大模型分布式训练笔记(基于accelerate+deepspeed分布式训练解决方案)
文章目录
- 一、分布式训练基础与环境配置
- (1)分布式训练简介
- (2)如何进行分布式训练
- (3)分布式训练环境配置
- 二、数据并行-原理与实战(pytorch框架的nn.DataParallel)
- 1)data parallel-数据并行 原理及流程
- 2)data parallel-数据并行 训练实战
- 3)data parallel-数据并行 推理对比
- 三、分布式数据并行Distributed DataParallel-原理与实战(俗称ddp)
- 1)distributed data parrallel并行原理
- 2)分布式训练中的一些基本概念
- 3)分布式训练中的通信基本概念
- 4)distributed data parallel 训练实战(DDP)
- 四、Accelerate基础入门
- 1)Accelerate基本介绍
- 2)基于AccelerateDDP代码介绍
- 3)Accelerate启动命令介绍
- 五、Accelerate使用进阶
- 1)Accelerate混合精度训练
- 2)Accelerate梯度累积功能
- 3)Accelerate实验记录功能
- 4)Accelerate模型保存功能
- 5)Accelerate断点续训练功能
- 6)前五个功能后的总代码
- 六、Accelerate集成Deepspeed
- 1)Deepspeed介绍
- 2)Accelerate + Deepspeed代码实战
一、分布式训练基础与环境配置
(1)分布式训练简介
- 背景介绍
海量的训练数据给大模型训练带来了海量的计算需求,主要体现在变大的模型对显存的依赖逐渐加剧 - 单卡场景如何解决显存问题
1)可训练参数量降低
①参数高效微调--PEFT
②prompt-Tuning、Prefix-Tuning、Lora等
2)参数精度降低
①低精度模型训练--Bitsandbytes
②半精度、INT8、NF4
- 分布式训练简介
指的是系统或计算任务被分布到多个独立的节点或计算资源上进行处理,而不是集中在单个节点或计算机上
(2)如何进行分布式训练
-
分布式训练方法
1)数据并行:Data Parrallel,DP
原理:每个GPU上都复制一份完整模型,但是每个GPU上训练的数据不同。要求每张卡内都可以完整执行训练过程
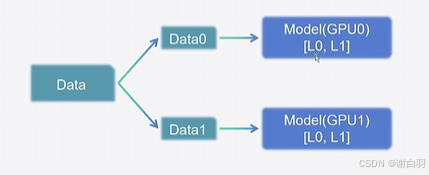
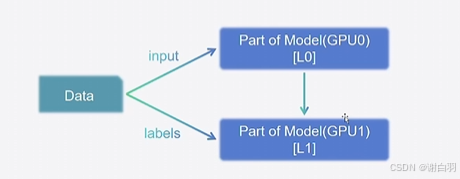
2)流水并行:Pipeline Parrallel,PP
原理:将模型按层拆开,每个GPU上包含部分的层,保证能够正常训练。不要求每张卡内都能完整执行训练过程
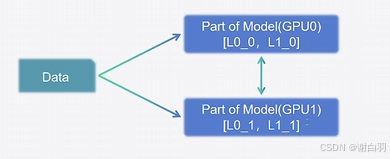
3)张量并行:Tensor Parrallel,TP
原理:将模型每层的权重拆开,对于一份权重,每个GPU上各包含一部分,保证能够正常训练。不要求每张卡内都可以完整执行训练过程
-
分布式训练方式选择
①单卡可以完成训练流程的模型:
做法:每个GPU上都复制一份完整模型,但是每个GPU上训练的数据不同
组合:数据并行
②单卡无法完成训练流程的模型
做法:
1)做法一:流水并行,将模型按层拆开训练,每个GPU包含一部分层
2)做法二:张量并行,将模型权重拆开,每个GPU包含一部分权重
③混合策略
做法:数据并行+流水并行+张量并行 -
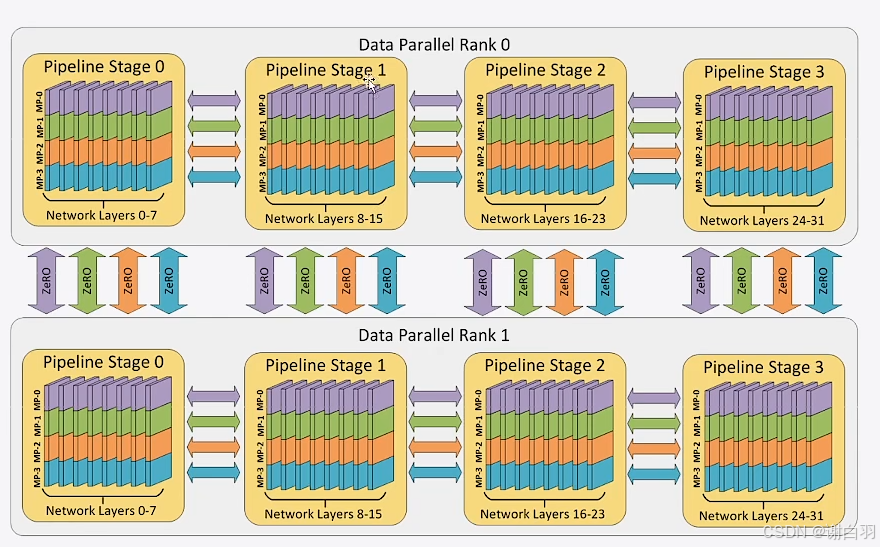
3D并行举例
2路数据并行,上下各一路
4路流水并行(0-7层的权重每个方块都被拆成了4份分开训练)
4路张量并行(0~7、8~15、16~23、24~31)
(3)分布式训练环境配置
1)服务器显卡租赁平台:趋动云、AutoDL
2)环境安装:
①设置pypi源:
进入下图的路径修改源

