从 CLIP 和 Qwen2.5-VL 入门多模态技术
什么是多模态对齐

多模态人工智能(Multimodal AI)领域中的一个核心概念是:模态对齐(Multimodal Alignment)。简单来说,多模态AI的目标是让机器能够理解和处理来自不同来源的信息,例如文本、图像、声音等(这些不同的信息来源就是“模态”)。而“对齐”就是建立这些不同模态信息之间的联系。
这张图将模态对齐分为两种主要方法:显式对齐 (Explicit Alignment) 和 隐式对齐 (Implicit Alignment)。
- 左右两侧 (Modality 1 & Modality 2):代表两种不同的信息类型。例如,Modality 1 可以是文本(比如一句话中的每个词 t1, t2, … tn),而 Modality 2 可以是图像(比如图像中被识别出的不同物体 t’1, t’2, … t’n)。
- 中间的橘色方块 (Fancy algorithm):代表一个精心设计的算法或模型。它的作用是学习和理解两种模态之间的关系。
- 箭头 (→):表示对齐的过程。算法试图将 Modality 1 中的元素(如文本中的词)与 Modality 2 中对应的元素(如图像中的物体)建立连接。
A) 显式对齐 (Explicit Alignment)
- 目标:直接、明确地找到不同模态元素之间的对应关系。
- 解释:这种方法的目标非常直接,就是要在最小的颗粒度上进行匹配。就像做“连连看”一样,算法需要明确地指出 Modality 1 中的
t1对应 Modality 2 中的t'4,t2对应t'1等等。 - 例子:
- 图文对齐:给定一张图片和一句话描述,算法需要准确地框出图片中被文字提到的每一个物体。例如,对于句子“一个女孩在公园里追逐一个红色的球”,算法需要分别将“女孩”、“公园”、“红色的球”这些词语与图片中对应的区域或像素建立明确的链接。
- 视频和字幕对齐:将视频中的每一句对话(音频模态)与字幕文件中的相应文本(文本模态)在时间轴上精确地对应起来。
B) 隐式对齐 (Implicit Alignment)
- 目标:并不直接寻找元素间的对应关系,而是利用模态间潜在的、内在的对齐来解决一个更宏观的问题。
- 解释:这种方法不关心细粒度的“谁对谁”。相反,它将两种模态的信息融合在一起,让模型在内部自己学习它们之间的关联,从而对整个场景或任务有一个更高层次的理解。对齐是作为实现最终目标的副产品而存在的,是“隐藏”在模型内部的。
- 例子:
- 视觉问答 (Visual Question Answering, VQA):给定一张图片和一个问题(例如,“图中有几个人?”),模型需要输出答案(例如,“3个”)。为了回答这个问题,模型必须在内部隐式地理解问题中的“人”这个词和图片中人的形象之间的关联,但它不需要明确地把“人”这个词和图片中的每一个人都连上线。它只需要利用这种潜在的对齐来完成“计数”这个最终任务。
- 情感分析:通过分析一段视频中人物的面部表情(视觉模态)和他说的话的语气(音频模态)来判断他的整体情绪(例如,高兴、悲伤)。模型不需要明确地指出是哪个面部肌肉的抽动对应了哪个语气的变化,而是将这些信息融合起来,得出一个综合性的情感判断。
- 显式对齐 像是“翻译”或“标注”,任务本身就是为了建立清晰的对应关系。
- 隐式对齐 像是“推理”或“判断”,为了完成一个更高级的任务(如回答问题、判断情感),模型在“幕后”自动地利用了不同信息之间的关联。
