Python基于SVM技术的手写数字识别问题项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。

1.项目背景
在当今数字化转型加速的时代,手写数字识别作为图像处理与机器学习领域的一个经典问题,具有广泛的实际应用价值。无论是邮政编码的自动识别、银行支票上的手写金额辨识,还是移动设备中的手写输入法,都离不开高效准确的手写数字识别技术。支持向量机(SVM)作为一种强大的监督学习模型,在分类和回归分析中表现出色,尤其适用于高维空间的数据分类任务。本项目旨在利用SVM技术对手写数字进行识别,通过构建并训练一个高性能的SVM模型,实现对来自MNIST数据集的手写数字进行精准分类。此项目不仅能够深化对SVM算法原理及其实现细节的理解,同时也为实际应用提供了可靠的解决方案,展示了机器学习技术在日常生活中的巨大潜力。
本项目通过Python基于SVM技术的手写数字识别问题项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据详情如下:

3.数据预处理
3.1 数据读取处理
使用Numpy工具读取数据:

关键代码:
![]()
4.探索性数据分析
4.1 展示原始图片
用Matplotlib工具绘图:

5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

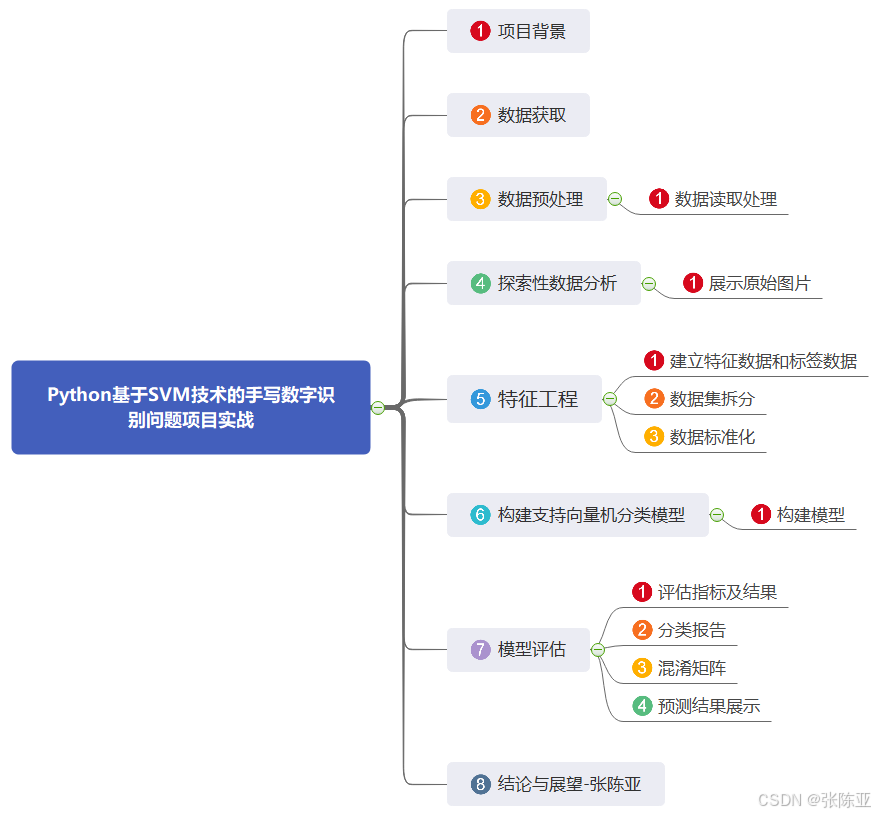
5.3 数据标准化
关键代码如下:
6.构建支持向量机分类模型
主要通过Python基于SVM技术的手写数字识别问题,用于目标分类。
6.1 构建模型
构建分类模型。
| 模型名称 | 模型参数 |
| SVM分类模型 | 默认参数 |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| SVM分类模型 | 准确率 | 0.9369 |
| 查准率 | 0.9382 | |
| 查全率 | 0.9369 | |
| F1分值 | 0.9371 | |
从上表可以看出,F1分值为0.9371,说明模型效果良好。
关键代码如下:

7.2 分类报告
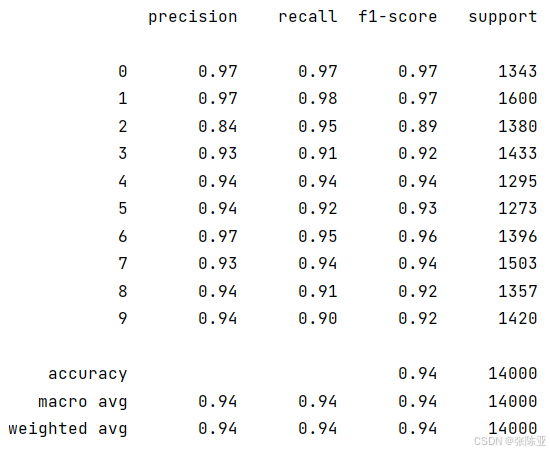
从上图可以看出,每种类别的F1分值。
7.3 混淆矩阵
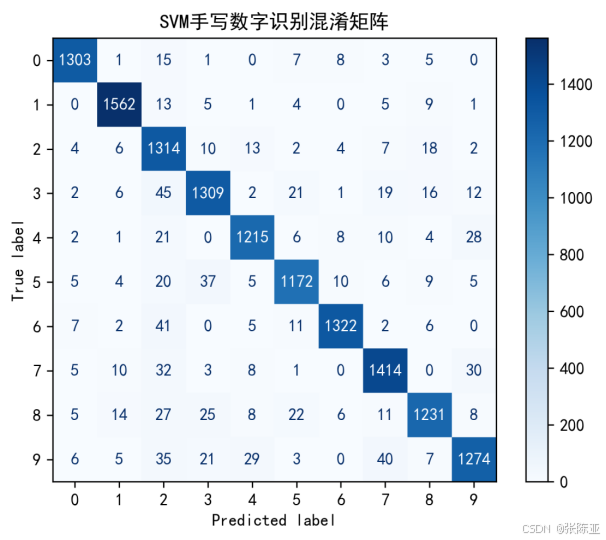
从上图可以看出,每种类别预测错误的数量。
7.4 预测结果展示

8.结论与展望
综上所述,本文采用了通过Python基于SVM技术的手写数字识别问题项目实战,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。