http://mirrors.aliyun.com/pypi/simple/
修改后如图下

安装aacelerate库
pip install transformers==4.36.2 accelerate==0.26.1 evaluate datasets
- 以下是趋动云的环境配置举例
①选择pytorch2.1.1作为环境的docker镜像
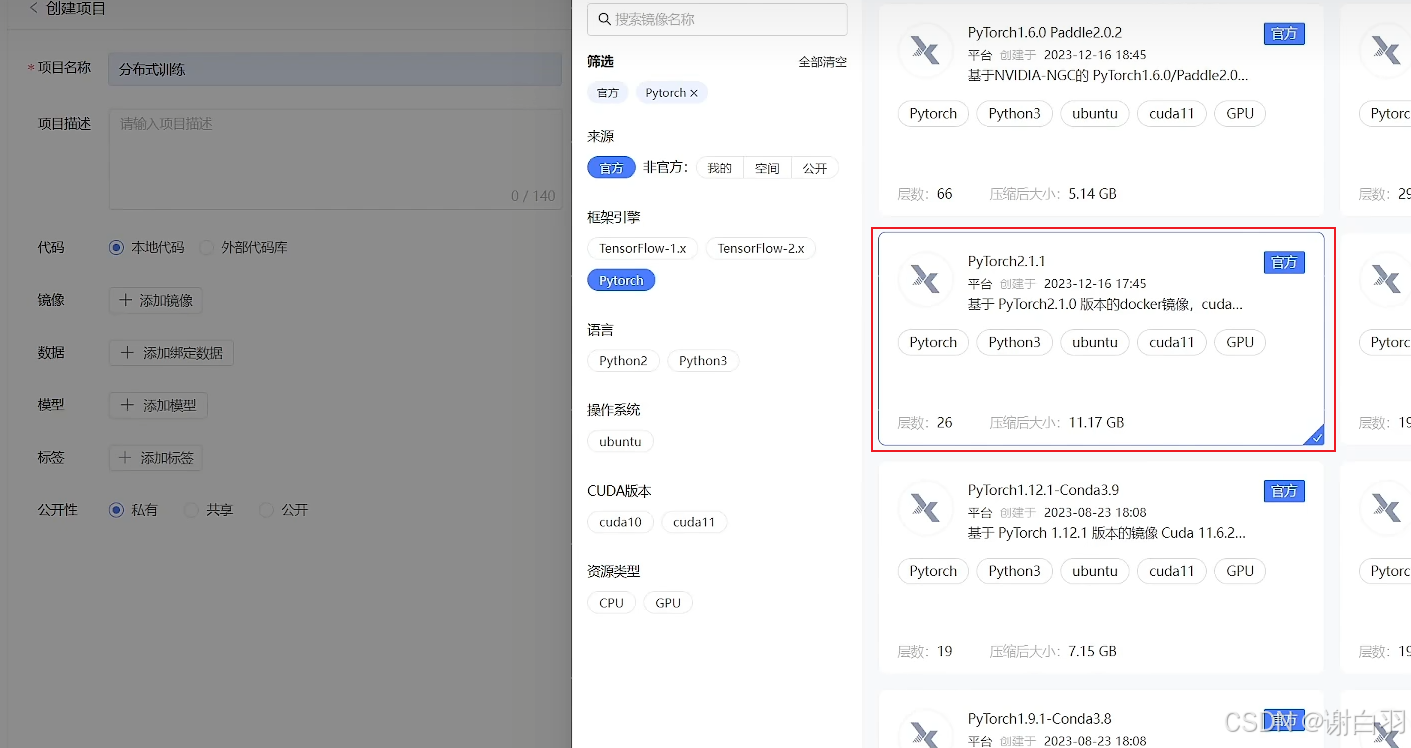
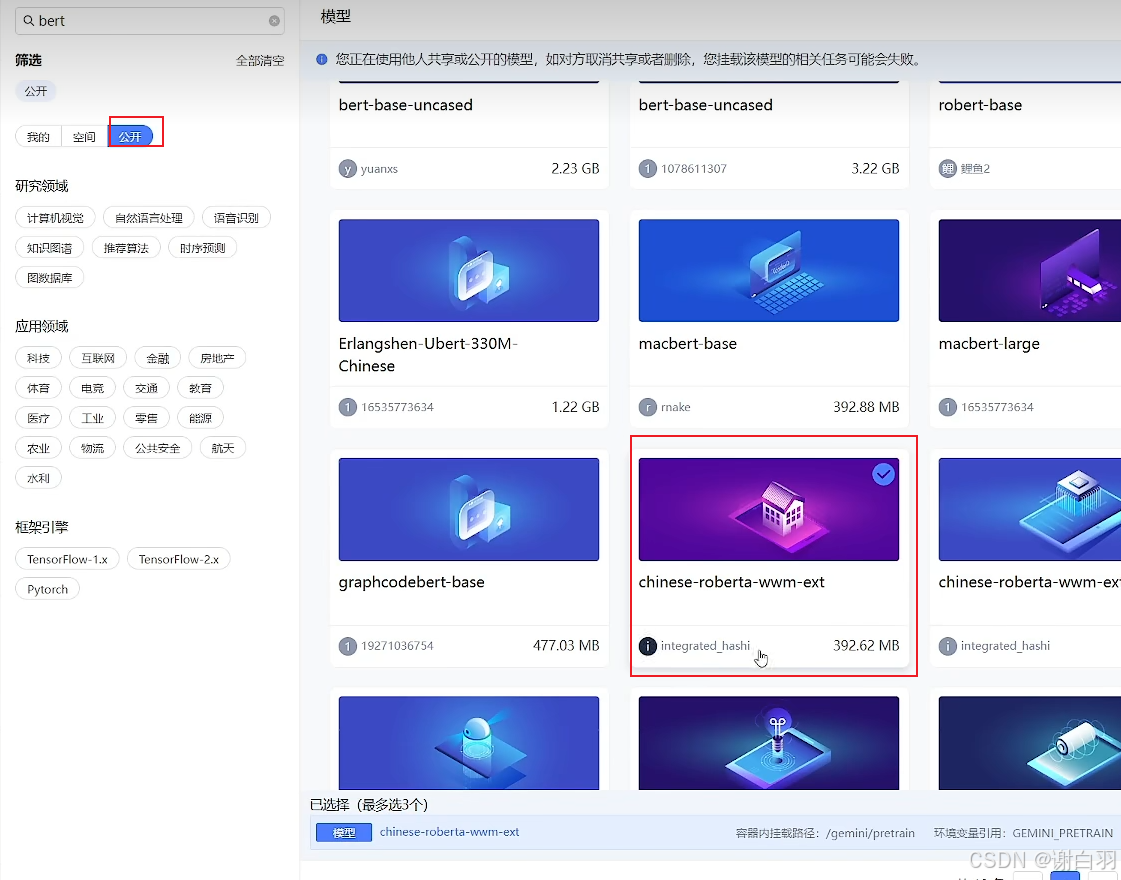
②任选公开模型,这里举例选择的bert
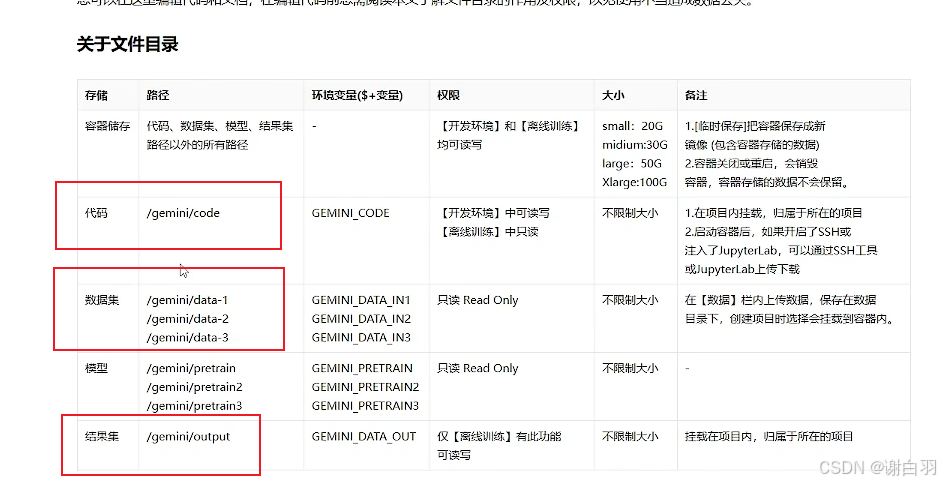
可以看到代码、数据集、结果集在云平台的存放位置
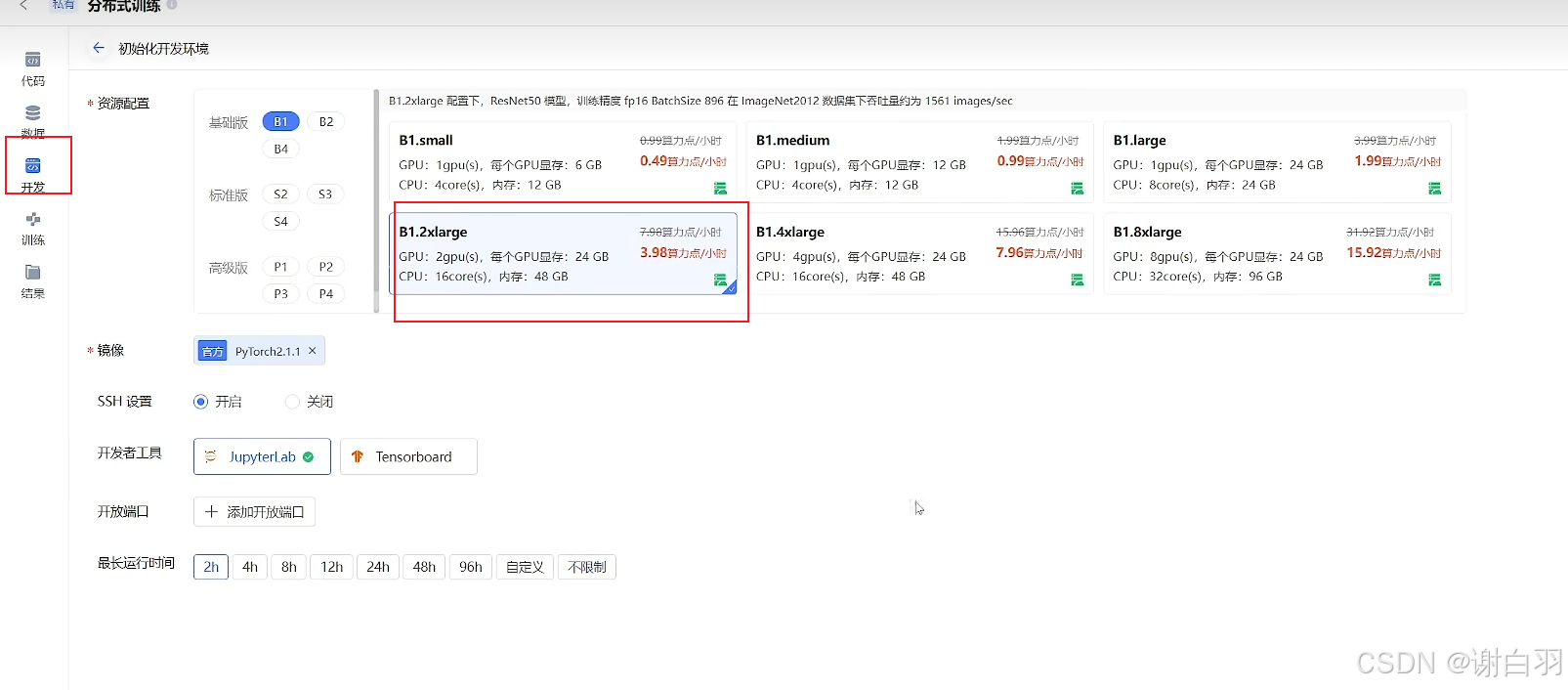
③开发上传代码要选择不同显卡资源配置,这里选择2张显卡的B1款
-
测试代码运行
1)报错解决:import apex报错
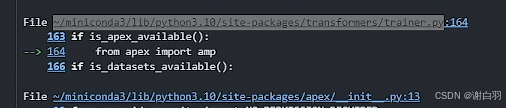
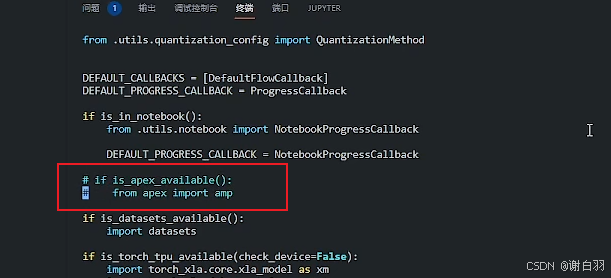
解决方法:
①进入路径

②修改源码,注释掉这两行
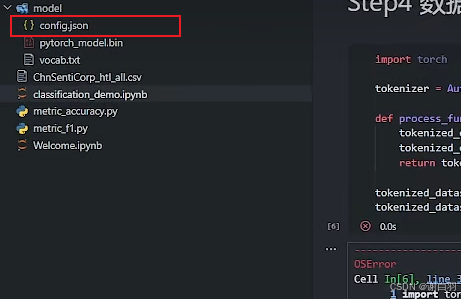
2)json文件报错,因为老版文件是config.json,新版本是bert_config.json,为了兼容老版本需要换成新的tokenlizer,又因为是只读路径,不支持修改,所以复制到另外个目录去修改

修改名字为config.json
-
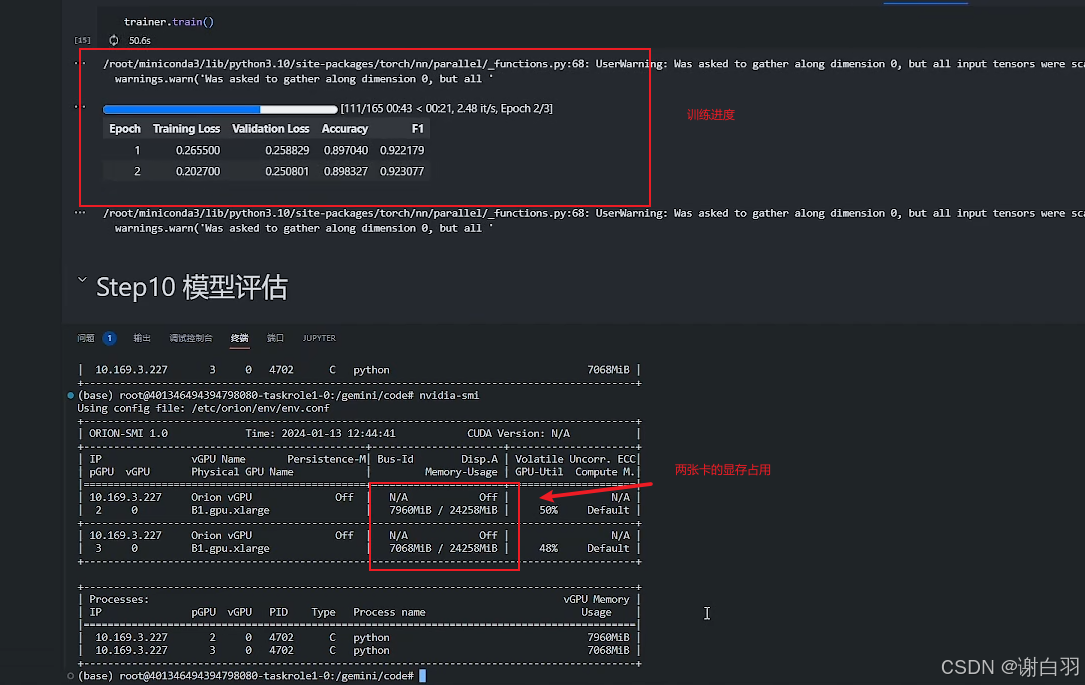
训练代码
检测显卡可以看到两张显卡都占用了显存
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
from datasets import load_dataset
import torch
import evaluate#1、load dataset
dataset = load_dataset("csv", data_files="./ChnSetiCorp_htl_all.csv",split="train")
dataset = dataset.filter(lambda x:x["review"] is not None)#2、split dataset
datasets = dataset.train_test_split(test_size=0.1)#4、dataset preprocess
tokenizer = BertTokenizer.from_pretrained("/gemini/pretrain/")
def process_function(examples):tokenized_examples = tokenizer(examples["review"], truncation=True, padding="max_length", max_length=32)tokenized_examples["labels"] = examples["label"]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True,remove_columns=datasets["train"].column_names)#5、create model 创建模型
model = BertForSequenceClassification.from_pretrained("/model/")#6、create evaluation function 创建评估函数
acc_metric = evaluate.load("./metric_acuracy.py")
f1_metric = evaluate.load("./metric_f1.py")
def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metric.compute(predictions=predictions, references=labels)acc.update(f1)return acc#7、create training args 创建训练参数
training_args = TrainingArguments(output_dir="./checkpoint", #输出文件目录per_device_train_batch_size=64, #训练批次大小per_device_eval_batch_size=128, #评估批次大小logging_steps=10, #日志打印频率 evaluation_strategy="epoch", #评估策略save_strategy="epoch", #保存策略save_total_limit=3, #保存的最大检查点数量learning_rate=2e-5, #学习率weight_decay=0.01, #权重衰减metric_for_best_model="f1", #最佳模型评估指标load_best_model_at_end=True, #在训练结束时加载最佳模型
)#8、create trainer 创建训练器
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric,
)#9、start training 开始训练
trainer.train()二、数据并行-原理与实战(pytorch框架的nn.DataParallel)
- 特点
改动代码改动小,但是效率提升不明显
1)data parallel-数据并行 原理及流程
-
介绍

