基于cnn的通用图像分类项目
背景
项目上需要做一个图像分类的工程。本人希望这么一个工程可以帮助学习ai的新同学快速把代码跑起来,快速将自己的数据集投入到实战中!
代码仓库地址:imageClassifier: 图片分类器
数据处理
 自己准备的分类图像,按照文件夹分类,放在dataset目录下。
自己准备的分类图像,按照文件夹分类,放在dataset目录下。
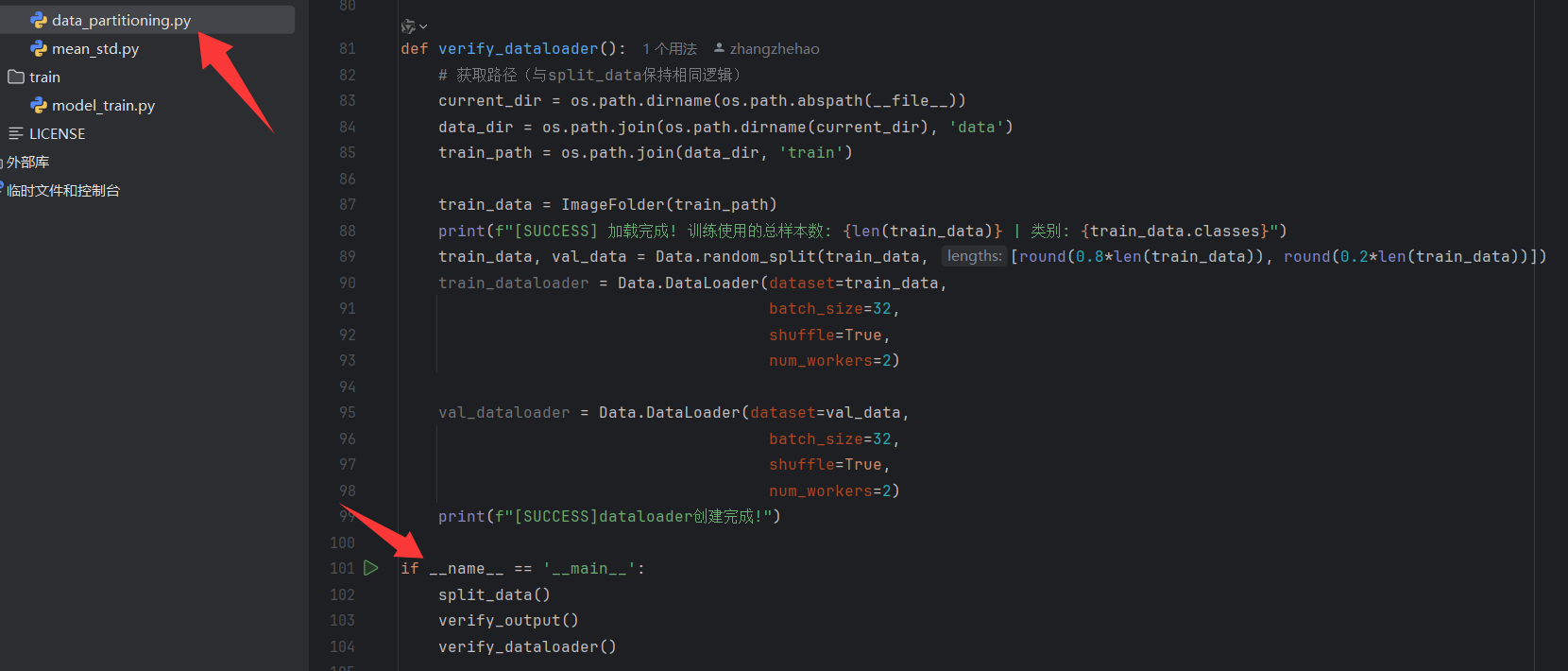
运行一下data_partitioning的方法,会自动按照比例将数据划分为训练集和测试集。存放在data目录下。
