DexUMI:以人手为通用操作界面,实现灵巧操作
25年5月来自斯坦福大学、哥伦比亚大学、JP Morgan 研究、CMU 和 Nvidia 的论文“DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation”。
DexUMI——一个数据收集和策略学习框架,它使用人手作为自然界面,将灵巧的操作技能转移到各种机械手上。DexUMI 包括硬件和软件适配,以最大限度地缩小人手和各种机械手之间的具体差距。硬件适配使用可穿戴手的外骨骼来弥合运动学差距。它允许在操作数据收集中提供直接触觉反馈,并使人体运动适应可行的机械手运动。软件适配通过用高保真机械手修复替换视频数据中的人手来弥合视觉差距。在两个不同的灵巧机械手硬件平台上进行全面真实实验,展示了 DexUMI 的能力,平均任务成功率达到 86%。
人类的双手在各种任务中都极其灵巧。灵巧机器人手的设计初衷就是为了复制这种能力。然而,由于两者之间存在巨大的具体差异,将技能从人手转移到机器手上仍然是一项艰巨的挑战。这种差异体现在多个方面,例如运动结构、接触面形状、可用的触觉信息以及视觉外观等方面的差异。
当今灵巧手硬件设计的多样性使这一挑战更加复杂。每只机械手在自由度、电机范围、驱动机制和整体尺寸方面都呈现出不同的工程权衡。缩小具身差距的解决方案必须能够应对巨大的硬件设计空间。遥操作已成为灵巧手的一种流行操作界面。然而,由于空间观察不匹配和缺乏直接触觉反馈,遥操作可能会变得困难。当人手能够直接执行操作任务时,这些问题就不会存在。换句话说,人手本身就是一个更好的操作界面。
遥操作:遥操作是一种流行的灵巧操作界面。手部控制可以通过动作捕捉手套[21–25]、虚拟现实设备[26–28]或基于摄像头的追踪[29–35]实现。大多数方法采用基于优化的重定向将人类指尖映射到机器人手上。虽然重定向技术可以适应不同的机器人平台,但它难以应对人手和机器人手之间的根本形态差异,尤其是拇指的灵活性[36]。周等人[37]最近的研究引入了一种用于直接关节映射的手外骨骼,但机械结构差异限制了映射精度。此外,遥操作或动觉教学[38]需要机器人硬件,这限制了数据收集的灵活性。相比之下,DexUMI 无需实体机器人即可收集操作数据。
人手视频:从人手视频中学习操作技能是一个颇具吸引力的方向。先前的研究探索了学习affordance [39–42] 或从视频中提取人体和物体姿态 [43– 47]。尽管取得了令人鼓舞的成果,但其中许多研究要么需要额外的现实世界机器人数据,要么需要在模拟环境中学习策略,并依赖于特殊信息(例如物体姿态)来在现实世界中部署策略。
可穿戴设备:另一项研究专注于设计用于数据收集的可穿戴设备,例如便携式手持式夹持器 [1–3, 48–57]。这些方法在扩展真实机器人操作技能方面已显示出良好的效果。然而,这些系统主要针对简单的并行/夹持夹持器,不易适应多指系统。Dexcap [58] 使用动作捕捉手套进行接触式数据收集。然而,它仍然依赖于重定向方法和通过远距传送进行的人为校正数据。相比之下,我们的方法消除了这些要求,能够使用通过 DexUMI 收集的数据直接部署策略。最近,Wei 和 Xu [59] 以及 Fang 等人[60] 提出了用于灵巧手的手拉手系统。这些工作需要真实的机械手可用并由人手举起。
本文提出一个问题:如何才能最大限度地缩小具身差距,以便将人手作为各种机械手的通用操作界面?
为了回答这个问题,DexUMI,一个包含硬件和软件自适应组件的框架,旨在最大限度地缩小动作和观察差距,如图所示。硬件适配采用可穿戴式外骨骼手部结构。用户佩戴时可直接收集操作数据。该外骨骼通过硬件优化框架针对每个目标机械手进行设计,该框架优化外骨骼参数(例如连杆长度),使其与机械手手指轨迹紧密匹配,同时保持人手的可穿戴性。软件适配采用数据处理流程的形式,弥补人类演示和机器人部署之间的视觉观察差距。该处理流程首先使用视频分割技术从演示视频中移除人手和外骨骼,然后使用与目标动作匹配的机械手和环境背景对视频进行修复。尽管人手和机械手之间存在视觉差异,但这种适配确保训练和机器人部署之间的视觉输入一致性。

外骨骼机构设计
现代机械手通常在解剖学上与人手非常相似,这意味着外骨骼会与佩戴它的人手争夺空间。最大的挑战在于拇指,其旋前-旋后运动会扫过很大的空间,并导致拇指与设计简单的外骨骼之间发生严重碰撞。
本文外骨骼设计有两个目标:
- 共享关节动作映射:外骨骼和目标机械手必须共享相同的关节到指尖位置映射,包括其限值,以便动作能够迁移。
- 可穿戴性:外骨骼必须允许用户手部进行足够自然的运动。
虽然第一个目标可以用数学方法定义,但可穿戴性目标却很难具体地写下来。解决方案是参数化外骨骼设计,并将可穿戴性要求作为设计参数的约束条件,然后通过优化求解,找到既能满足可穿戴性要求又能保持运动学关系的解决方案。
为了使优化方案切实可行,优先考虑指尖连杆的精确运动学特性,同时赋予不易接触物体的连杆更大的运动学灵活性。
E.1 设计初始化:用基于URDF文件的参数化机械手模型初始化设计(如图所示)。当此类详细设计不可用时(例如,Inspire-Hand的手指机构),会用具有相同自由度的等效通用连杆设计(例如,四连杆)代替,并进行优化以找到与观察的运动学行为最匹配的参数。
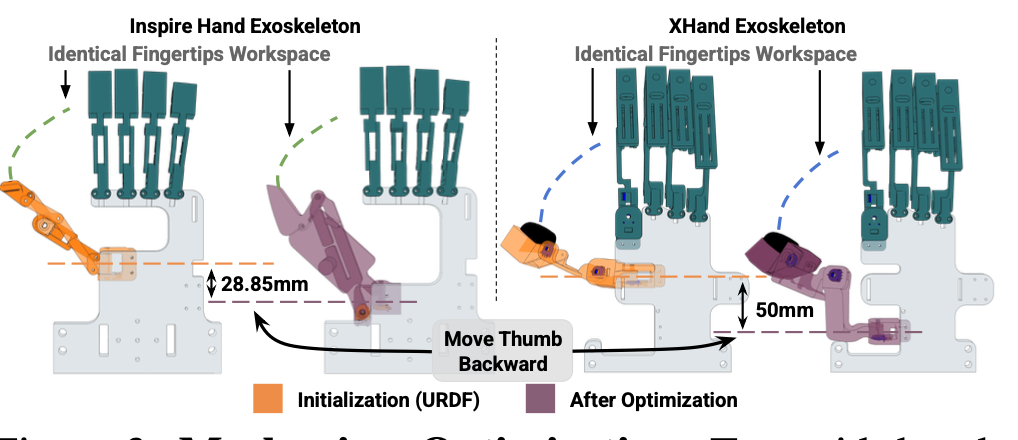
E.2 双层优化目标:优化目标是最大化以下相似度:max_p S(Wtip_exo §, Wtip_robot),其中 Wtip_exo 和 Wtip_robot 分别表示外骨骼和机械手的指尖工作空间(在 SE(3) 中所有可能的指尖姿势集合)。p = {j_1,…,j_n, l_1,…,l_m} 是外骨骼设计参数,包括腕坐标(即法兰)中的关节位置 j_i 和连杆长度 l_j。函数 S (·, ·) 表示两个工作空间之间的相似性度量,它量化外骨骼的指尖姿势分布与机械手的指尖姿势分布的匹配程度。在实践中,通过从两个工作空间中采样配置来实现 S (·, ·) 的最小化。给定一组 K 个机器人手配置 θ_robot,k 和 N 个外骨骼配置 θ_exo,n:
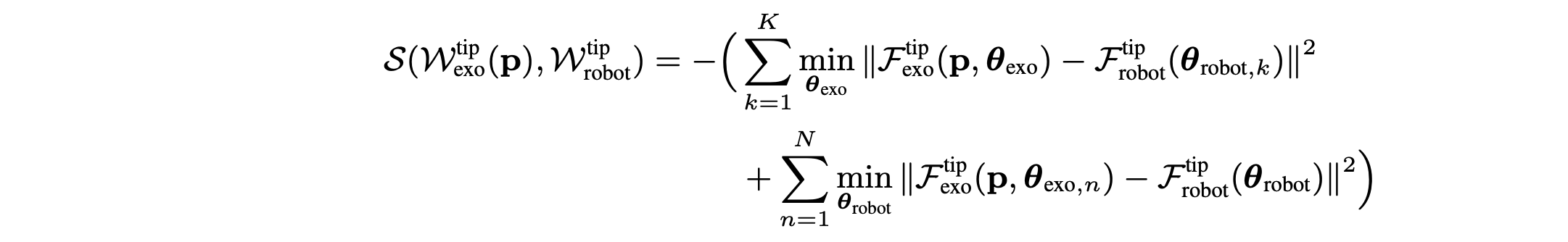
优化第一项可使外骨骼通过寻找与采样机械手配置最接近的外骨骼配置来覆盖机械手的工作空间。第二项要求 Wtip_exo § ⊆ Wtip_robot,以确保外骨骼的指尖工作空间保持在机械手的能力范围内,防止产生在机械手工作空间之外无法到达的姿势。
E.3 约束:应用边界约束 j_i ∈ C_i 和 lmin_j ≤ l_j ≤ lmax_j,这些约束是根据经验选择的,以确保外骨骼佩戴舒适。例如,希望在 MANO [61] 约定下,将拇指摆动关节沿 x 轴移近手腕,以避免人类拇指的旋前-旋后运动与外骨骼的运动发生碰撞。
外骨骼设计如图所示:
传感器集成
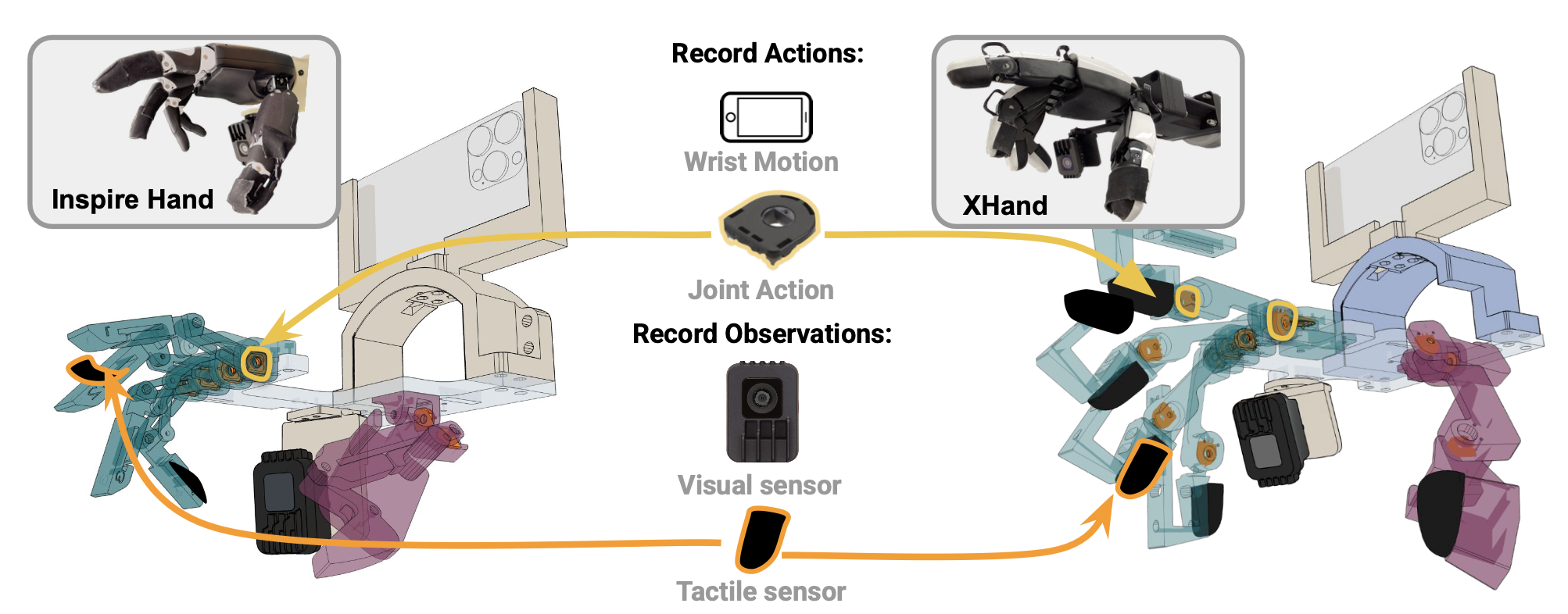
外骨骼上的传感器需要满足以下设计目标:
- 捕获足够的信息:传感器需要捕获策略学习所需的所有信息,包括:机器人动作,例如关节角度(S.1)和腕部运动(S.2),以及视觉(S.3)和触觉(S.4)的观察结果。
- 最小化具身差距:传感信息在人类演示和机器人部署之间的分布偏移应最小。
S.1 关节捕获与映射。为了精确捕获关节动作,外骨骼在每个驱动关节处都集成关节编码器——XHand 和 Inspirehand 均使用电阻式位置编码器。选择 Alps 编码器 [62] 来确保其尺寸和精度。由于关节摩擦和电机间隙,外骨骼关节编码器 θi_exo 和机器人手电机 Mi_robot 值之间的映射通常是非线性的,因此,为每个关节训练一个简单的回归模型来获得这种映射。为了标定回归模型,在实体机器人上均匀采样每个手指的 K 个运动值来收集一组配对数据,然后通过叠加机械手和外骨骼之间的视觉观察来找到相应的外骨骼关节值。此过程为训练回归模型创建一个配对数据集。
S.2 腕部姿态追踪。用 iPhone ARKit 捕捉 6DoF 腕部姿态,因为智能手机是最易于获取的能够提供精确空间追踪的设备。此追踪设备仅用于数据收集,机器人部署时无需使用。
S.3 视觉观察。在腕部下方安装了一个 150° 对角线视场 (DFoV) 广角摄像头 OAK-1 [63],用于外骨骼和目标机器人灵巧手。选择此位置是为了有效捕捉手与目标的交互。至关重要的是,腕部框架内外骨骼和机械手的摄像头姿态相同,从而保持训练和部署之间的视觉一致性。
S.4 触觉感知。可穿戴外骨骼允许用户直接接触目标并接收触觉反馈。然而,这种人类触觉反馈无法直接传递到机械灵巧手。因此,在外骨骼上安装触觉传感器,以捕捉和转换这些触觉交互。为了确保传感器读数的一致性,在外骨骼上安装与目标机械手相同类型的触觉传感器。对于 XHand,用机械手自带的电磁触觉传感器。对于 Inspire-Hand,为外骨骼和机械手安装相同的电阻式触觉传感器——力敏电阻(Force Sensitive Resistor)[64]。
如图显示人类演示 (a) 和机器人部署 (h) 之间的视觉差距。为了弥合这一视觉差距,开发一套数据处理流程,将演示图像调整为机器人看到的机械手收集数据的图像。此适配过程使用现成的预训练模型来确保通用性。此适配过程分为四个步骤:
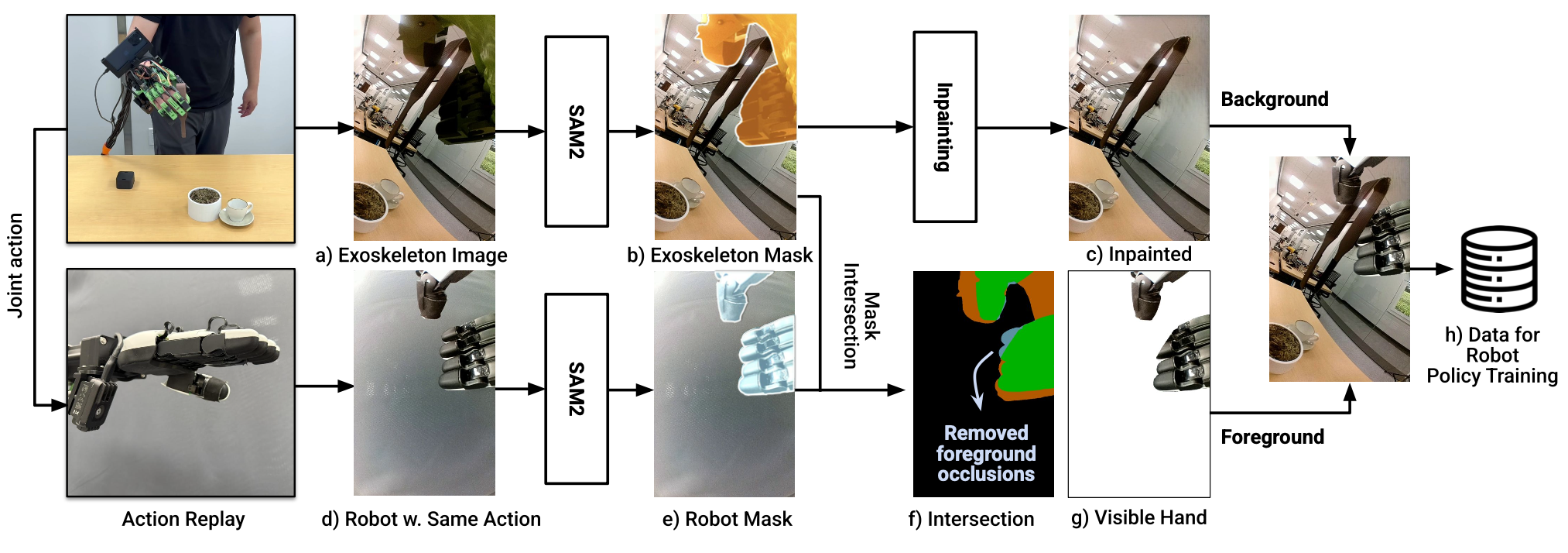
V.1 分割人手和外骨骼。首先,用 SAM2 [65] 在观察视频中分割人手和外骨骼(图 b)。由于 SAM2 需要初始提示点,建立一个协议,使操作员始终以相同的手势开始,从而允许在所有演示中重复使用相同的提示点。
V.2 修复环境背景。通过分割,从图像数据中移除人手和外骨骼像素。然后,用基于流的修复方法 ProPainter [66] 完全填充(图 c)缺失区域 [67–69]。
V.3 录制相应的机械手视频。接下来,为了将机械手正确地渲染到视频中,重放记录的机械手关节动作,并录制另一段仅包含机械手的视频(图 d)。此步骤不涉及机械臂。然后,再次使用 SAM2 提取机械手像素(图 e)并丢弃背景。需要注意的是,可以训练一个图像生成模型,根据动作输出机械手图像,但这需要额外的模型训练。
V.4 创作机器人演示。最后一步是将仅包含修复背景的视频与仅包含机械手的视频合并。保持适当的遮挡关系至关重要:机械手并不总是出现在上方。开发一种遮挡-觉察合成方法,该方法利用:(1) 一致的腕下摄像头设置,以及 (2) 外骨骼和机械手之间的运动学和形状相似性。通过将外骨骼遮挡和机械手遮挡相交来计算可见遮挡(图 f)。不是简单地覆盖像素,而是仅在可见遮挡中存在机械手像素的情况下,才选择性地用修复后的观察结果替换这些像素。从腕下摄像头的视角来看,这保留了手和物体之间自然的遮挡关系。这种方法生成视觉上连贯的机器人操作演示,并保持适当的空间关系。
模仿学习。模仿学习策略 p(a_t|o_t,f_t) 将处理后的视觉观察 o_t 和触觉感知 f_t 作为输入。输出是一系列动作 {a_t , … , a_t+L},长度为 L,从当前时间 t 开始,记为 a_t。a_t 处的机器人动作包括 6-DOF 末端执行器动作和 N-DOF 手部动作,其中 N 取决于具体的机器人手部硬件。
目标机械手:通过两种不同的机械手来评估 DexUMI:
• Inspire Hand (IHand):一只 12 自由度(6 个主动自由度)欠驱动机械手。拇指有两个主动自由度和两个被动自由度,其余每个手指分别有一个主动自由度和一个被动自由度。
• XHand:一只全驱动机械手,拥有 12 个主动自由度。拇指有三个自由度,食指有三个自由度,其余每个手指分别有两个自由度。
任务:通过四种不同的实际任务来评估 DexUMI(如图所示):

• 立方体 [IHand]:从桌子上拿起一个 2.5 厘米宽的立方体并将其放入杯中。这将评估 DexUMI 系统的基本功能和精度。
• 鸡蛋盒 [IHand]:用多根手指打开鸡蛋盒:机械手需要用食指、中指、无名指和小指向下按压纸盒顶部,同时用拇指提起前锁扣。
• 茶 [IHand 和 XHand]:从桌上抓取镊子,用它们将茶叶从茶壶移到杯中。主要的挑战在于如何稳定地操作可变形镊子,并实现多指接触。
• 厨房 [XHand]:该任务包含四个连续步骤:关闭炉灶旋钮(Knob Closing);将锅从炉灶顶部移到操作台;从容器中取盐(Salt Picking);最后,将盐撒在锅中的食物上。该任务测试 DexUMI 处理长视域任务的能力,包括精准动作、触觉感知以及指尖以外的技能。
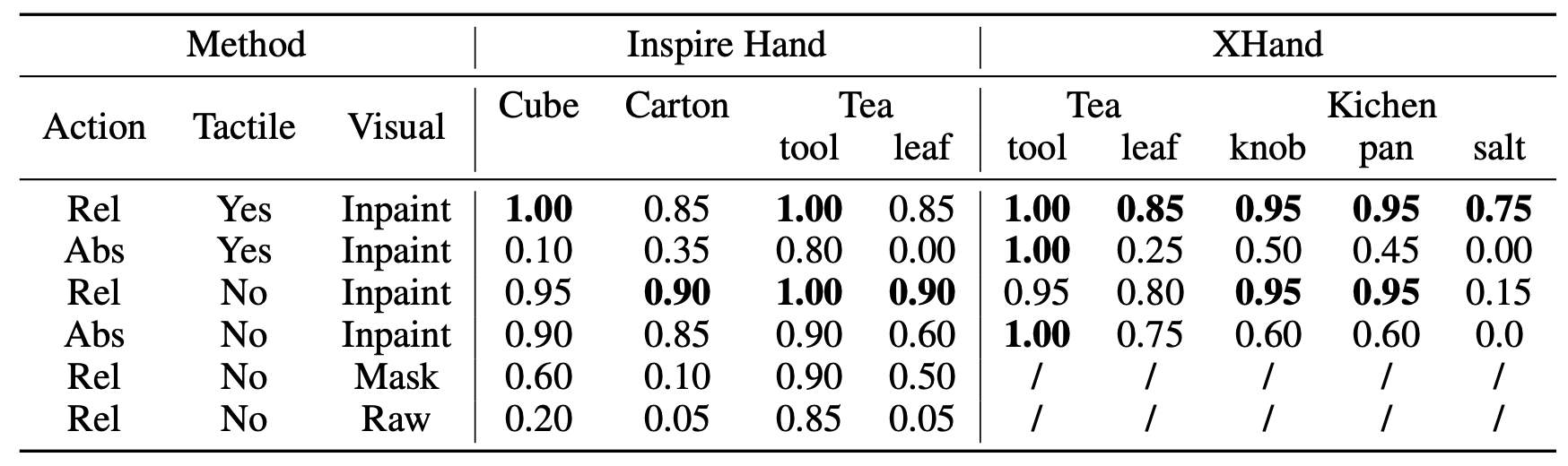
比较:评估策略动作空间选择、触觉感知和软件自适应对系统性能的影响。
• 相对手指动作 vs. 绝对手指动作:比较 [1] 中提出的手指动作轨迹的形式:绝对位置或相对轨迹。对于腕部动作,始终使用相对位置。
• 有触觉感知 vs. 无触觉感知:分别在有触觉传感器输入和无触觉传感器输入的情况下训练策略。
• 有软件适配 vs. 无软件适配:研究两种无软件适配的变体:(1) Mask,将外骨骼(训练期间)或机械手(推理期间)占用的像素替换为绿色掩码;(2) Raw,仅将包含外骨骼的未修改图像作为策略输入。
评估协议:对于每个评估回合,测试目标在初始化时随机放置在桌面上。为每个任务进行 20 个评估回合,并在该方法和所有基线中保持一致的初始目标配置。对于长周期任务,在下表中报告分阶段的累积成功率。
主要发现
DexUMI 框架支持高效的灵巧策略学习:如表所示,DexUMI 系统在两只机械手上执行的四项任务中均取得了较高的成功率。该系统能够处理精确操作、长时域任务和协调的多指接触,同时能够有效地泛化到各种操作场景中。
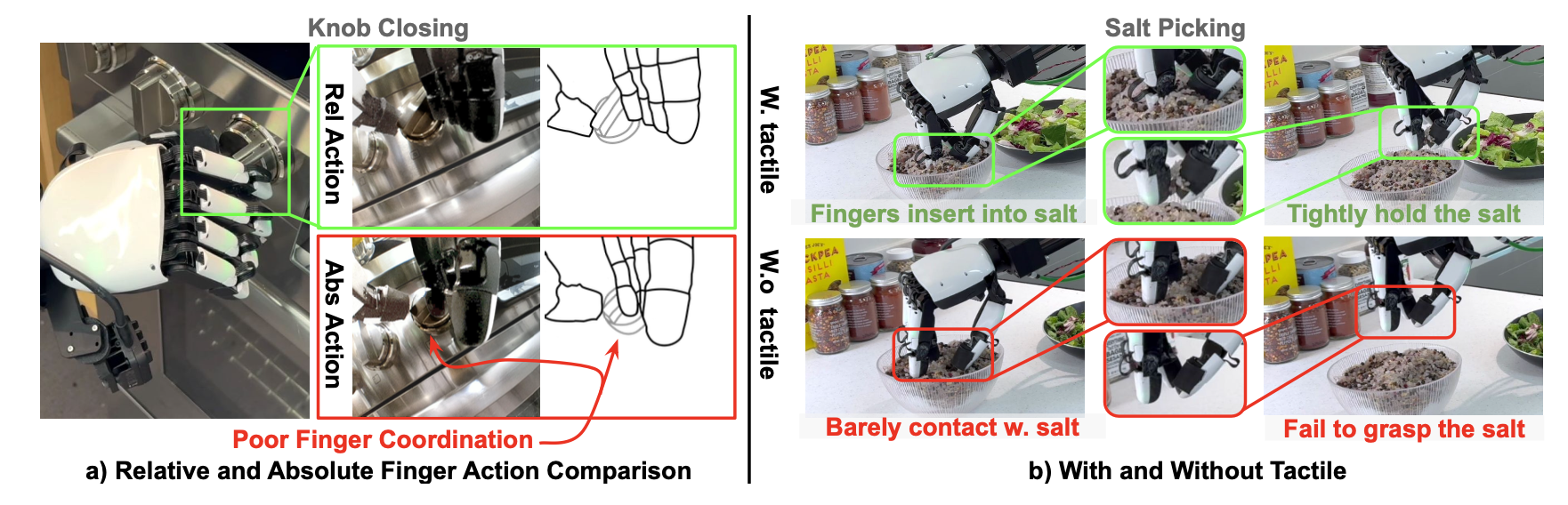
相对手指轨迹对噪声和硬件缺陷具有更强的鲁棒性:如表显示,相对手指轨迹在所有任务中始终都能取得更好的成功率。下图展现更多见解:相对轨迹可以使关键接触事件更加可靠。假设造成这种差异的两个原因:1. 相对动作比绝对动作具有更简单的分布,因此更容易学习;2. 相对动作学习的是一种反应行为,其中增量动作不断累积,直到发生关键事件(例如手指闭合接触)。然而,绝对动作学习的是静态映射,如果映射出现错误,则会停滞。
只有相对手指轨迹才能从嘈杂的触觉反馈中获益:上表中一个有趣的观察是,触觉对结果的影响有所不同。XHand 上的触觉传感器在承受高压后可能会发生漂移并变得不一致。因此,在大多数情况下,触觉会使结果更糟。只有相对轨迹才能使策略受益于这种触觉感知。对于 Inspire Hand,手动安装的触觉传感器噪声更大,添加触觉传感器作为输入后,所有方法的效果都会变差。然而,与绝对轨迹策略相比,相对轨迹策略的性能下降仍然较小。
触觉反馈可提高具有清晰力分布的任务的性能:试图了解哪些类型的任务会从触觉感知中受益。专注于 XHand,因为它的触觉传感器可以提供更清晰的读数。触觉反馈显著提高捡起盐的性能。这项任务凸显触觉的作用,因为 1) 当手指接触到盐碗时,触觉传感器会给出清晰、大的读数。2) 由于摄像头视野大部分被碗遮挡,抓取动作中几乎没有有用的视觉信息。在这种情况下,触觉反馈彻底改变策略行为。有了触觉传感器,手指总是先插入盐中,然后再合拢。如果没有触觉反馈,手指有时会试图在空中抓住盐。相反,触觉信息对镊子操作没有帮助,因为手部运动和力反馈之间缺乏很强的相关性。拿着镊子只会触发极少的触觉传感器读数。
DexUMI 框架实现高效的灵巧手数据收集:比较三种方式的数据收集效率:DexUMI、裸手和远程操作在采茶任务中的应用。同一个人类操作员在 15 分钟内使用每种方法收集数据。根据成功获取的演示次数计算了采集吞吐量(CT)。虽然 DexUMI 的速度仍然比直接人手操作慢,但其效率比传统的远程操作方法提高了 3.2 倍,显著缩短了灵巧操作数据采集所需的时间。
数据收集
收集了 310 条用于“立方体拾取”任务策略训练的轨迹、175 条用于“鸡蛋盒打开”任务策略训练的轨迹以及 400 条用于“使用工具拾取茶叶”任务策略训练的轨迹(针对 Inspire Hand 和 XHand)。对于厨房任务,收集了 370 条轨迹,涵盖所有四个子任务,另外还收集 100 条仅关注旋钮关闭的轨迹。
对于 Inspire Hand,所有类型的数据(包括来自 ARKit 的腕部位置、来自腕式摄像头的策略视觉观察、来自编码器的关节角度以及触觉反馈)均以 45 FPS 的速度记录。对于 XHand,以 30 FPS 的速度记录,因为触觉传感器读数在较高的记录频率下会变得不稳定。对于每种数据类型,都记录数据到达记录缓冲区时的接收时间戳 t/receive。