这两种方法在多模态研究中都非常重要,适用于解决不同类型的问题。
从看图识字到动手操作:多模态技术架构的四次跃迁
在人工智能的浪潮中,多模态技术正从一个前沿探索领域,迅速演变为驱动下一代AI应用的核心引擎。它赋予了机器超越单一文本或图像的局限,像人类一样通过多种感官综合理解世界的能力。回顾过去五年,其技术架构经历了四次关键的跃迁,每一次都深刻地改变了我们与AI的交互方式。
第一阶段:对比学习 —— 建立图文“语感”的桥梁 (2019-2021)
核心思想: 这一阶段的突破在于 对比学习(Contrastive Learning)。其目标并非让模型理解图像的每一个细节,而是在一个高维的 共享嵌入空间(Shared Embedding Space) 中,将语义相关的图像和文本“拉近”,将不相关的“推远”。

架构特点:
模型通常采用双编码器(Dual-Encoder)结构,一个用于处理图像(如 Vision Transformer, ViT),另一个用于处理文本。它们分别将图文信息映射为数学向量。通过在海量图文对上进行对比训练,模型学会了判断“这个文本”和“这张图片”是否匹配。这就像是为机器建立了一本普适的“感觉词典”,让它对图文关系有了基础的“语感”。
能力与局限:
- 能力: 具备强大的零样本(Zero-shot)分类和图文检索能力。只需给出类别名称(如“一只柯基”),模型就能在万千图片中找出对应的图像。
- 局限: 模型对内容的理解是“整体的”而非“分析的”。它知道图片与“狗”相关,但无法回答“狗在做什么?”或“图中有几只狗?”这类需要深入理解和推理的问题。
代表性工作:
论文标题: Learning Transferable Visual Models From Natural Language Supervision
解读: 这篇论文介绍了 CLIP (Contrastive Language-Image Pre-training) 模型,是该阶段的奠基之作,它通过从互联网上收集的4亿个图文对进行训练,展示了惊人的泛化能力,为后续的多模态发展铺平了道路。
第二阶段:视觉-语言模型融合 —— 从“匹配题”到“看图说话” (2022-2023)
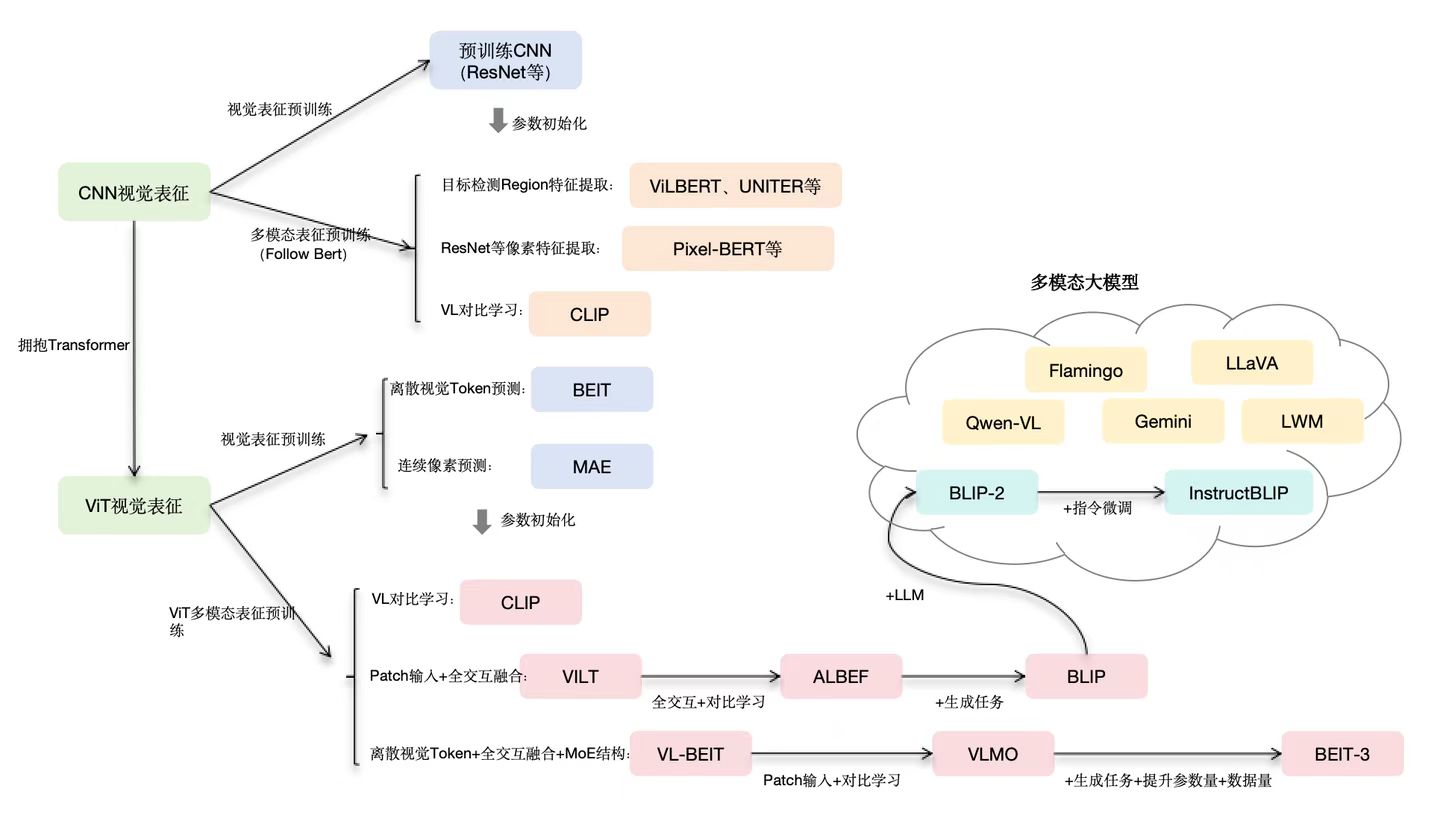
核心思想: 将强大的 视觉编码器(Vision Encoder) 与预训练好的 大型语言模型(LLM) 连接起来,实现从理解到生成的跨越。视觉信息不再仅仅用于匹配,而是被“翻译”成语言模型可以理解的“外语”。
架构特点:
典型架构是“视觉编码器 + 投影层 + LLM”。视觉编码器(如 ViT)先将图像切块并提取特征,生成一系列视觉令牌(Visual Tokens)。一个轻量级的投影层(Projection Layer)充当“翻译器”,将这些视觉令牌转换为语言模型能够识别的格式,并与文本指令一起输入LLM。LLM则发挥其强大的序列建模和生成能力,输出对图像的详细描述、分析或问答。
能力与局限:
- 能力: 实现了真正的多模态对话和初步的指令遵循。用户可以上传一张图片,并像聊天一样对图片内容进行提问和探讨(例如,“图中这辆红色汽车在做什么?” -> “这辆红色汽车正在加油站加油。”)。
- 局限: 视觉特征在传入LLM前经过了高度压缩,损失了大量细节,导致模型在处理高分辨率、需要精细识别的任务(如读取仪表盘数字、识别文档中的小字)时表现不佳。其推理能力也大多继承自LLM本身,而非源于深度的视觉-语言协同。
