NLP学习路线图(二十四):门控循环单元(GRU)
一、背景:RNN的困境与门控机制的曙光
-
RNN的基本原理:
-
RNN的核心思想是引入循环连接,使网络具有“记忆”功能。
-
在时刻
t,RNN接收当前输入x_t和前一个时刻的隐藏状态h_{t-1}。 -
通过一个共享的权重参数(
W,U,b)计算当前时刻的隐藏状态h_t:
h_t = tanh(W * x_t + U * h_{t-1} + b) -
隐藏状态
h_t包含了截止到时刻t的序列信息,可用于预测输出y_t(如词性标签)或传递给下一个时刻。
-
-
RNN的致命缺陷:梯度消失/爆炸
-
问题本质: RNN通过时间反向传播(BPTT)算法学习。在计算损失函数对较早时刻参数的梯度时,需要将梯度沿时间步连续相乘。
-
梯度爆炸: 当梯度乘积中的因子持续大于1时,梯度值会指数级增长,导致参数更新过大,模型无法收敛(可通过梯度裁剪缓解)。
-
梯度消失: 当梯度乘积中的因子持续小于1时(尤其在使用
tanh/sigmoid激活函数时),梯度值会指数级衰减到接近于零。这意味着:-
模型无法学习到长距离的依赖关系。较早时刻的输入对当前预测的影响几乎为零。
-
参数(尤其是影响早期输入的参数)几乎得不到有效的更新。
-
-
影响: 梯度消失严重限制了RNN处理长文本、理解复杂上下文的能力,使其在实际NLP任务中表现不佳。
-
-
解决之道:引入门控机制
-
长短期记忆网络(LSTM)首先成功引入了精妙的门控机制(输入门、遗忘门、输出门)和细胞状态(Cell State) 来解决梯度消失问题。
-
GRU在2014年由Cho等人提出,可以看作是LSTM的一种简化变体。它合并了LSTM的部分门和状态,使用更少的参数实现了与LSTM相当甚至更好的性能,尤其在中小型数据集上表现更优,计算效率也更高。
-
二、GRU:结构剖析与工作原理
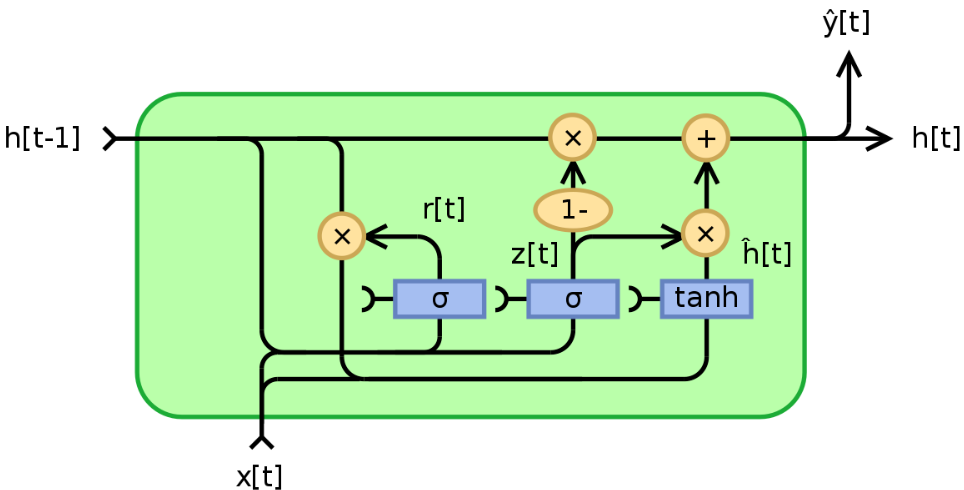
GRU的核心创新在于引入了两个门控单元:更新门(Update Gate) 和重置门(Reset Gate)。这些门使用sigmoid激活函数(输出0到1之间的值),控制着信息的流动和遗忘。
-
核心组件:两个门
-
更新门(
z_t): 决定当前时刻的隐藏状态h_t在多大程度上由候选隐藏状态\tilde{h}_t更新,以及在多大程度上保留前一个时刻的隐藏状态h_{t-1}。它控制着模型记忆的更新程度。
z_t = \sigma(W_z * x_t + U_z * h_{t-1} + b_z)(其中\sigma是sigmoid函数) -
重置门(
r_t): 决定前一个时刻的隐藏状态h_{t-1}在计算候选隐藏状态\tilde{h}_t时的重要性。它控制着模型“遗忘”或“忽略”多少过去的信息,以便更好地捕捉当前输入x_t的新信息。
r_t = \sigma(W_r * x_t + U_r * h_{t-1} + b_r)
-
-
候选隐藏状态(
\tilde{h}_t):-
这是基于当前输入
x_t和经过重置门筛选后的前一个状态r_t \odot h_{t-1}计算出的一个临时状态。重置门r_t的作用在这里体现:如果r_t接近0,则r_t \odot h_{t-1}接近0,意味着模型在计算新候选状态时“忘记”了大部分过去信息h_{t-1},主要依赖当前输入x_t(适用于序列中状态发生突变的情况)。如果r_t接近1,则几乎保留全部h_{t-1}(适用于状态连续变化的情况)。
\tilde{h}_t = tanh(W_h * x_t + U_h * (r_t \odot h_{t-1}) + b_h) -
注意:这里使用的是
tanh激活函数,将值压缩到(-1, 1)之间。
-
-
最终隐藏状态(
h_t):-
这是GRU在当前时刻
t的最终输出,也是传递给下一个时刻的“记忆”。 -
它由更新门
z_t控制,是前一个时刻隐藏状态h_{t-1}和候选隐藏状态\tilde{h}_t的加权组合:
h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t -
解读:
-
如果
z_t接近0:则h_t ≈ h_{t-1}。这意味着模型几乎完全保留了前一个时刻的状态,当前输入x_t对最终状态的影响很小(适用于当前信息不重要或冗余的情况)。 -
如果
z_t接近1:则h_t ≈ \tilde{h}_t。这意味着模型几乎完全采用了基于当前输入计算出的候选状态,而忽略了之前的记忆(适用于当前输入包含全新重要信息的情况)。 -
在0和1之间:
h_t是h_{t-1}和\tilde{h}_t的线性插值。更新门z_t精细地调节着“保留多少旧记忆”和“加入多少新信息”。
-
-
三、GRU如何解决梯度消失问题?
GRU解决梯度消失问题的关键在于其门控机制和隐藏状态更新方式创造了一条相对“畅通”的梯度传播路径:
-
加法更新 vs 乘法更新: RNN的核心公式
h_t = tanh(...)是一个复合函数,其梯度包含多个tanh导数的连乘,这是梯度消失的主要来源。而GRU的最终状态更新公式h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t是一个线性求和操作(h_{t-1}和\tilde{h}_t的加权和)。 -
梯度流的路径:
-
损失函数
L相对于h_{t-1}的梯度可以通过两条路径传播回来:-
直接路径 (Shortcut Path): 通过公式中的
(1 - z_t) \odot h_{t-1}项。梯度∂L / ∂h_t可以几乎无损地(乘以(1 - z_t))直接传递到∂L / ∂h_{t-1}。只要更新门z_t不总是接近1,这条路径就能让梯度相对稳定地流向更早的时刻,避免了RNN中因连乘导致的指数衰减。 -
间接路径 (Candidate Path): 通过
\tilde{h}_t(\tilde{h}_t依赖于h_{t-1}) 和z_t \odot \tilde{h}_t项。这条路径仍然包含非线性操作(tanh)和门控(z_t,r_t),梯度计算涉及乘法链,依然存在衰减或爆炸的风险。
-
-
-
主要贡献: 正是这条直接路径(Shortcut Path) 的存在,为梯度从
h_t流向h_{t-1}提供了一条高速公路,显著缓解了长距离依赖中的梯度消失问题。模型学习的主要目标之一,就是让更新门z_t学会在需要长期记忆时(z_t较小),充分利用这条直接路径。
四、GRU vs LSTM:异同与选择
GRU和LSTM是解决RNN梯度问题的两大主流方案,各有千秋:
| 特性 | LSTM (长短期记忆网络) | GRU (门控循环单元) |
|---|---|---|
| 核心状态 | 细胞状态 (c_t) + 隐藏状态 (h_t) | 隐藏状态 (h_t) (合并了记忆功能) |
| 门数量 | 3个:输入门(i_t)、遗忘门(f_t)、输出门(o_t) | 2个:更新门(z_t)、重置门(r_t) |
| 关键公式 | c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_th_t = o_t \odot tanh(c_t) | h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t |
| 参数数量 | 较多 (4组W/U/b参数) | 较少 (3组W/U/b参数) |
| 计算效率 | 稍慢 | 更快 |
| 主要优势 | 门控机制更精细,理论上对超长序列建模能力可能更强 | 结构更简洁高效,参数少,训练更快,在中小型数据集上常表现更优或相当 |
| 选择考量 | 任务对超长依赖要求极高;计算资源充足 | 计算效率优先;数据集规模有限; 模型需要更快收敛 |
五、GRU在NLP中的PyTorch实践:文本情感分析
让我们通过一个经典的NLP任务——IMDb电影评论情感分析(二分类:积极/消极),来实践如何使用PyTorch构建一个基于GRU的模型。
环境准备与数据加载
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy import data, datasets # 使用经典torchtext API# 设置随机种子确保可复现性
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True# 定义字段 (Field)
TEXT = data.Field(tokenize='spacy', # 使用spacy分词tokenizer_language='en_core_web_sm',include_lengths=True) # 包含文本实际长度,用于处理变长序列
LABEL = data.LabelField(dtype=torch.float)# 加载IMDb数据集
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)# 构建词汇表 (只考虑训练集中出现频率最高的25000个词)
MAX_VOCAB_SIZE = 25000
TEXT.build_vocab(train_data,max_size=MAX_VOCAB_SIZE,vectors="glove.6B.100d", # 使用预训练的100维GloVe词向量unk_init=torch.Tensor.normal_) # 初始化未登录词(OOV)
LABEL.build_vocab(train_data)# 创建数据迭代器 (Iterator),自动处理padding和batch
