Linux 进程调度与管理:从内核管理到调度机制的深度解析
文章目录
- 引言
- 一、进程基础:概念与核心数据结构
- 1.1 进程的本质:程序的动态化身
- 1.2 进程控制块(PCB):内核管理的灵魂
- 1.2.1 链表节点嵌入
- 1.2.2 链表操作宏
- 1.2.3 全局链表管理
- 1.3 进程查看与系统调用
- 1.3.1 通过系统调用获取进程标识符
- 1.3.2 通过系统调用创建子进程
- 二、进程生命周期:状态与特殊场景
- 2.1 进程的几个状态
- 2.2 进程状态查看
- 2.3 僵尸进程与孤儿进程:资源管理的两面性
- 2.3.1 僵尸进程
- a. 什么是僵尸进程?
- b. 僵尸进程的成因
- c. 僵尸进程的危害
- d. 如何识别僵尸进程?
- 2.3.2 孤儿进程
- a. 什么是孤儿进程?
- b. 孤儿进程与僵尸进程的对比
- c. 如何识别孤儿进程?
- 三、进程优先级与调度策略
- 3.1 基本概念
- 3.2 优先级体系:PRI 与 NI 的协同
- 3.3 调度的核心矛盾:竞争、独立、并行与并发
- 四、进程切换:内核级上下文管理
- 4.1 进程切换的核心步骤
- 4.2 切换背后的 “原子操作”
- 4.3 进程切换的开销
- 五、Linux 2.6 内核调度队列:O (1) 算法的经典实现
- 5.1 调度队列架构:双向链表与位图的精妙组合
- 5.2 active指针和expired指针
引言
在操作系统的庞大体系中,进程是当之无愧的核心枢纽 —— 它是程序从代码到动态执行的 “生命载体”,是内核调度资源的最小单元,更是理解操作系统如何协调硬件与软件的关键切入点。从进程控制块(PCB)对进程状态的精细描述,到调度队列对 CPU 资源的高效分配,每一个机制都蕴含着计算机科学的精妙设计。
本文将深入进程的 “内核视角”,解析task_struct如何通过双向链表编织成复杂的进程网络,探讨僵尸进程与孤儿进程的资源管理哲学,揭示优先级调度与进程切换的底层逻辑。无论你是想夯实操作系统基础的学习者,还是渴望深入内核机制的开发者,都能从中窥见计算机系统如何通过进程管理实现 “有序的并发奇迹”。
一、进程基础:概念与核心数据结构
1.1 进程的本质:程序的动态化身
- 《操作系统概念》中指出:进程是程序的执行实例。
- 内核视角:资源分配的最小单元。
1.2 进程控制块(PCB):内核管理的灵魂
- 进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- Linux下的PCB是
task_struct
struct task_struct {// 1. 进程标识与状态pid_t pid; // 进程唯一 IDpid_t ppid; // 父进程 IDvolatile long state; // 状态(如 TASK_RUNNING, TASK_INTERRUPTIBLE)struct task_struct *parent; // 父进程指针// 2. 内存与资源管理struct mm_struct *mm; // 虚拟内存描述(页表、地址空间)struct files_struct *files; // 文件描述符表(打开的文件)struct fs_struct *fs; // 文件系统上下文(根目录、当前目录)// 3. CPU 上下文(执行状态)struct thread_struct thread; // 寄存器、栈等线程信息(Linux 中进程与线程统一)unsigned long thread_saved_pc; // 程序计数器(PC)// 4. 调度与优先级int prio; // 动态优先级(影响 CPU 调度)struct sched_entity se; // CFS 调度器实体(公平调度)// 5. 信号与 IPCsigset_t blocked; // 阻塞的信号集合struct sigpending pending; // 待处理信号struct sem_undo *semundo; // 信号量 undo 操作(IPC 回滚)// 6. 其他元数据char comm[TASK_COMM_LEN]; // 进程名(如 "bash")struct list_head tasks; // 进程链表(内核维护的进程列表)
};
在运行时,它会被加载到内存中。
组织进程
Linux是通过双向循环链表的形式来组织 task_struct 的。它是通过在 task_struct 中嵌入了链表节点来实现双向循环链表的。
1.2.1 链表节点嵌入
list_head结构体
内核定义通用双向链表节点:
struct list_head {struct list_head *next, *prev; // 双向指针
};
task_struct中的链表成员
每个进程的task_struct包含list_head类型的成员(如tasks),作为链表节点:
struct task_struct {struct list_head tasks; // 连接到全局进程链表// 其他成员(如PID、状态、内存管理等)
};
1.2.2 链表操作宏
通过一个宏来计算 task_struct 的起始地址。
接下来就有意思了,你都知道 task_struct 的起始地址了,然后通过对它的设计,我们是能够保证它在一定的偏移量上是用于保存什么的结构。因而可以利用偏移量和强转指针类型实现类型无关的链表操作。