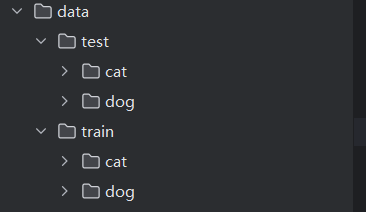
执行完之后可以看到data文件夹下出现了train文件夹和test文件夹,这两个文件夹下按照分类也做了数据划分。
模型训练
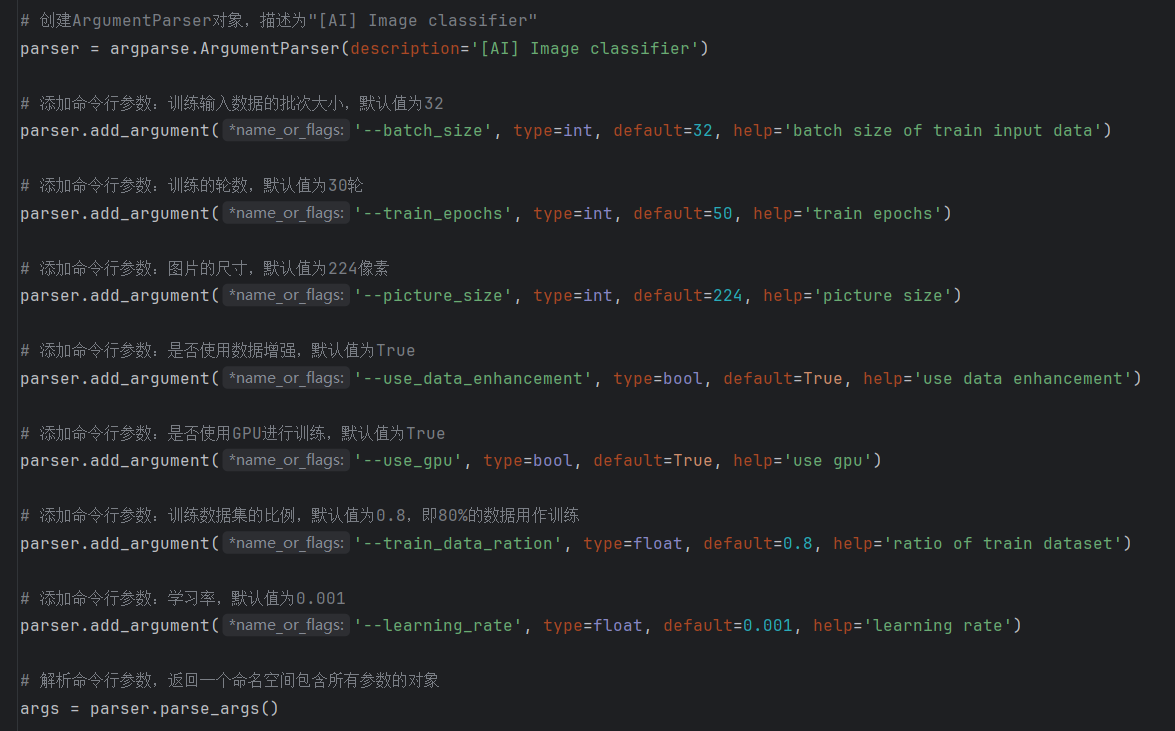
在train_model.py里面首先是超参数设置。这里面的数值都有默认值,根据数据集不同,经常修改的值通常是批次大小和轮数。
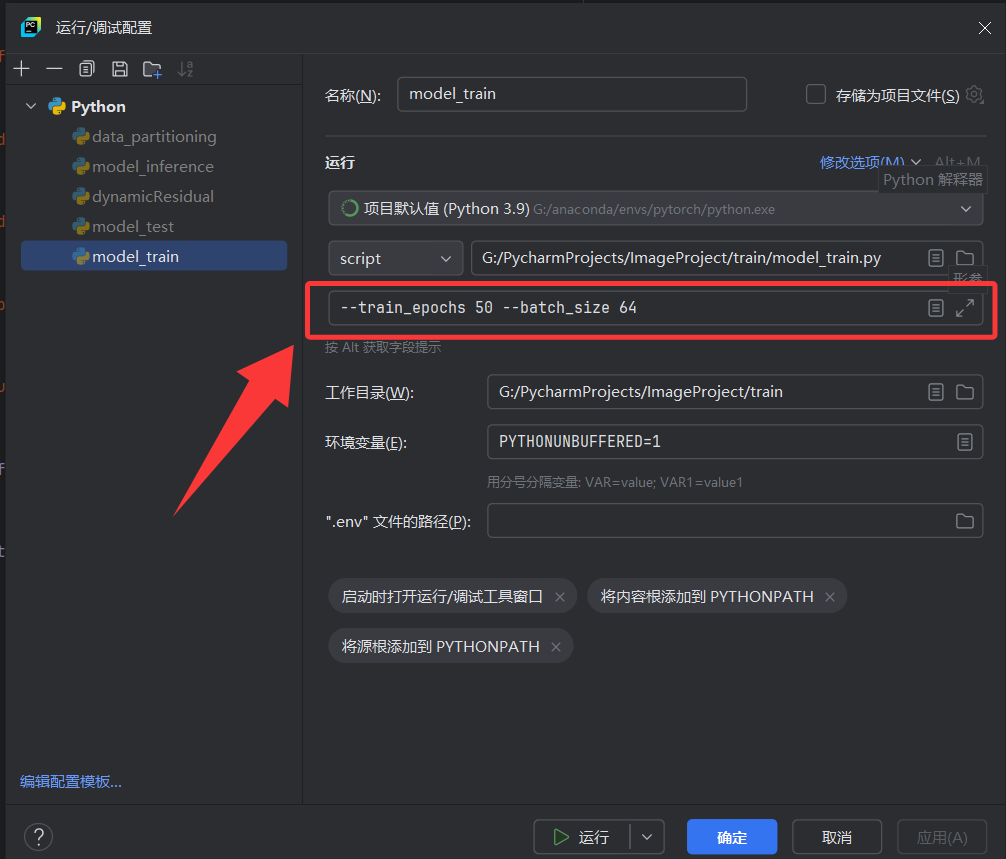
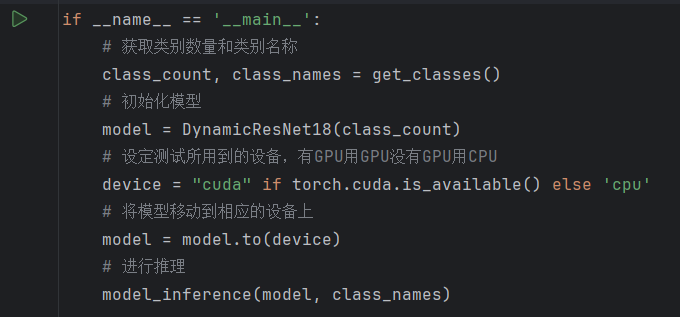
