HDFS分布式存储 zookeeper
hadoop介绍
狭义上hadoop是指apache的一款开源软件
用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件
hdfs(分布式文件存储系统):解决海量的数据存储
yarn(集群资源管理和任务调度框架):解决资源任务调度
mapreduce(分布式计算框架):解决海量数据计算官网
http://hadoop.apache.org/
hahoop1.x架构
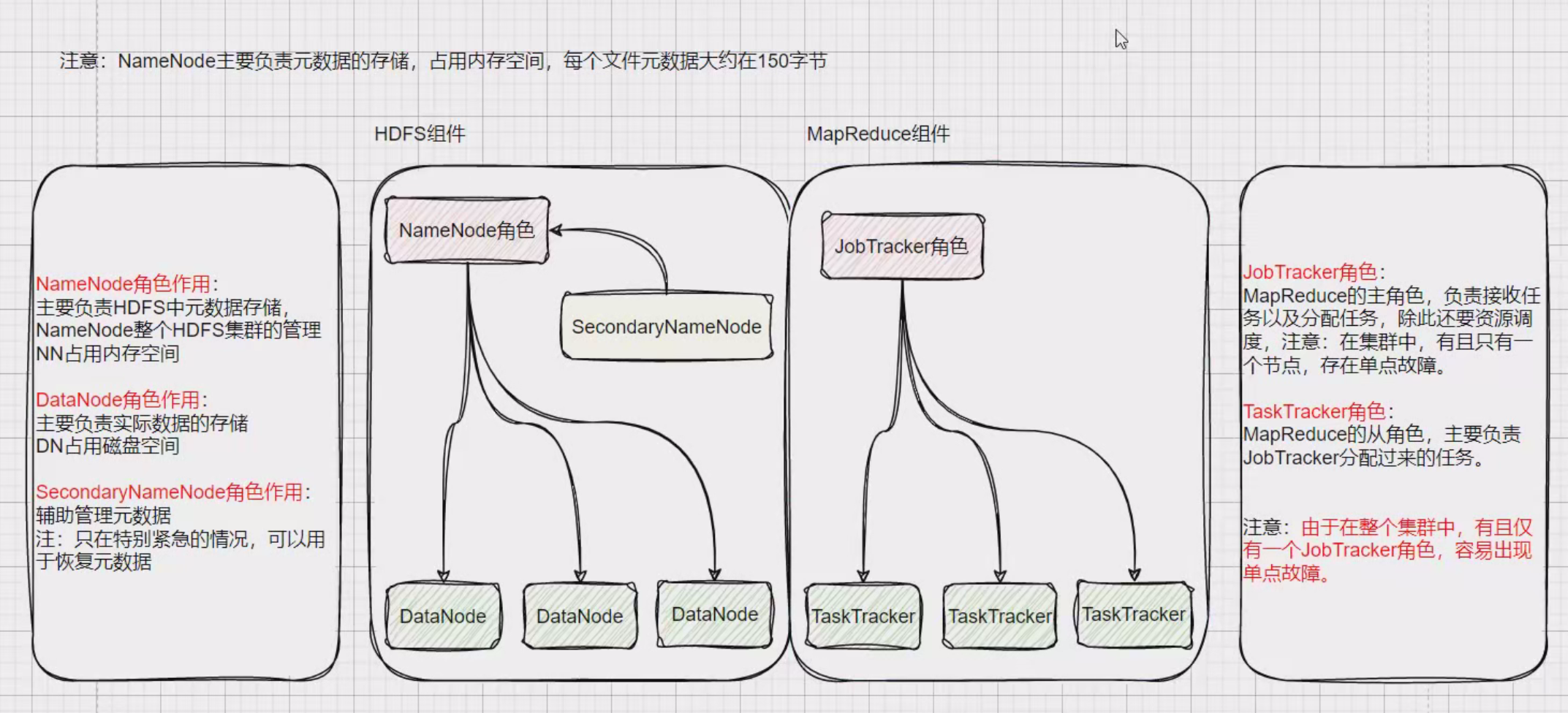
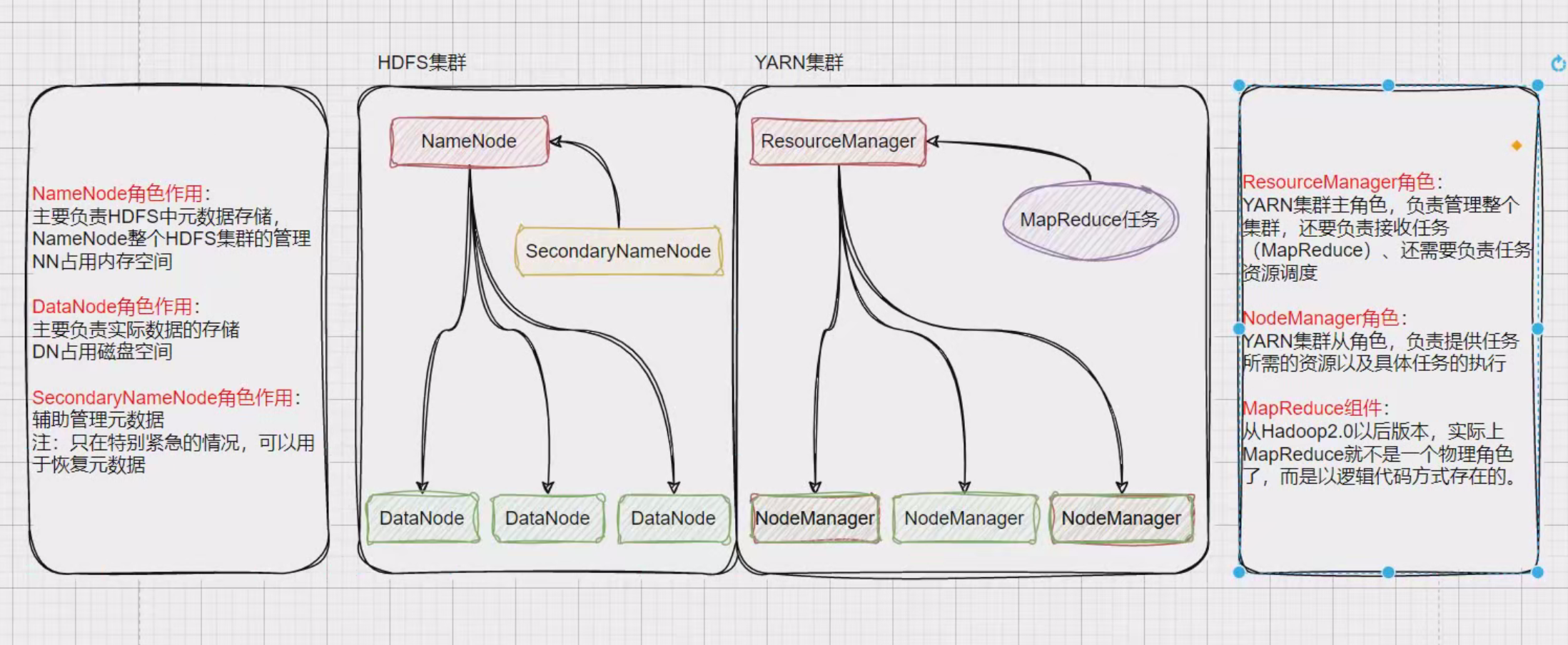
hahoop2.x,hahoop3.x架构架构
机器准备
192.168.12.135 master centos7
192.168.12.134 node centos7
192.168.12.138 ubuntu
实验
1.关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# getenforce
Disabled
2.hosts解析
[root@master ~]# tail -n 3 /etc/hosts
192.168.12.135 master
192.168.12.134 node
192.168.12.138 ubuntu安装jdk
[root@master ~]# yum install java-11-openjdk -y
[root@master ~]# java -version
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)[root@master ~]# ls hadoop-3.3.0.tar.gz
hadoop-3.3.0.tar.gz
[root@master ~]# tar xf hadoop-3.3.0.tar.gz
[root@master ~]# cd hadoop-3.3.0/
[root@master hadoop-3.3.0]# ls
bin etc include lib libexec LICENSE-binary licenses-binary LICENSE.txt NOTICE-binary NOTICE.txt README.txt sbin share配置环境变量(三台机器都执行)
[root@master sbin]# tail -n2 /etc/profile
export HADOOP_HOME=/root/hadoop-3.3.0/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master sbin]# source /etc/profile
[root@master ~]# cd hadoop-3.3.0/etc/hadoop/
[root@master hadoop]# ls
capacity-scheduler.xml hadoop-env.sh hdfs-site.xml kms-env.sh mapred-env.sh ssl-server.xml.example yarnservice-log4j.properties
configuration.xsl hadoop-metrics2.properties httpfs-env.sh kms-log4j.properties mapred-queues.xml.template user_ec_policies.xml.template yarn-site.xml
container-executor.cfg hadoop-policy.xml httpfs-log4j.properties kms-site.xml mapred-site.xml workers
