LLM应用开发(九)- 幻觉及如何缓解
1.幻觉的定义
1.1.事实性幻觉
指模型生成的内容与可验证的现实事实不一致。比如提问“第一个在月球上行走的人是谁?",模型回复"CharlesLindbergh在1951年月球先驱任务中第一个登上月球",而实际上,第一个登上月球的人是Nei Armstrong。而事实性幻觉又分为事实不一致(与现实世界信息相矛盾)和事实捏造(压根没有,无法根据现实信息验证)。
1.2.忠实性幻觉
指模型生成的内容与用户的指令或上下文不一致。比如让模型总结今年10月的新闻,结果模型却在说2006年10月的事。忠实性幻觉也可以细分,分为指令不一致(输出偏离用户指令)、上下文不一致(输出与上下文信息不符)、逻辑不一致(推理步骡以及与最终答案之间不一致)三类,
2.产生幻觉原因
2.1.数据源导致的幻觉
首先病从口入,大模型的粮食数据,是致使它产生幻觉的一大原因。这里面就包括 数据缺陷和数据中捕获的事实知识的利用率低。具体来说,数据缺陷分为错误信息和偏见(重复偏见、社会偏见),此外大模型也存在知识边界,所以存在领域知识缺陷和过时的事实知识。即便大模型吃掉了大量的数据,也会在利用时出现问题。
除此之外,大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉,比如:如果训练数据中频繁出现“加拿大”和“多伦多”,那么大模型可能会错误地将多伦多识别为加拿大的首都。
2.2.训练过程导致的幻觉
在模型的预训练阶段(大模型学习通用表示并获取世界知识)、对齐阶段(微调大模型使其更好地与人类偏好一致)两个阶段产生的问题也会导致幻觉的发生。
预训练阶段:
架构缺陷:基于前一个token 预测下一个token,这种单向建模阻碍了模型捕获复杂的上下文关系的能力;自注意力模块存在缺陷随着 token 长度增加,不同位置的注意力被稀释。
暴露偏差:训练策路也有缺陷,模型推理时依赖于自己生成的token 进行后续预测,模型生成的错误 token 会在整个后续 token 中产生级联错误。
对齐阶段:
能力错位:大模型内在能力与标注数据中描述的功能之间可能存在错位。当对齐数据需求超出这些预定义的能力边界时,大模型会被训练来生成超出其自身知识边界的内容,从而放大幻觉的风险。
信念错位:基于 RLHF 等的微调,使大模型的输出更符合人类偏好,但有时模型会倾向于迎合人类偏好,从而牺牲信息真实性。
2.3.推理导致的幻觉
1.固有的抽样随机性:在生成内容时根据概率随机生成。
2.不完美的解码表示:上下文关注不足,(过度关注相邻文本而忽视了源上下文)和 softmax 瓶颈(输出概率分布的表达能力受限)
3.幻觉评估检测
3.1.不确定性检测评估方法
1.基于内部状态的方法主要依赖于大模型的内部状态。例如,通过考虑关键概念的最小标记概率来确定模型的不确定性。
2.基于行为的方法主要依赖观察大模型的行为,不需要访问其内部状态。例如,通过采样多个大语言模型响应并评估事实陈述的一致性来检测幻觉。
3.2.忠实性检测评估方法
基于事实的度量:测量生成内容和源内容之间事实的重叠程度来评估忠实性。
分类器度量:使用训练过的分类器来区分模型生成的忠实内容和幻觉内容。
问答度量:使用问答系统来验证源内容和生成内容之间的信息一致性。
不确定度估计:测量模型对其生成输出的置信度来评估忠实性。
提示度量:让大模型作为评估者,通过特定的提示策略来评估生成内容的忠实性。
4.幻觉的缓解方案
4.1.缓解数据相关幻觉(重点)
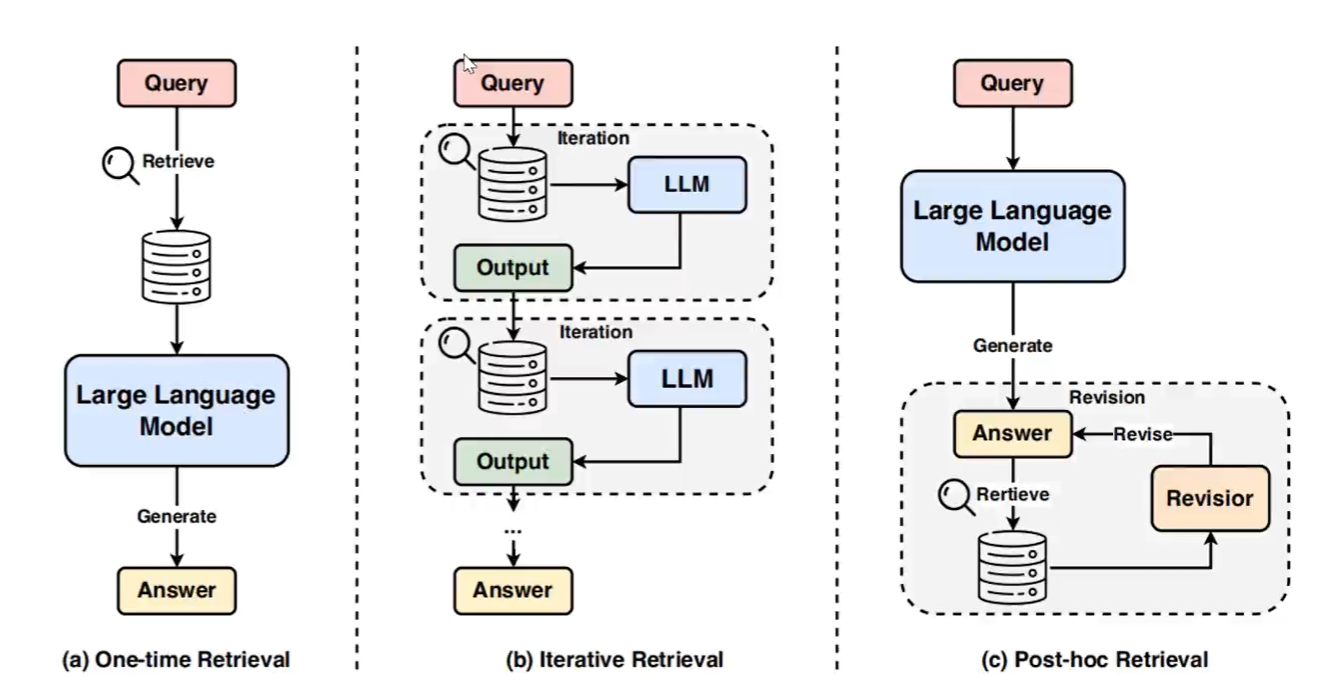
减少错误信息和偏见,最直观的方法是收集高质量的事实数据,并进行数据清理以消除偏见。对于大语言模型知识边界的问题,有两种流行方法。一种是知识编辑,直接编辑模型参数弥合知识差距。另一种通过检索增强生成(RAG)利用非参数知识源。
检索增强生成具体分为三种类型:一次性检索、迭代检索和事后检索。