代表性工作:
论文标题: Visual Instruction Tuning
解读: 该论文提出了 LLaVA (Large Language and Vision Assistant),它通过创新的指令微调方法,有效教会了LLM如何理解和响应基于图像的指令,成为开源领域最具影响力的多模态模型之一。
第三阶段:视觉原生与高分辨率解析 —— 让AI拥有“鹰之眼” (2024)
核心思想: 突破第二阶段的视觉瓶颈,直接处理和理解高分辨率、任意尺寸和长宽比的图像。重点从“如何连接”转向“如何更精细、更高效地看”。
架构特点:
这一阶段的模型在视觉处理端进行了根本性革新。不再是固定尺寸的低分辨率输入,而是采用更灵活的视觉编码策略。例如,使用**视觉提示词(Visual Prompts)**让模型聚焦于特定区域,或发展出更高效的视觉压缩技术,能将数千乃至上万个像素块智能地提炼成少数几个关键的“精华Token”,在保留核心信息的同时,极大降低了LLM的处理负担。
能力与局限:
- 能力: 具备了强大的细粒度识别和空间推理能力。能够轻松处理高清卫星图像、医学影像(如CT切片)、复杂图表和长篇文档截图,并准确提取其中的关键信息(如发票金额、代码截图中的错误行)。
- 局限: 尽管感知能力大幅增强,但模型仍然主要扮演着一个“信息处理器”或“观察者”的角色,它能精准描述问题,但无法主动执行任务来解决问题。
代表性工作:
论文标题: Gemini 1.5: Unlocking multimodal understanding across long contexts
解读: Google Gemini 1.5 Pro 的技术报告展示了其处理超长上下文(高达100万Token)的能力,能够“消化”数小时的视频或数万行代码,并对其中的细节进行精准问答,是高分辨率、长序列多模态理解的典范。
第四阶段:多模态智能体 —— 从“观察世界”到“改变世界” (2025+)
核心思想: 这是多模态技术的终极目标——构建能够自主行动的智能体(Agent)。视觉和语言不再是两种需要翻译的信号,而是融合成一种统一的表征。模型不仅能看懂,更能基于理解去操作。
架构特点:
核心是构建一个 “感知-思考-行动”(Perception-Reasoning-Action) 的闭环。图像(尤其是GUI截图、摄像头画面)本身被视为一种可执行的令牌(Actionable Token)。模型能够将用户的模糊指令(如“帮我订一张明天去上海的机票”)分解为一系列具体操作(1.截图当前屏幕 -> 2.识别“出发地”输入框 -> 3.生成点击和输入文本的指令 -> 4.循环直至任务完成)。
能力与展望:
- 能力: 实现与数字世界(如操作系统、网页应用)乃至物理世界(通过机器人)的无缝交互。AI将从一个“知识问答机”进化为一个能解决实际问题的“数字雇员”或“机器人管家”。
- 展望: 这是通往通用人工智能(AGI)的关键一步。当模型能将复杂的视觉输入直接映射到行动空间时,意味着它真正开始理解世界运行的因果规律。我们期待能构建出统一的视觉大模型,最终实现能够处理任意模态、完成任意任务的通用大模型。
代表性工作:
论文标题: RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
