【学习笔记】深度学习-过拟合解决方案
过拟合概念
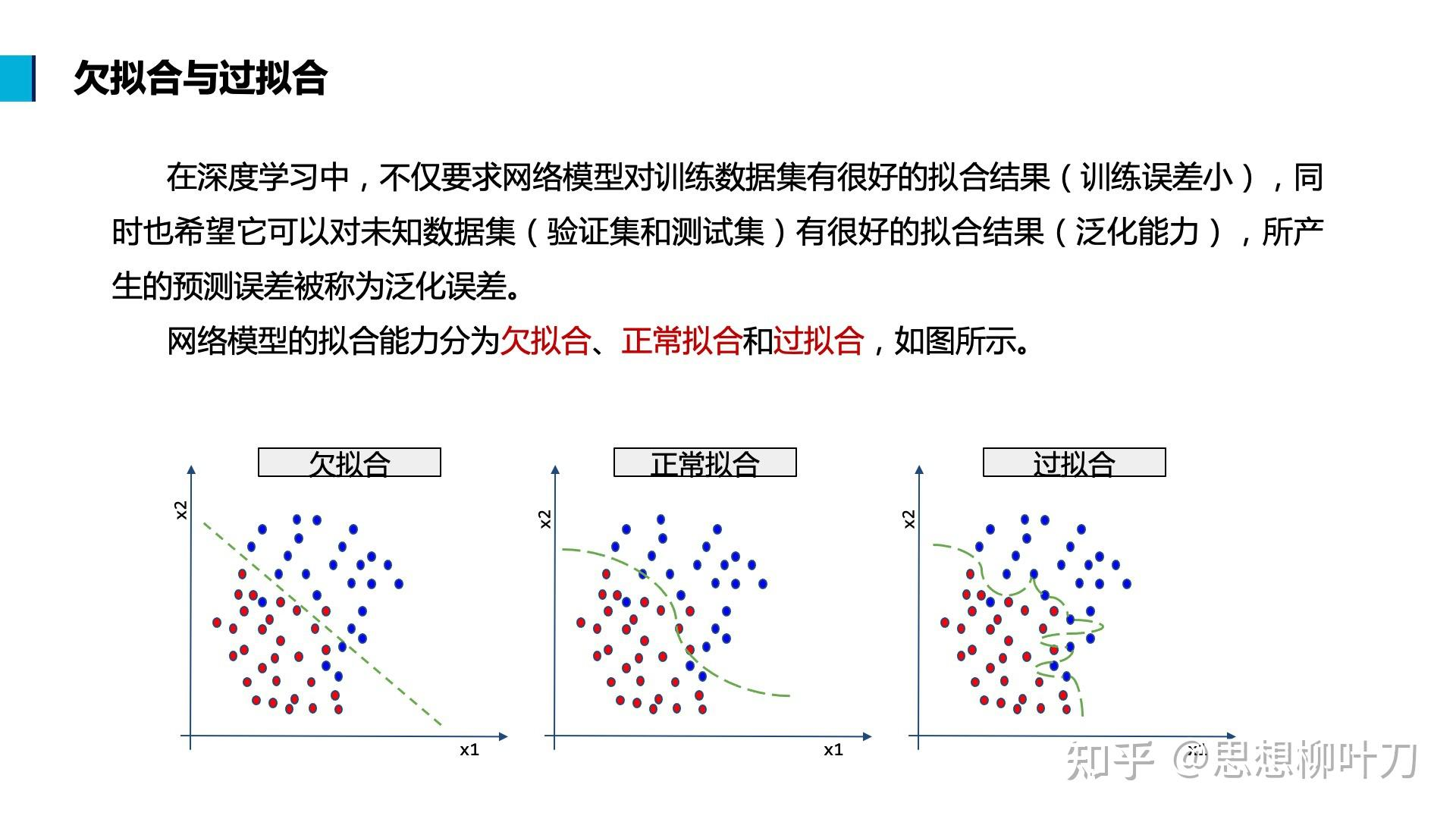
欠拟合:一般是在训练、验证、测试集上表现都不佳。
过拟合:在训练集上表现不错,但在验证集和测试集上表现不佳,主要是因为学习到了训练数据的噪声和细节(样本之间的方差大,参数的方差也大)。
过拟合常伴随着大权重
以一个最简单的神经元为例:
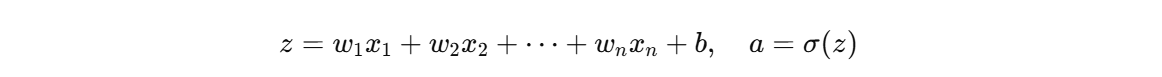
要让输出 𝑎对输入 𝑥 的微小变化非常敏感(即对每一个训练样本都严格拟合),就要让 𝑧 对 𝑥的变化幅度更大;实现这种敏感的方式就是让 权重 𝑤𝑖足够大。
方法一 L2正则化
公式
在原损失函数中加入权重参数的平方和作为惩罚项:
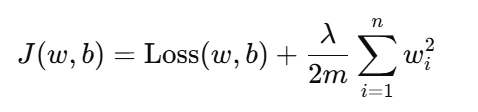
其中:
Loss(𝑤,𝑏):原始损失(如交叉熵、MSE 等)
𝜆/2𝑚∑𝑤𝑖²:L2 正则项
𝜆:正则化强度(超参数)
𝑚:样本数
原理
在反向传播时,计算对某个wi的梯度,得到dw为:
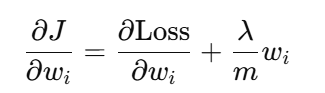
如果wi特别大,则其梯度也会特别大,更新参数时,根据公式
wi = wi - αwi,wi减小的也会更多,将参数拉向原点
故L2正则化可以防止某个参数过大,即某个特征的权重过大
相当于给模型加了“平滑性”约束,使得模型不容易学习噪声。
方法二 Dropout(丢弃神经元)
原理
在训练时,以概率 𝑝随机“屏蔽”(设为 0)神经元的激活值,使网络结构每次都不一样

作用
每次训练只依赖部分神经元,强迫网络不能过度依赖某些路径;
实现方式
假设有0.8的概率保留结点,即keep_prob = 0.8
D = np.random.rand(A.shape[0], A.shape[1]) < keep_prob ## 生成掩码
"""
np.random.rand(...)会生成一个和激活矩阵 A 同样形状的矩阵,里面的每个值是从 [0, 1) 之间均匀分布中随机抽取的。
< keep_prob —— 阈值过滤,会返回一个布尔矩阵,值小于 0.8 的位置变为 True,大于等于 0.8 的变为 False
如 array([[True, True, False],[True, False, True]])
"""
A = A * D ## 被丢弃的位置为 False,对应 A 值乘 0
A = A / keep_prob ## 保证剩下的期望值不变
效果
强化模型的鲁棒性和泛化能力
每次丢弃神经元等于训练了一个不同的子模型。训练过程中,模型好比在“投票平均”多个结构。
方法三 扩充数据
当数据和预算都足够时,可以采集更多的训练集,这也是最本质的解决方案
当数据和预算不足时,可以通过图像旋转、裁剪、翻转,人为扩充训练集,防止模型记住训练图像
方法四 早停
验证集损失停止下降则终止训练,防止训练太久对训练集过拟合