-
训练流程
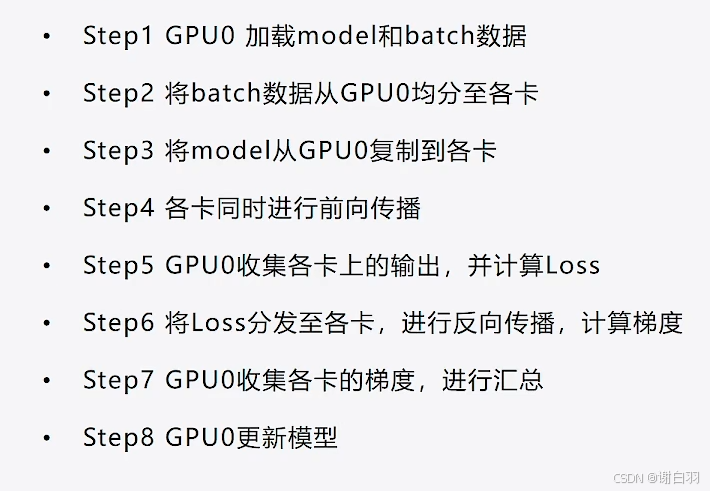
-
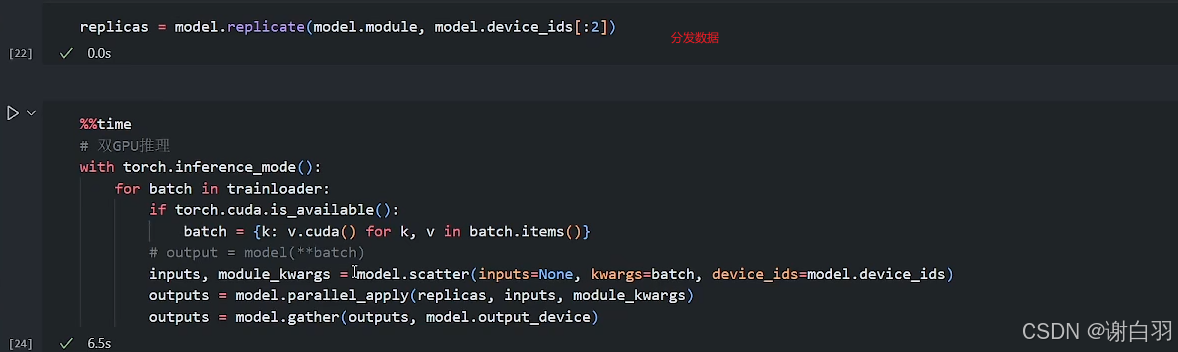
nn.DataParallel源码实现.
代码讲解:
①将batch数据分发到各个显卡
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
②将model分发到各个显卡
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
③收集各个显卡的梯度
self.gather(outputs, self.output_device)
def forward(self, *inputs, **kwargs):with torch.autograd.profiler.record_function("DataParallel.forward"):if not self.device_ids:return self.module(*inputs, **kwargs)for t in chain(self.module.parameters(), self.module.buffers()):if t.device != self.src_device_obj:raise RuntimeError("module must have its parameters and buffers ""on device {} (device_ids[0]) but found one of ""them on device: {}".format(self.src_device_obj, t.device))inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)# for forward function without any inputs, empty list and dict will be created# so the module can be executed on one device which is the first one in device_idsif not inputs and not kwargs:inputs = ((),)kwargs = ({},)if len(self.device_ids) == 1:return self.module(*inputs[0], **kwargs[0])replicas = self.replicate(self.module, self.device_ids[:len(inputs)])outputs = self.parallel_apply(replicas, inputs, kwargs)return self.gather(outputs, self.output_device)2)data parallel-数据并行 训练实战
- 备注
①huggingface的train源码自带数据并行
参数设置在TrainingArguments函数的默认参数


-
环境配置

-
训练代码(文本分类)
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch#1、load dataset 加载数据集
data = pd.read_csv("./ChnSetiCorp_htl_all.csv")
data = data.dropna() # 删除review列中为None的行#2、创建dataset
class MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]dataset = MyDataset()#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1])#4、创建dataloader
tokenizer = BertTokenizer.from_pretrained("./model/")
def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
trainloader = DataLoader(train_set, batch_size=32, shuffle=True, collate_fn=collate_fn)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_fn)# Note: The following line is for demonstration purposes and may not produce meaningful output without the actual dataset.
# It attempts to print the second element (data) of the first enumerated item from the validloader.#5、创建模型及优化器
model = BertForSequenceClassification.from_pretrained("./model")if torch.cuda.is_available():model = model.cuda()
#新加(当 device_ids=None 时,DataParallel 会默认使用所有可用的 GPU 设备)
model=torch.nn.DataParallel(model,device_ids=None)optimizer = Adam(model.parameters(), lr=2e-5)#6、训练和验证
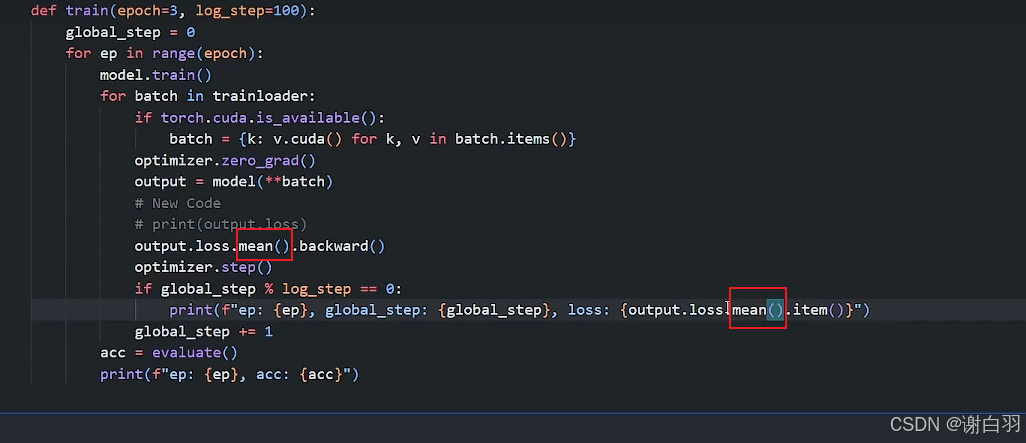
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(*batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validset)def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)output.loss.mean().backward()optimizer.step()if global_step % log_step == 0:print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.mean().item()}")global_step += 1acc = evaluate()print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")train()#7、模型预测- 遇到的问题点
loss是标量值才进行反向传播,loss使用mean方法转化为变量才能反向转播
- 数据并行训练耗时总结
1)单GPU batch32 1min42.3s
2)双GPU batch 2*16 1min33.6s总batchsize提升64
2)双GPU batch 2*32 1min9.5s
- data parallel问题点
每次前向传播都得主卡去同步给副卡一遍

GIL锁:

3)data parallel-数据并行 推理对比
1)单GPU推理:共花了13s,batchsize=32
2)双GPU:21.1s,batchsize=32
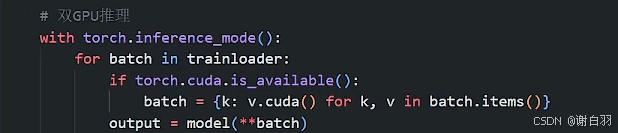
3)batchsize=64
单GPU:10.5s
双GPU:8.8s
4)batchsize=128
单GPU:10.4s
双GPU:7.0s
5)每次训练的时候都会同步模型,将这部分去掉,推理的时候使用自己的train函数,双显卡只耗时6.6s
三、分布式数据并行Distributed DataParallel-原理与实战(俗称ddp)
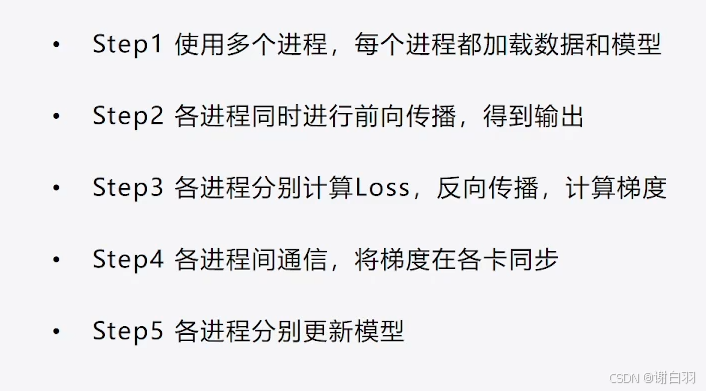
1)distributed data parrallel并行原理
2)分布式训练中的一些基本概念

