高效VLM:VisionZip
论文:[2412.04467] VisionZip: Longer is Better but Not Necessary in Vision Language Models
github:https://github.com/dvlab-research/VisionZip
LLaVA论文:https://arxiv.org/abs/2310.03744
LLaVA仓库:https://github.com/haotian-liu/LLaVA?tab=readme-ov-file
1.内容概括:
LLMs的发展推动了VLMs的发展,现有的VLMs为了把视觉信号与文本语义连接起来,通常采用顺序视觉表示,将图像转换为视觉tokens并通过LLM解码器处理。通过模态对齐和指令调优,这些VLM利用LLM的感知和推理能力,使其适应视觉领域【传统处理方法】。
VLM模型性能依赖于视觉token的数量,但是通过增加视觉token的长度(比文本token长度还要长)使得模型性能提升,这种方式显著增加了计算成本,限制了模型在边缘计算、自动驾驶和机器人等实际应用场景中的发展【传统方法的局限性】【问题1:计算成本】。有研究表明:图像中的信息更加稀疏。而现有的最先进的 VLMs 的视觉 tokens 数量远远超过文本 tokens。“所有视觉 tokens 都是必要的吗?”,而经过实验证明CLIP和SigLIP生成的视觉token存在冗余【问题2:token虽然长,但不都是有用的】。
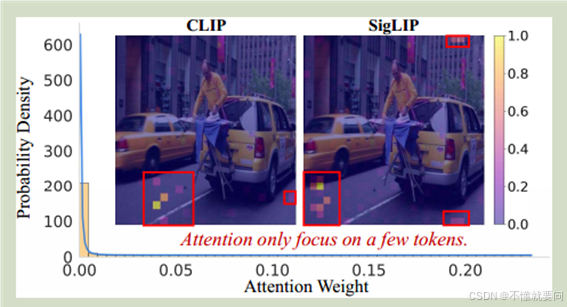
如图所示就是改论文所作的实验,左侧的实验是注意力权重分布图,可见高注意力权重(如 0.05–0.10 区间)的标记概率密度低,即此类标记数量少;大量标记的注意力权重集中在 0 附近(概率密度高),说明多数标记未被关注,进一步验证视觉标记冗余现象。
在两张图片中,高亮度区域是高注意力权重的视觉token,可以看见在整张图中,高注意力权重的区域非常小,那么也就是说视觉token的冗余现象非常严重。而且还可以看见一个现象就是高注意权重的视觉token区域并不在图像的主要目标物体中,例如图中的人物或者出租车,而是出现在了马路上,这种高注意力权重视觉token的偏移现象似乎也能解释为什么在LLM阶段根据文本与图像之间的对应关系筛选主导token时可能性能下降比较明显:因为与文本对象关联的视觉主体上的视觉token权重并不高,这样筛选出的视觉token会丢失大量的图像原本的信息。
VisionZip的解决方案:选择一组信息丰富的 tokens 作为语言模型的输入,减少视觉 tokens 的冗余,提升效率的同时保持模型性能。VisionZip可广泛应用于图像和视频理解任务,尤其适合多轮对话等实际场景,而此前的方法在这些场景中表现欠佳【优势】。
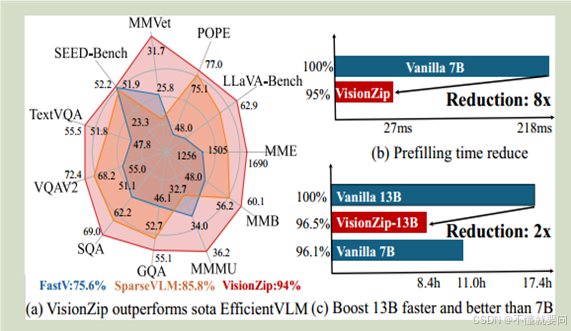