core-site.xml hadoop-user-functions.sh.example httpfs-site.xml log4j.properties shellprofile.d yarn-env.cmd
hadoop-env.cmd hdfs-rbf-site.xml kms-acls.xml mapred-env.cmd ssl-client.xml.example yarn-env.sh配置HDFS集群,我们主要涉及到如下文件的修改:
- workers: 配置从节点(DataNode)有哪些
- hadoop-env.sh: 配置Hadoop的相关环境变量
- core-site.xml: Hadoop核心配置文件
- hdfs-site.xml: HDFS核心配置文件
hadoop-env.sh文件
文件中设置的是hadoop运行时的环境变量 JAVA_HOME 是必须设置的#配置jdk的运行环境
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-2.el7_9.x86_64/
#以上配置完成后,在文件最后加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml
<configuration><property><!--namenode所在节点,集群启动会读取该文件确定namenode节点位置--><name>fs.defaultFS </name><value>hdfs://master:8020</value></property><!--设置hadoop本地保存数据的--><property><name>hadoop.tmp.dir</name><value>/data/hadoop-3.3.0</value></property><!--设置HDFS web UI用户身份--><property><name>hadoop.http.staticuser.useer</name><value>root</value></property></configuration>hdfs-site.xml
<property><!--设置SNN进程运行机器位置信息--><name>dfs.namenode.secondary.http-address</name><value>node:9868</value></property>mapred-site.xml
[root@master hadoop]# cat mapred-site.xml <configuration><!--设置MR程序默认运行模式,yarn集群模式 local本地模式--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--MR程序历史服务器端地址--><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><!--历史服务器web端地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>[root@master hadoop]# cat workers
master
node
ubuntu[root@master ~]# scp -r hadoop-3.3.0 node:/root/
[root@master ~]# scp -r hadoop-3.3.0 ubuntu:/root/初始化hadoop
只能在master节点上进行初始化
[root@master ~]# hdfs namenode -format
[root@master ~]# hdfs namenode -format
2025-05-30 23:55:49,677 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.12.135
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.0