解读: DeepMind的RT-2 项目证明,通过在海量的互联网图文数据上训练,一个视觉-语言模型可以将其泛化的理解能力迁移到机器人控制上,无需显式的机器人操作数据训练,就能“看懂”指令并“动手”完成任务。这标志着从VLM(视觉-语言模型)向VLA(视觉-语言-行动模型)的范式转变。
Qwen2.5-VL
核心总览:从输入到输出的数据之旅
整个流程可以概括为五个关键步骤:
- 接收输入 (Input): 接收各种格式和尺寸的视觉材料。
- 视觉编码 (Vision Encoding): “鹰之眼”将原始像素转化为机器能理解的特征。
- 视觉令牌化 (Visual Tokenization): 将视觉特征“翻译”成语言模型能读懂的“单词”。
- 融合与推理 (Fusion & Decoding): “智慧大脑”将视觉“单词”和用户提问结合起来进行思考。
- 生成输出 (Output): 给出最终的答案或执行结果。
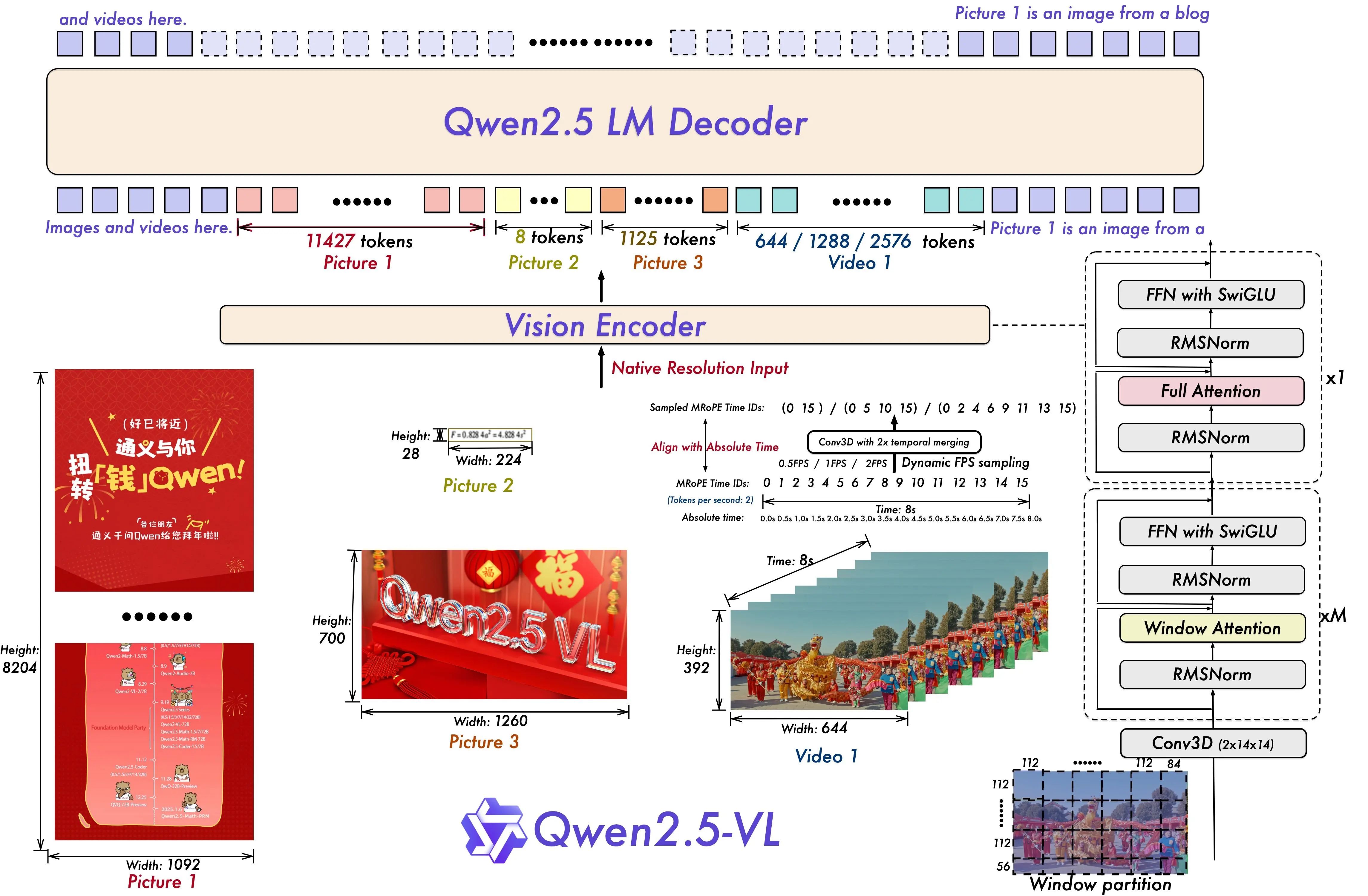
第一步:多模态、原生分辨率输入 (Input Stage)
- 发生了什么: 模型接收用户提供的视觉数据。
- 图中细节: 左下角展示了这一点。Qwen2.5-VL 的强大之处在于其**原生分辨率输入(Native Resolution Input)**能力。它能同时处理:
- 超长文档图 (Picture 1): 一张高达 8204x1092 像素的网页截图。
- 小尺寸图标 (Picture 2): 仅有 28x224 像素。
- 高清照片 (Picture 3): 1260x700 像素的横幅图。
- 视频流 (Video 1): 644x392 像素的动态视频。
- 解读: 传统模型在这一步需要将所有图片强制缩放或裁剪到统一的小尺寸,导致信息大量丢失。而 Qwen2.5-VL 则像人眼一样,能直接处理原始材料,无论是一篇长论文的截图还是一个短视频,都能“一览无余”,为后续的精准理解打下了坚实基础。
第二步:视觉编码 (Vision Encoder Stage)
- 发生了什么: 位于图中央的 Vision Encoder 模块开始工作,它负责从原始像素中提取出有意义的、结构化的特征。
- 图中细节: 针对不同的输入,它会采用精细化的策略。以 Video 1 为例:
- Window partition (窗口分区): 它将视频帧切分为 112x56 的小块(patches),这是为了在可控的计算量下进行局部特征提取。
- 时间信息处理: 图中提到了
Align with Absolute Time(对齐绝对时间) 和Dynamic FPS sampling(动态帧率采样)。这意味着编码器不仅在看画面的内容,还在记录这些内容在什么时间发生,并且会智能地跳过一些冗余帧,只关注关键变化,极大提升了效率。
- 解读: 这一步相当于大脑的初级视觉皮层。它将混乱的像素点转化为有意义的“视觉基元”,比如“这是一个红色方块”、“这条线在向上移动”等,并附上时空信息。右侧的
Conv3D模块就是专门用于捕捉这种时空动态的利器。
第三步:视觉令牌化 (Visual Tokenization Stage)
- 发生了什么: 这是从“视觉语言”到“文本语言”的关键翻译步骤。视觉编码器提取的特征被转换成一系列视觉令牌(Visual Tokens),这是语言模型(LM Decoder)唯一能“阅读”的格式。
- 图中细节: 图的上半部分清晰地展示了这一结果。
