01-python爬虫-第一个爬虫程序
开始学习 python 爬虫
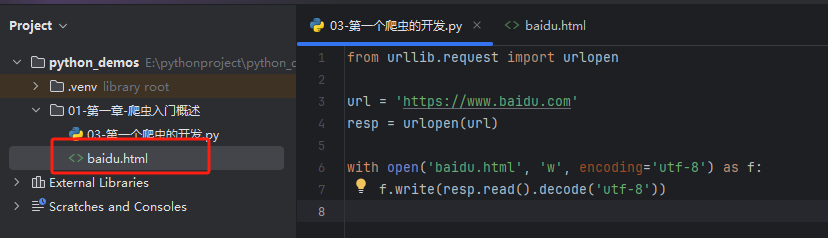
第一个获取使用最多的网站-百度 源代码 并将源代码保存到文件中
from urllib.request import urlopenurl = 'https://www.baidu.com'
resp = urlopen(url)with open('baidu.html', 'w', encoding='utf-8') as f:f.write(resp.read().decode('utf-8'))
知识点:
1. urlopen 打开网址
2. with open 文件操作
3. decode 解码
运行结果: