java day15 (数据库)
进入数据库的学习
DB
因为数据太多了,方便统一管理的软件
操作就不用改代码了,直接改数据库则可;

命令就是sql语句
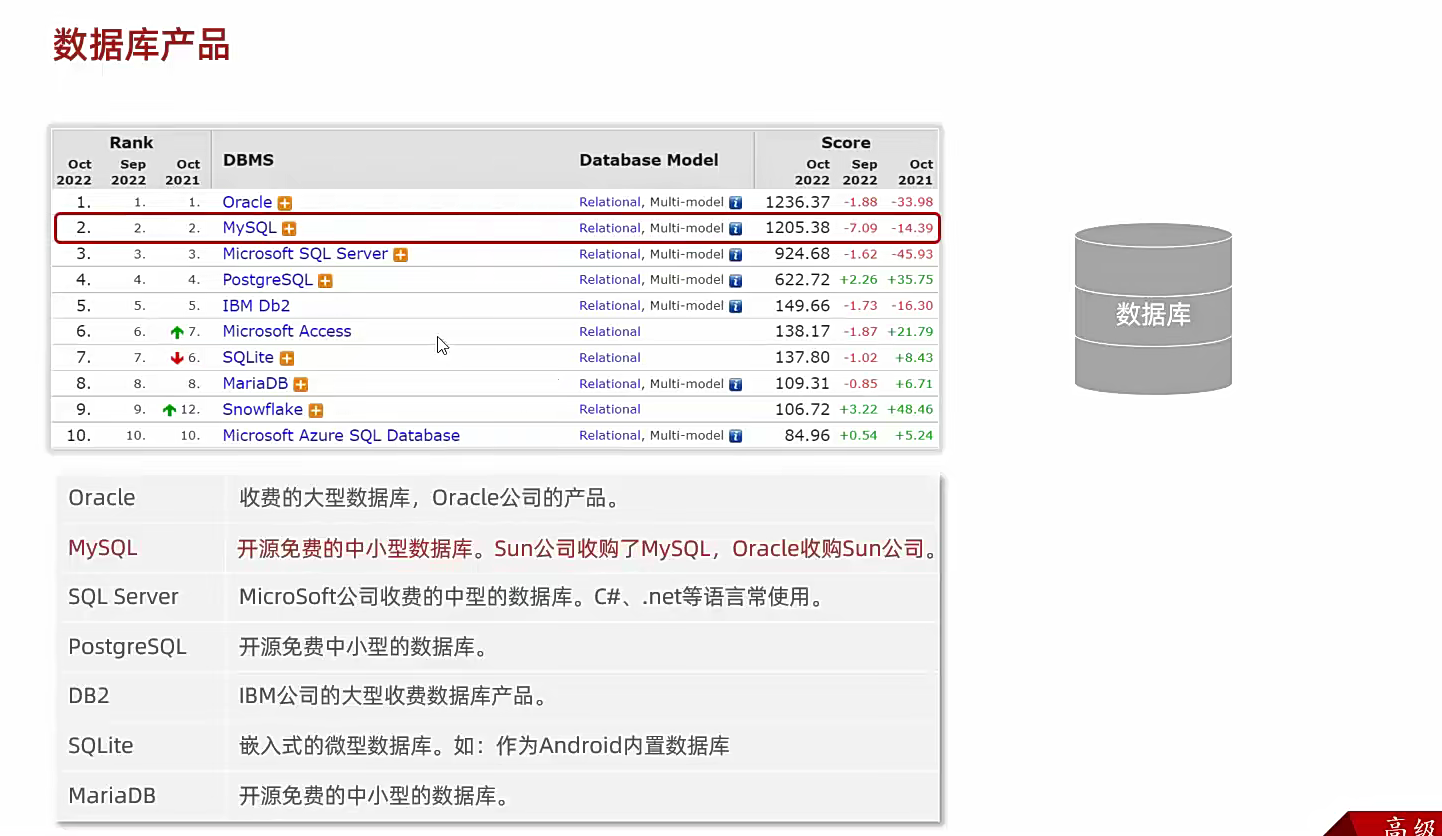
这些都是关系型数据库,sql可以控制全部,至于具体的环境我以前就有安装过了;
理解,在企业开发过程中呢;数据是在一个中心服务器的,为了避免丢失或者窃取而且得方便存储;然后就集中在一台服务器上;多个电脑通过sql软件连接;连接上了之后进行访问和修改;
有很多的软件都类似;
我们可以通过虚拟机来实现,就是把虚拟机当作内个中央机房,你连接,通过软件访问,去用;
虚拟机就vmware;
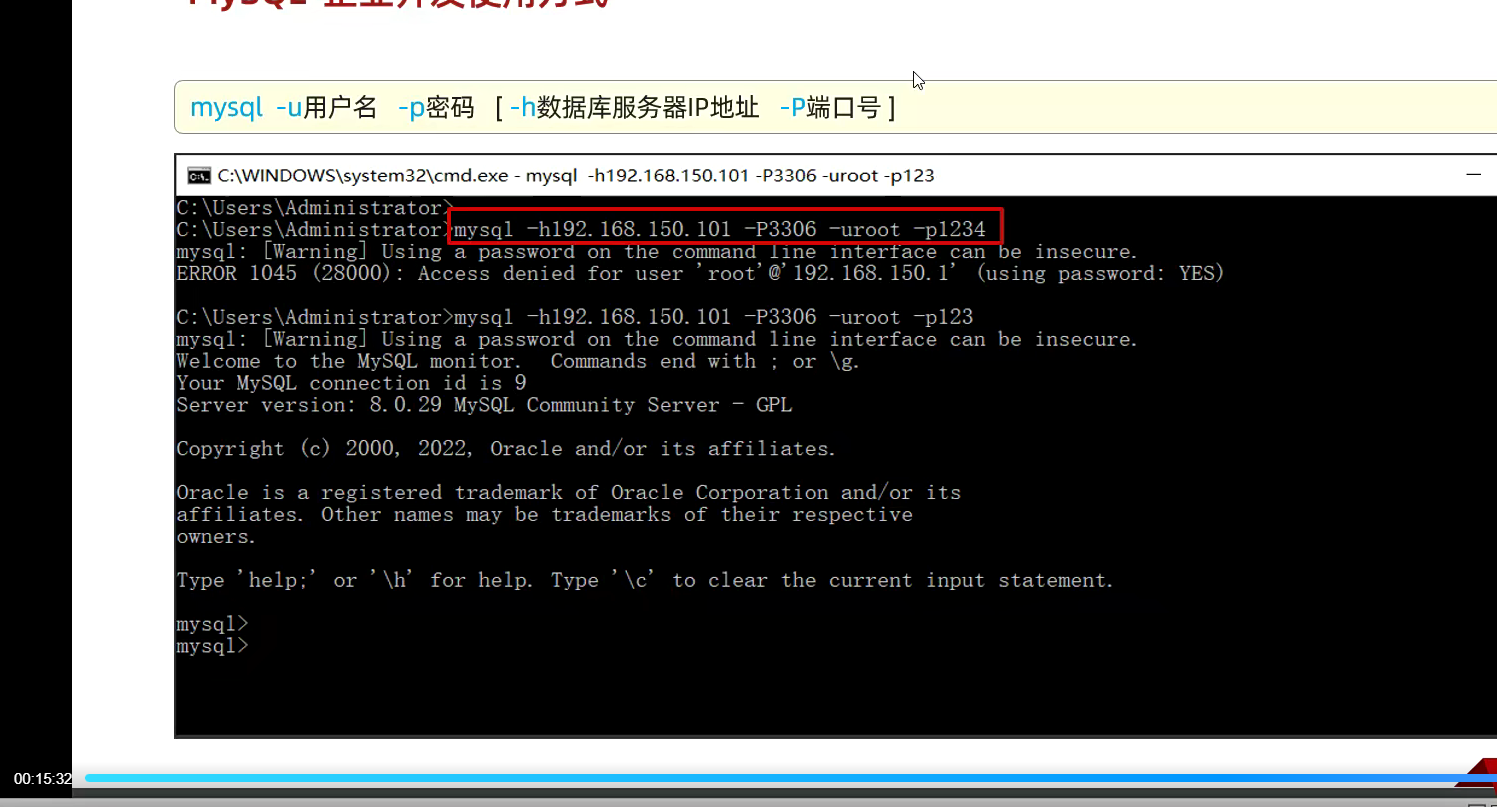
通过这条指令去连接数据库,可以指定连接某一条;
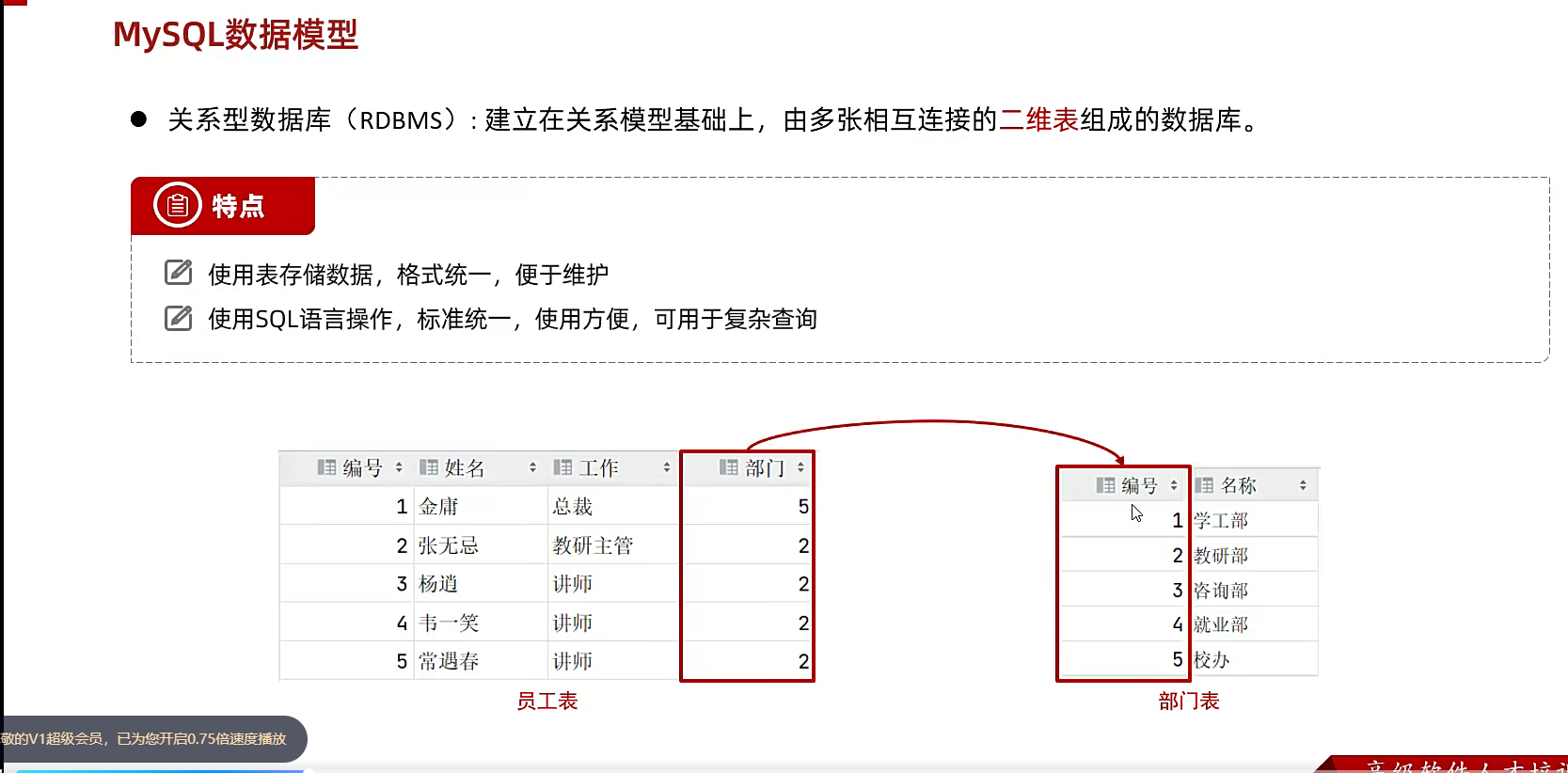
很多表彼此之间有联系
比如redis就是非关系型的数据库中间件;
登录语句;


用户通过数据库先连接,然后按照数据库语句进行创造;比如创一个数据库吧,然后这个数据库里面可以放很多表
然后也可以创一些用户;这些用户能操作哪些表;
**sql语句四大类:
DDL操作表,字段的
DML,增删改
DQL,查
DCL 创建用户**

这是一个企业拿到一个项目之后,立马该干的事情;
先产品经理给原型;然后我们先完成数据库设计;然后一个个模块和功能开始实现;最后推出上线之后要优化更新;
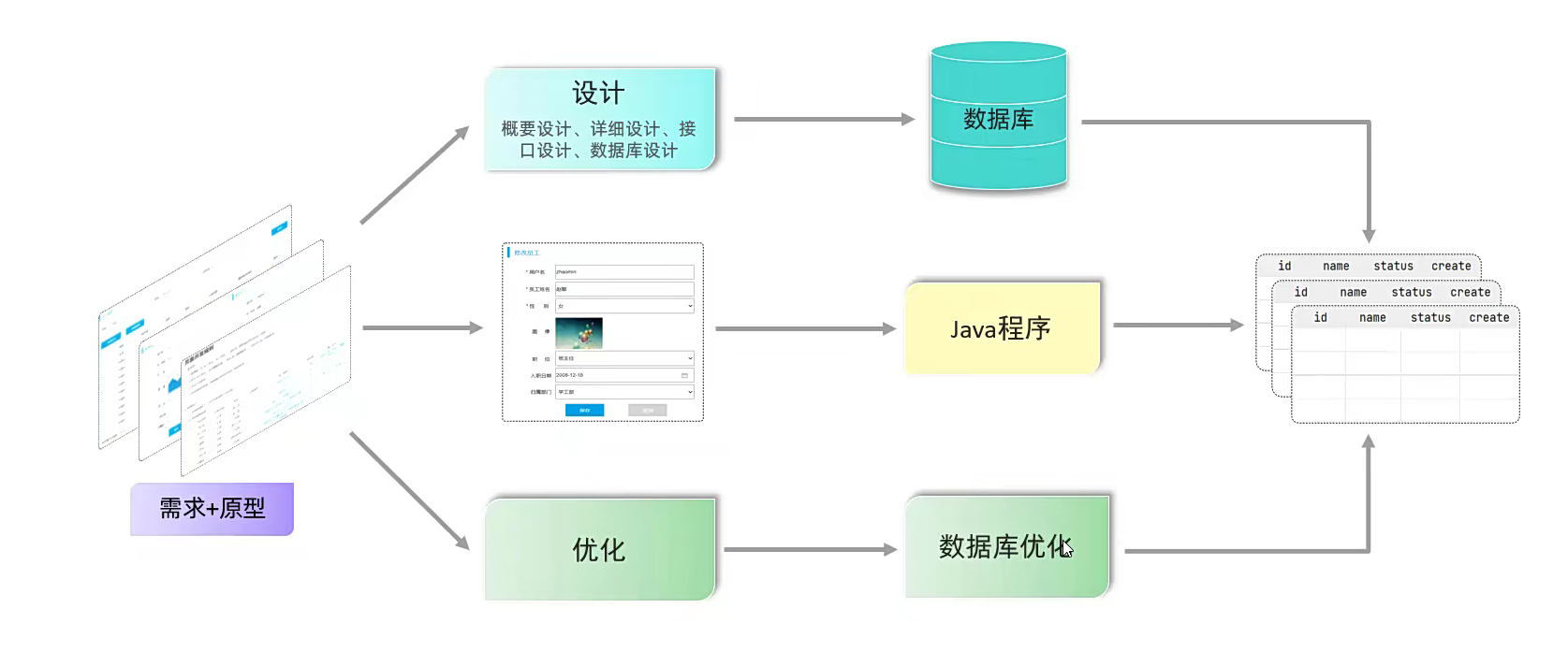
前面两个就是,一个是数据库的设计;一个是数据库的操作;
SQL语句

