C++性能优化指南
思维导图(转载)
https://www.processon.com/view/5e5b3fc5e4b03627650b1f42
第 1 章 优化概述
1.1 优化是软件开发的一部分
优化更像是一门实验科学。
1.2 优化是高效的
1.3 优化是没有问题的
**90/10 规则:**程序中只有 10% 的代码的性能是很重要的。
1.4 这儿一纳秒,那儿一纳秒
1.5 C++代码优化策略总结
1.用好的编译器并用好编译器
使用支持 C++11 的编译器。
多数情况下,只要正确地打开了优化选项,你都不用做额外的优化,因为编译器就可以让程序的运行速度提高数倍。
2.使用更好的算法
选择一个最优算法对性能优化的效果最大。(许多优化手段可以将程序性能提升 30% 至 100%。如果足够幸运,也许你可以将性能提升至三倍。但是除非你能找到一种更加高效的算法,否则要想实现性能的指数级增长通常是不太可能的。)
3.使用更好的库
某些方式的函数调用的开销非常大。
4.减少内存分配和复制
减少对内存管理器的调用是一种非常有效的优化手段,以至于开发人员只要掌握了这一个技巧就可以变为成功的性能优化人员。(绝大多数 C++ 语言特性的性能开销最多只是几个指令,但是每次调用内存管理器的开销却是数千个指令。)
对缓存复制函数的一次调用也可能消耗数千个 CPU 周期。因此,很明显减少复制是一种提高代码运行速度的优化方式。
5.移除计算
除了内存分配和函数调用外,单条 C++ 语句的性能开销通常都很小。
6.使用更好的数据结构
7.提高并发性
如果一个程序的处理进度因需要等待这些事件被暂停,而没有利用这些时间进行其他处理,都是一种浪费。
8.优化内存管理
第 2 章 影响优化的计算机行为
其中一小部分宝贵的内存字是寄存器(register),它们的名字被直接定义在机器指令中。其他绝大多数内存字则都是以数值型的地址(address)命名的。每台计算机中都有一个特殊的寄存器保存着下一条待执行的指令的地址。
指令会告诉执行单元要从内存中读取(加载,取得)什么数据,如何处理数据,以及将什么结果写入(存储、保存)到内存中。
2.1 C++所相信的计算机谎言
2.2 计算机的真相
真实计算机的实际内存硬件的处理速度与指令的执行速率相比是很慢的。
1.内存很慢
优化的根据在于处理器访问内存的开销远比其他开销大,包括执行指令的开销。
2.内存访问并非以字节为单位
虽然 C++ 认为每个字节都是可以独立访问的,但计算机会通过获取更大块的数据来补偿缓慢的内存速度。
**一次非对齐的内存访问的时间相当于这些字节在同一个字中时的两倍,因为需要读取两个字。**C++ 编译器会帮助我们对齐结构体,使每个字段的起始字节地址都是该字段的大小的倍数。但是这样也会带来相应的问题:结构体的“洞”中包含了无用的数据。在定义结构体时,对各个数据字段的大小和顺序稍加注意,可以在保持对齐的前提下使结构体更加紧凑。
64 位电脑的 CPU 一次最多处理 8 字节(64 位) 的数据, 但从内存访问角度看,通常一次读取 64 字节(一个 Cache Line) 以优化性能。
3.某些内存访问会比其他的更慢
在桌面级处理器中,通过一级高速缓存、二级高速缓存、三级高速缓存、主内存和磁盘上的虚拟内存页访问内存的时间开销范围可以跨越五个数量级。
访问那些被频繁地访问过的存储位置的速度会比访问不那么频繁地被访问的存储位置更快。
访问内存中相邻位置的字节要比访问互相远隔的字节的速度更快。
4.内存字分为大端和小端
5.内存容量是有限的
6.指令执行缓慢
如果指令 B 需要指令 A 的计算结果,那么在计算出指令 A 的处理结果前是无法执行指令 B的计算的。这会导致在指令执行过程中发生流水线停滞(pipeline stall)——一个短暂的暂停,因为两条指令无法完全同时执行。
7.计算机难以作决定
大多数情况下,在执行完一条指令后,处理器都会获取下一个内存地址中的指令继续执行。这时,**多数情况下,下一条指令已经被保存在高速缓存中了。**一旦流水线的第一道工序变为可用状态,指令就可以连续地进入到流水线中。
但是控制转义指令略有不同。跳转指令或跳转子例程指令会将执行地址变为一个新的值。在执行跳转指令一段时间后,执行地址才会被更新。**在这之前是无法从内存中读取“下一条”指令并将其放入到流水线中的。**新的执行地址中的内存字不太可能会存储在高速缓存中。在更新执行地址和加载新的“下一条”指令到流水线中的过程中,会发生流水线停滞。
在执行了一个条件分支指令后,执行可能会走向两个方向:下一条指令或者分支目标地址中的指令。最终会走向哪个方向取决于之前的某些计算的结果。这时,流水线会发生停滞,直至与这些计算结果相关的全部指令都执行完毕,而且还会继续停滞一段时间,直至决定一下条指令的地址并取得下一条指令为止。
8.程序执行中的多个流
为了性能调优,如果一个程序必须在启动时执行或是在负载高峰期时执行,那么在测量性能时也必须带上负载。
当新线程继续执行时,它的数据可能并不在高速缓存中,所以当加载新的上下文到高速缓存中时,会有一个缓慢的初始化阶段。因此,切换线程上下文的成本很高。
当操作系统从一个程序切换至另外一个程序时,这个过程的开销会更加昂贵。所有脏的高速缓存页面(页面被入了数据,但还没有反映到主内存中)都必须被刷新至物理内存中。所有的处理器寄存器都需要被保存。然后,内存管理器中的“物理地址到虚拟地址”的内存页寄存器也需要被保存。接着,新线程的“物理地址到虚拟地址”的内存页寄存器和处理器寄存器被载入。最后就可以继续执行了。但是这时高速缓存是空的,因此在高速缓存被填充满之前,还有一段缓慢且需要激烈地竞争内存的初始化阶段。
当一个程序必须等某个事件发生时,它甚至可能会在这个事件发生后继续等待,直至操作系统让处理器为继续执行程序做好准备。这会导致当程序运行于其他程序的上下文中,竞争计算机资源时,程序的运行时间变得更长和更加难以确定。
对优化而言,这意味着访问线程间的共享数据比访问非共享数据要慢得多。
9.调用操作系统的开销是昂贵的
对优化而言,这意味着系统调用的开销是昂贵的,是单线程程序中的函数调用开销的数百倍。
2.3 C++也会说谎
1.并非所有语句的性能开销都相同
对优化而言,这一点的意义是某些语句隐藏了大量的计算,但从这些语句的外表上看不出它的性能开销会有多大。
2.语句并非按顺序执行
当程序中包含共享数据的并发线程时,编译器对语句的重排序和延迟写入主内存会导致计算结果与按顺序执行语句的计算结果不同。开发人员必须向多线程程序中显式地加入同步代码来确保可预测的行为的一致性。当并发线程共享数据时,同步代码降低了并发量。
第 3 章 测量性能
编译器厂商通常在编译器中都会提供的分析器(profiler)。分析器会生成各个函数在程序运行过程中被调用的累积时间的表格报表。对性能优化而言,它是一个非常关键的工具,因为它会列出程序中最热点的函数。
计时器软件(software timer)。
3.1 优化思想
1.必须测量性能
2.优化器是王牌猎人
3.90/10规则
性能优化的基本规则是 90/10 规则:一个程序花费 90% 的时间执行其中 10% 的代码。
4.阿姆达尔定律

3.2 进行实验
1.记实验笔记
如果每次的测试运行情况都被记录在案,那么就可以快速地重复实验,回答上述问题就会变得很轻松了。
2.测量基准性能并设定目标
优化工作受两个数字主导:优化前的性能基准测量值和性能目标值。
3.你只能改善你能够测量的
3.3 分析程序执行
分析器的最大优点是它直接显示出了代码中最热点的函数。**优化过程被简化为列出需要调查的函数的清单,确认各个函数优化的可能性,修改代码,然后重新运行代码得到一份新的分析结果。**如此反复,直至没有特别热点的函数或是你无能为力了为止。
对调试构建(debug build)的分析结果和对正式构建(release build)的分析结果是一样的。在某种意义上,调试构建更易于分析,因为其中包含所有的函数,包括内联函数,而正式构建则会隐藏这些被频繁调用的内联函数。
*在 Windows 上分析调试构建的一个问题是,调试构建所链接的是调试版本的运行时库。*有一个环境变量可以让调试器不要使用调试内存管理器:进入控制面板→系统属性→高级系统设置→环境变量→系统变量,然后添加一个叫作 _NO_DEBUG_HEAP 的新变量并设定其值为 1。
3.4 测量长时间运行的代码
*如果程序要做许多不同的处理,可能在分析器看来,没有任何一个函数是热点。*程序还有可能会花费大量的时间等待 I/O 或是外部事件,这样降低了程序的性能,增加了程序的实际运行时间。在这种情况下,我们需要测量程序中各个部分的时间,然后试着减少其中低效部分的运行时间。
1.一点关于测量时间的知识
2.用计算机测量时间
多数现在流行的计算机体系结构在设计时都没有考虑过要提供很好的时钟。
这就导致不太可能测量函数的一次调用的持续时间。
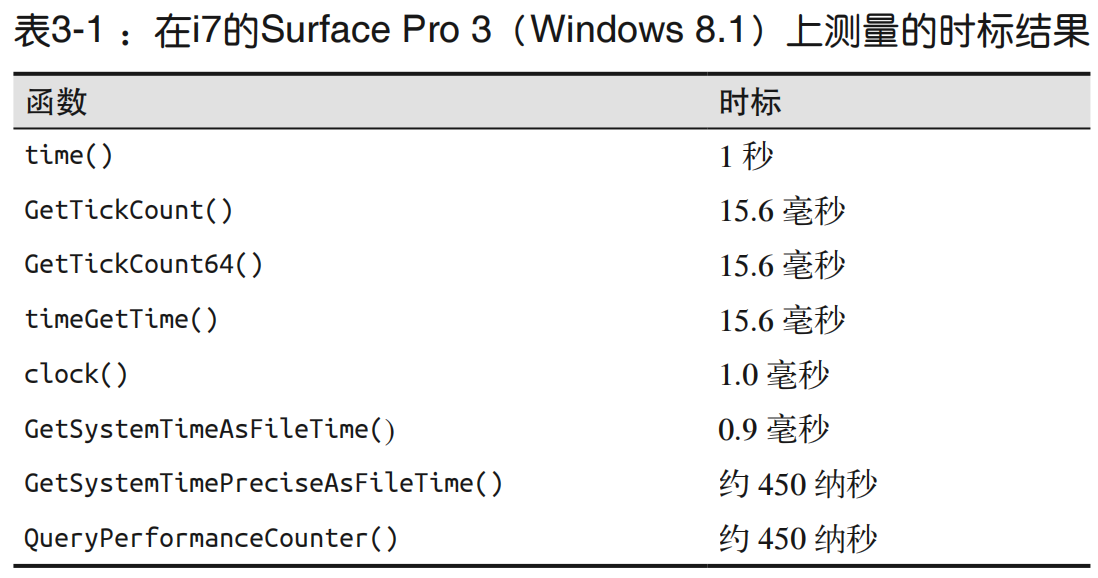