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data),batch_size=BATCH_SIZE,sort_within_batch=True, # 为了使用pack_padded_sequence需要按长度排序sort_key=lambda x: len(x.text),device=device)定义GRU模型 (GRUModel)
class GRUModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout_rate, pad_idx):super().__init__()# 词嵌入层 (Embedding Layer)self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)# GRU层 (GRU Layer)self.rnn = nn.GRU(embedding_dim,hidden_dim,num_layers=n_layers,bidirectional=False, # 这里使用单向GRUbatch_first=True) # 输入输出张量形状为 [batch, seq_len, features]# 全连接输出层 (Fully Connected Layer)self.fc = nn.Linear(hidden_dim, output_dim)# Dropout层self.dropout = nn.Dropout(dropout_rate)# 初始化嵌入层权重 (使用预训练词向量)self.embedding.weight.data.copy_(TEXT.vocab.vectors)# 将填充符`<pad>`的嵌入向量置零self.embedding.weight.data[pad_idx] = torch.zeros(embedding_dim)def forward(self, text, text_lengths):# text: [batch_size, sent_len]# text_lengths: [batch_size] (包含每个序列的实际长度)# 1. 词嵌入 (Embedding)embedded = self.dropout(self.embedding(text)) # embedded: [batch_size, sent_len, emb_dim]# 2. 打包序列 (Pack padded sequences) - 提高效率packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.cpu(), batch_first=True, enforce_sorted=False)# 3. 通过GRU层 (GRU Layer)packed_output, hidden = self.rnn(packed_embedded)# packed_output: 所有时间步的隐藏状态 (已打包)# hidden: 最后一个时间步的隐藏状态 [num_layers * num_directions, batch_size, hid_dim]# 由于是单向单层GRU, hidden: [1, batch_size, hid_dim]# 4. 解包序列 (Unpack packed sequence) - 可选,这里我们只需要最后一个有效时间步的隐藏状态# output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True)# 5. 获取最后一个有效时间步的隐藏状态作为整个序列的表示# hidden: [1, batch_size, hid_dim] -> 取第0层 -> [batch_size, hid_dim]hidden = self.dropout(hidden[0])# 6. 全连接层输出 (Fully Connected Layer)return self.fc(hidden) # output: [batch_size, output_dim (1)]模型实例化与参数设置
# 超参数
INPUT_DIM = len(TEXT.vocab) # 词汇表大小
EMBEDDING_DIM = 100 # 词向量维度 (与GloVe一致)
HIDDEN_DIM = 256 # GRU隐藏层维度
OUTPUT_DIM = 1 # 输出维度 (二分类)
N_LAYERS = 1 # GRU层数
DROPOUT_RATE = 0.5 # Dropout率
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 填充符索引# 创建模型实例
model = GRUModel(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, N_LAYERS, DROPOUT_RATE, PAD_IDX)
