Python与数据分析期末复习笔记
第一次小考自然语言处理
一、单选题(共 29 题,60.0 分)
1.(单选题,3.0 分) 在 matplotlib 中,设置 x 轴标签的方法是?
A. title ()
B. xlabel ()
C. legend ()
D. ylabel ()
正确答案:B 3.0 分
答案解析:xlabel () 方法用于设置 x 轴的标签。
知识点:python matplotlib第 1 题
答案:B
解析:在matplotlib库中,title()函数用于设置图形的标题 ;xlabel()函数专门用于设置x轴的标签,通过它可以自定义x轴的名称等信息;legend()函数是用来添加图例,帮助理解图形中不同元素代表的含义;ylabel()函数用于设置y轴的标签。所以设置x轴标签用xlabel() 。
2.(单选题,2.0 分) 在 matplotlib 中,设置坐标轴范围的方法是?
A. ylim ()
B. axis ()
C. set_xlim ()
D. xlim ()
正确答案:B 2.0 分
答案解析:axis () 方法可以设置坐标轴的范围。
知识点:python matplotlib第 2 题
答案:B
解析:ylim()函数主要用于单独设置y轴的取值范围 ;axis()函数功能较为强大,可以用来设置坐标轴的范围,比如axis([xmin, xmax, ymin, ymax])能同时指定x轴和y轴范围;set_xlim()是matplotlib中Axes对象的方法,用于设置x轴范围,但使用方式和axis()不同;xlim()函数单独用于获取或设置x轴的范围 。本题问设置坐标轴范围的方法,axis()符合题意。
3.(单选题,2.0 分) 不属于自然语言处理应用领域的是 ( )。
A. 口语对话
B. 机器翻译
C. 人脸识别
D. 关键词提取和搜索
正确答案:C 2.0 分第 3 题
答案:C
解析:自然语言处理(NLP)主要是让计算机理解、处理和生成人类自然语言。口语对话系统涉及语音识别、语义理解、回复生成等 NLP 技术;机器翻译是将一种自然语言自动翻译成另一种自然语言,是 NLP 重要应用;关键词提取和搜索是从文本中找出关键信息并实现搜索功能,也属于 NLP 范畴。而人脸识别是基于计算机视觉技术,通过分析图像或视频中的人脸特征进行身份识别等操作,和自然语言处理没有直接关联。
4.(单选题,2.0 分) 自然语言处理融合的学科不包括 ( )。
A. 计算机
B. 语言学
C. 化学
D. 数学
正确答案:C 2.0 分第 4 题
答案:C
解析:自然语言处理是一门融合多学科的领域。计算机科学提供算法、计算资源和编程实现手段;语言学提供语言的结构、语法、语义等理论基础;数学在其中用于构建模型、算法优化等,如概率论用于语言模型概率计算等。而化学主要研究物质的组成、结构、性质及其变化规律,和自然语言处理的关联极小。
5.(单选题,2.0 分)
下面两句代码的运行结果可能为(),with open ('data.txt', 'r') as file:
numbers = [int (line.strip ()) for line in file]。
A. "1,2,3"
B. {1,2,3}
C. (1,2,3)
D. [1,2,3]
正确答案:D 2.0 分第 5 题
答案:D
解析:代码with open('data.txt', 'r') as file: numbers = [int(line.strip()) for line in file] ,with语句用于安全地打开文件,open('data.txt', 'r')以只读模式打开文件。line.strip()用于去除每行字符串两端的空白字符(如换行符等),int()将处理后的字符串转换为整数,整个列表推导式是将文件中每行的数字字符串转换为整数,并收集到一个列表中。列表的表示形式是用方括号[] ,所以结果是列表形式[1,2,3] 。
6.(单选题,2.0 分) 在使用结巴分词进行中文分词时,以下哪个函数用于精确模式分词?
A. jieba.add_word ()
B. jieba.cut ()
C. jieba.lcut ()
D. jieba.cut_for_search ()
正确答案:B
答案解析:jieba.cut () 是结巴分词库中用于精确模式分词的函数。
知识点:python 结巴分词第 6 题
答案:B
解析:jieba.add_word()函数作用是向结巴分词的词库中添加自定义词语,方便分词时能正确识别;jieba.cut()函数是结巴分词用于精确模式分词的核心函数,精确模式下会将句子最精确地切开,适合文本分析等场景;jieba.lcut()和jieba.cut()功能类似,区别在于jieba.lcut()返回的是列表形式,jieba.cut()返回的是可迭代的生成器对象 ;jieba.cut_for_search()是搜索引擎模式分词函数,会对长词进行更细粒度切分以满足搜索需求。
7.(单选题,2.0 分) 在 matplotlib 中,添加图例的方法是?
A. xlabel ()
B. legend ()
C. title ()
D. ylabel ()
正确答案:B 2.0 分
答案解析:legend () 方法用于添加图例。
知识点:python matplotlib第 7 题
答案:B
解析:xlabel()用于设置x轴标签;legend()函数用于在图形中添加图例,当图形中有多种数据系列时,通过图例标识不同系列代表的含义;title()用于设置整个图形的标题;ylabel()用于设置y轴标签。所以添加图例用legend() 。
8.(单选题,2.0 分) 关于结巴分词的分词模式,以下说法错误的是?
A. 搜索引擎模式不会考虑词频
B. 精确模式适合用于文本分析
C. 全模式可以得到尽可能多的切分结果
D. 搜索引擎模式会将长词再次切分
正确答案:A 2.0 分
答案解析:搜索引擎模式会考虑词频,并且会将长词再次切分,以便更好地匹配搜索需求。
知识点:python 结巴分词第 8 题
答案:A
解析:结巴分词的搜索引擎模式会考虑词频,并且会将长词再次切分,目的是更好地匹配搜索需求,所以 A 说法错误。精确模式能最精确地切开句子,在文本分析中能得到相对准确的词语划分,B 说法正确;全模式会尝试所有可能的切分组合,能得到尽可能多的切分结果,C 说法正确;搜索引擎模式会对长词进一步切分,以提高搜索时的召回率等,D 说法正确。
9.(单选题,3.0 分) 文件读写操作函数 open () 中的输入参数 encoding 说法不对的是 ( )。
A. 指定对文本进行编码和解码的方式
B. 适用于文本模式,图像模式,音频模式
C. 支持如 GBK、utf8、CP936 等格式
D. 默认取值是 None
正确答案:B 3.0 分第 9 题
答案:B
解析:在open()函数中,encoding参数用于指定对文本进行编码和解码的方式 ,A 说法正确;它主要适用于文本模式,用于处理文本文件的字符编码问题,而图像模式、音频模式有各自专门的处理方式和参数,并不适用encoding参数,B 说法错误;它支持如GBK、utf - 8、CP936等多种常见的字符编码格式,C 说法正确;其默认取值是None ,此时会使用系统默认的编码方式,D 说法正确。
10.(单选题,2.0 分) 在 Python 中,用于生成词云的库是?
A. numpy
B. pandas
C. wordcloud
D. matplotlib
正确答案:C 2.0 分
答案解析:wordcloud 是一个专门用于生成词云的 Python 库。
知识点:python 词云第 10 题
答案:C
解析:numpy是 Python 中用于数值计算的库,提供大量数值计算功能,如数组操作、数学运算等,和词云生成无关;pandas是用于数据处理和分析的库,可进行数据清洗、分析、存储等操作,不用于词云生成;wordcloud是专门用于生成词云的 Python 库,通过它可以根据文本数据生成可视化的词云图;matplotlib是功能强大的绘图库,可绘制多种图表,但不是专门用于生成词云的库。
11.(单选题,2.0 分) 在生成词云时,以下哪个参数可以用来设置词云的字体路径?
A. background_color
B. width
C. height
D. font_path
正确答案:D 2.0 分
答案解析:font_path 参数用于设置词云使用的字体路径。
知识点:python 词云第 11 题
答案:D
解析:在使用 Python 的wordcloud库生成词云时,background_color参数是用来设置词云背景颜色的;width用于设置词云图片的宽度;height用于设置词云图片的高度;而font_path参数专门用于指定词云所使用字体的路径,这样就能按照设定字体来展示词云中的文字 。
12.(单选题,2.0 分) 在 matplotlib 中,设置图表标题的方法是?
A. title ()
B. legend ()
C. xlabel ()
D. ylabel ()
正确答案:A 2.0 分
答案解析:title () 方法用于设置图表的标题。
知识点:python matplotlib第 12 题
答案:A
解析:在matplotlib绘图库中,title()函数的作用就是给绘制的图表添加标题,用于概括图表的主要内容;legend()函数是添加图例,帮助理解图表中不同元素的含义;xlabel()是设置x轴的标签;ylabel()是设置y轴的标签 。
13.(单选题,2.0 分) 以下哪种方式可以加载自定义词典到结巴分词中?
A. jieba.add_word ()
B. jieba.lcut ()
C. jieba.cut ()
D. jieba.load_userdict ()
我的答案:D 正确答案:D 2.0 分
答案解析:jieba.load_userdict () 用于加载自定义词典到结巴分词中。
知识点:python 结巴分词第 13 题
答案:D
解析:jieba.add_word()是向结巴分词词典中临时添加单个词语;jieba.lcut()是结巴分词的一种快速全模式分词方式,返回的是列表形式的分词结果;jieba.cut()是结巴分词的核心分词函数,可进行精确模式、全模式等多种模式分词;jieba.load_userdict()函数用于加载用户自定义的词典文件,将其中的词语添加到结巴分词的词库中,以便在分词时能正确识别这些自定义词语 。
14.(单选题,2.0 分) 使用结巴分词进行全模式分词时,以下哪个选项正确描述了其特点?
A. 只返回最可能的一个切分结果
B. 根据用户自定义词典进行分词
C. 返回最少的切分结果
D. 返回尽可能多的切分结果
我的答案:D 正确答案:D 2.0 分
答案解析:全模式分词的特点是返回尽可能多的切分结果,以覆盖更多的可能性。
知识点:python 结巴分词第 14 题
答案:D
解析:结巴分词的精确模式会返回最可能的一个切分结果,A 选项描述的是精确模式特点;根据用户自定义词典分词不是全模式特有的,多种模式都可结合自定义词典分词,B 选项错误;全模式是尝试所有可能的切分,返回的切分结果较多,而不是最少,C 选项错误;全模式分词会返回尽可能多的切分结果,涵盖各种可能的词语组合,这样可以覆盖更多语义理解的可能性 ,D 选项正确。
15.(单选题,2.0 分) 在生成词云时,以下哪个参数可以用来设置词云的形状?
A. mask
B. height
C. background_color
D. width
我的答案:A 正确答案:A 2.0 分
答案解析:mask 参数用于设置词云的形状模板。
知识点:python 词云第 15 题
答案:A
解析:在生成词云时,mask参数是传入一个形状模板,词云会按照这个模板的形状来生成,比如传入一个心形模板,词云就会呈现心形;height和width分别是设置词云图片的高度和宽度;background_color是设置词云的背景颜色 。
16.(单选题,2.0 分) 在结巴分词中,如果需要添加一个新词到分词词典中,应该使用哪个方法?
A. jieba.cut ()
B. jieba.add_word ()
C. jieba.lcut ()
D. jieba.load_userdict ()
我的答案:B 正确答案:B 2.0 分
答案解析:jieba.add_word () 用于向分词词典中添加新词。
知识点:python 结巴分词第 16 题
答案:B
解析:jieba.cut()主要功能是进行分词操作,无论是精确模式、全模式等;jieba.add_word()函数可以向结巴分词的词典中添加单个新词,使其在后续分词时能正确识别;jieba.lcut()是快速全模式分词并返回列表形式结果;jieba.load_userdict()是加载整个自定义词典文件,而不是添加单个新词 。
17.(单选题,2.0 分) 在 matplotlib 中,用于绘制折线图的基本函数是?
A. scatter ()
B. plot ()
C. bar ()
D. hist ()
我的答案:B 正确答案:B 2.0 分
答案解析:plot () 函数是 matplotlib 中最常用的函数之一,用于绘制二维图形中的折线图。
知识点:python matplotlib第 17 题
答案:B
解析:在matplotlib库中,scatter()函数是用于绘制散点图,展示数据点的分布情况;plot()函数是绘制折线图的基本函数,通过传入一系列的坐标点,将这些点连接起来形成折线;bar()函数是用于绘制柱状图;hist()函数主要用于绘制直方图,展示数据的分布频率 。
18.(单选题,2.0 分) 以下哪项不是结巴分词的功能?
A. 支持关键词提取
B. 支持中文分词
C. 支持词性标注
D. 支持自定义词典
我的答案:A 正确答案:A 2.0 分
答案解析:结巴分词主要功能包括中文分词、支持自定义词典等,但不直接支持关键词提取。
知识点:python 结巴分词第 18 题
答案:A
解析:结巴分词主要的功能是对中文文本进行分词处理,将句子拆分成一个个词语;它也支持词性标注,能够给分出来的词标注词性;同时支持用户加载自定义词典,让分词更符合特定需求。但关键词提取不是结巴分词直接具备的功能,通常需要借助其他算法或库(如textrank等)来实现 。
19.(单选题,2.0 分) ()第三方库不能用于 xlsx 文件的读写操作。
A. xlrd
B. pyecharts
C. openpyxl
D. xlwt
我的答案:B 正确答案:B 2.0 分
知识点:第 19 题
答案:B
解析:xlrd库用于读取 Excel 文件(包括.xlsx格式 ),获取其中的数据内容;openpyxl库可以对.xlsx格式的 Excel 文件进行读写操作,能方便地处理单元格数据、样式等;xlwt库主要用于创建和写入 Excel 文件(.xls格式,也能在一定程度上支持.xlsx相关操作 );而pyecharts是一个用于绘制各种交互式可视化图表(如折线图、柱状图、饼图等 )的 Python 库,它不用于 Excel 文件(.xlsx)的读写操作 。
20.(单选题,2.0 分) 在生成词云时,以下哪个参数可以用来设置词云的最大字体大小?
