【算法设计与分析】实验——汽车加油问题, 删数问题(算法实现:代码,测试用例,结果分析,算法思路分析,总结)
说明:博主是大学生,有一门课是算法设计与分析,这是博主记录课程实验报告的内容,题目是老师给的,其他内容和代码均为原创,可以参考学习,转载和搬运需评论吱声并注明出处哦。
4-1算法实现题 汽车加油问题
问题描述:
一辆汽车加满油后可行驶 n 公里。旅途中有若干个加油站。设计一个有效算法,指出应在哪些加油站停靠加油,使沿途加油次数最少。并证明算法能产生一个最优解。
编程任务:
对于给定的 n 和 k 个加油站位置,编程计算最少加油次数。
数据输入:
由文件 input.txt 给出输入数据。第一行有 2 个正整数 n 和 k,表示汽车加满油后可行驶n 公里,且旅途中有 k 个加油站。接下来的 1 行中,有 k+1 个整数,表示第 k 个加油站与第k-1 个加油站之间的距离。第 0 个加油站表示出发地,汽车已加满油。第 k+1 个加油站表示目的地。
结果输出:
将编程计算出的最少加油次数输出到文件 output.txt。如果无法到达目的地,则输出”No Solution”。
输入文件示例
input.txt
7 7
1 2 3 4 5 1 6 6
输出文件示例
output.txt
4
请使用以下测试数据,并在报告中附上结果:
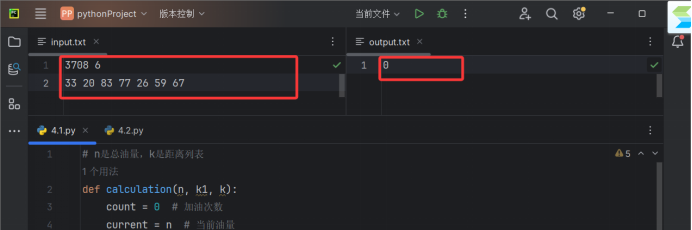
第一组
3708 6
33 20 83 77 26 59 67
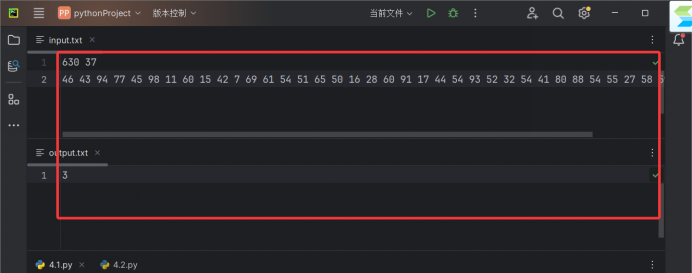
第二组
630 37
46 43 94 77 45 98 11 60 15 42 7 69 61 54 51 65 50 16 28 60 91 17 44 54 93 52 32 54 41 80 88 54 55 27 58 59 92 73
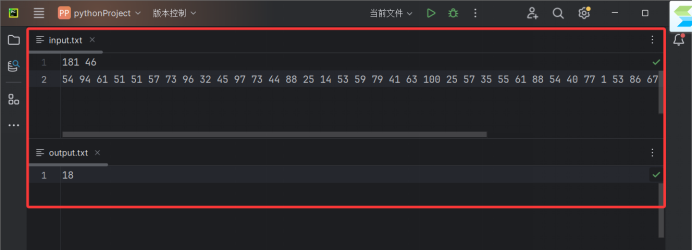
第三组
181 46
54 94 61 51 51 57 73 96 32 45 97 73 44 88 25 14 53 59 79 41 63 100 25 57 35 55 61 88 54 40 77 1 53 86 67 59 13 56 96 56 75 45 37 76 99 41 94
实验代码
# n是总油量,k是距离列表
def calculation(n, k1, k):count = 0 # 加油次数current = n # 当前油量for i in range(k1 + 1):if current >= k[i]:current -= k[i]else:count += 1current = n - k[i]if current < 0:return "No Solution"return count
with open("input.txt", 'r') as file:n, k1 = map(int, file.readline().split())k = list(map(int, file.readline().split()))