1.2.3 全局链表管理
- 进程链表头
内核以init_task(0 号进程的task_struct)为头节点,维护全局进程链表。所有进程通过tasks成员链接到该链表,形成进程树。 - 多链表共存
task_struct可通过不同的list_head成员属于多个链表(如:run_list:就绪队列(CPU 调度时使用)。wait_list:等待队列(I/O 阻塞时使用)。
),实现进程在不同状态(运行、就绪、阻塞)下的动态管理。
1.3 进程查看与系统调用
-
进程的信息可以通过
/proc系统文件夹查看
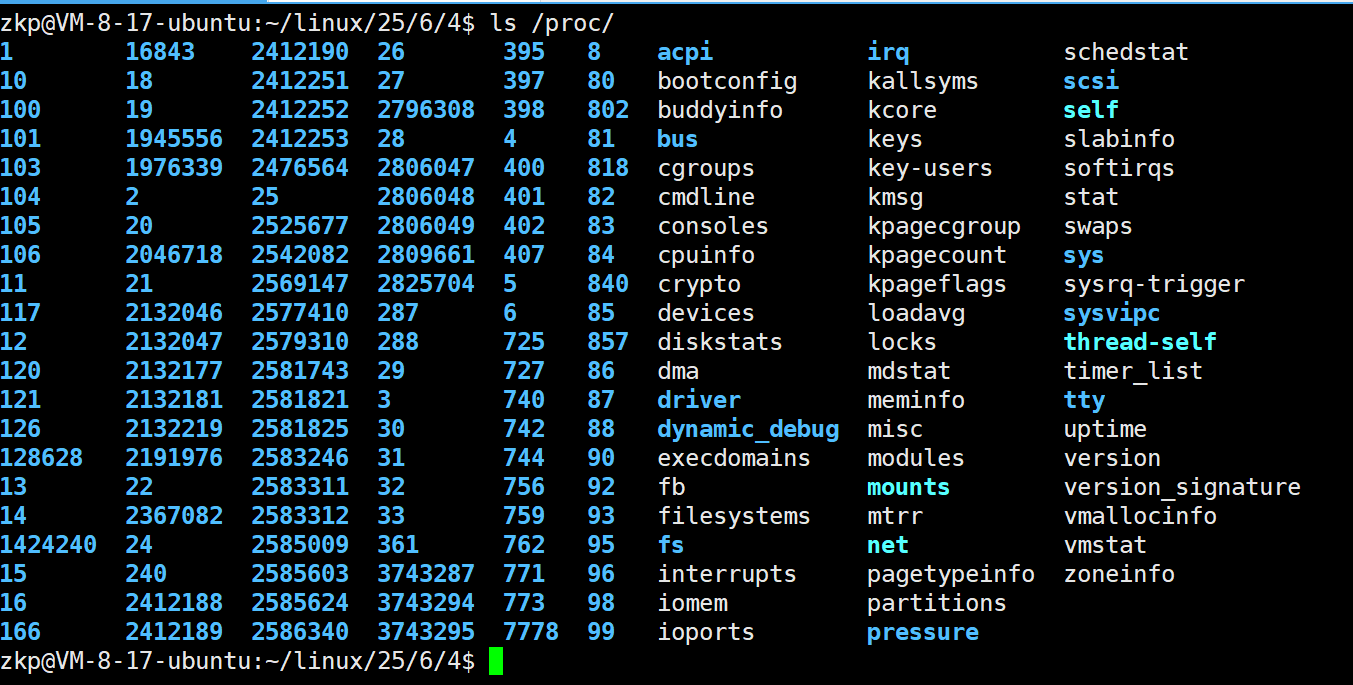
如:要获取PID为1的进程信息,你需要查看/proc/1这个文件夹。 -
大多数进程信息也可以使用 top 、ps 这些用户级工具来获取
ps aux | grep test | grep -v grep
我们这里让程序一直休眠,查看一下进程

使用另一个终端进行查看:

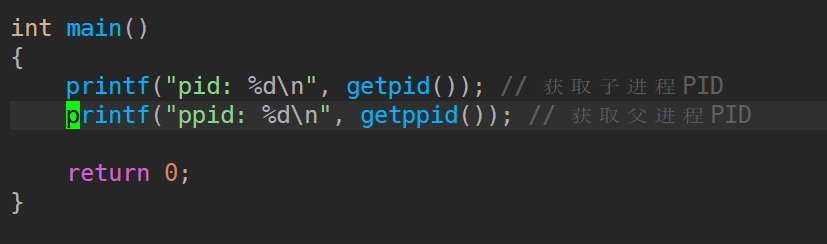
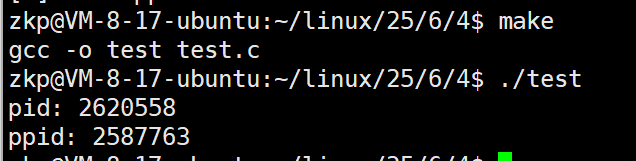
1.3.1 通过系统调用获取进程标识符
1.3.2 通过系统调用创建子进程
这里我们需要知道:
fork虽然是一次调用,但是它有两个返回值- 父子进程代码共享,数据各自开辟空间,私有一份(采用写实拷贝)
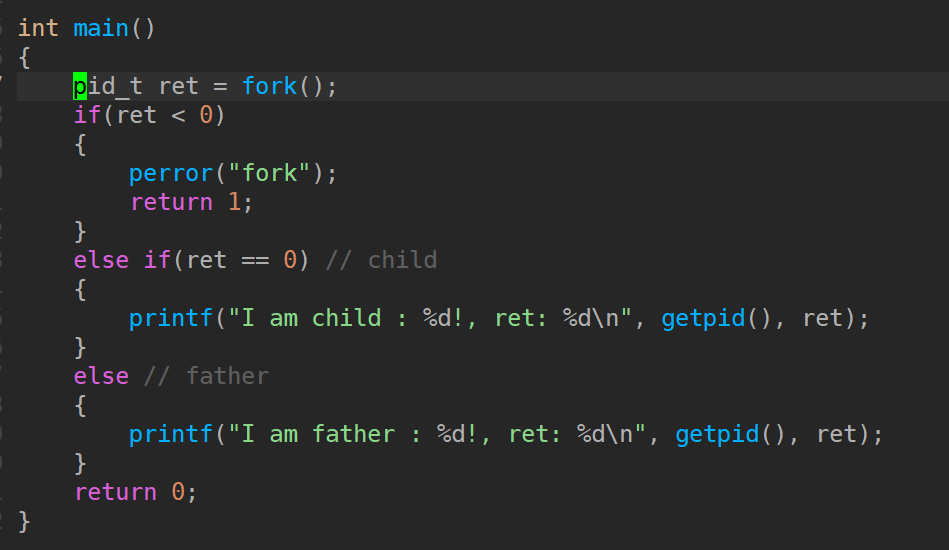

可以看到,父进程ret接收到的返回值和子进程的 pid 是相同的!但是子进程的ret为 0。
为什么会有两个返回值呢?
- 父进程返回值
- 父进程调用
fork进入内核态之后,内核复制出子进程并分配新pid。 - 父进程从内核态返回时,直接返回子进程的
pid,因此父进程fork的返回值是子进程的PID
- 父进程调用
- 子进程返回值
- 我们前面提到过,子进程在创建的时候,代码和父进程共享,但是它会复制父进程的数据,但内核会做一件事:把子进程用来存储返回值的寄存器,强制设置为0,所以子进程从内核态返回到用户态时,
fork的返回值为 0,以便于识别子进程。
- 我们前面提到过,子进程在创建的时候,代码和父进程共享,但是它会复制父进程的数据,但内核会做一件事:把子进程用来存储返回值的寄存器,强制设置为0,所以子进程从内核态返回到用户态时,
还有一个问题:
我们这里的 ret 不是一个变量吗?为什么它能同时让 else if(ret == 0) 和 else 成立呢?