举例:如果需要将训练轮次设置为50轮,批次大小设置为64的话,只需要按照下图所示,在ide的运行配置里加上即可。注意,不同的配置字段之间用空格隔开。
关于轮次大小和批次大小的设置,这里建议:
- 第一次训练时可以将轮次调整为一个较大的值,数据量越大建议轮数越高。由于代码里存在早停机制,所以即使轮数大到过于夸张,在训练后期由于准确率提升不明显,训练流程会自动停止。
- 第一次训练可以将批次大小调整为一个较小的值。由于训练期间同一批次的数据会一起放入显存中,所以批次过大容易出现爆显存的现象。当训练期间发现显存没有被占满时,可以提高批次大小,提升训练速度。
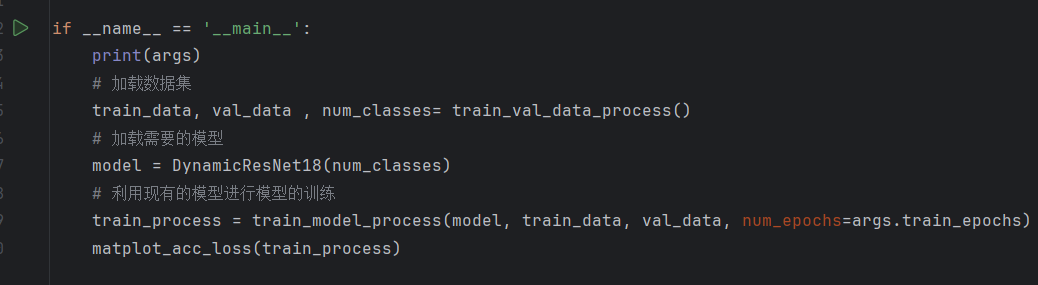
执行以上方法就可以开始训练了。图像分类的类别通过文件夹数量获取即可,不需要人为设置。
训练后参数文件会保存在dict文件夹下面。
模型测试
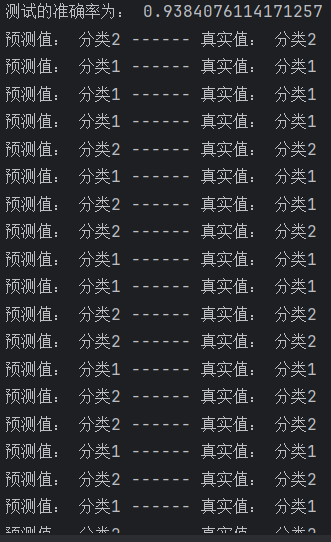
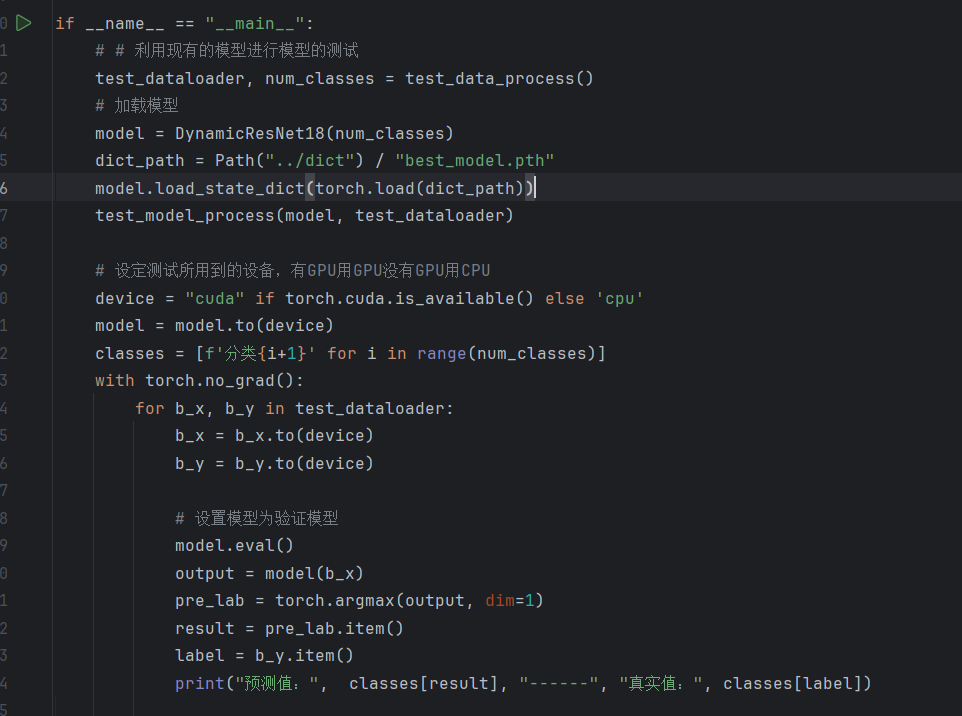 在训练完成后,到model_test.py文件里运行代码即可,会把在测试集中的数据完整验证一遍,计算出准确率,并打印出每条数据的预测值与真实值。
