Linux(线程概念)
目录
一 虚拟地址到物理地址的转换
1. 操作系统如何管理物理内存:
2. 下面来谈谈虚拟地址如何转换到物理地址:
3. 补充字段:
二 Linux中的线程
1. 先来说说进程:
2. 线程:
3. 线程相比较于进程的优缺点:
4. 线程独有的字段:
5. pthread库:
一 虚拟地址到物理地址的转换
1. 操作系统如何管理物理内存:
假设物理内存是4GB,管理物理内存基本单位是1字节吗?不是,一般是以4KB为一个基本单位,称为页框(页桢),正好操作系统与磁盘交互也是以4KB为基本单位,即读取8个扇区,既然4KB为单位,4GB有很多个4KB,势必也要进行管理吧,这里简单一点当成数组进行管理,实际是伙伴系统/slab....机制。
4GB / 4KB = 1,039,386个4KB,忽略其他字段:页框的使用情况...等。
也就是说数组大小为100w,假设地址从 0 ~ 4GB 编制,第0~1023字节,也就是对应的第0号下标,1024 ~ 2*4KB,对应第二个下标,取模,余数丢掉,所以只要拿着任意的地址都能索引到这个数组的任意下标,反向也能转回到页框的起始地址,当然,这个数组肯定也要在内存中开辟空间,100w * 4 = 400w 字节 -> 4k,每个下标存放页框的起始地址,这个不考虑。
2. 下面来谈谈虚拟地址如何转换到物理地址:
32位平台下:
虚拟地址主要是通过页表转换到物理地址,虚拟地址是 0 ~ 4G,如果按一对一进行映射,页表存放虚拟地址和物理地址的指针,一共4G,也就是4G * 8 = 32G的内存大小,显然是不现实的。
上面是把虚拟地址整体使用了,下面来看看另一个方案。
指针大小也就是 0 ~ 2^32次方,那能不能从这个虚拟地址的bit位入手?
实际上不仅仅只有一个页表,会有一个页目录,和页表。
页目录:存放指针高位前10bit位,也就是 2^10次方,1024,页目录一共1024个项,里面每一项存放的是页表的起始地址。
页表:页目录能索引到页表,页表大小是多少呢?也是1024项,取指针中间的10个bit位,每一项存放的是页框的起始地址,所以页表主要是用来建立页框的起始地址,也就是映射。
还有12bit位干嘛的?
页框是4KB,2^12次方刚好也是4KB,所以后面剩余的12bit是用来在页框中偏移的,页表以及存放的是页框的起始地址了,在进行页内偏移,最终拿到页框中某一个字节。
所以上述方案是利用了指针大小的bit位来进行转换划分的,而不是当整块使用暴力映射。
不同的进程虚拟地址完全一样,索引路径也一样,但最终页表存放的物理地址不一样,也侧面证明了进程是相互独立的,父子进程除外。
最后再来算一算页表和页目录占用内存的大小:
页目录:1024项 + 存放页表的地址:1024 * 4 = 4KB
页表:1024个页目录 + 每个页目录对应的页表也是1024项 + 页表每一项和物理地址的映射也就是存放页框的起始地址 = 1024 * 1024 * 4 = 4M
最终占总大小:4M + 4KB,这是最坏的情况,所有的虚拟地址全用上了,实际可能只会用一点点。
3. 补充字段:
1. 谁拿页表进行寻址呢?
OS?不是,CPU内部集成了一个硬件MMU,作用是用来进行页表转换的,怎么拿到页表?CPU内又有一个寄存器CR3,记录页表的起始地址在交给MMU,自此从MMU出来的就是实际的物理地址。
2. 如果在程序某个地方打了个死循环,MMU每次都要查相同的虚拟地址,是不是没必要啊?所以在CPU内部还有个寄存器TLB,主要用来缓存MMU之前查过的虚拟地址,以便后续省了查表的过程,变相提高了虚拟到物理的转换了。
3. 页表下标存放页框的地址,也就是指针4字节整数(2^32),直接用来索引页框吗?上面说的页框有100w个,2^20次方就是100w,剩下的12位浪费了吗?不是,页表不仅仅只有映射,还有比如该地址对应的对象的读写权限位,用户/内核态标记等字段,所以也就利用了这些剩余的bit位来标记比如虚拟地址是否合法,是否命中物理内存(否则缺页中断)等标记位。
二 Linux中的线程
1. 先来说说进程:
当创建一个进程,加载可执行文件代码和数据,创建内核数据结构:PCB,mm_struct,文件描述符表....等对象,都需要在内存中申请空间,被CPU调度,切换保护进程上下文数据,重新填充pc指针,MMU,TLB,CR3,等一系列的寄存器,每个进程新创建/被切换,带来的开销势必是很大的,这也就是为什么进程是资源分配的基本单位,要什么资源直接给进程分配物理内存。
2. 线程:
上面说的进程,不管是创建,调度等策略,线程是否也需要构建和进程一样的策略呢?如果采用,编码方面肯定复杂,其次比如调度和进程不一样,CPU是不是还要识别是进程还是线程?