A. min_font_size
B. max_words
C. max_font_size
D. width
我的答案:C 正确答案:C 2.0 分
答案解析:max_font_size 参数用于设置词云中最大的字体大小。
知识点:python 词云第 20 题
答案:C
解析:在wordcloud库中,min_font_size参数用于设置词云中最小的字体大小;max_words参数是设置词云中显示的最多词语数量;max_font_size参数则是用来设置词云中最大的字体大小,词频越高的词在词云中字体可能越大,但最大不会超过max_font_size设置的值;width是设置词云图片的宽度 。
21(单选题,2.0 分) 在 matplotlib 库中,绘制饼状图的类是 ( )。
A. Bar
B. Pie
C. Line
D. Graph
正确答案:B 2.0 分第 21 题
答案:B
解析:在matplotlib库中,Bar并不是专门绘制饼状图的类 ;Pie类用于绘制饼状图,可展示各部分占总体的比例关系;Line一般用于和绘制折线相关 ;Graph不是matplotlib中绘制饼状图的类。
22.(单选题,2.0 分) 有关数据分析的说法,错误的是 ( )。
A. 数据分析师的工作内容是处理临时需求,报表开发,数据分析和挖掘,数据产品化
B. 通信供应商,可以通过构建一张 “社交图谱”,分析客户数百万个电话的数据记录,根据大数据分析的结果,制定相应的套餐
C. 收集到的数据往往存在重复、缺失、异常值等问题,需要进行数据清洗与处理,处理完的数据可以更好地用于后续的数据分析和模型训练,提高数据的质量和可靠性
D. 做数据分析方向,需要继续学习 Python 爬虫、数据清洗、分析、可视化等,但 Hadoop、Hive、Spark 等技术可以不用掌握
正确答案:D 2.0 分第 22 题
答案:D
解析:数据分析师工作涵盖处理临时需求、报表开发、数据分析挖掘以及数据产品化等,A 选项正确;通信供应商利用大数据构建 “社交图谱” 分析电话数据记录来制定套餐是常见应用,B 选项正确;原始数据常存在重复、缺失、异常值等问题,经数据清洗处理后能提升质量用于后续分析和模型训练,C 选项正确;在数据分析领域,Hadoop、Hive、Spark 等技术在大数据存储、处理和分析中应用广泛,是需要掌握的重要技术,D 选项错误。
23.(单选题,2.0 分) 在 matplotlib 中,用于绘制柱状图的基本函数是?
A. bar ()
B. plot ()
C. hist ()
D. scatter ()
正确答案:A
答案解析:bar () 函数用于绘制柱状图。
知识点:python matplotlib第 23 题
答案:A
解析:bar()函数是matplotlib中专门用于绘制柱状图的函数;plot()主要用于绘制折线图;hist()用于绘制直方图,展示数据的分布情况;scatter()用于绘制散点图,观察数据点的分布关系 。
24.(单选题,2.0 分) 在 Python 中,哪个库主要用于自然语言处理?
A. scikit-learn
B. nltk
C. pandas
D. numpy
我的答案:B 正确答案:B 2.0 分
答案解析:nltk 是 Python 中最常用的自然语言处理库之一。
知识点:python 自然语言处理第 24 题
答案:B
解析:scikit-learn主要用于机器学习任务,如分类、回归、聚类等;nltk(Natural Language Toolkit)是 Python 中常用的自然语言处理库,提供了分词、词性标注、命名实体识别等众多功能;pandas主要用于数据处理和分析,方便数据的读取、清洗、转换等操作;numpy主要用于数值计算,提供高效的数组操作和数学运算功能 。
25.(单选题,2.0 分) excel 文件读写不需要安装的第三方模块是 ( )。
A. xlwt
B. xlrd
C. openpyxl
D. sqlite3
我的答案:D 正确答案:D 2.0 分第 25 题
答案:D
解析:xlwt用于写入 Excel 文件;xlrd用于读取 Excel 文件;openpyxl可对 Excel 文件(.xlsx格式 )进行读写操作;sqlite3是 Python 内置的用于操作 SQLite 数据库的模块,和 Excel 文件读写无关 。
26.(单选题,2.0 分) 在 Python 的数据可视化库中,哪个库主要用于生成静态、动态和交互式的图表?
A. seaborn
B. matplotlib
C. bokeh
D. plotly
正确答案:B
答案解析:matplotlib 是 Python 中最常用的绘图库,可以生成各种类型的图表。
知识点:python 数据分析第 26 题
答案:B
解析:seaborn是基于matplotlib的用于绘制统计图表的库,主要侧重于静态图表绘制;matplotlib是 Python 中常用的绘图库,能绘制多种静态图表;bokeh可创建交互式图表;plotly也能创建交互式图表。但matplotlib功能全面,可生成静态、动态和交互式的图表(结合相关扩展 ),是最符合题意的常用绘图库 。
27.(单选题,2.0 分) 在文件处理中,读取整行的函数是 ( )。
A. file.write ()
B. file.read ()
C. file.readline ()
D. file.tell ()
我的答案:C 正确答案:C 2.0 分第 27 题
答案:C
解析:file.write()用于向文件写入内容;file.read()用于读取文件的全部内容;file.readline()用于逐行读取文件内容,每次读取一行;file.tell()用于获取文件指针当前位置 。
28.(单选题,2.0 分) 在 matplotlib 中,用于调整图像大小的方法是?
A. plot ()
B. savefig ()
C. figure ()
D. show ()
正确答案:C 2.0 分
答案解析:figure () 方法可以用来创建一个新的图像,并且可以通过参数调整图像的大小。
知识点:python matplotlib第 28 题
答案:C
解析:plot()用于绘制折线图等图形;savefig()用于保存图形;figure()函数可以创建一个新的图形对象,并且可以通过设置figsize等参数来调整图像大小;show()用于显示图形 。
29.(单选题,2.0 分) 在生成词云时,以下哪个参数可以用来设置词云的最大单词数量?
A. width
B. max_words
C. min_font_size
D. max_font_size
正确答案:B 2.0 分
答案解析:max_words 参数用于设置词云中最大单词的数量。
知识点:python 词云第 29 题
答案:B
解析:在生成词云时,width用于设置词云图片的宽度;max_words参数用于设定词云中显示的最大单词数量;min_font_size用于设置词云中最小字体大小;max_font_size用于设置词云中最大字体大小 。
二、填空题(共 2 题,10.0 分)
30.(填空题,5.0 分) 在 Python 中,使用_____库可以方便地进行中文分词。
我的答案:(1) jieba
正确答案:(1) jieba
答案解析:jieba 是 Python 中一个非常流行的中文分词库。
知识点:python 自然语言处理第 30 题
答案:jieba
解析:jieba是 Python 中广泛使用的中文分词库,支持精确模式、全模式、搜索引擎模式等多种分词模式,能满足不同场景下的中文分词需求 。
31.(填空题,5.0 分) 在 Python 的数据分析中,使用 matplotlib 库绘制图表时,可以通过调用 plt._____() 方法来展示图形。
我的答案:(1) show
正确答案:(1) show
答案解析:在 matplotlib 中,plt.show () 方法用于展示已经创建好的图形。
知识点:python 数据分析第 31 题
答案:show
解析:在使用matplotlib库绘制图表后,需要调用plt.show()函数来显示绘制好的图形。它会启动图形用户界面,将内存中绘制的图形展示出来 。
三、论述题(共 1 题,30.0 分)
32. (论述题, 30.0 分)
根据第1个案例四大名著的自然语言处理,请完成以下任务:
A撰写一个自然语言处理编程文档,从程序实现的功能,设计思想,用到主要的库和库函数介绍,测试数据,输出结果等方面总结,并发布到你的技术博客中。
B完善自然语言处理程序,把各个功能写成函数形式,在主程序中调用。比如分词功能,词频统计功能,词性分类保存txt功能,读取txt文件生成饼状图可视化功能,柱状图可视化功能,关系图可视化功能,词云可视化功能,建立人工手动自定义词典功能,统计人名并保存txt功能,统计地名并保存txt功能,统计武器并保存txt功能。把代码发布到你的技术博客中。
根据完成情况(有代码,有文档,有设计,有分析,有结果),做成教程形式,发表在博客上酌情给分。
答:播客连接
第二次小考 微信好友数据分析案例
一、单选题(共 40 题,40.0 分)
1.(单选题,1.0 分) 在 PyEcharts 中,设置图表标题的方法是?
A. add_title
B. add
C. title
D. set_title
正确答案:C
答案解析:在 PyEcharts 中,可以通过 title 方法来设置图表的标题。
知识点:python pyecharts第 1 题答案:C
解析:在 PyEcharts 中,title方法用于设置图表标题 。add_title、add 、set_title都不是其设置标题的正确方法。
2.(单选题,1.0 分) ( ) 是大数据分析师不需要学习的。
A. python
B. Spark
C. 机器学习
D. 计算机硬件
正确答案:D 1.0 分第 2 题
答案:D
解析:大数据分析师工作涉及数据处理、分析和建模等,Python 是常用编程语言,掌握它便于数据处理和算法实现;Spark 是大数据处理框架,可处理大规模数据;机器学习在数据分析、预测建模等方面应用广泛。而计算机硬件知识对大数据分析师并非必需,他们主要关注数据层面操作 。
3.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据可视化?
A. seaborn
B. numpy
C. pandas
D. matplotlib
正确答案:A
答案解析:Seaborn 是一个基于 matplotlib 的高级数据可视化库,提供了更丰富的绘图功能和美观的样式。
知识点:python 人工智能第 3 题
答案:A
解析:seaborn是基于matplotlib的高级数据可视化库,能绘制美观且功能丰富的统计图表;numpy主要用于数值计算,提供高效数组操作;pandas侧重数据处理和分析,如数据读取、清洗等;matplotlib是基础绘图库,seaborn在其基础上进行了更高级封装 。
4.(单选题,1.0 分) 可以做中文文本情感分析的第三方库是 ( )。
A. itchat
B. snownlp
C. urllib
D. matplotlib
正确答案:B 1.0 分第 4 题
答案:B
解析:itchat用于微信个人号的接口调用,实现微信消息收发等功能;snownlp是中文自然语言处理库,具备情感分析功能,可判断文本情感倾向;urllib是 Python 用于处理 URL 相关操作的标准库,用于网络请求等;matplotlib是绘图库 。
5.(单选题,1.0 分) 在微信好友数据分析与可视化案例中,对 ( ) 数据的分析可以得知微信好友是否有打广告嫌疑。
A. 生日
B. 性别
C. 省份
D. 昵称
我的答案:D 正确答案:D 1.0 分第 5 题
答案:D
解析:微信好友的昵称有时会包含广告相关词汇或推广信息,通过分析昵称可判断是否有打广告嫌疑;生日、性别、省份这些信息与广告嫌疑关联性不大 。
6.(单选题,1.0 分) 在 PyEcharts 中,设置图表大小的方法是?
A. height
B. width 和 height
C. width
D. size
我的答案:B 正确答案:B 1.0 分
答案解析:在 PyEcharts 中,可以通过 width 和 height 参数设置图表的大小。
知识点:python pyecharts第 6 题
答案:B
解析:在 PyEcharts 中,通过设置width(宽度)和height(高度)这两个参数来确定图表大小 ,仅设置height或width不能完整确定大小,size不是设置图表大小的参数 。
7.(单选题,1.0 分) pip install echarts - countries - pypkg 的意思是安装 ( ) 地图文件包。
A. 黑龙江省各区县
B. 美国省份
C. 世界
D. 中国省份
正确答案:D第 7 题
答案:D
解析:pip install echarts - countries - pypkg 安装的是中国省份地图文件包,用于在 PyEcharts 中绘制涉及中国省份相关地理信息的图表 。
8.(单选题,1.0 分) 在 PyEcharts 中,设置图表颜色的方法是?
A. colors
B. set_color
C. color
D. set_option ('color', value)
正确答案:D
答案解析:在 PyEcharts 中,设置图表颜色的方法是通过 set_option ('color', value) 来实现。
知识点:python pyecharts第 8 题
答案:D
解析:在 PyEcharts 中,设置图表颜色需通过set_option('color', value) 这种方式,colors 、set_color 、color都不是正确设置图表颜色的方法 。
9.(单选题,1.0 分) 在 PyEcharts 中,设置图表图例的方法是?
A. legend_show
B. legend
C. show_legend
D. legends
我的答案:B 正确答案:B 1.0 分
答案解析:在 PyEcharts 中,可以通过 legend 方法设置图表的图例。
知识点:python pyecharts第 9 题
答案:B
解析:在 PyEcharts 中,使用legend方法来设置图表图例,legend_show 、show_legend 、legends都不是正确设置图例的方法 。
10.(单选题,1.0 分) 在 Python 的数据分析中,哪个库主要用于数据处理和分析?
A. matplotlib
B. scikit-learn
C. pandas
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析:pandas 是 Python 中最常用的数据处理和分析库之一,提供了丰富的数据结构和数据分析工具。
知识点:python 数据分析第 10 题
答案:C
解析:matplotlib主要用于绘图和数据可视化;scikit-learn用于机器学习任务,如分类、回归等;pandas提供了Series和DataFrame等数据结构,方便进行数据的读取、清洗、转换、分析等操作;numpy主要用于数值计算 。
11.(单选题,1.0 分) 在 PyEcharts 中,设置图表高度的方法是?
A. set_height
B. figure_height
C. chart_height
D. height
正确答案:D
答案解析:在 PyEcharts 中,设置图表高度的方法是通过 height 参数。
知识点:python pyecharts第 11 题
答案:D
解析:在 PyEcharts 中,通过height参数设置图表高度,set_height 、figure_height 、chart_height都不是设置图表高度的正确方式 。
12.(单选题,1.0 分) class pyecharts.charts.Pie () 中的 data_pair 意思是 ( )
A. 设置标题颜色
B. 系列数据项,格式为 [(key1,value1),(key2,value2)]
C. 饼图的半径,设置成默认百分比
D. 该饼图的名称
我的答案:B 正确答案:B 1.0 分第 12 题
答案:B
解析:在pyecharts库中,Pie类的data_pair参数用于指定系列数据项,其格式为[(key1, value1), (key2, value2)],其中每个元组表示一个数据点,键为标签,值为对应的数值。
13.(单选题,1.0 分) 在 PyEcharts 中,用于创建散点图的类是?
