数据库MySQL基础(3)
主要是概念类
一、关于SQL
1.1、SQL概述
SQL:Structured Query Language(结构化查询语言),客户端使用SQL来操作数据库,可以应用到所有关系型数据库中。
SQL语法:
SQL语句可以在单行或多行书写,以分号结尾;
可使用空格和缩进来增强语句的可读性;
MySQL不区分大小写,建议大写。
经验:通常执行对数据库的“增删改查”,简称C(Create)R(Read)U(Update)D(Delete)
1.2、SQL分类
DDL(Data Definition Language)数据定义语言:创建、删除、修改库与表结构。
DML(Data Manipulation Language)数据操作语言:增、删、改表记录;
TPL(Transation Process Language)事务处理语言:用于对事务进行处理;
DQL(Data Query Language)数据查询语言:用来查询记录;
//DCL(Data Control Language)数据控制语言:用来定义访问权限和安全级别。
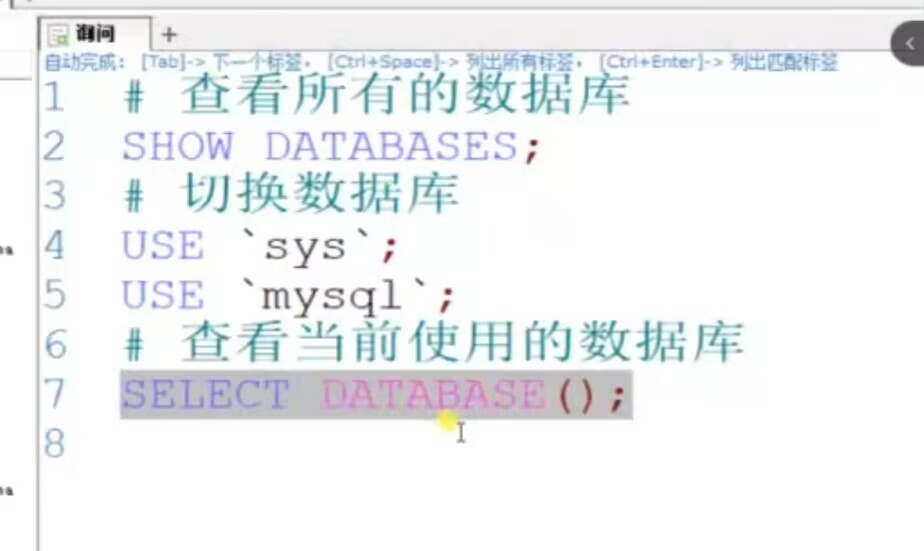
二、数据库操作
补充见文章(1)
 三、表的操作:
三、表的操作:
3.1、数据操作
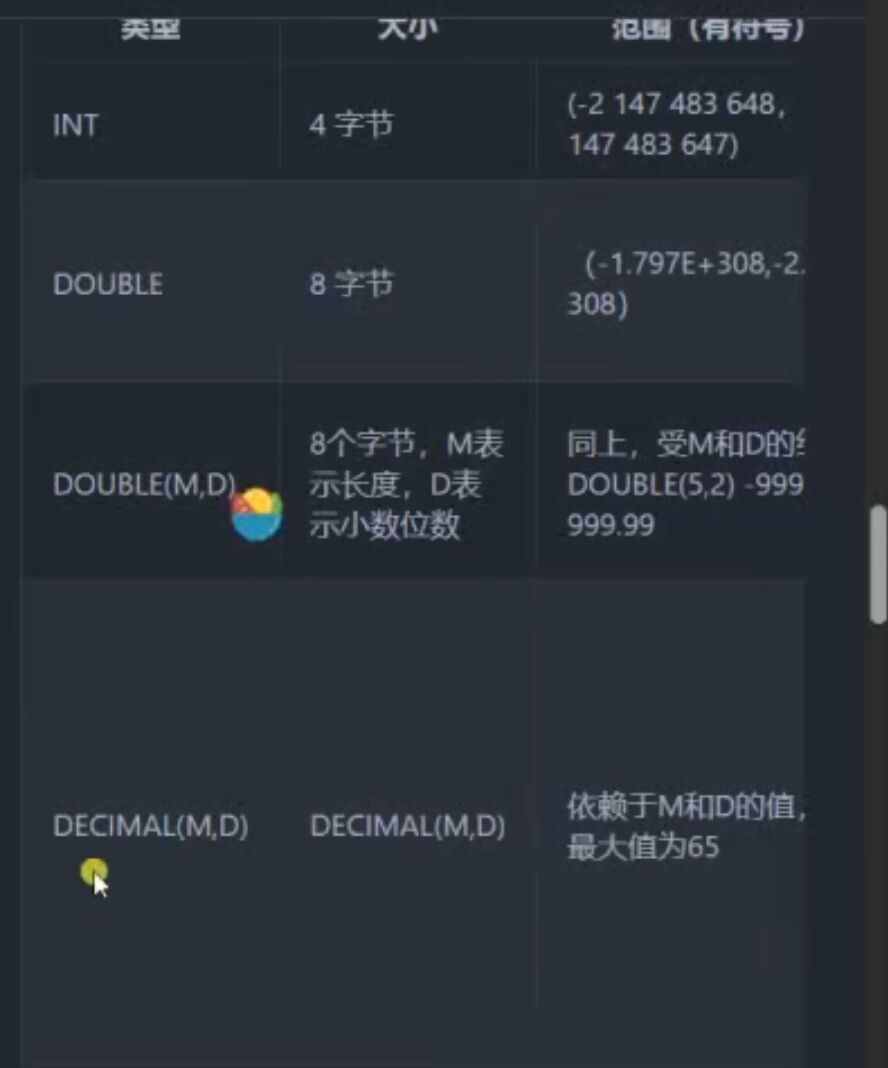
MySQL支持多种类型,大致可以分为三类:
数值;
字符串(字符)类型;
日期时间。
数据类型对于我们约束数据的类型有很大的帮助。
3.1.1、数值类型
3.1.2、字符串类型
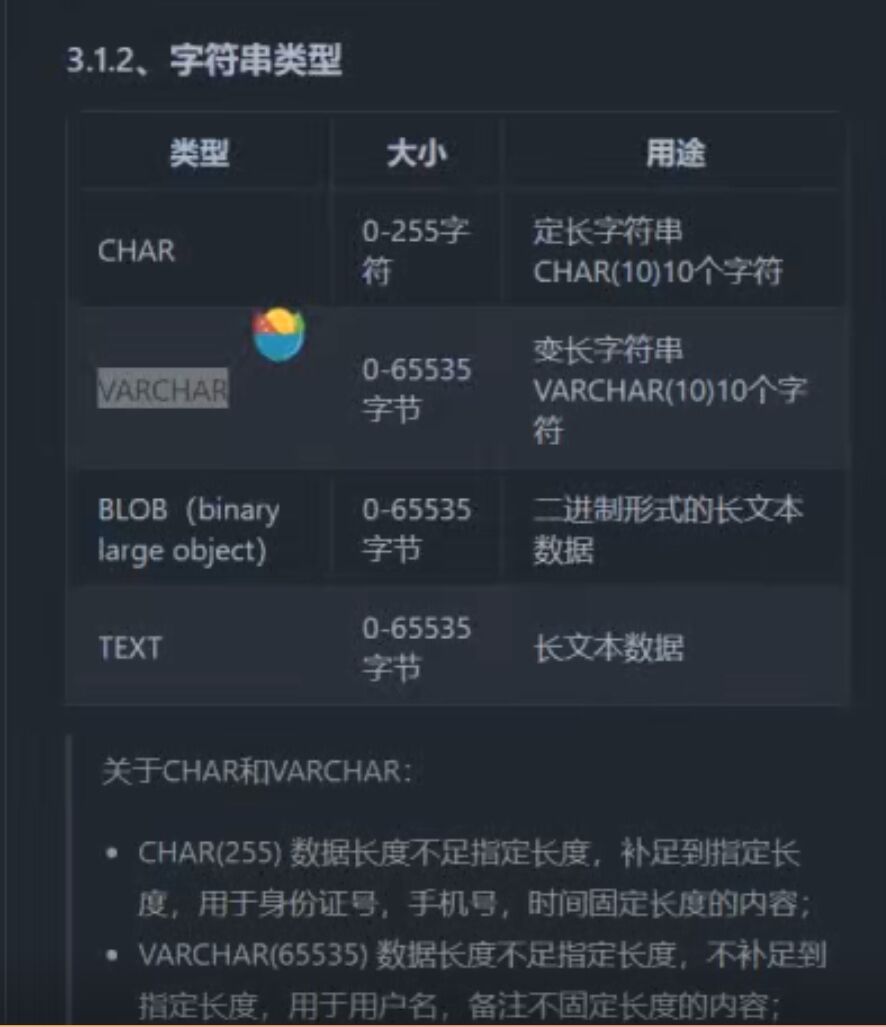 补充:VARCHAR单独至少花一个字节保存数据长度,如果长度超过一个字节,就要花费两个字节。
补充:VARCHAR单独至少花一个字节保存数据长度,如果长度超过一个字节,就要花费两个字节。
DDL相关:
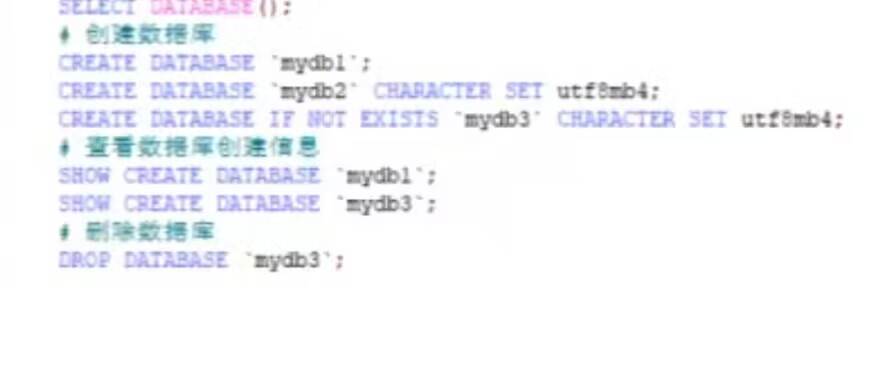
3.2、创建表 (也可以右键手敲创建表)
语法!!:
CREATE TABLE [ IF NOT EXISTS ] 表名(
列名 数据类型 [约束],
列名 数据类型 [约束],
列名 数据类型 [约束]//不要逗号
)[CHARSET=utf8];//这里加逗号
3.3、查看表

3.4、修改表
同样补充见文章1 2

DML相关:
查询stu表中所有数据
SELECT * FROM 'stu'
//添加数据1 INSERT INTO ‘表名’ ('列名1',‘列名2’)VALUES(列值1,列值2);
//1、需要为哪些列添加数据,就要将列名写在表名后面