这个有了上面父子进程的返回值不同解释起来也简单。
本质是:fork 让父子进程成为两个独立执行流,而前面说了,子进程的数据是拷贝自父进程的,但是内核对子进程 fork 的返回值进行了修改,所以看似 “一个变量满足多个分支”,实际是 “两个进程、两个变量副本”,所以能让父进程走 else、子进程走 else if ,产生 “同时成立” 的错觉 。
二、进程生命周期:状态与特殊场景
2.1 进程的几个状态
进程标准状态
- R(Running)
运行态:进程正在 CPU 上执行。 - S(Sleeping)
睡眠态 / 阻塞态:进程因等待资源(如 I/O 完成)而暂停执行。
细分可能包括:- D(Disk Sleep):不可中断睡眠,通常因等待磁盘 I/O 而阻塞,无法被信号唤醒。
- S(Interruptible Sleep):可中断睡眠,能被信号唤醒。
- T(Stopped)
暂停态 / 停止态:进程被暂停(如通过SIGSTOP信号),保留当前状态,可恢复。 - Z(Zombie)
僵尸态:进程已终止,但父进程尚未回收其退出状态(PCB 残留)。 - X(Dead)
死亡态:进程已完全终止,资源被彻底释放(此状态通常不可见,因进程已消失)。
补充状态(非标准但常见)
- I(Idle)
空闲态:某些系统中用于表示内核线程或空闲进程。 - W(Waiting)
等待态:与阻塞态类似,等待特定事件。 - K(Killed)
被杀死:进程接收到终止信号(如SIGKILL),正在被清理。 - t (Tracing Stop)
调试追踪暂停态(因调试器 ptrace 追踪触发,如 gdb 调试时遇到断点)。
2.2 进程状态查看
ps aux # 侧重资源监控(CPU / 内存占用)
ps axj # 侧重进程关系(父子 / 组 / 会话结构)
- a:显示一个终端所有的进程,包括其他用户的进程。
- x:显示没有控制终端的进程,例如后台运行的守护进程。
- j:显示进程归属的进程组ID、会话ID、父进程ID,以及与作业控制相关的信息
- u:以用户为中心的格式显示进程信息,提供进程的详细信息,如用户、CPU和内存使用情况等
2.3 僵尸进程与孤儿进程:资源管理的两面性
2.3.1 僵尸进程
a. 什么是僵尸进程?
- 定义:
子进程已经正常终止运行,但父进程尚未调用wait()或waitpid()系统调用来回收其进程控制块(PCB,Process Control Block)和退出状态时,子进程会暂时处于僵尸状态(Zombie State),简称 僵尸进程。 - 状态标识:
在 Linux 中,通过ps命令查看进程时,僵尸进程的STAT字段会显示为Z(Zombie 的首字母),例如:
PID PPID STAT COMMAND
1234 5678 Z+ [defunct]
- 僵尸进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态码。
- 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入 Z 状态。
b. 僵尸进程的成因
- 父子进程的生命周期差异:
- 父进程创建子进程后,子进程先于父进程结束运行。
- 子进程终止时,内核会保留其退出状态和少量资源(如 PID、运行时间等),直到父进程调用
wait()获取这些信息。 - 若父进程未及时调用
wait(),子进程就会变成僵尸进程。
- 常见场景:
- 父进程逻辑缺陷:父进程未编写回收子进程的代码(如未使用
wait())。 - 父进程阻塞或死循环:父进程因等待其他资源而无法执行
wait()。
- 父进程逻辑缺陷:父进程未编写回收子进程的代码(如未使用
c. 僵尸进程的危害
- 占用进程号(PID)资源:
- 系统中 PID 的数量有限(通常默认最大值为 32768 或更高),大量僵尸进程会耗尽 PID 资源,导致系统无法创建新进程。
- 影响进程监控:
僵尸进程虽不占用 CPU、内存等运行资源,但会干扰管理员对进程状态的判断(如通过 ps 命令看到无效进程)。 - 潜在的程序 bug 信号:
- 僵尸进程通常是程序中资源管理不当的表现,可能预示代码存在逻辑漏洞(如未处理子进程退出)。
d. 如何识别僵尸进程?