SQL语句要加上封号
登录mysql -u root -p
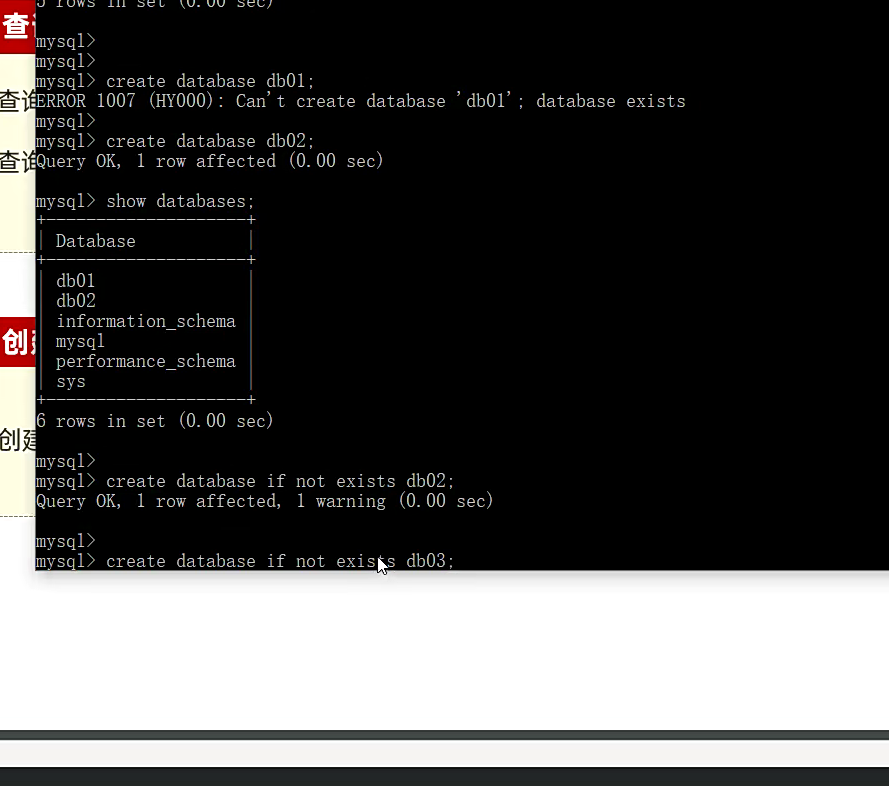
创建数据库 create database 创建数据库,后面跟数据库名字就行; if not exists这个语句加上就是如果这个数据库有的话,不报错,没有的话就创建
use 数据库名
就是使用这个数据库了
大部分sql语句
操作类型 SQL 语句 示例
-
数据库操作
创建数据库 CREATE DATABASE database_name; CREATE DATABASE mydb;
创建(不存在时) CREATE DATABASE IF NOT EXISTS database_name; CREATE DATABASE IF NOT EXISTS mydb;
指定字符集 CREATE DATABASE database_name CHARACTER SET charset_name; CREATE DATABASE mydb CHARACTER SET utf8mb4;
查看所有数据库 SHOW DATABASES; SHOW DATABASES;
查看创建语句 SHOW CREATE DATABASE database_name; SHOW CREATE DATABASE mydb;
修改字符集 ALTER DATABASE database_name CHARACTER SET charset_name; ALTER DATABASE mydb CHARACTER SET utf8;
删除数据库 DROP DATABASE database_name; DROP DATABASE mydb;
删除(存在时) DROP DATABASE IF EXISTS database_name; DROP DATABASE IF EXISTS mydb;
使用数据库 USE database_name; USE mydb;
查看当前正在使用的数据库select database(); -
表操作
操作类型 SQL 语句 示例
创建表 CREATE TABLE table_name (column1 data_type constraint, …); CREATE TABLE student (id INT PRIMARY KEY, name VARCHAR(50));
复制表结构 CREATE TABLE new_table_name LIKE existing_table_name; CREATE TABLE student_backup LIKE student;
查看所有表 SHOW TABLES; SHOW TABLES;
查看表结构 DESC table_name; 或 DESCRIBE table_name; DESC student;
重命名表 ALTER TABLE table_name RENAME TO new_table_name; ALTER TABLE student RENAME TO stu;
添加字段 ALTER TABLE table_name ADD column_name data_type constraint; ALTER TABLE student ADD age INT;
修改字段名 ALTER TABLE table_name CHANGE old_column new_column new_data_type; ALTER TABLE student CHANGE age new_age INT;
修改字段类型 ALTER TABLE table_name MODIFY column_name new_data_type; ALTER TABLE student MODIFY age TINYINT;
删除字段 ALTER TABLE table_name DROP column_name; ALTER TABLE student DROP age;
删除表 DROP TABLE IF EXISTS table_name; DROP TABLE IF EXISTS student; -
数据操作(增删改查)
操作类型 SQL 语句 示例
插入数据
插入指定列 INSERT INTO table_name (column1, column2) VALUES (value1, value2); INSERT INTO student (name, age) VALUES (‘Alice’, 20);
插入全列 INSERT INTO table_name VALUES (value1, value2, …); INSERT INTO student VALUES (1, ‘Bob’, 21);
插入多行 INSERT INTO table_name (…) VALUES (row1), (row2), …; INSERT INTO student (name) VALUES (‘Charlie’), (‘David’);
删除数据
按条件删除 DELETE FROM table_name WHERE condition; DELETE FROM student WHERE age < 18;
删除全量数据 DELETE FROM table_name; 或 TRUNCATE TABLE table_name; DELETE FROM student;(保留自增 ID)
修改数据
按条件更新 UPDATE table_name SET column1 = value1 WHERE condition; UPDATE student SET age = 22 WHERE name = ‘Alice’;
全量更新 UPDATE table_name SET column1 = value1; UPDATE student SET age = age + 1;(所有记录年龄 + 1)
查询数据
查询全量数据 SELECT * FROM table_name; SELECT * FROM student;
查询指定列 SELECT column1, column2 FROM table_name; SELECT name, age FROM student;
去重查询 SELECT DISTINCT column1 FROM table_name; SELECT DISTINCT age FROM student;
条件查询 SELECT * FROM table_name WHERE condition; SELECT * FROM student WHERE age > 20 AND gender = ‘M’;
模糊查询 SELECT * FROM table_name WHERE column LIKE pattern; SELECT * FROM student WHERE name LIKE ‘A%’;
范围查询 SELECT * FROM table_name WHERE column BETWEEN value1 AND value2; SELECT * FROM student WHERE age BETWEEN 18 AND 25;
排序查询SELECT * FROM table_name ORDER BY column [ASC DESC];SELECT * FROM student ORDER BY age DESC;
分页查询 SELECT * FROM table_name LIMIT offset, row_count; SELECT * FROM student LIMIT 0, 10;(前 10 条)
聚合查询 SELECT COUNT/SUM/AVG/MAX/MIN(column) FROM table_name; SELECT COUNT() FROM student;(统计总数)
分组查询 SELECT column1, COUNT() FROM table_name GROUP BY column1; SELECT gender, COUNT(*) FROM student GROUP
起别名 SELECT 列 别名 from 表名; 需要有空格那就直接打个引号; -
常用约束与关键字
约束 / 关键字 说明 示例
PRIMARY KEY 主键约束(唯一且非空) id INT PRIMARY KEY
AUTO_INCREMENT 自增(适用于整数类型) id INT AUTO_INCREMENT
NOT NULL 非空约束 name VARCHAR(50) NOT NULL
UNIQUE 唯一约束 email VARCHAR(100) UNIQUE
DEFAULT 默认值 status TINYINT DEFAULT 0
CHECK 检查约束(MySQL 5.7+ 支持) age INT CHECK (age >= 0)
JOIN 表连接(INNER/LEFT/RIGHT/FULL) SELECT * FROM orders JOIN users ON orders.user_id = users.id; -
注意事项
大小写:SQL 关键字(如 SELECT、FROM)不区分大小写,但表名、列名可能区分(取决于数据库配置)。
分号:每条 SQL 语句必须以 ; 结尾。
引号:字符串值用单引号 ‘value’,日期时间也需用引号。
转义字符:字符串中包含单引号时,使用 ’ 或双引号嵌套。
注释:单行注释用 --,多行注释用 /* … */。

来了,可视化的客户端工具;
老师用的是datagrip
我咋感觉还是navicat更多;

这两是同一家,而且也可以直接用idea,现在已经把datagrip的功能集合到idea里面去了;
在idea里面可以直接用;
右侧栏的数据库拉开选择mysql,行了连接这一趴也可以跳过了;之前我做过jdbc的
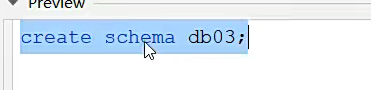
这和创建数据库没区别
进行创建表吧
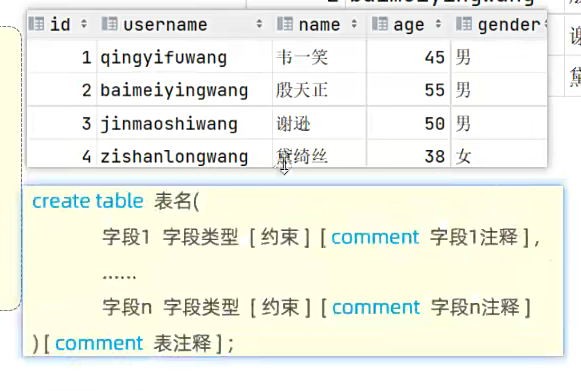
创建一个这样的表
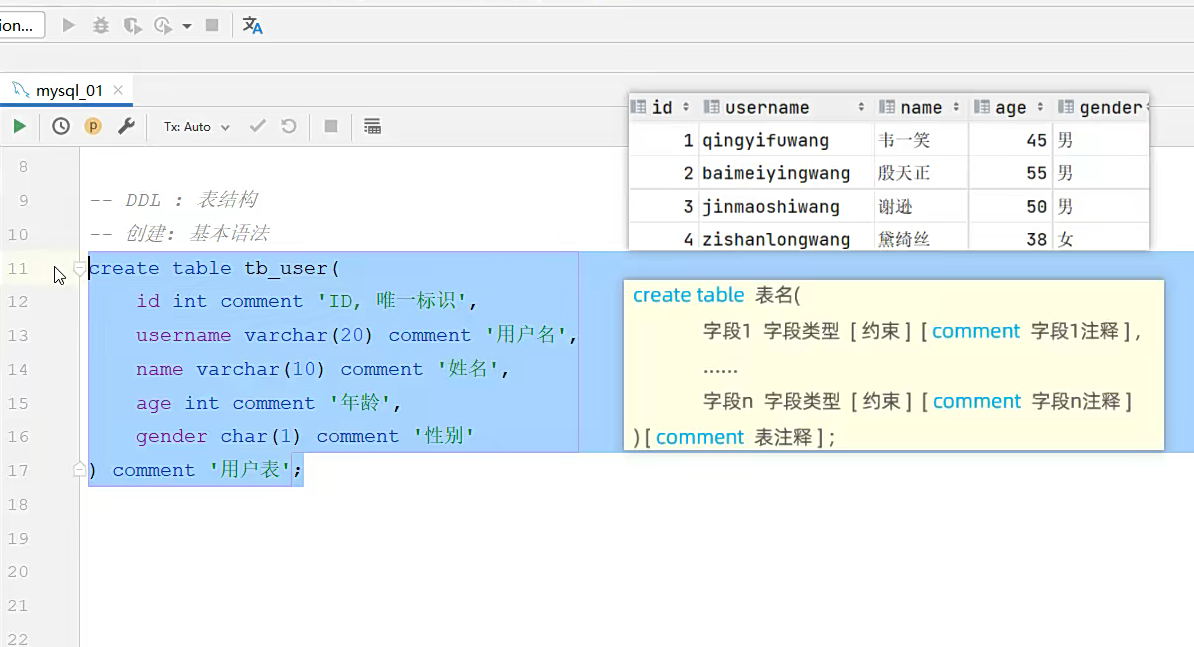
大致就是根据字段创建表;
先前面的创建表和表名吗;
里面就是比如第一个字段是id 那他就是Int 然后后面的就是 comment这个是注释;然后一以此类推;里面的东西挨个建立;最后在表后面的这个也是注释;其实comment’‘这种格式就是注释;最后一个,不用打,
但是现在navicat比较方便呀;直接创就完了,但是也得学,毕竟也不知道下一个公司是不是navicat;
选到表然后点击加号去加值就可以了;
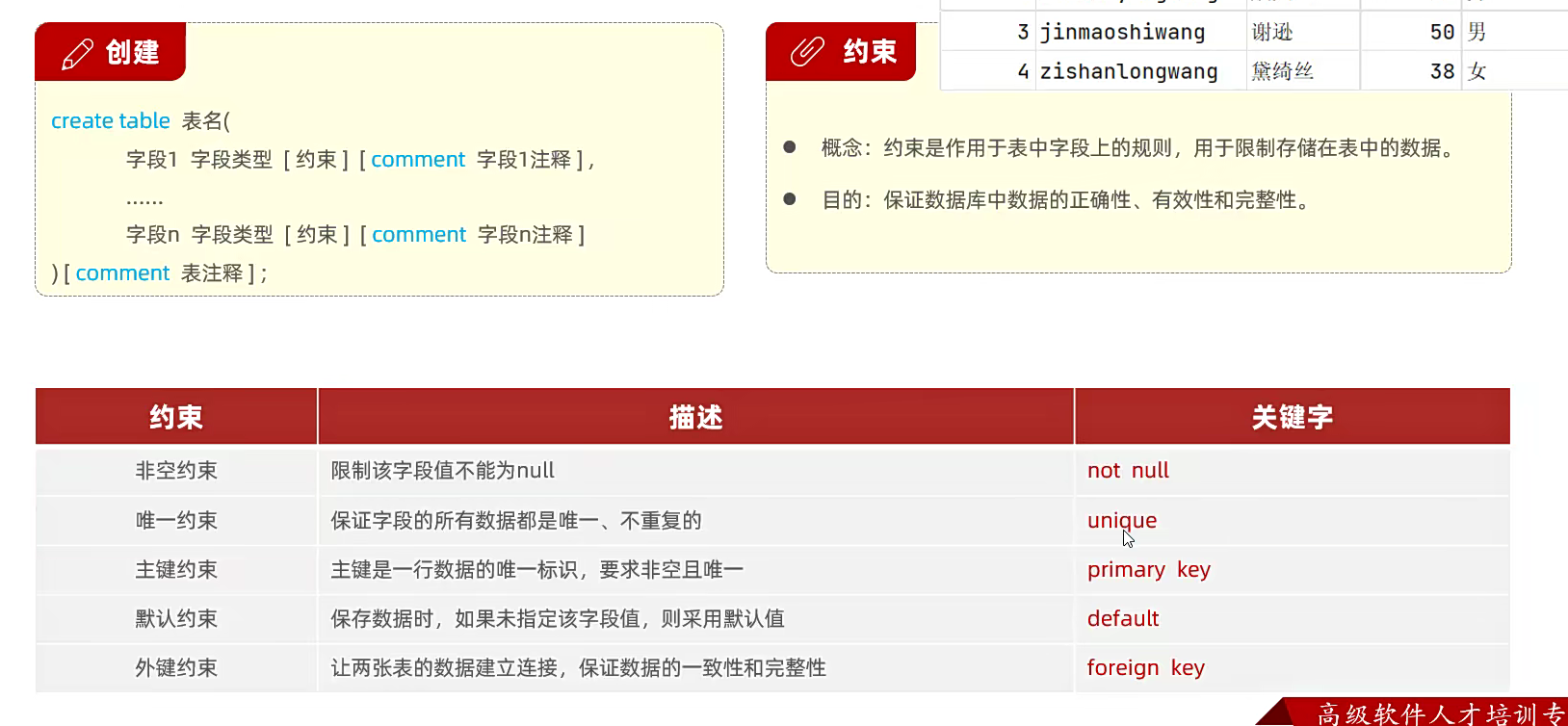
约束唯一性
一看,我们给id就该给主键约束;
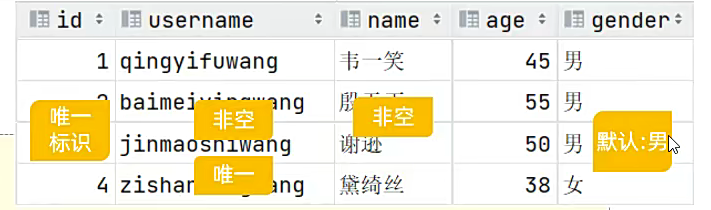
这是要求;

