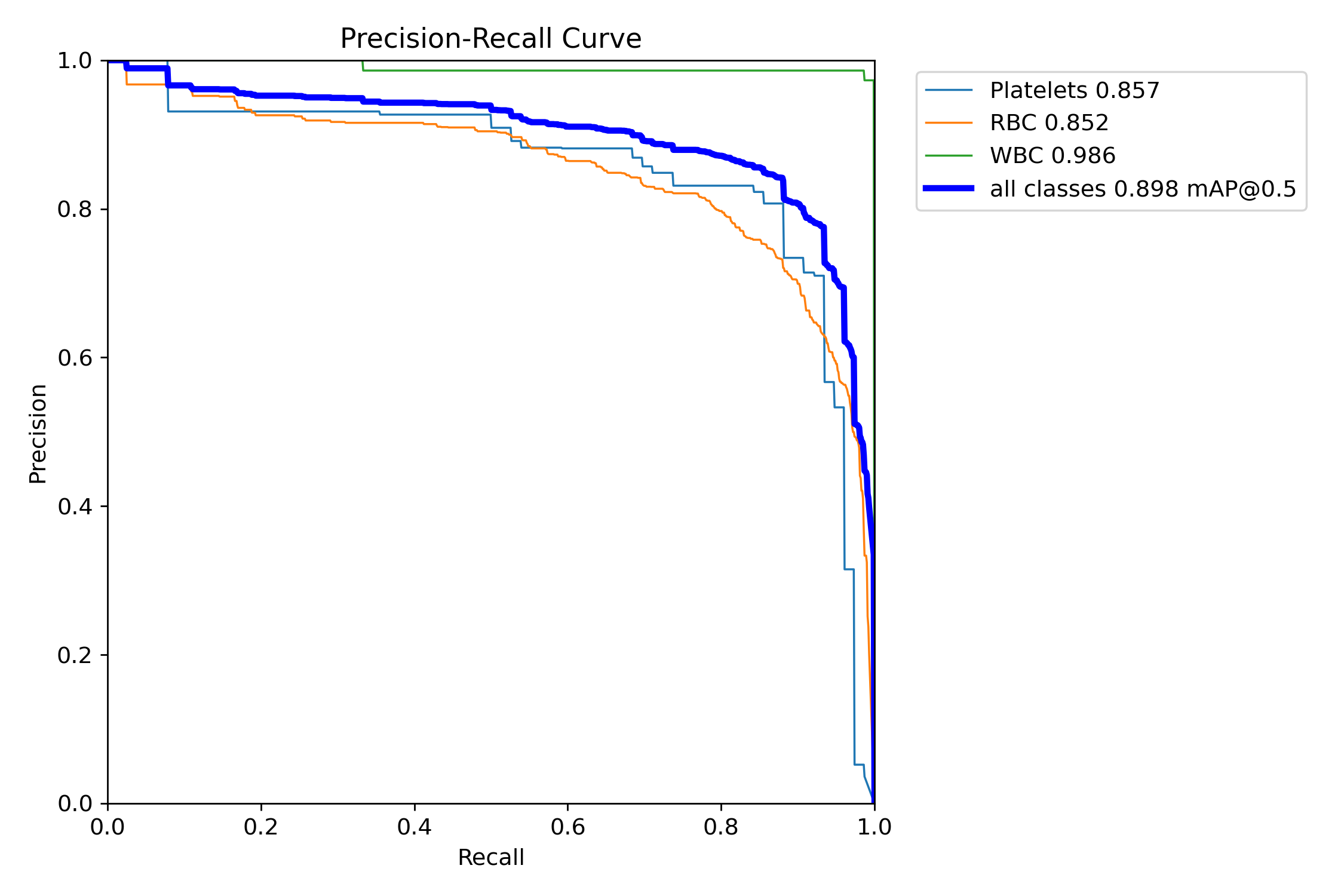
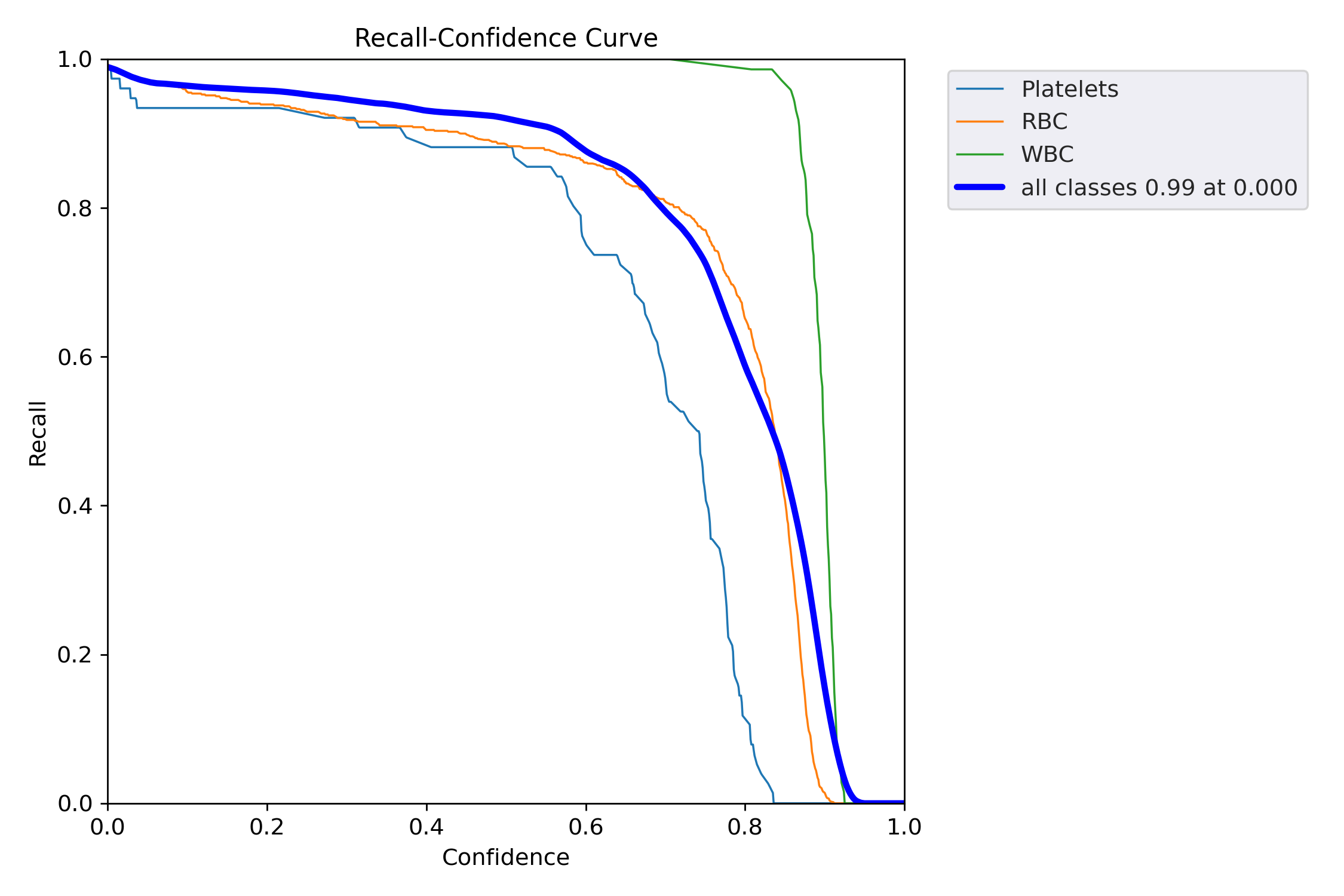