A: 性能对比雷达图
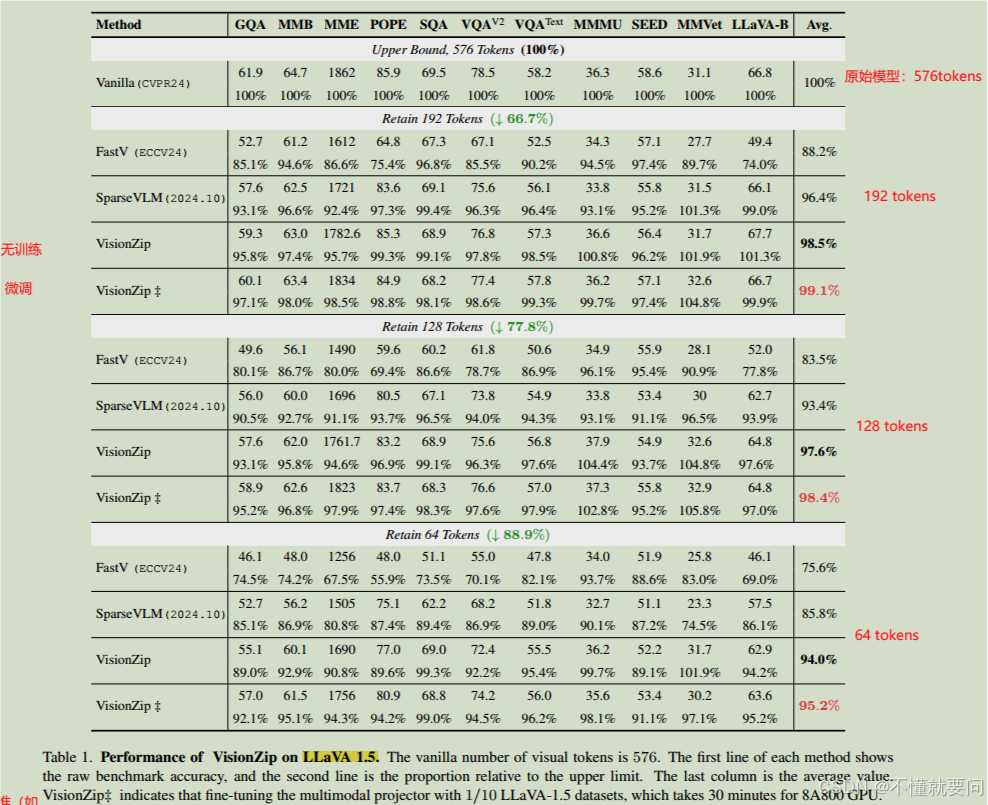
对比使用 VisionZip 优化的LLaVA-1.5模型与当前高效VLM模型优化方法(如 FastV、SparseVLM 等)在 11 个基准测试(如 LLaVA-Bench、MME、TextVQA、VQAV2 等)上的性能表现。VisionZip 在仅使用 10%tokens的情况下,实现了接近当前最优模型95% 的性能。
B: 预填充时间对比柱状图
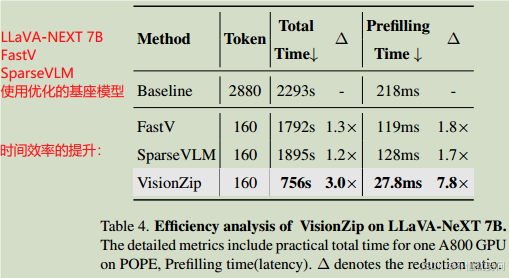
基座模型选择LLaVA-NeXT,7B是70亿参数版本。VisionZip 大幅优化了预填充效率,将 LLaVA-NeXT 7B 模型的预填充时间从 218ms 减少至 27ms,实现了8 倍的时间缩减(Reduction: 8x),同时可以达到基座模型性能的95%。
C: 推理时间与性能对比柱状图
三个模型:LLaVA-NeXT 13B,经过VisionZip优化的13B模型,LLaVA-NeXT 7B,内容:在 11 个基准测试中的 GPU 推理时间与性能。经过VisionZip优化的13B模型推理时间上是原本13B模型的1/2,性能可以达到96.5%,比7B模型的推理时间还少,性能却更好(96.1%)。
2.方法总结:
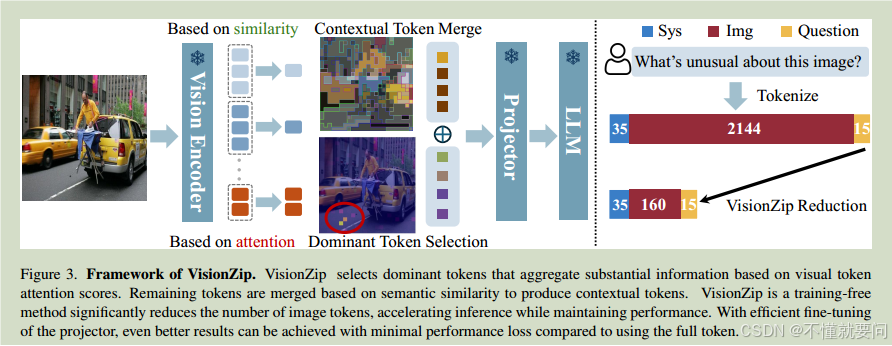
VisionZip方法总结起来就是删去无用的视觉token以达到提高推理速度的作用。这种类型的方法在此之前已经出现过,比如FastV、SparseVLM这类,但是他们主要在VLM的LLM阶段(Vision Encoder->MM->LLM)对视觉token进行处理,在这个过程中操作较为复杂而且性能损失较大。VisionZip选择的道路是在VisionEncoder之后就对视觉token进行处理,主要的处理分为两个步骤:
2.1:保留主导token:
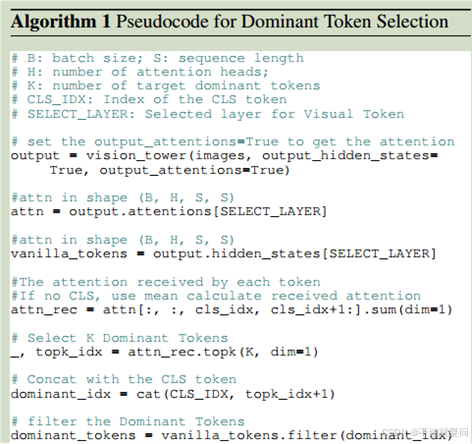
这一块的主要思路是确定一个阈值k,即我们要保留多少高注意力权重的视觉token,然后根据CLS标识得到所有视觉token的注意力得分,然后选择其中最高的k个做保留即可。
2.2:合并其余token:

这一块的主要思路是在剩余的视觉token中,可能他们所携带的信息量并不多,但是完全删去他们可能会损失模型的性能,因此对于剩余的token要做一定的合并处理,首先给定一个阈值M,即要合并出多少个token,之后将剩余的视觉token分割为两部分,一部分是目标token,一部分是合并token,计算出合并token与目标token之间的余弦相似度,此时,对于每一个合并token来说,只保留与他相似度最大的目标token的索引,然后统计针对每一个目标token,有哪些合并token要与他合并,最后进行求和相加即可完成合并工作。