with open("output.txt", 'w') as file:file.write(str(calculation(n, k1,k)))
测试用例(示例)

测试用例1
测试用例2
测试用例3
实验结果分析
本次实验利用贪心算法正确实现沿途加油次数最少,可以通过两点证明该算法可以产生最优解,一点是本算法贪心性质的选择:每一步的局部最优选择能导致全局最优解(每次尽可能的使加油的次数最少,当前油量能到达下一站就不加油);一点是最优子结构:问题的最优解包含子问题的最优解(可以用数学归纳法进行证明)
主要算法思路
利用贪心算法,主要思路就是每次选择最好的情况,也就是尽可能使加油次数少,当当前油量可以跑完下一段路时选择不加油,不能跑完就选择加满。我用python实现,遍历所有,每到一个加油站都进行判断,最后返回次数即可。
时间复杂度分析
循环经行了K+1次,K是加油站的个数,内层循环是O(1)的基本操作,所以总时间复杂度为O(K)
实验小结
本次实验是很经典也是很基础的贪心算法的实际应用,在算法的思路方面我没有遇到问题。代码编写过程中,一个卡住的点是map(int, file.readline().split())
,我一开始写为map(file.readline().split(), int)导致结果一直报错,这里提醒了我注意基本语法,函数参数的正确顺序传递问题。
4-2 算法实现题 删数问题
问题描述:
给定 n 位正整数 a,去掉其中任意 k≤n 个数字后,剩下的数字按原次序排列组成一个新的正整数。对于给定的 n 位正整数 a 和正整数 k,设计一个算法找出剩下数字组成的新数最小的删数方案。
编程任务:
对于给定的正整数 a,编程计算删去 k 个数字后得到的最小数。
数据输入:
由文件 input.txt 提供输入数据。文件的第 1 行是 1 个正整数 a。第 2 行是正整数 k。
结果输出:
程序运行结束时,将计算出的最小数输出到文件 output.txt 中。
输入文件示例
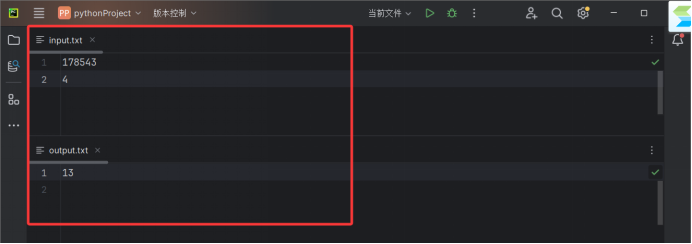
input.txt
178543
4
输出文件示例
output.txt
13
请使用以下测试数据,并在报告中附上结果:
第一组
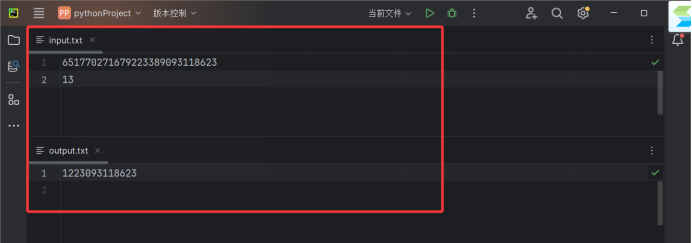
651770271679223389093118623
13
第二组
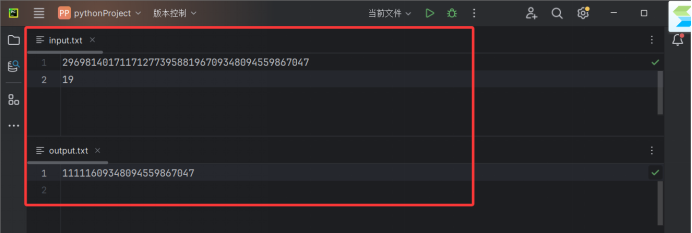
2969814017117127739588196709348094559867047
19
第三组
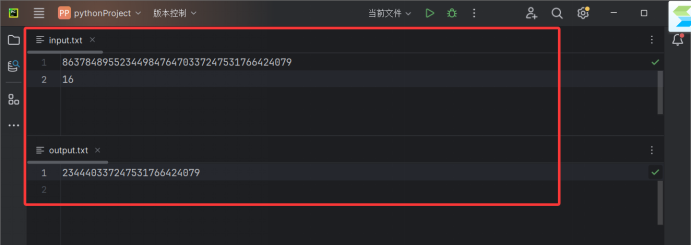
8637848955234498476470337247531766424079
16
实验代码