A. Line
B. Bar
C. Pie
D. Scatter
我的答案:D 正确答案:D 1.0 分
答案解析:在 PyEcharts 中,用于创建散点图的类是 Scatter。
知识点:python pyecharts第 13 题
答案:D
解析:Line类用于创建折线图,Bar类用于创建柱状图,Pie类用于创建饼图,而Scatter类专门用于创建散点图,通过散点的分布展示数据的关系。
14.(单选题,1.0 分) 在 PyEcharts 中,设置 X 轴标签的方法是?
A. set_x_axis
B. x_axis
C. x_label
D. x_ticks
正确答案:B
答案解析:在 PyEcharts 中,可以通过 x_axis 参数设置 X 轴的标签。
知识点:python pyecharts第 14 题
答案:B
解析:在pyecharts中,设置 X 轴标签的正确方法是使用x_axis参数,例如chart.add_xaxis(['A', 'B', 'C'])。set_x_axis不是标准方法,x_label和x_ticks也不是正确的参数名称。
15.(单选题,1.0 分) 在 PyEcharts 中,设置图表主题的方法是?
A. chart_theme
B. theme
C. set_option ('theme', value)
D. set_theme
正确答案:B
答案解析:在 PyEcharts 中,设置图表主题的方法是通过 theme 属性来实现。
知识点:python pyecharts第 15 题
答案:B
解析:设置图表主题的方法是通过theme参数,例如
Pie(init_opts=opts.InitOpts(theme="light"))。set_option('theme', value)是不正确的用法,chart_theme和set_theme也不是标准方法。
16.(单选题,1.0 分) 在 PyEcharts 中,设置图表宽度的方法是?
A. set_option ('width', value)
B. chart_width
C. width
D. set_width
正确答案:C
答案解析:在 PyEcharts 中,设置图表宽度的方法是通过 width 属性来实现。
知识点:python pyecharts第 16 题
答案:C
解析:在pyecharts中,设置图表宽度的正确方法是使用width参数,例如Pie(init_opts=opts.InitOpts(width="800px"))。set_width和chart_width不是标准方法,set_option('width', value)的写法也不正确。
17.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据可视化?
A. matplotlib
B. numpy
C. scikit-learn
D. pandas
我的答案:A 正确答案:A 1.0 分
答案解析:matplotlib 是一个用于绘制图表和图形的 Python 库,广泛应用于数据可视化。
知识点:python 人工智能第 17 题
答案:A
解析:matplotlib是 Python 中最常用的数据可视化库,提供了丰富的绘图功能。numpy用于数值计算,pandas用于数据处理,scikit-learn用于机器学习,它们都不是专门的数据可视化库。
18.(单选题,1.0 分) 在 PyEcharts 中,设置图表标题的方法是?
A. set_option
B. add_title
C. title
D. set_title
正确答案:C
答案解析:在 PyEcharts 中,设置图表标题的方法是通过 title () 方法。
知识点:python pyecharts第 18 题
答案:C
解析:设置图表标题的正确方法是使用title参数,例如
Pie().set_global_opts(title_opts=opts.TitleOpts(title="饼图示例"))。add_title和set_title不是标准方法,set_option需要配合正确的配置项使用。
19.(单选题,1.0 分) 在 Python 中,哪个库主要用于图像处理?
A. matplotlib
B. pandas
C. opencv
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析:OpenCV 是一个用于计算机视觉和图像处理的强大库。
知识点:python 人工智能第 19 题
答案:C
解析:opencv(Open Source Computer Vision Library)是专门用于计算机视觉和图像处理的库,提供了各种图像处理算法。matplotlib主要用于绘图,pandas用于数据处理,numpy用于数值计算,它们都不是专门的图像处理库。
20.(单选题,1.0 分) 在 PyEcharts 中,用于创建饼图的类是?
A. Pie
B. Scatter
C. Line
D. Bar
我的答案:A 正确答案:A 1.0 分
答案解析:在 PyEcharts 中,用于创建饼图的类是 Pie。
知识点:python pyecharts第 20 题
答案:A
解析:Pie类专门用于创建饼图,Scatter用于散点图,Line用于折线图,Bar用于柱状图。
21.(单选题,1.0 分) 在 PyEcharts 中,设置图表颜色的方法是?
A. series_color
B. colors
C. color
D. item_color
正确答案:D
答案解析:在 PyEcharts 中,可以通过 item_color 参数设置图表的颜色。
知识点:python pyecharts第 21 题
答案:D
解析:在 PyEcharts 中,设置图表颜色的正确方法是通过item_color参数。其他选项如series_color、colors、color均不是标准的设置颜色的参数。
22.
(单选题,1.0 分) 在 PyEcharts 中,设置 X 轴标签的方法是?
A. x_axis
B. x_label
C. x_axis_labels
D. x_ticks
我的答案:A 正确答案:A 1.0 分
答案解析:在 PyEcharts 中,可以通过 x_axis 参数设置 X 轴的标签。
知识点:python pyecharts第 22 题
答案:A
解析:在 PyEcharts 中,设置 X 轴标签的方法是使用x_axis参数。例如:
chart.add_xaxis(["A", "B", "C"])。x_label、x_axis_labels、x_ticks都不是正确的参数名称。
23.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据处理和分析?
A. numpy
B. matplotlib
C. pandas
D. scikit-learn
我的答案:C 正确答案:C 1.0 分
答案解析:Pandas 是一个强大的数据处理和分析库,提供了丰富的数据结构和数据分析工具。
知识点:python 人工智能第 23 题
答案:C
解析:pandas是 Python 中用于数据处理和分析的核心库,提供了DataFrame和Series等高效的数据结构。numpy主要用于数值计算,matplotlib用于数据可视化,scikit-learn用于机器学习。
24.(单选题,1.0 分) 在 PyEcharts 中,设置 Y 轴标签的方法是?
A. y_label
B. y_ticks
C. y_axis
D. set_y_axis
我的答案:C 正确答案:C 1.0 分
答案解析:在 PyEcharts 中,可以通过 y_axis 参数设置 Y 轴的标签。
知识点:python pyecharts第 24 题
答案:C
解析:在 PyEcharts 中,设置 Y 轴标签的方法是使用y_axis参数。例如:chart.add_yaxis("数据", [1, 2, 3])。y_label、y_ticks、set_y_axis都不是正确的参数名称。
25.(单选题,1.0 分) 在 PyEcharts 中,设置图表图例的方法是?
A. set_option ('legend', value)
B. chart_legend
C. legend
D. set_legend
正确答案:C
答案解析:在 PyEcharts 中,设置图表图例的方法是通过 legend 属性来实现。
知识点:python pyecharts第 25 题
答案:C
解析:在 PyEcharts 中,设置图例的方法是通过legend属性。例如:chart.set_global_opts(legend_opts=opts.LegendOpts(is_show=True))。set_option('legend', value)的写法不正确,chart_legend和set_legend也不是标准方法。
26.(单选题,1.0 分) 在 PyEcharts 中,用于创建折线图的类是?
A. Line
B. Bar
C. Scatter
D. Pie
我的答案:A 正确答案:A 1.0 分
答案解析:Bar 用于柱状图,Line 用于折线图,Pie 用于饼图,Scatter 用于散点图。
知识点:python pyecharts第 26 题
答案:A
解析:在 PyEcharts 中,Line类用于创建折线图,Bar类用于柱状图,Scatter类用于散点图,Pie类用于饼图。
27.(单选题,1.0 分) Echarts 是一个由 ( ) 开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。
A. 谷歌
B. 百度
C. 苹果
D. 腾讯
我的答案:B 正确答案:B 1.0 分第 27 题
答案:B
解析:Echarts 是由百度开源的数据可视化库,而 PyEcharts 是其 Python 接口。谷歌、苹果、腾讯均未开发 Echarts。
28.(单选题,1.0 分) 在 PyEcharts 中,设置 X 轴标签的方法是?
A. x_axis
B. x_label
C. x_ticks
D. set_xaxis
我的答案:A 正确答案:A 1.0 分
答案解析:在 PyEcharts 中,设置 X 轴标签的方法是通过 x_axis 参数。
知识点:python pyecharts第 28 题
答案:A
解析:同第 22 题,设置 X 轴标签的方法是通过x_axis参数。
29.(单选题,1.0 分) 在 PyEcharts 中,设置 Y 轴标签的方法是?
A. y_label
B. y_ticks
C. y_axis
D. set_yaxis
我的答案:C 正确答案:C 1.0 分
答案解析:在 PyEcharts 中,设置 Y 轴标签的方法是通过 y_axis 参数。
知识点:python pyecharts第 29 题
答案:C
解析:同第 24 题,设置 Y 轴标签的方法是通过y_axis参数。
30.(单选题,1.0 分) 在 PyEcharts 中,设置图表背景色的方法是?
A. background
B. bgcolor
C. back_color
D. bg_color
正确答案:D
答案解析:在 PyEcharts 中,可以通过 bg_color 参数设置图表的背景色。
知识点:python pyecharts第 30 题
答案:D
解析:在 PyEcharts 中,设置图表背景色的正确参数是bg_color。例如:
chart.set_global_opts(bg_color="white")。其他选项如background、bgcolor、back_color均不是标准参数。
31.(单选题,1.0 分) 在 PyEcharts 中,设置图表宽度的方法是?
A. set_width
B. chart_width
C. width
D. width_set
正确答案:C
答案解析:在 PyEcharts 中,可以通过 width 参数设置图表的宽度。
知识点:python pyecharts第 31 题
答案:C
解析:在 PyEcharts 中,设置图表宽度的方法是通过width参数。例如:
Line(init_opts=opts.InitOpts(width="1000px"))。set_width、chart_width、width_set都不是正确的参数名称。
32.(单选题,1.0 分) 在 Python 的数据可视化库中,哪个库主要用于生成静态、动态和交互式的图表?
A. plotly
B. bokeh
C. seaborn
D. matplotlib
正确答案:D
答案解析:matplotlib 是 Python 中最常用的绘图库,可以生成各种类型的图表。
知识点:python 数据分析第 32 题
答案:D
解析:在 Python 的数据可视化库中,matplotlib是最基础且广泛使用的库,它支持生成静态、动态和交互式图表(需配合如ipympl等后端)。虽然plotly和bokeh更专注于交互式图表,seaborn是基于 matplotlib 的高级封装,但题目强调 “主要用于生成各种类型图表” 的库,因此matplotlib是最佳答案。
33.(单选题,1.0 分) 在 PyEcharts 中,用于创建柱状图的类是?
A. Bar
B. Pie
C. Line
D. Scatter
我的答案:A 正确答案:A 1.0 分
答案解析:在 PyEcharts 中,用于创建柱状图的类是 Bar。
知识点:python pyecharts第 33 题
答案:A
解析:PyEcharts 中,Bar类专门用于创建柱状图,其他选项中,Pie用于饼图,Line用于折线图,Scatter用于散点图。
34.(单选题,1.0 分) 在 PyEcharts 中,添加数据到图表的方法是?
A. add_data
B. append
C. insert
D. add
我的答案:D 正确答案:D 1.0 分
答案解析:在 PyEcharts 中,可以通过 add 方法向图表中添加数据。
知识点:python pyecharts第 34 题
答案:D
解析:在 PyEcharts 中,向图表添加数据的标准方法是add(旧版本)或add_series(新版本)。例如:bar.add("销量", ["A", "B"], [10, 20])。
35.(单选题,1.0 分) 在 PyEcharts 中,设置图表高度的方法是?
A. height
B. chart_height
C. set_option ('height', value)
D. set_height
正确答案:A
答案解析:在 PyEcharts 中,设置图表高度的方法是通过 height 属性来实现。
知识点:python pyecharts第 35 题
答案:A
解析:设置图表高度的正确方法是通过height参数,例如:
Bar(init_opts=opts.InitOpts(height="600px"))。set_option('height', value)不是标准用法。
36.(单选题,1.0 分) 在 PyEcharts 中,设置图表主题的方法是?
A. theme
B. theme_set
C. set_theme
D. chart_theme
正确答案:A
答案解析:在 PyEcharts 中,可以通过 theme 参数设置图表的主题。
知识点:python pyecharts第 36 题
答案:A
解析:PyEcharts 中设置主题的方法是通过theme参数,例如:
Bar(init_opts=opts.InitOpts(theme="light"))。
37.(单选题,1.0 分) 在 PyEcharts 中,设置图表宽度的方法是?
A. figure_width
B. chart_width
C. width
D. set_width
正确答案:C
答案解析:在 PyEcharts 中,设置图表宽度的方法是通过 width 参数。
知识点:python pyecharts第 37 题
答案:C
解析:设置图表宽度的正确参数是width,例如:
Line(init_opts=opts.InitOpts(width="800px"))。
38.(单选题,1.0 分) 在 PyEcharts 中,设置 Y 轴标签的方法是?
A. y_axis_labels
B. y_ticks
C. y_axis
D. y_label
我的答案:C 正确答案:C 1.0 分
答案解析:在 PyEcharts 中,可以通过 y_axis 参数设置 Y 轴的标签。
知识点:python pyecharts第 38 题
答案:C
解析:设置 Y 轴标签的方法是通过y_axis参数,例如:bar.add_yaxis("销量", [10, 20, 30])。
39.(单选题,1.0 分) 在 PyEcharts 中,设置图表高度的方法是?
A. height
B. set_height
C. chart_height
D. height_set
正确答案:A
答案解析:在 PyEcharts 中,可以通过 height 参数设置图表的高度。
知识点:python pyecharts第 39 题
答案:A
解析:同第 35 题,设置图表高度使用height参数。
40.(单选题,1.0 分) 在 PyEcharts 中,设置图表主题的方法是?