model = model.to(device)定义损失函数与优化器
# 损失函数:带Sigmoid的二元交叉熵损失 (BCEWithLogitsLoss)
criterion = nn.BCEWithLogitsLoss().to(device)
# 优化器:Adam
optimizer = optim.Adam(model.parameters())训练与评估函数
def train(model, iterator, optimizer, criterion):model.train() # 训练模式epoch_loss = 0epoch_acc = 0for batch in iterator:text, text_lengths = batch.text # text_lengths来自Field(include_lengths=True)optimizer.zero_grad() # 清零梯度predictions = model(text, text_lengths).squeeze(1) # [batch_size, 1] -> [batch_size]loss = criterion(predictions, batch.label) # 计算损失acc = binary_accuracy(predictions, batch.label) # 计算准确率loss.backward() # 反向传播optimizer.step() # 更新参数epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)def evaluate(model, iterator, criterion):model.eval() # 评估模式epoch_loss = 0epoch_acc = 0with torch.no_grad(): # 禁用梯度计算for batch in iterator:text, text_lengths = batch.textpredictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, batch.label)acc = binary_accuracy(predictions, batch.label)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)# 辅助函数:计算二分类准确率
def binary_accuracy(preds, y):rounded_preds = torch.round(torch.sigmoid(preds)) # 将概率四舍五入到0/1correct = (rounded_preds == y).float() # 转换为浮点数acc = correct.sum() / len(correct)return acc模型训练与结果
N_EPOCHS = 5
best_valid_loss = float('inf')for epoch in range(N_EPOCHS):train_loss, train_acc = train(model, train_iterator, optimizer, criterion)valid_loss, valid_acc = evaluate(model, test_iterator, criterion) # 这里用test做演示,实际应用需用验证集if valid_loss < best_valid_loss:best_valid_loss = valid_losstorch.save(model.state_dict(), 'gru-sentiment.pt') # 保存最佳模型print(f'Epoch: {epoch+1:02}')print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')print(f'\tValid Loss: {valid_loss:.3f} | Valid Acc: {valid_acc*100:.2f}%')预期输出示例 (训练几轮后):
Epoch: 01Train Loss: 0.692 | Train Acc: 50.12%Valid Loss: 0.693 | Valid Acc: 50.19%
Epoch: 02Train Loss: 0.686 | Train Acc: 54.89%Valid Loss: 0.684 | Valid Acc: 56.23%
Epoch: 03Train Loss: 0.671 | Train Acc: 59.12%Valid Loss: 0.666 | Valid Acc: 59.87%