最终版本;auto_increment这个东西一加上;就是自动递增;自动增长;价格约束就可以了;
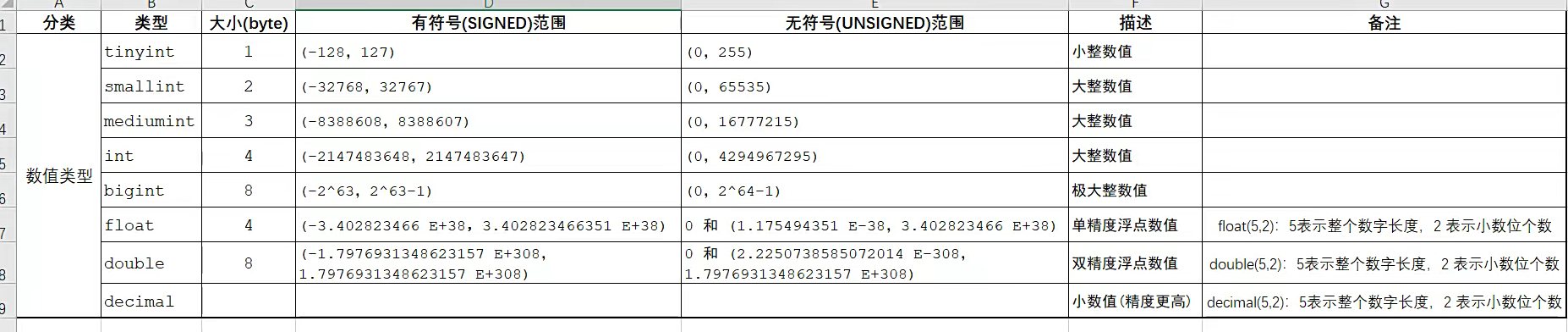
Mysql里面的数值类型
现在MySql中的数据类型有很多
MySql 的类型主要分三类;数值类型、字符串类型、日期时间类型。
数值类型
字符串类型
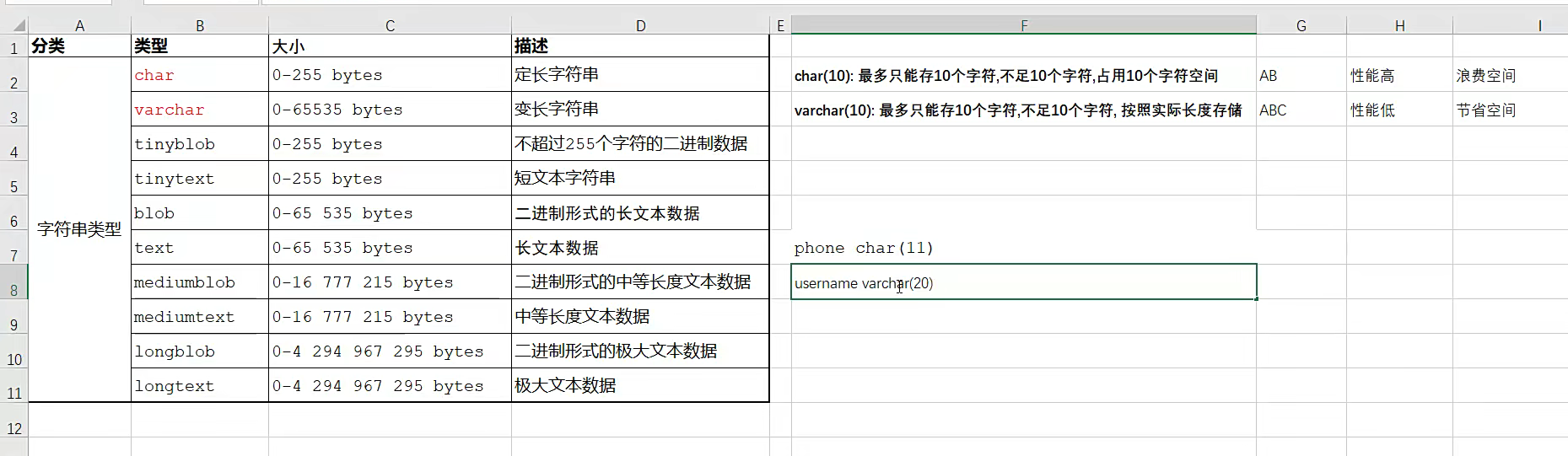
对于char 定长但是给多少就是10
varchar不定长,按自己所以看需求;
日期类型
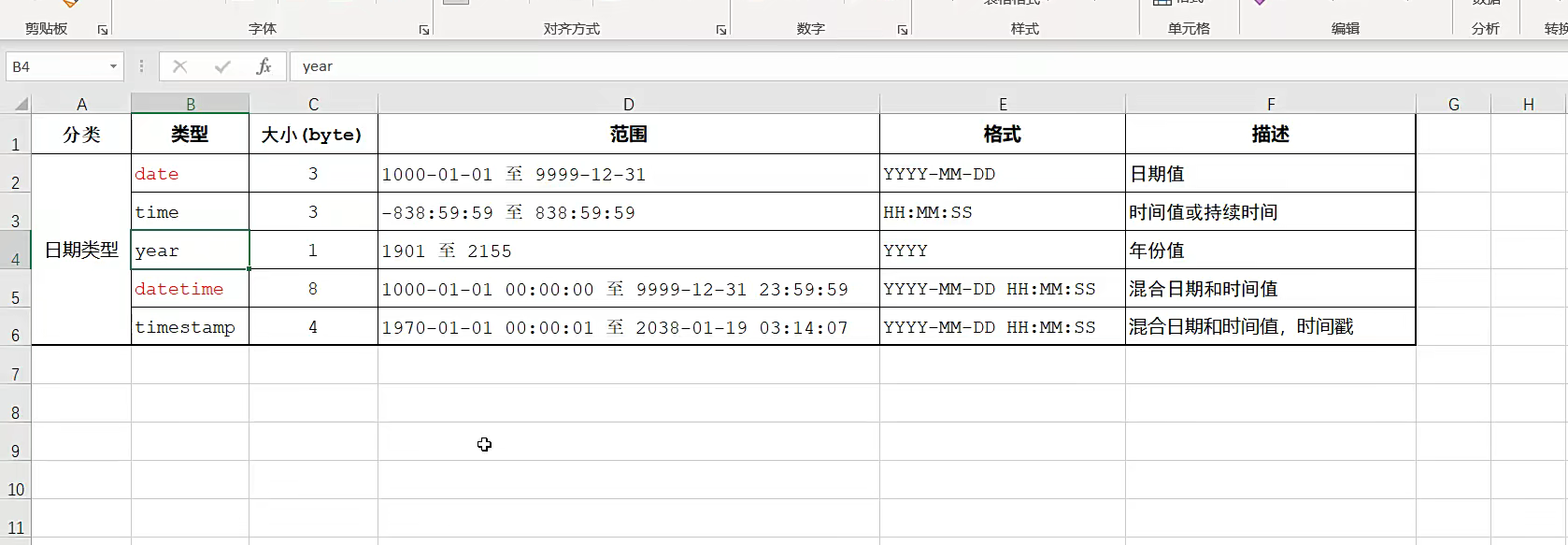
注意我们的格式类型是 id int 后面再写数据类型的这种;
比如日期类型吧;我们是birthday date
date是年月日,datatime是时分秒;
实际开发会给一个需求表
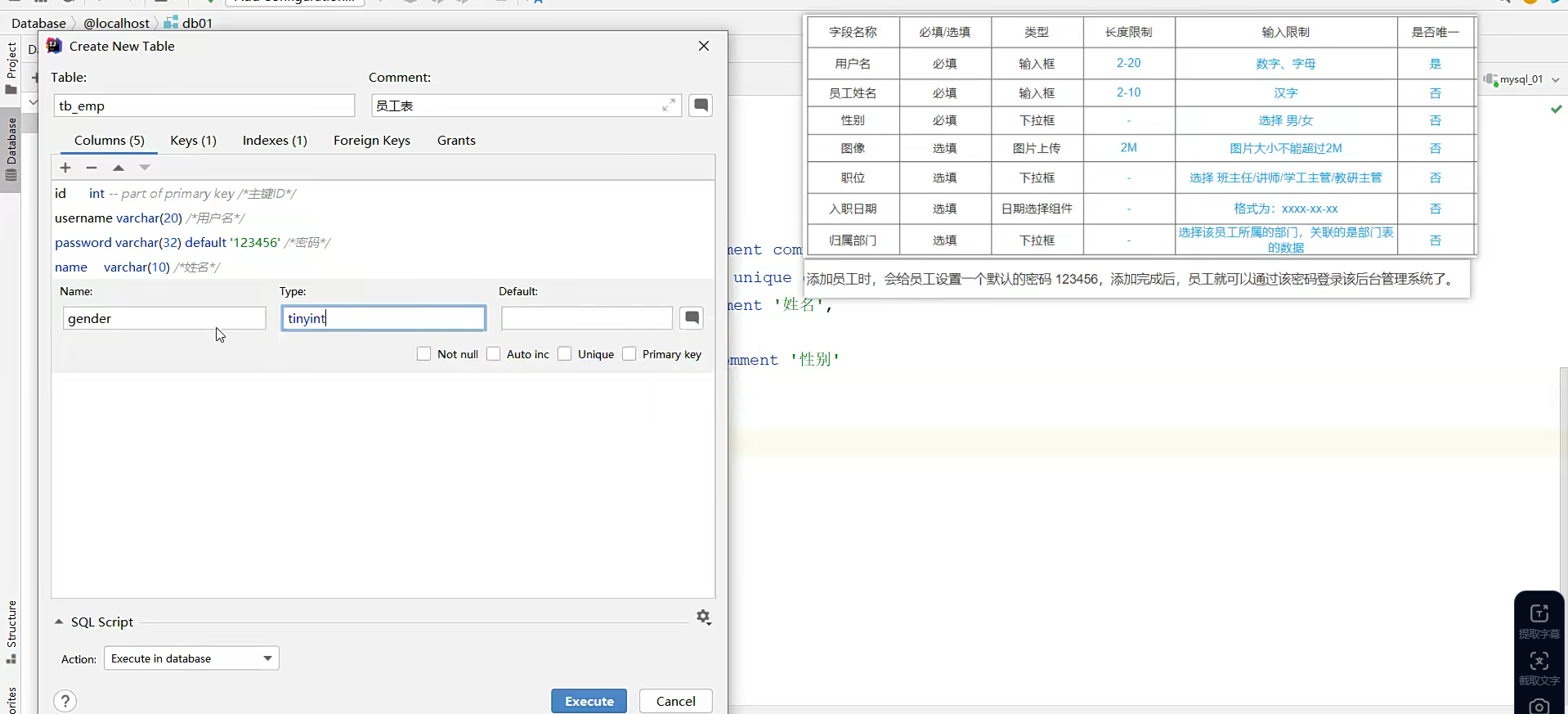
给一个需求文档之后呢;
我们先选用最小的类型;然后存1,2之类的;存好之后以后去服务层重写方法改就完了;
然后根据需求一个个分析,这个表就建立好了;
1.DDL 表操作
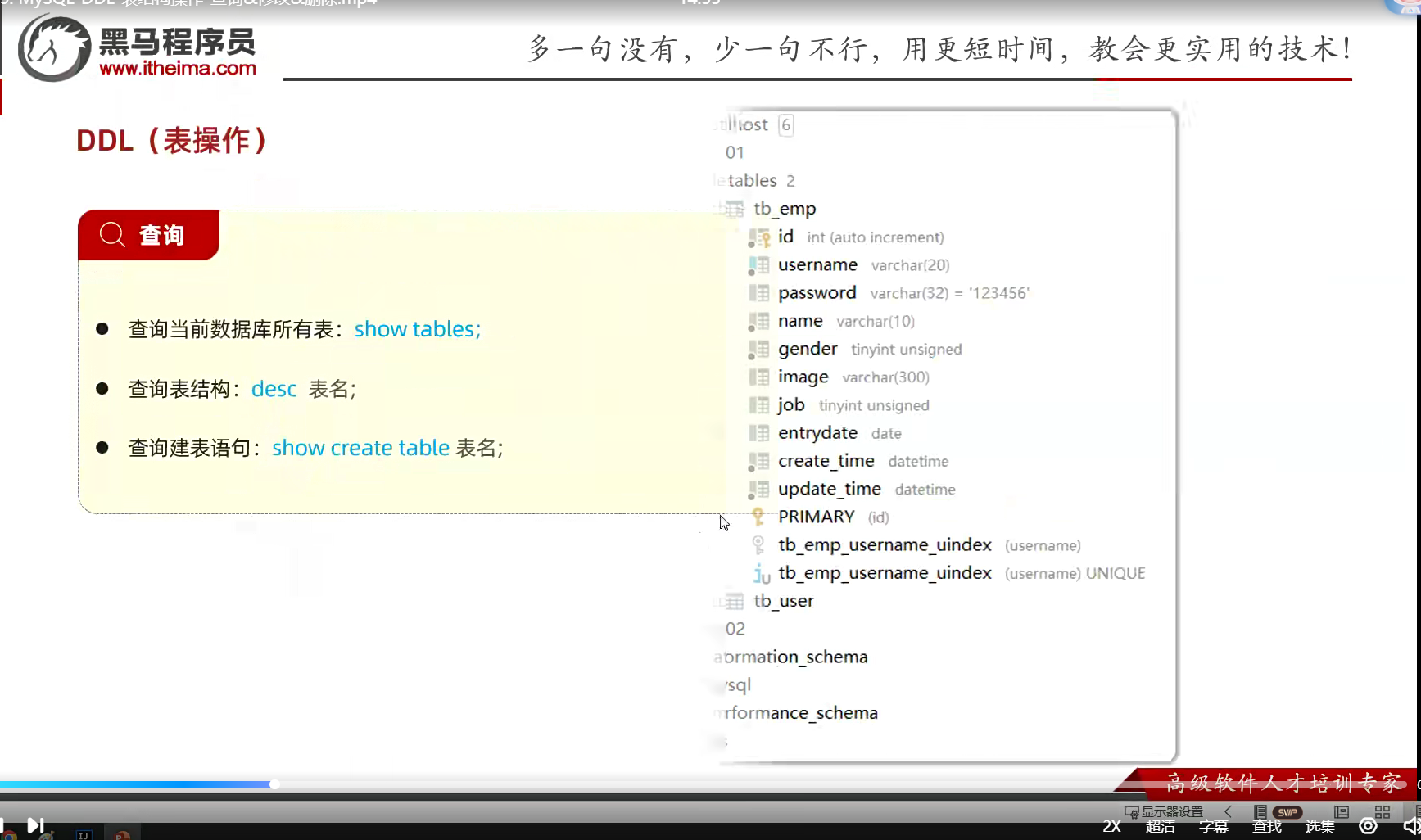
这些语句吧,很多东西一目了然;就是英语;上面这个纯查询