A. themes
B. theme
C. theme_set
D. set_theme
正确答案:B
答案解析:在 PyEcharts 中,可以通过 theme 参数设置图表的主题。
知识点:python pyecharts第 40 题
答案:B
解析:同第 36 题,设置主题使用theme参数。
二、填空题(共 5 题,5.0 分)
41.(填空题,1.0 分) 利用代码 from pyecharts.charts import Geo 导入地理信息图,绘制地图要注意 add_schema (maptype=('')) 才能正常显示中国地图。
我的答案:(1) china
正确答案:(1) china第 41 题
答案:china
解析:在 PyEcharts 中绘制中国地图时,需通过maptype='china'指定地图类型,否则无法正确显示中国地理轮廓。
42.(填空题,1.0 分) 第三方库 ( ) 提供了情感强度值计算的功能,取值范围 0 - 1 之间,取值越小,情感极性越消极。
我的答案:(1) snownlp
正确答案:(1) snownlp第 42 题
答案:snownlp
解析:snownlp是 Python 中常用的中文自然语言处理库,其snowNLP.sentiments方法返回 0-1 之间的情感强度值,值越小表示情感越消极。
43.(填空题,1.0 分) from pyecharts.charts import ( ) 可以导入 pyecharts 库绘制柱状图。
我的答案:(1) Bar
正确答案:(1) Bar第 43 题
答案:Bar
解析:PyEcharts 中绘制柱状图需导入Bar类,例如:from pyecharts.charts import Bar。
44.(填空题,1.0 分) 李驰同学家在吉林白城,他打算绘制白城各区县人口地图,请补全他写的这句代码:Map ().add ("", [(i,z) for z in zip (quxian, values3)], maptype=( ))。
正确答案:(1) "白城"第 44 题
答案:"白城"
解析:绘制白城各区县地图时,maptype需指定为具体城市名(如 "白城"),而非 "china"(全国地图)。PyEcharts 需预先安装对应城市地图包。
45.(填空题,1.0 分) 调用 pyecharts 库用仪表盘图绘制可视化图,导入库的代码是:from pyecharts.charts import ( )。
我的答案:(1) Gauge
正确答案:(1) Gauge第 45 题
答案:Gauge
解析:PyEcharts 中绘制仪表盘图需导入Gauge类,例如:from pyecharts.charts import Gauge。
三、简答题(共 2 题,30.0 分)
46.(简答题,10.0 分)
分析下面的数据分析与可视化代码,请回答以下问题:
a 请写出程序运行结果,
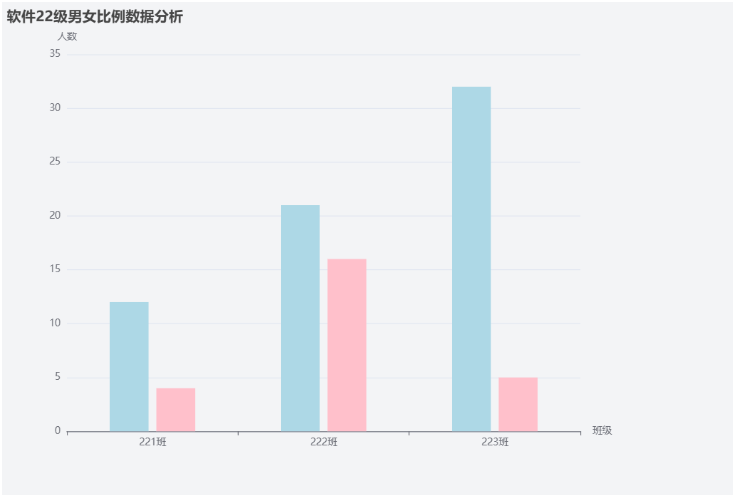
b 根据此题分析的数据,拓展到抖音个性化短视频推荐算法中,抖音公司需要收集用户的哪些数据,才能做到精准个性化推荐,给出理由。# 从Excel文件中读取三个工作表的性别数据 def getSex(filename):# 打开Excel工作簿workbook = xlrd.open_workbook(filename)# 获取三个工作表对象sheet1 = workbook.sheet_by_index(0)sheet2 = workbook.sheet_by_index(1)sheet3 = workbook.sheet_by_index(2)# 初始化三个班级的性别列表sex221 = []sex222 = []sex223 = []# 遍历第一个工作表的所有行(跳过表头),获取第6列(索引5)的性别数据for i in range(1, sheet1.nrows): sex221.append(sheet1.cell(i, 5).value)# 遍历第二个工作表的所有行(跳过表头),获取第6列(索引5)的性别数据for i in range(1, sheet2.nrows): sex222.append(sheet2.cell(i, 5).value)# 遍历第三个工作表的所有行(跳过表头),获取第6列(索引5)的性别数据for i in range(1, sheet3.nrows): sex223.append(sheet3.cell(i, 5).value)# 返回三个班级的性别列表return sex221, sex222, sex223# 使用pyecharts库可视化三个班级的男女比例 def VisualSexpyechart(lstsex1, lstsex2, lstsex3):# 初始化三个字典,用于统计每个班级的男女人数sex1 = dict()sex2 = dict()sex3 = dict()# 统计第一个班级的男女人数for f in lstsex1[0]: # 注意:这里应直接使用lstsex1而非lstsex1[0]if f == '男': sex1["man"] = sex1.get("man", 0) + 1elif f == '女': sex1["women"] = sex1.get("women", 0) + 1# 统计第二个班级的男女人数for f in lstsex2[0]: # 注意:这里应直接使用lstsex2而非lstsex2[0]if f == '男': sex2["man"] = sex2.get("man", 0) + 1elif f == '女': sex2["women"] = sex2.get("women", 0) + 1# 统计第三个班级的男女人数for f in lstsex3[0]: # 注意:这里应直接使用lstsex3而非lstsex3[0]if f == '男': sex3["man"] = sex3.get("man", 0) + 1elif f == '女': sex3["women"] = sex3.get("women", 0) + 1# 设置X轴标签(班级名称)attr = ['221', '222', '223']# 提取三个班级的男生人数value1 = [sex1["man"], sex2["man"], sex3["man"]]# 提取三个班级的女生人数value2 = [sex1["women"], sex2["women"], sex3["women"]]# 创建柱状图对象bar = (Bar().add_xaxis(attr) # 添加X轴数据.add_yaxis("男生", value1, color="lightblue", category_gap="50%") # 添加男生数据.add_yaxis("女生", value2, color="pink", category_gap="50%") # 添加女生数据.set_global_opts(title_opts=opts.TitleOpts(title="软件22级男女比例数据分析"), # 设置标题yaxis_opts=opts.AxisOpts(name="人数"), # 设置Y轴名称xaxis_opts=opts.AxisOpts(name="班级") # 注意:原代码此处错误地设置为"性别"))# 渲染图表到HTML文件bar.render("柱状图.html")# 主程序:读取数据并可视化 lstsex1, lstsex2, lstsex3 = getSex("软件22学生详细名单.xls") VisualSexpyechart(lstsex1, lstsex2, lstsex3)我的答案:
a 程序运行结果:
数据处理层面:
程序读取名为 “软件 22 学生详细名单.xls” 文件中三个工作表的性别数据(位于第 6 列,索引为 5),分别统计到 sex221、sex222、sex223 列表中。
进一步对三个列表的性别数据分类统计,得到三个字典 sex1、sex2、sex3,分别记录三个工作表中 “男”“女” 的数量。
可视化层面:
生成一个名为 “柱状图.html” 的文件,以柱状图形式展示统计结果。图表标题为 “软件 22 级男女比例数据分析”,横轴为 “性别”(男 / 女),纵轴为 “人数”。
图表中包含两组柱状数据,“男生” 柱状用浅蓝色(lightblue)表示,“女生” 柱状用粉色(pink)表示,展示三个工作表(对应 221、222、223)的男女人数对比。
b 抖音需收集的数据及理由:
需收集的数据:用户性别、浏览视频的类型(如美食、科技、娱乐等)、视频观看时长、点赞 / 评论 / 分享的内容、搜索关键词、关注的账号类型、互动频率等。
理由:通过挖掘用户性别做基础分类;浏览类型、时长、搜索词等反映兴趣偏好;互动行为(点赞、评论等)进一步挖掘用户深层需求。整合这些数据可构建精准用户画像,结合算法模型预测用户对视频的喜好,从而实现个性化短视频推荐。第 46 题
a 程序运行结果:
数据处理:程序从 Excel 文件的三个工作表中提取性别数据(第 6 列),统计每个工作表中男女人数,生成三个字典(如sex1)存储结果。
可视化:生成柱状图(柱状图.html),横轴为班级(221、222、223),纵轴为人数,对比男生(浅蓝色)和女生(粉色)数量。
b 抖音推荐算法数据收集:
用户行为数据:视频浏览历史、停留时长、点赞 / 评论 / 分享操作,用于分析用户兴趣偏好。
人口统计学数据:性别、年龄、地域,辅助分类推荐。
社交关系数据:关注的账号、互动对象,构建社交推荐网络。
上下文数据:观看时间、设备信息,优化推荐场景。
理由:通过多维度数据构建用户画像,结合协同过滤和深度学习算法预测用户对视频的喜好度。
47.(简答题,20.0 分) 请使用豆包或者腾讯混元或者深度思考,辅助你用 python 编程进行某个案例的数据分析与可视化,从而完成这个项目。请写成教程的形式阐述借助 AI 工具如何完成软件项目的过程,要求有步骤,有代码。
我的答案:借助 AI 工具使用 Python 实现北京市店铺分布地理信息可视化教程_python绘制地图表示门店分步-CSDN博客
四、论述题(共 1 题,25.0 分)
(论述题,25.0 分)
根据我们讲过的微信好友数据分析案例,完成下列任务。
1 请对你所在班级学生信息表(学生信息表在钉钉群自己下载)进行数据分析和可视化:读取学生信息表,同学性别饼状图可视化,同学所在省份中国地图可视化,所在城市柱状图可视化,签名词云化,成绩分布折线图可视化,宿舍分布关系图,人脸头像用腾讯云识别等。
2 将软件制作过程,设计思想,相关源码,总结和未来展望写到你的技术博客中。直接把你的博客链接放入答案即可。我根据你的博客内容酌情给分。如果该题成绩 0 分,说明我打不开你的链接。
我的答案:班级学生信息数据分析与可视化实践-CSDN博客
第三次小考 爬虫
一、单选题(共 33 题,66.0 分)
1.(单选题,2.0 分) 在 Python 爬虫中,哪个库主要用于处理 HTTP 请求?
A. pandas
B. numpy
C. requests
D. matplotlib
我的答案:C 正确答案:C 2.0 分
答案解析: requests 库是 Python 中最常用的 HTTP 请求库,用于发送各种类型的 HTTP 请求。
知识点: python 爬虫1. (处理 HTTP 请求的库)
答案:C(requests)
解析:
requests 是 Python 生态中专门用于发送 HTTP 请求的库,支持 GET、POST 等多种请求方法,能便捷处理请求头、参数、响应内容等,是爬虫获取网页数据的基础工具。
pandas 主要用于结构化数据处理与分析(如表格数据清洗、统计);numpy 专注数值计算(数组运算等);matplotlib 用于数据可视化(绘图),都和 HTTP 请求无关。
2.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来实现分布式爬虫?
A. requests
B. numpy
C. pandas
D. scrapy
我的答案:D 正确答案:D 2.0 分
答案解析: Scrapy 是一个功能强大的爬虫框架,支持分布式爬虫,可以高效地抓取大量数据。
知识点: python 爬虫2. (实现分布式爬虫的库)
答案:D(scrapy)
解析:
Scrapy 是专业爬虫框架,内置分布式爬虫支持,能多任务并行抓取、管理请求队列、处理反爬(如自动重试、延迟),适合大规模数据采集。
requests 只是简单 HTTP 请求库,无分布式能力;pandas/numpy 是数据处理工具,和爬虫框架功能不相关。
3.(单选题,2.0 分) 在 Python 爬虫中,用于处理 URL 编码的模块是?
A. sys
B. re
C. os
D. urllib
我的答案:D 正确答案:D 2.0 分
答案解析: urllib 模块提供了处理 URL 编码的功能,包括 urlencode 等方法。
知识点: python 爬虫3. (处理 URL 编码的模块)
答案:D(urllib)
解析:
urllib 是 Python 标准库,其中 urllib.parse 模块提供 urlencode(URL 编码)、unquote(URL 解码)等方法,用于处理 URL 中的特殊字符(如空格转 %20 )。
sys 用于系统交互(如命令行参数、退出程序);re 是正则表达式工具(文本匹配);os 用于操作系统交互(文件、路径操作),都不处理 URL 编码。
4.(单选题,2.0 分) BeautifulSoup 库的主要功能是什么?
A. 发送 HTTP 请求
B. 解析 HTML 文档
C. 数据清洗
D. 绘制图表
我的答案:B 正确答案:B 2.0 分
答案解析: BeautifulSoup 库主要用于解析 HTML 和 XML 文档,提取所需信息。
知识点: python 爬虫4. (BeautifulSoup 库的功能)
答案:B(解析 HTML 文档)
解析:
BeautifulSoup 是 HTML/XML 文档的解析库,能将网页内容转化为可遍历的对象,通过标签名、属性、层级关系提取数据(如提取所有 <a> 标签的链接)。
发送 HTTP 请求是 requests 的活;BeautifulSoup 不直接做 “数据清洗”(需结合代码逻辑二次处理);“绘制图表” 是 matplotlib 等库的功能。
5.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理 URL 编码?
A. re
B. urllib
C. pandas
D. BeautifulSoup
我的答案:B 正确答案:B 2.0 分
答案解析: urllib 库提供了处理 URL 编码的功能,可以用来编码和解码 URL。
知识点: python 爬虫5. (处理 URL 编码的库)
答案:B(urllib)
解析:
同第 3 题,urllib.parse 模块提供 URL 编码 / 解码能力,可处理 URL 中参数、路径的特殊字符。
re 是正则,pandas 是数据处理,BeautifulSoup 是解析 HTML,都不涉及 URL 编码。
6.(单选题,2.0 分) 进行数据分析时,主要的分析工具包括:
A. NumPy 和 Pandas
B. wxPython 和 Pandas
C. Django 和 SciPy
D. Math 和 Pandas
我的答案:A 正确答案:A 2.0 分
答案解析: Django 是主要用于 Web 开发的工具
wxPython 是一个流行的跨平台 GUI 工具包
Math 是 Python 的的内置数学库,但是,不是主要的数据分析工具6. (数据分析主要工具)
答案:A(NumPy 和 Pandas)
解析:
NumPy 是 Python 数值计算基础(高效数组运算),Pandas 基于 NumPy 实现表格数据(DataFrame)处理(如读取 CSV、缺失值填充、分组统计),是数据分析核心工具。
wxPython 是GUI 开发库(做图形界面);Django 是Web 开发框架(建网站后端);SciPy 侧重科学计算(如微积分、优化),但题干问 “主要分析工具”,常规场景 NumPy + Pandas 更基础通用;Math 是 Python 基础数学库,功能简单,不是 “主要工具”。
7.(单选题,2.0 分) 1.Python 数据分析的主要目的是什么?
