day21 常见的降维算法
特征降维
通常情况下,我们提到特征降维,很多时候默认指的是无监督降维,这种方法只需要特征数据本身。但是实际上还包含一种有监督降维。
1.无监督降维(Unsupervised Dimensionality Reduction)
- 定义:这类算法在降维过程中不使用任何关于数据样本的标签信息(比如类别标签、目标值等)。它们仅仅根据数据点本身的分布、方差、相关性、局部结构等特性来寻找低维表示。
- 输入:只有特征矩阵 X。
- 目标:
· 保留数据中尽可能多的方差(如PCA)。
· 保留数据的局部或全局流形结构(如LLE,Isomap,t-SNE,UMAP)。
· 找到能够有效重构原始数据的紧凑表示(如Autoencoder)。
· 找到统计上独立的成分(如ICA)。
- 典型算法:
· PCA(Principal Component Analysis)/SVD(Singular Value Decomposition)
· t-SNE(t-distributed Stochastic Neighbor Embedding)
· UMAP(Uniform Manifold Approxiamtion and Projection)
· LLE(Locally Linear Embedding)
· Isomap(Isometric Mapping)
· Autoencoders(基本形式)
· ICA(Independent Component Analysis)
- “只要特征就可以对特征降维了”:这句话描述的就是无监督降维。算法通过分析特征间的关系和分布来进行降维。
2.有监督降维(Supervised Dimensionality Reduction)
- 定义:这类算法在降维过程中会利用数据样本的标签信息(通常是类别标签 y)。它们的目标是找到一个低维子空间,在这个子空间中,不同类别的数据点能够被更好地分离开,或者说,这个低维表示更有利于后续的分类(或回归)任务。
- 输入:特征矩阵 X 和对应的标签向量 y。
- 目标:
· 最大化不同类别之间的可分性,同时最小化同一类别内部的离散度(如LDA)。
· 找到对预测目标变量 y 最有信息量的特征组合。
- 典型算法:
· LDA(Linear Discriminant Analysis):这是最经典的监督降维算法。它寻找的投影方向能够最大化类间散度与类内散度之比。
· 还有一些其他的,比如NCA(Neighbourhood Components Analysis),但LDA是最主要的代表。
- “还需要有分类标签么”:是的,对于有监督降维,分类标签(或其他形式的监督信号)是必须的。

举个例子来说明:
PCA (无监督):如果你有一堆人脸图片,PCA会尝试找到那些能最好地概括所有人脸变化的“主脸”(特征向量),比如脸型、鼻子大小等,它不关心这些人脸属于谁。
LDA (有监督):如果你有一堆人脸图片,并且你知道每张图片属于哪个人(标签)。LDA会尝试找到那些能最好地区分不同人的人脸特征组合。比如,如果A和B的脸型很像,但眼睛差别很大,LDA可能会更强调眼睛的特征,即使脸型方差更大。PCA是利用最大化方差来实现无监督降维,而LDA则是在此基础上,加入了类别信息,其优化目标就变成了类间差异最大化和类内差异最小化。
--- 1. 默认参数随机森林 (训练集 -> 测试集) ---
训练与预测耗时: 0.6742 秒默认随机森林 在测试集上的分类报告:precision recall f1-score support0 0.77 0.96 0.85 10591 0.77 0.30 0.43 441accuracy 0.77 1500macro avg 0.77 0.63 0.64 1500
weighted avg 0.77 0.77 0.73 1500默认随机森林 在测试集上的混淆矩阵:
[[1020 39][ 309 132]]主成分分析(PCA)
PCA的核心思想是识别数据中方差最大的方向(即主成分)。然后,它将数据投影到由这些最重要的主成分构成的新的维度更低子空间上。这样做的目的是在降低数据维度的同时,尽可能多地保留原始数据中的“信息”(通过方差来衡量)。新的特征(主成分)是原始特征的线性组合,并且它们之间是正交的(不相关)。
PCA与SVD的关系:
1.步骤0:均值中心化(对PCA的解释至关重要)
2.步骤1:对均值中心化后的数据应用SVD
3.步骤2:在PCA的语境下理解SVD的各个组成部分
PCA何时适用?数据是线性还是非线性?