改变;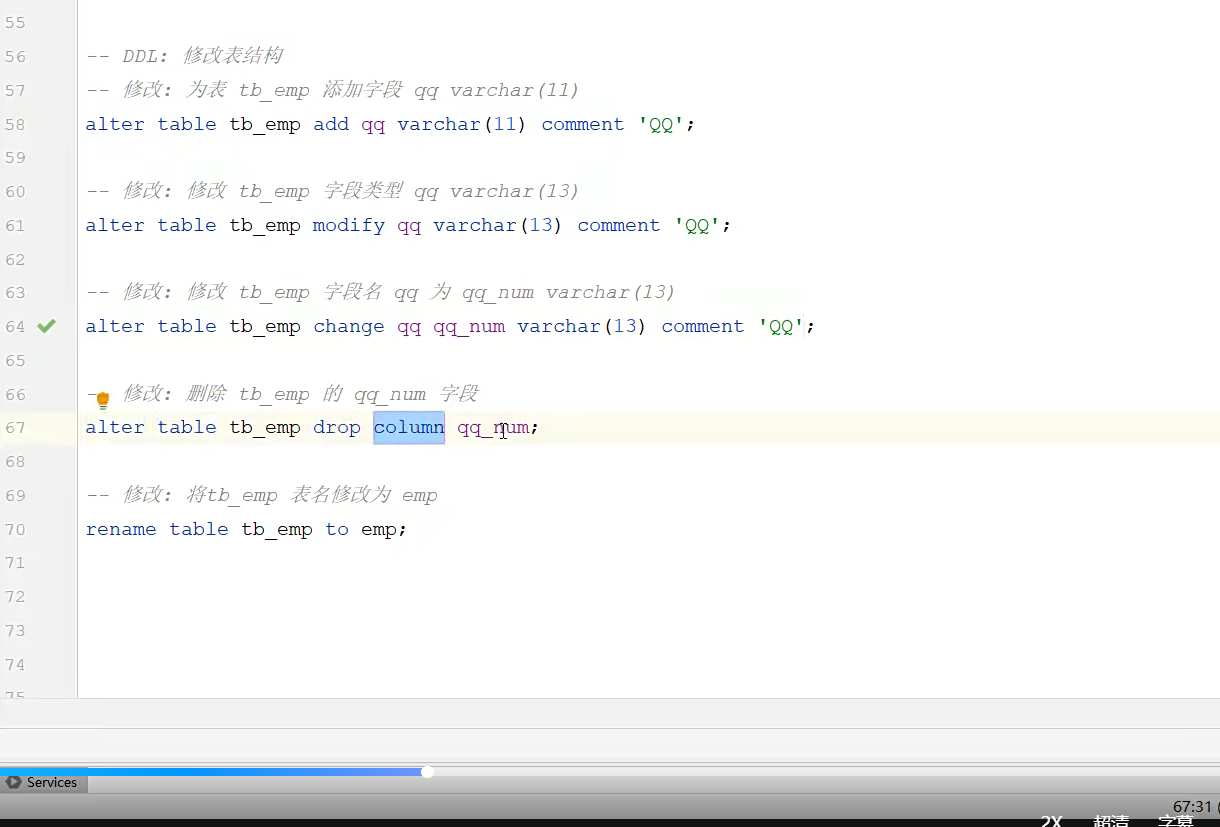
一一执行则可,不会的语句ai就行;
这些所有用可视化工具就完了;

只有创建最重要,学可视化就行了;
2.DML 增删改
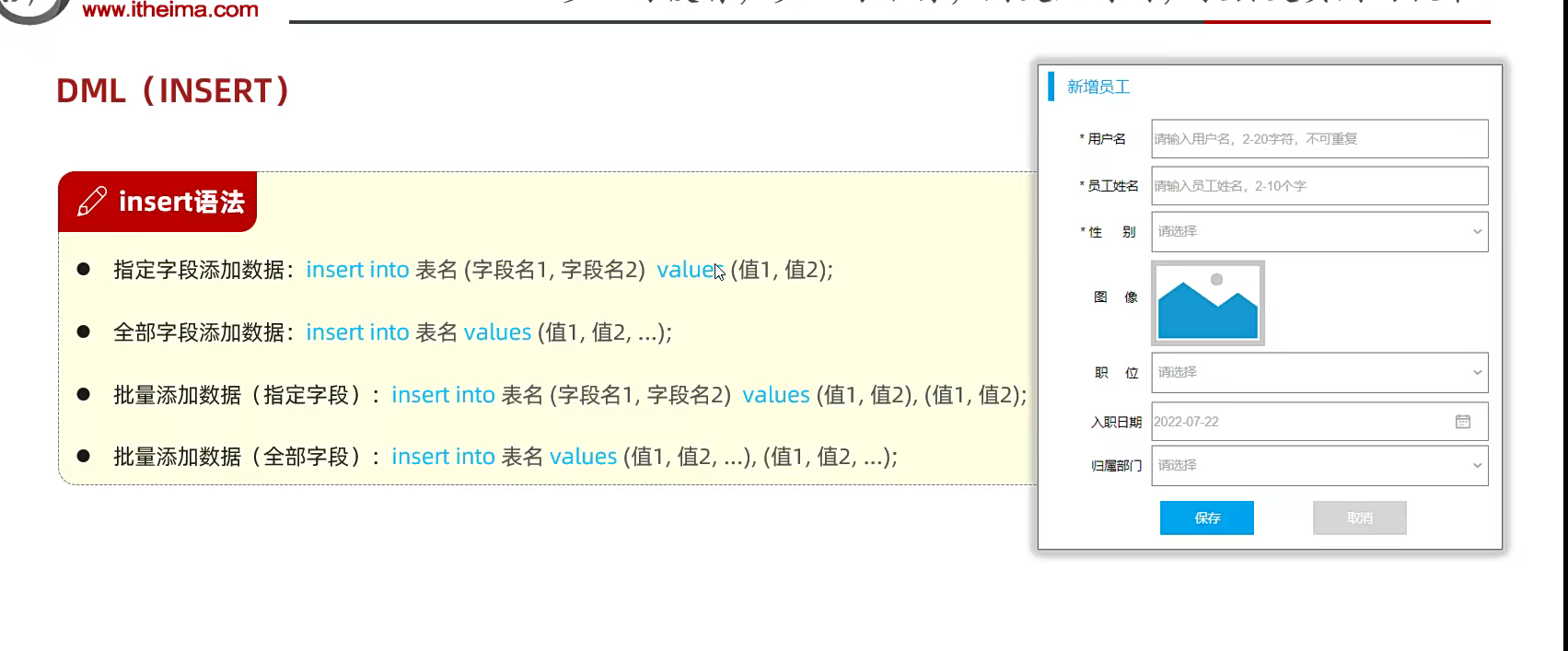
就是给表加字段;我觉得sql语句都不用学了,现在的东西有很多;
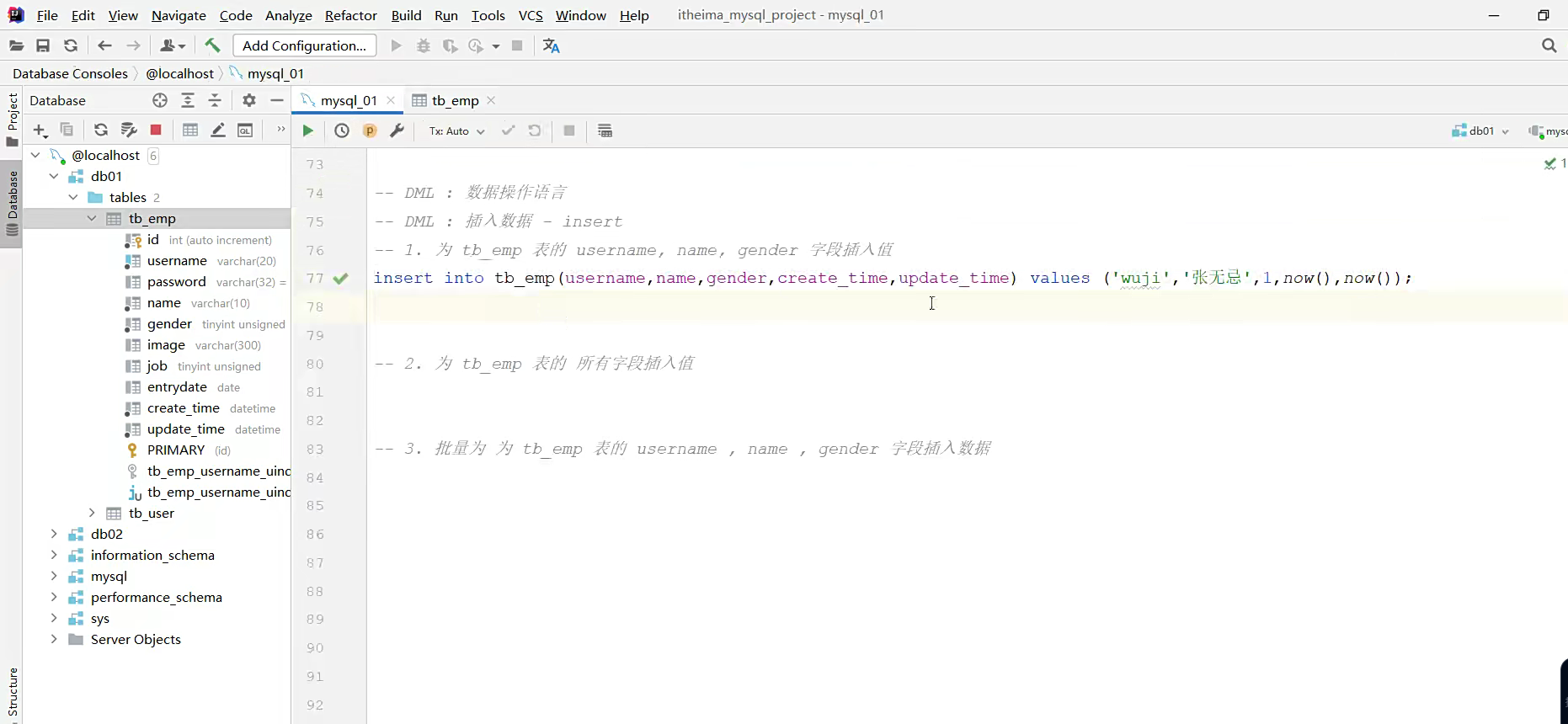
这句话给表插入数据;
1给字段,2给值,然后非空的字段,要去给值
前面是所有的字段,后面给个value里面都是值
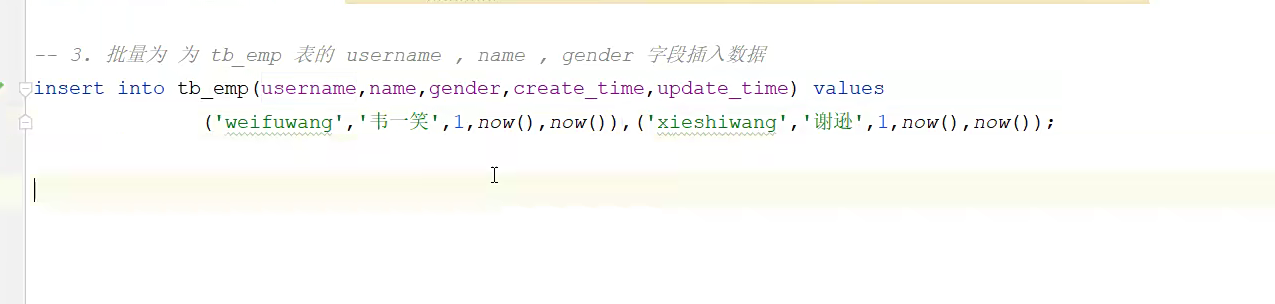
批量插入;这个插入值进去,前面是字段,后面的值就直接分成两个括号,在括号里面写就行;一次性建立了两条数据;
给表更新,这是更新经常用到的场景;
比如点击页面给展示了吗,然后给详情了;然后咱们点击好修改好提交表单了;然后那里面的数值肯定会修改的;
看update的场景

他调用的now()这个东西就是当前时间;,然后更新字段
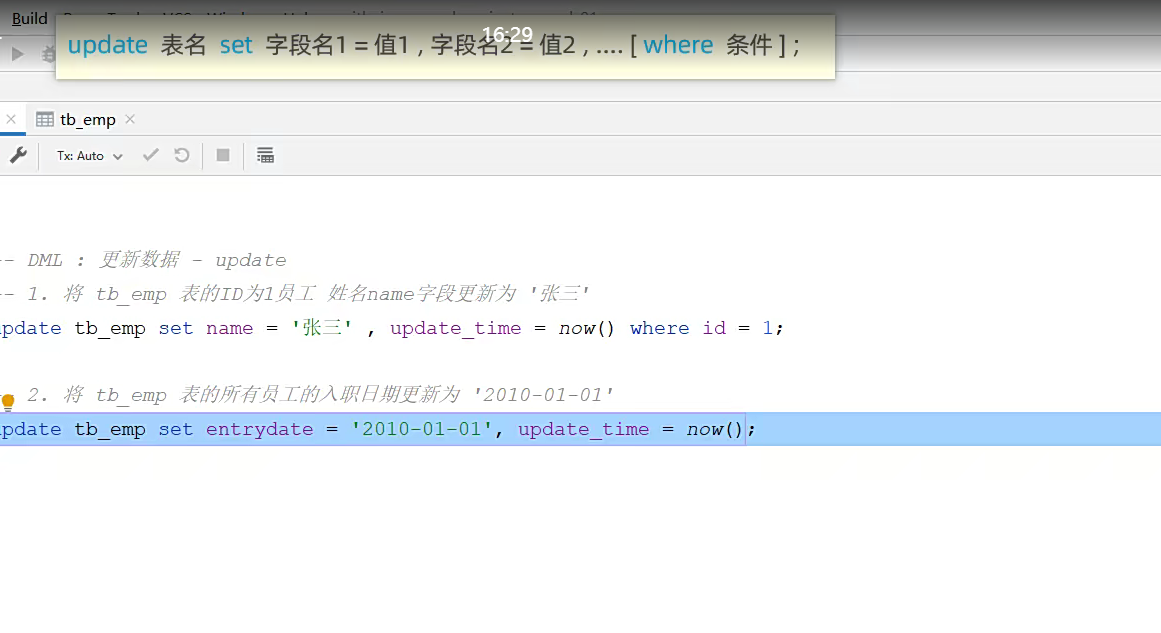
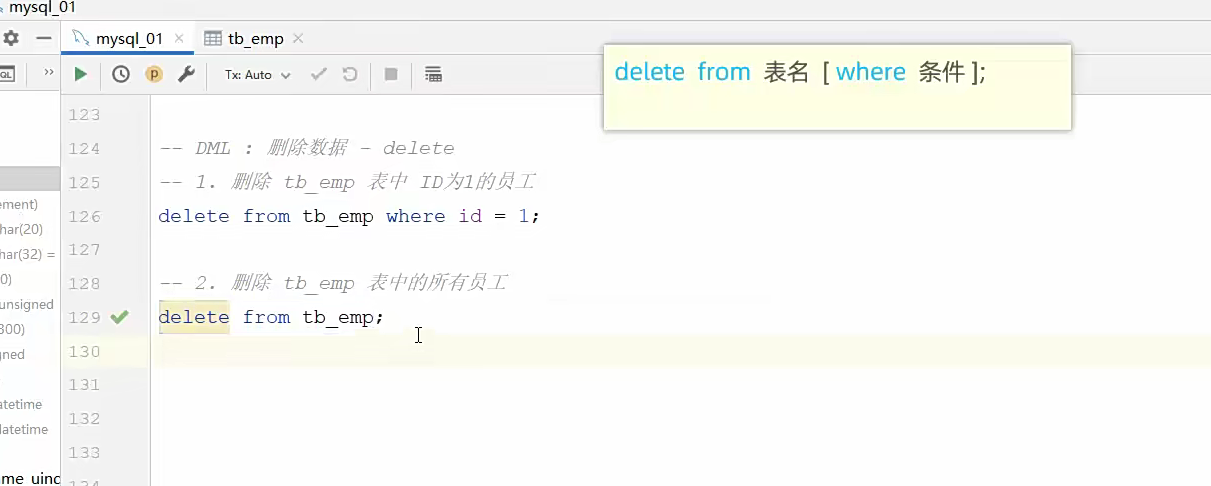
同理,删就完了;