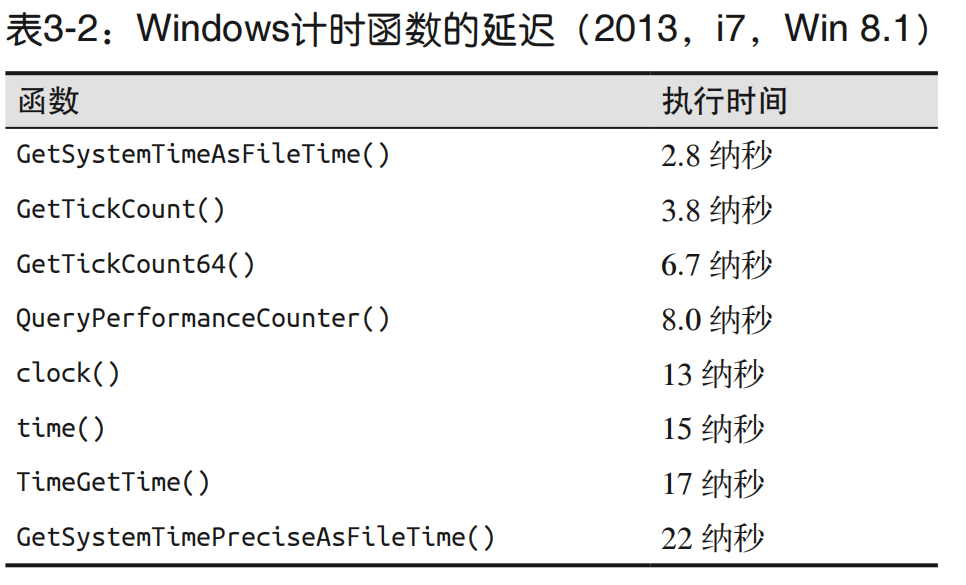
3.克服测量障碍
1.别为小事烦恼
测量误差只要在几个百分点以内就足够指引我们进行性能优化了。
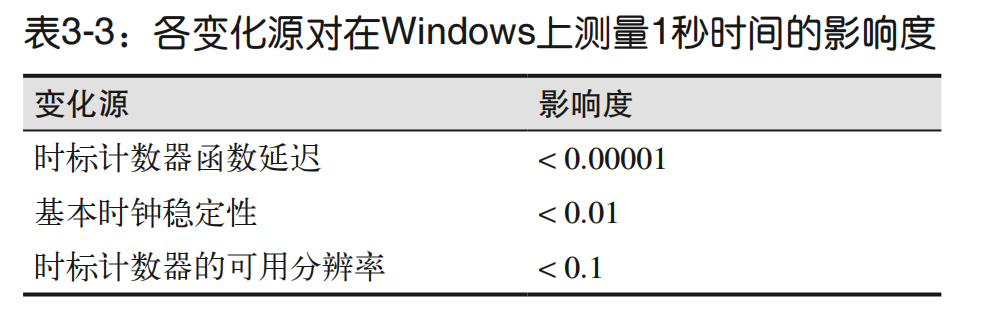
2.测量相对性能
优化后代码的运行时间与优化前代码的运行时间的比率被称为相对性能。
3.通过测量模块测试改善可重复性
4.根据指标优化性能
这种方式就是不测量临界响应时间等值,而是收集指标、代码统计数据(例如中间值和方差),或是响应时间的指数平滑平均数。由于这些统计数字是从大量的独立事件中得到的,因此这些数字的持续改善表明对代码的修改是成功的。
5.通过取多次迭代的平均值来提高准确性
6.通过提高优先级减少操作系统的非确定性行为
通过提高测量进程的优先级,可以减小操作系统使用 CPU 时间片段去执行测量程序以外的处理的几率。
7.非确定性发生了就克服它
如果在测量时间时调用了某个函数 10 000 次,这段代码和相关的数据会被存储在高速缓存中。当为一个实时系统测量最差情况下的绝对时间时,这会有影响。但是现在我是在一个内核本身就充满了非确定性的系统上测量相对时间。而且,我所测试的函数是我的分析器指出的热点函数。因此,即使是当正式版本在运行时,它们也会被缓存于高速缓存中。
**速度提高 10% 是临界值,而速度提高 100% 则对缩短整个程序的运行时间有非常大的帮助。**只进行有明显效果的性能改善可以将开发人员从对方法论的担忧中解放出来。
4.创建stopwatch类
5.使用测试套件测量热点函数

迭代次数需要凭经验估计。如果 stopwatch 使用的时标计数器的有效分辨率是大约 10 毫秒,那么测试套件在桌面处理器上的运行时间应当在几百到几千毫秒。
3.5 评估代码开销来找出热点代码
1.评估独立的C++语句的开销
有一条有效的规则能够帮助我们评估一条 C++ 语句的开销有多大,那就是计算该语句对内存的读写次数。
比如,r = *p + a[i]; 这条语句访问内存的次数如下:一次访问用于读取 i,一次读取a[i],一次读取 p,一次读取 *p 所指向的数据,一次将结果写入至 r。也就是说 , 总共进行了 5 次访问。
2.评估循环的开销
1.评估嵌套循环中的循环次数
2.评估循环次数为变量的循环的开销
3.识别出隐式循环
4.识别假循环
第 4 章 优化字符串的使用:案例研究
只要操作字符串的代码会被频繁地执行,那么那里就有优化的用武之地。
4.1 为什么字符串很麻烦
1.字符串是动态分配的
当一个字符串变量超出了其定义范围或是被赋予了一个新的值后,动态分配的存储空间会被自动释放。
如果字符串的实现策略是字符串缓冲区增大为原来的两倍,那么在该字符串的存储空间中,有一半都是未使用的。
2.字符串就是值
在赋值语句和表达式中,字符串的行为与值是一样的。可以将一个新值赋予给一个变量,但是改变这个变量并不会改变这个值。将一个字符串赋值给另一个字符串的工作方式是一样的,就仿佛每个字符串变量都拥有一份它们所保存的内容的私有副本一样。
如果你使用 s1 = s2 + s3 + s4; 这条语句连接字符串,那么 s2 + s3 的结果会被保存在一个新分配的临时字符串中。连接 s4后的结果则会被保存在另一个临时字符串中。这个值将会取代 s1 之前的值。接着,为第一个临时字符串和 s1 之前的值动态分配的内存将会被释放。这会导致多次调用内存管理器。
// 实际上 roughly 会被编译成:
auto tmp1 = s2 + s3; // 第一个临时字符串,存放 "s2 + s3" 的结果
auto tmp2 = tmp1 + s4; // 第二个临时字符串,存放 "tmp1 + s4" 的结果
s1 = tmp2; // 将结果赋值给 s1,触发 s1 的赋值操作
3.字符串会进行大量复制
**实现这种行为的最简单的方式是当创建字符串、赋值或是将其作为参数传递给函数的时候进行一次复制。**如果字符串是以这种方式实
现的,那么赋值和参数传递的开销将会变得很大,但是变值函数(mutating function)和非常量引用的开销却很小。
Copy-On-Write(写时复制)是 C++ 字符串实现历史中的一个经典技术概念。多个字符串对象可以共享同一个底层数据缓冲区,直到其中一个对象试图修改它——这时会复制一份新的缓冲区来进行修改。写时复制甚至是不符合 C++11 标准的实现方式,而且问题百出。
如果一个函数使用“右值引用”作为参数,那么当实参是一个右值表达式时,字符串可以进行轻量级的指针复制,从而节省一次复制操作。
4.2 第一次尝试优化字符串
字符串连接运算符的开销是很大的。它会调用内存管理器去构建一个新的临时字符串对象来保存连接后的字符串。
result = result + s[i];std::string tmp = result + s[i]; // operator+(std::string, char)
result = tmp; // 再把 tmp 赋值给 result
除了分配临时字符串来保存连接运算的结果外,将字符串连接表达式赋值给 result 时可能还会分配额外的字符串。当然,这取决于字符串是如何实现的。
• 如果字符串是以写时复制惯用法实现的,那么赋值运算符将会执行一次高效的指针复制并增加引用计数。
• 如果字符串是以非共享缓冲区的方式实现的,那么赋值运算符必须复制临时字符串的内容。如果实现是原生的,或者 result 的缓冲区没有足够的容量,那么赋值运算符还必须分配一块新的缓冲区用于复制连接结果。这会导致 100 次复制操作和 100 次额外的内存分配。
• 如果编译器实现了 C++11 风格的右值引用和移动语义,那么连接表达式的结果是一个右值,这表示编译器可以调用 result 的移动构造函数,而无需调用复制构造函数。因此,程序将会执行一次高效的指针复制。
1.使用复合赋值操作避免临时字符串
2.通过预留存储空间减少内存的重新分配
3.消除对参数字符串的复制
如果通过值将一个字符串表达式传递给一个函数,那么**形参将会通过复制构造函数被初始化。**这可能会导致复制操作,当然,这取决于字符串的实现方式。
• 如果字符串是以写时复制惯用法方式实现的,那么编译器会调用复制构造函数,这将执行一次高效的指针复制并增加引用计数。
• 如果字符串是以非共享缓冲区的方式实现的,那么复制造函数必须分配新的缓冲区并复制实参的内容。
• 如果编译器实现了 C++11 风格的右值引用和移动语义,而且实参是一个表达式,那么它就是是一个右值,这样编译器将会调用移动构造函数,这会执行一次高效的指针复制。如果实参是一个变量,那么将会调用形参的构造函数,这会导致一次内存分配和复制。
4.使用迭代器消除指针解引
指针解引用(dereferencing a pointer) 是指通过指针,访问它指向的值。
字符串迭代器是指向字符缓冲区的简单指针。
使用迭代器的实现方式,比不使用迭代器(比如用下标、裸指针)的方式要更快。
在 C++ 中,处理字符串或容器时,通常有几种常见方式:
方式 1:下标法(不使用迭代器):
for (size_t i = 0; i < s.length(); ++i) {char c = s[i];
}
方式 2:迭代器法:
for (auto it = s.begin(); it != s.end(); ++it) {char c = *it;
}
❗理论上:两者性能应该相近
s[i]:每次访问都要调用函数(operator[]),可能有边界检查或偏移计算*it:迭代器通常是轻量的封装(对vector,string来说就是一个指针)
5.消除对返回的字符串的复制
其中一种选择是将字符串作为输出参数返回,这种方法适用于所有的 C++ 版本以及字符串的所有实现方式。这也是编译器在省去调用复制构造函数时确实会进行的处理。
6.用字符数组代替字符串
**不使用 C++ 标准库,而是利用 C 风格的字符串函数来手动编写函数。**相比 std::string,C 风格的字符串函数更难以使用,但是它们却能带来显著的性能提升。
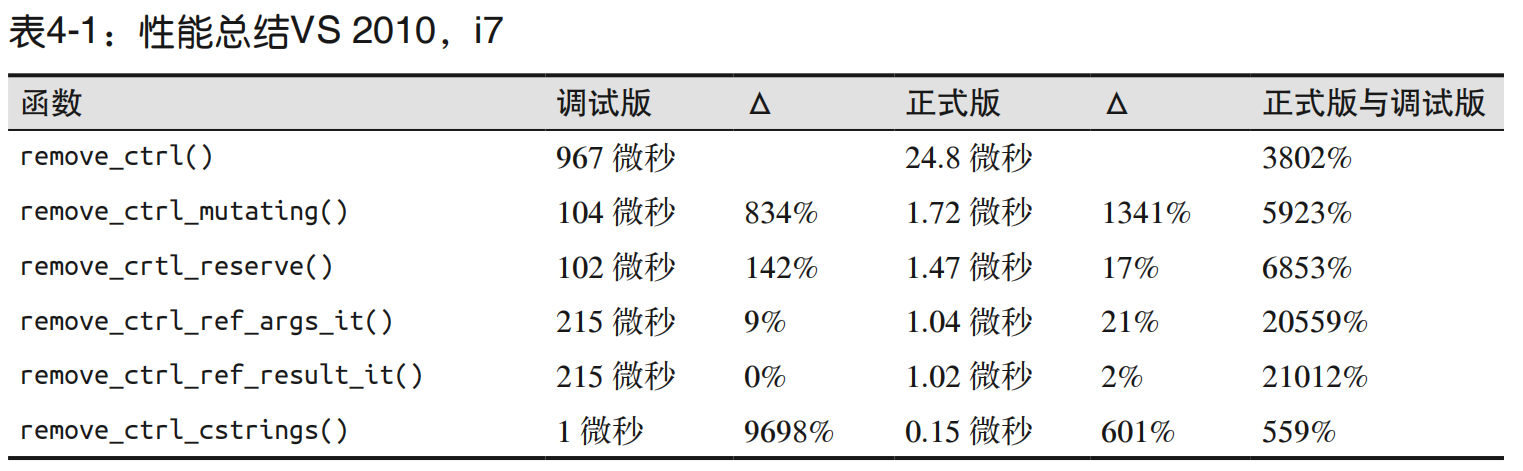
4.3 第二次尝试优化字符串
1.使用更好的算法
2.使用更好的编译器
3.使用更好的字符串库
1.采用更丰富的std::string库
Boost 字符串库(http://www.boost.org/doc/libs/?view=category_String)
Boost 字符串库提供了按标记将字符串分段、格式化字符串和其他操作 std::string 的函数。这为那些喜爱标准库中的 头文件的开发人员提供了很大的帮助。
C++ 字符串工具包(http://www.partow.net/programming/strtk/index.html)
另一个选择是 C++ 字符串工具包(StrTk)。StrTk 在解析字符串和按标记将字符串分段方面格外优秀,而且它兼容 std::string。
