OpenEMMA: 打破Waymo闭源,首个开源端到端多模态模型
1. 概述
OpenEMMA(Open-source End-to-end Multimodal Model for Autonomous driving)是由德州农工大学、密歇根大学和多伦多大学联合推出的开源端到端自动驾驶多模态模型框架,旨在复现并开源 Waymo 旗下 EMMA 系统的核心思路与方法。
该框架基于预训练的多模态大型语言模型(MLLMs),结合视觉感知和历史驾驶状态,实现对复杂驾驶场景的推理、判断和轨迹规划。借助“链式思维推理”(Chain-of-Thought Reasoning)机制,OpenEMMA 在自动驾驶任务中实现了前所未有的解释性和精度,显著提升了模型在轨迹生成与感知理解方面的能力。此外,框架集成了专门优化的 YOLO 模型用于高精度的 3D 边界框预测,极大地增强了空间感知能力。
OpenEMMA 不仅为学术研究和工业部署提供了坚实的技术基座,更推动了自动驾驶系统的开放化、透明化发展。
-
📄 官方论文:arXiv:2412.15208
-
💻 GitHub 开源地址: https://github.com/taco-group/OpenEMMA
2. 核心技术(技术原理)
OpenEMMA 的核心技术融合了多模态大模型(MLLM)的推理能力与专用视觉模型的高精度感知能力。整个系统围绕“场景理解—行为决策—轨迹预测—对象检测”四个关键步骤构建,具有高度可解释性和工程实用性。
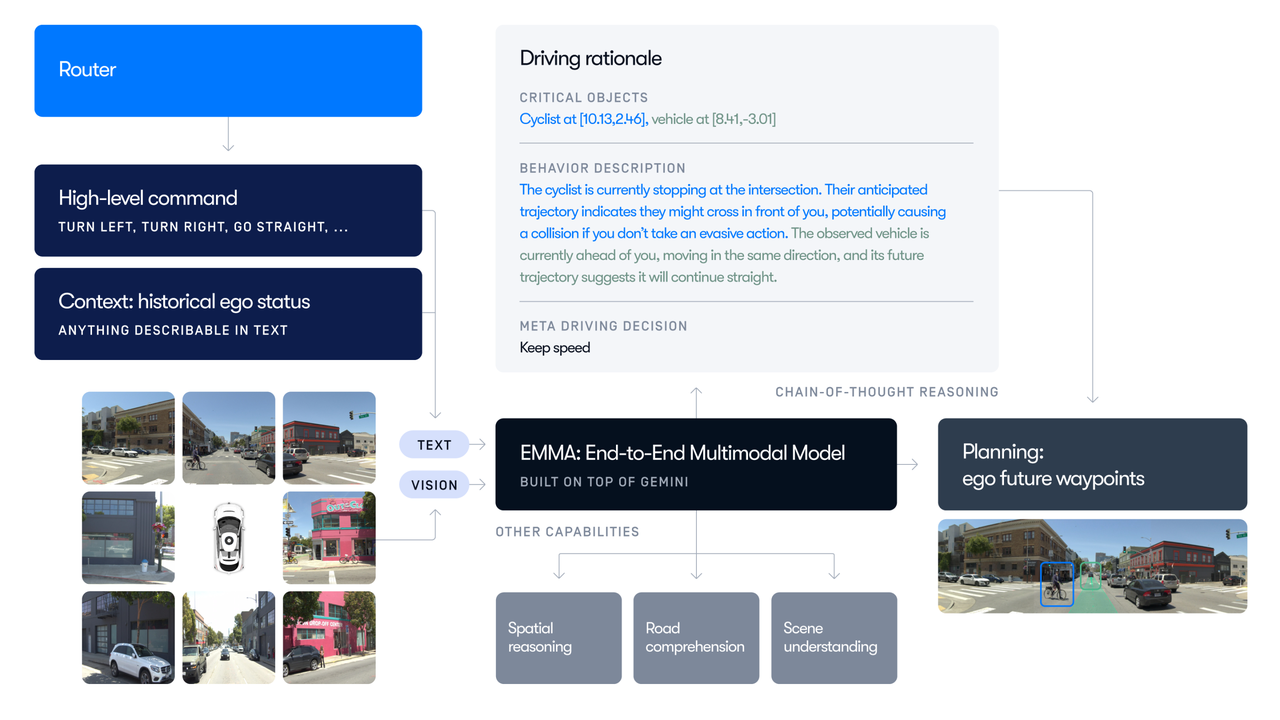
2.1. 基于多模态大模型的链式思维推理
在第一阶段,系统输入的是车辆前视摄像头捕捉到的图像,以及车辆过去五秒钟的速度和行驶曲率信息。然后,通过预先设计的任务提示(prompt),引导 MLLM 模拟驾驶员的思维过程,分步骤分析当前驾驶场景。
具体包括三个方面:
-
驾驶意图推断:系统会判断当前道路条件下车辆应采取的行为,例如直行、变道、左转或右转,并判断是否需要减速或加速;
-
场景理解描述:识别交通信号、车道线、前方行人或车辆等关键信息,生成简洁明了的自然语言场景描述;
-
关键对象分析:定位场景中需要特别关注的道路使用者,比如穿越马路的行人或突然变道的车辆,并分析这些对象对驾驶决策的影响。
这部分不仅完成了对环境的感知,更实现了人类类似的“解释型”推理,为接下来的行为规划打下清晰基础。
2.2. 可解释的轨迹预测机制
在获得场景解释和行为意图后,系统会进一步预测未来几秒内的行驶路径。这一过程不再是“直接输出目标点”,而是先预测每一时刻的速度变化与转向趋势,再通过这些中间变量推导出完整的车辆轨迹。
这种方式类似人类驾驶时的操作:我们不会直接规划终点位置,而是基于“踩多少油门”“打多少方向盘”来不断调整车的运动轨迹。OpenEMMA 的这一设计,使得轨迹生成过程具备更高的可控性与可解释性,也便于未来引入人类反馈机制。
2.3. 专用视觉模型辅助的 3D 目标检测
虽然 MLLMs 在语言理解和整体场景推理上表现优秀,但在精确的三维空间定位任务中仍存在明显不足。为此,OpenEMMA 额外集成了一个专注于单目图像 3D 目标检测的轻量级模型——YOLO3D。
该模型专为单张图像设计,不依赖时间序列信息,能够快速识别图像中所有关键交通参与者的位置、尺寸与朝向。其核心技术在于将二维检测框与三维边界框进行对齐,从而提升空间定位的精度。
这种“通用模型 + 专业模块”的架构设计,使得系统在保持高推理能力的同时,也具备可靠的感知能力,显著提升了整体的安全性和落地能力。
3. 主要功能(系统能力)
OpenEMMA 的整体系统提供了以下几个关键功能模块:
-
端到端轨迹规划
从摄像头图像和自车状态直接学习未来的驾驶动作,完全跳过中间的手工规则和符号化决策模块,实现真正意义上的端到端控制。 -
多模态输入处理
系统同时接收图像和文本格式的状态历史信息,并将驾驶任务转化为一个“视觉问答”(VQA)任务,充分利用 MLLM 的语言推理能力。 -
人类可解释的推理输出
借助链式思维和明确的提示,系统不仅输出轨迹,还能同步输出对当前场景的结构化解释,使其结果具备人类可读性和决策透明性。 -
高精度 3D 目标检测
通过 YOLO3D 实现精准的 3D 道路目标检测,弥补 MLLM 在空间定位方面的不足,并为路径规划提供更可靠的障碍物信息。