- 超长的 Picture 1 被翻译成了 11,427 个视觉令牌,保留了海量细节。
- 小图标 Picture 2 被提炼为 8 个令牌。
- 视频 Video 1 则根据其内容和时长被转换为 644 / 1288 / 2576 不等数量的令牌。
- 解读: 令牌数量的巨大差异直观地反映了模型处理信息的能力。它能根据输入内容的复杂程度,动态决定需要用多少“词汇”来描述它。一个复杂的文档自然需要长篇大论(更多的令牌),而一个简单的图标则只需寥寥数语(更少的令牌)。
第四步:图文融合与解码推理 (LM Decoder Stage)
- 发生了什么: 这是模型的核心“思考”环节。
- 图中细节: 图的顶部显示,所有视觉令牌(
Images and videos here)和用户的文本指令(例如Picture 1 is an image from a blog...)被拼接成一个统一的序列,然后被送入 Qwen2.5 LM Decoder。- 内部机制(右侧): 解码器由多个 Transformer 模块堆叠而成。它会使用 **Full Attention(全局注意力)**来建立视觉和文本之间的初始关联,然后可能采用 **Window Attention(窗口注意力)**来高效处理这个可能非常长的混合序列。
- 核心组件: 在每个模块内部,
FFN with SwiGLU和RMSNorm等技术(如我们之前分析的)确保了信息在传递和推理过程中的高效性和准确性。
- 解读: 在这一步,模型真正开始“理解”。它会将文本中的“红色汽车”这个词,与视觉令牌中代表红色汽车的部分联系起来。它会根据“视频中发生了什么?”这个问题,去分析和推理有时序关系的视频令牌序列,最终形成一个连贯的答案。
第五步:生成最终结果 (Output Stage)
- 发生了什么: 解码器在完成推理后,会生成新的文本令牌,最终组合成人类可读的自然语言答案。
- 图中细节: 虽然图中没有明确画出“Output”框,但这是解码器工作的必然结果。
- 解读: 输出的结果可以是:
- 一个简单的问答: “图中发票的总金额是1024元。”
- 一段详细的描述: “这段视频记录了一场舞龙表演,从第3秒到第5秒,龙头有一个向上抬起的动作……”
- 一个结构化的JSON对象: 用于后续的程序处理。
- 一个行动指令: 用于驱动 Agent 完成更复杂的任务。
流程总结
| 步骤 | 核心任务 | 涉及的关键技术/图中细节 |
|---|---|---|
| 1. 输入 | 接收原始视觉数据 | 多种尺寸的图片和视频,原生分辨率输入 |
| 2. 编码 | 提取时空特征 | Vision Encoder, Window partition, Conv3D, 时间编码 |
| 3. 令牌化 | 将视觉特征翻译为令牌 | 根据输入复杂度生成可变长度的视觉令牌序列 |
| 4. 推理 | 融合图文并进行思考 | Qwen2.5 LM Decoder, Full/Window Attention, FFN, RMSNorm |
| 5. 输出 | 生成文本答案或指令 | 语言生成,可以是自然语言、JSON或其他格式 |
Qwen2.5-VL,不止是“看图说话”,更是一个拥有“鹰之眼”与“智慧大脑”的数字生命体
如果说上一代多模态模型解决了“看图说话”的问题,那么通义千问 Qwen2.5-VL 则是在回答一个更深刻的问题:“如何像人类一样,既能看得清微小细节,又能理解宏观全局,并最终基于理解去行动?”