2.使用std::stringstream避免值语义
std::stringstream 之于字符串,就如同 std::ostream 之于输出文件。std::stringstream 类以一种不同的方式封装了一块动态大小的缓冲区(事实上,通常就是一个 std::string),数据可以被添加至这个实体中。
3.采用一种新奇的字符串实现方式
4.使用更好的内存分配器
4.4 消除字符串转换
1.将C字符串转换为std::string
2.不同字符集间的转换
移除转换的最佳方法是为所有的字符串选择一种固定的格式,并将所有字符串都存储为这种格式。
我个人比较喜欢 UTF-8,因为它能够表示所有的 Unicode 代码点,可以直接与 C 风格的字符串进行比较(是否相同),而且多数浏览器都可以输出这种格式。
| 特性 | UTF-8 |
|---|---|
| 字符集支持 | 全部 Unicode |
| 空间效率 | 高(ASCII 最优) |
| C 兼容性 | ✅ |
| 语言/平台支持 | 几乎全平台支持 |
| 编码安全性 | 需小心字符边界处理 |
| 问题 | 描述 |
|---|---|
| 👣 多字节字符 | 一个“字符”可能是 1~4 个字节,s[i] 不能直接取第 i 个字符 |
| 🔄 编码边界 | 不能随意截断字符串,否则可能破坏字符(乱码) |
| 📏 长度计算 | s.length() 返回的是字节数,不是“字符数” |
第 5 章 优化算法
多数优化方法的性能改善效果是线性的,但是使用更高效的算法替换低效算法可以使性能呈现指数级增长。
除了为未知数据选择一种最优算法外,对于已经排序好或是几乎排序好的数据以及具有其他特性的数据,有些算法会特别高效。
5.1 算法的时间开销
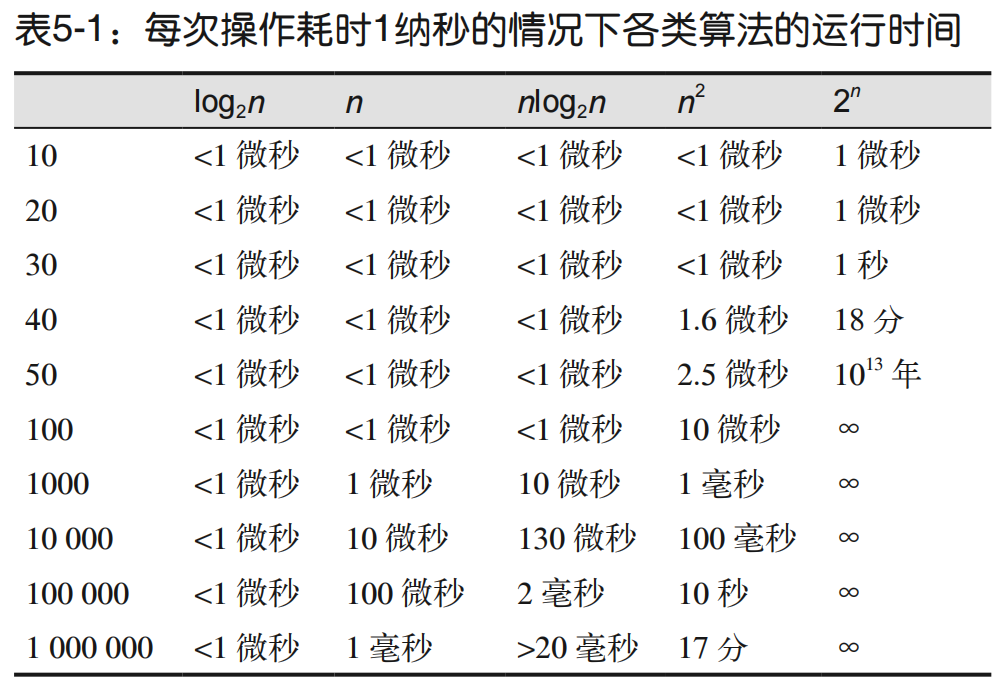
当考虑在有严格的性能需求的代码中使用哪种算法时,非常重要的一点是必须知道该算法是否有最差情况。
摊销时间开销表示在大量输入数据上的平均时间开销。
假设某个数据结构支持操作A,有时候它的执行非常快(比如O(1)),但在某些特定情况下会非常慢(比如O(n)),这种时候我们不只看某一次操作的最坏时间,而是:
从整体来看,总共做了很多操作,总共花了多少时间,平均下来每次操作花多少时间。
5.2 优化查找和排序的工具箱
• 用平均时间开销更低的算法替换平均时间开销较大的算法。
• 加深对数据的理解(例如,知道数据是已经排序完成的或是几乎排序完成的),然后根据数据的特性选择具有最优时间开销的算法,避免使用那些针对这些数据特性有较差时间开销的算法。
• 调整算法来线性地提高其性能。
5.3 高效查找算法
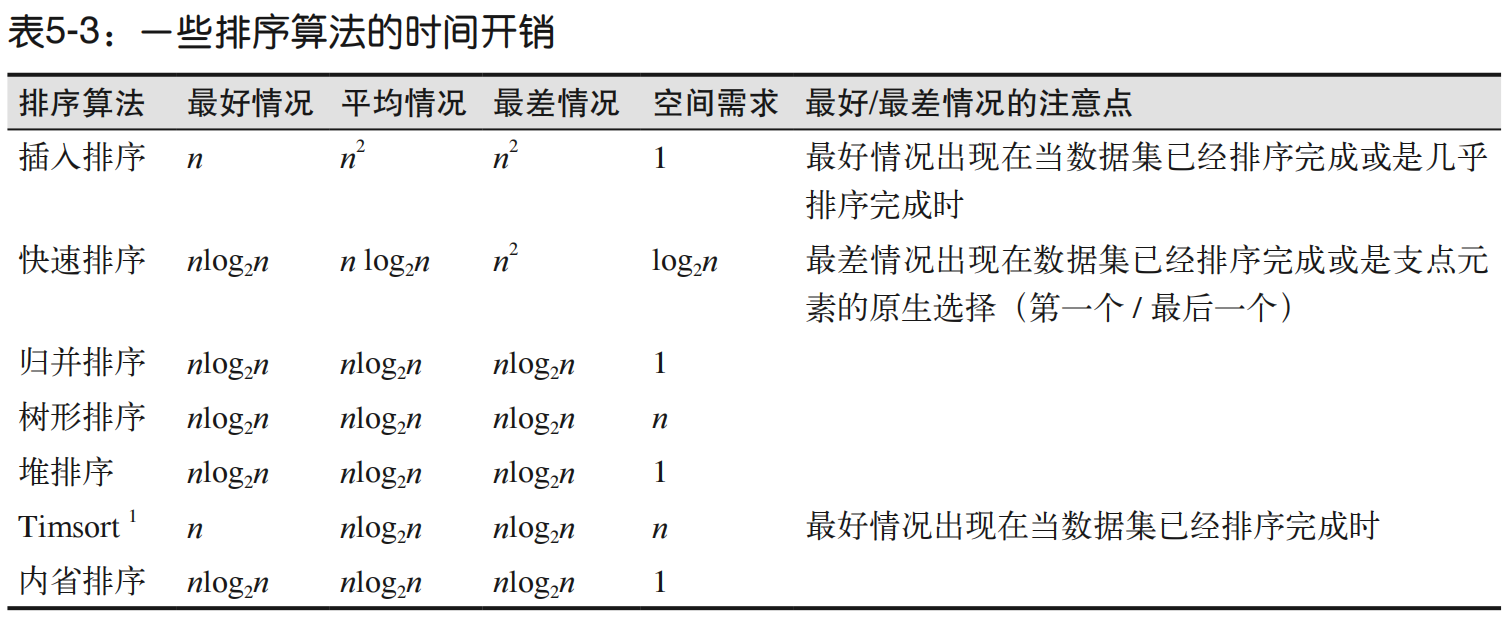
5.4 高效排序算法
基数排序算法(将输入数据反复地分到一个或 r 个桶中的排序算法)的时间开销是 O(n logrn),其中 r 是基数,即排序桶的个数。在大型输入数据集上,它的效率比比较排序算法更高。而且,如果要排序的关键字属于某个特定的集合,例如从 1 到 n 的连续整数,Flash Sort 的排序时间开销是 O(n)。
有些排序算法,包括插入排序算法,虽然并非非常适合用于随机数据,但在几乎排序完成的数据集上却具有非常棒的(线性)效率。
5.5 优化模式
1.预计算
可以在程序早期,例如设计时、编译时或是链接时,通过在热点代码前执行计算来将计算从热点部分中移除。
2.延迟计算
通过在真正需要执行计算时才执行计算,可以将计算从某些代码路径上移除。
3.批量处理
每次对多个元素一起进行计算,而不是一次只对一个元素进行计算。
4.缓存
通过保存和复用昂贵计算的结果来减少计算量,而不是重复进行计算。
5.特化
通过移除未使用的共性来减少计算量。
6.提高处理量
通过一次处理一大组数据来减少循环处理的开销。
7.提示
通过在代码中加入可能会改善性能的提示来减少计算量。
8.优化期待路径
以期待频率从高到低的顺序对输入数据或是运行时发生的事件进行测试。
9.散列法
大型数据结构或长字符串会被一种算法处理为一个称为散列值的整数值。通过比较两个输入数据的散列值,可以高效地判断出它们是否相等。如果散列值不同,那么这两个数据绝对不相等。如果散列值相等,那么输入数据可能相等。
10.双重检查
通过先进行一项开销不大的检查,然后只在必要时才进行另外一项开销昂贵的检查来减少计算量。
第 6 章 优化动态分配内存的变量
除了使用非最优算法外,乱用动态分配内存的变量就是 C++ 程序中最大的“性能杀手”了。
从循环处理中或是会被频繁调用的函数中移除哪怕一次对内存管理器的调用,就能显著地改善性能,而且通常程序中有很多可被移除的调用。
6.1 C++变量回顾
具有静态存储期的变量被分配在编译器预留的内存空间中。
自 C++11 开始,用 thread_local 存储类型指示符关键字声明的变量具有线程局部存储期。
| 存储期 | 有运行时开销吗? | 主要开销来自 |
|---|---|---|
| 静态存储期 | ❌ 无 | 编译期分配,无运行时开销 |
| 线程存储期 | ✅ 有 | 线程创建时的变量分配和销毁 |
| 自动存储期 | ✅ 有 | 栈帧建立 + 构造/析构函数 |
| 动态存储期 | ✅ 有 | 堆分配器的管理成本 |
一个变量是实体对象还是值对象决定了复制以及比较相等是否有意义。实体不应当被复制和比较。
一个类的成员变量是实体还是值决定了应该如何编写该类的构造函数。
类实例可以共享实体的所有权,但是无法有效地复制实体。
透彻地理解实体对象和值对象非常重要,因为实体变量中往往包含许多动态分配内存的变量,即使复制这些变量是合理的,但其性能开销也是昂贵的。
6.2 C++动态变量API回顾
placement new
char array[sizeof(Book)];
Book* bp2 = new(array) Book("Moby Dick"); // placement new 操作符
它在一个已经分配好的内存区域 array 上构造一个 Book 对象,并返回它的指针。
1.使用智能指针实现动态变量所有权的自动化
相比于自己编写代码实现的智能指针,unique_ptr 被编译后产生的代码更加高效。
使用 unique_ptr 时会发生一些小的性能损失,因此当开发人员想要优化性能时,unique_ptr 是首选。
由于在引用计数上会发生性能开销昂贵的原子性的加减运算,因此 shared_ptr 可以工作于多线程程序中。**std::shared_ptr 也因此比 C 风格指针和std::unique_ptr 的开销更大。**开发人员不能将 C 风格的指针(例如 new 表达式返回的指针)赋值给多个智能指针,而只
能将其从一个智能指针赋值给另外一个智能指针。如果将同一个 C 风格的指针赋值给多个智能指针,那么该指针会被多次删除,导致发生 C++ 标准中所谓的“未定义的行为”。
2.动态变量有运行时开销
为动态变量分配内存的开销则是数千次内存访问。平均来看,这种开销太大了。
调用内存释放函数与调用内存分配函数有着相同的问题:降低缓存效率和争夺对未使用的内存块的多线程访问。
6.3 减少动态变量的使用
1.静态地创建类实例
一种解决模式是将这个“问题类”(而不是指向它的指针)声明为其他类的成员,并在创建其他类时部分初始化这个“问题类”。然后,在
“问题类”中定义一个用于在资源准备就绪时完全地初始化变量的成员函数。最后,在原来使用 new 表达式动态地创建实例的地方,插入一段调用这个初始化成员函数的代码就可以了。这种常用的解决模式被称为两段初始化。
当一个类必须在初始化的过程中做一些非常耗时的事情,如读取文件(这可能会失败)或是从互联网上获取网页的内容时,“两段初始化”特别有效。提供一个单独的初始化函数使得与其他程序活动一起并发地进行这类初始化工作成为可能,而且如果失败了,也很容易进行第二次初始化。
2.使用静态数据结构
1.用std::array替代std::vector 数组大小固定且不会调用内存管理器的 std::array
2.在栈上创建大块缓冲区
3.静态地创建链式数据结构
4.在数组中创建二叉树
如果节点的索引是 i,那么它的两个子节点的索引分别是 2i 和 2i+1。这种方法带来的另外一个好处是,能够很快地知道父节点的索引是 i/2。
这些特性——能够计算子节点和父节点的能力以及左平衡树所表现出的高效——使得对于堆数据结构而言,在数组中构建树是一种高效的实现方法。
5.用环形缓冲区替代双端队列
还可以在环形缓冲区上实现双端队列。
环形缓冲区与链表或是双端队列的不同在于,环形缓冲区使得缓冲区中元素的数量限制变得可见。通过暴露这项限制条件给使用者来特化通用队列数据结构,使得显著地性能提升成为可能。
3.使用std::make_shared替代new表达式
这个函数可以分配一块独立的内存来同时保存引用计数和 MyClass的一个实例。
4.不要无谓地共享所有权
void fiddle(Foo* f);...