//2、如果要为所有列添加数据
* 表名后面的()中填写所有的列名
* 表名后面什么列名和()都不写
//3、表名后面有几个列VALUES后面就要按照列名的顺序设置对应的列值
//4、不管表名后面有几个列名,每次添加都是添加一行
添加数据2 INSERT INTO ‘表名’ ('列名1',‘列名2’)VALUES(列值1,列值2),(列值1,列值2),(列值1,列值2);//能添加三行数据
INSERT INTO 'stu' ('name','age','gender') VALUES('张三',‘20‘,’男‘);
INSERT INTO 'stu' (’id‘,'name','age','gender') VALUES(10,'lisi',‘20‘,’男‘);
INSERT INTO 'stu' VALUES(10,'lisi',‘20‘,’男‘);
3.5、修改数据
//修改表中的数据
//UPDATE '表名’ SET ‘列名1’ = 列值1,‘列名2’ = 列值2 WHERE 条件;
//IS NULL:判断是否为NULL
# 将id为1的学生的姓名修改为“张三”
UPDATE ‘stu’ SET ‘name’ = ‘张三’ WHERE ‘id' = 1;
# 将学生表中空地址修改“北京”
UPDATE ’stu‘ SET ’addr‘ = ’北京‘ WHERE ’addr‘ IS NULL;
# 将tom和bob的年龄修改为30
UPDATE ’stu‘ SET 'age' = 30 WHERE 'name' = 'tom' OR 'name' = 'bob';
# 将年龄为30并且地址为qd的地址修改为“青岛”
UPDATE 'stu' SET 'addr' = '青岛' WHERE 'age' = 30 AND 'addr' = 'qd';
# 将年龄为10和20的地址修改为上海
UPDATE ’stu‘ SET ’addr‘ = ’上海‘ WHERE 'age' = 10 OR 'age' = 20;
UPDATE ’stu‘ SET ’addr‘ = ’上海‘ WHERE 'age' IN(10,20);
3.6、删除数据
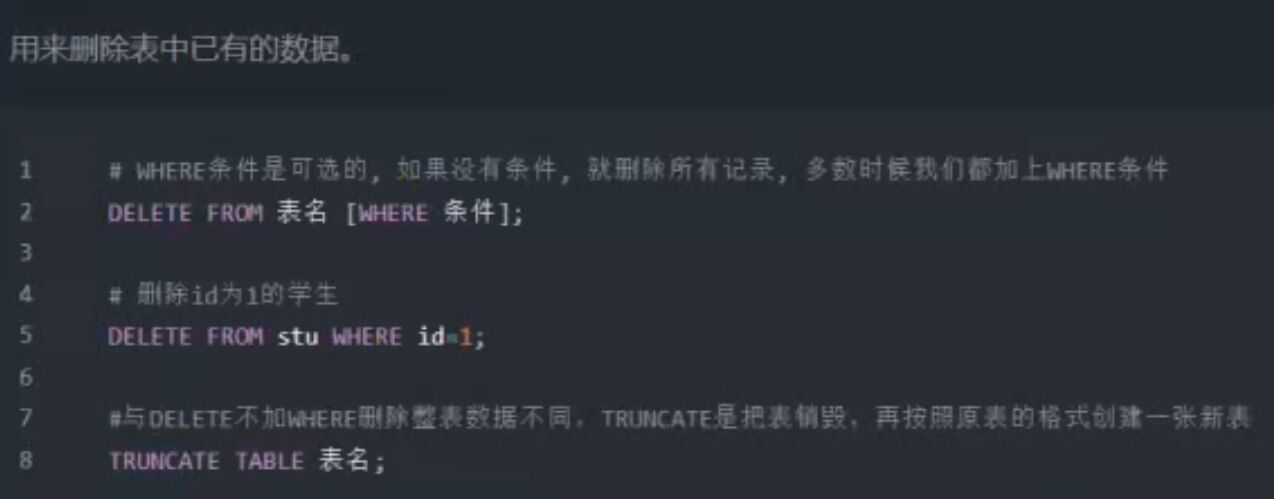
四、约束
1、是什么?
用于限制加入表的数据的类型和规范,约束是添加在列上的,用来约束列的。
分类:
实体完整性约束;
域完整性约束;
引用完整性约束。
2、实体完整性约束
2.1、主键约束
标识表中的一行数据,是该行数据的唯一标识,特性:
非空 ;唯一 ; 被引用(在外键中引用)
当表的某一列被指定为主键后,该列就不能为空,不能有重复值出现。