这不仅仅是一次模型迭代,它代表了多模态技术从“模糊感知”到“高清解析”,从“被动描述”到“主动推理”的范式革命。
Vision Encoder— 如何看得又清、又快、又懂
传统模型在“看”世界时,往往需要将图片缩放或裁剪成固定的小尺寸,这就像让人透过一个模糊的门镜看世界,大量关键细节都丢失了。Qwen2.5-VL 的视觉编码器则彻底改变了这一点,其核心是原生分辨率输入(Native Resolution Input)。
正如架构图所示,无论是高达 8K 分辨率的超长文档(Picture 1),还是普通的海报(Picture 3)和视频(Video 1),模型都能直接处理它们的原始尺寸和长宽比。这是如何做到的?答案在于其内部三大技术支柱:
-
动态窗口注意力 (Dynamic Window Attention) - 看得又快又广
- 挑战: 如果对一张 4K 图片使用全局注意力(让每个像素点都和其他所有像素点做比较),其计算量会呈指数级爆炸,成本高到无法接受。
- Qwen 的方案: 它像一个高效的阅读者,不会逐字阅读,而是将图像划分为多个“段落”(窗口分区)。例如,静态图划分为 56x56 的网格,视频则为 112x84。模型首先在这些小窗口内部进行高强度计算(局部注意力),极大降低了计算量(约7倍)。
- 关键创新: 为了避免“只见树木,不见森林”,它设计了跨窗口交互机制,允许信息在相邻的“段落”间流动。这使得模型既能聚焦于发票上的一个数字,又能理解这个数字在整个表格中的位置和意义,实现了全局感知的统一。
-
特征增强模块 (FFN with SwiGLU) - 看得更准
- 挑战: 在神经网络中,如何让特征信息在传递过程中不失真、不退化,并有效放大关键信号?
- Qwen 的方案:
- SwiGLU 激活函数: 传统激活函数(如GELU)像一个简单的“开/关”按钮。而 SwiGLU 引入了“门控(Gating)”机制,像一个精密的“调光器”。它能根据上下文动态决定哪些特征信号应该被放大,哪些应该被抑制,从而实现更细腻、更非线性的表达。
- RMSNorm 归一化: 替代传统的 LayerNorm,它在归一化过程中计算更简单、方差更小,能让模型训练更稳定,特征对齐更精准(实测提升12%)。
-
视频时空建模 (3D Convolution) - 看得懂时间
- 挑战: 视频不仅有空间(画面),更有时间。模型必须理解动作的连续性。
- Qwen 的方案: 它引入了
Conv3D(2x14x14)时序卷积层。可以将其理解为,模型在看视频时,不是一帧一帧地看静态图片,而是用一个能同时覆盖14x14像素区域和2帧时间的小窗口去看,从而直接捕捉到物体的运动和变化。再结合绝对时间编码(给每一帧打上精确的时间戳),模型就能实现秒级甚至毫秒级的事件定位,精准捕捉到“骑手未戴头盔”的瞬间。
神经桥梁 (Vision-Language Interface) — 将像素语言翻译为文字思想
当“鹰之眼”看清了世界后,如何将这些复杂的视觉信息传递给“大脑”——语言模型(LLM)?这个过程就是视觉-语言融合。
看架构图上半部分,不同尺寸的输入被视觉编码器处理后,转化为了不同长度的视觉令牌(Visual Tokens)。一个视觉令牌,可以理解为语言模型能读懂的一个“视觉单词”。
- 看图中的 Picture 1,这张超长文档被转换成了惊人的 11,427 个视觉令牌,保留了海量细节。
- 而小尺寸的 Picture 2,则被高效地提炼为 8 个令牌。
这种自适应、可变长度的令牌化是原生分辨率处理的关键。随后,这些视觉令牌与用户的文本指令令牌一起,被送入 Qwen2.5 的语言模型解码器,进行深度融合与推理。Qwen 采用两阶段对齐机制和渐进式学习,先让模型学会简单的图文对应(这是什么),再引导其学习复杂的逻辑推理(为什么会这样),确保了视觉与语言的无缝对接。
智慧大脑 (Qwen2.5 LM Decoder) — 从理解到推理,再到行动
这是整个系统的中枢,它不仅继承了 Qwen2.5 语言模型的强大通用能力,更针对多模态任务进行了深度定制。
-
结构化输出: 它不再仅仅输出一段描述性文字,而是能按照指令生成高度结构化的数据格式,如 JSON。例如,在分析监控视频时,它可以直接输出
{"time": "00:02:15", "action": "违规停车"}。这对于自动化流程和工业应用至关重要,因为机器可以直接读取和使用这些数据。 -
动态工具调用 (Agent 能力): 这是其迈向“行动”的关键一步。Qwen2.5-VL 不再是一个封闭的系统,它能作为一个“总指挥”,在需要时调用外部的专业工具。例如:
- 当需要识别图片中的文字时,它可以调用一个高精度的 OCR 模型。
- 当需要定位图中所有车辆时,它可以调用一个目标检测模型。
- 最终,它能实现“看图操作电脑”:理解屏幕截图,并生成鼠标点击和键盘输入指令来完成任务,如自动填写表单、预订机票等。
融会贯通:Qwen2.5-VL 在真实世界中的三大杀手锏
这些先进的技术最终转化为了强大的应用能力,使其从实验室走向了工业现场:
- 文档解析革命: 直接“阅读”扫描的PDF、财务报表、发票,准确率高达99.2%。它不再需要预先的格式转换,真正实现了任意文档的端到端理解。
- 长视频理解专家: 通过高效的帧分组和时空建模,它能“看完”并理解长达1小时的视频,同时仅占用少量计算资源(压缩至约512个令牌),并保持对事件因果关系的推理能力。