shared_ptr<Foo> myFoo = make_shared<Foo>();...
fiddle(myFoo.get());void fiddle(Foo& f);...
shared_ptr<Foo> myFoo = make_shared<Foo>();...
if (myFoo)fiddle(*myFoo.get());
5.使用“主指针”拥有动态变量
6.4 减少动态变量的重新分配
1.预分配动态变量以防止重新分配
在使用 reserve() 预分配 string 或是 vector 后,还可以使用 std::string 或是 std::vector的 shrink_to_fit() 成员函数将未使用的空间返回给内存管理器。
标准库散列表类型 std::unordered_map有一个链接到其他数据结构的骨干数组(桶的链表)。它也有一个 reserve() 成员函数。不幸的是,std::deque 虽然也有一个骨干数组,却没有 reserve() 成员函数。
2.在循环外创建动态变量
6.5 移除无谓的复制
复制可能会发生于以下任何一种情况下:
• 初始化(调用构造函数)
• 赋值(调用赋值运算符)
• 函数参数(每个参数表达式都会被移动构造函数或复制构造函数复制到形参中)
• 函数返回(调用移动构造函数或复制构造函数,甚至可能会调用两次)
• 插入一个元素到标准库容器中(会调用移动构造函数或复制构造函数复制元素)
• 插入一个元素到 vector 中(如果需要重新为 vector 分配内存,那么所有的元素都会通过移动构造函数或复制构造函数复制到新的 vector 中)
1.在类定义中禁止不希望发生的复制
在 C++11 中,我们可以在复制构造函数和赋值运算符后面加上 delete 关键字来达到这个目的。将带有 delete 关键字的复制构造函数的可见性设为 public 更好,因为在这种情况下调用复制构造函数的话,编译器会报告出明确的错误消息。
2.移除函数调用上的复制
3.移除函数返回上的复制
如果函数返回一个值,那么这个值会被复制构造到一个未命名的与函数返回值类型相同的临时变量中。
就像返回值的复制构造的开销并不算太糟糕,调用方常常会像 auto res =scalar_product(argarray, 10); 这样将函数返回值赋值给一个变量。因此,除了在函数内部调用复制构造外,在调用方还会调用复制构造函数或赋值运算符。
在早期的 C++ 程序中,这两次复制构造函数的开销简直是性能杀手。幸运的是,C++ 标准的制定人员和许多优秀的 C++ 编译器找到了一种移除额外的复制构造函数调用的方法。这种优化方法被称为复制省略(copy elision)或是返回值优化(return value optimization,RVO)。
只有在某些特殊的情况下编译器才能够进行 RVO。函数必须返回一个局部对象。编译器必须能够确定在所有的控制路径上返回的都是相同的对象。返回对象的类型必须与所声明的函数返回值的类型相同。
4.免复制库
5.实现写时复制惯用法
6.切割数据结构
**切割(slice)是一种编程惯用法,它指的是一个变量指向另外一个变量的一部分。*例如,C++17 中推荐的 string_view 类型就指向一个字符串的子字符串,它包含了一个指向子字符串开始位置的 char 指针以及到子字符串的长度。
6.6 实现移动语义
1.非标准复制语义:痛苦的实现
2.std::swap():“穷人”的移动语义
3.共享所有权的实体
4.移动语义的移动部分
为了实现移动语义,C++ 编译器需要能够识别一个变量在什么时候只是临时值。这样的实例是没有名字的。例如,函数返回的对象或 new 表达式的结果就没有名字。不可能会有其他引用指向该对象。该对象可以被初始化、赋值给一个变量或是作为表达式或函数的参数。但是接下来它会立即被销毁。这样的无名值被称为右值,因为它与赋值语句右侧的表达式的结果类似。相反,左值是指通过变量命名的值。在语句 y = 2x + 1; 中,表达式2x + 1 的结果是一个右值,它是一个没有名字的临时值。等号左侧的变量是一个左值,y是它的名字。
5.更新代码以使用移动语义
6.移动语义的微妙之处
1.移动实例至std::vector
如果你希望你的对象在 std::vector 中能够高效地移动,那么仅仅编写移动构造函数和移动赋值运算符是不够的。开发人员必须将移动构造函数和移动赋值运算符声明为noexcept。
2.右值引用参数是左值
std::string MoveExample(std::string&& s) {std::string tmp(std::move(s));
// 注意!现在s是空的return tmp;
}...
std::string s1 = "hello";
std::string s2 = "everyone";
std::string s3 = MoveExample(s1 + s2);template <typename T> void std::swap(T& a, T& b) {
{T tmp(std::move(a));a = std::move(b);b = std::move(tmp);
}
3.不要返回右值引用
返回右值引用会妨碍返回值优化,即允许编译器向函数传递一个指向目标的引用作为隐藏参数,来移除从未命名的临时变量到目标的复制。返回右值引用会执行两次移动操作,而一旦使用了返回值优化,返回一个值则只会执行一次移动操作。
4.移动父类和类成员
class Base {...};
class Derived : Base {...std::unique_ptr<Foo> member_;Bar* barmember_;
};
Derived::Derived(Derived&& rhs): Base(std::move(rhs)),member_(std::move(rhs.member_)),barmember_(nullptr) {std::swap(this->barmember_, rhs.barmember_);
}
6.7 扁平数据结构
当一个数据结构中的元素被存储在连续的存储空间中时,我们称这个数据结构为扁平的。
第 7 章 优化热点语句
语句级别的优化可以被模式化为从执行流中移除指令的过程。
语句级别的性能优化的问题在于,除了函数调用外,没有哪条 C++ 语句会消耗许多条机器指令。
重点:循环、频繁被调用的函数、贯穿整个程序的惯用法
在语句级别优化代码能够显著地改善嵌入在各种工具、装置、外设和玩具中的简单的小型处理器的性能,因为在这类处理器上,指令是直接从内存中被获取,然后一条一条被执行的。不过,由于桌面级和手持设备的处理器提供了指令级的并发和缓存,因此语句级别的优化带来的回报比优化内存分配和复制要小。
在为桌面级计算机设计的程序中,应当只对那些会被频繁调用的库函数或是程序中最底层的循环,如占用最多运行时间的图形引擎或编程语言解释器,进行语句级别的优化。
语句级别的性能优化还有一个问题:优化效果取决于编译器。这是语句级别的优化可能比其他性能优化手段效果更差的另一个原因。
7.1 从循环中移除代码
1.缓存循环结束条件值
2.使用更高效的循环语句
将一个 for 循环简化为 do 循环通常可以提高循环处理的速度。
3.用递减替代递增
缓存循环结束条件的另一种方法是用递减替代递增,将循环结束条件缓存在循环索引变量中。许多循环都有一种结束条件判断起来比其他结束条件更高效。
4.从循环中移除不变性代码
现代编译器非常善于找出在循环中被重复计算的具有循环不变性的代码(如同这里介绍的),然后将计算移动至循环外部来改善程序性能。开发人员通常没有必要重写这段代码,因为编译器已经替我们找出了具有循环不变性的代码并重写了循环。
5.从循环中移除无谓的函数调用
6.从循环中移除隐含的函数调用
当一个变量是以下类型之一时就可能会发生这种情况:
• 声明一个类实例(调用构造函数)
• 初始化一个类实例(调用构造函数)
• 赋值给一个类实例(调用赋值运算符)
• 涉及类实例的计算表达式(调用运算符成员函数)
• 退出作用域(调用在作用域中声明的类实例的析构函数)
• 函数参数(每个参数表达式都会被复制构造到它的形参中)
• 函数返回一个类的实例(调用复制构造函数,可能是两次)
• 向标准库容器中插入元素(元素会被移动构造或复制构造)
• 向矢量中插入元素(如果矢量重新分配了内存,那么所有的元素都需要被移动构造或是复制构造)
7.从循环中移除昂贵的、缓慢改变的调用
8.将循环放入函数以减少调用开销
循环倒置是指将在循环中调用函数变为在函数中进行循环。这需要改变函数的接口,不再接收一条元素作为参数,而是接收整个数据结构作为参数。按照这种方式修改后,如果数据结构中包含 n条元素,那么可以节省 n-1 次函数调用。
9.不要频繁地进行操作
10.其他优化技巧
事实上,编译器比绝大多数程序员的编程能力更加优秀。这也是为什么使用类似的性能优化技巧的结果总是让人沮丧,以及为什么本
节中的内容并不会太多。
7.2 从函数中移除代码
尽管执行函数体的开销可能会非常大,但是调用函数的开销与调用大多数 C++ 语句的开销一样,是非常小的。
1.函数调用的开销
函数参数、成员函数调用(与函数调用)、调用和返回、虚函数的开销、继承中的成员函数调用、函数指针的开销
C 风格的不带参数的 void 函数的调用开销是最小的。如果能够内联它的话,就没有开销;即使不能内联,开销也仅仅是两次内存读取加上两次程序执行的非局部转移。
如果基类没有虚函数,而虚函数在多重虚拟继承的继承类中,那么这是最坏的情况。不过幸运的是,这种情况非常罕见。在这种情况下,代码必须解引类实例中的函数表来确定加到类实例指针上的偏移量,构成虚拟多重继承函数的实例的指针,接着解引该实例来获取虚函数表,最后索引虚函数表得到函数执行地址。
2.简短地声明内联函数
那些函数体在类定义中的函数会被隐式地声明为内联函数。通过将在类定义外部定义的函数声明为存储类内联,也可以明确地将它们声明为内联函数。
3.在使用之前定义函数
如果函数在第一次被调用之前就已经定义了(提供了函数体),那么编译器有机会选择将函数内联(inline),从而提升性能 —— 即“把函数调用展开成直接的代码”。
这个逻辑甚至适用于虚函数,但有条件。
4.移除未使用的多态性
5.放弃不使用的接口
有时,一个程序虽然定义了接口,但是只提供了一种实现。在这种情况下,通过移除接口,即移除 file.h 类定义中的 virtual 关键字并提供 file 的成员函数的实现,可以节省虚函数调用(特别是频繁地对 GetChar() 的调用)的开销。
1.在链接时选择接口实现
**如果无需在运行时做出选择的话,那么开发人员可以使用链接器来从多个实现中选择一种。**具体做法是不声明 C++ 接口,而是在头文件中直接声明(但不实现)成员函数,就像它们是标准库函数一样。
// file.h——接口
class File {
public:File();bool Open(Path& p);bool Close();int GetChar();unsigned GetErrorCode();
};
在 windowsfile.cpp 文件中有如下 Windows 的实现代码:
// windowsfile.cpp——Windows的实现代码
# include "File.h"
bool File::Open(Path& p) {...
}
bool File::Close() {...
}
...