Epoch: 04Train Loss: 0.645 | Train Acc: 64.05%Valid Loss: 0.632 | Valid Acc: 65.41%
Epoch: 05Train Loss: 0.617 | Train Acc: 66.78%Valid Loss: 0.605 | Valid Acc: 68.92%可以看到,随着训练的进行,训练损失和验证损失都在下降,准确率在提升,表明GRU模型成功学习到了从电影评论文本到情感倾向的映射关系。
模型推理示例
import spacy
nlp = spacy.load('en_core_web_sm')def predict_sentiment(model, sentence):model.eval()tokenized = [tok.text for tok in nlp.tokenizer(sentence.lower())] # 分词并小写化indexed = [TEXT.vocab.stoi[t] for t in tokenized] # 转换为索引length = [len(indexed)] # 句子长度tensor = torch.LongTensor(indexed).unsqueeze(1).T.to(device) # [1, seq_len]length_tensor = torch.LongTensor(length).to(device) # [1]prediction = torch.sigmoid(model(tensor, length_tensor)) # 计算概率return prediction.item()# 测试评论
positive_review = "This movie is absolutely fantastic! The acting was superb and the plot kept me engaged from start to finish."
negative_review = "What a waste of time. Terrible acting, nonsensical plot, and boring dialogue. Avoid this one."print(f'Positive review prediction: {predict_sentiment(model, positive_review):.4f}') # 期望接近1
print(f'Negative review prediction: {predict_sentiment(model, negative_review):.4f}') # 期望接近0输出示例:
Positive review prediction: 0.9321
Negative review prediction: 0.0874六、GRU的局限性与未来
尽管GRU在序列建模中取得了巨大成功,它也存在一些局限性:
-
顺序计算瓶颈: GRU(以及RNN/LSTM)本质上是顺序处理序列的。每个时间步的计算依赖于前一个时间步的结果,这限制了模型的并行计算能力,导致训练速度较慢,尤其是在处理超长序列时。
-
难以建模绝对位置信息: RNN族主要依靠循环来传递信息,位置信息隐含在时间步中。对于需要精确位置信息的任务(如问答中的答案定位),表现可能不如后来基于自注意力机制的模型。
-
Transformer的崛起: 以Transformer为代表的自注意力模型(如BERT, GPT)彻底打破了顺序计算的限制。它们通过全局注意力机制,允许序列中任意两个位置直接交互,并行化程度极高,在捕捉长距离依赖和上下文建模能力上展现出碾压性优势,已成为当前NLP的绝对主流架构。Transformer的Self-Attention机制本身可以看作是一种强大的“门控”机制。
GRU在当今NLP中的地位:
-
特定场景仍有价值: 在资源受限的移动端/嵌入式设备、对模型大小和计算延迟要求极高的场景、处理流式数据(如实时语音识别)或需要增量更新状态的任务中,GRU/LSTM因其循环特性仍有应用价值。
-
作为组件集成: 有时会被用作Transformer模型中的子模块(如处理时序信息)。
-
教学价值: 理解GRU/LSTM的门控机制对于深入掌握序列模型的设计思想和理解Transformer中门控思想(如前馈网络FFN中的门控线性单元GLU变种)仍有重要意义。
七、总结
门控循环单元(GRU)通过引入更新门和重置门,创造性地解决了传统RNN面临的梯度消失问题,使其能够更有效地学习和利用序列中的长距离依赖关系。其结构相对LSTM更简洁高效,参数更少,训练速度更快,在众多NLP任务(如机器翻译、文本生成、情感分析、命名实体识别)中取得了卓越的成果。本文详细解析了GRU的门控机制、工作原理、缓解梯度消失的原理,并通过PyTorch实战展示了其在文本情感分析任务中的应用。