六、模型预测
python detect.py --weights ./runs/train/exp/weights/best.pt --source ./data_cell/test/images/



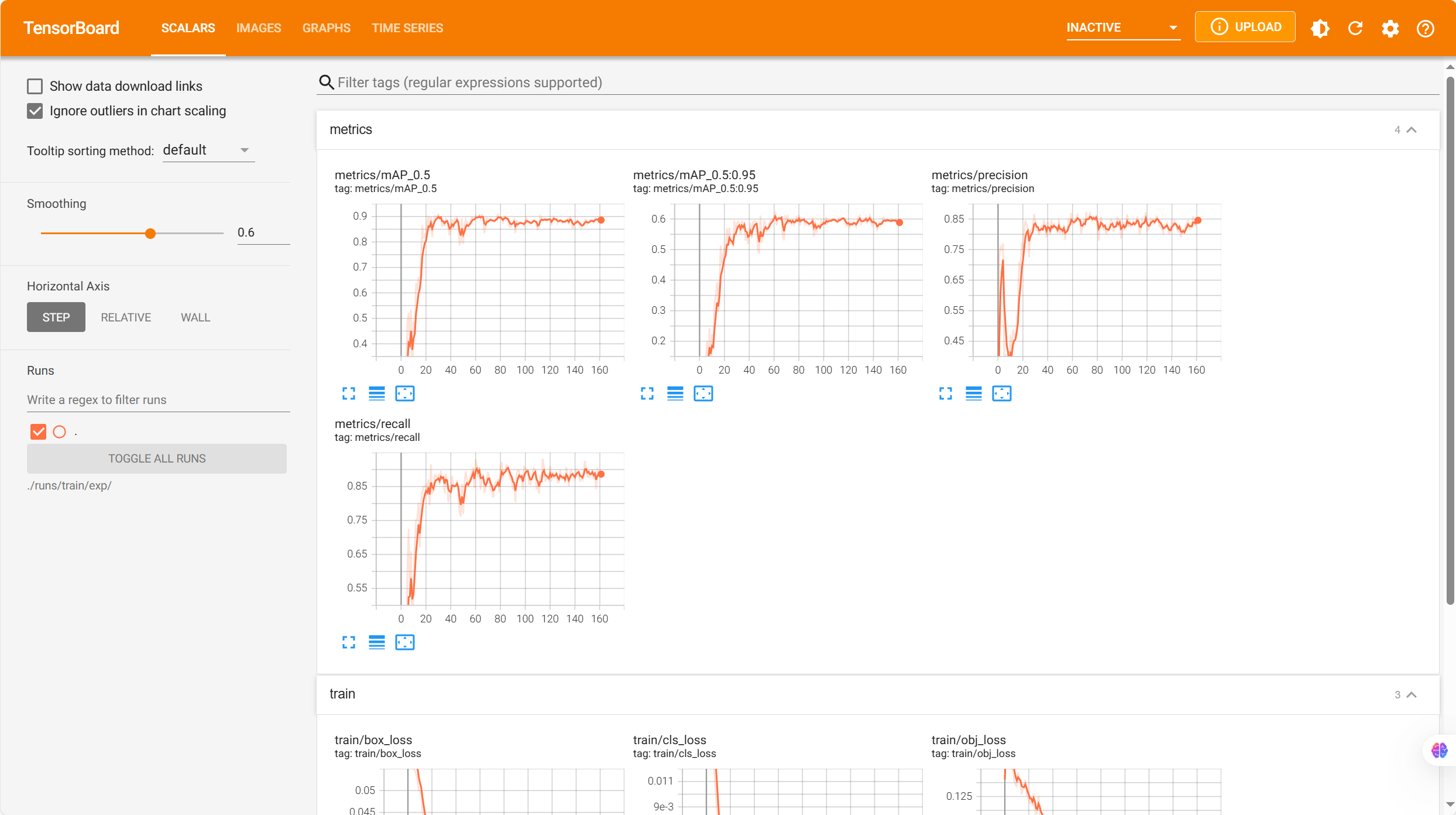