STARTUP_MSG: classpath = /root/hadoop-3.3.0//etc/hadoop:/root/hadoop-3.3.0//share/hadoop/common/lib/zookeeper-jute-3.5.6.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/avro-1.7.7.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/protobuf-java-2.5.0.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/javax.activation-api-1.2.0.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/hadoop-auth-3.3.0.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/commons-math3-3.1.1.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/kerby-pkix-1.0.1.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/log4j-1.2.17.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/jetty-webapp-9.4.20.v20190813.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/jersey-servlet-1.19.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/audience-annotations-0.5.0.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/jcip-annotations-1.0-1.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/jetty-server-9.4.20.v20190813.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/kerb-simplekdc-1.0.1.jar:/root/hadoop-3.3.0//share/hadoop/common/lib/accessors-smart-1.2.jar:/root/hadoop配置免密
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id node
[root@master ~]# ssh-copy-id ubuntu
启动
[root@master ~]# start-all.sh验证
[root@master ~]# jps
4210 ResourceManager
7427 DataNode
7925 NodeManager
7292 NameNode
8141 Jps
[root@node hadoop]# jps
3347 NodeManager
3160 DataNode
3243 SecondaryNameNode
3983 Jpsroot@localhost:~/hadoop-3.3.0/etc/hadoop# jps
5702 DataNode
6551 Jps
5835 NodeManagerwin做三台机器的hosts解析此时就能访问hadoop集群了(HDFS)
yarn集群管理页面
单台如何加入hdfs集群
配置好之后,单独运行
hdfs --daemon start datanode