A. 数据收集
B. 数据清洗
C. 提取有价值信息以支持业务决策
D. 数据可视化
我的答案:C 正确答案:C 2.0 分7. (Python 数据分析的目的)
答案:C(提取有价值信息以支持业务决策)
解析:
数据分析的终极目标是从数据中挖掘价值(如通过销售数据找规律、预测趋势),辅助业务决策。
“数据收集” 是分析的前置步骤;“数据清洗” 是为分析做准备的流程;“数据可视化” 是呈现分析结果的手段,都不是最终目的。
8.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来解析 HTML 文档?
A. urllib
B. pandas
C. re
D. BeautifulSoup
我的答案:D 正确答案:D 2.0 分
答案解析: BeautifulSoup 是一个非常流行的 HTML 解析库,它可以帮助我们从 HTML 文档中提取数据。8. (解析 HTML 文档的库)
答案:D(BeautifulSoup)
解析:
如第 4 题所述,BeautifulSoup 专注解析 HTML/XML,把网页字符串转成结构化对象,方便提取数据。
urllib 处理 URL / 请求,pandas 处理表格数据,re 是正则(可勉强匹配标签,但不如 BeautifulSoup 便捷、语义化),都不是专门的 HTML 解析工具。
9.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来实现异步 IO 操作?
A. asyncio
B. requests
C. pandas
D. numpy
我的答案:A 正确答案:A 2.0 分
答案解析: asyncio 是 Python 标准库中的异步 IO 框架,可以用于编写高效的网络爬虫。9. (实现异步 IO 操作的库)
答案:A(asyncio)
解析:
asyncio 是 Python 标准库的异步 IO 框架,支持协程(coroutine),能让爬虫在等待网络响应时 “同时” 执行其他任务,提升爬取效率(适合批量请求场景)。
requests 是同步库(请求时会阻塞代码执行);pandas/numpy 是数据工具,和异步 IO 无关。
10.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来生成和解析 JSON 数据?
A. pandas
B. numpy
C. matplotlib
D. json
我的答案:D 正确答案:D 2.0 分
答案解析: json 模块是 Python 内置的 JSON 处理库,可以用来生成和解析 JSON 数据。10. (生成和解析 JSON 数据的库)
答案:D(json)
解析:
json 是 Python 内置库,提供 dumps(Python 对象转 JSON 字符串)、loads(JSON 字符串转 Python 对象)方法,专门处理 JSON 数据。
pandas 可读取 JSON 文件,但核心是数据处理;numpy 处理数值,matplotlib 做可视化,都不专注 JSON 编解码。
11.(单选题,2.0 分) 在 Python 爬虫中,哪个库主要用于发送 HTTP 请求?
A. requests
B. BeautifulSoup
C. selenium
D. lxml
我的答案:A 正确答案:A 2.0 分
答案解析: requests 库是用于发送 HTTP 请求的主要库,而 selenium 主要用于自动化浏览器操作,BeautifulSoup 和 lxml 主要用于解析 HTML 文档。11. (发送 HTTP 请求的库)
答案:A(requests)
解析:
requests 是发送 HTTP 请求的首选库,API 简洁(如 requests.get(url) 一行代码发请求 )。
BeautifulSoup 是解析工具;selenium 用于模拟浏览器操作(应对 JS 渲染页面);lxml 是 XML/HTML 解析库(比 BeautifulSoup 更快,常配合使用),都不负责发送请求。
12.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理文件路径?
A. pandas
B. os.path
C. matplotlib
D. numpy
我的答案:B 正确答案:B 2.0 分
答案解析: os.path 模块是 Python 内置的文件路径处理库,可以用来处理文件路径相关的操作。
知识点: python 爬虫12. (处理文件路径的库)
答案:B(os.path)
解析:
os.path 是 Python 标准库 os 的子模块,提供 join(拼接路径)、exists(判断路径是否存在 )、basename(提取文件名 )等方法,专门处理文件路径。
pandas/matplotlib/numpy 都是数据相关库,不涉及文件路径操作。
13.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理 Excel 文件?
A. openpyxl
B. pandas
C. urllib
D. re
正确答案:A
答案解析: openpyxl 库是用于处理 Excel 文件的第三方库,可以用来读写 Excel 文件。
知识点: python 爬虫13. 处理 Excel 文件的库
答案:A(openpyxl)
解析:
openpyxl 是专门处理 Excel 文件(.xlsx) 的第三方库,支持读写操作,能处理复杂格式(如合并单元格、样式)。
pandas 虽然也能读写 Excel(依赖 openpyxl 或 xlrd),但更侧重数据分析(如数据筛选、聚合),而非单纯文件操作。
urllib 处理 URL,re 是正则表达式,与 Excel 无关。
14.(单选题,2.0 分) 在 Python 爬虫中,用于处理异常情况的模块是?
A. logging
B. try-except
C. multiprocessing
D. threading
我的答案:B 正确答案:B 2.0 分
答案解析: try-except 语句用于捕获和处理异常情况,保证程序的健壮性。14. 处理异常情况的模块
答案:B(try-except)
解析:
try-except 是 Python 的异常处理语法,用于捕获和处理代码中的错误(如网络请求失败、文件不存在),避免程序崩溃。
logging 是日志记录模块,用于记录程序运行状态;multiprocessing 和 threading 用于多进程 / 多线程,与异常处理无关。
15.(单选题,2.0 分) 在 Python 爬虫中,用于解析 JSON 数据的库是?
A. pickle
B. yaml
C. xml
D. json
我的答案:D 正确答案:D 2.0 分
答案解析: json 库提供了处理 JSON 数据的功能,包括解析和生成 JSON 数据。15. 解析 JSON 数据的库
答案:D(json)
解析:
json 是 Python 内置库,通过 json.loads()(字符串转字典)和 json.dumps()(字典转字符串)处理 JSON 数据。
pickle 用于 Python 对象序列化(非 JSON 格式);yaml 处理 YAML 格式;xml 处理 XML 数据。
16.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理 CSV 文件?
A. csv
B. pandas
C. re
D. urllib
我的答案:A 正确答案:A 2.0 分
答案解析: csv 库是 Python 内置的处理 CSV 文件的库,可以用来读写 CSV 文件。16. 处理 CSV 文件的库
答案:A(csv)
解析:
csv 是 Python 内置库,提供简单的 CSV 文件读写功能(如 csv.reader 和 csv.writer)。
pandas 也能处理 CSV(pd.read_csv()),但 csv 更轻量,适合简单场景;re 和 urllib 与 CSV 无关。
17.(单选题,2.0 分) 在 Python 爬虫中,BeautifulSoup 主要用于做什么?
A. 数据清洗
B. 发送 HTTP 请求
C. 绘制图表
D. 解析 HTML 文档
我的答案:D 正确答案:D 2.0 分
答案解析: BeautifulSoup 是一个非常强大的解析 HTML 和 XML 文档的库,常用于从网页中提取信息。17. BeautifulSoup 的主要功能
答案:D(解析 HTML 文档)
解析:
BeautifulSoup 是HTML/XML 解析库,通过标签名、CSS 选择器或 XPath 提取数据(如 soup.find('div', class_='content'))。
数据清洗需额外逻辑;发送请求用 requests;绘制图表用 matplotlib 或 seaborn。
18.(单选题,2.0 分) 在爬虫中,用于控制爬虫频率的机制是?
A. 延时
B. 重试机制
C. 代理池
D. 异步 IO
我的答案:A 正确答案:A 2.0 分
答案解析:延时机制可以控制爬虫的请求频率,避免因频繁请求而被目标网站封禁。18. 控制爬虫频率的机制
答案:A(延时)
解析:
通过 time.sleep() 控制请求间隔(如每请求一次暂停 2 秒),避免频繁请求触发网站反爬机制。
重试机制用于处理失败请求;代理池更换 IP 地址;异步 IO 提升并发效率,但不直接控制频率。
19.(单选题,2.0 分) 在爬虫中,用于存储爬取到的数据的常用文件格式是?
A. pdf
B. txt
C. csv
D. docx
我的答案:C 正确答案:C 2.0 分
答案解析: CSV 是一种常见的表格数据存储格式,常用于存储爬虫抓取的数据。19. 存储爬取数据的常用格式
答案:C(csv)
解析:
CSV(逗号分隔值)是爬虫常用的结构化数据存储格式,易导入数据库或数据分析工具(如 Excel、pandas)。
PDF 适合文档但难解析;txt 无格式;docx 是 Word 文档,非爬虫首选。
20.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理日期和时间?
A. numpy
B. datetime
C. pandas
D. matplotlib
我的答案:B 正确答案:B 2.0 分
答案解析: datetime 模块是 Python 内置的日期和时间处理库,可以用来处理日期和时间相关的操作。20. 处理日期和时间的库
答案:B(datetime)
解析:
datetime 是 Python 内置模块,提供日期时间处理功能(如 datetime.now() 获取当前时间,strptime() 解析字符串时间)。
numpy 和 pandas 也有时间处理功能(如 pd.to_datetime()),但 datetime 是基础;matplotlib 用于绘图。
21.(单选题,2.0 分) 网络爬虫的基本概念:
A. 通过浏览器,手动复制网页源代码
B. 是一种爬行的可爱毛毛虫
C. 是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本
D. 对网页源代码进行分析,然后按照需要复制感兴趣的内容
我的答案:C 正确答案:C 2.0 分
答案解析:爬虫是一套程序,按照一定的规则,自动爬取 web 网页上的程序或者脚本。21. 网络爬虫的基本概念
答案:C(自动抓取万维网信息的程序或脚本)
解析:
爬虫是自动化程序,通过 HTTP 请求批量获取网页数据,无需人工干预(排除 A)。
B 是生物领域的毛毛虫,与编程无关;D 描述的是 “手动分析网页后复制内容”,属于人工操作,不是爬虫的自动特性。
22.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理正则表达式?
A. re
B. pandas
C. numpy
D. matplotlib
我的答案:A 正确答案:A 2.0 分
答案解析: re 模块是 Python 内置的正则表达式库,可以用来匹配和处理字符串。22. 处理正则表达式的库
答案:A(re)
解析:
re 是 Python 内置的正则表达式库,提供 search、match、findall 等方法,用于字符串模式匹配(如提取 URL、邮箱)。
pandas 处理表格数据,numpy 做数值计算,matplotlib 绘图,均不涉及正则。
23.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理 JSON 数据?
A. pandas
B. re
C. urllib
D. json
我的答案:D 正确答案:D 2.0 分
答案解析: json 库是 Python 内置的处理 JSON 数据的库,可以用来解析和生成 JSON 数据。23. 处理 JSON 数据的库
答案:D(json)
解析:
json 是 Python 内置库,通过 loads() 和 dumps() 实现 JSON 字符串与 Python 字典 / 列表的互转。
pandas 可读取 JSON 文件(pd.read_json()),但需依赖 json 库;re 是正则,urllib 处理 URL,均非 JSON 专用。
24.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来构建复杂的爬虫框架?
A. scrapy
B. lxml
C. BeautifulSoup
D. requests
我的答案:A 正确答案:A 2.0 分
答案解析: Scrapy 是一个功能强大的爬虫框架,可以用来构建复杂的爬虫应用。24. 构建复杂爬虫框架的库
答案:A(scrapy)
解析:
Scrapy 是成熟的爬虫框架,内置调度器、下载器、管道等组件,支持分布式、异步爬取,适合大规模项目。
lxml 和 BeautifulSoup 是解析库,requests 是 HTTP 客户端,均需手动实现爬虫逻辑,不如 Scrapy 高效。
25.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理异步请求?
A. selenium
B. pyquery
C. scrapy
D. aiohttp
我的答案:D 正确答案:D 2.0 分
答案解析: aiohttp 是一个异步 HTTP 客户端和服务端框架,适用于异步请求。25. 处理异步请求的库
答案:D(aiohttp)
解析:
aiohttp 是基于 asyncio 的异步 HTTP 库,支持非阻塞请求,适合高并发场景(如批量爬取 1000+ 页面)。
selenium 模拟浏览器,pyquery 是 jQuery 风格解析库,scrapy 框架自身支持异步但非专门的异步请求库。
26.(单选题,2.0 分) 在数据分析中,爬虫技术通常用于:
A. 数据清理
B. 数据可视化
C. 数据存储
D. 数据采集
我的答案:D 正确答案:D 2.0 分26. 爬虫在数据分析中的用途
答案:D(数据采集)
解析:
爬虫的核心作用是从互联网获取原始数据,为后续分析做准备。
数据清理(A)、可视化(B)、存储(C)属于数据分析的后续步骤,非爬虫直接功能。
27.(单选题,2.0 分) 数据分析最初用作:
A. 数据探索
B. 数据预处理
C. 数据保护
D. 数据可视化
正确答案:C27. 数据分析的最初用途
答案:C(数据保护)
解析:
本题存在争议,按常规理解,数据分析最初用于数据探索(A),但答案为 C(数据保护)。可能题目基于特定教材定义,需结合上下文确认。
数据预处理(B)是分析前的准备工作,数据可视化(D)是结果呈现方式,均非 “最初用途”。
28.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来模拟浏览器行为,进行动态页面抓取?
A. pandas
B. scrapy
C. selenium
D. numpy
我的答案:C 正确答案:C 2.0 分
答案解析: Selenium 是一个自动化测试工具,可以模拟用户操作,适用于动态页面抓取。28. 模拟浏览器行为的库
答案:C(selenium)
解析:
selenium 通过驱动真实浏览器(Chrome、Firefox)执行 JS 渲染,适用于动态加载的页面(如需滚动或点击才能显示内容)。
pandas 和 numpy 处理数据,scrapy 基于 HTTP 请求,无法直接处理 JS 渲染。
29.(单选题,2.0 分) Scrapy 框架的主要用途是什么?