3.实验思路:
实验思路:
该论文提出的实验思路有三种应用:
第一种是无训练方法,即只需要在推理时在Vision Encoder之后进行视觉token筛选即可。
第二种是高效微调方法:视觉token经过了压缩之后出现了一个问题,那就是经过信息性视觉token压缩后,输入到大语言模型的视觉token长度显著减少,这可能导致原本在完整视觉token上训练的视觉语言模型难以适应这种变化,使得视觉和大语言模型空间之间出现差距 ,即两者在信息表示和处理方式上不太匹配。解决方法是通过微调多模态投影器,让它适应减少后的视觉token输入,从而增强视觉和语言空间之间的对齐。具体操作中,只对多模态投影器进行微调,保持模型的其他组件(如视觉编码器、大语言模型主体等)不变。
第三种方法是从头开始训练:全新训练,整合 VisionZip 方法到模型构建中,从初始训练就应用标记优化策略。
实验结果:
通过在 Mini - Gemini(基于 ConvNeXt - L)上应用 VisionZip,观察其性能变化,证明 VisionZip 不仅适用于基于 Transformer 的 VLM(如 LLaVA 系列),还能在基于 CNN 的 VLM 中发挥作用,从而验证其跨架构的普适性。如果在 ConvNeXt - L 生成的视觉标记中同样存在冗余,并且 VisionZip 能够有效减少冗余并提升效率,这将进一步证明视觉标记冗余是一个普遍现象,而非特定架构的问题。

分析:
视觉 tokens 冗余的原因:

注意力跨层变化分析
- 早期层(如视觉编码器初始层):
注意力在图像上广泛分布,模型此时在捕捉图像的基础特征(如边缘、颜色、简单形状等),尚未聚焦到特定区域或物体,属于对图像整体信息的初步感知阶段。 - 中间层:
注意力突然收敛到少量标记(token)。这表明模型在中间层开始筛选关键信息,过滤掉冗余细节,逐步明确对图像中重要内容的关注,是从底层特征向高层语义过渡的阶段。 - 深层(如第 23 层,用于为大语言模型提取视觉标记,作为VLM的视觉编码器的输出):
注意力和信息高度集中在一小部分 “主导token” 上,达到集中化的峰值。此时模型已识别出图像中最核心、最具信息量的部分,这些主导标记承载了图像的关键语义,是后续大语言模型处理的核心视觉输入。 - 最后一层(如第 24 层):
注意力分布更分散。因为最后一层的标记需通过对比损失(contrastive loss)与 CLIP 文本分支对齐,这种对齐操作会让标记更偏向语言空间的特征,而非单纯表示原始图像内容,从而限制了其对原始图像细节的精准表达。
Softmax 函数的梯度特性会加剧视觉标记冗余:

当输入值 zi 增大时,softmax梯度呈指数上升趋势。在模型训练中,这种梯度特性会让模型更倾向于关注少数响应值高的标记(对应图像中的局部区域),而忽略其他标记的信息。长期训练后,大量标记因未被充分利用成为冗余,仅少数标记承载主要信息。