机器学习监督学习sklearn实战三:八种算法对印第安人糖尿病预测数据进行分类和比较
本项目代码在个人github链接:https://github.com/KLWU07/Machine-learning-Project-practice/tree/main/3-Classification。
八种机器学习分类算法为逻辑回归LR、线性判别分析LDA、K近邻KNN、决策树CART、支持向量机SVM、朴素贝叶斯NB、随机森林RF、极端梯度提升XGBoost,并选用最好一种算法进行网格超参数优化。数据集和特征重要性分析、可视化、评估方法前面已有文章介绍,参考机器学习回归或分类数据预处理中特征重要性选择方法:纯python代码实现和机器学习分类算法模型性能的评估方法:数据集划分、交叉验证、准确率、性能指标、混淆矩阵、交叉熵损失。
一、项目代码描述
1.数据预处理:将Pima Indians糖尿病数据集中的特征和目标变量分开。
2.模型构建:定义了8种不同的分类模型。
3.模型评估:通过10折交叉验证评估每个模型的性能,并计算平均准确率和标准差。
4图表显示:使用箱线图比较不同模型的性能。
1.数据集
8 个特征(自变量) 和 1 个标签(因变量),共 9 列。
| 序号 | 特征名称 | 特征名称 | 说明 |
|---|---|---|---|
| 1 | preg | 怀孕次数 | 过去怀孕的次数 |
| 2 | plas | 血浆葡萄糖浓度 | 口服葡萄糖耐量试验中 2 小时的血浆葡萄糖浓度(mg/dL) |
| 3 | pres | 舒张压 | 血压(mm Hg) |
| 4 | skin | 三头肌皮肤褶皱厚度 | 三头肌皮肤褶皱厚度(mm),反映体脂率 |
| 5 | test | 血清胰岛素 | 2 小时血清胰岛素水平(μU/mL),数值越高可能胰岛素抵抗越严重 |
| 6 | mass | 体重指数(BMI) | 体重(kg)/(身高(m))^2 |
| 7 | pedi | 糖尿病家族史系数 | 糖尿病家族史的遗传易感性指标(基于亲代糖尿病史计算的权重值) |
| 8 | age | 年龄 | 年龄(岁) |
| 9 | class | 糖尿病诊断结果 | 标签 |
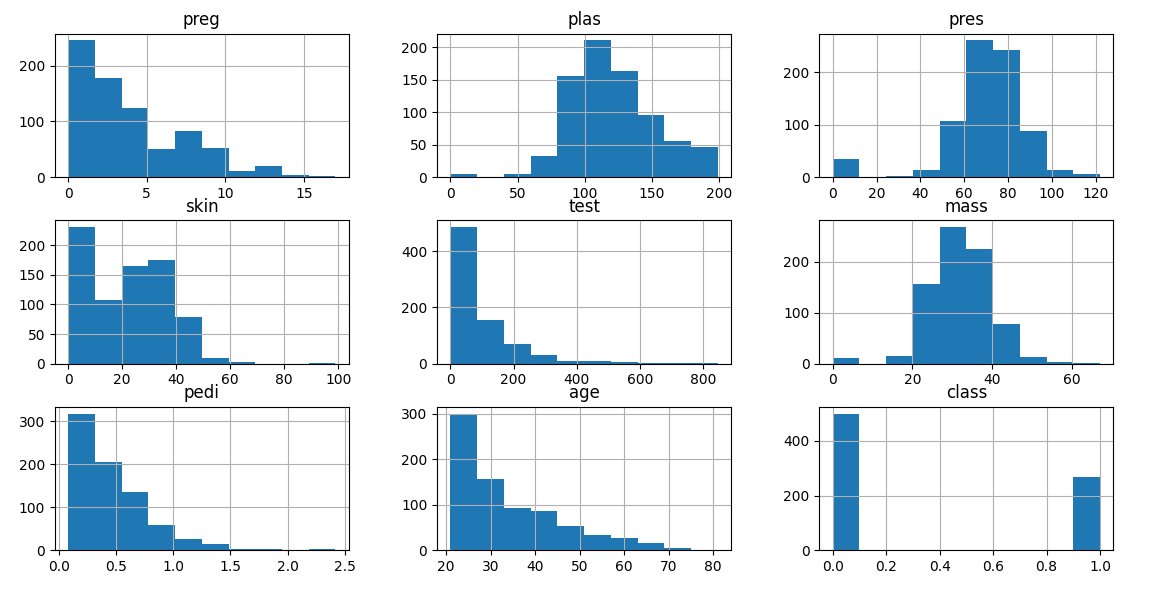
2.各特征的分布情况
3.准确率最高一组特征重要性(XGBoost)
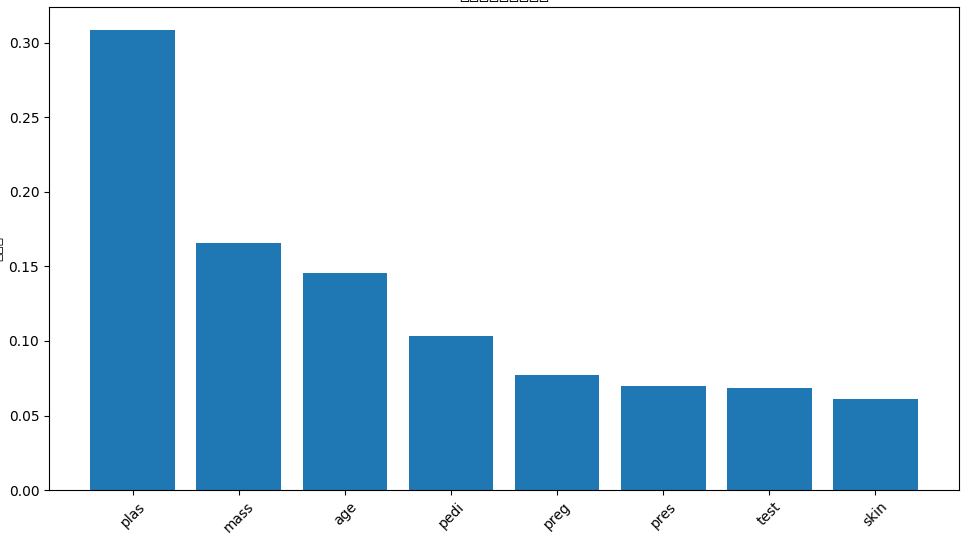
最高得分:0.781
最优参数:
max_depth: 9
max_features: sqrt
min_samples_leaf: 3
min_samples_split: 5
n_estimators: 156特征重要性排序:
1. plas: 0.3082
2. mass: 0.1659
3. age: 0.1458
4. pedi: 0.1035
5. preg: 0.0772
6. pres: 0.0696
7. test: 0.0688
8. skin: 0.0611
4.混淆矩阵
训练集:测试集比例=0.7:0.3
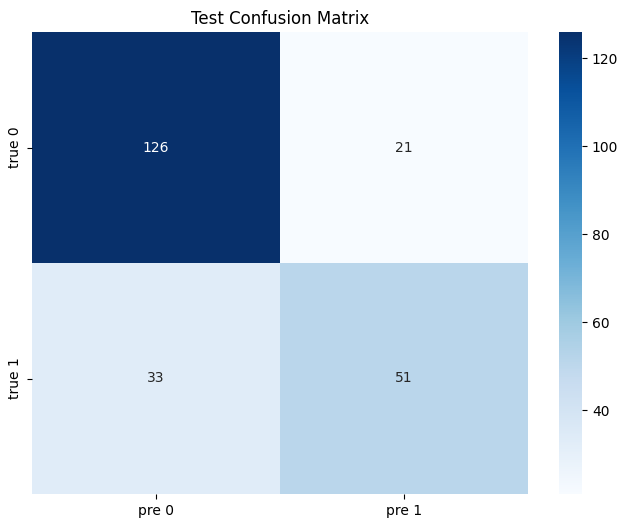
训练集准确率: 0.838
测试集准确率: 0.766
二、算法结果比较

1.K折交叉验证法(K=10)
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from matplotlib import pyplot# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)models = {}