3)分布式训练中的通信基本概念
-
图来示例
-
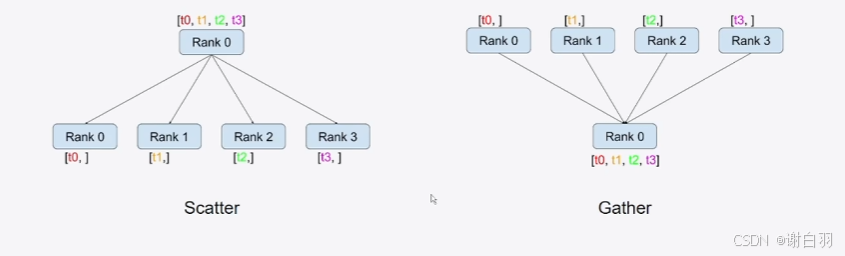
通信类型

①scatter和Gather
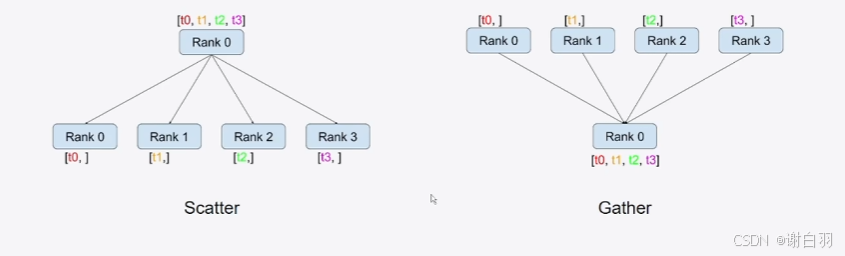
reduce:将各显卡的信息集中并做额外的处理,例如图中的加法
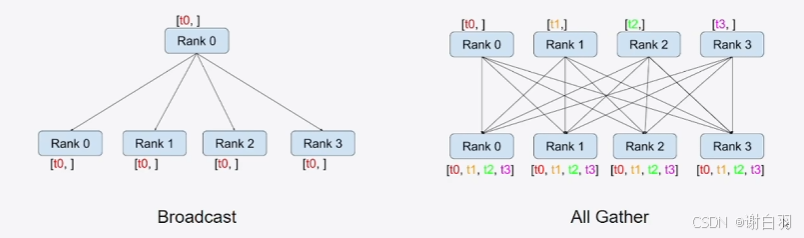
4)distributed data parallel 训练实战(DDP)
- 环境配置
- 代码相关
①加载distribute库
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器#1)初始化进程组
dist.init_process_group(backend='nccl')
②去掉DataLoader的shuffle为true的参数,传sample参数为DistributedSampler
trainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,sampler=DistributedSampler(train_set))
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,sampler=DistributedSampler(validset))
③用local_rank区别同一显卡内的不同进程
#5、创建模型及优化器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
model = BertForSequenceClassification.from_pretrained("./model")
if torch.cuda.is_available():model = model.to(int(os.environ["LOCAL_RANK"])) # 使用环境变量 LOCAL_RANK 获取当前进程的 GPU 设备编号model = DDP(model) # 使用DistributedDataParallel包装模型
optimizer = Adam(model.parameters(), lr=2e-5)
继续把train函数的地方把.cuda改成local_rank
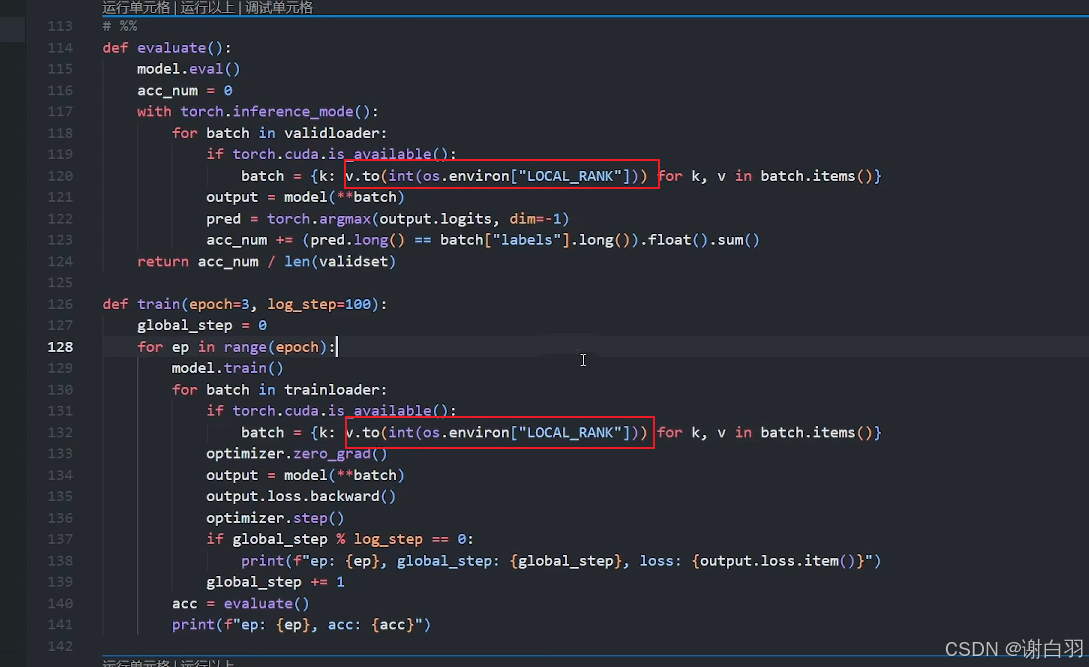
④运行命令
torchrun --nproc_per_node 2 ddp.py #这里nproc_per_node表示一张显卡的进程数
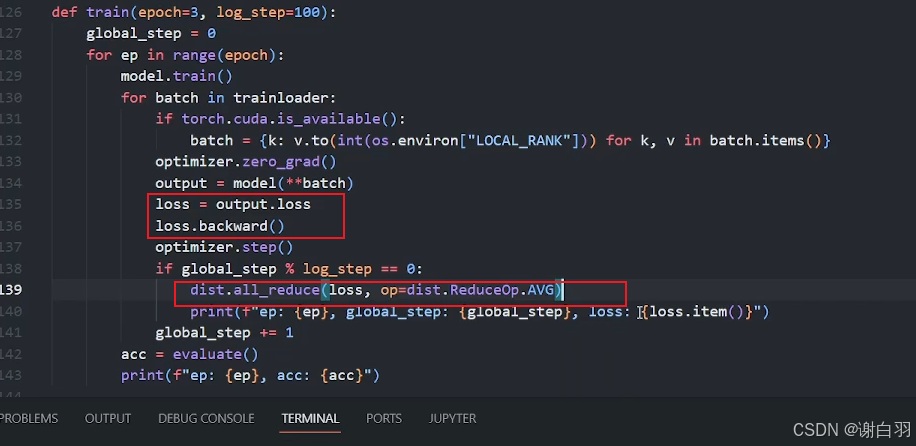
⑤优化一:由于结果打印的是各个GPU显卡的损失值loss,而不是总体的平均值,需要各显卡通信打印平均值loss
⑥优化二:
由于一张卡有全体唯一的global_rank,而现在一张卡用了两条线程去做,会打印两次,现在需求是根据global_rank只打印一次
把打印都替换一下
def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)
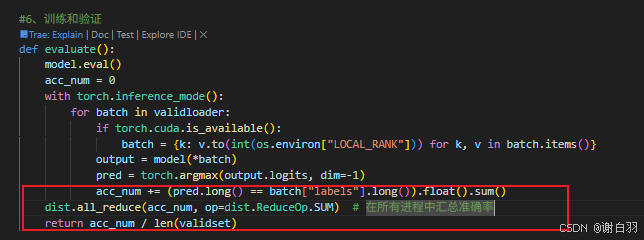
⑦优化三:现在准确率是除以了全部的数据,现在单个local rank只需要除以自己处理部分的数据来计算准确率
⑧优化四:
数据集两个进程之间划分容易有重叠,准确率会虚高
#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))
⑨优化五:让训练数据不重复,随机打断
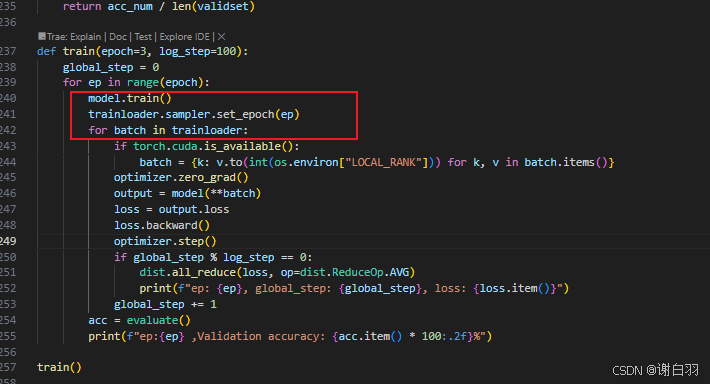
istributedSampler 的 set_epoch 方法会依据传入的轮次编号(ep)更新采样器的随机种子,这样在不同的训练轮次中,采样器会以不同的随机顺序对数据进行采样。这意味着每个进程在不同轮次会处理不同的数据子集,有助于模型接触到更多的数据变化,提高模型的泛化能力和训练效果。
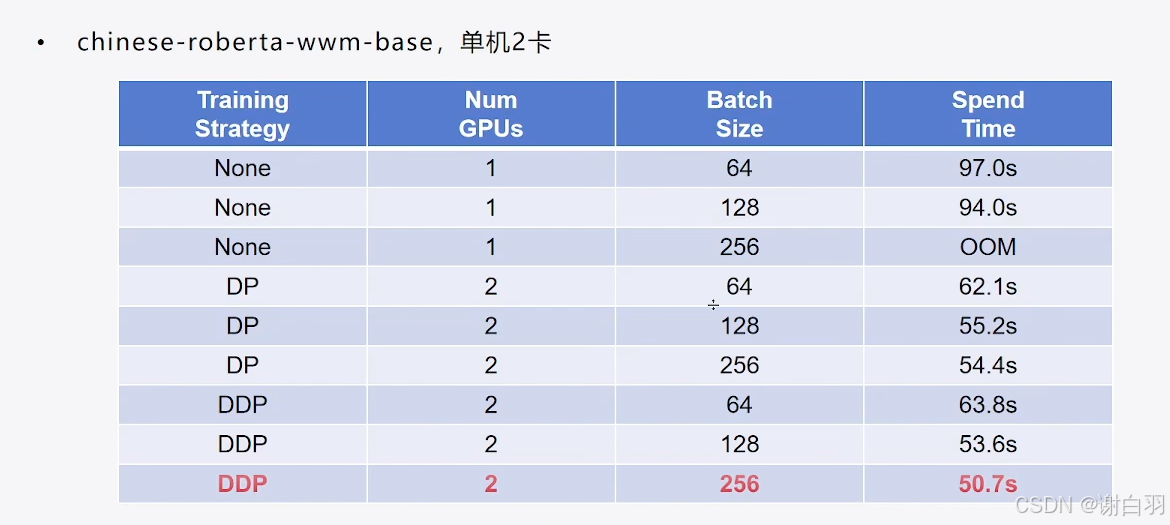
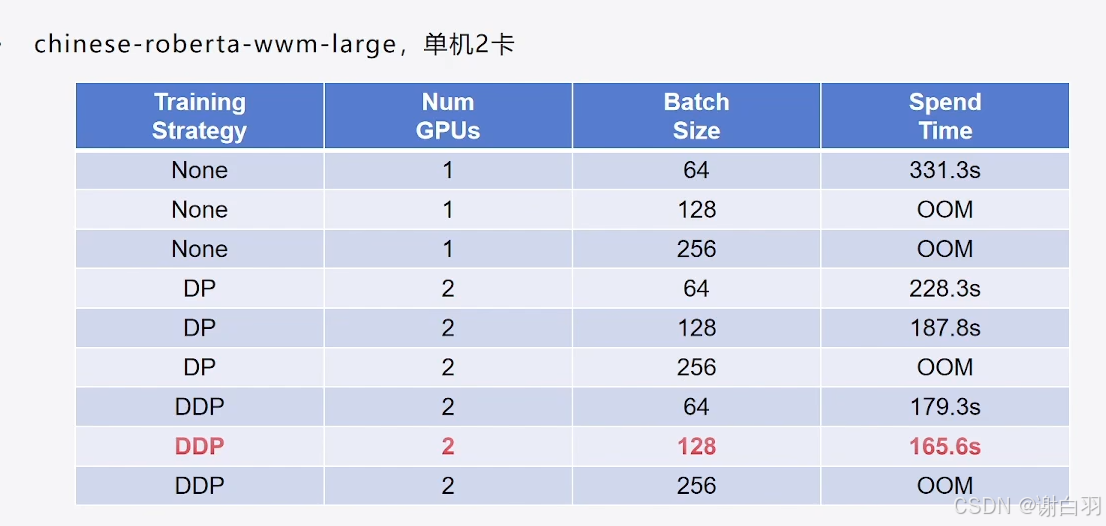
- DDP和DP效率对比(基本上batchsize越高ddp效率越好过于DP)
- 代码
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
import os#1)初始化进程组
dist.init_process_group(backend='nccl')def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)#2、创建dataset
class MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]dataset = MyDataset()#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloader
tokenizer = BertTokenizer.from_pretrained("./model/")
def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
trainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,sampler=DistributedSampler(train_set))
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,sampler=DistributedSampler(validset))# Note: The following line is for demonstration purposes and may not produce meaningful output without the actual dataset.
# It attempts to print the second element (data) of the first enumerated item from the validloader.#5、创建模型及优化器
from torch.nn.parallel import DistributedDataParallel as DDP
model = BertForSequenceClassification.from_pretrained("./model")
if torch.cuda.is_available():model = model.to(int(os.environ["LOCAL_RANK"])) # 使用环境变量 LOCAL_RANK 获取当前进程的 GPU 设备编号model = DDP(model) # 使用DistributedDataParallel包装模型
optimizer = Adam(model.parameters(), lr=2e-5)#6、训练和验证
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()}output = model(*batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()dist.all_reduce(acc_num, op=dist.ReduceOp.SUM) # 在所有进程中汇总准确率return acc_num / len(validset)def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()trainloader.sampler.set_epoch(ep)for batch in trainloader:if torch.cuda.is_available():batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)loss = output.lossloss.backward()optimizer.step()if global_step % log_step == 0:dist.all_reduce(loss, op=dist.ReduceOp.AVG)print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")global_step += 1acc = evaluate()print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")train()
四、Accelerate基础入门
1)Accelerate基本介绍