在另外一个名为 linuxfile.cpp 的相似文件中包含了 Linux 的实现。Visual Studio 工程文件引用 windowsfile.cpp,Linux 的 makefile 则引用 linuxfile.cpp。选择哪个实现会由链接器根据参数列表来做出决定。现在,调用 GetChar() 已经达到最高性能了。
在链接时选择实现的优点是使得程序具有通用性,而缺点则是部分决定被放在了 .cpp 文件中,部分决定被放在了 makefile 或是工程文件中。
2.在编译时选择接口实现
如果对于两种 file 实现使用不同的编译器(例如对 Window 版本使用 Visual Studio,对Linux 版本使用 GCC),那么可以在编译时使用 #ifdef 来选择实现。头文件不需要做任何改变。下面是一个名为 file.cpp 的源文件,其中预处理宏会选择实现:
// file.cpp——实现
# include "File.h"
# ifdef _WIN32bool File::Open(Path& p) {...}bool File::Close() {...}...
# else // Linuxbool File::Open(Path& p) {...}bool File::Close() {...}...
# endif
这个方法要求能够使用预处理宏来选择所希望的实现。
6.用模板在编译时选择实现
7.避免使用PIMPL惯用法
PIMPL 是“Pointer to IMPLementation”的缩写,它是一种用作编译防火墙——一种防止修改一个头文件会触发许多源文件被重编译的机制——的编程惯用法。
8.移除对DDL的调用
9.使用静态成员函数取代成员函数
静态成员函数不会计算隐式 this 指针,可以通过普通函数指针,而不是开销更加昂贵的成员函数指针找到它们。
10.将虚析构函数移至基类中
7.3 优化表达式
1.简化表达式
C++ 编译器绝对不会使用分配律将表达式重新编码为像 a*(b+c) 这样的更高效的形式。
这意味着开发人员必须尽可能使用最少的运算符来书写表达式。
多项式 y = ax3 + bx2 + cx + d 在 C++ 中可以写为:
y = a*x*x*x + b*x*x + c*x + d;
这条语句将会执行 6 次乘法运算和 3 次加法运算。我们可以根据霍纳法则重复地使用分配律来重写这条语句:
y = (((a*x + b)*x) + c)*x + d;
这条优化后的语句只会执行 3 次乘法运算和 3 次加法运算。
2.将常量组合在一起
3.使用更高效的运算符
所有处理器(除了最小型的处理器)都可以在一个内部时钟周期中执行一次位移或是加法操作。
用位移运算和加法运算替代乘法。
4.使用整数计算替代浮点型计算
浮点型计算的开销是昂贵的。
5.双精度类型可能会比浮点型更快
6.用闭形式替代迭代计算
对于某些问题,还有更快更紧凑的闭形式解决方法:计算的时间开销为常量,不进行任何迭代。
考虑一个简单的用于确定一个整数是否是 2 的幂的迭代算法。所有这些值都只有 1个置为 1 的位,因此算出置为 1 的位的数量是一种解决方法。
这个问题同样有一种闭形解决方法。如果 x 是 2 的 n 阶幂,那么它只在第 n 位有一个置为1 的位(以最低有效位作为第 0 位)。接着,我们用 x-1 作为当置为 1 的位在第 n-1,…,0 位时的位掩码,那么 x& (x-1) 等于 0。如果 x 不是 2 的幂,那么它就有不止一个置为 1 的位,那么使用 x-1 作为掩码计算后只会将最低有效位置为 0,x& (x-1) 不再等于 0。
7.4 优化控制流程惯用法
1.用switch替代if-else if-else
如果所有的条件为真的概率都是一样的,那么 if-then-else if 将会进行 O(n) 次判断。如果这段代码执行得非常频繁,例如在事件分发代码或是指令分发代码中,那么开销将会显著地增加。
switch 语句也会测试一个变量是否等于这 n 个值,但是由于 switch 语句的形式比较特殊,它用 switch 的值与一系列常量进行比较,这样编译器可以进行一系列有效的优化。
2.用虚函数替代switch或if
3.使用无开销的异常处理
第 8 章 使用更好的库
8.1 优化标准库的使用
1.C++标准库的哲学
C++ 的这种实现方法的优点包括 C++ 程序能够运行于没有提供任何操作系统的硬件之上,以及在适当时程序员能够选择一种专业的适用于某种操作系统特性的库,或是在要实现平台独立性时使用一种跨平台的库。
2.使用C++标准库的注意事项
标准库的实现中有 bug、标准库的实现可能不符合 C++ 标准、对标准库开发人员来说,性能并非最重要的事情、库的实现可能会让一些优化手段无效、并非 C++ 标准库中的所有部分都同样有用、标准库不如最好的原生函数高效
8.2 优化现有库
1.改动越少越好
2.添加函数,不要改动功能
8.3 设计优化库
那些最优秀和最实用的库都实现了这些远大的目标。
1.草率编码后悔多
接口的稳定性是设计可持续交付的库的核心。
如果在测试一个目标函数前需要实例化许多对象,那么这对于设计人员来说就是一个信号,它表明库的组件之间存在着太多的耦合。
2.在库的设计上,简约是一种美德
3.不要在库内分配内存
4.若有疑问,以速度为准
在发生性能问题之后再去改善性能则会非常困难,甚至是不可能的,特别是当牵扯到需要改变函数签名或是函数行为时。
5.函数比框架更容易优化
框架在概念上是一个非常庞大的类,它实现了一个完整程序的骨架,例如一个视窗应用程序或是一个 Web 服务器。
函数的优势在于我们可以独立地测量和优化它们的性能。调用一个框架会牵扯到它内部的所有类和函数,使得修改变得难以隔离和测试。
6.扁平继承层次关系
多数抽象都不会有超过三层类继承层次:一个具有通用函数的基类,一个或多个实现多态的继承类,以及一个在非常复杂的情况下可能会引入的多重继承混合层。
从性能优化的角度看,继承层次越深,在成员函数被调用时引入额外计算的风险就越高。
7.扁平调用链
与继承类一样,绝大多数抽象的实现都不会超过三层嵌套函数调用
8.扁平分层设计
9.避免动态查找
动态地查找符号表可是“性能杀手”,原因如下。
- 动态查找天生低效。有些库查找 JSON 或 XML 元素的性能是 O(n),时间开销与待查找的文件大小成正比。基于表的查找的时间开销可能是 O(log2n)。相比之下,从结构体中获取一个元素的时间开销只有 O(1),而且这个比例常量非常小。
- 库的设计人员可能对库需要访问的元数据不太了解。
- 一旦决定采用基于表的查找的设计方式,那么接下来的问题就是一致性了。
- 基于结构体的数据仓库在某种程度上可以说是自描述的,因为所有可能的元数据都是立即可见的。
10.留意“上帝函数”
“上帝函数”是指实现了高级策略的函数。
第 9 章 优化查找和排序
先将现有解决方案分解为组件算法和数据结构,然后在每个组件算法和数据结构中寻找优化机会。
9.1 使用std::map和std::string的键值对表
使用 std::map 构建一个 std::string 类型的名字与无符号整数值之间的映射关系的表是很容易的。
9.2 改善查找性能的工具箱
1.进行一次基准测量
2.识别出待优化的活动
3.分解待优化的活动
但如果表具有静态存储期,那么初始化表的开销可能会被加到所有在程序启动时发生的其他初始化操作上。**如果程序需要进行太多的初始化操作,那么它会失去响应。**而如果表具有自动存储期,那么它可能会在程序运行期间中多次被初始化,使程序的启动开销变得更大。
4.修改或替换算法和数据结构
5.在自定义抽象上应用优化过程
9.3 优化std::map的查找
1.以固定长度的字符数组作为std::map的键
如果表使用 std::string 作为键,而开发人员希望如下这样用 C 风格的字符串字面常量来查找元素,那么每次查找都会将 char 的字符串字面常量转换为 std::string,其代价是分配更多的内存,而且这些内存紧接着会立即被销毁掉。*
unsigned val = table["zulu"];template <unsigned N=10, typename T=char> struct charbuf {charbuf();charbuf(charbuf const& cb);charbuf(T const* p);charbuf& operator=(charbuf const& rhs);charbuf& operator=(T const* rhs);bool operator==(charbuf const& that) const;bool operator<(charbuf const& that) const;
private:T data_[N];
};
C++ 标准库通常只会使用 == 运算符和 <运算符。其他四种运算符可以从这两种中合成出来。
2.以C风格的字符串组作为键使用std::map
// method 1
bool less_free(char const* p1, char const* p2) {return strcmp(p1,p2)<0;
}...
std::map<char const*,unsigned,bool(*)(char const*,char const*)> table(less_free);// method 2
struct less_for_c_strings {bool operator()(char const* p1, char const* p2) {return strcmp(p1,p2)<0;}
};...
std::map<char const*,unsigned,less_for_c_strings> table;// method 3
auto comp = [](char const* p1, char const* p2) {return strcmp(p1,p2)<0;
};
std::map<char const*,unsigned,decltype(comp)> table(comp);
3.当键就是值的时候,使用map的表亲std::set
9.4 使用头文件优化算法
有些基于迭代器的查找方法实现了分而治之的算法。这些算法依赖于某些迭代器的一种特性——计算两个迭代器之间的距离或是元素数量的能力——以这种方法实现比线性大 O 性能更高的性能。通过逐渐增大迭代器直到与另一个迭代器相等,总是能够计算出两个迭代器之间的距离,但是这会导致计算距离的时间开销变为 O(n)。随机访问迭代器具有一种特殊的特性,即它能够以常量时间计算出这个距离。
1.以序列容器作为被查找的键值对表
相比于 std::map 或它的表亲 std::set,有几个理由使得选择序列容器实现键值对表更好:序列容器消耗的内存比 map 少,它们的启动开销也更小。
2.std::find():功能如其名,O(n)时间开销
3.std::binary_search():不返回值
4.使用std::equal_range()的二分查找
5.使用std::lower_bound()的二分查找
6.自己编写二分查找法
7.使用strcmp()自己编写二分查找法
9.5 优化键值对散列表中的查找
唯一的开销是产生这个散列值的开销。
寻找高效的散列函数是实现散列表时的一个复杂环节。
1.使用std::unordered_map进行散列
2.对固定长度字符数组的键进行散列
3.以空字符结尾的字符串为键进行散列
大型散列表比基于二分查找的查找算法有更大的优势。
4.用自定义的散列表进行散列
如果能够像示例程序中那样提前知道表中的键值,那么一个非常简单的散列函数可能就足够了。
散列函数的“圣杯”是能够创建出无冲突、无多余空间的表的最小完美散列。
在本节的示例表中,26 条有效元素的首字母各不相同,而且它们是有序的,因此基于首字母的散列就是一个完美的最小散列。
9.6 斯特潘诺夫3 的抽象惩罚
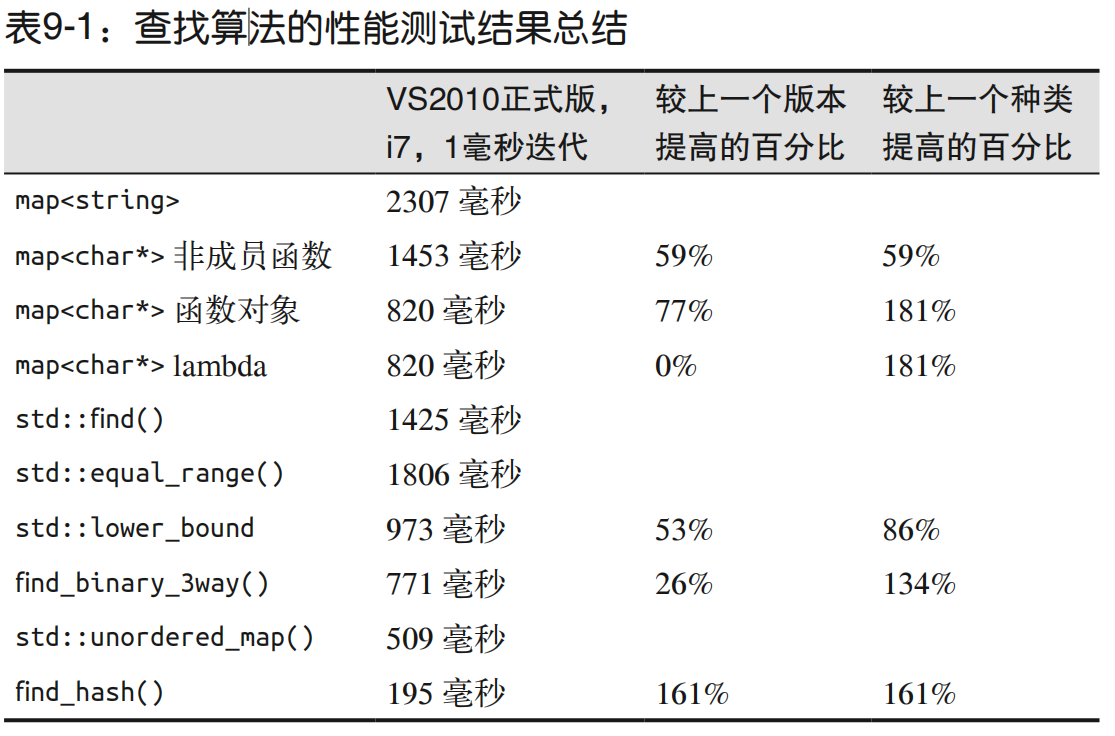
相对于手动编码的解决方案,斯特潘诺夫的抽象惩罚是通用解决方案无法避免的开销,它也是使用 C++ 标准库算法这样的能够提高生产力的工具的代价。
9.7 使用C++标准库优化排序
尽管 C++ 标准并没有明确指定使用了哪种排序算法,但它的定义允许使用快速排序的某个变种实现 std::sort 以及可以使用归并排序实现 std::stable_sort()。
std::sort中C++11 要求最差情况性能为 O(n log2n)。符合 C++11 标准的实现通常都是Timsort 或内省排序等混合排序。
第 10 章 优化数据结构
10.1 理解标准库容器
对于性能优化而言,有些特性格外重要,包括:
• 对于插入和删除操作的性能开销的大 O 标记的性能保证