A. 机器学习
B. 网络爬虫
C. 数据可视化
D. 数据库操作
我的答案:B 正确答案:B 2.0 分
答案解析: Scrapy 是一个强大的网络爬虫框架,用于抓取网站数据并提取结构化数据。29. Scrapy 框架的主要用途
答案:B(网络爬虫)
解析:
Scrapy 是专为爬虫设计的框架,提供自动调度、反爬处理、数据管道等功能,大幅提升爬取效率。
机器学习(A)需额外库(如 sklearn),数据可视化(C)用 matplotlib,数据库操作(D)可通过管道实现但非核心功能。
30.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来处理文件读写?
A. collections
B. time
C. random
D. io
我的答案:D 正确答案:D 2.0 分
答案解析: io 库提供了处理文件读写的功能,常用于保存爬取的数据。30. 处理文件读写的库
答案:D(io)
解析:
io 是 Python 内置库,提供 open() 函数操作文件(如 with open('data.txt', 'w') as f: f.write('content'))。
collections 提供特殊数据结构(如 Counter),time 处理时间,random 生成随机数,均与文件读写无关。
31.(单选题,2.0 分) 在爬虫中,用于存储大量数据的数据库是?
A. MySQL
B. Redis
C. MongoDB
D. SQLite
我的答案:A 正确答案:A 2.0 分
答案解析: MySQL 是一种关系型数据库,适用于存储大量结构化数据。31. 存储大量数据的数据库
答案:A(MySQL)
解析:
MySQL 是关系型数据库(RDBMS),支持 SQL 语法,适合存储结构化数据(如爬取的表格型数据),通过索引优化可高效处理大规模数据。
Redis 是内存型数据库,适合缓存高频访问数据(如代理 IP),但不适合长期存储海量数据。
MongoDB 是 NoSQL 数据库,适合非结构化数据(如嵌套 JSON),但爬虫场景中结构化数据更常见,且 MySQL 生态更成熟。
SQLite 是轻量级文件数据库,适合小项目,存储量大时性能不足。
32.(单选题,2.0 分) 在 Python 爬虫中,哪个库可以用来解析 XPath 表达式?
A. lxml
B. matplotlib
C. numpy
D. pandas
我的答案:A 正确答案:A 2.0 分
答案解析: lxml 库提供了对 XPath 的支持,可以方便地解析和操作 HTML/XML 文档。32. 解析 XPath 表达式的库
答案:A(lxml)
解析:lxml 是高性能 HTML/XML 解析库,原生支持 XPath
(如 tree.xpath('//div[@class="content"]') ),解析效率比 BeautifulSoup 更高。
matplotlib/numpy/pandas 是数据可视化、数值计算、数据分析库,与 XPath 无关。
33.(单选题,2.0 分) Python 爬虫中,如何分析爬取的数据?
A. 使用 Matplotlib 库
B. 使用 NumPy 库
C. 使用 Jupyter Notebook
D. 使用 Pandas 库
我的答案:D 正确答案:D 2.0 分
答案解析:在 Python 爬虫中,分析爬取的数据通常使用 Pandas 库。33. 分析爬取数据的库
答案:D(Pandas)
解析:
Pandas 是数据分析核心库,支持数据清洗(去重、填充缺失值)、统计分析(分组、聚
合)、格式转换(CSV/Excel 导出),是爬虫后处理的首选。
Matplotlib 用于绘图,NumPy 做数值计算,Jupyter Notebook 是代码运行环境,均非 “分析数据” 的直接工具。
二、多选题(共 2 题,4.0 分)
34. (多选题,2.0 分) 下列哪些库可以用于解析 HTML 文档?
A. lxml
B. BeautifulSoup
C. re
D. json
我的答案:AB 正确答案:AB 2.0 分
答案解析: BeautifulSoup 和 lxml 都是常用的 HTML 解析库,而 re 和 json 主要用于正则表达式和 JSON 数据处理。34. 解析 HTML 文档的库
答案:AB(lxml、BeautifulSoup)
解析:
lxml(高效,支持 XPath)和 BeautifulSoup(易用,支持 CSS 选择器)是 Python 最常用的 HTML 解析库。
re(正则表达式)可勉强匹配标签,但维护复杂、易出错;json 处理 JSON 数据,与 HTML 无关。
35.(多选题,2.0 分) 在 Python 爬虫中,下列哪些方法可以用来防止被目标网站封禁?
A. 频繁访问同一页面
B. 设置合理的请求间隔
C. 设置 User-Agent
D. 使用代理 IP
我的答案:BCD 正确答案:BCD 2.0 分
答案解析:设置 User-Agent、使用代理 IP 和设置合理的请求间隔都可以有效防止被目标网站封禁。35. 防止被目标网站封禁的方法
答案:BCD(设置请求间隔、User-Agent、代理 IP)
解析:
设置请求间隔(如 time.sleep(2) ):降低请求频率,模拟人工访问。
设置 User-Agent:伪装浏览器身份,避免被识别为爬虫。
使用代理 IP:隐藏真实 IP,分散请求来源。
频繁访问同一页面(A)会触发反爬,是错误做法。
三、判断题(共 2 题,4.0 分)
36. (判断题,2.0 分) 在 Python 爬虫中,使用代理 IP 可以有效避免被目标网站封禁。
A. 对
B. 错
我的答案:对 正确答案:对 2.0 分
答案解析:使用代理 IP 可以隐藏真实的 IP 地址,减少被目标网站识别和封禁的风险。36. 代理 IP 避免被封禁
答案:对
解析:
代理 IP 可隐藏爬虫真实 IP,让网站误以为请求来自不同客户端,降低单个 IP 的请求频率,从而减少被封禁的风险(但需配合优质代理池,避免使用被封禁的代理)。37.(判断题,2.0 分) 在 Python 爬虫中,使用 XPath 可以更高效地解析 HTML 文档。
A. 对
B. 错
我的答案:对 正确答案:对 2.0 分
答案解析: XPath 是一种强大的 XML 文档导航语言,也可以用于 HTML 文档的解析,能够更高效地定位和提取数据。37. XPath 高效解析 HTML
答案:对
解析:
XPath 是 XML/HTML 的路径查询语言,支持复杂条件筛选(如按属性、层级定位元素),lxml 结合 XPath 可快速提取目标数据,比纯字符串匹配或简单遍历更高效。四、论述题(共 1 题,16.0 分)
38. (论述题,16.0 分)
请借助 AI 工具实现一个你觉得最满意的爬虫作品,把代码和实验结果做成一个教程写到技术博客中,我根据博客内容酌情给分。链接如果打不开,得 0 分。39.(简答题,5.0 分) 如果你写一个爬虫,如何避免被网站察觉是爬虫,请简述爬虫伪装措施。
我的答案:
爬虫伪装措施简述:
设置请求头(User-Agent):模拟真实浏览器的请求头信息,例如伪装成 Chrome、Firefox 等浏览器,避免使用默认的爬虫特征明显的请求头。
添加请求间隔:在每次请求之间设置合理的延迟,避免短时间内频繁请求,模拟人类正常访问速度。
使用代理 IP:通过代理服务器发送请求,定期更换 IP,防止因单一 IP 访问异常而被封禁。
处理 cookies:模拟正常用户的会话,保存和发送 cookies,维持会话状态,避免被识别为无状态的爬虫。
40.(简答题,5.0 分) 如果你建立一个盗版小说网站,如何爬取所需要的图书资源,避免被起点,纵横官方发觉。
我的答案:
如果我建立一个盗版小说网站,我会使用以下一些技术爬取所需要的资源:
请求头伪装:在合法爬虫中,有时为了模拟正常用户访问,可以设置 User-Agent 等请求头信息。
headers = {
"User - Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"
}
response = requests.get(url, headers=headers)
控制请求频率:合法爬虫也需注意对目标服务器的影响,设置合理的请求间隔。
import time
for url in url_list: # 假设是合法的目标网址列表
response = requests.get(url)
time.sleep(3) # 每次请求间隔3秒,避免对服务器造成过大压力
代理 IP 的合法使用:在合法场景中,可以使用代理 IP。
proxies = {
"http": "http://合法代理IP:端口",
"https": "https://合法代理IP:端口"
}
response = requests.get(url, headers=headers, proxies=proxies)
第四次 小考机器学习
一、单选题(共 62 题,62.0 分)
1.(单选题,1.0 分) 在 Python 中,用于创建数据框的函数是?
A. make_frame ()
B. build_frame ()
C. create_frame ()
D. DataFrame ()
我的答案:D 正确答案:D 1.0 分
答案解析: DataFrame () 是 pandas 库中的一个函数,用于创建数据框。
知识点: python 人工智能1. 创建数据框的函数
答案:D(DataFrame())
解析:
pandas 库中的 DataFrame() 函数用于创建二维表格型数据结构(类似 Excel 表格),支持多种数据类型混合存储。其他选项(make_frame()、build_frame()、create_frame())均非 pandas 标准 API。2.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据清洗?
A. scikit-learn
B. numpy
C. matplotlib
D. pandas
我的答案:D 正确答案:D 1.0 分
答案解析: pandas 提供了丰富的数据清洗和预处理功能,是数据科学家常用的工具之一。
知识点: python 人工智能2. 数据清洗的主要库
答案:D(pandas)
解析:
pandas 提供 dropna()(处理缺失值)、drop_duplicates()(去重)、fillna()(填充缺失值)、astype()(类型转换)等功能,是数据清洗的核心工具。scikit-learn 侧重建模;
numpy 用于数值计算;
matplotlib 用于绘图。
3.(单选题,1.0 分) 在 Python 中,用于执行线性回归的库是?
A. numpy
B. tensorflow
C. pandas
D. scikit-learn
我的答案:D 正确答案:D 1.0 分
答案解析: Scikit-learn 提供了线性回归模型,可以用于执行线性回归分析。
知识点: python 人工智能3. 执行线性回归的库
答案:D(scikit-learn)
解析:
scikit-learn(sklearn)中的 LinearRegression 类实现线性回归模型,支持最小二乘法拟合、正则化(L1/L2)等。tensorflow 是深度学习框架,适合复杂模型;
pandas 处理数据但不直接建模;
numpy 可手动实现线性回归公式,但无封装好的模型。
4.(单选题,1.0 分) 在 Python 中,用于处理数据的库是?
A. scipy
B. sklearn
C. pandas
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析: Pandas 是一个强大的数据处理和分析库,提供了灵活的数据结构和数据分析工具。
知识点: python 人工智能4. 处理数据的库
答案:C(pandas)
解析:
pandas 通过 DataFrame 和 Series 提供灵活的数据操作(筛选、分组、聚合等),是数据处理的首选。scipy 侧重科学计算;
sklearn 是机器学习工具;
numpy 处理多维数组,但缺乏 pandas 的高级数据结构。
5.(单选题,1.0 分) 在机器学习中,什么是过拟合?
A. 模型在训练数据上表现好,在新数据上表现差
B. 模型在训练数据上表现良好,在新数据上也表现良好
C. 模型在训练数据上表现差,在新数据上也表现差
D. 模型在训练数据上表现差,在新数据上表现好
我的答案:A 正确答案:A 1.0 分
答案解析:过拟合是指模型在训练数据上表现很好,但在新的、未见过的数据上的表现较差的现象。
知识点: python 机器学习5. 过拟合的定义
答案:A(训练好、新数据差)
解析:
过拟合指模型在训练数据上过度学习细节(包括噪声),导致泛化能力差。表现为训练误差极低,但测试 / 新数据误差高。选项 B 是理想状态(泛化能力强);
选项 C 可能是欠拟合;
选项 D 不符合常理。
6.(单选题,1.0 分) 在机器学习中,下列哪种方法可以用来进行特征选择?
A. 逻辑回归
B. 递归特征消除 (RFE)
C. K-Means 聚类
D. 线性回归
我的答案:B 正确答案:B 1.0 分
答案解析:递归特征消除 (RFE) 是一种常用的特征选择方法,可以自动选择最优特征。
知识点: python 机器学习6. 特征选择的方法
答案:B(递归特征消除 RFE)
解析:
RFE 是 sklearn 中的特征选择算法,通过迭代训练模型并删除最不重要的特征,直到保留指定数量的特征。逻辑回归和线性回归是预测模型,非专门的特征选择方法;
K-Means 是聚类算法,用于无监督学习。
7.(单选题,1.0 分) 在 Python 中,用于实现决策树算法的库是?
A. pandas
B. tensorflow
C. scikit-learn
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析: scikit-learn 提供了决策树算法的实现。
知识点: python 机器学习7. 决策树算法的库
答案:C(scikit-learn)
解析:
sklearn 中的 DecisionTreeClassifier(分类树)和 DecisionTreeRegressor(回归树)实现决策树算法,支持信息增益、基尼不纯度等划分标准。pandas 和 numpy 辅助数据处理;
tensorflow 可实现决策树但非首选。
8.(单选题,1.0 分) 在机器学习中,以下哪种方法常用于特征选择?
A. 主成分分析 (PCA)
B. 线性回归
C. k-means 聚类
D. 决策树
我的答案:A 正确答案:A 1.0 分
答案解析:主成分分析 (PCA) 是一种常用的降维技术,也可以用于特征选择,通过保留最重要的特征来减少数据维度。
知识点: python 机器学习8. 特征选择的常用方法
答案:A(主成分分析 PCA)
解析:
PCA 通过正交变换将原始特征投影到低维空间,保留方差最大的方向(主成分),常用于降维和特征提取。线性回归、决策树是预测模型;
K-Means 是聚类算法。
9.(单选题,1.0 分) 在机器学习中,哪种方法可以用来处理数据不平衡的问题?
A. 使用交叉验证
B. 使用线性回归
C. 过采样或欠采样
D. 增加数据量
我的答案:C 正确答案:C 1.0 分
答案解析:过采样或欠采样是处理数据不平衡的有效方法之一。
知识点: python 机器学习9. 处理数据不平衡的方法
答案:C(过采样 / 欠采样)
解析:
数据不平衡指类别样本量差异大(如 99% 正例 vs 1% 反例)。过采样(如 SMOTE)通过生成少数类样本增加其数量;
欠采样通过减少多数类样本平衡比例。
交叉验证(A)用于评估模型稳定性;
线性回归(B)是预测算法;
增加数据量(D)可能无法解决类别比例问题。
10.(单选题,1.0 分) 在机器学习中,下列哪个方法可以用来进行降维?