在使用外骨骼收集数据时佩戴绿色手套,因为使用绿色PLA-CF 3D打印外骨骼。一致的颜色有助于SAM2获得更好的分割结果。
训练数据延迟管理
传感器捕获数据和数据实际到达记录缓冲区之间存在固有延迟。为了确保模仿学习策略能够接收到正确对齐的观察结果(视觉观察、触觉传感器读数)和动作(关节编码器读数),用t/capture = t/receive − l/sensor计算实际数据捕获时间,其中l/sensor表示特定传感器从捕获到接收的延迟。通过读取计算机显示器上显示的滚动二维码来测量iPhone和OAK摄像头的延迟,该二维码显示当前计算机系统时间,正如UMI [1]中提出的。摄像头和iPhone的延迟计算公式为l/camera = t/receive − t/display − l/display,其中l/display表示显示器刷新率。
通过检查记录的外骨骼图像与动作回放中对应的机器人手图像之间的叠加图像来调整编码器延迟。如果编码器延迟设置过高,机器人手指将执行后续动作并提前进入叠加图像。如果编码器延迟设置过低,机器人手指在叠加图像中将落后于外骨骼手指。不断调整编码器延迟,直到外骨骼手指和机器人手指完全对齐。调整所有数据时间戳后,对关节角度和触觉读数进行线性插值,以获得与摄像头时间戳完全对齐的数据点。最后,将数据下采样 3 倍,以减少策略训练时间。
策略训练
用预训练的 DINO-V2 [76, 77] 处理视觉观测数据。在将视觉观测数据输入 DINO-V2 之前,对其进行随机裁剪、色彩抖动、随机灰度和高斯模糊等处理。将来自 DINO-V2 的 CLS token 与触觉传感器读数连接起来,作为扩散策略的输入 [78, 79]。该策略预测机器人动作的 16 个步骤,其中包含 6 自由度机器人末端执行器相对动作和手部动作(Inspire Hand 为 6 自由度,XHand 为 12 自由度)。针对两种手型在所有任务上训练 400 个 epoch。预训练的 DINO-V2 在策略训练期间不会冻结和更新。