- 线性性
- PCA效果好的情况:
· 目标是最大化方差
· 数据分布大致呈椭球形或存在线性关系
· 作为其他线性模型的预处理步骤
· 探索性数据分析(EDA)
· 降噪
· 当原始特征数量非常多
- PCA可能不使用或需要谨慎使用的情况:
· 高度非线性数据
· 方差并非衡量重要性的唯一标准
· 主成分的可解释性
· 数据特征尺度差异巨大
总之,可以将PCA视为:
1.对数据进行均值中心化
2.对中心化后的数据进行SVD
3.使用SVD得到的右奇异向量V作为主成分方向
4.使用奇异值S来评估每个主成分的重要性(解释的方差)
5.使用U*S或(X_centered*V)来获得降维后的数据表示
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np # 确保numpy导入# 假设 X_train, X_test, y_train, y_test 已经准备好了print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
pca_expl.fit(X_train_scaled_pca)
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---
为了保留95%的方差,需要的主成分数量: 26
# 我们测试下降低到10维的效果
n_components_pca = 10
pca_manual = PCA(n_components=n_components_pca, random_state=42)X_train_pca = pca_manual.fit_transform(X_train_scaled_pca)
X_test_pca = pca_manual.transform(X_test_scaled_pca) # 使用在训练集上fit的pcaprint(f"PCA降维后,训练集形状: {X_train_pca.shape}, 测试集形状: {X_test_pca.shape}")
start_time_pca_manual = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train)# 步骤 4: 在测试集上预测
rf_pred_pca_manual = rf_model_pca.predict(X_test_pca)
end_time_pca_manual = time.time()print(f"手动PCA降维后,训练与预测耗时: {end_time_pca_manual - start_time_pca_manual:.4f} 秒")print("\n手动 PCA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca_manual))
print("手动 PCA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca_manual))PCA降维后,训练集形状: (6000, 10), 测试集形状: (1500, 10)
手动PCA降维后,训练与预测耗时: 1.3935 秒手动 PCA + 随机森林 在测试集上的分类报告:precision recall f1-score support0 0.77 0.94 0.85 10591 0.69 0.32 0.44 441accuracy 0.76 1500macro avg 0.73 0.63 0.64 1500
weighted avg 0.75 0.76 0.73 1500手动 PCA + 随机森林 在测试集上的混淆矩阵:
[[996 63][299 142]]t-分布随机临域嵌入(t-SNE)
t-SNE:保持高维数据的局部临域结构,用于可视化
PCA的目标是保留数据的全局方差,而t-SNE的核心目标是在高维空间中相似的数据点,在降维后的低维空间中也应该保持相似(即彼此靠近),而不相似的点应该相聚较远。它特别擅长将高维数据集投影到二维或三维空间进行可视化,从而揭示数据中的簇结构或流形结构。---深度学习可视化中很热门。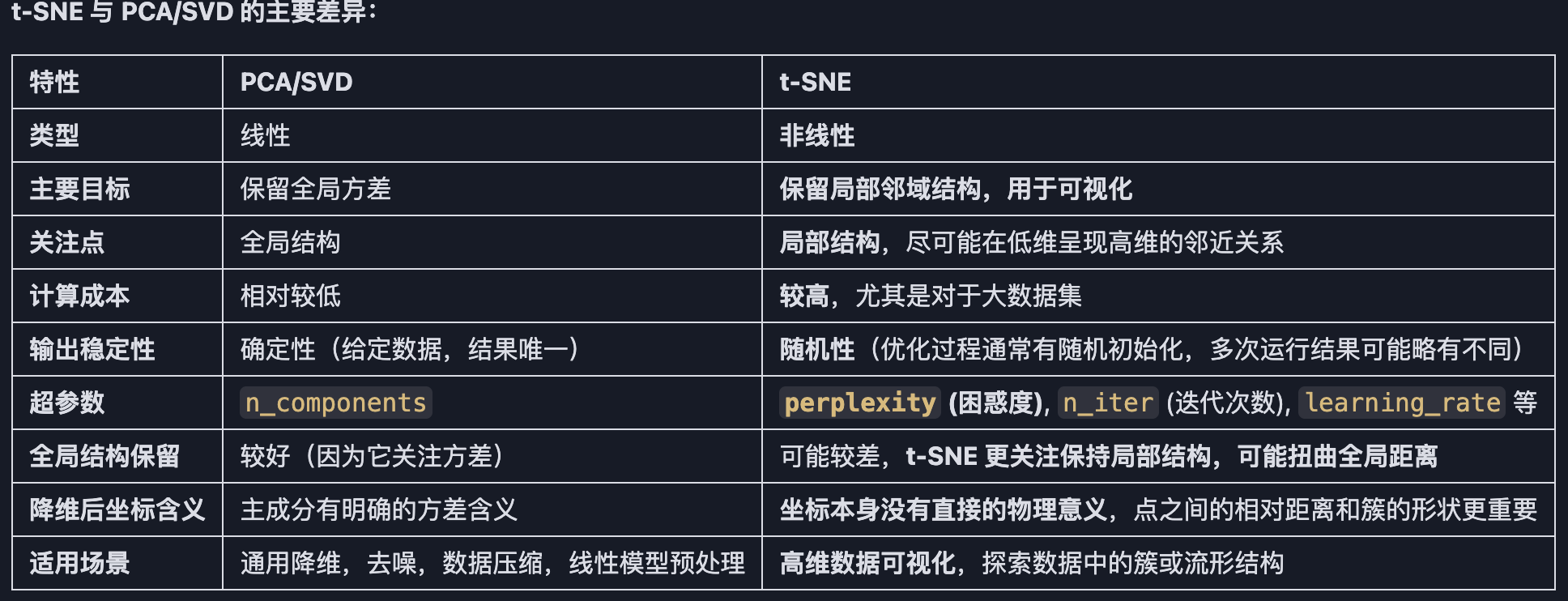