def remove(a, k):stack = [] # 使用列表作为栈top = -1 # 栈顶指针初始化为-1(表示空栈)for digit in a:# 当还能删除数字,且栈不为空,且当前数字比栈顶数字小while k > 0 and top >= 0 and stack[top] > digit:stack.pop() # 弹出栈顶元素top -= 1 # 栈顶指针减1k -= 1 # 剩余可删除次数减1# 将当前数字压入栈stack.append(digit)top += 1# 如果还有剩余删除次数(比如数字是升序的情况)if k > 0:stack = stack[:top + 1 - k] # 从末尾删除剩余k个数字top = len(stack) - 1# 拼接结果并去除前导零result = ''.join(stack).lstrip('0')return result if result else '0' # 如果结果为空字符串,返回"0"with open('input.txt', 'r') as f:string = f.readline()a = []for i in string:a.append(i)k = int(f.readline())
with open('output.txt', 'w') as f:string_remove = remove(a, k)f.write(string_remove)
测试用例(示例)
测试用例1
测试用例2
测试用例3
实验结果分析:
本次实验成功实现了找出剩下数字组成的新数最小的删数方案,主要思路还是贪心算法,每次从前往后尽可能的删除较大的数。
算法思路:
我一开始的想法也是从前往后删除尽可能大的,为什么是从前往后删?因为前面的数更高位,对整个数的影响更大。而在具体实现方面,我选择用栈来辅助实现,从前往后依次把每个数字入栈。这里有一个卡住的点,我怎么“删除尽可能大的数”,是每当遇到一个比前面大的数就删除吗?这显然是最直观的想法。但是举一个很简单的例子,如果数是“4321”明显从4开始删除,但前面说的这种显然无法进行删除,所以最好的思路就是“遇到一个比前面小的数字,就删除前面的这个数字”,于是便能正确实现“删除尽可能大的数字”。
时间复杂度分析:
外层循环:遍历整个数字字符串,执行n次
内层while循环:每个数字最多被压入和弹出栈各一次 → 所有数字的操作总数是2n
所以总的时间复杂度为O(n)
实验小结:
这道题我有较多的实验心得想要记录,下面附上了我最开始写的不完善有错误的代码,回顾一下几个没考虑到位的点:
- 对于循环的条件:
很明显,我一开始想的是,当数字删除完了,循环就结束了,但是我没有考虑到,最终结果的存放,在Python中,字符串是不可以修改的数据类型,所以我必须用一个新的变量来表示,而最好的就是我用来删除的“栈”。这里就出现了问题,如果用栈来表示,那就必须遍历完所有数字,都要放入栈中,所以循环就应该是遍历整个字符串
- 对于特殊情况,当所有字符升序排列时,前面没有我们要找的“尽可能大的数字”,所以此时要从末尾删除,因为大的数字都在后面。
- 去除前导0:
当有0时,前面的数字不为0,便都是大于0的,所以前面的数字都要删除,此时0在最后会入栈,所以在转换为数字的时候要把前导的0删除。