models['LR'] = LogisticRegression(max_iter=1000)
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVC()
models['NB'] = GaussianNB()
models['RF'] = RandomForestClassifier(n_estimators=100, random_state=seed)
models['XGB'] = XGBClassifier(n_estimators=100, random_state=seed)results = []
for name in models:result = cross_val_score(models[name], X, Y, cv=kfold)results.append(result)msg = '%s: %.3f (%.3f)' % (name, result.mean(), result.std())print(msg)# 图表显示
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
```bash
LR: 0.772 (0.050)
LDA: 0.767 (0.048)
KNN: 0.711 (0.051)
CART: 0.688 (0.053)
SVM: 0.760 (0.035)
NB: 0.759 (0.039)
RF: 0.772 (0.055)
XGB: 0.727 (0.045)
2.K折交叉验证法(K=10)和数据标准化
LR: 0.773 (0.047)
LDA: 0.767 (0.048)
KNN: 0.740 (0.051)
CART: 0.689 (0.059)
SVM: 0.757 (0.056)
NB: 0.759 (0.039)
3.线性判别分析(LDA)降维
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from matplotlib import pyplot
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]# 设置交叉验证参数
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)# 定义模型
models = {}
models['LR'] = LogisticRegression(max_iter=1000)
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVC()
models['NB'] = GaussianNB()
models['RF'] = RandomForestClassifier(n_estimators=100, random_state=seed)
models['XGB'] = XGBClassifier(n_estimators=100, random_state=seed)# 创建Pipeline,包括标准化、LDA降维和模型
pipelines = {}
for name in models:pipelines[name] = Pipeline([('scaler', StandardScaler()), # 数据标准化('lda', LinearDiscriminantAnalysis()), # LDA降维('model', models[name]) # 模型])# 评估模型