在训练完成后,到model_test.py文件里运行代码即可,会把在测试集中的数据完整验证一遍,计算出准确率,并打印出每条数据的预测值与真实值。
模型推理
推理过程我们要做的是,导入一张图片,经过模型运算得出其分类类型。在model_inference.py里面,我们需要指定一张用来推理的图片。图片的路径放在inference目录下,图片名称可以改成真实的图片名称。
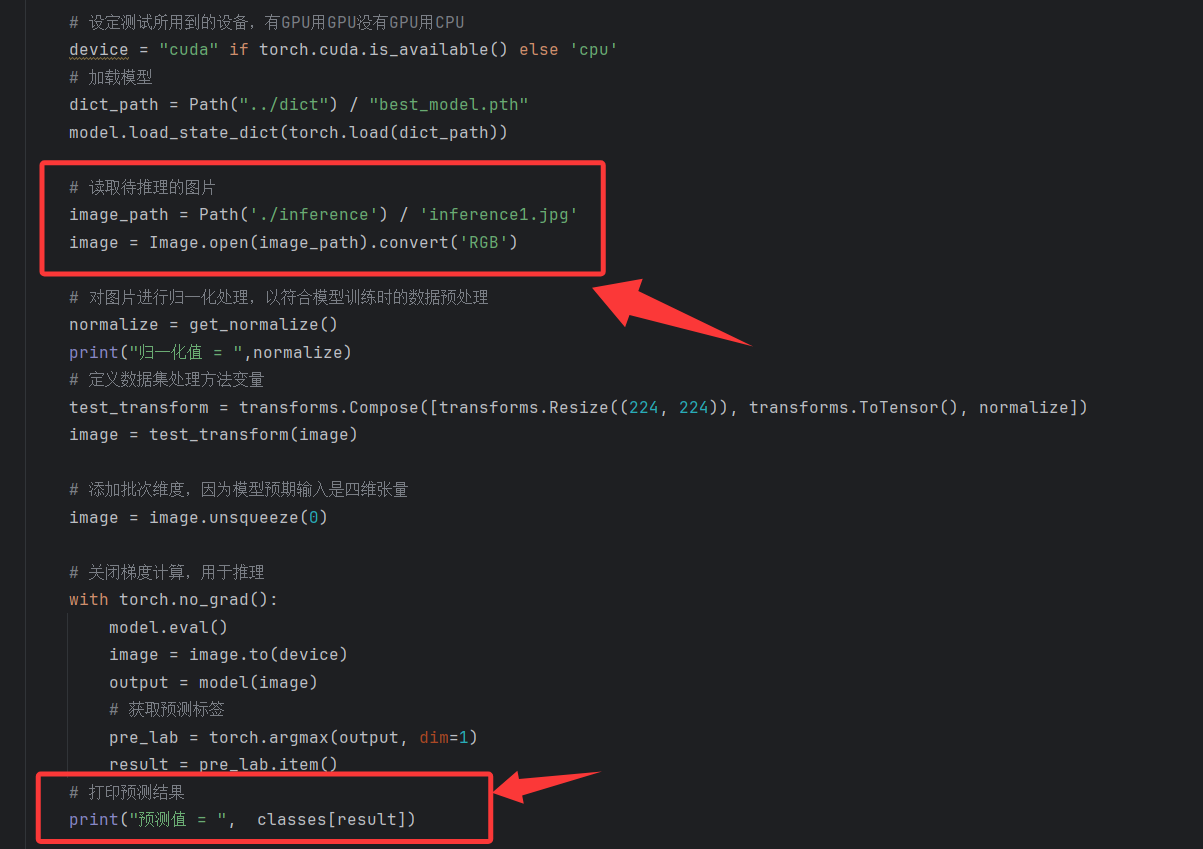
运行model_inference.py的方法,即加载模型->加载图片->模型推理->得出预测值。
示例
