Day12
1. 链表和数组有什么区别?
在存储方式上,数组是连续内存存储,所有元素在内存中是连续排列的,因此可以通过下标快速访问(O(1)),但插入、删除操作代价高,需要移动后续元素(O(n))。而链表是非连续存储,每个元素是一个节点,包含数据和指向下一个节点的指针,因此插入、删除效率高(O(1)),但查找元素需要从头开始遍历(O(n))。此外,数组的大小是固定的(除非使用动态数组如 ArrayList),而链表是动态扩容的,适合不确定大小的场景。
数组适合查找频繁、元素数量固定的场景;链表适合插入删除频繁、元素数量动态变化的场景。
2. 如何使用两个栈实现队列?
使用两个栈(我们称为 inStack 和 outStack)可以实现一个先进先出(FIFO)的队列。核心思想是:
- 入队操作(enqueue):直接压入 inStack。
- 出队操作(dequeue):如果 outStack 为空,则将 inStack 中的所有元素弹出并依次压入 outStack,然后从 outStack 弹出栈顶元素。
把一个栈当作输入端,另一个当作输出端,每当需要出队时,把输入栈的元素全部倒入输出栈,从而实现先进先出。
import java.util.Stack;public class MyQueue {private Stack<Integer> inStack = new Stack<>();private Stack<Integer> outStack = new Stack<>();// 入队public void enqueue(int x) {inStack.push(x);}// 出队public int dequeue() {if (outStack.isEmpty()) {while (!inStack.isEmpty()) {outStack.push(inStack.pop());}}if (outStack.isEmpty()) {throw new RuntimeException("Queue is empty");}return outStack.pop();}// 获取队首元素但不出队public int peek() {if (outStack.isEmpty()) {while (!inStack.isEmpty()) {outStack.push(inStack.pop());}}if (outStack.isEmpty()) {throw new RuntimeException("Queue is empty");}return outStack.peek();}public boolean isEmpty() {return inStack.isEmpty() && outStack.isEmpty();}
}
3. MySQL的三大日志说一下,分别应用场景是什么?
- Redo Log(重做日志):是 InnoDB 存储引擎特有的,用来记录已经提交事务对数据的修改,它保证了即使数据库宕机,只要事务提交了,就可以通过 redo Log 把数据恢复到正确状态,应用场景比如数据库崩溃后重启恢复。
- undo Log(回滚日志):也是 InnoDB 的日志,记录的是事务修改前的数据,用来支持事务的回滚功能,确保在事务失败或主动回滚时可以恢复现场,同时它还支持 MVCC,实现数据库的非阻塞读。
- binlog(二进制日志):属于 MySQL层,记录了所有对数据库数据的更改操作,比如 INSERT、UPDATE、DELETE等,它的主要用途是主从复制和数据恢复,比如主库把 binlog 同步到从库,或者用来做增量备份恢复数据。