results = []
for name in pipelines:result = cross_val_score(pipelines[name], X, Y, cv=kfold)results.append(result)msg = '%s: %.3f (%.3f)' % (name, result.mean(), result.std())print(msg)
LR: 0.770 (0.048)
LDA: 0.767 (0.048)
KNN: 0.740 (0.038)
CART: 0.672 (0.055)
SVM: 0.770 (0.045)
NB: 0.770 (0.050)
RF: 0.673 (0.053)
XGB: 0.753 (0.034)
4.随机森林算法、K折交叉验证和网格搜索最优参数
- 网格搜索寻找最优参数:可参考之前文章机器学习模型训练超参数优化使用sklearn库里网格搜索(Grid Search)方法所有参数含义解释和更多的方法机器学习做模型预测时超参数优化提升性能(降低评价指标)五种种方法:网格搜索、随机搜索、贝叶斯优化、遗传算法、基于梯度的优化。
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint# 导入数据
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:8]
Y = array[:, 8]# 算法实例化
model = RandomForestClassifier(random_state=7)# 设置要遍历的参数
param_dist = {'n_estimators': randint(50, 200), # 树的数量范围'max_depth': randint(3, 10), # 树的最大深度范围'min_samples_split': randint(2, 10), # 分裂内部节点所需的最小样本数'min_samples_leaf': randint(1, 5), # 叶节点所需的最小样本数'max_features': ['sqrt', 'log2', None] # 寻找最佳分割时要考虑的特征数量
}# 通过随机搜索查询最优参数
grid = RandomizedSearchCV(estimator=model,param_distributions=param_dist,n_iter=100,cv=10, # 使用10折交叉验证random_state=7,verbose = -1,n_jobs=-1 # 使用所有可用的CPU核心
)grid.fit(X, Y)# 搜索结果
print('最高得分:%.3f' % grid.best_score_)
print('最优参数:')
best_params = grid.best_params_
for param, value in best_params.items():print(f"{param}: {value}")
Fitting 10 folds for each of 1000 candidates, totalling 10000 fits
最高得分:0.775
最优参数:
max_depth: 20
max_features: sqrt
min_samples_leaf: 6
min_samples_split: 60
n_estimators: 13