- 无处不在的边缘AI: 它提供了从3B到72B的多种模型尺寸。其中3B的轻量级模型可以在手机等移动设备上实时运行(延迟<50ms),让强大的视觉问答能力摆脱了对云端的依赖。
Qwen2.5-VL 凭借其原生高清视觉能力、高效的时空建模以及Agent级的工具调用框架,在 当时的 12 项权威基准测试中取得第一(SOTA)。它系统性地解决了多模态模型在工业落地中的核心痛点:分辨率限制、计算成本和行动能力。它标志着多模态大模型真正从一个“聪明的观察者”进化为一个“能干的执行者”,为未来在自动驾驶、智能制造、医疗影像分析、个人智能助理等领域的广泛应用铺平了道路。
融合知识图谱的多模态推理

在人工智能追求更高层次认知智能的征途中,单纯的“看图说话”或“文本理解”已远不能满足需求。我们需要模型不仅能感知世界,更能像人类一样,利用背景知识进行思考和推理。**基于知识图谱的多模态推理(Multimodal Reasoning with Knowledge Graphs)**正是实现这一目标的关键技术路径,它将机器的“感知能力”与“认知能力”深度融合,催生出更具智慧的AI应用。
1. 奠基概念:从独立到融合
要理解这项复杂技术,我们必须首先清晰地解构其三大核心支柱:多模态推理、知识图谱、以及知识图谱推理。
1.1 什么是多模态推理 (Multi-Modal Reasoning)?
多模态推理是一种高级的人工智能形式,它要求模型能够处理和整合至少两种不同模态(如视觉、语言、听觉等)的信息,并在此基础上进行逻辑判断、因果分析或预测。
- 核心目标:实现协同理解(Synergistic Understanding)。不同模态的信息不是简单叠加,而是互为补充、相互印证。例如,在理解一个场景时,图像提供了“有什么”的视觉证据,而文本则可能描述“为什么会这样”的背景或意图。
- 超越感知:它不仅仅是识别图像中的物体或转录语音,而是要理解模态之间的深层语义关联,并进行超越内容本身的推断。
1.2 什么是知识图谱 (Knowledge Graph, KG)?
知识图谱是一种用图(Graph)结构来建模和存储人类知识的数据库。它将现实世界的知识以一种机器可读的方式进行结构化组织。
- 基本构成:
- 实体 (Entities):代表现实世界中的具体事物或抽象概念,如图中的“节点”(Nodes)。例如:
埃菲尔铁塔、巴黎、建筑师。 - 关系 (Relations):描述实体之间存在的各种联系,如图中的“边”(Edges)。例如:
位于、设计者是。 - 三元组 (Triples):构成知识的基本单元,形式为
(头实体, 关系, 尾实体),或记为(h, r, t)。例如:(埃菲尔铁塔, 位于, 巴黎)。
- 实体 (Entities):代表现实世界中的具体事物或抽象概念,如图中的“节点”(Nodes)。例如:

知识图谱的本质是将分散的知识连接成一张巨大的语义网络,使机器能够理解概念之间的复杂关系。
1.3 什么是知识图谱推理 (KG Reasoning)?
知识图谱推理是在图谱现有知识的基础上,自动发现和推断出新的、隐含的知识(即新的三元组)的过程,填补知识图谱中的空白或增强图谱的表达能力。

- 核心任务:知识补全(Knowledge Completion)或链接预测(Link Prediction)。例如,如果图谱中有
(A, 是B的父亲)和(B, 是C的父亲),推理的目标就是推断出(A, 是C的祖父)这一新关系。 - 主流方法:基于**图神经网络(Graph Neural Networks, GNNs)**的方法已成为主导。GNN通过在图谱的节点间传递和聚合信息,为每个实体和关系学习到包含其邻域结构信息的向量表示(Embedding)。基于这些向量,模型可以预测两个实体间存在某种关系的可能性。

2. 核心引擎:知识图谱如何赋能多模态推理
单纯的多模态模型常常受限于当前输入的数据,缺乏外部的、通用的世界知识,导致它们在需要常识或专业背景的复杂问题上表现不佳。这正是知识图谱发挥关键作用的地方。
核心动机:为多模态模型注入一个结构化的“外部大脑”,使其能够将感知到的信息与广泛的世界知识关联起来,从而进行更深层次的推理。

实现路径与关键技术
将知识图谱与多模态数据融合,通常遵循一个精密的、分阶段的技术流程:
阶段一:跨模态语义对齐 (Cross-modal Semantic Alignment)
这是基础步骤。模型需要理解“图片中的一只猫”和文本“a cat”指向的是同一个概念。这通常通过大规模对比学习(如CLIP模型)实现,将不同模态的信息映射到统一的语义向量空间。
阶段二:知识关联与注入 (Knowledge Association & Injection)
这是最关键的步骤,即在感知信息和结构化知识之间建立桥梁。
- 实体/概念链接 (Entity/Concept Linking):首先,模型需要从图像和文本中识别出关键的实体或概念(如从一张巴黎街景图片中识别出“埃菲尔铁塔”、“汽车”)。
- 知识图谱对齐 (KG Grounding):然后,将识别出的实体链接(Grounding)到知识图谱中对应的节点上。
- 构建多模态知识图 (Multimodal Knowledge Graph):将视觉对象(来自图像)、文本实体(来自问题)和外部知识图谱的节点融合,构建一个临时的、包含多源信息的混合图。
阶段三:联合推理与答案生成 (Joint Reasoning & Answer Generation)
在这个混合图上,模型可以执行复杂的推理路径。
-
推理过程示例:
- 问题:“这张图片中的塔是谁设计的?”