何时适用t-SNE?
- 当主要目的是可视化高维数据时
- 当数据具有复杂的非线性结构时
- 探索型数据分析
使用时注意事项:
- 计算成本高
- 超参数敏感:Perplexity(困惑度)、n_iter(迭代次数)、learning_rate(学习率)
- 结果的解释:
· 簇的大小和密度在t-SNE图中没有直接意义
· 点之间的距离在全局上没有意义
· 多次运行结构可能不同
- 不适合作为通用的有监督学习预处理步骤
总之,t-SNE 是一种强大的非线性降维技术,主要用于高维数据的可视化。它通过在低维空间中保持高维空间中数据点之间的局部相似性(邻域关系)来工作。与PCA关注全局方差不同,t-SNE 更关注局部细节。理解它的超参数(尤其是困惑度)和结果的正确解读方式非常重要。
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt # 用于可选的可视化
import seaborn as sns # 用于可选的可视化# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,perplexity=30, # 常用的困惑度值n_iter=1000, # 足够的迭代次数init='pca', # 使用PCA初始化,通常更稳定learning_rate='auto', # 自动学习率 (sklearn >= 1.2)random_state=42, # 保证结果可复现n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,perplexity=30,n_iter=1000,init='pca',learning_rate='auto',random_state=42, # 保持参数一致,但数据不同,结果也不同n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")print(f"t-SNE降维后,训练集形状: {X_train_tsne.shape}, 测试集形状: {X_test_tsne.shape}")start_time_tsne_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train)# 步骤 4: 在测试集上预测
rf_pred_tsne_manual = rf_model_tsne.predict(X_test_tsne)
end_time_tsne_rf = time.time()print(f"t-SNE降维数据上,随机森林训练与预测耗时: {end_time_tsne_rf - start_time_tsne_rf:.4f} 秒")
total_tsne_time = (end_tsne_fit_train - start_tsne_fit_train) + \(end_tsne_fit_test - start_tsne_fit_test) + \(end_time_tsne_rf - start_time_tsne_rf)
print(f"t-SNE 总耗时 (包括两次fit_transform和RF): {total_tsne_time:.2f} 秒")print("\n手动 t-SNE + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne_manual))
print("手动 t-SNE + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne_manual))
--- 3. t-SNE 降维 + 随机森林 ---标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。
正在对训练集进行 t-SNE fit_transform...