hdfs --daemon start namenode本机如何上传文件到hadoop集群
[root@node ~]# hadoop fs -mkdir /itcast
[root@node ~]# touch zookeeper.out
[root@node ~]# hadoop fs -put zookeeper.out /itcast
[root@node ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2025-06-03 17:55 /itcast[root@node ~]# hadoop fs /itcast/某个文件 删除某个文件
[root@node ~]# hadoop fs -rm -r /目录
此时就有了,web界面也可以直接上传下载
hdfs垃圾桶机制
HDFS的垃圾桶机制是一种允许用户在一定时间内恢复误删除文件的功能,通过将删除的文件暂时移至垃圾桶核心:将被删除的内容移动到回收站指定目录下,并保留源文件的所在目录作用:防止无删除重要文件开启HDFS的垃圾桶机制core-site.xml添加一段xml代码就可以实现[root@node hadoop]# grep -A 2 -B 1 'fs.trash.interval' core-site.xml <property><name>fs.trash.interval</name><value>1440</value> # 保存时间 单位:分钟 1440分钟</property> 其实 1440表示1440分钟,也就是24小时,一天的时间开启垃圾桶机制后,在使用-rm指令删除文件时,系统会自动将文件移动到 /user/root/.Trash/Current垃圾桶中同步到另外俩集群中在重启
[root@master hadoop]# stop-all.sh
[root@master hadoop]# start-all.sh[root@master ~]# hadoop fs -put hello.txt /itcast
[root@master ~]# hadoop fs -rm /itcast/hello.txt
2025-06-03 19:06:55,562 INFO fs.TrashPolicyDefault: Moved: 'hdfs://master:8020/itcast/hello.txt' to trash at: hdfs://master:8020/user/root/.Trash/Current/itcast/hello.txt此时在垃圾桶里面就能看到了
[root@master ~]# hadoop fs -ls /user/root/.Trash/Current/itcast
Found 2 items
-rw-r--r-- 3 root supergroup 0 2025-06-03 19:05 /user/root/.Trash/Current/itcast/hello.txt
-rw-r--r-- 3 root supergroup 0 2025-06-03 17:55 /user/root/.Trash/Current/itcast/zookeeper.out[root@master ~]# hadoop fs -mv /user/root/.Trash/Current/itcast/hello.txt /itcast/
[root@master ~]# 分块存储的好处
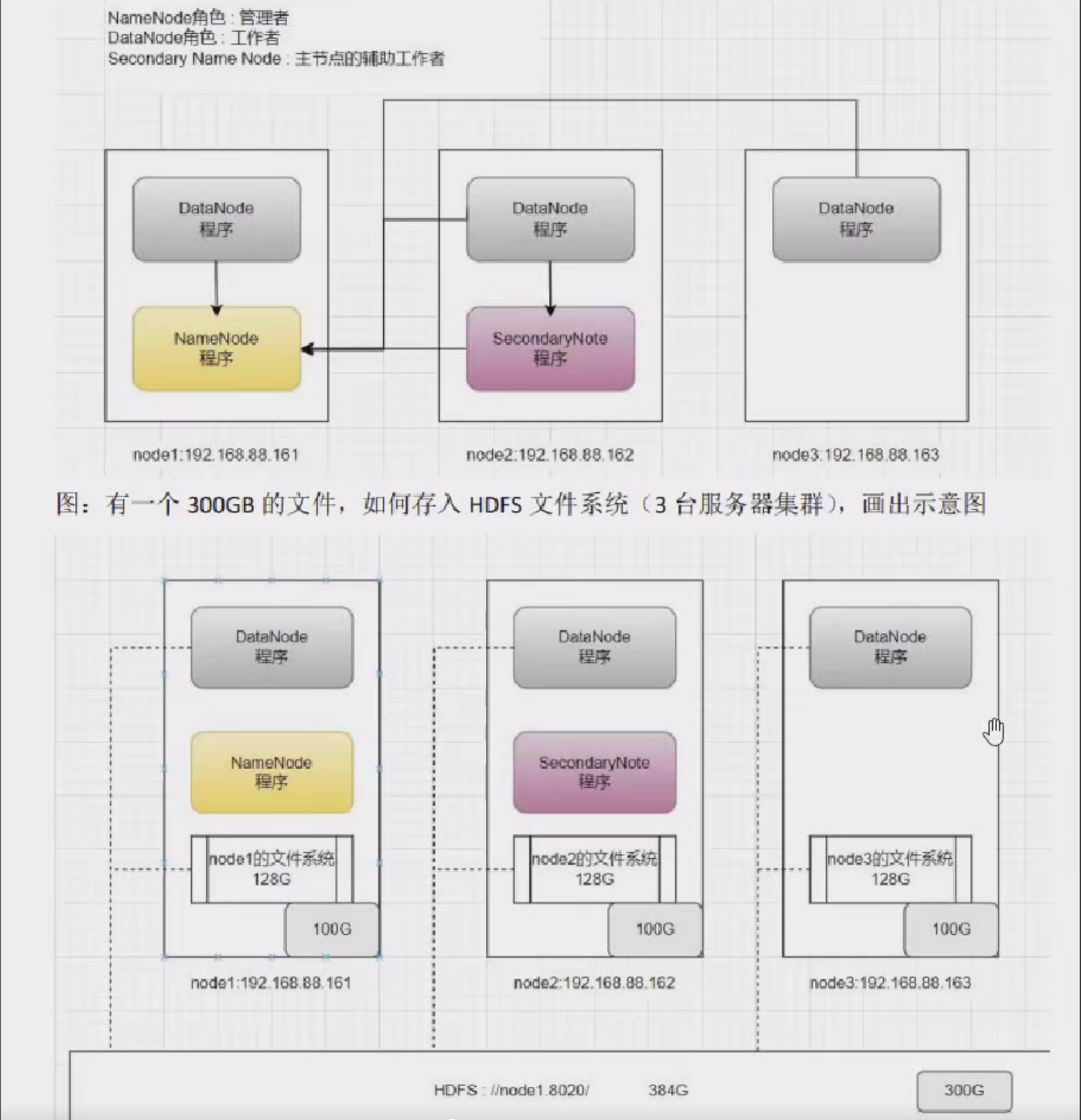
问题:文件过大导致单机存不下,上传下载效率低
解决:文件分块存储在不同机器,针对块并行操作提高效率
HDFS简介
HDFS主要是解决大数据如何存储问题的,分布式意味着是HDFS是横跨在多台计算机上的存储系统
HDFS是一种能够在普通硬件上运行的分布式文件系统,他是高度容错的,适应于具有大数据集的应用程序,他非常适用于存储大型的数据(比如TB和PB)