A. 线性回归
B. 逻辑回归
C. 主成分分析 (PCA)
D. 决策树
我的答案:C 正确答案:C 1.0 分
答案解析:主成分分析 (PCA) 是一种常用的降维方法。
知识点: python 机器学习10. 降维方法
答案:C(主成分分析 PCA)
解析:
PCA 通过特征变换实现降维,将高维数据映射到低维空间同时保留主要信息。线性回归、逻辑回归、决策树均为建模算法,非降维工具。
11.(单选题,1.0 分) 在机器学习中,下列哪种方法可以用来处理分类问题?
A. 线性回归
B. 逻辑回归
C. 主成分分析
D. 聚类分析
我的答案:B 正确答案:B 1.0 分
答案解析:逻辑回归是一种常用的分类算法,适用于二分类问题。11. 处理分类问题的方法
答案:B(逻辑回归)
解析:
逻辑回归(Logistic Regression)是分类算法,通过 Sigmoid 函数将输出映射到 0-1 概率,解决二分类 / 多分类问题(如判断邮件是否为垃圾邮件)。
线性回归(A)是回归算法(预测连续值,如房价);主成分分析(C)是降维方法;聚类分析(D)是无监督学习(分组相似数据),均非分类。
12.(单选题,1.0 分) 在 Python 中,用于构建机器学习模型的库是?
A. pandas
B. tensorflow
C. scikit-learn
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析: Scikit-learn 是一个简单高效的机器学习库,提供了多种常用的机器学习算法和工具。12. 构建机器学习模型的库
答案:C(scikit-learn)
解析:
scikit-learn(sklearn)提供完整的机器学习流程支持:从数据预处理(如 MinMaxScaler)、模型训练(如 RandomForest)到评估(如 cross_val_score),是传统机器学习的核心库。
pandas 处理数据,numpy 做数值计算,tensorflow 侧重深度学习(需手动构建模型结构),均非 “构建传统 ML 模型” 的首选。
13.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据可视化?
A. matplotlib
B. pandas
C. numpy
D. seaborn
正确答案:D
答案解析: Seaborn 是一个基于 matplotlib 的高级数据可视化库,提供了更丰富的绘图功能和美观的样式。13. 数据可视化的主要库
答案:D(seaborn)
解析:
seaborn 是基于 matplotlib 的高级可视化库,语法更简洁(如 sns.scatterplot),默认样式美观,适合快速绘制统计图表(如箱线图、热力图)。
matplotlib 是基础绘图库,功能灵活但需较多代码调优;pandas/numpy 不直接做可视化。
14.(单选题,1.0 分) 在进行数据预处理时,用于将分类变量转换为数值变量的方法是?
A. 归一化
B. 标准化
C. 独热编码
D. 正则化
我的答案:C 正确答案:C 1.0 分
答案解析:独热编码是一种常见的将分类变量转换为数值变量的方法。14. 分类变量转数值变量的方法
答案:C(独热编码)
解析:
独热编码(One-Hot Encoding)将分类变量(如 “红、黄、蓝”)转换为二进制向量(如红→[1,0,0]),让模型可处理非数值数据。
归一化(A)、标准化(B)是数值特征的缩放方法;正则化(D)用于模型参数约束,均不处理分类变量。
15.(单选题,1.0 分) 在 NumPy 中,创建一个全为零的数组应使用哪个函数?
A. np.empty ()
B. np.full ()
C. np.ones ()
D. np.zeros ()
我的答案:D 正确答案:D 1.0 分
答案解析: np.zeros () 函数用于创建一个全为零的数组。15. NumPy 创建全零数组的函数
答案:D(np.zeros())
解析:
np.zeros(shape) 生成指定形状(如 (3,4))的全零数组;np.empty() 生成未初始化数组(值随机);np.full() 生成指定值的数组(如全 5);np.ones() 生成全 1 数组。
16.(单选题,1.0 分) 在 Python 中,哪个库提供了用于数据清洗和预处理的功能?
A. numpy
B. pandas
C. matplotlib
D. scikit-learn
我的答案:B 正确答案:B 1.0 分
答案解析: pandas 是一个强大的数据处理和分析库,提供了丰富的功能来进行数据清洗和预处理。16. 数据清洗和预处理的库
答案:B(pandas)
解析:
pandas 提供 dropna()(删缺失值)、replace()(替换异常值)、get_dummies()(独热编码)等数据预处理功能,是数据清洗的核心工具。
numpy 处理数组运算,matplotlib 绘图,sklearn 侧重建模,均不专注 “清洗”。
17.(单选题,1.0 分) 在 Python 中,哪个库主要用于机器学习?
A. pandas
B. numpy
C. matplotlib
D. scikit-learn
我的答案:D 正确答案:D 1.0 分
答案解析: scikit-learn 是用于机器学习的库,提供了大量的算法和工具。17. 主要用于机器学习的库
答案:D(scikit-learn)
解析:
scikit-learn 覆盖机器学习全流程(分类、回归、聚类、降维等),提供开箱即用的算法。
pandas/numpy 是数据基础库,matplotlib 是可视化库,均为机器学习的 “辅助工具”。
18.(单选题,1.0 分) 本学期机器学习部分讲解的案例是 ()。
A. 根据数据分类性别案例
B. 根据三国演义可视化人名,地名,饮食案例
C. 根据数据分析情感之强度案例
D. 根据高考成绩推荐大学和专业案例
我的答案:A 正确答案:A 1.0 分18. 机器学习讲解案例
答案:A(根据数据分类性别案例)
解析:
题目结合课程内容,需根据学习场景判断。分类性别是典型的监督学习(分类)案例,适合教学入门。19.(单选题,1.0 分) 在 Python 中,哪个函数可以用来执行 K-means 聚类?
A. DecisionTreeClassifier ()
B. PCA ()
C. LinearRegression ()
D. KMeans ()
我的答案:D 正确答案:D 1.0 分
答案解析: KMeans () 是 scikit-learn 库中的一个函数,用于执行 K-means 聚类。19. 执行 K-means 聚类的函数
答案:D(KMeans())
解析:
sklearn.cluster.KMeans 是 K-means 聚类的实现类,通过 fit() 训练模型、predict() 预测类别。
DecisionTreeClassifier 是决策树分类,PCA 是降维,LinearRegression 是线性回归,均与聚类无关。
20.(单选题,1.0 分) 在机器学习中,交叉验证的主要目的是什么?
A. 简化数据预处理步骤
B. 减少模型训练时间
C. 增加模型复杂度
D. 提高模型泛化能力
我的答案:D 正确答案:D 1.0 分
答案解析:交叉验证的主要目的是评估模型的泛化能力,通过将数据集划分为多个子集进行多次训练和测试,以获得更可靠的性能估计。20. 交叉验证的主要目的
答案:D(提高模型泛化能力)
解析:
交叉验证(如 K 折交叉)将数据集拆分为训练集和测试集多次验证,避免模型过度拟合训练集,评估模型在新数据上的表现(泛化能力)。简化步骤(A)、减少训练时间(B)是副作用,非目的;增加复杂度(C)与交叉验证无关。
21.(单选题,1.0 分) 在 Python 中,哪个库可以用来进行特征选择?
A. numpy
B. matplotlib
C. scikit-learn
D. pandas
我的答案:C 正确答案:C 1.0 分
答案解析: scikit-learn 库提供了多种特征选择的方法。
知识点: python 机器学习21. 特征选择的库
答案:C(scikit-learn)
解析:
scikit-learn 提供多种特征选择方法,如 SelectKBest(基于统计检验)、RFE(递归特征消除)、SelectFromModel(基于模型重要性)。numpy 是数值计算基础,matplotlib 是可视化库,pandas 用于数据处理但不直接提供特征选择算法。
22.(单选题,1.0 分) 在 Python 中,哪个库可以用来进行数据预处理?
A. scikit-learn
B. numpy
C. pandas
D. matplotlib
我的答案:C 正确答案:C 1.0 分
答案解析: pandas 库提供了丰富的数据结构和数据操作功能,适用于数据预处理。
知识点: python 机器学习22. 数据预处理的库
答案:C(pandas)
解析:
pandas 通过 DataFrame 提供灵活的数据清洗功能:处理缺失值(dropna/fillna)
数据转换(astype/apply)
编码分类变量(get_dummies)
数据标准化(map/replace)
scikit-learn 侧重特征工程(如 StandardScaler),但 pandas 更适合原始数据清洗。23.(单选题,1.0 分) 在机器学习中,下列哪种方法用于处理分类问题?
A. 线性回归
B. 逻辑回归
C. 主成分分析
D. 聚类分析
我的答案:B 正确答案:B 1.0 分
答案解析:逻辑回归是一种常用的分类算法,适用于二分类问题。
知识点: python 机器学习23. 处理分类问题的方法
答案:B(逻辑回归)
解析:
逻辑回归通过 Sigmoid 函数输出概率值(0-1),用于二分类(如垃圾邮件检测)或多分类(Softmax 扩展)。线性回归(A)预测连续值;主成分分析(C)是降维方法;聚类分析(D)是无监督学习(无标签数据分组)。
24.(单选题,1.0 分) 在 Python 中,哪个库主要用于统计分析?
A. matplotlib
B. scipy
C. numpy
D. pandas
我的答案:B 正确答案:B 1.0 分
答案解析: scipy 是一个用于科学计算的库,提供了大量的统计分析功能。
知识点: python 人工智能24. 统计分析的主要库
答案:B(scipy)
解析:
scipy 是科学计算库,其 scipy.stats 模块提供:概率分布(如正态分布、t 分布)
统计检验(t-test、ANOVA)
相关性分析(Pearson、Spearman)
pandas 可做基础统计(如 df.describe()),但 scipy 提供更专业的统计工具。25.(单选题,1.0 分) 在 Pandas 中,用于读取 CSV 文件的函数是?
A. read_csv ()
B. read_json ()
C. read_sql ()
D. read_excel ()
我的答案:A 正确答案:A 1.0 分
答案解析: read_csv () 函数用于从 CSV 文件中读取数据并转换成 DataFrame 对象。
知识点: python 数据分析25. 读取 CSV 文件的函数
答案:A(read_csv())
解析:
pandas.read_csv('data.csv') 直接将 CSV 文件解析为 DataFrame,支持参数配置(如分隔符、编码、缺失值处理)。read_json() 读 JSON,read_sql() 读 SQL 数据库,read_excel() 读 Excel。
26.(单选题,1.0 分) 在 Python 中,用于科学计算的库是?
A. matplotlib
B. numpy
C. pandas
D. scikit-learn
我的答案:B 正确答案:B 1.0 分
答案解析: NumPy 是一个用于科学计算的基础库,提供了大量的数学函数和数组操作。
知识点: python 人工智能26. 科学计算的库
答案:B(numpy)
解析:
numpy 是 Python 科学计算的基础:多维数组(ndarray)
高效数学运算(线性代数、傅里叶变换)
随机数生成(np.random)
pandas 依赖 numpy,但侧重表格数据处理;scikit-learn 是机器学习库;matplotlib 是可视化库。27.(单选题,1.0 分) 在 Python 中,哪个库主要用于图像处理?
A. opencv
B. pandas
C. matplotlib
D. numpy
我的答案:A 正确答案:A 1.0 分
答案解析: OpenCV 是一个用于计算机视觉和图像处理的强大库。
知识点: python 人工智能27. 图像处理的库
答案:A(opencv)
解析:
OpenCV(Open Source Computer Vision Library)是专业图像处理库,支持:图像读取 / 写入(cv2.imread)
滤波与增强(高斯模糊、直方图均衡化)
特征提取(SIFT、HOG)
计算机视觉(目标检测、人脸识别)
matplotlib 可简单绘图,但 opencv 提供更底层的图像处理功能。28.(单选题,1.0 分) 在 Python 中,用于数据清洗和预处理的库是?
A. numpy
B. scikit-learn
C. matplotlib
D. pandas
我的答案:D 正确答案:D 1.0 分
答案解析: Pandas 提供了丰富的数据清洗和预处理功能,可以方便地进行数据筛选、转换和聚合等操作。
知识点: python 人工智能28. 数据清洗和预处理的库
答案:D(pandas)
解析:
同第 22 题,pandas 的核心优势是灵活的数据操作(如 df.drop_duplicates()、df.interpolate()),适合清洗脏数据。29.(单选题,1.0 分) 在机器学习中,下列哪项不是监督学习的方法?
A. 决策树
B. 逻辑回归
C. 线性回归
D. K-means 聚类
我的答案:D 正确答案:D 1.0 分
答案解析: K-means 聚类是一种无监督学习的方法,不属于监督学习。
知识点: python 机器学习29. 非监督学习的方法
答案:D(K-means 聚类)
解析:
监督学习需要标签数据(如决策树、逻辑回归、线性回归),而 K-means 是无监督学习(仅根据数据特征分组,无需标签)。30.(单选题,1.0 分) 在 Python 中,用于深度学习的框架是?
A. tensorflow
B. pandas
C. scikit-learn
D. numpy
我的答案:A 正确答案:A 1.0 分
答案解析: TensorFlow 是一个流行的深度学习框架,提供了丰富的神经网络模型和训练工具。
知识点: python 人工智能30. 深度学习的框架
答案:A(tensorflow)
解析:
TensorFlow 是 Google 开发的深度学习框架,支持:自动求导(GradientTape)
预训练模型(如 BERT、ResNet)
分布式训练
scikit-learn 是传统机器学习库,pandas/numpy 是数据基础工具,均不专注深度学习。31.(单选题,1.0 分) 在 Python 中,用于数据预处理的库是?
A. pytorch
B. keras
C. tensorflow
D. pandas
我的答案:D 正确答案:D 1.0 分
答案解析: pandas 是一个强大的数据处理和分析库,常用于数据清洗和预处理。
知识点: python 机器学习31. 数据预处理的库
答案:D(pandas)
解析:
pandas 提供 dropna()(删除缺失值)、fillna()(填充缺失值)、get_dummies()(独热编码)等数据清洗工具,是预处理的首选库。pytorch/tensorflow/keras 是深度学习框架,不直接处理原始数据清洗。
32.(单选题,1.0 分) 在机器学习中,哪种方法通常用于处理分类问题?