训练集 t-SNE fit_transform 完成,耗时: 11.44 秒
正在对测试集进行 t-SNE fit_transform...
测试集 t-SNE fit_transform 完成,耗时: 2.48 秒
t-SNE降维后,训练集形状: (6000, 2), 测试集形状: (1500, 2)
t-SNE降维数据上,随机森林训练与预测耗时: 0.5085 秒
t-SNE 总耗时 (包括两次fit_transform和RF): 14.43 秒手动 t-SNE + 随机森林 在测试集上的分类报告:precision recall f1-score support0 0.70 0.94 0.80 10591 0.27 0.06 0.09 441accuracy 0.68 1500macro avg 0.49 0.50 0.45 1500
weighted avg 0.58 0.68 0.60 1500手动 t-SNE + 随机森林 在测试集上的混淆矩阵:
[[992 67][416 25]]线性判别分析(Linear Discriminant Analysis,LDA)
1.核心定义和目标:LDA是一种经典的有监督降维算法,也常直接用作分类器。作为降维技术时,其核心目标是找到一个低维特征子空间(即原始特征的线性组合),使得在该子空间中,不同类别的数据点尽可能地分开(类间距离最大化),而同一类别的数据点尽可能地聚集(类内方差最小化)
2.工作原理简述:LDA通过最大化“类间散布矩阵”与“类内散布矩阵”之比的某种度量(例如它们的行列式之比)来实现其降维目标。它寻找能够最好地区分已定义类别的投影方向。
3.关键特性:
- 有监督性(Supervised)
- 降维目标维度(Number of Components)
- 线性变换(Linear Transformation)
- 数据假设(Assumption)
4.输入要求:
- 特征(X)
- 标签(y)
5.特征和标签的关系
- LDA的降维过程和结构直接由标签中的类别结构驱动。它试图找到最能区分这些由y定义的类别的特征组合。
- 原始特征X提供了构建这些判别特征的原材料。特征X质量和相关性会影响LDA的效果,但降维的“方向盘”是由y控制的。
6.优点:
- 直接优化类别可分性,非常适合作为分类任务的预处理步骤,往往能提升后续分类器的性能
- 计算相对高效
- 生成的低维特征具有明确的判别意义。
7.局限性和注意事项:
- 降维的维度受限于n_classes -1,这可能比PCA能达到降维程度低很多,尤其在类别数较少时。
- 作为线性方法,可能无法捕捉数据中非线性的类别结构。如果类别边界是非线性的,LDA效果可能不佳。
- 对数据的高斯分布和等协方差假设在理论上是存在的,极端偏离这些假设可能影响性能。
- 如果类别在原始特征空间中本身就高度重叠,LDA的区分能力也会受限。
8.适用场景:
- 目标是提高后续分类模型的性能时
- 类别信息已知且被认为是区分数据的主要因素时
- 希望获得具有良好类别区分性的低维表示时
总之,LDA是一种利用类别标签信息来寻找最佳类别分离投影的降维方法,其降维潜力直接与类别数量挂钩。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