HDFS使用多台计算机存储文件,并且提供了统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统主从架构
HDFS集群是标准的master/slave主从架构
一般一个HDFS集群是有一个Namenode和一定数目的datanode组成
Namenode是HDFS主节点,Datanode是HDFS的从节点,两种角色各司其职,共同协调完成分布式存文件存储服务[root@master ~]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2025-06-03 19:19 /itcast
drwx------ - root supergroup 0 2025-06-03 18:20 /tmp
drwxr-xr-x - root supergroup 0 2025-06-03 18:20 /user
[root@master ~]# hadoop fs -ls hdfs://master:8020/
Found 3 items
drwxr-xr-x - root supergroup 0 2025-06-03 19:19 hdfs://master:8020/itcast
drwx------ - root supergroup 0 2025-06-03 18:20 hdfs://master:8020/tmp
drwxr-xr-x - root supergroup 0 2025-06-03 18:20 hdfs://master:8020/user
[root@master ~]# HDFS shell命令行
HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file://)、分布式文件系统(hdfs://nn:8020)等
如果没有指定前缀,则将会读取环境变量中的fs.defaultFS属性,以该属性值作为默认的文件系统1.追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> .. <dst>
将所有给定本地文件的内容追加到给定的dst文件
dst文件如果不存在,将创建该文件
[root@master ~]# echo 1 >> 1.txt
[root@master ~]# echo 2 >> 2.txt
[root@master ~]# echo 3 >> 3.txt
[root@master ~]# hadoop fs -put 1.txt /
[root@master ~]# hadoop fs -cat /1.txt
1
[root@master ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt
[root@master ~]# hadoop fs -cat /1.txt
1
2
32.查看HDFS集群剩余的空间
[root@master ~]# hadoop fs -df -h /
Filesystem Size Used Available Use%
hdfs://master:8020 171.7 G 128.0 K 143.2 G 0%3.文件移动
[root@master ~]# hadoop fs -mv /1.txt /itcast
[root@master ~]# hadoop fs -ls /itcast
Found 2 items
-rw-r--r-- 3 root supergroup 6 2025-06-04 01:18 /itcast/1.txt
-rw-r--r-- 3 root supergroup 0 2025-06-03 19:05 /itcast/hello.txt4.修改HDFS文件副本个数
hadoop fs -setrep [-R] [-w] <rep> <path> ..