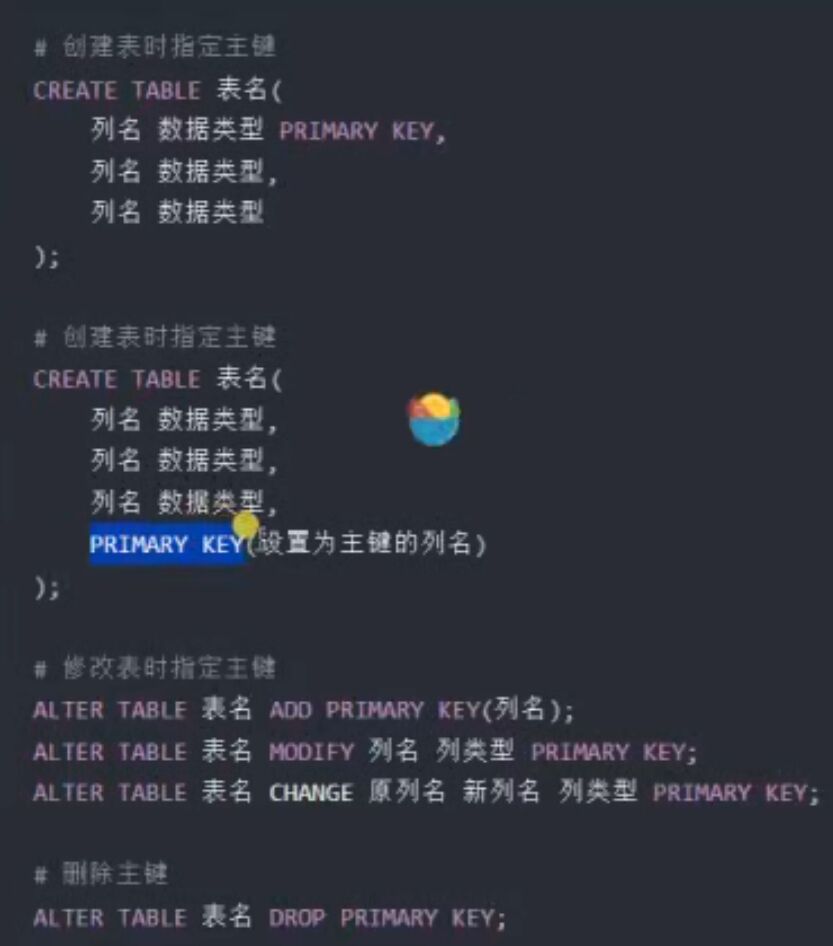
2.2、主键自增长
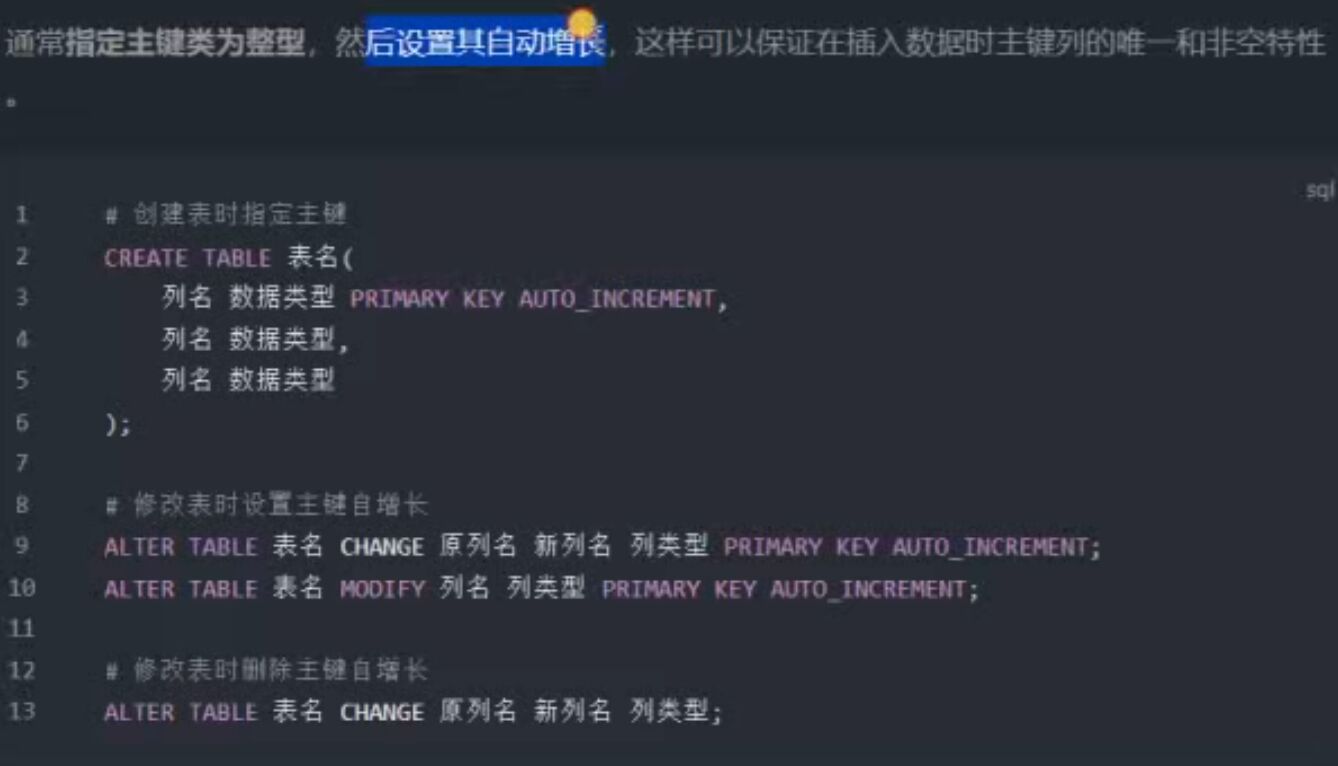
2.3、唯一约束
某些列不能设置重复的值,所以可以对列添加唯一约束。
、
3、域名完整性
3.1、非空约束
此列必须有值,某些列不能设置为NULL值
 3.2、默认值
3.2、默认值
为列赋予默认值,当新增数据不指定值是,书写DEFAULT,以指定的默认值进行填充

4、引用完整性约束
这里说的引用完整性约束就是指的外键约束,作用:
引用外部表的某个列的值;
新增数据时,约束此列的值必须是引用表中已经存在的值。
外键的特点:
外键必须是另一表的主键的值(外键要引用主键!);
外键可以重复;
外键可以为空;
一张表中可以有多个外键。

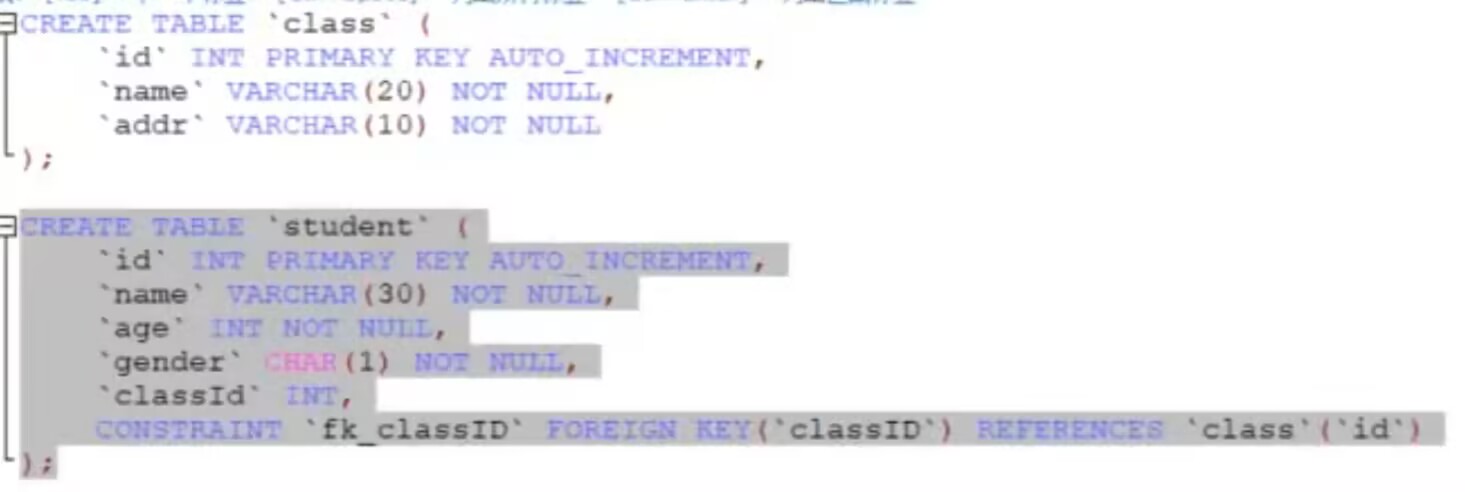 五、表结构
五、表结构
练前准备:
CREATE TABLE IF NOT EXISTS `student`(
`student_id` INT(10) NOT NULL AUTO_INCREMENT COMMENT '学号',
`student_name` VARCHAR(10) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`birthday` DATETIME NOT NULL COMMENT '出生日期',
`gender` VARCHAR(10) NOT NULL DEFAULT '男' COMMENT '性别',
PRIMARY KEY(`student_id`)
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO `student` VALUES
(1 , '赵雷' , '1990-01-01' , '男'),
(2 , '钱电' , '1990-12-21' , '男'),
(3 , '孙风' , '1990-12-20' , '男'),
(4 , '李云' , '1990-12-06' , '男'),
(5 , '周梅' , '1991-12-01' , '女'),
(6 , '吴兰' , '1992-01-01' , '女'),
(7 , '郑竹' , '1989-01-01' , '女'),
(8 , '张三' , '2017-12-20' , '女'),
(9 , '李四' , '2017-12-25' , '女'),
(10 , '李四' , '2012-06-06' , '女'),
(11 , '赵六' , '2013-06-13' , '女'),