在master分支上是一个猫狗分类的项目。其中dog文件夹里有4999张狗的图片,cat文件夹里有4990张猫的图片。
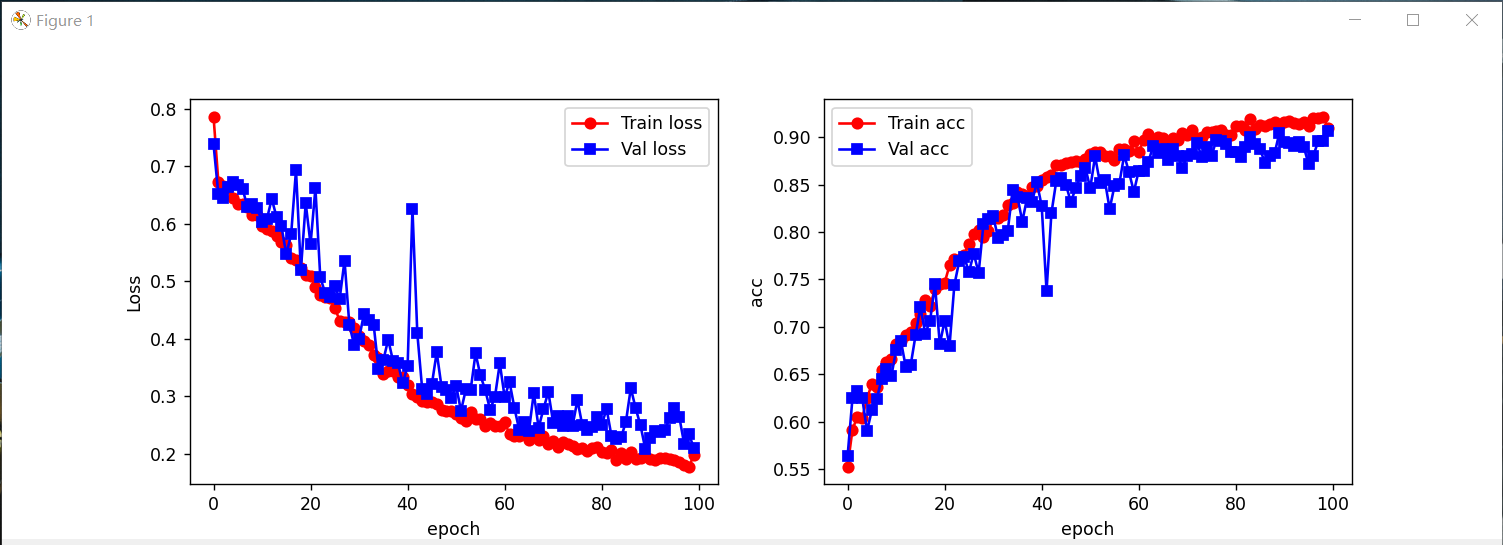
下图为训练100轮次的loss变化与准确率变化。由于训练阶段中也会切分训练-验证数据集,所以通常是通过val-acc来观察实际的准确率,可以看到最后准确率约达到90%。
运行模型测试代码,得出准确率为93.8%。
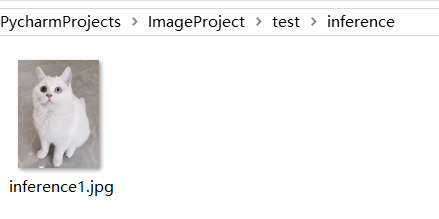
在inference文件夹里放入一个猫/狗图片,注意这张图片不要来自于训练数据。
运行推理程序,得出分类类型为cat。