# 假设你已经导入了 matplotlib 和 seaborn 用于绘图 (如果需要)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 如果需要3D绘图
import seaborn as snsprint(f"\n--- 4. LDA 降维 + 随机森林 ---")# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'): n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):n_classes = len(np.unique(y_train))
else:n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes})太少,无法产生至少1个判别组件。")X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")X_train_lda = X_train_scaled_lda.copy()X_test_lda = X_test_scaled_lda.copy()actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。")lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')
X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)
X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train)# 步骤 4: 在测试集上预测
rf_pred_lda_manual = rf_model_lda.predict(X_test_lda)
end_time_lda_rf = time.time()print(f"LDA降维数据上,随机森林训练与预测耗时: {end_time_lda_rf - start_time_lda_rf:.4f} 秒")print("\n手动 LDA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda_manual))
print("手动 LDA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda_manual))
--- 4. LDA 降维 + 随机森林 ---
原始特征数: 30, 类别数: 2
LDA 最多可降至 1 维。
目标降维维度: 10 维。
本次 LDA 将实际降至 1 维。
LDA降维后,训练集形状: (6000, 1), 测试集形状: (1500, 1)
LDA降维数据上,随机森林训练与预测耗时: 0.6795 秒手动 LDA + 随机森林 在测试集上的分类报告:precision recall f1-score support0 0.78 0.78 0.78 10591 0.47 0.47 0.47 441accuracy 0.69 1500macro avg 0.63 0.63 0.63 1500