(12 , '孙七' , '2014-06-01' , '女');
CREATE TABLE IF NOT EXISTS `course`(
`course_id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '课程编号',
`course_name` VARCHAR(10) NOT NULL COMMENT '课程名',
`teacher_id` INT(10) NOT NULL COMMENT '任课教师工号',
PRIMARY KEY(`course_id`)
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO `course` VALUES
(1, '语文', 2),
(2, '数学', 1),
(3, '英语', 3);
CREATE TABLE IF NOT EXISTS `teacher`(
`teacher_id` INT(10) NOT NULL AUTO_INCREMENT COMMENT '教师工号',
`teacher_name` VARCHAR(10) NOT NULL DEFAULT '匿名' COMMENT '教师姓名',
PRIMARY KEY(`teacher_id`)
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO `teacher` VALUES
(1, '高斯'),
(2, '李白'),
(3, 'Trump');
CREATE TABLE IF NOT EXISTS `score`(
`student_id` INT(10) NOT NULL COMMENT '学号',
`course_id` INT(4) NOT NULL COMMENT '课程编号',
`score` DECIMAL(18,1) COMMENT '成绩',
KEY(`course_id`)
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO `score` VALUES
(1 , 1 , 80),
(1 , 2 , 90),
(1 , 3 , 99),
(2 , 1 , 70),
(2 , 2 , 60),
(2 , 3 , 80),
(3 , 1 , 80),
(3 , 2 , 80),
(3 , 3 , 80),
(4 , 1 , 50),
(4 , 2 , 30),
(4 , 3 , 20),
(5 , 1 , 76),
(5 , 2 , 87),
(6 , 1 , 31),
(6 , 3 , 34),
(7 , 2 , 89),