- accelerate 四行代码导入训练

2)基于AccelerateDDP代码介绍
- 实战环境准备

- 代码
上篇章节DPP的代码 - 修改点
①去掉框中代码:在没有使用 accelerate 库时,这段代码的作用是把数据批次中的每个张量都移动到对应的 GPU 设备上。os.environ[“LOCAL_RANK”] 表示当前进程所在的本地 GPU 设备编号,v.to(int(os.environ[“LOCAL_RANK”])) 会将张量 v 移动到该编号对应的 GPU 上。
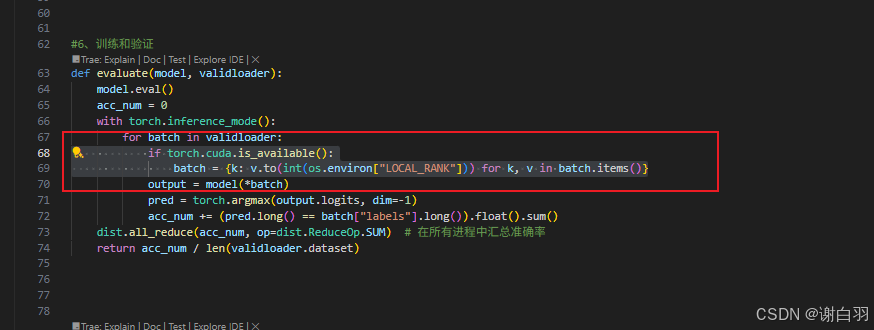
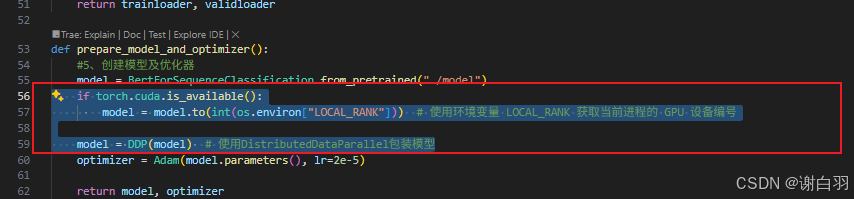
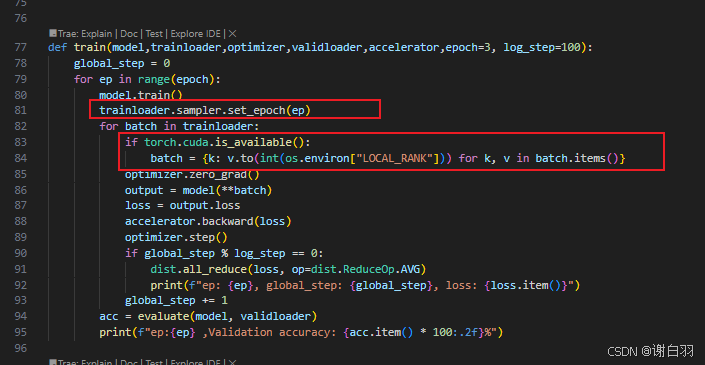
②出现问题一:准确率高于100%、
原因:数据集按照64作为batchsize训练的时候,不够一次训练就填充了数据
变更前:
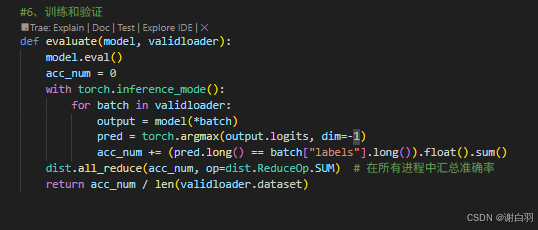
变更后:
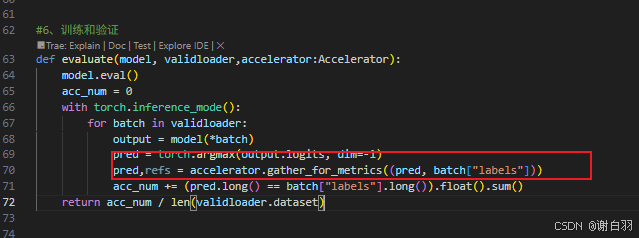
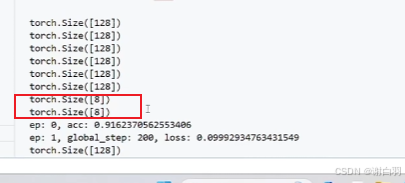
可以看到最后几次就不会把验证集填充到128次
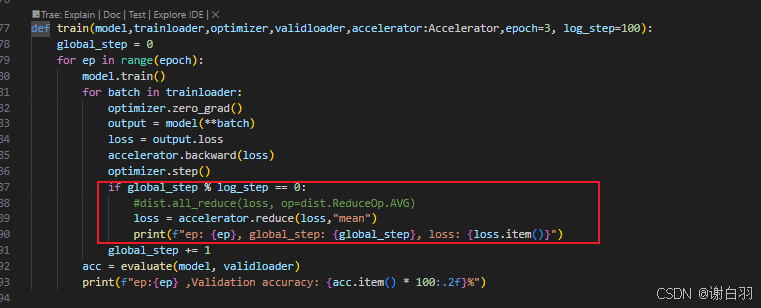
③ddp的all_reduce可以替换成accelerate的接口
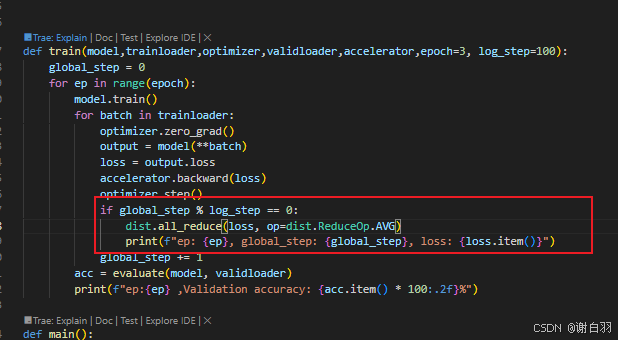
改成:
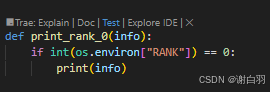
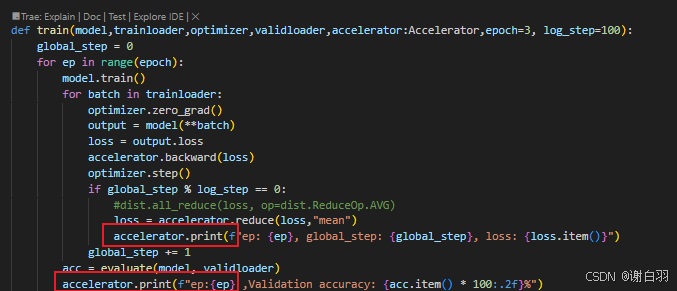
④打印日志接口可以用accelerate接口:
原先:
现在:
⑤启动该监本命令:
accelerate launch ddp_accelerate.py
第一次执行会询问生成配置
- 代码
from transformers import BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
import torch
from accelerate import Acceleratorclass MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)def prepare_dataloader():#2、创建datasetdataset = MyDataset()#3、split dataset 划分数据集train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloadertokenizer = BertTokenizer.from_pretrained("./model/")def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputstrainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,shuffle=True)validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,shuffle=False)return trainloader, validloaderdef prepare_model_and_optimizer():#5、创建模型及优化器model = BertForSequenceClassification.from_pretrained("./model")optimizer = Adam(model.parameters(), lr=2e-5)return model, optimizer#6、训练和验证
def evaluate(model, validloader,accelerator:Accelerator):model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:output = model(*batch)pred = torch.argmax(output.logits, dim=-1)pred,refs = accelerator.gather_for_metrics((pred, batch["labels"]))acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validloader.dataset)def train(model,trainloader,optimizer,validloader,accelerator:Accelerator,epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:optimizer.zero_grad()output = model(**batch)loss = output.lossaccelerator.backward(loss)optimizer.step()if global_step % log_step == 0:#dist.all_reduce(loss, op=dist.ReduceOp.AVG)loss = accelerator.reduce(loss,"mean")accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")global_step += 1acc = evaluate(model, validloader)accelerator.print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")def main():accelerator = Accelerator()trainloader, validloader = prepare_dataloader()model, optimizer = prepare_model_and_optimizer()model, optimizer, trainloader, validloader = accelerator.prepare(model, optimizer, trainloader, validloader)train(model, trainloader, optimizer, validloader,accelerator)if __name__ == "__main__":main()3)Accelerate启动命令介绍

五、Accelerate使用进阶
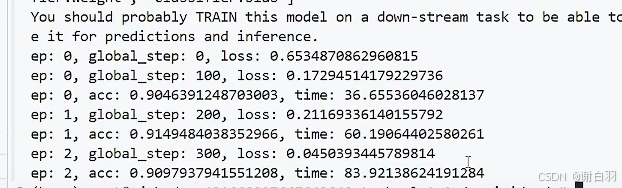
1)Accelerate混合精度训练
- 概念讲解
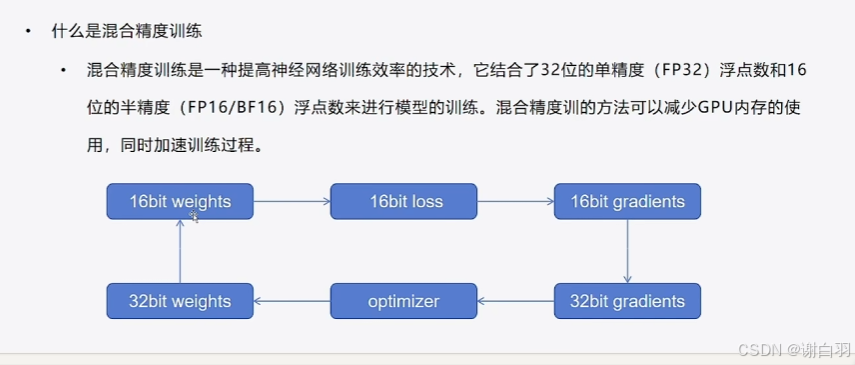
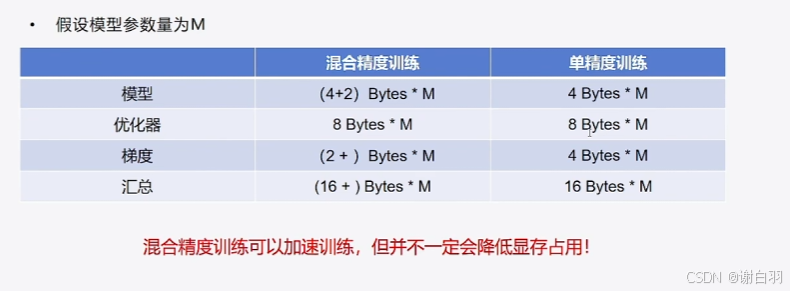
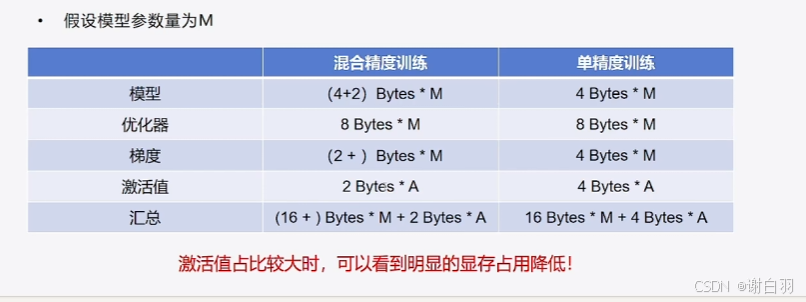
- 混合精度训练方式