• 向序列容器中添加元素具有分摊常时性能开销
• 具有精准地掌控容器的动态内存分配的能力
1.序列容器
序列容器 std::string、std::vector、std::deque、std::list 和 std::forward_list 中 元素的顺序与它们被插入的顺序相同。因此,每个容器都有一头一尾。所有的序列容器都能够插入元素。除了 std::forward_list 外,所有的序列容器都有一个具有常量时间性能开销的成员函数能够将元素推入至序列容器的末尾。不过,只有 std::deque、std::list 和std::forward_list 能够高效地将元素推入至序列容器的头部。
| 容器 | 支持推入头部 | 支持推入尾部 | 特点 |
|---|---|---|---|
std::vector | ❌ 不支持 | ✅ O(1) | 动态数组,尾部推入快,头部推入慢 |
std::deque | ✅ O(1) | ✅ O(1) | 双端队列,头尾插入都很快 |
std::string | ❌ 不支持 | ✅ O(1) | 字符串容器,尾部推入快 |
std::list | ✅ O(1) | ✅ O(1) | 双向链表,头尾插入都很快 |
std::forward_list | ✅ O(1) | ❌ 不支持 | 单向链表,头部插入快,尾部不支持 |
2.关联容器
所有的关联容器都会按照元素的某种属性上的顺序关系,而不是按照插入的顺序来保存元素。所有关联容器都提供了高效、具有次线性时间开销的方法来访问存储在它们中的元素。
就 实 现 上 而 言, 一 共 有 四 种 有序关联容器:std::map、std::multimap、std::set 和std::multiset。
C++11 又给我们带来了四种无序关联容器:std::unordered_map、std::unordered_multimap、
std::unordered_set 和 std::unordered_multiset。
3.测试标准库容器
10.2 std::vector与std::string
1.重新分配的性能影响
2.std::vector中的插入与删除
想要高效地填充一个 vector,请按照赋值、使用迭代器和 insert() 从另外一个容器插入元素、push_back() 和使用 insert() 在末尾插入元素的优先顺序选择最高效的方法。
3.遍历std::vector
迭代器版本耗时0.236 毫秒;使用 at() 函数的版本性能稍好,耗时 0.230 毫秒;但与插入操作一样,下标版本更加高效,只需 0.129 毫秒。在 Visual Studio 2010 中,下标版本快了 83%。
4.对std::vector排序
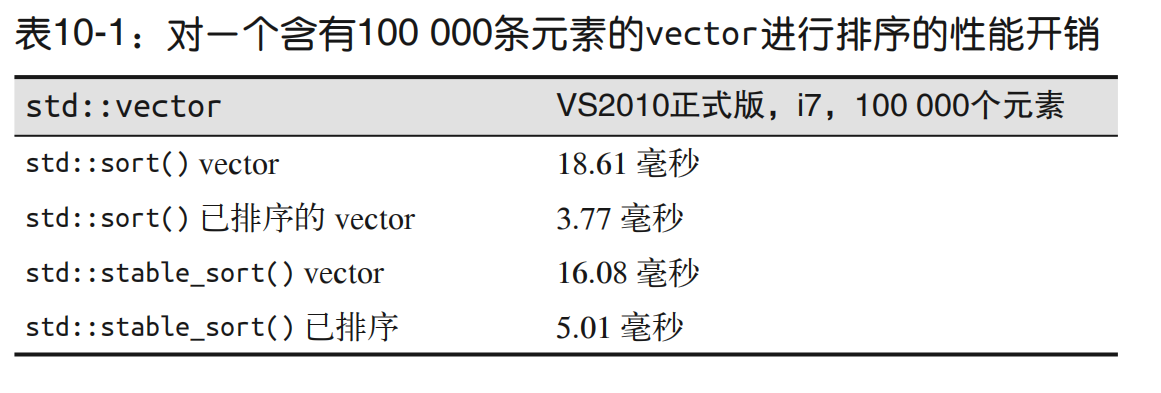
5.查找std::vector
10.3 std::deque
deque的这些操作的常量比例比 vector 大。对这些共通操作的性能测量结果表明,deque 的操作比 vector 相同的操作慢 3 到 10 倍。对 deque 而言,迭代、排序和查找相对来说是三个亮点,只是比 vector 慢了大约 30%。
获取 deque 中元素所需的两个间接引用会降低缓存局部性,而且更加频繁地调用内存管理器所产生的性能开销也比vector 的要大。
将一个元素加入到 deque 的任何一端都会导致最多调用内存分配器两次:一次是为新元素分配另一块存储元素的区域;另一次则可能没那么频繁,那就是扩展 deque 的内部数组。
1.std::deque中的插入和删除
2.遍历std::deque
3.对std::deque的排序
4.查找std::deque
10.4 std::list
尽管复制或是创建 std::list 的开销可能是 std::vector 的 10 倍,但是与 std::deque 相比,它还是具有竞争力的。将元素插入到 list 末尾的开销不足 vector 的两倍。遍历和排序 list 的开销只比 vector 多了 30%。对于我测试过的大部分操作,std::list 都比std::deque 的效率更高。
1.std::list中的插入和删除
2.遍历std::list中
3.对std::list排序
4.查找std::list
10.5 std::forward_list
1.std::forward_list中的插入和删除
2.遍历std::forward_list
3.查找std::forward_list
10.6 std::map与std::multimap
1.std::map中的插入和删除
带提示的插入永远不会比普通插入更慢。
优化“检查并更新”惯用法:如果程序程序能够得到第一次查找的结果,那么就能够将其作为对 insert() 的提示,将插入操作的时间开销提高到 O(1)。
std::pair<value_t, bool> result = table.insert(key, value);
if (result.second) {// k找到key的分支
}
else {// 没有找到key的分支
}iterator it = table.lower_bound(key);
if (it == table.end() || key < it->first) {// 找到key的分支table.insert(it, key, value);
}
else {// 没有找到key的分支it->second = value;
}
2.遍历std::map
3.对std::map排序
4.查找std::map

如果要一次性构造一个含有 100 000 条元素的表并会反复对其进行查找,那么使用 vector实现会更快。如果表中保存的元素会频繁地发生改变,例如对表进行插入操作或是删除操作,那么重排序基于 vector 的表可能会抵消它原本在查找性能上的优势。
10.7 std::set与std::multiset
10.8 std::unordered_map与std::unordered_multimap
尽管有多种方式能够实现散列表,但是只有采用了动态分配内存的骨干数组,然后在其中保存指向动态分配内存的节点组成的链表的桶的设计,才有可能符合标准定义。
unordered_map 的构造是昂贵的。它包含了为表中所有元素动态分配的节点,另外还有一个会随着表的增长定期重新分配的动态可变大小的桶数组(图 10-7)。因此,要想改善它的查找性能,需要消耗相当多的内存。每次桶数组重新分配时,迭代器都会失效。不过,只
有在删除元素时,指向元素节点的引用才会失效。
计算出的 size / buckets 比例称为负载系数(load factor)。负载系数大于 1.0 表示有些桶有一条多个元素链接而成的元素链,降低了查询这些键的性能(换言之,非完美散列)。在实际的散列表中,即使负载系数小于1.0,键之间的冲突也会导致形成元素链。负载系数小于 1.0 表示存在着未被使用,但却在unordered_map 的骨干数组中占用了存储空间的桶(换言之,非最小散列)。当负载系数小
于 1.0 时,(1 – 负载系数 ) 的值是空桶数量的下界,但是由于散列函数可能非完美,因此未使用的存储空间通常更多。
负载系数在 unordered_map 中是一个因变数。我们能够在程序中观察到它的值,但是无法在重新分配内存后直接设置或是预测它的值。当一条元素被插入到 unordered_map 中后,如果负载系数超过了程序指定的最大负载系数值,那么桶数组会被重新分配,所有的元素都被会重新计算散列值,这个值会被保存在新数组的桶中。
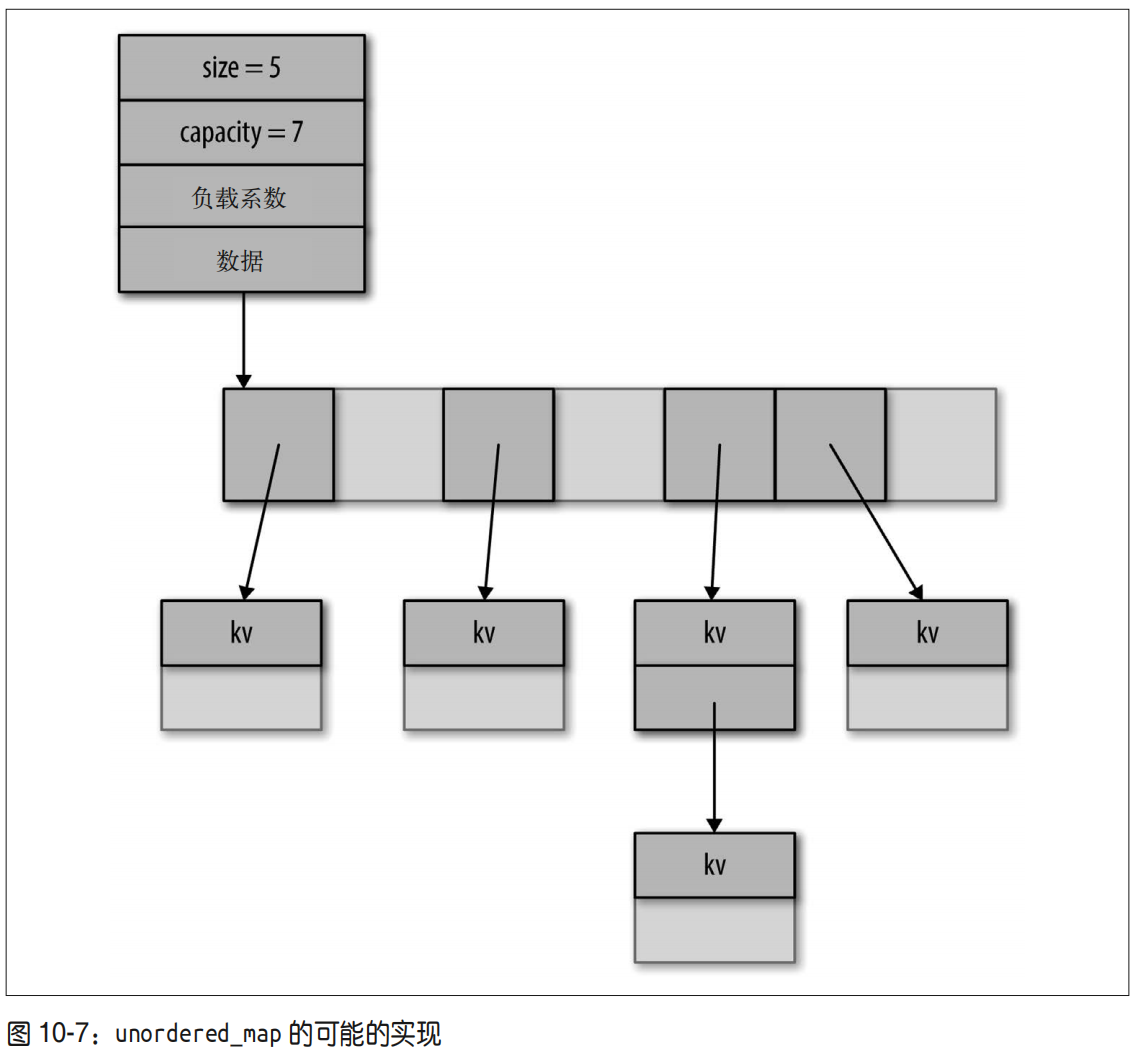
我们能够通过 unordered_map 的构造函数的参数指定桶的初始数量。除非容器大小超过了 ( 桶 * 负载系数 ),否则不会进行重新分配。程序可以通过调用 rehash() 成员函数增加 unordered_map 中桶的数量。我们可以通过调用 rehash(size_t n) 将桶的数量的最小值设置为 n,接着重新分配骨干数组,并通过将所有元素移动到新数组中的对应的桶中来重组表。如果 n 小于当前桶数量,rehash() 可能会,也可能不会减小表的大小并重新计算散列值。
调用 reserve(size_t n) 可以确保在重新分配骨干数组之前预留出足够的空间来保存 n 条元素。这等价于调用 rehash(ceil(n/max_load_factor()))。
调用 unordered_map 的 clear() 成员函数会清除所有的元素,并将所有存储空间返回给内存管理器。
与其他 C++ 标准库容器不同的是,std::unordered_map 通过为遍历桶和为遍历桶中的元素提供一个接口,暴露自己的实现结构。计算每个桶中的元素链的长度能够帮助我们发现散列函数的问题。
1.std::unordered_map中的插入与删除
2.遍历std::unordered_map
3.查找std::unordered_map
与 std::map 相比,unordered_map 的构建速度和查找速度都更快。unordered_map 的缺点在于它所使用的存储空间容量。如果是在一个存储空间极其受限的环境中,我们可能需要使用基于 std::vector 的更加紧凑的表;如果不是,我们就可以使用 unordered_map 得到更高的性能。
10.9 其他数据结构
boost::circular_buffer(http://www.boost.org/doc/libs/1_60_0/doc/html/circular_buffer.html)
在许多方面都与 std::deque 类似,但更加高效。
Boost.Container(http://www.boost.org/doc/libs/1_60_0/doc/html/container.html)
标准库容器的各种变种,包括一种稳定的 vector(一种发生重新分配也不会造成迭代器失效的 vector);一组作为 std::vector 的容器适配器实现的 map/multimap/set/multiset;一个长度可变但最大长度固定的静态 vector,以及一个当只有几个元素时具有最优行为的 vector。
dynamic_bitset(http://www.boost.org/doc/libs/1_60_0/libs/dynamic_bitset/dynamic_bitset.html)
看起来像是位组成的 vector。
Fusion(http://www.boost.org/doc/libs/1_60_0/libs/fusion/doc/html/)
元组上的容器和迭代器。
Boost 图形库(BGL,http://www.boost.org/doc/libs/1_60_0/libs/graph/doc/index.html)
适用于遍历图形的算法和数据结构。
boost.heap(http://bit.ly/b-heap/)
比简单 std::priority_queue 容器适配器具有更好性能和更微妙行为的优先队列。
Boost.Intrusive(http://www.boost.org/doc/libs/1_60_0/doc/html/intrusive.html)
提供了侵入式容器(依赖于显式地包含链接的节点类型的容器)。侵入容器的重点是提高热点代码的性能。这个库包含单向和双向链表、关联容器、无序关联容器和各种显式平衡树实现。在大多数容器中都加入了 make_shared、移动语义和 emplace() 成员函数,减少了对侵入式容器的需求。
boost.lockfree(http://www.boost.org/doc/libs/1_60_0/doc/html/lockfree.html)
无锁(lock-free)和无等待(wait-free)的队列和栈。
Boost.MultiIndex(http://www.boost.org/doc/libs/1_60_0/libs/multi_index/doc/index.html)
有多个具有不同行为的索引的容器。
第 11 章 优化I/O
11.1 读取文件的秘诀
1.创建一个吝啬的函数签名
作为一个库函数,这几种职责混合在一起使得调用方难以使用 file_reader() 函数。
2.缩短调用链
3.减少重新分配
4.更大的吞吐量——使用更大的输入缓冲区
增大 rdbuf 的大小可以让读取文件的性能提高几个百分点。
5.更大的吞吐量——一次读取一行
我测试到的最快的读取文件的方法是预先为字符串分配与文件大小相同的缓冲区,然后调用 std::streambuf::sgetn() 函数填充字符串缓冲区。
6.再次缩短函数调用链
