AI基础认知
一、认识LLM
LLM 通常是指大型语言模型(Large Language Model)。它是一种基于深度学习技术的人工智能基础模型,具有以下特点:
-
基于深度学习:一般基于 Transformer技术架构的神经网络,通过自注意力机制捕捉输入序列中的长距离依赖关系,实现对文本的全局理解。
-
处理自然语言:能够执行问答、文本生成、翻译、对话等多种自然语言处理任务,是生成式 AI 的一种形式。
-
参数规模庞大:为了理解自然语言,需要将自然语言拆分为最小粒度的参数(Tokens),一个大模型通常包含几十上百亿甚至数千亿参数。
LLM通过在海量文本数据上进行训练,学习语言的模式、结构和语义关联,逐步具备理解和生成自然语言的能力。其核心目标是通过概率建模,预测下一个词语或序列,最终生成连贯且符合上下文的文本。常见的LLM 有 GPT 系列、LLaMA、Mistral、BERT 等
二、认识RAG
RAG 即检索增强生成(Retrieval - Augmented Generation),是一种结合信息检索技术与语言生成模型的人工智能技术,用于增强大语言模型在处理知识密集型任务时的能力。
产生背景:
大语言模型输出结果可能不完全正确甚至错误,原因包括训练数据可能包含错误信息、过度泛化推理以及对知识的理解存在局限性等。此外,大模型还存在知识落后、输出难以解释、输出不确定等问题,RAG 正是为解决这些问题而诞生的一种优化方案。
工作原理:
检索:从预先建立的知识库中检索与问题相关的信息。首先将文本分割成较小的片段,使用文本嵌入模型将这些片段转换成向量,并存储在向量数据库中。当用户输入查询问题时,使用相同的文本嵌入模型将问题转换成向量,然后在向量数据库中检索与问题向量最相似的知识库片段,根据相似度得分对检索到的结果进行排序,选择最相关的片段作为后续生成的输入。
增强:将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。
生成:生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成符合用户需求的回答。
三、认识MCP
在 AI 中,MCP 指模型上下文协议(Model Context Protocol)。它是由 Anthropic 在 2024 年 11 月推出的一个开放协议,旨在统一 LLM 应用与外部数据源和工具之间的通信协议,为 AI 开发提供标准化的上下文交互方式。
核心功能
上下文共享:通过 MCP,可以将文件内容、数据库记录等 “背景资料” 提供给 AI,让 AI 的回答更准确。
工具调用:MCP 能让模型使用各种工具,如读写文件、调用 API 等。
灵活组合:它可以把不同的服务和组件串联起来,搭建各种 AI 工作流,简单高效。
安全保障:数据通过本地服务器传输,可保障敏感信息不会被传到云端泄露,保护隐私。
四、认识Agent
AI 中的 Agent 即智能体,是指能够在特定环境中自主执行任务或作出决策的实体。
关键特点
自主性:能在无直接外部干预下控制自身行为和内部状态,独立操作并决策。
社会能力:可与其他智能体(包括人类)交互和沟通,理解意图并在多智能体系统中协同工作。
反应性:能感知环境并对变化快速反应,根据传感器输入或外部事件调整行为。
主动性:不仅响应环境,还主动采取行动实现设计目标,能预测未来事件并采取预防措施。
智能性:使用人工智能技术,如机器学习、自然语言处理、计算机视觉等,提高决策和问题解决能力。
五、大模型中token的理解
1、token的定义
Token 是通过算法将文本(如单词、子词、字符甚至字节)分割后的最小单元,模型通过处理这些单元实现对语言的理解和生成。Token可能是一个字符、一个单词、或单词的一部分(如前缀/后缀),甚至标点符号。token的内容和数量由分词器(Tokenizer)决定:分词规则基于训练前的数据统计和算法(如Byte-Pair Encoding, BPE)。
2、Token的作用
模型的“输入语言”:模型无法直接理解文本,因此需要将Token转为向量进行处理。