| 日志类型 | 举例操作 | 什么时候用 |
|---|---|---|
| redo log | 崩溃后还能恢复转账数据 | 保证事务提交后数据不丢 |
| undo log | 撤销更新操作,快照读 | 支持事务回滚、MVCC 快照读取 |
| binlog | 主从复制、恢复历史数据 | 数据备份、恢复、数据库同步 |
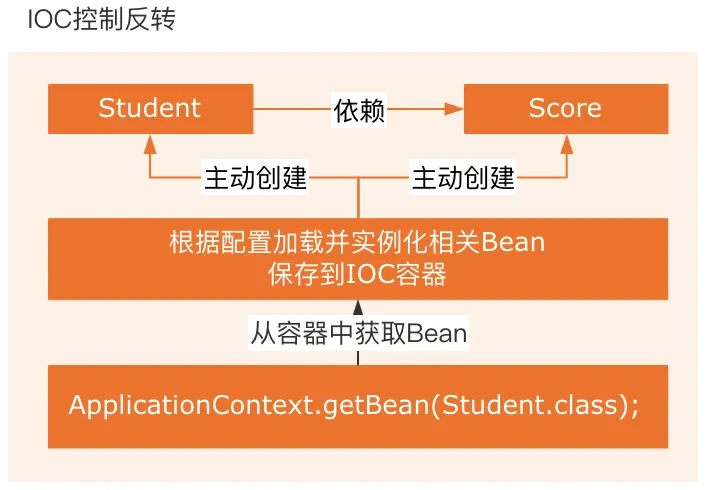
4. Spring的IOC介绍一下?
IOC 全称是 Inversion of Control,中文叫做“控制反转”,它是一种设计思想,不特指某个技术或框架。在 Spring中,IOC 的核心含义是:对象的创建、初始化、以及它所依赖的其他对象的注入,不再由我们自己控制,而是交给 Spring 容器负责。
Spring 是通过依赖注入(DI)机制来实现控制反转,即:你不需要创建依赖对象,而是通过注入的方式由 Spring 自己提供。
| 注入方式 | 描述说明 | 示例注解或语法 |
|---|---|---|
| 构造器注入 | 在创建对象时通过构造方法传入依赖对象(强依赖推荐) | @Autowired构造器 |
| Setter注入 | 在对象创建后通过setter方法注入依赖对象(可选依赖) | @Autowired 方法 |
| 字段注入 | 直接在字段上标注注解,Spring 反射注入(简洁但不易测试) | @Autowired 字段 |
| Java配置注入 | 使用 @Bean 方法手动注册 Bean 并注入 | @Configuration |
| 好处 | 说明 |
|---|---|
| 解耦合 | 类之间通过接口而非具体实现耦合,增强了灵活性 |
| 易测试 | 可通过 Mock 对象轻松替换依赖,适合单元测试 |
| 易扩展维护 | 不同实现类可以随时替换(只需修改配置),实现“开闭原则” |
| 统一管理生命周期 | Spring 控制 Bean 的创建、销毁等生命周期,开发者只关注业务逻辑 |
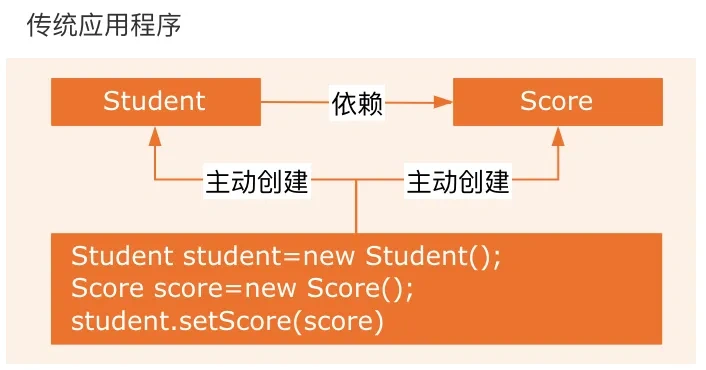
传统的 Java SE 程序设计中,我们直接在对象内部通过 new 的方式来创建对象,是程序主动创建依赖对象。
5. 为什么依赖注入不适合使用字段注入?
字段注入可能引起三个问题:
- 对象的外部可见性差,依赖不可见:字段注入是通过反射进行的,注入的依赖对象在类的构造方法中看不到,外部也不清楚这个类到底依赖了什么对象,不利于阅读、理解和维护代码,也违背了依赖显示原则。
- 可能导致循环依赖:字段注入在 Spring 中是实例化对象后通过反射注入的,这比构造器注入更晚。所以放发生循环依赖时(A 注入 B,B 注入 A),字段注入可能不会立即暴露出来,出错位置不明显,难以排查和调试。
构造器注入的循环依赖是 Spring 无法处理的,启动时就会报错,反而更容易发现问题;字段注入可能导致隐式循环依赖,运行中才报错。- 无法使用 final 修饰符,也无法注入静态变量:字段注入发生在对象创建之后,Spring 是通过反射设置字段的,所以不能注入 final 字段(编译器会禁止反射修改 final 值)。同样静态变量也不能注入,因为它属于类本身而不是某个对象实例。
6. Spring的AOP介绍一下?
AOP 全称是 Aspect-Oriented Programming(面向切面编程)。它把那些在多个模块中都会用到的、但跟主业务逻辑无关的代码(比如日志、安全、事务、缓存)提取出来单独编写成一个“切面类”,统一管理,减少重复,提高代码清晰度。
AOP 的核心概念包括连接点、切点、通知、切面和织入,Spring 通过 JDK 动态代理或 CGLIB 实现织入。我们可以通过 @Aspect 和一系列注解来定义切面,常见的场景包括日志记录、权限控制、事务管理等。
| 概念 | 中文 | 作用 |
|---|---|---|
| JoinPoint | 连接点 | 可能被拦截的方法执行点(如某个 service 方法) |
| Pointcut | 切点 | 明确拦截哪些连接点(通过表达式来定义) |
| Advice | 通知 | 要织入的方法逻辑,分为前置、后置、环绕等 |
| Aspect | 切面 | Pointcut + Advice 的组合 |
| Weaving | 织入 | 把 Advice 和业务方法组合的过程,Spring 用代理实现 |
Spring AOP 是通过 代理机制 实现的:
- 如果目标类实现了接口 → 使用 JDK 动态代理
- 如果目标类没有实现接口 → 使用 CGLIB 生成子类字节码代理
所以 AOP 只对 Spring 容器管理的 Bean 有效,自己 new 出来的对象不会生效。
7. Spring的事务,使用this调用是否生效?
在同一个类中,使用 this 调用被
@Transactional注解的方法,事务通常不会生效。
- Spring 事务管理基于 AOP(面向切面编程)实现:当你给一个方法加上
@Transactional注解时,Spring 并不会直接修改你的原始类(目标对象)。Spring 会创建一个代理对象(Proxy)来“包裹”你的目标对象。这个代理对象负责在目标方法执行前后添加事务管理逻辑(开启事务、提交/回滚事务等)。- 代理对象的工作方式:外部代码(比如另一个类中的方法)调用你的
@Transactional方法时,实际上调用的时这个代理对象上的方法。代理对象先进行事务处理(如开启事务),然后再调用目标对象内部真正的对应方法。这时事务逻辑才得以执行。- this 调用破坏了代理机制:当你在同一个类的一个方法(比如方法 A)中,使用
this.xxx()调用另一个被@Transactional注解的方法(比如方法 B)时,这个 this 关键字指向的是当前类的原始目标对象本身,而不是 Spring 创建的代理对象。因为调用发生在目标对象内部,它直接调用了自身的方法 B,完全绕过了外部的代理对象。既然代理对象没有介入,那么代理对象添加的事务管理逻辑(开启事务等)也就根本不会执行。方法B虽然被注解了,但就像没有注解一样运行在无事务环境中。
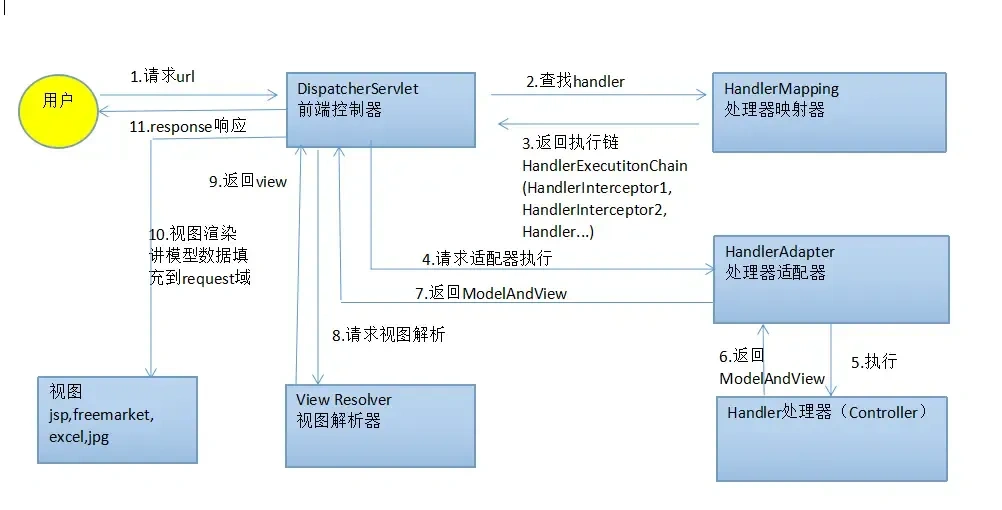
8. Spring MVC的工作流程描述一下?
当用户发送请求后,Spring MVC 的核心组件
DispatcherServlet首先接收到这个请求。它通过HandlerMapping查找对应的处理器(Controller),并返回一个包含处理器及其拦截器的执行链。接着由HandlerAdapter调用实际的 Controller 方法,同时完成参数封装、数据校验等操作。Controller 处理完业务逻辑后返回一个ModelAndView,DispatcherServlet会将它交给ViewResolver来解析具体的视图对象(如JSP)。最后,DispatcherServlet渲染视图,把数据填充进去后返回给客户端完成响应。整个流程体现了请求分发、控制器处理、视图渲染的解耦,保证了 Spring MVC 的灵活性和扩展性。