3.DQL 查
最重要
能看到,都是因为查
基本上每点击一次就能有一次查询操作;而且还有条件查询
分页查询;还可以对查询的数据进行排序;
单表查询:
记住这张图,基本上就能写很多基本的查询语句了;

突然想到,本来java就是对着建需求表,建立类,然后咱们的表是对着需求文档建立,所以流程就是,
对着需求文档建立表,对着表建立类;
继续

基本查询需求

条件查询
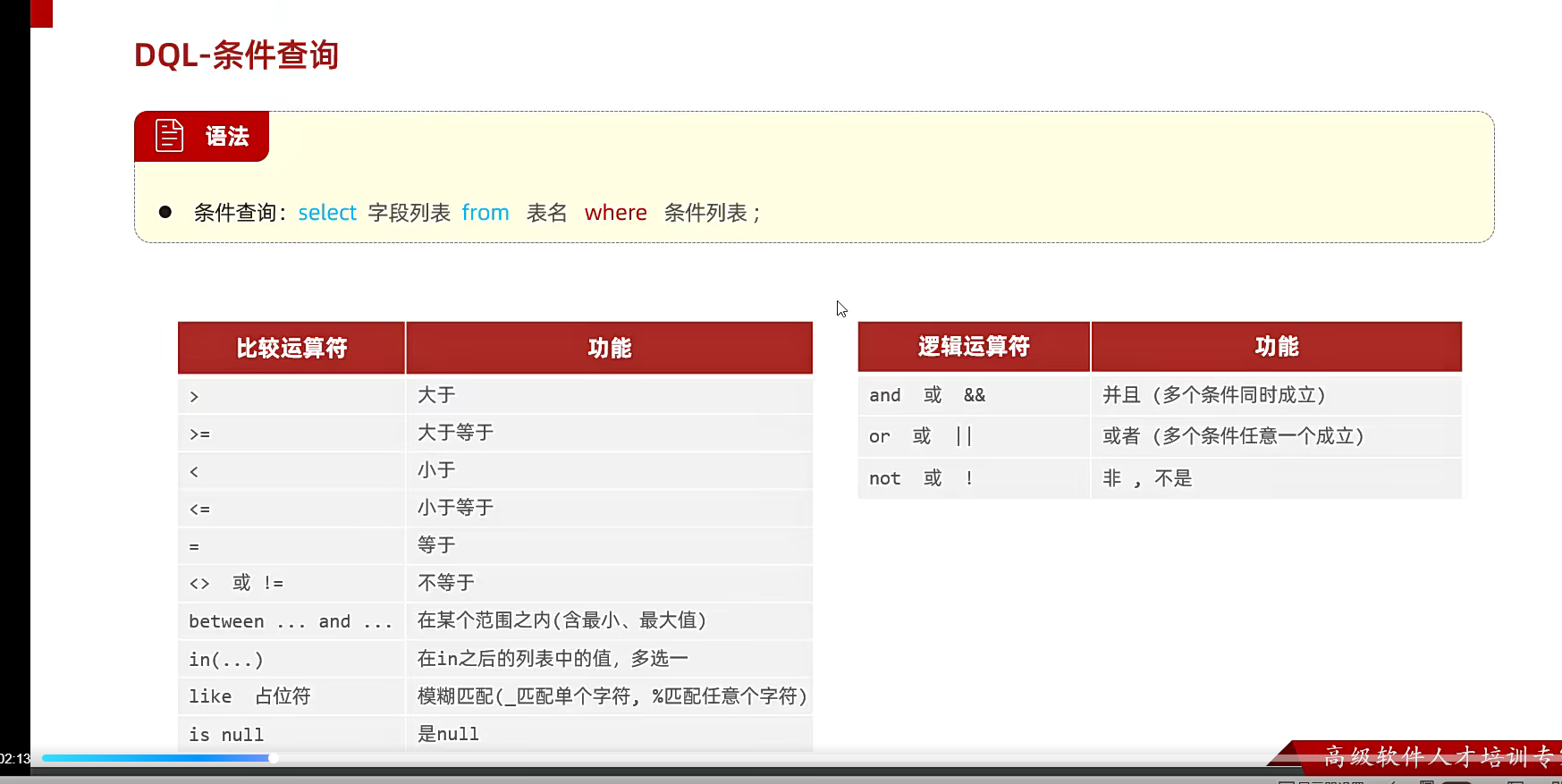
这里就是where的条件约束;比如查一整个表,name=''最好无论是什么符号,都带上引号;

类似这种;但是,null他不是;他必须用is;多个条件就用and
如果确定查谁了,直接等于就行;不确定的话,可以用到模糊查询;
比如要查所有是两个字的员工;
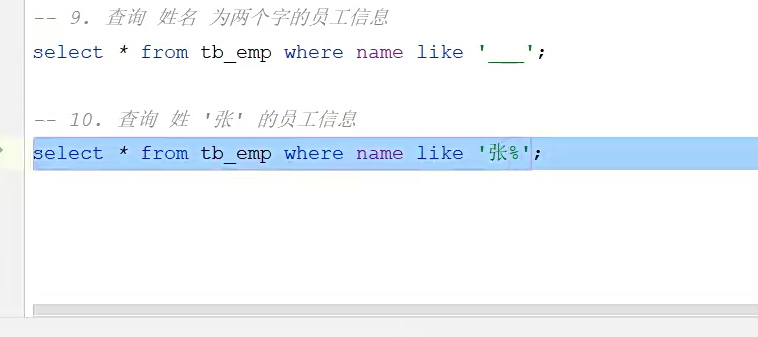
下划线是单个;百分号是多个
分组查询

就是可以统计计算;
聚合函数;
count是不对null值进行计算的;
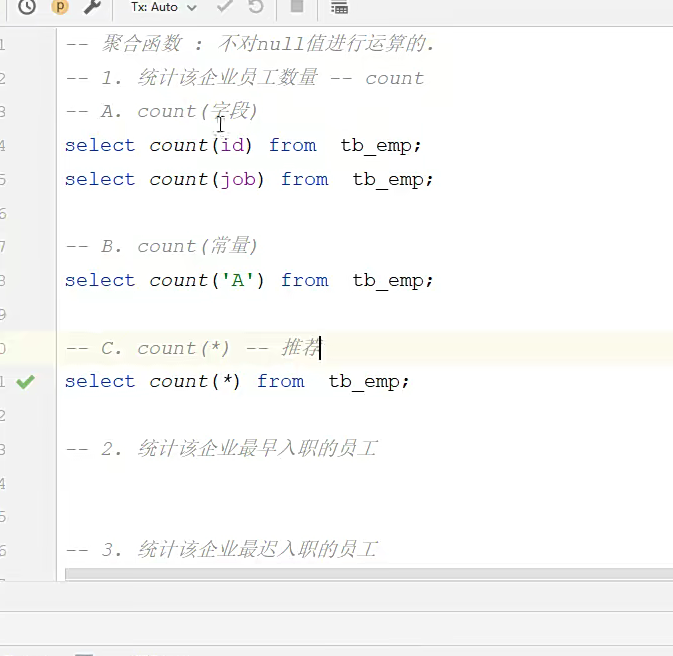

这些都是聚合函数; 比如统计数量啊,最大最小值啊
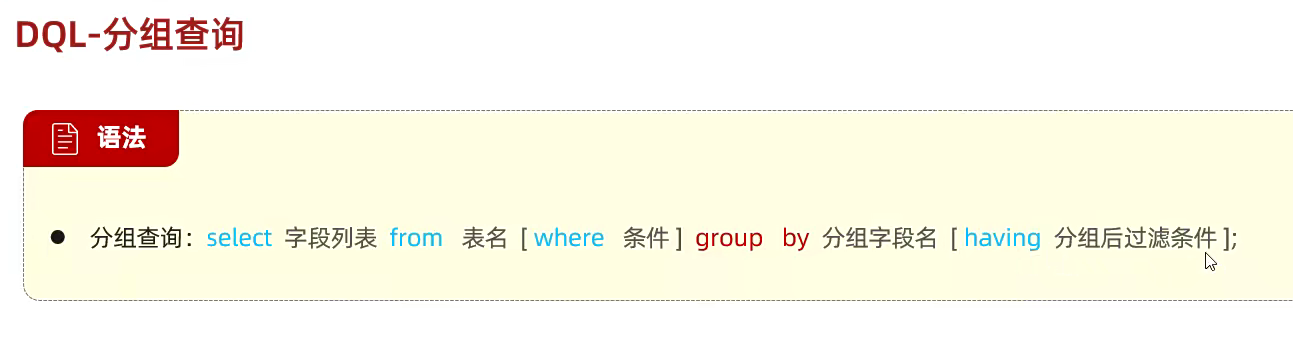

from还是表名哈;然后跟着的是按照什么分组;再一个就是跟的是按照什么分组,咱们跟的是一个gender;格式就是group by gender
然后前面要写分段;第一个是gender 第二个是统计;count();
聚合函数他必须用再前面,where是跟在from后面的,要什么条件直接and加就完了;然后分组语句写好,但是如果还有聚合函数的语法的话,再加个having;然后再用再判断;里面的就是统计数量的;having就是专门写在分组之后的东西;

