线性模型选择中容易被忽视的关键洞察
在机器学习实践中,许多从业者会直接跳入模型调参阶段,却忽略了一个根本性的问题:数据是如何生成的?理解数据生成过程(Data Generating Process, DGP)是区分优秀建模者与普通从业者的关键能力。
本文将系统阐述这一被严重低估的核心技能,它能帮助你在建模时建立清晰的思维框架,做出更有理论依据的决策。
破除模型选择的迷思
首先需要明确:没有任何模型是“放之四海而皆准”的魔法解决方案。以泊松回归为例,它的优越性并非来自算法本身的复杂性,而是因为它正确反映了数据的统计特性。当我们使用标准线性回归时,隐含假设了:
-
响应变量服从正态分布
-
方差具有同质性
-
预测值与误差项相互独立
然而,当处理计数型数据(如网站访问量、疾病发病率)时,这些假设往往被违背——数据呈现明显的右偏分布、方差随均值变化等特征。这正是泊松回归的设计前提:它假设数据来自泊松过程,其概率质量函数为:

系统化的建模方法论
基于DGP的建模应遵循以下科学流程:
数据勘探阶段
-
绘制响应变量的直方图与QQ图
-
计算过离散指数(方差/均值比)
-
检验零膨胀现象
模型匹配阶段
-
正态分布特征 → 线性回归
-
计数数据且均值≈方差 → 泊松回归
-
二分类结果 → 逻辑回归
-
超过20%零值 → 零膨胀模型
-
时间依赖性 → 广义估计方程(GEE)
验证阶段
-
残差模式分析
-
似然比检验
-
AIC/BIC跨模型比较

广义线性模型的理论统一性
GLM框架完美诠释了DGP与模型选择的内在联系。包括三个组成部分:
-
随机成分(响应变量分布)
-
系统成分(线性预测器)
-
连接函数
不同分布假设直接推导出各类回归模型:
| 数据特征 | 分布假设 | 连接函数 | 适用模型 |
|---|---|---|---|
| 连续型,对称分布 | 正态分布 | 恒等连接 | 线性回归 |
| 计数型,均值=方差 | 泊松分布 | 对数连接 | 泊松回归 |
| 二元分类 | 伯努利分布 | Logit连接 | 逻辑回归 |
| 超过离散计数 | 负二项分布 | 对数连接 | 负二项回归 |

例如:
● 如果数据生成过程遵循正态分布 → 线性回归模型。
● 如果响应变量仅包括正整数数据,可能来自泊松分布 → 泊松回归。
● 如果数据仅包括0和1两个目标值,可能由伯努利分布生成 → 逻辑回归。
● 如果数据具有有限且固定的分类(0,1,2,…n),则由二项分布生成 → 二项式回归。
是否明白了?每个线性模型都基于某种假设,并源自其底层的数据生成过程。
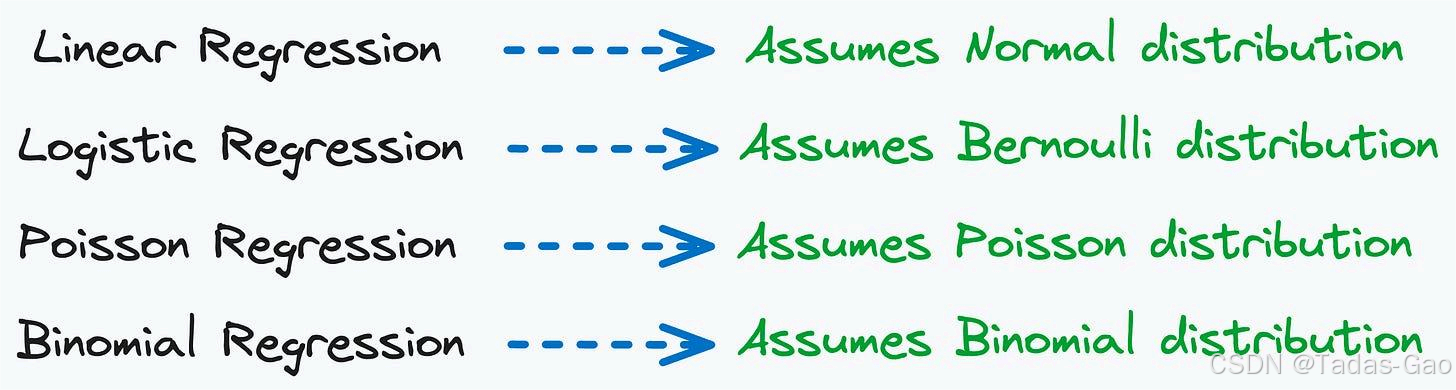
因此,养成稍作停顿、思考数据生成过程的习惯,将使你在建模阶段受益良多。
专业实践的价值提升
培养DGP思维将带来三重提升:
-
决策透明度:能清晰解释为什么选择特定模型而非"因为大家都用这个"
-
诊断效率:当模型表现不佳时,能快速定位是分布假设错误还是特征工程问题
-
结果可信度:在学术论文或商业报告中,完善的DGP分析能显著增强结论说服力
实际案例:在预测保险索赔次数的任务中,忽略索赔数据典型的过离散特性(方差>均值)而直接使用泊松回归,会导致标准误被严重低估。此时应选用负二项回归或考虑零膨胀模型,这直接源于对索赔数据生成机制的深入理解。
认知升级的长期收益
当这种思维成为本能,你将发现:
-
能够预判模型可能违反的假设
-
可以设计更合理的模拟数据验证方案
-
在阅读学术论文时能快速抓住模型选择逻辑
-
面对非标准数据时能灵活构建定制化解决方案
这正是一个数据科学家从"调参工程师"成长为"问题解决者"的关键跃迁。记住:优秀的建模不是从算法开始,而是从理解你的数据如何诞生开始。
扩展阅读
- 学习大模型,到底要学什么?-CSDN博客
- 关于大模型的认知升级-CSDN博客