std::istream 提供了一个 read() 成员函数,它能够将字符直接复制到缓冲区中。这个函数模仿了 Linux 上的底层 read() 函数和 Windows 上的底层 Readfile() 函数。如果std::istream::read() 直接连接到这个底层功能,绕过缓冲区和 C++ 流 I/O 的其他“负担” ,它应当能够更加高效。而且,如果能够一次读取整个文件,那么函数调用也会非常高效。
11.2 写文件
std::endl 会刷新输出。如果你并不打算在控制台上输出,那么它的开销是昂贵的。
11.3 从std::cin读取和向std::cout中写入
std::cout 是与 std::cin 和 stdout 捆绑在一起的。打破这种连接能够改善性能。
第 12 章 优化并发
12.1 复习并发
C++ 为共享内存的基于线程的并发提供了一个中规中矩的库。这绝不是 C++ 程序实现一个由若干协同工作的程序组成的系统的唯一方式。其他类型的并发库同样对 C++ 程序有影响。
1.并发概述
既有 C++ 内置的并发特性,也有通过库代码或操作系统提供的并发特性,但这并不表示某种并发模型优于其他模型。有些特性之所以内置在 C++ 中,是因为它们需要被内置,没有其他方式能够提供这种特性。
时间分割(time slicing)、虚拟化(Virtualization)、容器化(containerization)、对称式多处理(symmetric multiprocessing)、同步多线程(simultaneous multithreading)、多进程、分布式处理(distributed processing)、线程、任务
2.交叉执行
3.顺序一致性
4.竞争
5.同步
6.原子性
12.2 复习C++并发方式
与调用操作系统的原生并发方式相比,使用 C++ 并发特性的优势在于 C++ 的并发方式在不同的平台上具有一致性。
1.线程
**尽管我们能够直接使用 std::thread,但是使用基于它编写出更加优秀的工具的话,可能有助于提高生产率。**函数对象返回的任何值都会被忽略。函数对象抛出的异常会导致terminate() 被调用,使程序无条件地突然停止。这些限制让对 std::thread 的调用变得非常脆弱,就像是标准的制定人员不希望开发人员使用它一样。
2.promise和future
有一种编程惯用法是在发送线程中创建promise,然后使用 std::move(promise) 将其作为右值引用传递给接收线程,这样它的内容就会被移动到属于接收线程的 promise 中。开发人员可以使用 std::async() 来做到这一点。我们也可以通过指向发送线程的引用来传递 promise。
std::promise 和 std::future 是 C++11 引入的线程间通信机制,用来实现一个线程生成结果,另一个线程等待或获取这个结果的场景,常用于异步任务、线程池、任务调度等。
std::promise<T>用于设置一个值(或异常),
std::future<T>用于在另一个线程中等待并获取该值。
它们是一对配套工具,连接生产者(设置值的线程)和消费者(获取值的线程)
用法详解
1. std::promise<T> 的作用
- 用于在某个线程中设置结果值
- 成员函数:
set_value(T value):设置最终值set_exception(std::exception_ptr):设置异常get_future():获取关联的future对象
一旦设置了值或异常,future 就可以感知到。
2. std::future<T> 的作用
- 用于在另一个线程中异步获取结果
- 成员函数:
get():等待并返回结果(会阻塞)wait():阻塞直到结果就绪wait_for()/wait_until():带超时等待valid():是否仍然持有值
#include <iostream>
#include <future>
#include <thread>void producer(std::promise<int>& p) {std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟计算p.set_value(42); // 设置结果
}int main() {std::promise<int> p;std::future<int> f = p.get_future(); // 获取 future,供消费者使用std::thread t(producer, std::ref(p));std::cout << "Waiting for result...\n";int result = f.get(); // 阻塞等待结果std::cout << "Result: " << result << "\n";t.join();return 0;
}
3.异步任务
C++11 提供了将可调用对象包装为任务,并在可复用的线程上调用它的 async() 模板函数。async() 有点像“上帝函数”,它隐藏了线程池和任务队列的许多细节。
在 C++ 标准库 头文件中定义了任务。std::packaged_task 模板类能够包装任意的可调用对象(可以是函数指针、函数对象、lambda 表达式或是绑定表达式),使其能够被异步调用。packaged_task 自身也是一个可调用对象,它可以作为可调用对象参数传递给 std::thread。与其他可调用对象相比,任务的最大优点是一个任务能够在不突然终止程序的情况下抛出异常或返回值。任务的返回值或抛出的异常会被存储在一个可以通过std::future 对象访问的共享状态中。
std::packaged_task 是 C++11 提供的并发工具,它可以把一个可调用对象(函数、lambda、函数对象等)封装成一个任务,并且能够与 std::future 配合使用来获取任务执行结果或异常。
std::packaged_task是一个能绑定返回值的任务包装器,
它把普通函数变成一个“可以被执行一次”的任务,并允许异步获取其结果。
典型结构
std::packaged_task<ReturnType(Args...)> task(callable);
你可以:
- 把任务 传递给线程执行
- 通过
task.get_future()获取任务结果(std::future) - 在任何时候调用
task()来执行任务
#include <iostream>
#include <future>
#include <thread>int compute(int x) {return x * 2;
}int main() {// 1. 打包任务std::packaged_task<int(int)> task(compute);// 2. 获取 futurestd::future<int> result = task.get_future();// 3. 将任务交给线程执行std::thread t(std::move(task), 10); // compute(10)// 4. 获取返回值std::cout << "Result = " << result.get() << "\n";t.join();return 0;
}
库提供了一个基于任务的工具——std::async()。模板函数 std::async() 执行一个可调用对象参数,这个可调用参数可能是在新线程的上下文中被执行的。不过,std::async() 返回的是一个 std::future,它既能够保存一个返回值,也能够保存可调用对象抛出的异常。而且,有些实现方式可能会为了改善性能而选择在线程池外部分配std::async() 线程。
std::async 是 C++11 引入的标准库工具,用于启动异步任务并返回结果,本质上是一个高层封装的并发机制,相比 std::thread 更安全、更智能,能自动处理线程创建、返回值、异常传递等。
std::async就像 “带返回值的线程” 或 “线程自动管理器”,
启动一个任务,并通过std::future获取它的结果或异常。
基本语法
#include <future>
std::future<ReturnType> f = std::async(std::launch::policy, callable, args...);
参数说明:
| 参数 | 说明 |
|---|---|
std::launch::policy | 可选,指定执行策略(见下) |
callable | 要执行的函数或 lambda 表达式 |
args... | 函数的参数列表 |
| 返回值 | 一个 std::future<T>,用来获取结果 |
执行策略:std::launch
| 策略 | 含义 |
|---|---|
std::launch::async | 必定在新线程中执行 |
std::launch::deferred | 延迟执行,只有在 get() 或 wait() 时才在当前线程执行 |
| 默认(无策略) | 实现自行选择(可能是 async 或 deferred) |
#include <iostream>
#include <future>int square(int x) {return x * x;
}int main() {std::future<int> f = std::async(square, 5);std::cout << "Waiting for result...\n";int result = f.get(); // 阻塞直到结果返回std::cout << "Result: " << result << "\n";
}
4.互斥量
5.锁
6.条件变量
7.共享变量上的原子操作
8.展望未来的C++并发特性
协作多线程、SIMD 指令
12.3 优化多线程C++程序
1.用std::async替代std::thread
从性能优化的角度看,std::thread 有一个非常严重的问题,那就是每次调用都会启动一个新的软件线程。启动线程时,直接开销和间接开销都会使得这个操作非常昂贵。
并发编程的一项实用优化技巧是用复用线程取代在每次需要时创建新线程。
模板函数 std::async() 会运行线程上下文中的可调用对象,但是它的实现方式允许复用线程。从 C++ 标准来看,std::async() 可能是使用线程池的方式实现的。在 Windows 上,std::async() 明显快得多。
2.创建与核心数量一样多的可执行线程
3.实现任务队列和线程池
使用线程池(一种保持固定数量的永久线程的数据结构)和任务队列(一种存储待执行的计算的列表的数据结构),这些计算将由线程池中的线程负责执行。
4.在单独的线程中执行I/O
我们可以考虑将整个处理(包括读数据和解析数据)移动到一个单独的线程中。
5.没有同步的程序
编写没有显式同步的程序,有三个简单方式和一个困难方式。
- 面向事件编程
- 协程
- 消息传递
- 无锁编程(lock-free programming)
6.移除启动和停止代码
程序中有部分代码难以并发执行,那就是在 main() 得到控制权前执行的代码以及在main() 退出后执行的代码。
12.4 让同步更加高效
并发 C++ 程序比单线程程序要复杂得多,很难编写例子或是测试用例来得到令人信服的结果,因此我必须回到本节中的启发法上来。
1.减小临界区的范围
2.限制并发线程的数量
竞争临界区的理想线程数量是两个。
3.避免惊群
当有许多线程挂起在一个事件——例如只能服务一个线程的工作——上时就会发生所谓的惊群(thundering herd)现象。当发生这个事件时,所有的线程都会变为可运行状态,但由于只有几个核心,因此只有几个线程能够立即运行。
4.避免锁护送
当大量线程同步,挂起在某个资源或是临界区上时会发生锁护送(lock convoy)。这会导致额外的阻塞,因为它们都会试图立即继续进行处理,但是每次却只有一个线程能够继续处理,仿佛是在护送锁一样。
5.减少竞争
**注意内存和 I/O 都是资源:**在多线程系统中,内存管理器必须序列化对它的访问,否则它的数据结构会被破坏。磁盘驱动器一次只能读取一个地址。试图同时在多个文件上执行 I/O 操作会导致性能突然下降。
复制资源
分割资源
**细粒度锁:**要访问散列表的一条元素时,线程可以使用读锁锁住骨干数组,然后用一个读锁或写锁锁住元素。要插入或删除一条元素时,线程可以使用写锁锁住骨干数组。
无锁数据结构
资源的调度
6.不要在单核系统上繁忙等待
在单核处理器上,同步线程的唯一方法是调用操作系统的同步原语。繁忙等待太低效了。
7.不要永远等待
8.自己设计互斥量可能会低效
9.限制生产者输出队列的长度
12.5 并发库
Boost.Thread(http://www.boost.org/doc/libs/1_60_0/doc/html/thread.html)和 Boost.Coroutine