weighted avg 0.69 0.69 0.69 1500手动 LDA + 随机森林 在测试集上的混淆矩阵:
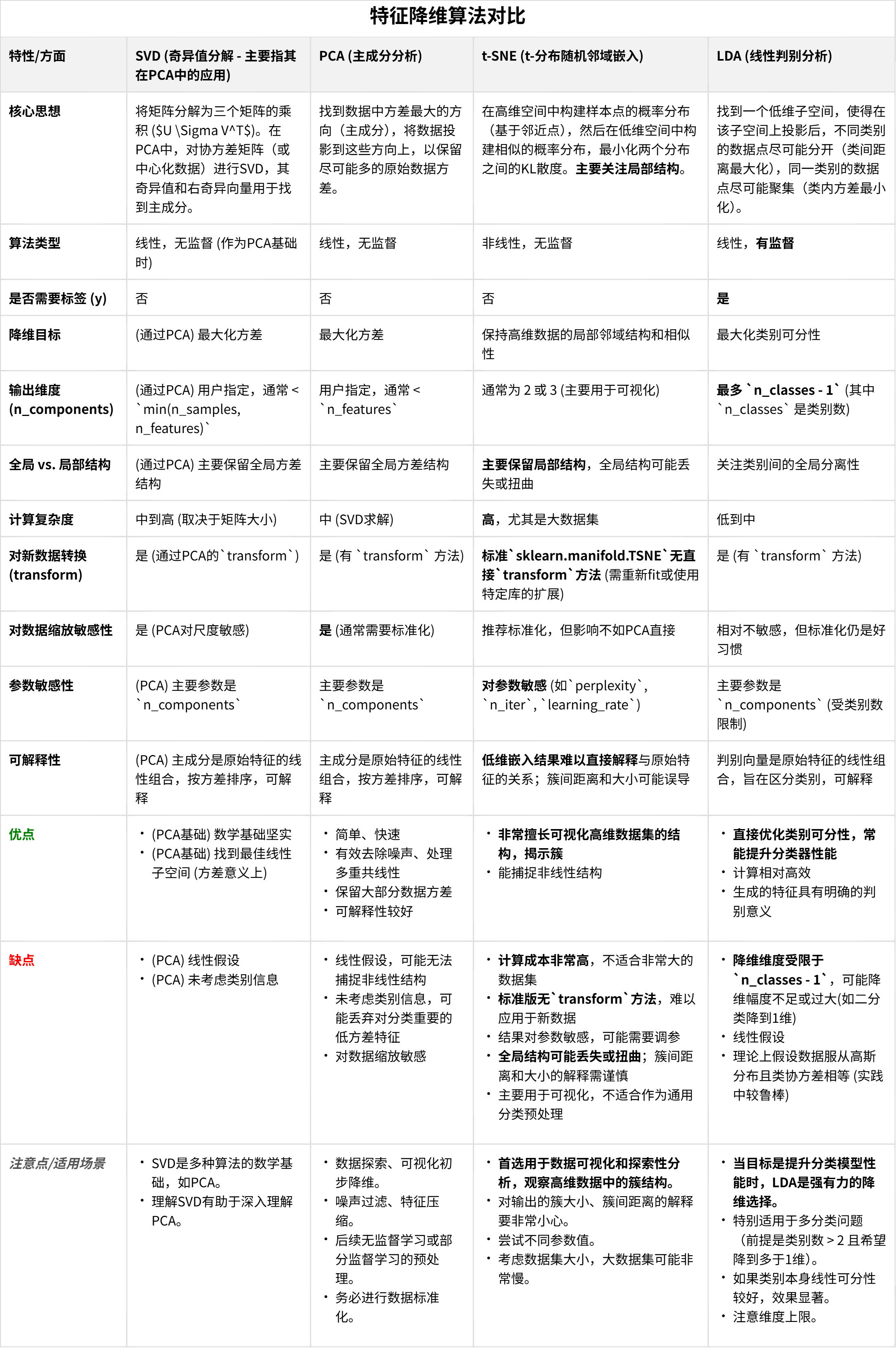
[[828 231][233 208]]总结
作业:
一、什么时候用到降维?
当数据存在以下特点或需求时,通常会考虑使用降维技术:
(一)数据维度过高
- 维度灾难:当特征维度(如变量数量)极大时(如成千上万维),数据在高维空间中会变得稀疏,传统机器学习模型的训练效率会显著下降,且容易出现过拟合问题。例如,图像数据(如 100×100 像素的图片,维度为 10000)、基因表达数据(维度可达数万个基因)等。
- 存储与计算成本:高维数据占用大量存储空间,且在计算距离、协方差等操作时复杂度呈指数级增长。
(二)特征冗余或相关性强
- 数据中存在大量冗余特征(如重复测量的指标、高度相关的变量),例如:
- 房价预测中,“房屋面积” 和 “使用面积” 可能高度相关;
- 金融数据中,不同时间窗口的同类型指标(如周收益率和月收益率)可能存在信息重叠。
(三)数据可视化需求
- 高维数据难以直接可视化(人类通常只能直观理解 2-3 维数据),降维可将数据映射到低维空间(如 2D 或 3D),便于观察数据分布、聚类结构或异常点。例如:
- 客户分群数据降维后可通过散点图展示群体分布;
- 图像数据集降维后可用于可视化不同类别样本的聚集情况。
(四)噪声干扰
- 高维数据中可能包含大量噪声或无关特征,降维可过滤噪声,提取核心信息。例如:
- 传感器采集数据中混杂的环境噪声;
- 文本数据中大量低频无意义词汇。
二、降维的主要应用领域
(一)机器学习与数据挖掘
- 预处理步骤:
- 在训练模型前对数据降维,提升模型效率和泛化能力。例如:
- 主成分分析(PCA)常用于图像识别(如人脸识别)的特征压缩;
- 线性判别分析(LDA)用于分类任务中的特征提取,最大化类间差异。
- 在训练模型前对数据降维,提升模型效率和泛化能力。例如:
- 聚类分析:
- 降维后的数据更易通过 K-means、DBSCAN 等算法发现聚类结构。例如:
- 基因表达数据降维后可识别共表达基因模块;
- 用户行为数据降维后用于电商用户分群。
- 降维后的数据更易通过 K-means、DBSCAN 等算法发现聚类结构。例如:
(二)计算机视觉
- 图像压缩:
- 通过降维减少图像数据量,同时保留主要视觉特征。例如:
- PCA 用于面部图像的特征脸(Eigenfaces)提取,压缩后的特征可用于人脸识别;
- 深度学习中的自动编码器(Autoencoder)可实现非线性降维,用于图像压缩和解码。
- 通过降维减少图像数据量,同时保留主要视觉特征。例如:
- 视频分析:
- 对视频帧序列降维,提取动作或场景的关键特征,用于行为识别或视频检索。
(三)自然语言处理(NLP)
- 文本降维:
- 将高维词向量(如 One-Hot 编码或 TF-IDF 向量)降维为低维稠密向量,捕捉语义关联。例如:
- 潜在语义分析(LSA)通过奇异值分解(SVD)提取文本主题;