所以在Linux中,线程没有单独制定个进程类似的策略,直接共享进程大部分属性,比如:调度算法,CPU一视同仁,不过线程也要有自己的一些其他字段。
既然线程能共享进程内的大部分资源,那么如何理解线程是CPU调度的基本单位?
进程也能被调度,线程也能:
进程调度,当时间片到了切换到下一个进程时,保存上下文更新,CR2指向的页表,TLB缓存内容,全部都失效重新加载新的进程,重新进行TLB缓存预热。
不仅仅是TLB缓存虚拟地址和物理地址的映射,CPU内部还有cache缓存,缓存代码块和数据,比如:访问第10行代码,把第10行代码周边的数据按4KB为基本单位缓存到cache缓存中,下次也能直接读取,不用间接寻址,遵循局部性原理规则,虽然不一定访问到,但极大概率访问到。
最重要的就是TLB,cache缓存,TLB存放高频访问的虚拟地址直接失效,cache缓存存放高频的数据块和代码块,进程会更新导致失效并重新进行寻址加载,而线程共享这些属性,无需更改,直接查,效率要高得多。
在Linux中没有真正的线程,只有轻量级进程(LWP),不管是单进程里面的一个执行流,也是轻量级进程,创建多个线程也是轻量级进程,而轻量级进程就是模拟进程的策略而诞生出来的。
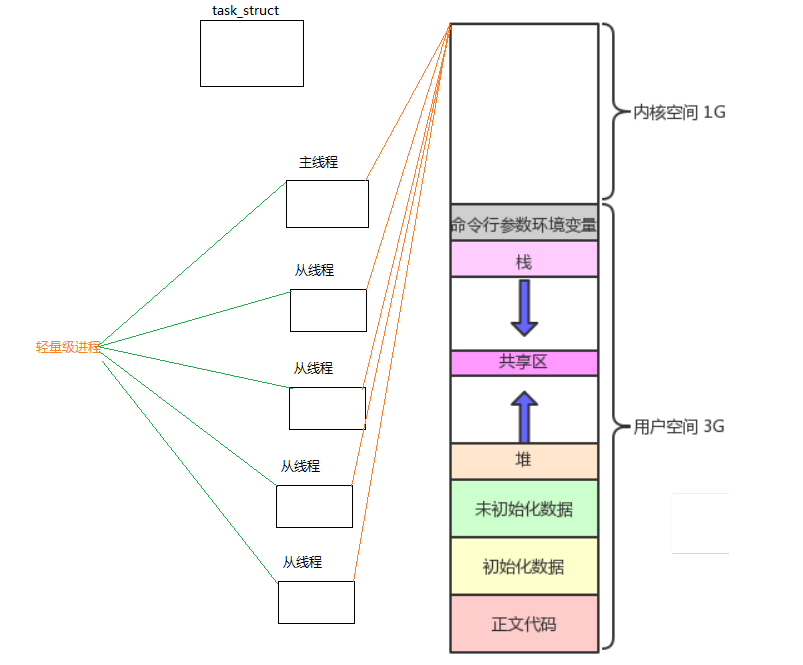
3. 线程相比较于进程的优缺点:
优点:
- 线程占用的资源比进程少,共享进程大部分资源,进程需要重新分配资源
- 线程创建成本小,共享进程大部分资源
- 线程共享进程虚拟地址空间,切换无需更改,进程则需要
- 进程切换会更新TLB快表,cache缓存,导致热数据直接失效,重新访问内存填充
- 线程共享数据容易,进程需要通信机制:fork(),管道,system v,posix通信机制提供的系统调用
缺点:
- 线程共享大部分资源,会导致资源竞争导致数据不一致,静态条件等问题
- 线程创建越多不会导致效率更高,主要以CPU的个数 * CPU的核心数来创建线程对象
- 进程独立不会影响另一个进程,某一个线程异常,其他同级线程也会异常,线程异常代表进程异常,因为线程共享进程大部分属性,OS直接把这个线程有关联的数据全部释放,其他线程也就没意义了
4. 线程独有的字段:
线程ID:多个线程也要有ID区分轻量级进程,总不能这些线程没有编号吧
优先级:调度优先级肯定也会不一样,如果一样先调度谁?
栈:线程执行函数,调用函数就会建立栈帧,如果共享,线程是并发执行的,入栈,弹栈顺 序就乱了
寄存器:不同的线程被切换也要将该线程当前的上下文数据保存起来,下次进行恢复
信号block表:线程共享handler表,block可以自行屏蔽,比如给进程发信号,所有的线程都要执行这个信号,某个线程可以单独屏蔽他不执行。
5. pthread库:
上面说Linux中没有真正的线程,只有LWP,即轻量级进程,所以为了保证操作系统学科的线程的概念,向上封装了一层软件层,pthread库,也就是对轻量级进程接口进行了封装,属于第三方库,使用必须 -lpthread 指定库名,具体pthread库如何管理这些线程,请看下章。