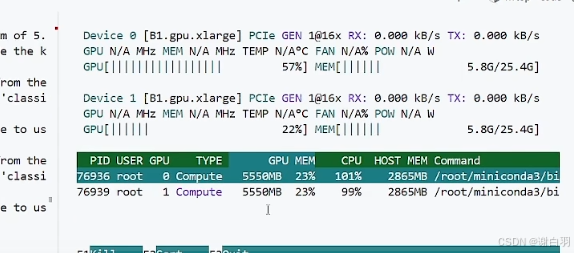
方式一:batchsize=32,bf16,最后测得59s,单卡占用5500MB显存
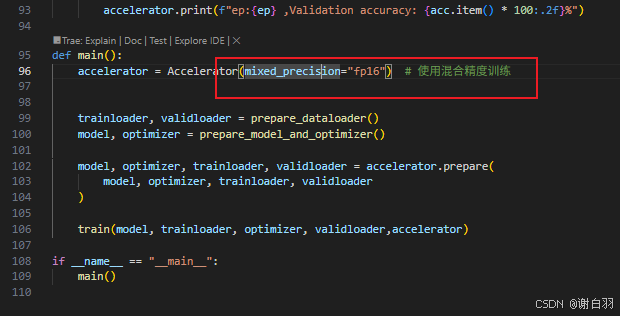
启动
accelerate launch ddp_accelerate.py
用nvtop检测显存占用
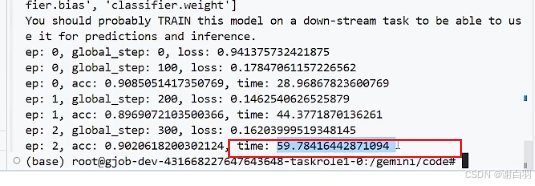
对比普通不用accelerate的情况,batchsize=32,正常跑,最后测得83s,单卡占用6400MB显存
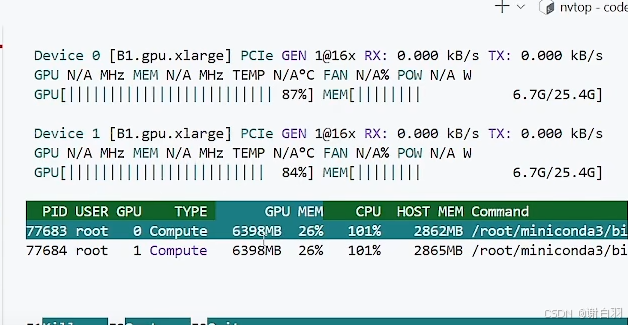
方式二:配置选择bf16
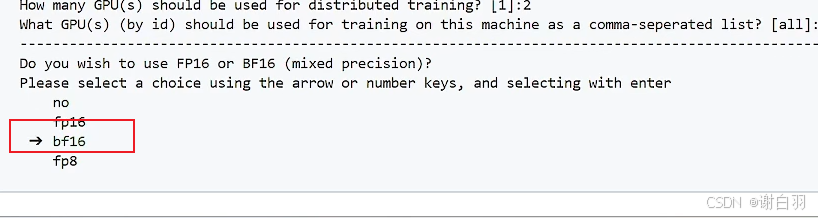
方式三:命令行指示精度

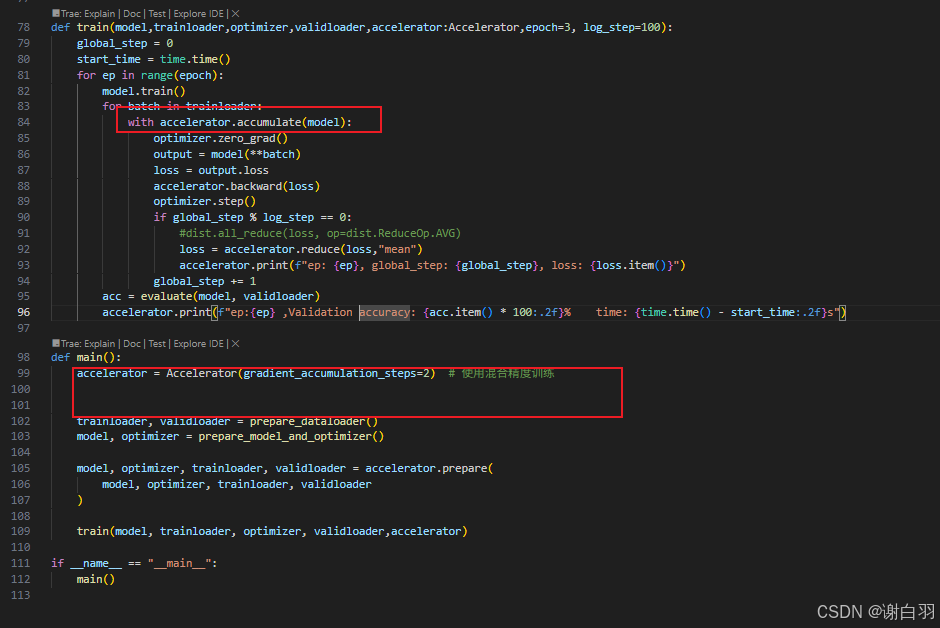
2)Accelerate梯度累积功能
-
介绍

-
代码实现

-
实现步骤

-
代码更改部分
-
问题点
global_step功能可以由梯度累积实现
global_step的作用:让单张显卡多个进程只打印一次更新模型梯度时的信息
改进前:
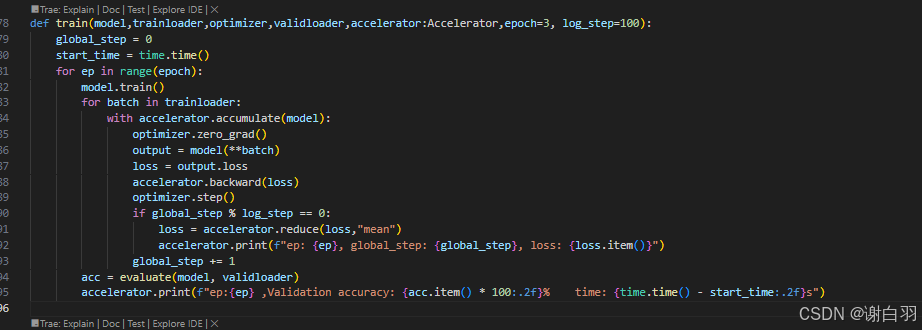
改进后:
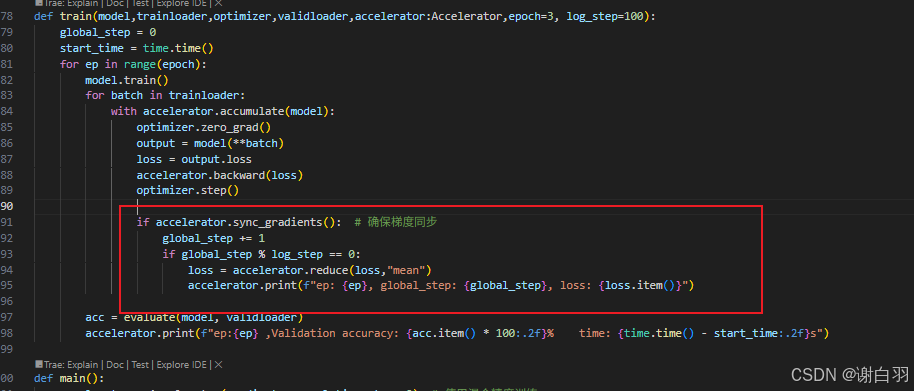
- 结果打印(因为2张显卡,参数更新步数少了一半)耗时52s
3)Accelerate实验记录功能
-
实验记录工具

-
记录方法

-
代码实现(记录损失值和正确率)
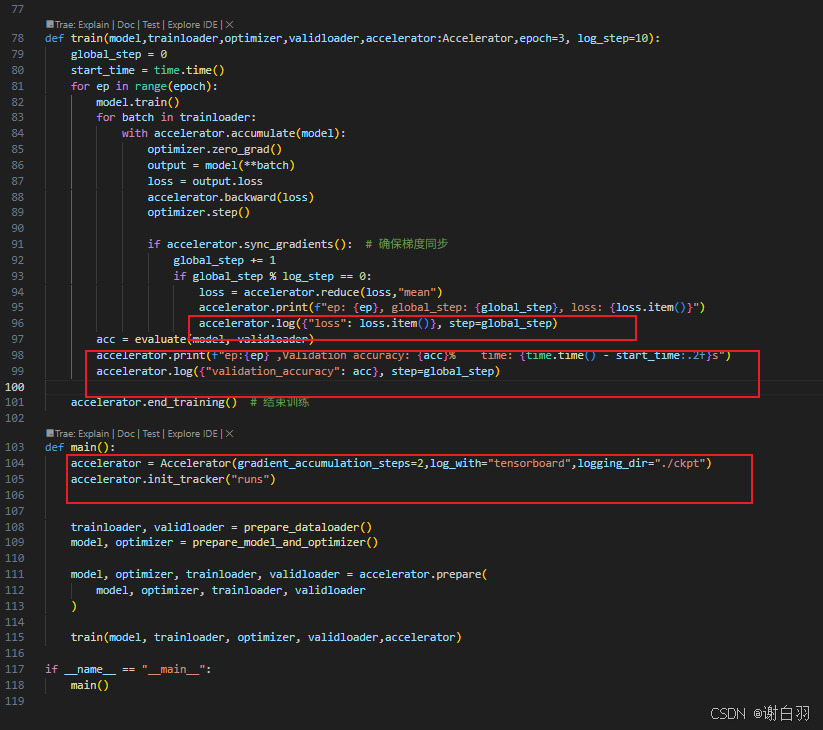
-
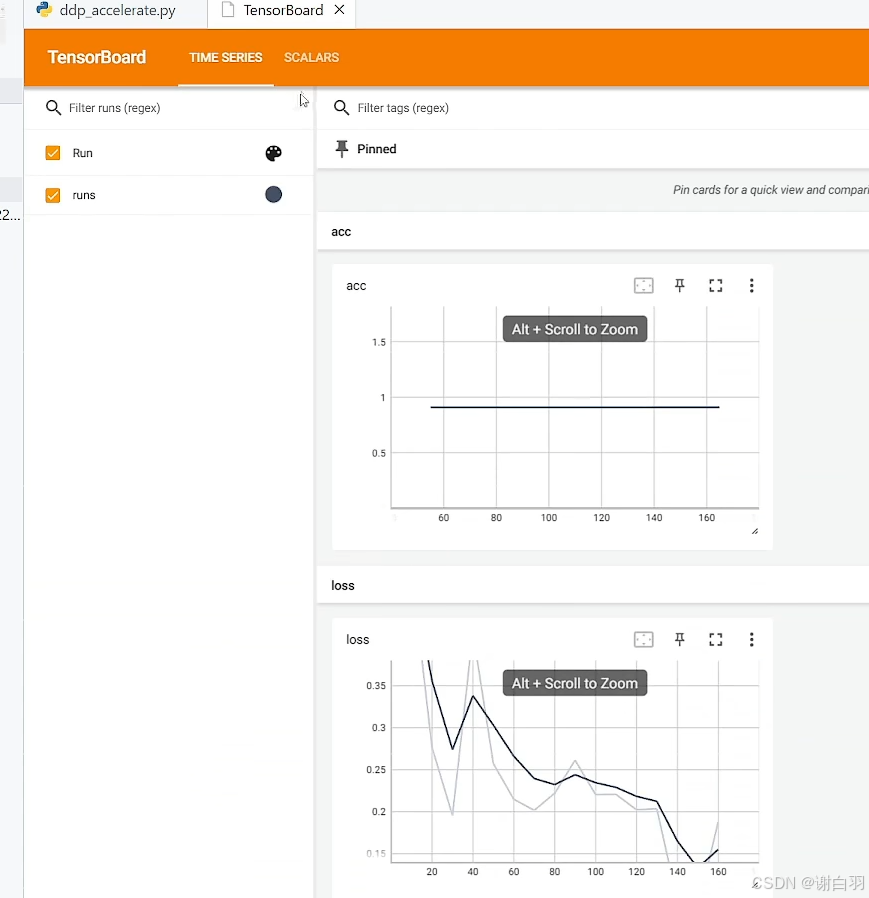
产出文件

用tensorboard打开
vscode界面,control+shift+p打开tensorboard命令

并选择文件目录

4)Accelerate模型保存功能
- 介绍

- 保存方式(方式一应该是save_model)