(7 , 3 , 98);
5.1、见练习及其注释:
-- 注释内容
#注释内容
#查询女同学的数据
select * from student where gender='女';
#查询id大于9的同学的信息
select * from student where student_id>9;
#查询id是1689这几个值的数据
select * from student where student_id in (1,6,8,9);
#模糊查询 像XX样子的查询
#查询张姓同学的数据
select * from student where student_name like '张%';
#模糊查询中可以使用两种占位符
# _ 代表有且仅有一个字符
# % 任意个数的字符
#例子:查询张X like '张_'
#张XX like '张__' 两个下划线
# 查询名字中包含 荣 like '%荣%'
#查询叫某电同学的信息
select * from student where student_name like '_电';
#查询名字中有 文 这个字的科目信息
select * from course where course_name like '%文%';
insert into score(student_id,course_id) value(1,2);
#查询 成绩表中成绩为空的数据
select * from score where score=null;
# 不行 对空值的判断要使用is
select * from score where score is null;
#判断非空使用is not null 不能not is null
select * from score where score is not null;
#排序 对查询结果进行排序
select * from student ORDER BY student_name;
#通过id值正序排序
select * from student ORDER BY student_id asc;
#通过id值倒数排序
SELECT * FROM student ORDER BY student_id desc;
#排序列后不使用排序方式,默认使用asc正序排序 从小到大
#可以指定多个列进行排序
SELECT * FROM student ORDER BY student_name,student_id;
#下面两行结果一样
SELECT * FROM student ORDER BY student_name asc,student_id desc;