- 使用
ps命令过滤:- 输出中
STAT为Z的进程即为僵尸进程,PPID是其父进程的 PID。
- 输出中
ps aux | grep Z
# 或
ps -e -o stat,ppid,pid,cmd | grep '^Z'
- 查看进程状态文件:
- 若显示
State: Z (zombie),则为僵尸进程。
- 若显示
cat /proc/[PID]/status | grep State
2.3.2 孤儿进程
孤儿进程(Orphan Process) 是操作系统中与 僵尸进程 相对的概念,同样涉及父子进程的生命周期管理。
a. 什么是孤儿进程?
- 定义:
当 父进程先于子进程终止,且子进程尚未结束时,子进程会被 init 进程(PID=1) 接管,成为 孤儿进程。- init 进程是系统启动后的第一个进程,负责管理所有孤儿进程的生命周期。
- 核心特点:
孤儿进程的 父进程 PID(PPID)会被重置为 1(即 init 进程的 PID),由 init 进程自动回收其资源,因此 不会产生资源泄漏问题。
b. 孤儿进程与僵尸进程的对比
| 特性 | 孤儿进程 | 僵尸进程 |
|---|---|---|
| 成因 | 父进程先于子进程终止 | 子进程先终止,父进程未回收 |
| 父进程 PID | 被重置为 1(init 进程) | 保持原父进程 PID |
| 资源管理 | init 进程自动回收资源 | 父进程需手动回收,否则残留 |
| 危害 | 无(资源会被正常释放) | 可能耗尽 PID 资源 |
| 状态标识 | 正常运行状态(如 S、R) | 状态为 Z(僵尸状态) |
c. 如何识别孤儿进程?
- 使用
ps命令查看进程的父进程 PID(PPID):- 若某进程的
PPID为 1,且状态正常(非 Z),则为孤儿进程。
- 若某进程的
ps -ef | grep [子进程关键词]
# 或
ps aux --forest | grep PID
UID PID PPID C STIME TTY TIME CMD
user 12345 1 0 10:00 ? 00:00:00 [orphan_process]
- 通过
/proc文件系统查看:
cat /proc/[PID]/status | grep PPid
# 输出示例:PPid: 1
三、进程优先级与调度策略
3.1 基本概念
- 优先级本质
进程优先级是一个 数值参数,用于标识进程获取 CPU 时间的 相对重要性。优先级越高的进程,越容易被 CPU 调度执行。 - 核心目标
- 系统稳定性:确保关键系统进程(如内存管理、设备驱动)优先运行。
- 响应性:提升交互式进程(如终端、GUI 应用)的响应速度,改善用户体验。
- 资源公平性:避免低优先级进程长时间饥饿(Starvation)。
查看系统进程
ps -l

其中:
- UID:代表执行者的身份
- PID:代表这个进程的代号
- PPID:代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- PRI:代表这个进程可被执行的优先级,其值越小越早被执行
- NI:代表这个进程的nice值
3.2 优先级体系:PRI 与 NI 的协同
- RPI 很好理解,就和比赛排名一样,数值越低,优先级越高
- NI 也就是 nice 值,表示进程可被执行的优先级的修正数值,范围为 [-20, 19],默认为 0
- PRI(new)= PRI(old)+ nice
查看进程优先级
top
输入 top 进入:
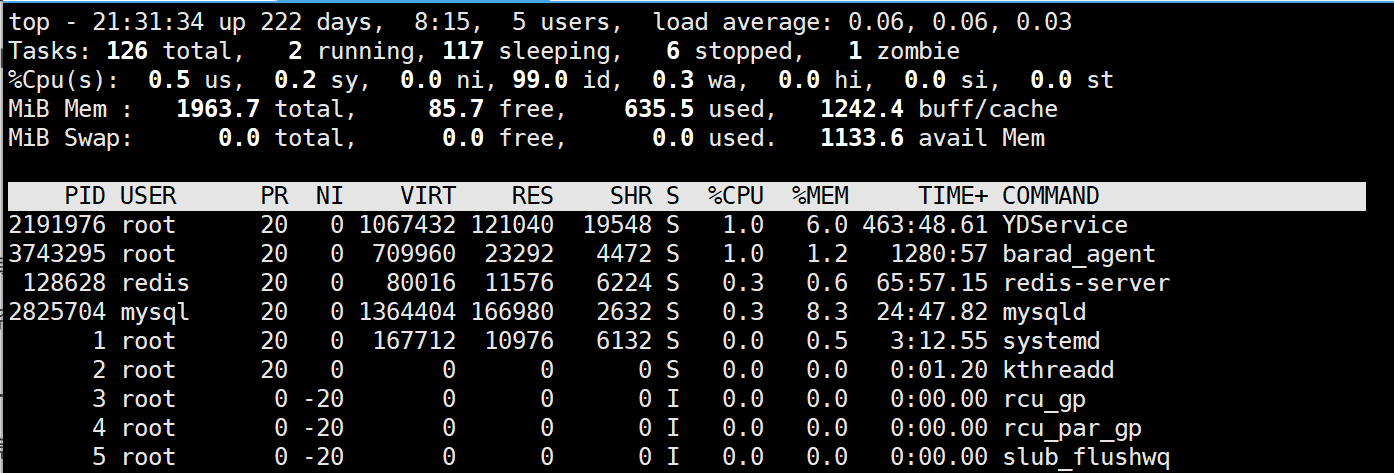
在这个界面按 r -> 输入进程PID -> 输入nice值就能修改已存在进程的 nice 值了
3.3 调度的核心矛盾:竞争、独立、并行与并发
在操作系统中,资源是有限的,但是又存在很多的进程,这就导致了存在以下几种关系:
- 竞争:
指多个进程因争夺 共享资源(如 CPU、内存、文件、I/O 设备等)而产生的相互制约关系。 - 独立:
指进程在逻辑上 互不干扰,各自拥有独立的运行环境和资源,执行结果仅取决于自身逻辑,与其他进程无关。 - 并行:
指 多个进程在同一时刻 同时执行,依赖 多核 CPU 或多处理器 硬件,每个任务分配到独立的计算单元(如 CPU 核心)。 - 并发:
指 多个进程或线程在同一时间段内交替执行,通过 CPU 时间片轮转(如分时系统)或事件驱动机制,在宏观上呈现 “同时运行” 的效果,但微观上同一时刻仅执行一个任务。
四、进程切换:内核级上下文管理
在操作系统中,进程切换(Process Switch) 是实现多任务并发执行的核心机制。当操作系统需要从一个进程切换到另一个进程时,会执行一系列复杂的操作,以确保上下文环境的正确保存和恢复。
4.1 进程切换的核心步骤
- 保存当前进程的上下文
- 硬件上下文:
- CPU 寄存器(如通用寄存器、程序计数器 PC、栈指针 SP)。
- 处理器状态(如标志位、特权级别)。
- 软件上下文:
- 进程控制块(PCB)中的信息,包括进程状态、内存管理信息(页表)、打开文件列表等。
- 硬件上下文:
- 更新进程状态
将当前进程的状态从 运行态 改为 就绪态 或 阻塞态,并将其 PCB 插入相应队列(就绪队列或阻塞队列)。 - 选择新进程
调度器根据调度算法(如优先级调度、轮转调度)从就绪队列中选择一个新进程。 - 恢复新进程的上下文
- 从新进程的 PCB 中加载寄存器值、内存映射等信息。
- 更新内存管理单元(MMU)的页表,切换虚拟地址空间。
- 执行上下文切换
通过 特权指令(如 x86 的iret)将控制权转移到新进程的程序计数器(PC)指向的指令处,开始执行新进程。