- 方式一实现
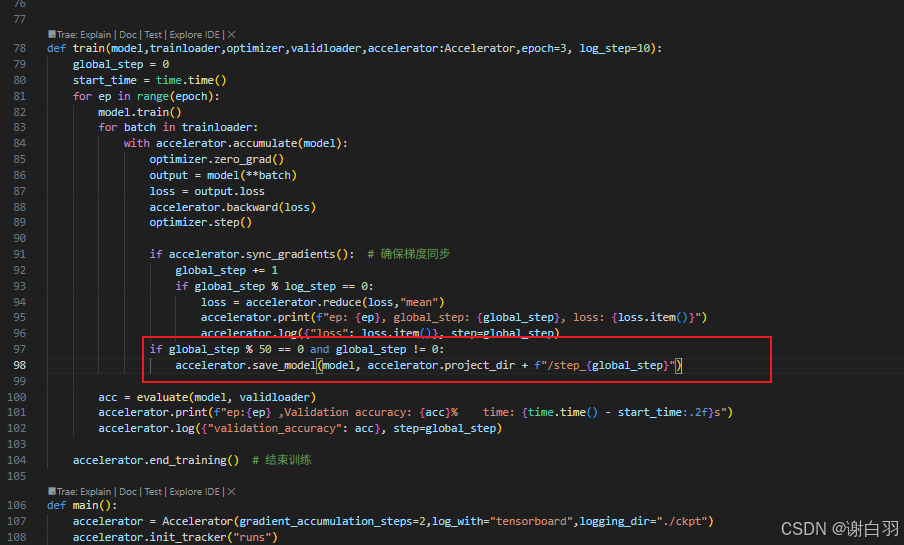
问题:没有模型配置文件
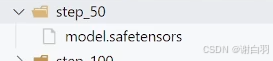
还有就是对peft不能只得到lora的那一部分

方式二:

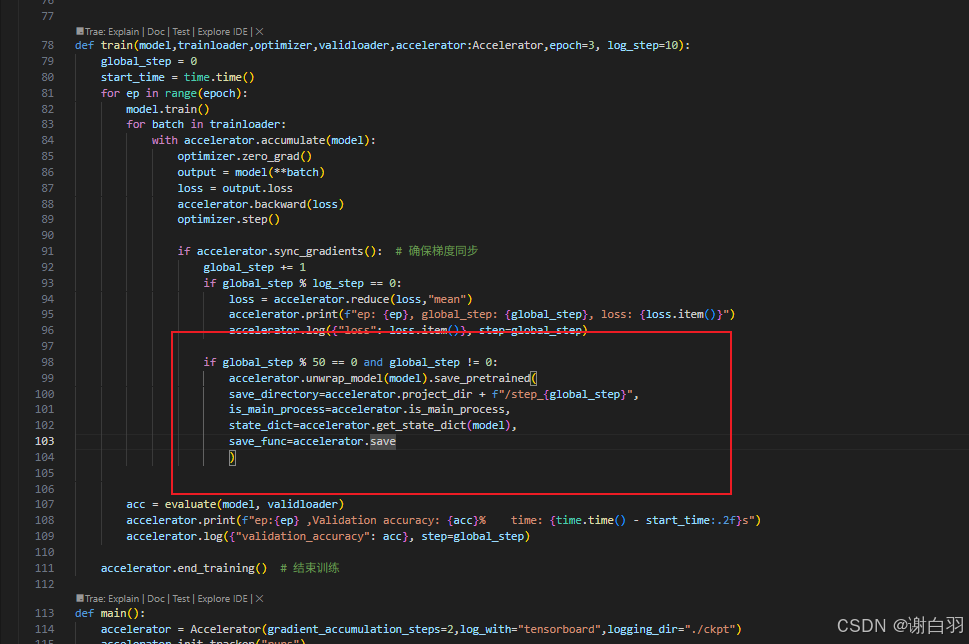
结果展示
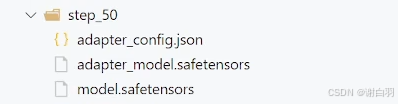
5)Accelerate断点续训练功能
- 介绍

- 步骤

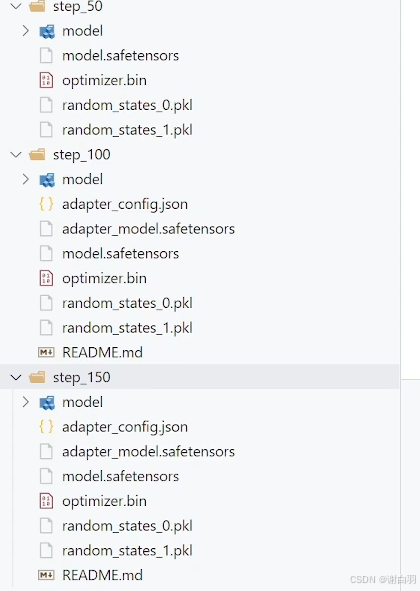
保存检查点,模型放到model下一级目录
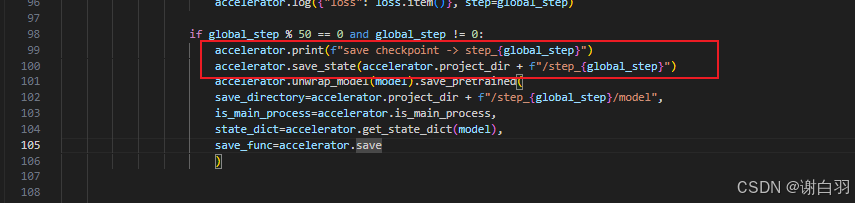
计算跳过步数
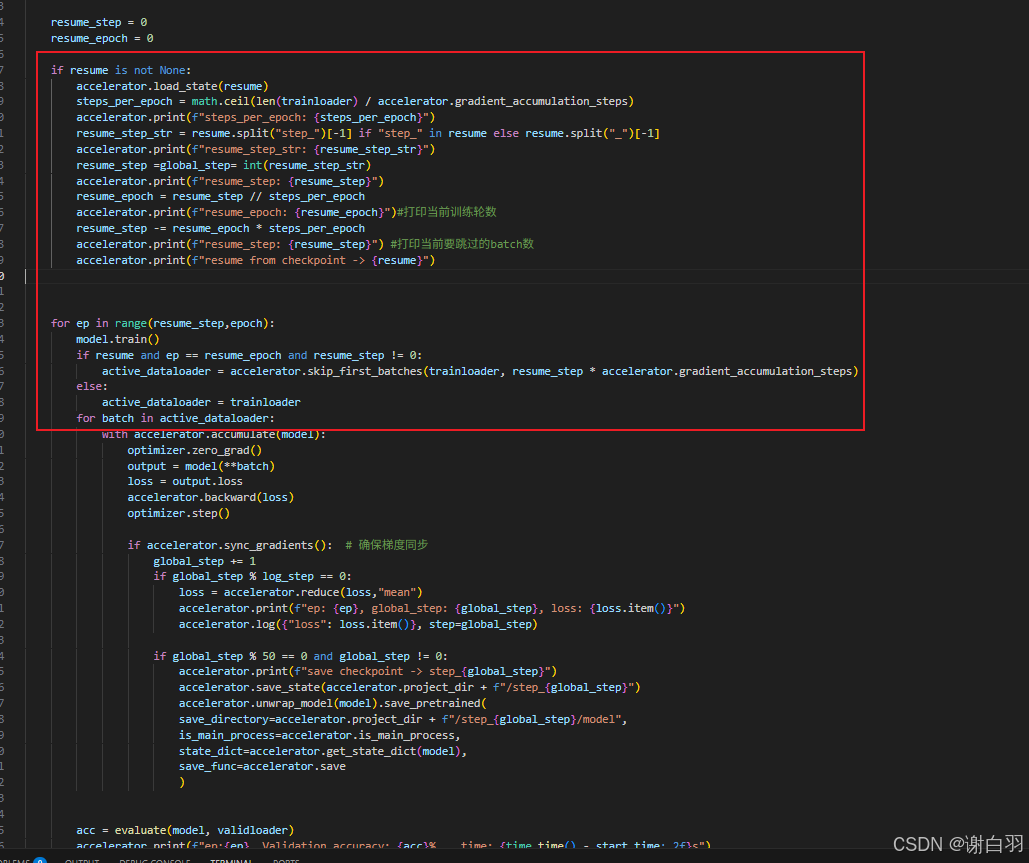
保存结果展示
续训代码

6)前五个功能后的总代码
- 代码
from transformers import BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
import torch
import time
import math
from accelerate import Acceleratorclass MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)def prepare_dataloader():#2、创建datasetdataset = MyDataset()#3、split dataset 划分数据集train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloadertokenizer = BertTokenizer.from_pretrained("./model/")def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputstrainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,shuffle=True)validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,shuffle=False)return trainloader, validloaderdef prepare_model_and_optimizer():#5、创建模型及优化器model = BertForSequenceClassification.from_pretrained("./model")optimizer = Adam(model.parameters(), lr=2e-5)return model, optimizer#6、训练和验证
def evaluate(model, validloader,accelerator:Accelerator):model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:output = model(*batch)pred = torch.argmax(output.logits, dim=-1)pred,refs = accelerator.gather_for_metrics((pred, batch["labels"]))acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validloader.dataset)def train(model,trainloader,optimizer,validloader,accelerator:Accelerator,resume,epoch=3, log_step=10):global_step = 0start_time = time.time()resume_step = 0resume_epoch = 0if resume is not None:accelerator.load_state(resume)steps_per_epoch = math.ceil(len(trainloader) / accelerator.gradient_accumulation_steps)accelerator.print(f"steps_per_epoch: {steps_per_epoch}")resume_step_str = resume.split("step_")[-1] if "step_" in resume else resume.split("_")[-1]accelerator.print(f"resume_step_str: {resume_step_str}")resume_step =global_step= int(resume_step_str)accelerator.print(f"resume_step: {resume_step}")resume_epoch = resume_step // steps_per_epochaccelerator.print(f"resume_epoch: {resume_epoch}")#打印当前训练轮数resume_step -= resume_epoch * steps_per_epochaccelerator.print(f"resume_step: {resume_step}") #打印当前要跳过的batch数accelerator.print(f"resume from checkpoint -> {resume}")for ep in range(resume_step,epoch):model.train()if resume and ep == resume_epoch and resume_step != 0:active_dataloader = accelerator.skip_first_batches(trainloader, resume_step * accelerator.gradient_accumulation_steps)else:active_dataloader = trainloaderfor batch in active_dataloader:with accelerator.accumulate(model):optimizer.zero_grad()output = model(**batch)loss = output.lossaccelerator.backward(loss)optimizer.step()if accelerator.sync_gradients(): # 确保梯度同步global_step += 1if global_step % log_step == 0:loss = accelerator.reduce(loss,"mean")accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")accelerator.log({"loss": loss.item()}, step=global_step)if global_step % 50 == 0 and global_step != 0:accelerator.print(f"save checkpoint -> step_{global_step}")accelerator.save_state(accelerator.project_dir + f"/step_{global_step}")accelerator.unwrap_model(model).save_pretrained(save_directory=accelerator.project_dir + f"/step_{global_step}/model",is_main_process=accelerator.is_main_process,state_dict=accelerator.get_state_dict(model),save_func=accelerator.save)acc = evaluate(model, validloader)accelerator.print(f"ep:{ep} ,Validation accuracy: {acc}% time: {time.time() - start_time:.2f}s")accelerator.log({"validation_accuracy": acc}, step=global_step)accelerator.end_training() # 结束训练def main():accelerator = Accelerator(gradient_accumulation_steps=2,log_with="tensorboard",logging_dir="./ckpt") accelerator.init_tracker("runs")trainloader, validloader = prepare_dataloader()model, optimizer = prepare_model_and_optimizer()model, optimizer, trainloader, validloader = accelerator.prepare(model, optimizer, trainloader, validloader)train(model, trainloader, optimizer, validloader,accelerator,resume="/gemini/code/ckpts/step_150")if __name__ == "__main__":main()六、Accelerate集成Deepspeed
1)Deepspeed介绍
- DDP存在的问题