SELECT * FROM student ORDER BY student_name,student_id desc;
-- 每一个排序列都需要指定排序方式 如果不指定就是asc
#关联查询
#子查询 在一个查询语句中包含另一个查询语句
#查询出 成绩在80分以上同学的信息
SELECT * FROM score WHERE score>80;
SELECT * FROM student WHERE student_id in (SELECT student_id FROM score WHERE score>80);
SELECT * FROM student;
SELECT * FROM score;
SELECT a.* , b.* FROM student AS a JOIN score as b on a.student_id=b.student_id;
#查询每个学生的姓名和成绩
SELECT a.student_name , b.score from student as a JOIN score as b on a.student_id=b.student_id;
#查询学生 科目 成绩 可以省略as
SELECT a.student_name,c.course_name,b.score FROM student as a JOIN score as b on a.student_id=b.student_id JOIN course as c on c.course_id=b.course_id;
# 连接方式
# 内连接
# inner join 内连接 会将关联条件成立的数据存入结果集
# 外连接
# 左外连接 left join 将左表视为主表,会显示主表中的所有数据
# 右外连接 right join 将右表视为主表,会显示主表中的所有数据
SELECT a.* , b.* from student AS a left JOIN score AS b on a.student_id=b.student_id;
# 查询出缺考同学的信息 有学生的信息 但是没有该学生的成绩
SELECT a.student_id,a.student_name from student as a left join score as b on a.student_id=b.student_id WHERE b.student_id is null;
5.2、去重 合并 分组 聚合 索引
#去重 去除掉重复的结果
SELECT student_name FROM student;
# distinct 对完整的结果集进行去重 不是对单个列进行去重
SELECT DISTINCT student_name FROM student;