- 词嵌入技术(如 Word2Vec)可视为一种非线性降维,将单词映射到低维语义空间。
- 将高维词向量(如 One-Hot 编码或 TF-IDF 向量)降维为低维稠密向量,捕捉语义关联。例如:
- 文档检索与分类:
- 降维后减少文本特征空间的维度,提升文本分类(如垃圾邮件识别)和信息检索(如搜索引擎)的效率。
(四)金融与量化分析
- 风险建模:
- 降维用于处理金融时间序列数据(如股票价格、汇率)中的多重共线性问题,例如:
- PCA 用于资产收益率的主成分提取,构建风险因子模型;
- 独立成分分析(ICA)用于分离金融数据中的独立噪声源(如市场波动与个别资产异常)。
- 降维用于处理金融时间序列数据(如股票价格、汇率)中的多重共线性问题,例如:
- 高频交易:
- 对海量交易数据降维,快速提取关键交易特征,优化交易策略。
(五)生物医学与基因研究
- 基因表达分析:
- 降维用于分析数千个基因的表达数据,识别与疾病相关的关键基因子集。例如:
- PCA 用于癌症基因表达数据的聚类,区分不同亚型肿瘤;
- t-SNE 用于单细胞 RNA 测序数据的可视化,展示细胞类型分布。
- 降维用于分析数千个基因的表达数据,识别与疾病相关的关键基因子集。例如:
- 蛋白质结构分析:
- 降维简化蛋白质构象的高维空间,研究分子动态变化与功能的关系。
(六)推荐系统
- 降维用于处理用户 - 物品交互矩阵的高稀疏性问题,例如:
- 矩阵分解(如 SVD)将用户和物品映射到低维隐空间,捕捉潜在偏好(如 Netflix 电影推荐);
- 深度学习中的协同过滤模型(如神经协同过滤 NCF)通过降维提取用户和物品的特征向量。
(七)数据可视化与探索性分析
- 通过降维技术(如 PCA、t-SNE、UMAP)将高维数据映射到 2D/3D 空间,辅助分析师发现数据中的模式、异常或相关性。例如:
- 社交媒体用户数据降维后可视化群体结构;
- 工业传感器数据降维后实时监控设备运行状态。
三、常见降维方法分类
| 类型 | 方法 | 核心思想 | 应用场景 |
|---|---|---|---|
| 线性降维 | 主成分分析(PCA) | 最大化数据方差,投影到正交主成分空间 | 图像压缩、噪声过滤 |
| 线性判别分析(LDA) | 最大化类间差异,最小化类内差异 | 有监督分类任务 | |
| 独立成分分析(ICA) | 分离数据中的独立成分(非高斯分布) | 信号分离(如脑电信号去噪) | |
| 非线性降维 | 局部线性嵌入(LLE) | 保持局部线性结构,全局非线性映射 | 流形学习、图像 manifold |
| t - 分布随机邻域嵌入(t-SNE) | 高维空间近邻概率映射到低维,强调局部结构 | 数据可视化 | |
| 均匀流形近似与投影(UMAP) | 结合全局结构和局部邻域,效率高于 t-SNE | 大规模数据集可视化 | |
| 特征选择 | 过滤法(Filter) | 基于统计指标(如方差、相关系数)筛选特征 | 预处理阶段快速降维 |
| 包裹法(Wrapper) | 基于模型性能迭代选择特征组合 | 特定模型的定制化特征选择 | |
| 嵌入法(Embedded) | 在模型训练中自动进行特征选择(如 L1 正则化) | 集成到机器学习算法中 |
@浙大疏锦行