零冗余:优化每个GPU显卡上存在以下三个冗余的情况
①梯度 gradient
②优化器 optimizer,每张卡只加载优化器的一部分
③模型参数 model param
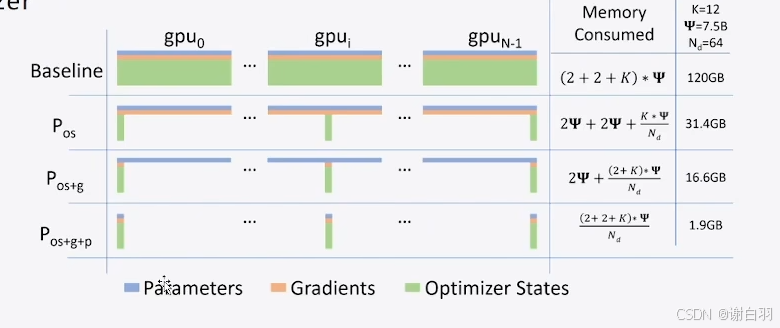
- 通信量分析

- 额外功能介绍

2)Accelerate + Deepspeed代码实战
- Accelerate + Deepspeed集合
方式一:

使用之前记得安装deepspeed
pip install deepspeed
使用accelerate config配置文件,一般选择zero2策略即可,速度比zero要快一些,然后指定目录下配置文件启动
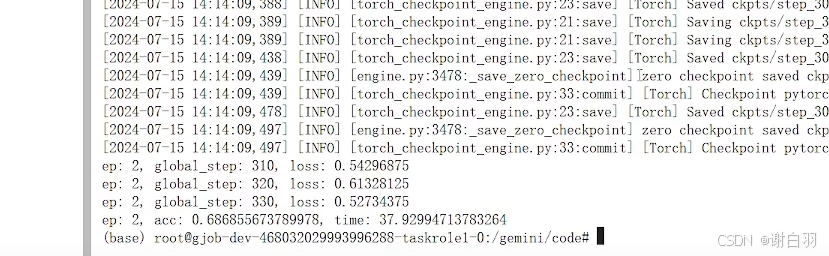
训练结果:37秒完成训练
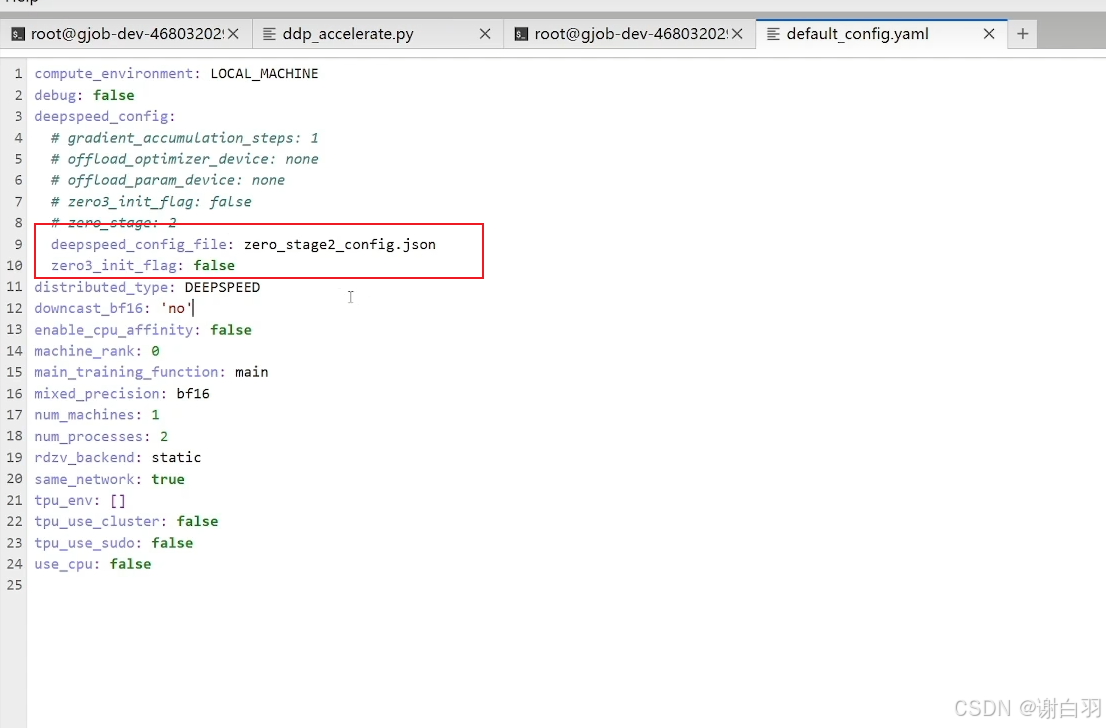
方式二:

accelerate配置文件增加deepspeed配置文件名字
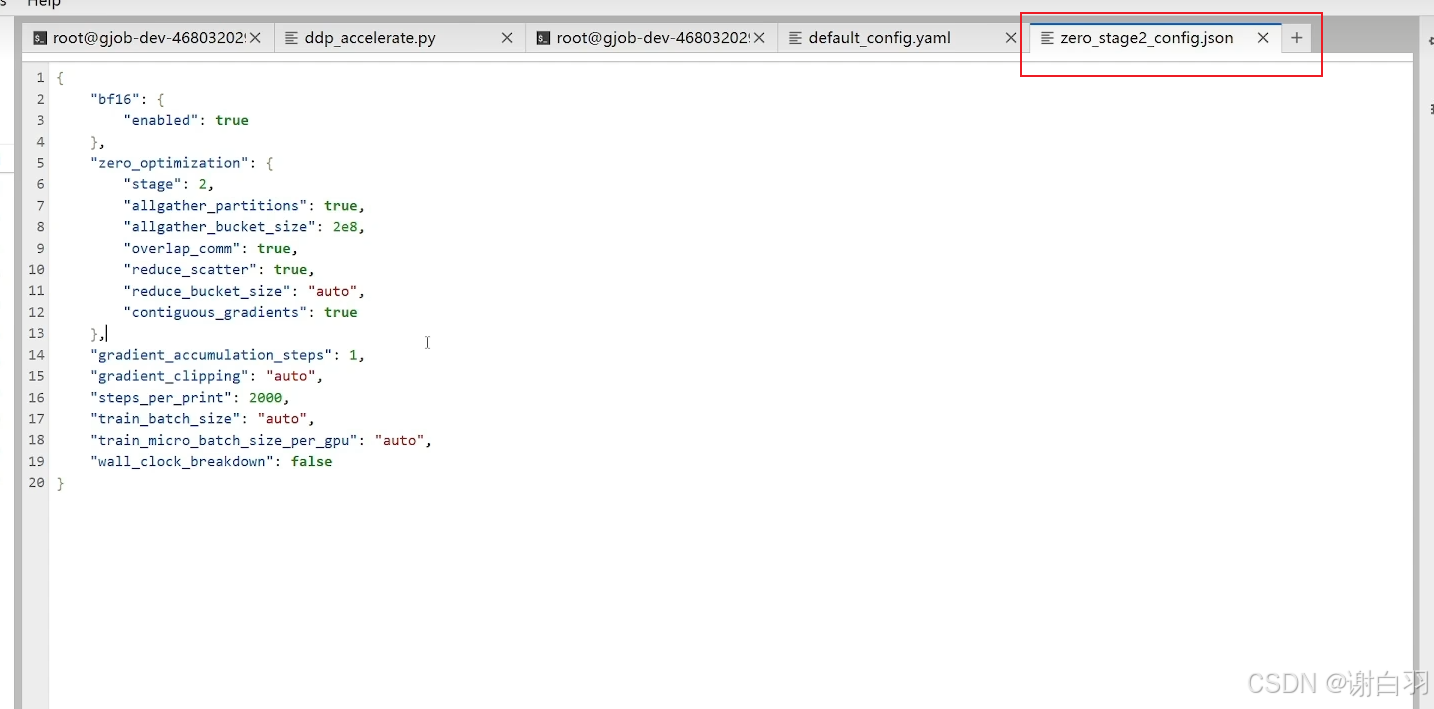
新增deepspeed配置文件
- 遇到的问题:
①由于accelerate配置指定zero3的时候,会有模型参数保存补全报错
解决:要加一行配置
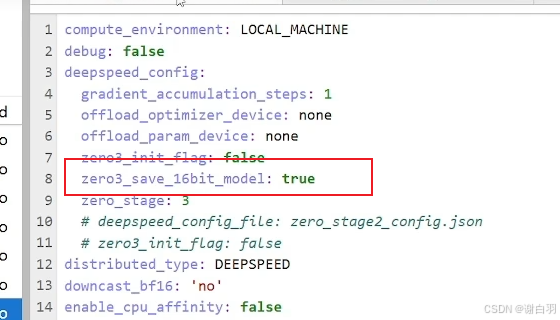
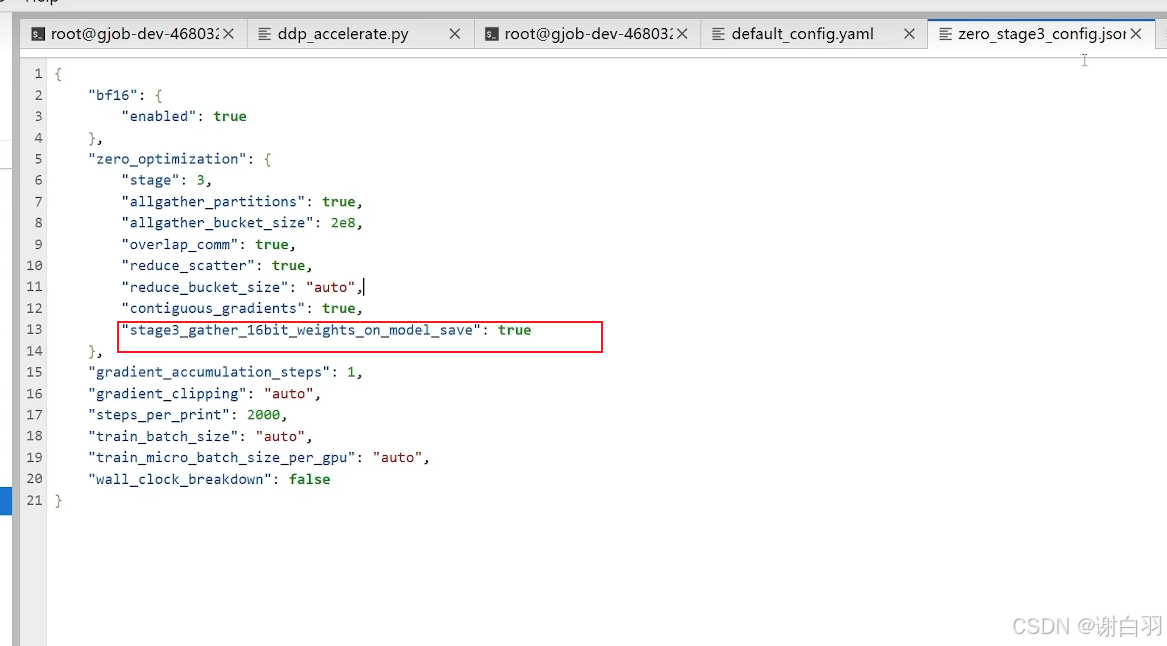
相当于deepspeed配置的这个:
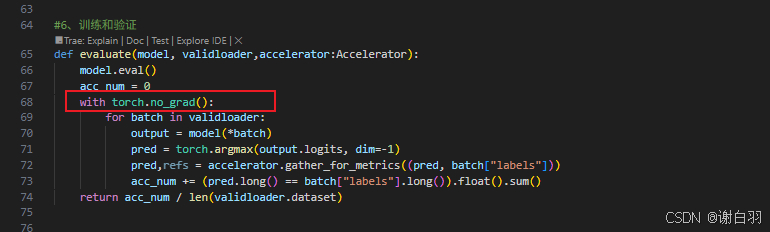
②由于zero3会计算提低更新模型,但是梯度已经分散出去,这时候要在推理过程中禁止梯度计算
原因:
将 torch.inference_mode 替换为 torch.no_grad() 主要作用是在推理过程中禁止梯度计算。在验证阶段,我们只需要模型前向传播得到预测结果,无需计算梯度来更新模型参数,因此禁用梯度计算能节省内存和计算资源
- 注意事项