- 图片:一张埃菲尔铁塔的照片。
- 流程:
- 模型从图片中识别出视觉对象
[埃菲尔铁塔]。 - 将该视觉对象对齐到知识图谱中的节点
埃菲尔铁塔。 - 模型在图谱中沿着关系
设计者是进行遍历(推理)。 - 找到链接的节点
古斯塔夫·埃菲尔。 - 将推理结果
古斯塔夫·埃菲尔转化为自然语言答案并输出。
- 模型从图片中识别出视觉对象
-
技术实现:这一步通常由**图注意力网络(Graph Attention Network, GAT)**等高级GNN模型完成。GAT能够动态地为不同的邻居节点(知识)分配不同的注意力权重,从而在推理路径上聚焦于与当前问题最相关的信息。
3. 两大典型应用解析
基于知识图谱的多模态推理在多个前沿领域展现出巨大潜力,其中视觉问答和视觉常识推理是两个最典型的代表。
3.1 视觉问答 (VQA) 与知识型VQA

- 标准VQA:问题通常可以直接从图像内容中找到答案(例如,“图中有几只猫?”)。
- 知识型VQA (Knowledge-Based VQA):问题需要依赖图像内容之外的外部知识。这正是知识图谱的用武之地。
- 例子:“照片中这位演员出演过哪部科幻电影?”
- 解析:模型必须先识别出照片中的演员(感知),然后链接到知识图谱,查询其作品列表(知识推理),并根据“科幻电影”这一约束进行筛选,最终生成答案。
3.2 视觉常识推理 (VCR)
VCR任务的设计更为精巧,它要求模型不仅选出答案,还要解释原因,从而更深入地考察其推理能力。

- 任务结构:包含两个子任务。
- 问答 (Q -> A):
[问题]->[正确答案]。例如,针对一张人们在餐厅吃饭的图片,问题是“为什么这个人看起来很开心?”,答案选项可能是“因为他在过生日”。 - 理由推断 (QA -> R):
[问题] + [正确答案]->[正确理由]。模型需要从理由选项中选择一个来支撑上面的问答对,例如理由是“桌子上的生日蛋糕表明这是一个庆祝活动”。
- 问答 (Q -> A):
- 知识图谱的作用:常识本身可以被构建成一个庞大的知识图谱(例如,
生日->通常伴随->蛋糕;庆祝活动->导致->开心)。模型可以利用这个常识图谱来验证和发现问题、答案与理由之间的逻辑链条,从而做出更可靠的推理,而不是基于表面相关性的猜测。
尽管前景广阔,该领域仍面临诸多挑战:
- 知识的完备性与时效性:知识图谱永远无法包含世界的全部知识,且知识会随时间变化。
- 对齐的模糊性与准确性:如何将模糊的视觉概念(如“快乐的氛围”)精确地对齐到图谱节点上是一个难题。
- 推理的可扩展性与效率:在亿级节点的大规模知识图谱上进行实时推理,计算开销巨大。
- 端到端学习:如何将离散的符号推理(知识图谱)与连续的神经网络(多模态模型)进行更优雅、更高效的端到端联合训练。
未来趋势:
- 神经符号结合 (Neuro-Symbolic AI):深度融合神经网络的强大感知能力和符号系统的严谨逻辑推理能力,是实现通用人工智能的重要方向。
- 隐式知识与显式知识的协同:探索如何让大型语言模型(LLMs)中蕴含的庞大“隐式知识”与知识图谱的“显式知识”协同工作,取长补短。
- 自动化多模态知识图谱构建:研究如何从海量的网络文本、图片、视频中自动构建和更新多模态知识图谱,实现知识的自增长。
- 可解释性与因果推理:未来的模型不仅要给出答案,更要提供清晰、符合逻辑的推理路径和因果解释,建立值得信赖的AI系统。
融合知识图谱的多模态推理,正引领AI从一个被动的“信息处理器”向一个主动的“知识思考者”转变,为实现真正理解世界、与人类深度协作的通用人工智能奠定了基础。