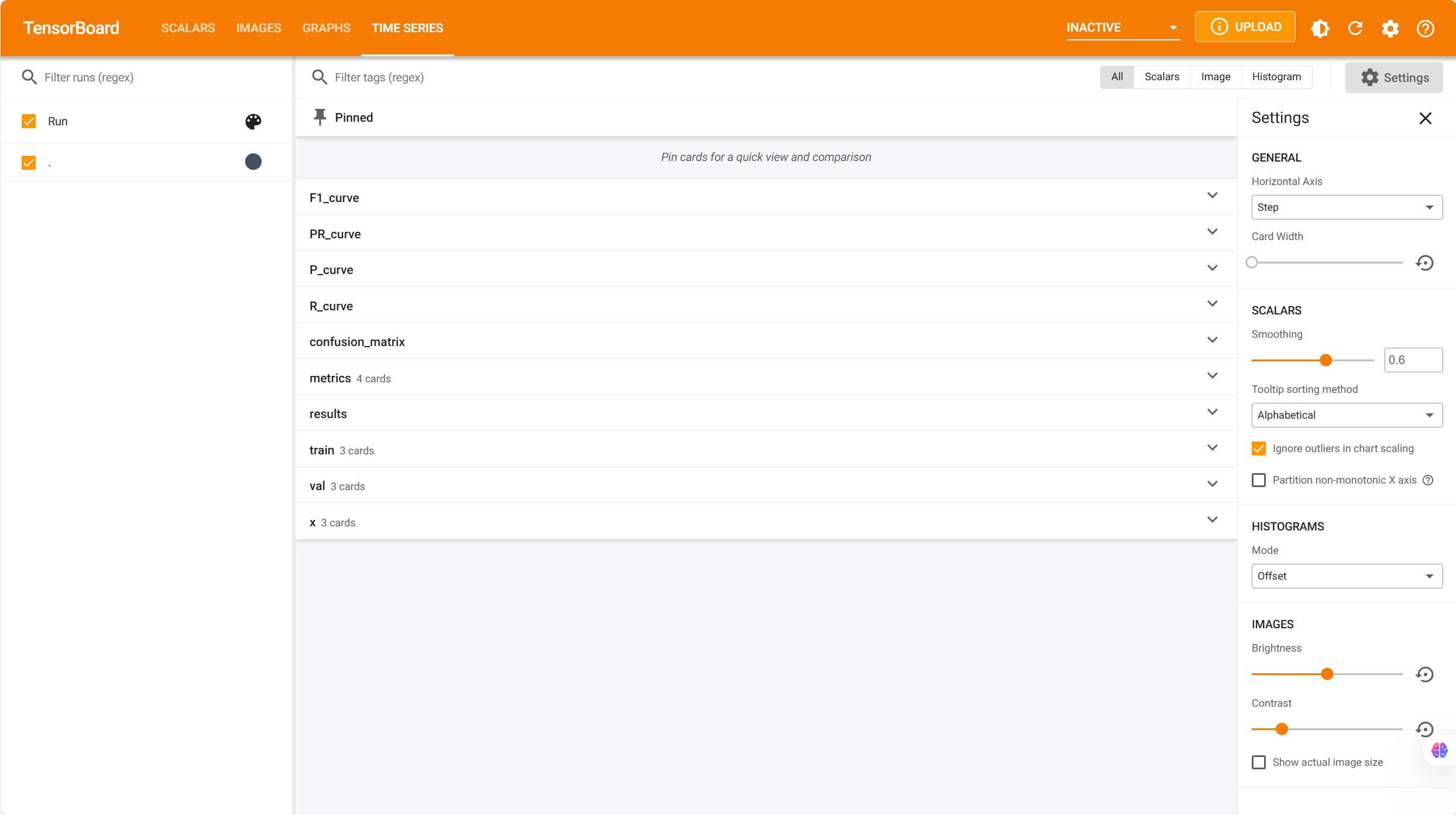
七、TensorBoard 可视化
tensorboard --logdir=./runs/train/exp/