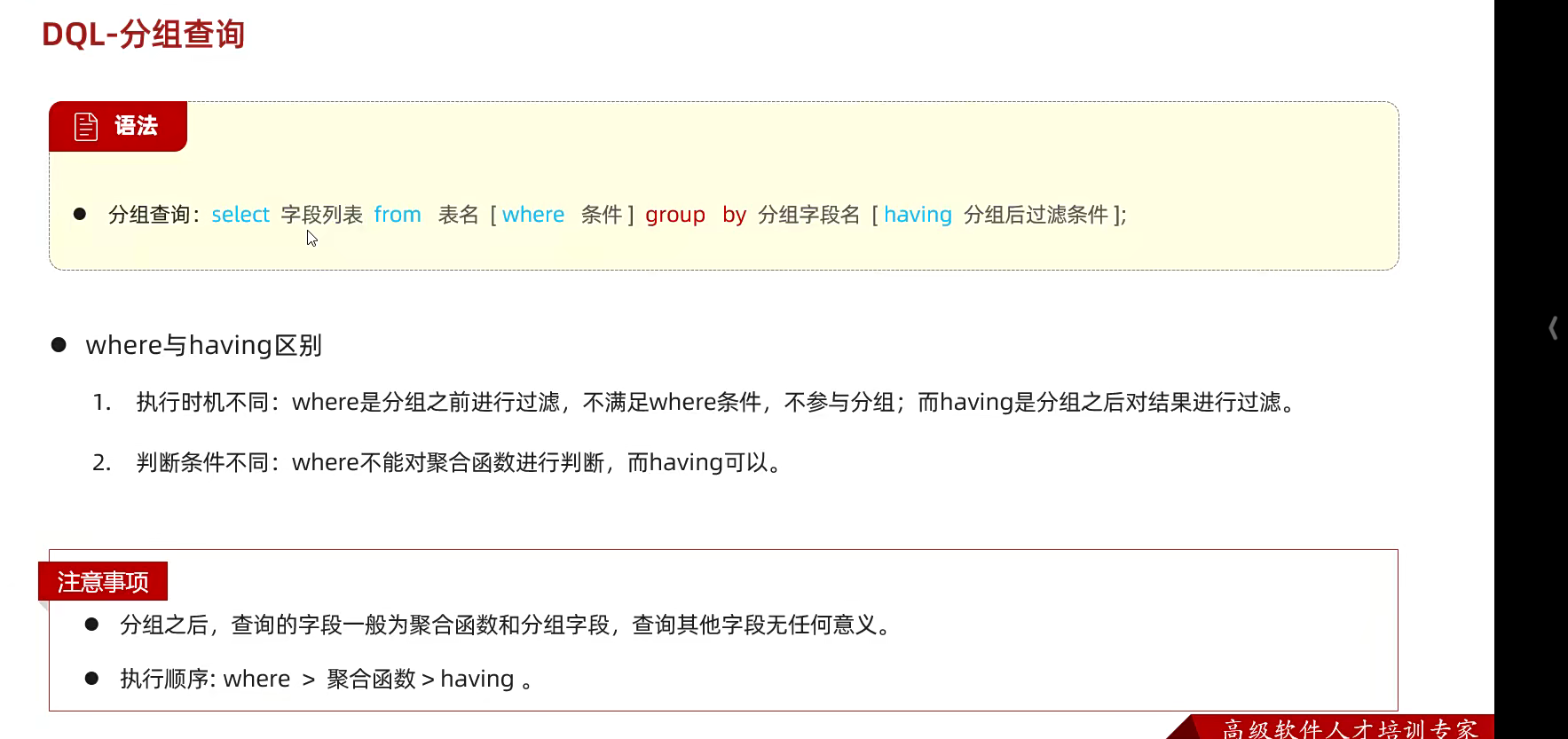
排序查询
也是一个字段加上就行了

分页查询

这个非常好理解了;直接在后面接个Limit然后给个范围就可以了;怎么说呢,这个范围吧;你要按id去算,后面是展示几条,比如第一页展示五条就是0,5;第二页展示五条,那之前的id是0,1,2,3,4 现在就该 5,6,7,8,9,所以开头的索引是从5开始的;后面再跟展示五条,第三页就是类推;从10开始一直往后;
**但是!**咱们不可能是说每个,咱们都去写吧,那不得算死;所以我们上公式;
就是查询的页码减1然后乘以每条消息的记录数;
案例
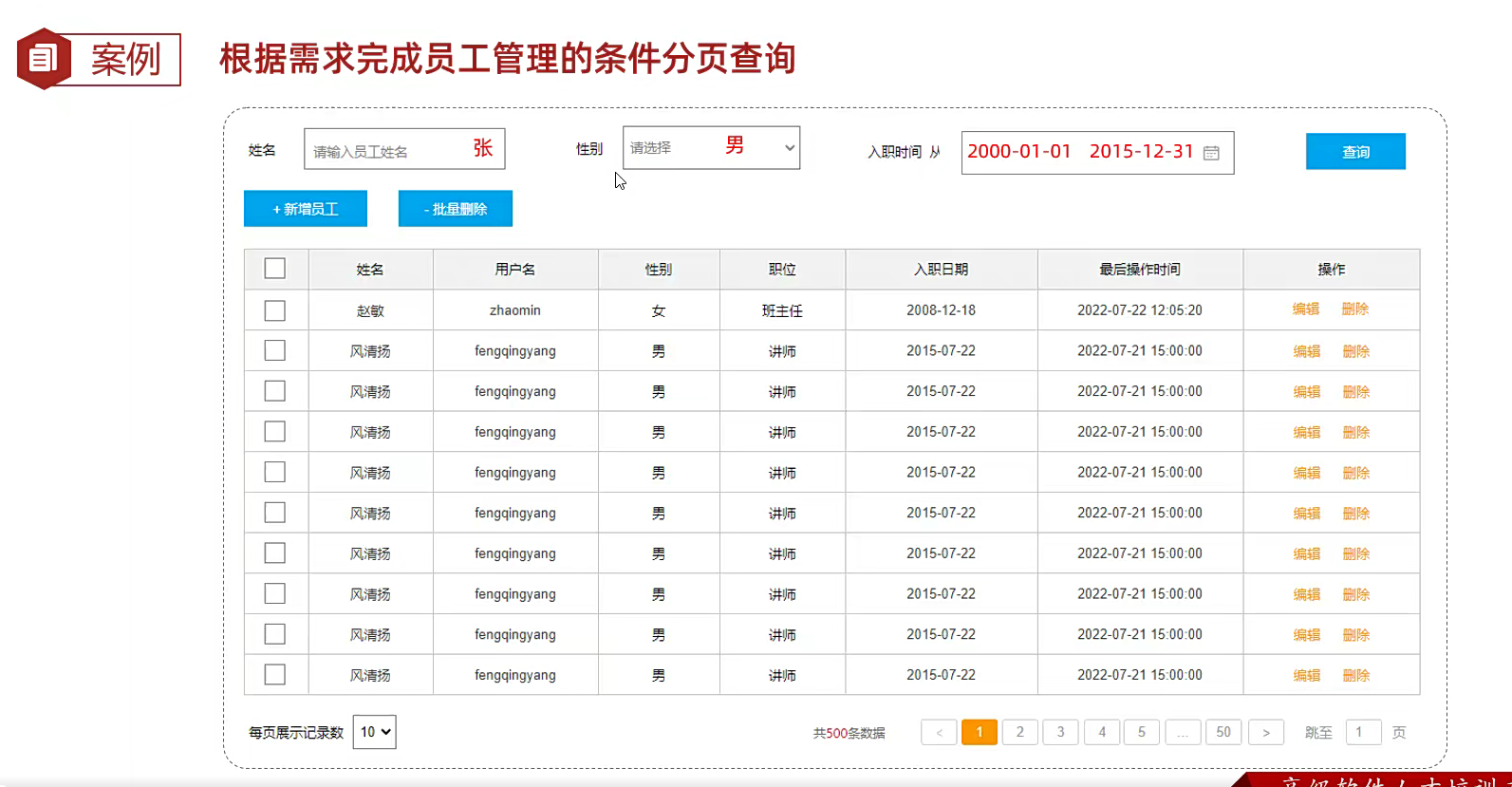
现在需求来了,我们看这个表,先分析吧;
就是普通的字段,名字用户名性别 职位 日期 之前和之后的日期,想起来是调now()然后一个按钮绑定点击事件进行增删改
然后最上面就是查询,监听用户输入的条件,后端是不是把这些条件转换成对应的sql语句;然后进行分页,每页十条的显示;
越学好像越清晰了一点;
那就是先建表,把这张图的表建立出来;然后开始分页,然后写好约束条件;先把增删改查弄了;
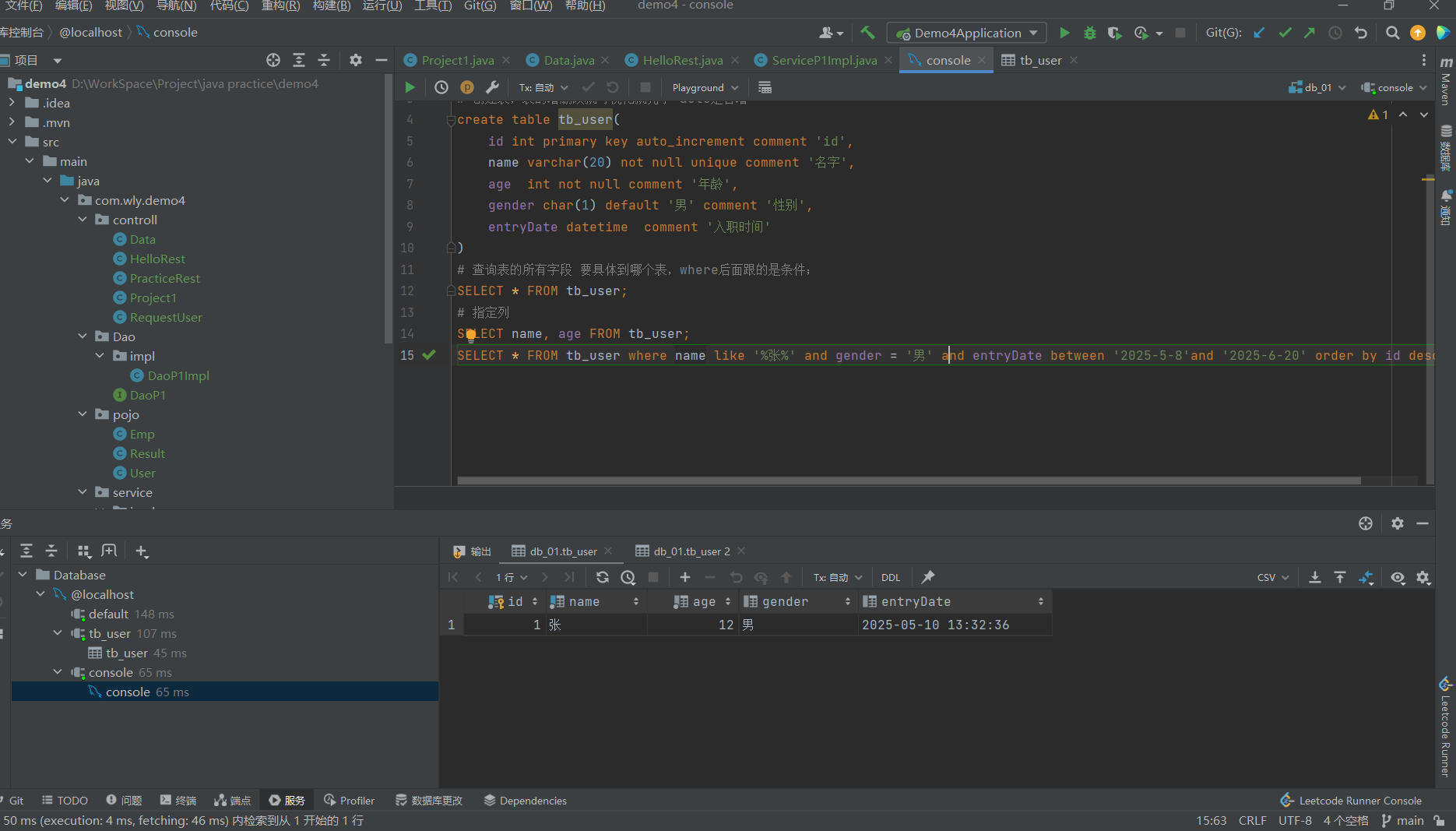
很多需求也是按照产品经理给的文档;

然后一段不是太长了吗,咱们就直接把他格式化一下
idea里面有快捷键;直接快捷键格式化就行了;
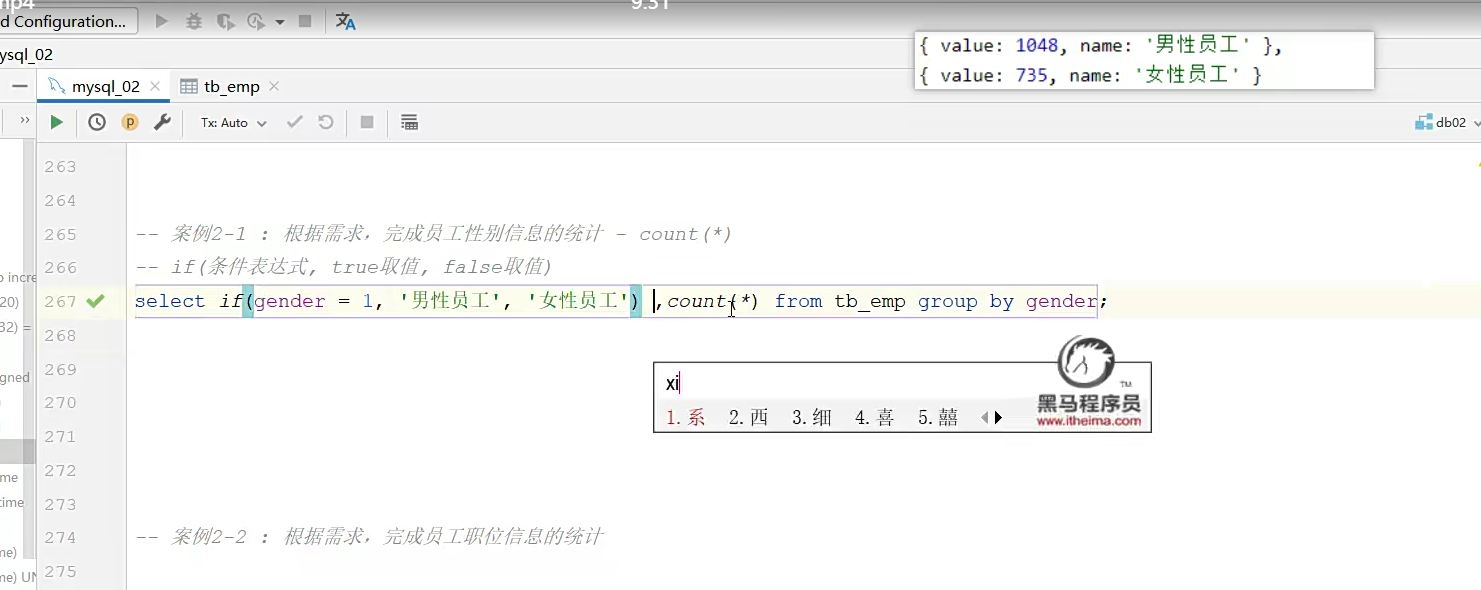
查询里面可以用if这种流程控制语句;比如看这个性别等于1,正确就是男性员工;不正确就是女性员工;
这个的作用主要是进行转换
还有一个转换词的流程语句 其实也就那两,一个是if 一个是switch里面的case

首先还是先选择出来;然后case后面跟着工作;意思是对工作进行简单的案例判断,用when开始开头,说案例,当等于1 的时候呢,然后是班主任
所以是 when 1 then ‘班主任’ 然后直接接就行了;这种流程条件要放在前面先筛选,不然,没筛就计数,就完蛋了;
然后就能把这个sql语句返回给前端,然后前端渲染出来就好了;
多学多练才能有出路!!!!!!!!!!没考上的东西继续考,大家都不看好你,偏偏你最争气,人多靠自己,我也想靠自己赚很多,不用我妈给生活费;靠自己去旅游,去买想要的,吃想吃的;现在实习工作了,才真正体会到什么是社会价值,什么是残酷,学校真的是大家最后最后的避风港了;呜呜再坚持一下;大家都不看好我一个没咋吃苦的女生走开发;我必走!先得尝尝咸淡吧! 今日开会人家的项目是清楚的分成vo bo 层的,就是数据库表映射进来,转换成语句,然后是类吗;这些类咱们不一定都要;比如点击这一面只弹出来年龄信息,别的不要,可能就是子表类似,我们可以再设计一个vo层去转换接收;还有一个bo层,他就是来接收指令的;现在sql的增删改查也有注解可以直接生成了;但是还是要理解底层逻辑!
今日开会人家的项目是清楚的分成vo bo 层的,就是数据库表映射进来,转换成语句,然后是类吗;这些类咱们不一定都要;比如点击这一面只弹出来年龄信息,别的不要,可能就是子表类似,我们可以再设计一个vo层去转换接收;还有一个bo层,他就是来接收指令的;现在sql的增删改查也有注解可以直接生成了;但是还是要理解底层逻辑!
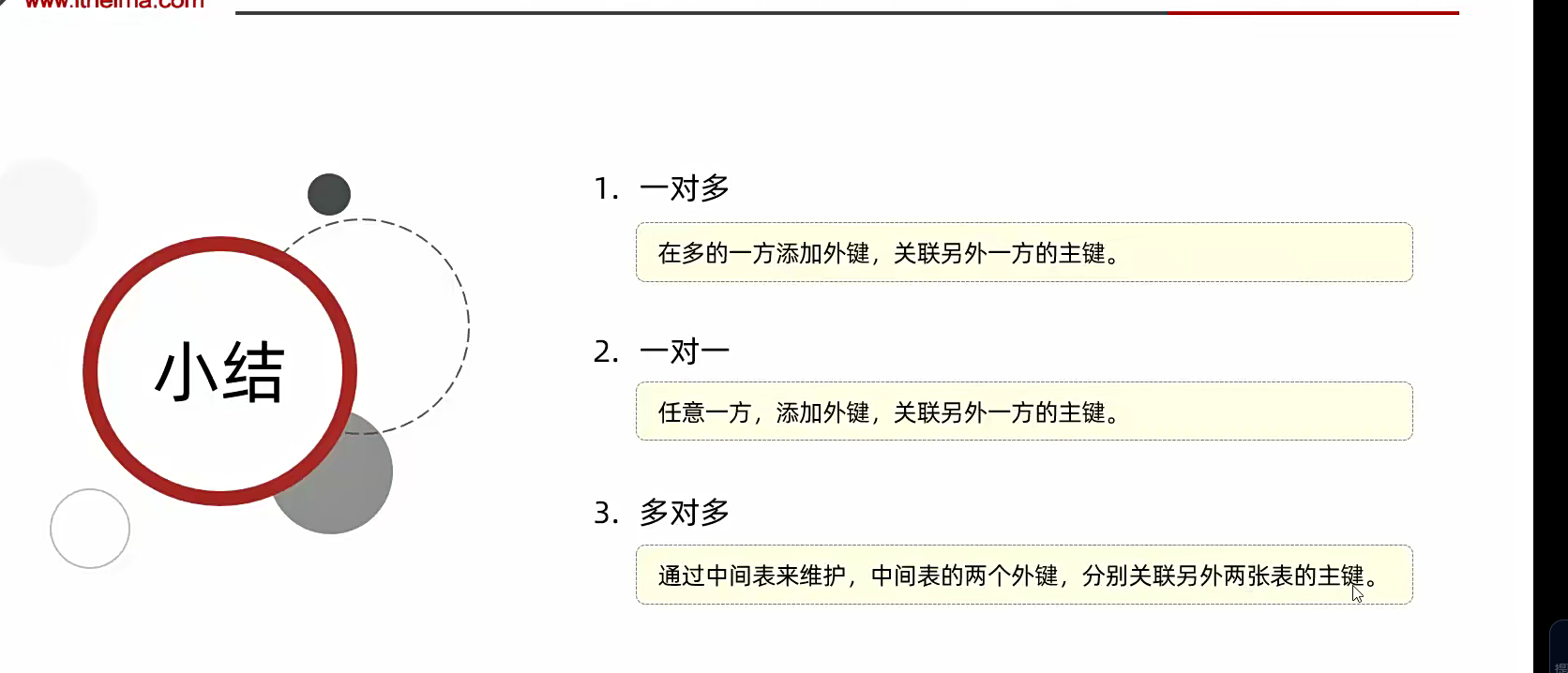
多表设计

表与表之间的关系互相是,有这三种;1是一对多的或者多对一,一张表可以联系多个;
2.是多对多的;具体情况具体描述
3.是一对一的,我只与他有关;