4.2 切换背后的 “原子操作”
进程切换通常由以下事件触发:
- 时间片耗尽:
进程在 CPU 上执行的时间超过分配的时间片(如 Linux 默认 10-20ms),调度器强制切换。 - 进程阻塞:
进程因等待资源(如 I/O、锁、信号量)主动进入阻塞状态,释放 CPU。 - 高优先级进程就绪:
新的高优先级进程进入就绪队列,抢占当前低优先级进程。 - 进程终止:
进程执行完毕或被强制终止,释放 CPU 资源。 - 系统调用 / 中断:
进程执行系统调用(如read())或发生硬件中断(如时钟中断),CPU 从用户态切换到内核态,由内核决定是否切换进程。
4.3 进程切换的开销
进程切换会带来一定的性能开销,主要包括:
- 上下文保存 / 恢复开销:
寄存器读写、PCB 操作等指令执行需要时间。 - 内存访问开销:
切换页表会导致 TLB(Translation Lookaside Buffer)失效,后续内存访问需重新查询页表,增加延迟。 - CPU 缓存失效:
新进程的指令和数据可能不在 CPU 缓存中,导致缓存缺失(Cache Miss),降低执行效率。
五、Linux 2.6 内核调度队列:O (1) 算法的经典实现
5.1 调度队列架构:双向链表与位图的精妙组合
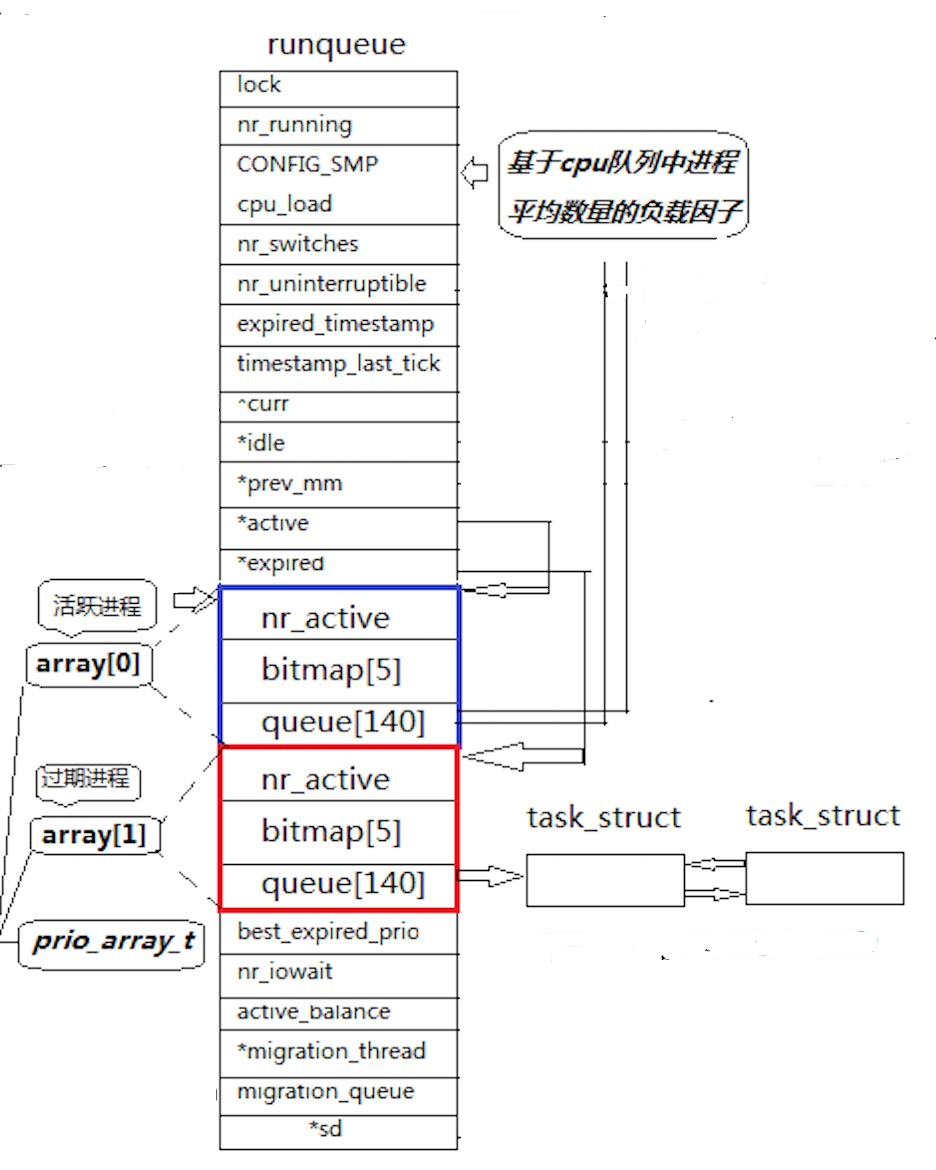
这张图是 Linux 2.6 内核进程调度队列(runqueue)的结构示意图
下面来解释一下这张图:
一个单核 CPU 维护着一个 runqueue
-
运行队列(runqueue)组成
- 元数据:包含锁(
lock)、运行进程数(nr_running)、CPU 负载因子(cpu_load)等,用于调度控制和状态统计。 - 双队列设计:
- 活跃队列(
array[0],蓝色框):存储时间片未耗尽的进程,通过nr_active(活跃进程数)、bitmap[5](位掩码,快速标记非空优先级队列)、queue[140](140 个优先级链表,同优先级进程按 FIFO 排列)管理。 - 过期队列(
array[1],红色框):存储时间片耗尽的进程,结构与活跃队列相同,通过active和expired指针轮换(活跃队列为空时交换,重新分配时间片,避免进程饥饿)。
- 活跃队列(
- 元数据:包含锁(
-
优先级与队列管理
- 优先级范围:
0~139(0~99实时优先级,100~139普通优先级,对应nice值-20~19)。 queue[140]:每个优先级对应一个双向链表,进程按优先级分组,同优先级 FIFO 调度。bitmap[5]:5 个 32 位掩码(共 160 位),快速定位最高优先级非空队列(位运算实现 O (1) 查找,提升调度效率)。
- 优先级范围:
-
任务结构(task_struct)
- 进程通过