修改指定文件的副本数
-R表示递归
-W 客户端是否等待副本修改完毕
[root@master ~]# hadoop fs -ls /itcast
Found 2 items
-rw-r--r-- 3 root supergroup 6 2025-06-04 01:18 /itcast/1.txt
-rw-r--r-- 3 root supergroup 0 2025-06-03 19:05 /itcast/hello.txt
[root@master ~]# hadoop fs -setrep -w 2 /itcast/1.txt
Replication 2 set: /itcast/1.txt
Waiting for /itcast/1.txt ...
WARNING: the waiting time may be long for DECREASING the number of replications.
. done
[root@master ~]# hadoop fs -ls /itcast
Found 2 items
-rw-r--r-- 2 root supergroup 6 2025-06-04 01:18 /itcast/1.txt
-rw-r--r-- 3 root supergroup 0 2025-06-03 19:05 /itcast/hello.txtHDFS集群角色
NameNode是hadoop分布式文件系统的核心,架构中的主角色
NameNode维护和管理元数据,包括名称空间目录树结构,文件和块的位置信息,访问权限等信息
NameNode是访问HDFS的唯一入口
NameNode内部是通过内存和磁盘两种方式来管理元数据从角色
Datanode是hadoop HDFS中的从角色,负责具体的数据块的存储
Datanode的数量决定了HDFS集群的整体数据存储能力,通过和NameNode配合维护着数据块主角色辅助角色:secondaryNameNode
除了Datanode和NameNode之外,还有一个守护进程,他称之为secondary NameNode,他充当NameNode的辅助节点,但不能代替NameNode
当NameNode启动时,NameNode合并fsimage和edits log文件以还原当前文件系统命名空间,如果edits log过大不利加载,secondary NameNode就辅助NameNode从NameNode下载simage文件和edits log文件进行合并
ZooKeeper使用场景
官网:https://zookeeper.apache.org/ZooKeeper 是一个分布式服务框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:命名服务、状态同步、配置中心、集群管理等。命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别命名服务是分布式系统中比较常见的一类场景。命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等——这些我们都可以统称它们为名字(Name),其中较为常见的就是一些分布式服务框架(如 RPC、RMI)中的服务地址列表,通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等状态同步
每个节点除了存储数据内容和 node 节点状态信息之外,还存储了已经注册的APP 的状态信息,当有些节点或 APP 不可用,就将当前状态同步给其他服务。配置中心
分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。现在我们大多数应用都是采用的是分布式开发的应用,搭建到不同的服务器上,我们的配置文件,同一个应用程序的配置文件一样,还有就是多个程序存在相同的配置,当我们配置文件中有个配置属性需要改变,我们需要改变每个程序的配置属性,这样会很麻烦的去修改配置,那么可用使用 ZooKeeper 来实现配置中心,ZooKeeper 采用的是推拉相结合的方式: 客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher 事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据。
zookeeper集群介绍