先按照需求来;
比如现在是crm系统,做员工和部门的关系,肯定是这个员工隶属于哪个部门吗,一对多体现在,一个部门多个员工;
一是部门那边,多是员工那边;
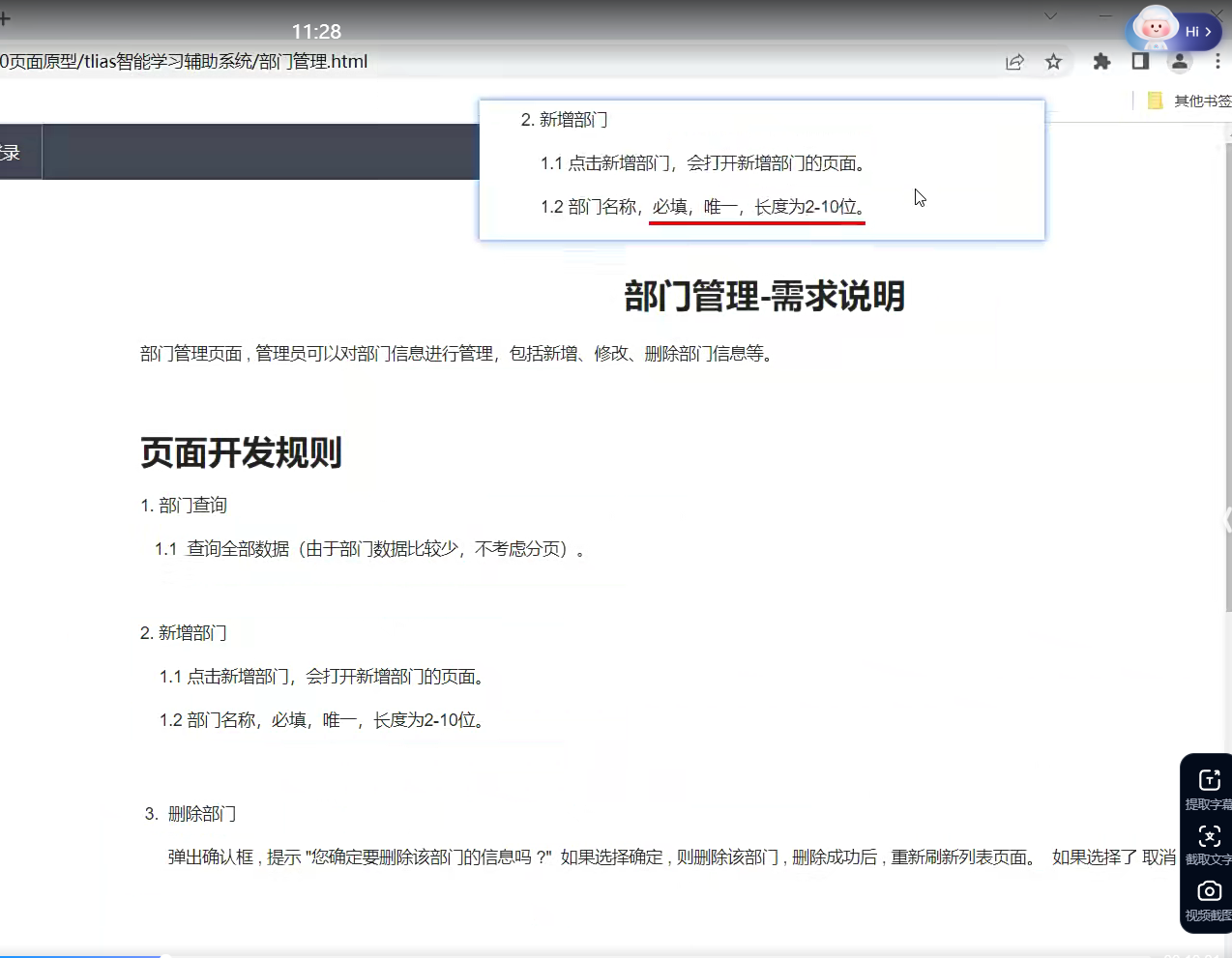
看这种需求说明;
比如部门管理页面;
先看需求说明;说的是数据少不做分页,也就是不写Limit;
页面开发规则;新增的时候弹出新增的页面;,然后只填入部门名称;
然后还有删除的功能
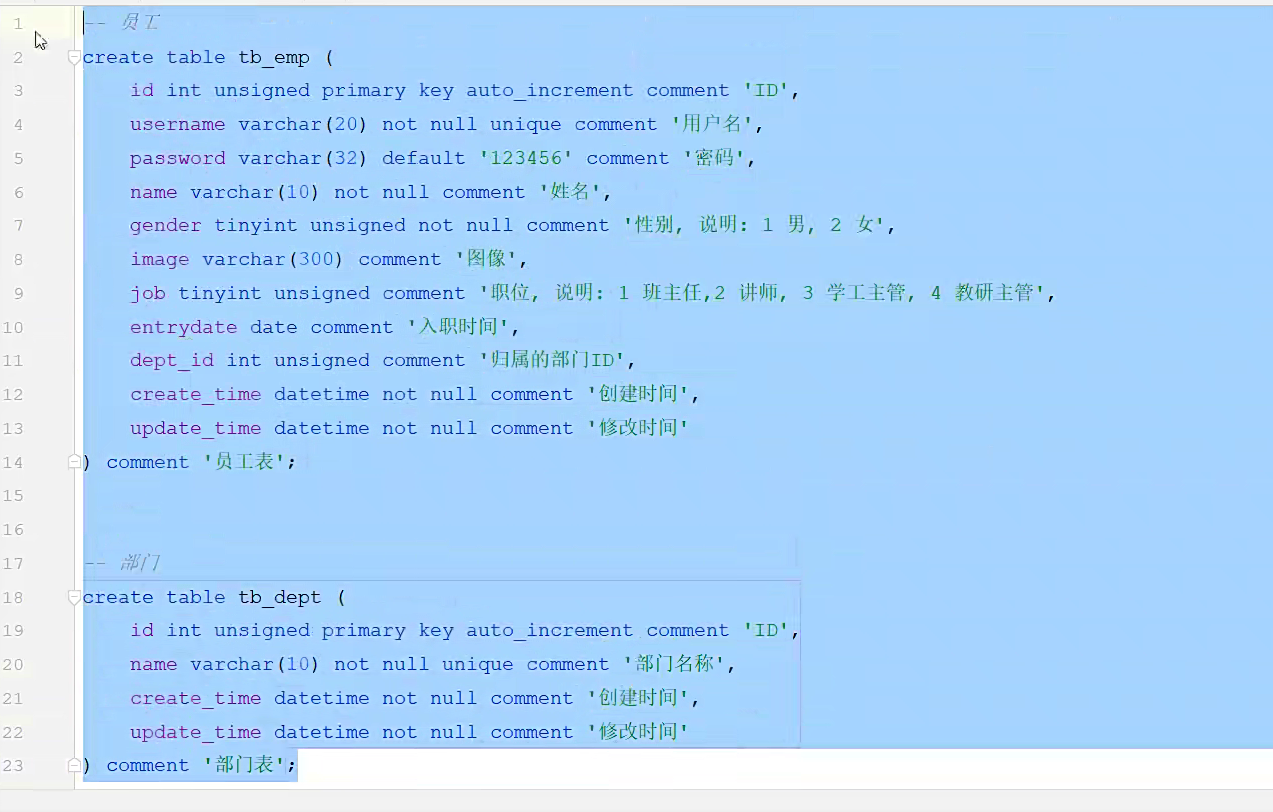
这是两张表;员工和部门表;要让他们联系起来,我们去员工表里面创建一个部门的属性;就是内个dept—id 然后把这个类型设置成一致;然后加上注释,这样两张表就关联起来了;
一对多
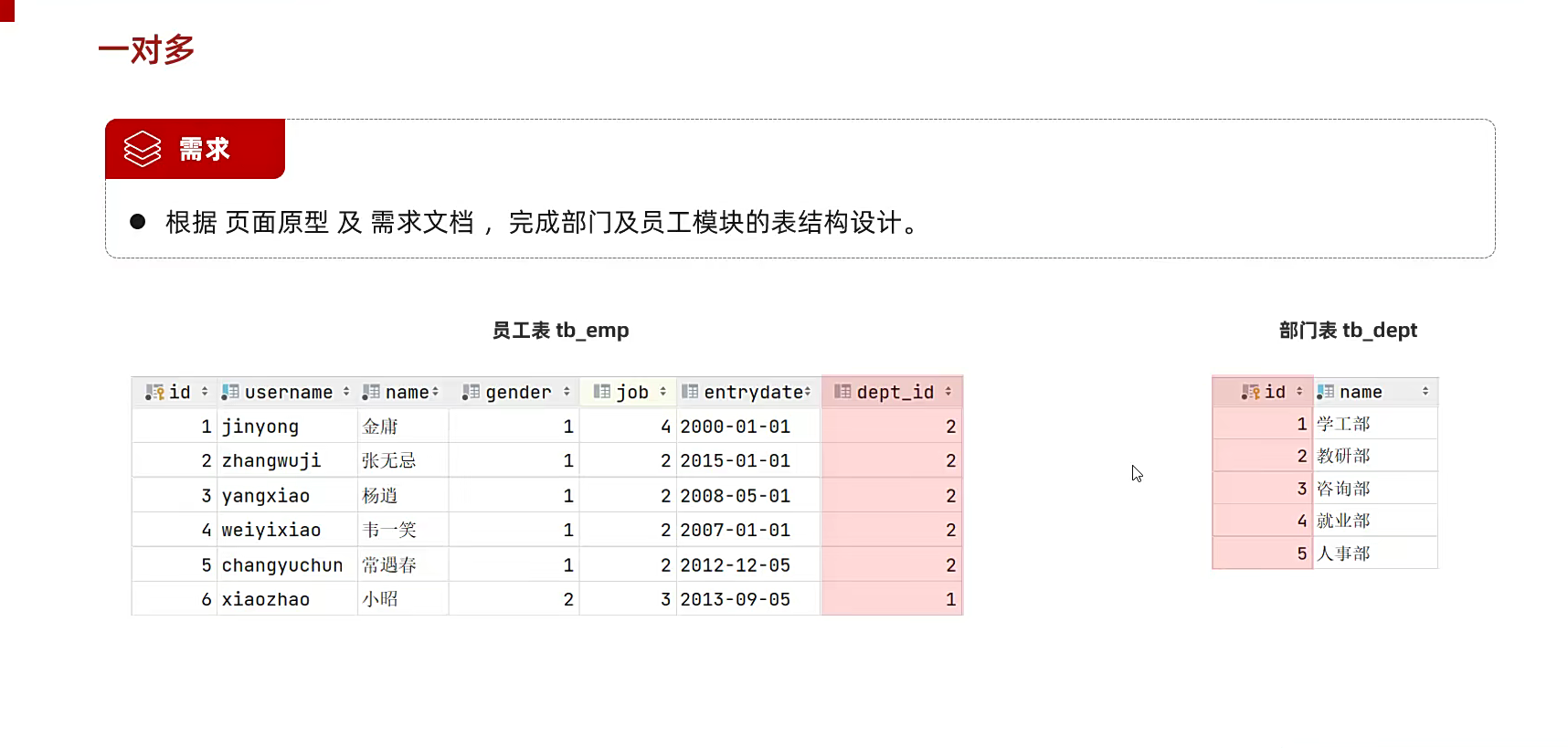
像这个,就用id联系到一起了;
也就是去多的地方,关联员工的主键
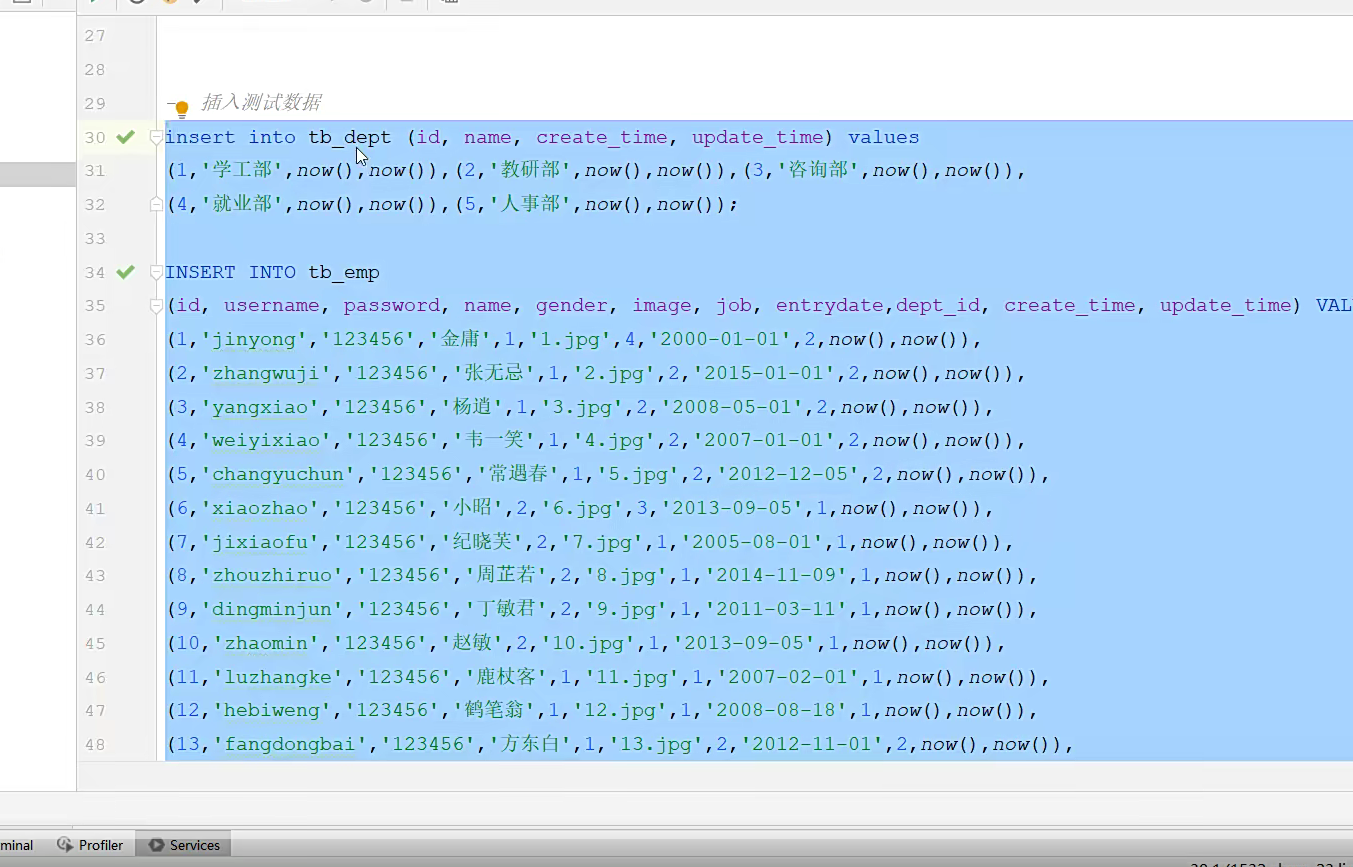
插入语句;
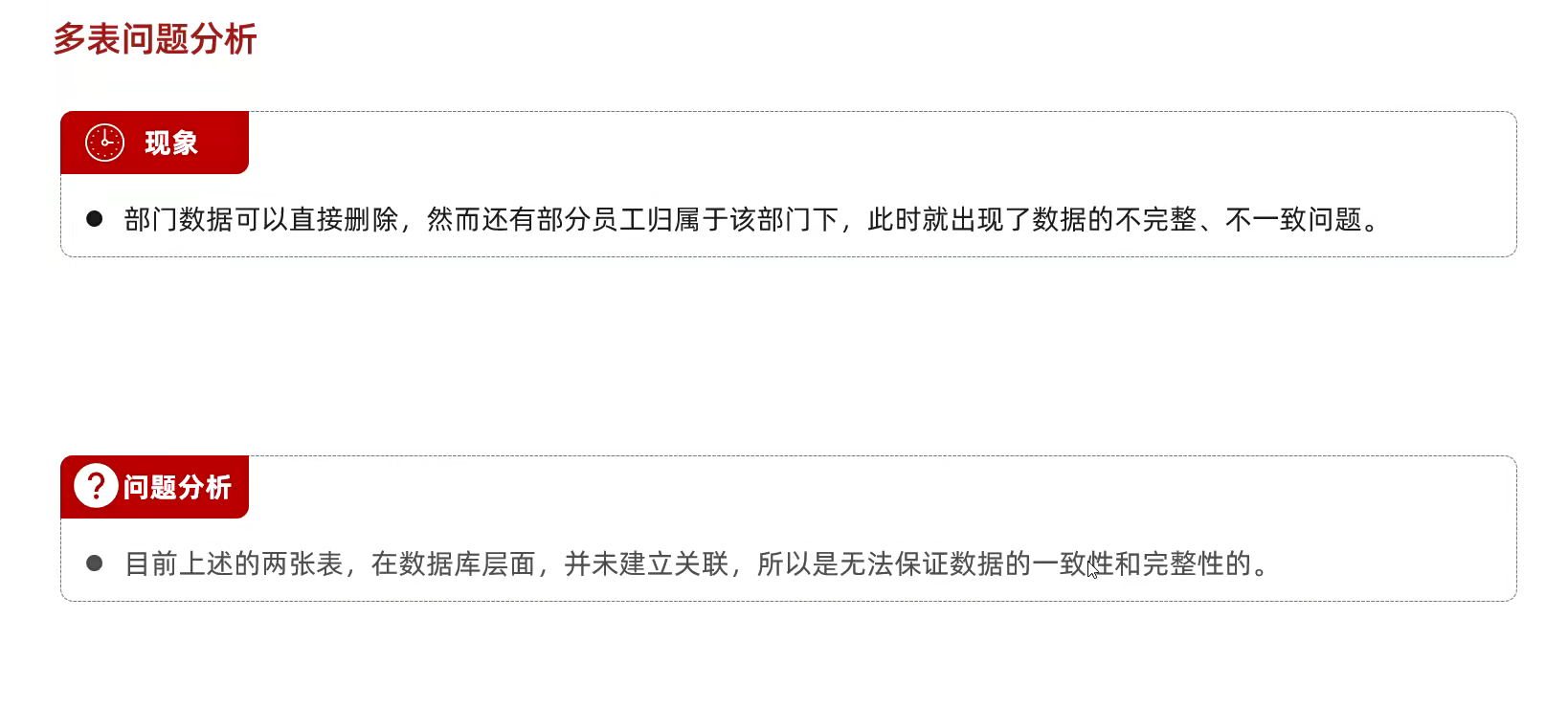
现象;就是比如多表里面吧;部门数据删除一个部门吧;但是另一个员工表里面;
用外键约束就能解决