run_list节点嵌入queue的双向链表中,支持快速插入 / 删除(如进程状态切换、时间片耗尽时的队列迁移)。
- 进程通过
-
O (1) 调度算法核心
- 优先级范围:0~139(共 140 个优先级,对应
queue[140]数组,每个下标代表一个优先级)。 - 位图结构:
bitmap[5]由 5 个unsigned long(共 160 位)组成,每一位对应一个优先级队列的空满状态。例如:- 优先级p对应
bitmap[p/32]的第p%32位(如优先级 5 →bitmap[0]第 5 位,优先级 33 →bitmap[1]第 1 位)。
- 优先级p对应
- 优先级范围:0~139(共 140 个优先级,对应
简单总结:
queue[140]是指一共有这么多优先级队列。然后有进程进入运行队列,就把对应的bitmap置为非0。在进程调度时,通过位运算找出第一个为1的比特位,再从对应优先级的优先级队列中选择进程进行调度,直到这个优先级队列为空,且前面优先级均为空,才在下一个非空优先级队列中选择进程进行调度。
5.2 active指针和expired指针
上面对于这两个指针只是简单的提到了一句,这里还需要做些补充
active指针永远指向活动队列expired指针永远指向过期队列
活动队列的调度逻辑
-
调度流程:
- 调度器通过
active->bitmap快速定位最高优先级非空队列(如idx=5),取出队首进程执行。 - 进程时间片耗尽后,从
active->queue[idx]移除,加入expired->queue[idx],并标记expired->bitmap[idx]为非空。
- 调度器通过
-
关键特性:
- 只出不进:active队列在调度期间不接收新进程,确保原有进程按优先级有序执行。
- 动态减少:随着调度进行,
active->nr_active递减,expired->nr_active递增。
过期队列的辅助作用
- 进程管理:
- 新进程直接加入
expired队列。 - 时间片耗尽的进程从
active队列移入expired队列。 - 只进不出:
expired队列在active队列未空时不参与调度,仅积累进程。
- 新进程直接加入
- 时间片重置:
- 当
expired队列切换为active队列时,所有进程重新分配时间片(基于优先级计算),确保公平性
- 当
指针交换的触发条件
- 主动触发:
- 当
active->nr_active减至 0 时,内核自动执行swap(&active, &expired),交换指针指向。 - 交换后,原
expired队列成为新的active队列,原active队列变为expired队列。
- 当
- 被动触发:
- 若
active队列未空但存在更高优先级进程插入expired队列,调度器会优先处理active队列,直到其为空后再交换指针。
- 若