(http://www.boost.org/doc/libs/1_60_0/libs/coroutine/doc/html/index.html)
Boost 的线程库是对 C++17 标准库线程库的展望。其中有些部分现在仍然处于实验状态。 Boost.Coroutine 也处于实验状态。
POSIX 线程
POSIX 线程(pthreads)是一个跨平台的线程和同步原语库,它可能是最古老和使用最广泛的并发库了。POSIX 线程是 C 风格的函数库,提供了传统的并发能力。它有非常完整的文档资源,不仅适用于多种 Linux 发行版,也适用于 Windows(http://sourceware.org/pthreads-win32/)。
线程构建模块(TBB,http://www.threadingbuildingblocks.org/)
TBB 是一个有雄心壮志的、有良好文档记录的、具有模板特性的 C++ 线程 API。它提供了并行 for 循环,任务和线程池,并发容器,数据流消息传递类以及同步原语。TBB由英特尔开发,旨在提高多核处理器效率。现在它已经被开源了,同时支持 Windows和 Linux。它有良好的文档记录,其中还包括一本优秀书籍(James Reinders 编写的Intel Threading Building Blocks,O’Reilly 出版社)。
0mq(也拼写为 ZeroMQ,http://zeromq.org/)
0mq 是一个用于连接消息传递程序的通信库。它支持多种通信范式,追求高效与简约。以我的个人经验来看,0mq 是非常优秀的。0mq 是开源的,有良好的文档,获得了不少支持。0mq 还有一个称为 nanomsg 的改进版(http://www.nanomsg.org),它修正了 0mq中的一些问题。
消息传递接口(MPI,http://computing.llnl.gov/tutorials/mpi/)
MPI 是分布式计算机网络中的消息传递的一个 API 规范。它的实现类似于 C 风格的函数库。MPI 诞生于加利福尼亚的劳伦斯利弗莫尔国家实验室,该实验室长期与超级计算机集群和繁荣的高能物理联系在一起。MPI 具有良好的文档记录,具有老式的 20 世纪
80 年代的 DoD 风格。它既有支持 Linux 的实现,也有支持 Windows 的实现,其中还包括来自 Boost 的实现(http://www.boost.org/doc/libs/1_60_0/doc/html/mpi.html),但是这些实现并非都完整地覆盖了规范。
OpenMP(http://openmp.org)
OpenMP 是一款用于“使用 C/C++ 和 Fortran 语言进行多平台共享内存并行编程”的API。其用法是开发人员使用定义程序并行行为的编译指令装饰 C++ 程序。OpenMP 提供了一个擅长数值计算的细粒度的并发模型,而且它正在朝着 GPU 编程的方向发展。在 Linux 上,GCC 和 Clang 都支持 OpenMP;在 Windows 上 Visual C++ 支持 OpenMP。
C++ AMP(https://msdn.microsoft.com/en-us/library/hh265137.aspx)
C++ AMP 是一份关于设计 C++ 库在 GPU 设备上进行并行数据计算的开源规范。其中,来自于微软的版本会被解析为 DirectX 11 调用。
第 13 章 优化内存管理
内存管理器是 C++ 运行时系统中监视动态变量的内存分配情况的一组函数和数据结构。
**在进行性能优化时首先应该寻找其他能够优化的地方,这可能会比改善内存管理器更加有效果。**作为热点代码的内存管理器,其性能通常已经被榨干了。
对大型程序进行的研究表明,优化内存管理的性能改善效果范围是从微不足道至大约 30%。
为申请相同大小内存块的请求分配内存的内存管理器是很容易编写的,它的运行效率也很高。
同一个类的实例的分配内存的请求所申请的内存的大小是一样的。
可以在类级别重写 new() 运算符。
编写一个自定义的内存管理器或分配器可以提高程序性能,但相比于移除对内存管理器的调用等其他优化方法,它的效果没有那么明显。
13.1 复习C++内存管理器API
1.动态变量的生命周期
动态变量有五个唯一的生命阶段。最常见的 new 表达式的各种重载形式执行分配和放置生命阶段。在使用阶段后,delete 表达式会执行销毁和释放阶段。C++ 提供了单独管理每个阶段的方法。
2.内存管理函数分配和释放内存
new() 运算符对于性能优化非常重要,因为默认内存管理器的开销是昂贵的。在有些情况下,通过实现专门的运算符能够让程序非常高效地分配内存。
在我所知道的所有标准库实现中,new() 运算符都会调用malloc() 来进行实际的内存分配。通过替换 malloc() 和 free() 函数,一个程序能够全局地改变管理内存的方式。
3.new表达式构造动态变量
new 表达式的声明看起来如下:
::_optional new (placement-params)_optional (type) initializer_optional
或是:
::_optional new (placement-params)_optional type initializer_optional
1.不抛出异常的new表达式
如果 placement-params 中包含有关键字 std::nothrow,那么 new 表达式不会抛出 std::bad_alloc。它不会尝试构造对象,而是直接返回 nullptr。
2.定位放置new表达式执行定位放置处理而不进行分配
如果 placement-params 是一个指向已经存在的有效存储空间的指针,那么 new 表达式不会调用内存管理器,而只是简单地将 type 放置在指针所指向的内存地址,而且这块内存必须能够容下 type。
3.自定义定位放置new表达式——内存分配的腹地
如果 placement-params 是 std::nothrow 或单个指针以外的其他东西,那么这个 new 表达式就被称为自定义定位放置 new 表达式。
4.类专用new()运算符允许我们精准掌握内存分配
一个类能够通过提供这些运算的实现来精准地掌握对它自己的内存分配。如果在类中没有定义类专用 new() 运算符,那么全局 new() 运算符将会被使用。
如果一个类实现了自定义定位放置 new() 运算符,那么它必须实现相应的 delete() 运算符,否则全局 delete() 运算符就会被调用,这会带来未定义的而且通常都不希望看到的结果。
4.delete表达式处置动态变量
delete表达式的语法如下:
::_optional delete expression
或
::_optional delete [] expression
5.显式析构函数调用销毁动态变量
通过显式地调用析构函数,而不是使用 delete 表达式,能够只执行动态变量的析构,但不释放它的存储空间。
13.2 高性能内存管理器
默认情况下,所有申请存储空间的请求都会经过 ::operator new(),释放存储空间的请求都会经过 ::operator delete()。这些函数形成了 C++ 的默认内存管理器。
大多数 C++ 编译器所提供的 ::operator new() 都是 C 语言的 malloc() 函数的简单包装器。
对于小型嵌入式项目,实现自己的内存管理器并不是不可能的。
13.3 提供类专用内存管理器
如果一个类实现了 new() 运算符,那么当为该类申请内存时就不会调用全局 new() 运算符,而是调用这个 new() 运算符。
所有为某个类的实例申请分配内存的请求都会申请相同的字节大小。编写高效地处理分配相同大小内存的请求的内存管理器是很容易的。
1.分配固定大小内存的内存管理器
作为从自由存储区分配内存的一种方式,我们经常在嵌入式工程中看到这种分配固定大小内存块的内存管理器。
2.内存块分配区
3.添加一个类专用new()运算符
4.分配固定大小内存块的内存管理器的性能
5.分配固定大小内存块的内存管理器的变化形式
6.非线程安全的内存管理器是高效的
13.4 自定义标准库分配器
幸运的是,C++ 模板提供了一种定义每种容器所使用的内存管理器的机制。标准库容器可以接收一个 Allocator 参数,它具有与类专用 new() 运算符相同的自定义内存管理器的能力。
Allocator 是一个管理内存的模板类。作为被扩展的基础,一个分配器会做三件事情:从内存管理器中获取存储空间,返回存储空间给内存管理器,以及从相关联的分配器中复制构造出它自己。
对于编写自定义分配器来改善性能的开发人员而言,选择带有还是不带有局部状态的分配器取决于有多少类需要优化。如果只有一个类是热点代码,需要优化,那么选择一个无状态分配器更简单。如果开发人员希望优化多个类,那么选择带有局部状态的分配器会更加灵活。为许多容器都编写自定义分配器也许无法收回开发人员的时间投资。
1.最小C++11分配器
如果开发人员足够幸运,有一个完全符合 C++11 标准的编译器和标准库,那么他就可以提供一个只需要极少定义的最小分配器。
2.C++98分配器的其他定义
3.一个分配固定大小内存块的分配器
4.字符串的分配固定大小内存块的分配器
达式执行定位放置处理而不进行分配**
如果 placement-params 是一个指向已经存在的有效存储空间的指针,那么 new 表达式不会调用内存管理器,而只是简单地将 type 放置在指针所指向的内存地址,而且这块内存必须能够容下 type。
3.自定义定位放置new表达式——内存分配的腹地
如果 placement-params 是 std::nothrow 或单个指针以外的其他东西,那么这个 new 表达式就被称为自定义定位放置 new 表达式。
4.类专用new()运算符允许我们精准掌握内存分配
一个类能够通过提供这些运算的实现来精准地掌握对它自己的内存分配。如果在类中没有定义类专用 new() 运算符,那么全局 new() 运算符将会被使用。
如果一个类实现了自定义定位放置 new() 运算符,那么它必须实现相应的 delete() 运算符,否则全局 delete() 运算符就会被调用,这会带来未定义的而且通常都不希望看到的结果。
4.delete表达式处置动态变量
delete表达式的语法如下:
::_optional delete expression
或
::_optional delete [] expression
5.显式析构函数调用销毁动态变量
通过显式地调用析构函数,而不是使用 delete 表达式,能够只执行动态变量的析构,但不释放它的存储空间。
13.2 高性能内存管理器
默认情况下,所有申请存储空间的请求都会经过 ::operator new(),释放存储空间的请求都会经过 ::operator delete()。这些函数形成了 C++ 的默认内存管理器。
大多数 C++ 编译器所提供的 ::operator new() 都是 C 语言的 malloc() 函数的简单包装器。
对于小型嵌入式项目,实现自己的内存管理器并不是不可能的。
13.3 提供类专用内存管理器
如果一个类实现了 new() 运算符,那么当为该类申请内存时就不会调用全局 new() 运算符,而是调用这个 new() 运算符。
所有为某个类的实例申请分配内存的请求都会申请相同的字节大小。编写高效地处理分配相同大小内存的请求的内存管理器是很容易的。
1.分配固定大小内存的内存管理器
作为从自由存储区分配内存的一种方式,我们经常在嵌入式工程中看到这种分配固定大小内存块的内存管理器。
2.内存块分配区
3.添加一个类专用new()运算符
4.分配固定大小内存块的内存管理器的性能
5.分配固定大小内存块的内存管理器的变化形式
6.非线程安全的内存管理器是高效的
13.4 自定义标准库分配器
幸运的是,C++ 模板提供了一种定义每种容器所使用的内存管理器的机制。标准库容器可以接收一个 Allocator 参数,它具有与类专用 new() 运算符相同的自定义内存管理器的能力。
Allocator 是一个管理内存的模板类。作为被扩展的基础,一个分配器会做三件事情:从内存管理器中获取存储空间,返回存储空间给内存管理器,以及从相关联的分配器中复制构造出它自己。
对于编写自定义分配器来改善性能的开发人员而言,选择带有还是不带有局部状态的分配器取决于有多少类需要优化。如果只有一个类是热点代码,需要优化,那么选择一个无状态分配器更简单。如果开发人员希望优化多个类,那么选择带有局部状态的分配器会更加灵活。为许多容器都编写自定义分配器也许无法收回开发人员的时间投资。
1.最小C++11分配器
如果开发人员足够幸运,有一个完全符合 C++11 标准的编译器和标准库,那么他就可以提供一个只需要极少定义的最小分配器。