这边声明外键,可以进行多表的联系
就是在字段外,进行一个constraint的名称声明;然后,进行一个外键的标注,比如你要联系另一个表的id吧还是什么,就写到这里,然后关联一下主表;

物理外键和逻辑外键,逻辑外键就是只是解决外键的关联性;物理外键是使用这个关键字去定义外键关联一张表。
逻辑外键可以解决很多东西;比如可以表层把他删了,实际东西还在;
因为如果一旦物理绑定了
就不能随意删除某张表的东西了
所以用逻辑外键更好
可以把部门删了,员工也还在,重新分配就行了,而不是删都删不掉;
一对一
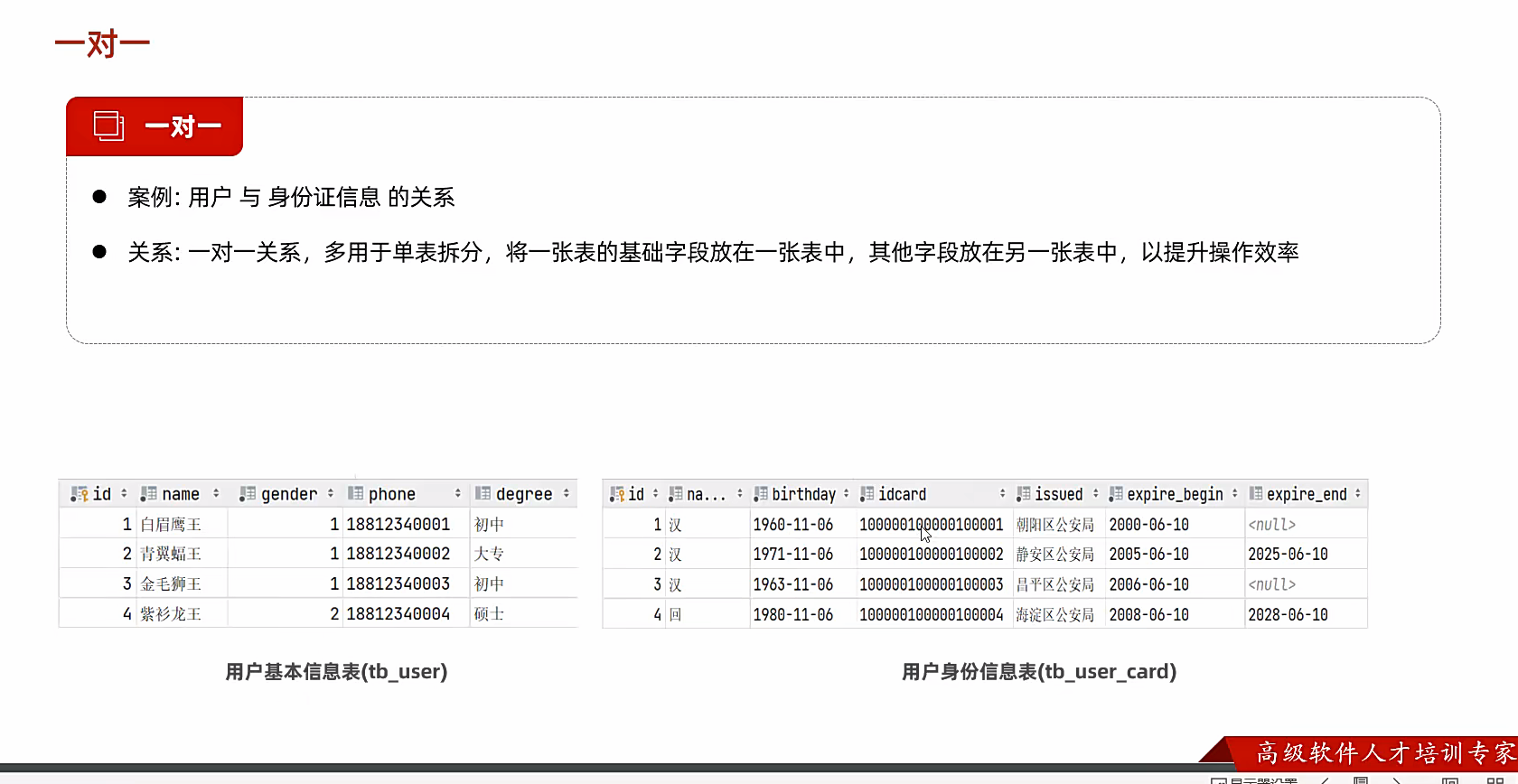
就是比如一个人只有一个身份证这种类型;
现在有个情况就是;有些信息的查询频率很高;有些真的很低,比如我们只要身份证,不看民族吧
那我们就可以对表进行拆分;这也是项目里面的;vo层干的事情;
对他们直接随意一张表加一个外键就行了,加一个Unique唯一就行
多对多
比如学生对老师

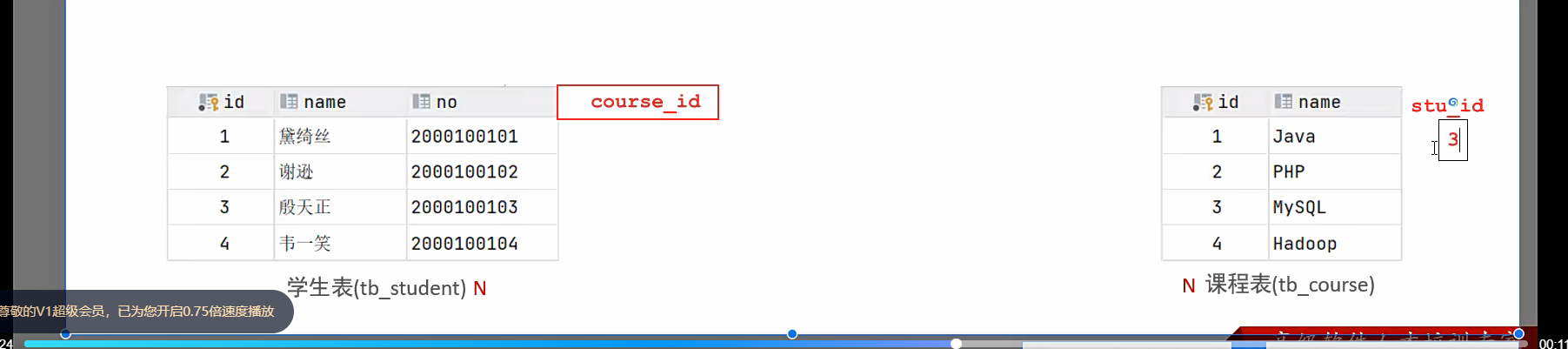
这时候用外键就不合适
给谁加都不知道怎么填,因为一个学生可以选多门课,一个课多个学生选;
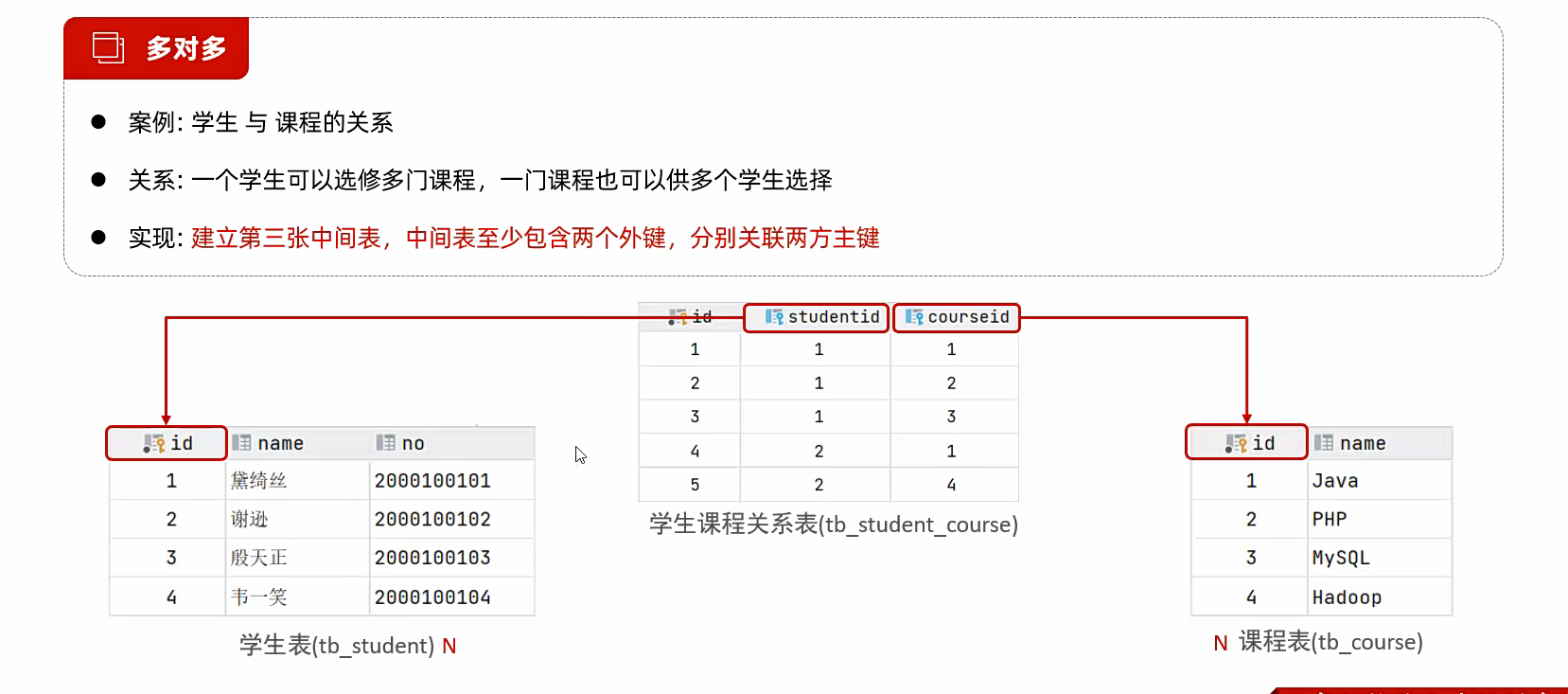
解决方案就是出现了第三章表
第三张表呢有两个外键,一个放学生一个放课程;一个放自己的东西;成功解决,比如图中1号学生对应了3门课
可视化
案例
先看好三个模块,然后对此进行分析

先看关系
比如,分类模块和菜品模块吧;
一个分类应该有多个菜品;分类是1,菜品是多
比如一个荤菜分类底下,应该有多个荤菜,什么红烧肉啥的等等等等;
套餐呢,他一个套餐有多个菜,这里两个对应菜品我认为应该都是一对多;套餐是1,菜品是多
然后就是分类与套餐的关系了;一个分类比如一个荤菜分类,可能会有多个荤菜套餐啥的,套餐肯定不能混吗,应该是一对多,一个分类,多个套餐
按之前设计的原则;应该是在多的一方增加外键,进行一个关联;
现在还有一个就是套餐和菜品,这两个是多对多的关系;所以需要再添加一张表,关联他们两个的字段
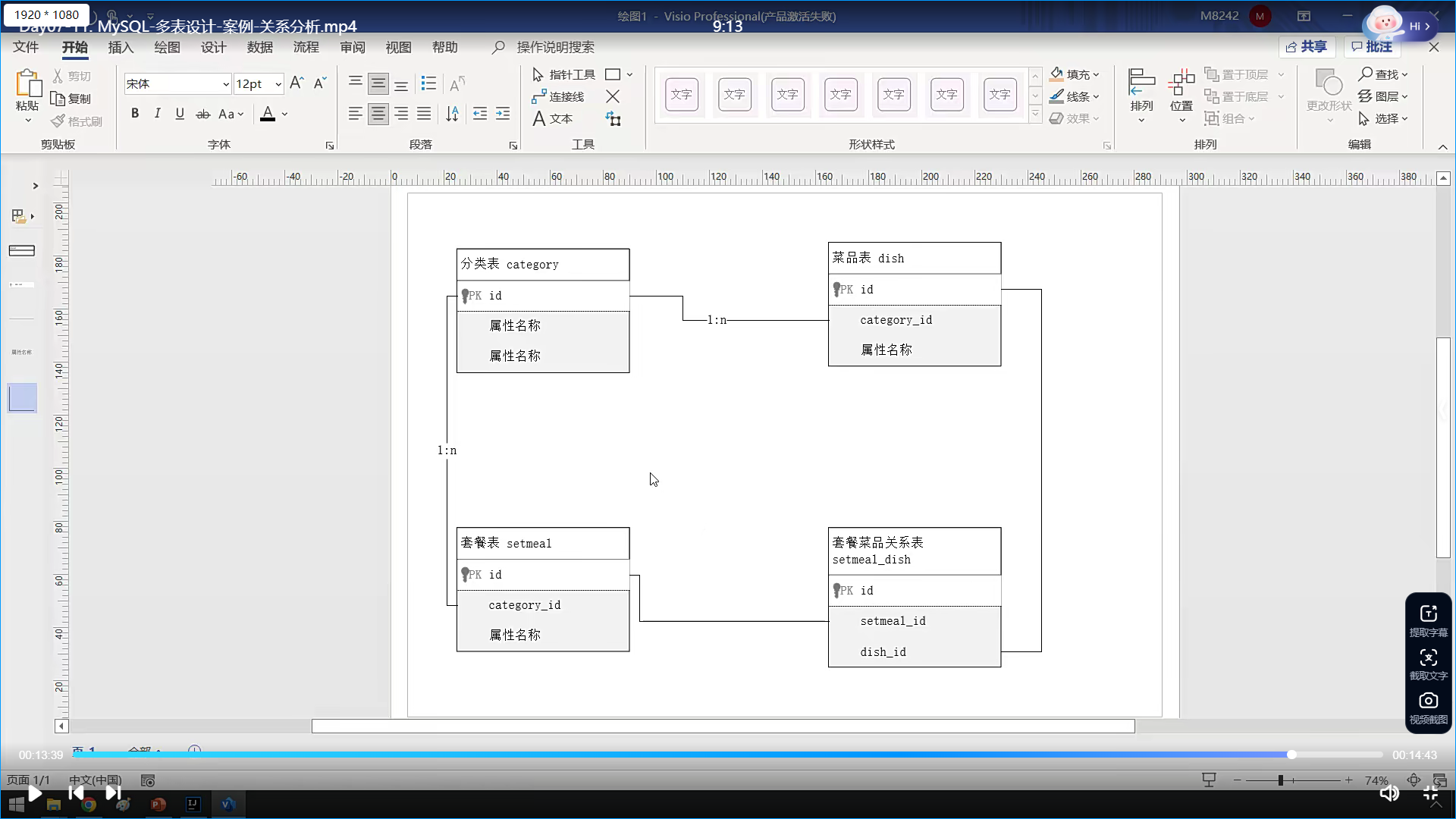
最后这是总的表结构关系
按照需求一一对应去可视化建表就行了,约束啊,唯一啊,等等等等,都按照需求填