如:句子 “Hello, world!” 经分词后得到 Token 序列:[“Hello”, “,”, “world”, “!”],对应 Token ID 为[101, 102, 103, 104]。
模型通过计算这些数字序列的向量表示实现语义建模。
上下文窗口的限制:模型的上下文长度以Token数量计算(如GPT-4的“32K Token”限制)。
示例:1个英文句子 ≈ 5-10个Token,1个中文句子 ≈ 2-5个Token(因中文更紧凑)。
六、模型的上下文窗口长度
在大模型(如 GPT、Claude、LLaMA 等)中,8K、32K通常指模型的上下文窗口长度(Context Window Size),即模型单次处理的最大 Token 数(包括输入和输出),8K、32K等单位是token,1K 等于 1024 个 Token,所以 8K 意味着模型支持的上下文窗口约为 8192 个 Token,32K 则表示上下文窗口约为 32768 个 Token。这一指标直接影响模型能够理解和处理的文本长度,是评估模型能力的关键参数。
什么是上下文窗口:
定义:模型在一次调用中能够处理的最大 Token 数量(包括输入和输出)。
作用:决定了模型可以 “记住” 和关联的文本范围,例如:
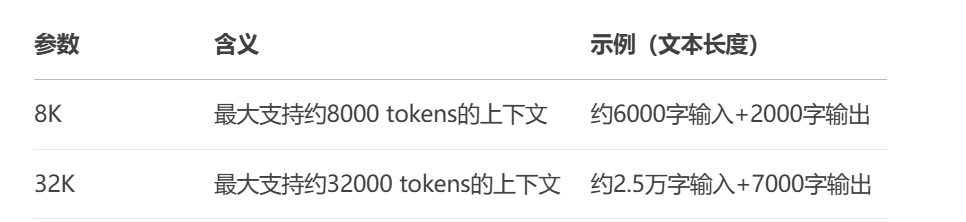
不同上下文窗口长度应用场景不一样,如:
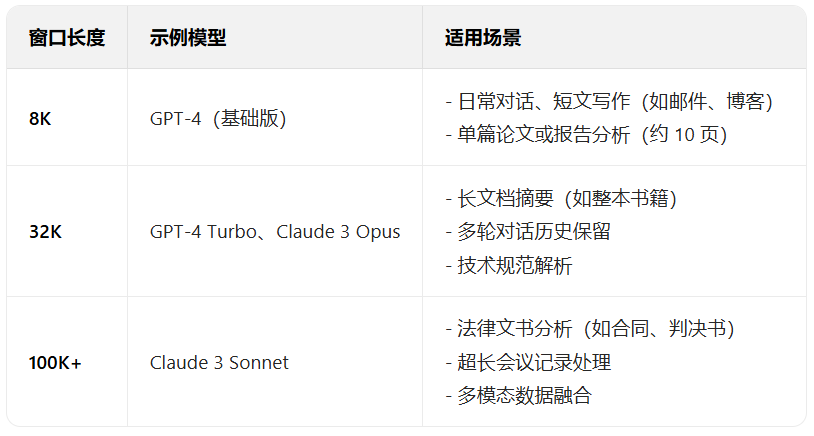
七、向量和向量库
1、什么是向量?
本质:向量是将文本转化为高维空间中的数值数组(如 [0.1, -0.3, 0.5, …]),每个维度代表文本的一种语义特征(如情感、主题、语法角色等)。
作用:通过向量,计算机可以用数学方法(如向量距离、相似度计算)衡量文本之间的语义关联,解决 “语义鸿沟” 问题(如 “计算机” 和 “电脑” 含义相近,向量距离应较近)。
2、如何生成?
大模型(如 Transformer 架构)通过编码器将输入的各类数据(如文本、图像、音频等)转化为向量,这个过程称为嵌入(Embedding),简称:EMB。
也就是通过模型的嵌入层(Embedding Layer)将输入转换为向量,例如:
OpenAI的text-embedding-ada-002
开源的BERT、Sentence-BERT
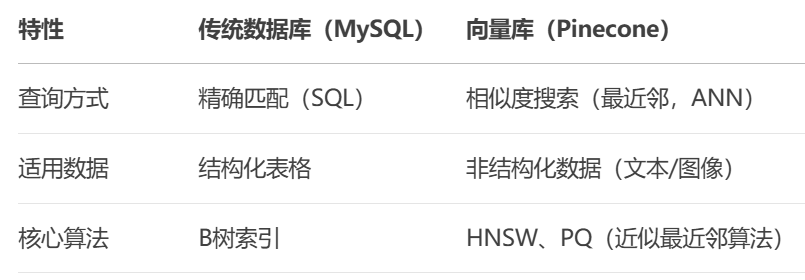
3、向量库(Vector Database)
基本概念:专门用于存储、检索高维向量的数据库,支持相似性搜索(Similarity Search)。
与传统数据库比较,向量库存在如下差异:
八、多模态
在大模型中,“多模态” 是指模型能够同时处理和理解多种不同类型的数据模态,如文本、图像、音频、视频等。在支持多模态的大模型中,输入的就不一定是文本或者其它的某一类;
九、FC、MCP、A2A
在大模型中,FC、MCP、A2A 是三种不同通信模式。
FC(Function Calling,函数调用技术):由 OpenAI 推动,允许大语言模型(LLM)通过解析用户问题,判断是否调用预定义的外部函数或 API,从而实现与外部系统交互,扩展模型能力。例如模型可通过函数调用获取实时天气、股票行情等外部信息,将自然语言转换为 API 调用,最初在 GPT-3.5 和 GPT-4 模型上实现。
MCP(Model Context Protocol,模型上下文协议):由 Anthropic 公司于 2024 年 11 月推出的标准化开放通信协议。旨在为大型语言模型提供标准化接口,实现与外部数据源和工具的无缝集成,让 AI 模型能动态发现并调用外部服务,无需预先定义固定代码。它基于 HTTP (S) 协议,通过 JSON 格式描述功能能力,具有模型无关性,任何具备兼容运行时的 LLM 均可使用,且与 API 网关及企业级认证标准兼容。
A2A(Agent-to-Agent,智能体到智能体协议):由 Google 推出的开放智能体通信协议,旨在标准化不同 AI 智能体之间的通信与协作。可让不同平台和框架之间的 AI 智能体进行通信和协作,无需考虑底层技术,使多个专门的智能体能够发现、沟通并协作完成任务,每个智能体专注于某一方面,多个智能体可构成流水线共同完成任务,还支持多模态通信。