SELECT * FROM student
SELECT DISTINCT student_name,gender FROM student;
SELECT DISTINCT student_name,gender,student_id FROM student;
# 合并结果集
SELECT student_name FROM student;
SELECT teacher_name FROM teacher;
#合并 union
SELECT student_name as '人员信息' FROM student
union
SELECT teacher_name FROM teacher;
# 注意 怎样的结果集能够合并 合并的两个结果集和类型[[没有关系]]
# 合并结果集时,前后的SQL语句的字段数量必须一样
SELECT birthday FROM student
UNION
SELECT teacher_id FROM teacher;
#合并多个结果集
SELECT * FROM student
UNION
SELECT *,1,2 FROM teacher
UNION
SELECT 4,5,6,7
# 分组查询
# 按照每一个字段的内容不同。将表中数据分成一个一个的组,可以通过组中数据处理得到分组数据
# 查询出各个性别同学的数量
SELECT gender,COUNT(*) as '人数' FROM student GROUP BY gender
# 通过分组,并且可以将分组的多条数据,
# 提取出一个数据来这样的函数叫做聚合数
# MYSQL中一共有五个聚合函数 count sum avg max min
# 查询每个同学的最高成绩
# 结果集中 id name 最高成绩
# 对分组后的结果进行筛选 having
# having 关键的使用和select的使用
SELECT a.student_id,student_name,MAX(b.score)
FROM student AS a left join score as b
on a.student_id=b.student_id
GROUP BY a.student_id
# 查询每个科目的平均成绩
SELECT a.course_id,course_name,AVG(b.score)
FROM course AS a left join score as b
on a.course_id=b.course_id
GROUP BY a.course_id
# 没有count也可以
SELECT a.student_id,student_name,COUNT(*)
FROM student AS a left join score as b
on a.student_id=b.student_id
GROUP BY a.student_id
HAVING count(*)>2
# 索引 index
# 目的:加快检索数据的速度
# 什么是索引:索引是一种能够加快检索数据速度的数据结构
# 分类: 聚簇索引 非聚簇索引
# 聚簇索引:当创建主键后,表中所有的数据都聚集在索引之下
# 聚簇索引的数据结构保存在mysql表的数据文件中
# 非聚簇索引会有一个单独的文件来保存索引内容
# (非聚簇索引和数据是不直接关联的)
# 聚簇索引叶子结点指向的是表中数据
# 非聚簇索引叶子结点指向的是主键的值
# 通过业务分类:主键索引 唯一索引 普通索引 联合索引 全文索引
# 如何创建索引?
CREATE INDEX index_student_name ON student(student_name);
#短索引 在购物软件中 减少索引维护的成本
# 怎么用索引?
# 在where 字句中使用索引列当做条件 就可能使用到索引
SELECT * FROM student WHERE student_name='张三';
# 检测一个SQL语句是否使用到索引了 -- 执行计划
EXPLAIN SELECT * FROM student WHERE student_name='张三';
EXPLAIN SELECT * FROM student WHERE student_id=0;
EXPLAIN SELECT * FROM student WHERE student_name LIKE'%张%';
EXPLAIN SELECT * FROM student WHERE student_name='张三' OR gender='女';
EXPLAIN SELECT * FROM student WHERE student_name='张三' OR student_id=3;
EXPLAIN SELECT * FROM student WHERE student_name=12
EXPLAIN SELECT * FROM student WHERE SUBSTR(student_name,1,1) ='张'
# 索引失效的情况 使用了索引列但是索引没有生效
# 索引生效: 加快检索速度?
# 索引失效: 就会将表中所有的数据都进行检测
# 1.liek 第一个字符不是确定字符
# 2.or 会造成索引失效 如果or 两侧都是索引列索引会生效
# 3.类型发生转换
# 4.索引列的类型发生转换
# 5.索引列的数据经过函数处理
# 6.mysql认为不需要使用索引