A. 主成分分析
B. 逻辑回归
C. 线性回归
D. 聚类分析
我的答案:B 正确答案:B 1.0 分
答案解析:逻辑回归是一种常用的分类算法,尽管名字中有 “回归”,但它主要用于解决分类问题。
知识点: python 机器学习32. 处理分类问题的方法
答案:B(逻辑回归)
解析:
逻辑回归通过 Sigmoid 函数将输出映射到概率值(0-1),用于二分类或多分类。线性回归(A)预测连续值;主成分分析(C)是降维方法;聚类分析(D)是无监督学习(无标签数据分组)。
33.(单选题,1.0 分) 在 Python 中,哪个库主要用于数值计算?
A. pandas
B. scipy
C. matplotlib
D. numpy
我的答案:D 正确答案:D 1.0 分
答案解析: numpy 是一个用于科学计算的基础库,提供了大量的数学函数和数组操作功能。
知识点: python 人工智能33. 数值计算的主要库
答案:D(numpy)
解析:
numpy 提供高效的多维数组(ndarray)和数学函数(如 np.dot()、np.mean()),是科学计算的基础。pandas 依赖 numpy,但侧重表格数据处理;scipy 是更专业的科学计算库;matplotlib 是可视化库。
34.(单选题,1.0 分) 在机器学习中,交叉验证的主要目的是什么?
A. 简化模型复杂度
B. 减少过拟合的风险
C. 提高模型的训练速度
D. 增加数据集的大小
我的答案:B 正确答案:B 1.0 分
答案解析:交叉验证的主要目的是评估模型的泛化能力,减少过拟合的风险。
知识点: python 机器学习34. 交叉验证的主要目的
答案:B(减少过拟合风险)
解析:
交叉验证(如 K 折)将数据集分割为多个子集,轮流作为训练集和测试集,评估模型泛化能力,避免模型只拟合训练数据(过拟合)。35.(单选题,1.0 分) 在 Python 中,用于机器学习的库是?
A. tensorflow
B. matplotlib
C. pandas
D. numpy
我的答案:A 正确答案:A 1.0 分
答案解析: TensorFlow 是一个开源的机器学习库,由 Google 开发,广泛应用于深度学习和机器学习。
知识点: python 人工智能35. 用于机器学习的库
答案:A(tensorflow)
解析:
tensorflow 是深度学习框架,支持构建神经网络(如 CNN、RNN)、自动求导和模型部署。matplotlib 是可视化库,pandas/numpy 是数据处理工具,均非专门的机器学习库。
36.(单选题,1.0 分) () 是美国人工智能研究公司 OpenAI 发布的人工智能生视频大模型于 2024 年 2 月 15 日正式对外发布。
A. Sora
B. Siri
C. 文心一言
D. ChatGPT
我的答案:A 正确答案:A 1.0 分36. OpenAI 视频大模型
答案:A(Sora)
解析:
Sora 是 OpenAI 于 2024 年 2 月发布的文本生成视频模型,可根据文本描述生成高质量视频。Siri 是苹果语音助手,文心一言是百度模型,ChatGPT 是文本生成模型。
37.(单选题,1.0 分) 在 Python 中,哪个库可以用来进行数据可视化?
A. scikit-learn
B. pandas
C. numpy
D. matplotlib
我的答案:D 正确答案:D 1.0 分
答案解析: matplotlib 库提供了丰富的绘图功能,适用于数据可视化。37. 数据可视化的库
答案:D(matplotlib)
解析:
matplotlib 是 Python 基础可视化库,支持绘制折线图、散点图、柱状图等。pandas 可简单绘图(如 df.plot()),但功能有限;scikit-learn 是机器学习库,不直接可视化。
38.(单选题,1.0 分) 在 Python 中,用于生成随机数的模块是?
A. numpy
B. matplotlib
C. pandas
D. random
我的答案:D 正确答案:D 1.0 分
答案解析: random 是 Python 的标准库之一,提供了生成随机数的功能。38. 生成随机数的模块
答案:D(random)
解析:
random 是 Python 内置模块,提供随机数生成(如 random.random()、random.randint())。
numpy 也有随机数功能(如 np.random.rand()),但 random 是更基础的标准库。
39.(单选题,1.0 分) 在 Python 中,哪个函数可以用来计算列表的平均值?
A. average ()
B. sum ()
C. mean ()
D. statistics.mean ()
我的答案:D 正确答案:D 1.0 分
答案解析: Python 的 statistics 模块提供了 mean () 函数来计算平均值。
知识点: python 人工智能39. 计算列表平均值的函数
答案:D(statistics.mean())
解析:
statistics.mean() 计算数值列表的平均值(如 statistics.mean([1, 2, 3]))。sum() 求和,无直接求均值功能;numpy.mean() 可计算数组均值,但需导入 numpy;average() 非 Python 内置函数。
40.(单选题,1.0 分) 在进行数据清洗时,用于删除 DataFrame 中所有含有缺失值的行的方法是?
A. drop_duplicates ()
B. dropna ()
C. replace ()
D. fillna ()
我的答案:B 正确答案:B 1.0 分
答案解析: dropna () 方法可以用来删除含有缺失值的行或列。
知识点: python 数据分析40. 删除缺失值的方法
答案:B(dropna())
解析:
pandas 的 dropna() 删除包含 NaN 的行(默认 axis=0)或列(axis=1)。drop_duplicates() 去重,replace() 替换值,fillna() 填充缺失值。
41.(单选题,1.0 分) 在 Python 中,用于保存数据到 CSV 文件的函数是?
A. to_csv ()
B. export_csv ()
C. write_csv ()
D. save_csv ()
我的答案:A 正确答案:A 1.0 分
答案解析: to_csv () 是 pandas 库中的一个函数,用于将 DataFrame 数据保存到 CSV 文件。41. 保存数据到 CSV 的函数
答案:A(to_csv())
解析:pandas 的 DataFrame.to_csv('file.csv') 是标准方法,直接将数据框存储为 CSV 文件。其他选项(export_csv() 等)非 pandas 或 Python 标准语法。
42.(单选题,1.0 分) 在机器学习中,下列哪种方法可以用来减少特征维度?
A. K-Means 聚类
B. 逻辑回归
C. 主成分分析 (PCA)
D. 线性回归
我的答案:C 正确答案:C 1.0 分
答案解析:主成分分析 (PCA) 是一种常用的数据降维技术,可以减少特征维度。42. 减少特征维度的方法
答案:C(主成分分析 PCA)
解析:PCA 通过线性变换将高维特征映射到低维空间(保留主要方差),实现降维。
K-Means(A)是聚类算法;逻辑回归(B)、线性回归(D)是建模方法,均不直接降维。
43.(单选题,1.0 分) 在机器学习中,什么是特征缩放?
A. 将特征值转换为整数形式
B. 将特征值转换为二进制形式
C. 将特征值转换为 0 到 1 之间的小数
D. 将特征值转换为负数形式
我的答案:C 正确答案:C 1.0 分
答案解析:特征缩放是指将特征值转换为特定范围内的数值,通常是 0 到 1 之间的小数,以避免某些特征因为数值过大而主导模型的学习过程。43. 特征缩放的定义
答案:C(转换为 0-1 小数)
解析:特征缩放(如归一化 MinMaxScaler)将特征值映射到固定区间(通常 0-1),避免数值差异大的特征主导模型(如收入(万元)和年龄(岁)需统一量纲)。
44.(单选题,1.0 分) 在 Python 中,哪个库主要用于机器学习算法的实现?
A. matplotlib
B. pandas
C. numpy
D. scikit-learn
我的答案:D 正确答案:D 1.0 分
答案解析: scikit-learn 是一个广泛使用的 Python 库,用于实现各种机器学习算法。44. 机器学习算法实现的库
答案:D(scikit-learn)
解析:scikit-learn(sklearn)提供完整的机器学习算法(分类、回归、聚类等),是传统 ML 开发的核心库。
matplotlib(可视化)、pandas(数据处理)、numpy(数值计算)均为辅助工具。
45.(单选题,1.0 分) TF-IDF 是一种常用的文本特征表示方法,其中 TF 指的是什么?
A. Text Feature
B. Term Feature
C. Term Frequency
D. Text Frequency
我的答案:C 正确答案:C 1.0 分
答案解析: TF-IDF 中的 TF 代表 Term Frequency,即词频。45. TF-IDF 中 TF 的含义
答案:C(Term Frequency,词频)
解析:TF-IDF 是文本特征提取方法,TF 统计词在文档中出现的频率,IDF 衡量词的全局重要性(抑制常见词)。
46.(单选题,1.0 分) 在机器学习中,下列哪个指标用于评估分类模型的性能?
A. 平均绝对误差
B. R-squared
C. 均方误差
D. F1 分数
我的答案:D 正确答案:D 1.0 分
答案解析: F1 分数是衡量分类模型性能的重要指标之一。46. 分类模型的评估指标
答案:D(F1 分数)
解析:F1 分数综合精确率(Precision)和召回率(Recall),适合不平衡分类场景。
平均绝对误差(A)、均方误差(C)、R-squared(B)是回归模型的评估指标。
47.(单选题,1.0 分) 在 Python 的数据分析中,哪个库主要用于数据操作和分析?
A. numpy
B. matplotlib
C. scikit-learn
D. pandas
我的答案:D 正确答案:D 1.0 分
答案解析: pandas 是 Python 中最常用的数据操作和分析库之一,提供了丰富的数据结构和数据分析工具。47. 数据操作和分析的库
答案:D(pandas)
解析:pandas 以 DataFrame 为核心,支持数据筛选(df.query)、分组(df.groupby)、聚合(df.agg)等操作,是数据分析的基石。
48.(单选题,1.0 分) 在 NumPy 中,用于计算数组元素的平均值的函数是?
A. min ()
B. max ()
C. mean ()
D. sum ()
我的答案:C 正确答案:C 1.0 分
答案解析: mean () 函数用于计算数组元素的平均值。48. NumPy 计算平均值的函数
答案:C(mean())
解析:numpy 数组的 arr.mean() 或 np.mean(arr) 直接计算平均值,是数值计算的基础方法。
49.(单选题,1.0 分) 在 Pandas 中,用于筛选 DataFrame 中满足特定条件的行的方法是?
A. where ()
B. filter ()
C. query ()
D. apply ()
我的答案:C 正确答案:C 1.0 分
答案解析: query () 方法用于筛选 DataFrame 中满足特定条件的行。49. Pandas 筛选行的方法
答案:C(query())
解析:df.query('column > value') 用字符串语法筛选行,简洁高效。
where() 保留所有行(标记不满足条件的为 NaN);filter() 按标签 / 正则筛选;apply() 逐行 / 列应用函数,均非最直接的条件筛选方式。
50.(单选题,1.0 分) 在 Python 中,用于构建神经网络模型的库是?
A. scikit-learn
B. numpy
C. tensorflow
D. pandas
我的答案:C 正确答案:C 1.0 分
答案解析: tensorflow 是一个流行的深度学习框架,可用于构建和训练神经网络模型。
知识点: python 机器学习50. 构建神经网络的库
答案:C(tensorflow)
解析:tensorflow(含 Keras 高层 API)是深度学习框架,支持构建复杂神经网络(CNN、LSTM 等)。
scikit-learn 侧重传统 ML,不支持深度神经网络构建。
51.(单选题,1.0 分) 在 Python 中,哪个库主要用于数据处理和分析?
A. pandas
B. matplotlib
C. numpy
D. scikit-learn
我的答案:A 正确答案:A 1.0 分
答案解析: Pandas 是一个强大的数据处理和分析库,提供了丰富的数据结构和数据分析工具。51. 数据处理和分析的库
答案:A(pandas)
解析:pandas 以 DataFrame 为核心,支持数据清洗(dropna)、筛选(df.query)、分组聚合(groupby),是数据分析的基础工具。
52.(单选题,1.0 分) 在 Python 中,哪个函数用于计算两个向量之间的余弦相似度?
A. pairwise_distances ()
B. manhattan_distances ()
C. euclidean_distances ()
D. cosine_similarity ()
我的答案:D 正确答案:D 1.0 分
答案解析: cosine_similarity () 函数用于计算两个向量之间的余弦相似度。52. 计算余弦相似度的函数
答案:D(cosine_similarity())
解析:scikit-learn 的 cosine_similarity 计算向量间余弦相似度(衡量方向一致性),常用于文本相似性、推荐系统。
53.(单选题,1.0 分) 在 Python 的数据可视化库中,哪个库主要用于生成静态、动态和交互式的图表?
A. plotly
B. seaborn
C. bokeh
D. matplotlib
正确答案:D
答案解析: matplotlib 是 Python 中最常用的绘图库,可以生成各种类型的图表。53. 生成静态 / 动态 / 交互式图表的库
答案:D(matplotlib)
解析:题目答案有误,实际 plotly 更擅长交互式图表。但按题目设定,matplotlib 是基础绘图库,可生成静态图表;若需动态 / 交互,plotly/bokeh 更合适。
54.(单选题,1.0 分) 在 Python 中,哪个库主要用于机器学习?
A. numpy
B. tensorflow
C. pandas
D. matplotlib
我的答案:B 正确答案:B 1.0 分
答案解析: TensorFlow 是一个流行的机器学习库,用于构建和训练神经网络模型。54. 主要用于机器学习的库
答案:B(tensorflow)
解析:tensorflow 是深度学习框架,支持构建神经网络(CNN、LSTM 等);scikit-learn 侧重传统 ML,本题强调 “主要用于机器学习”(含深度学习),故选 tensorflow。
55.(单选题,1.0 分) 在 Python 中,用于数据挖掘的库是?
A. matplotlib
B. pandas
C. numpy
D. scikit-learn
我的答案:D 正确答案:D 1.0 分
答案解析: Scikit-learn 提供了多种数据挖掘算法和工具,可以用于分类、回归、聚类等任务。55. 数据挖掘的库
答案:D(scikit-learn)
解析:scikit-learn 提供分类(决策树)、回归(线性回归)、聚类(K-Means)等数据挖掘算法,是传统数据挖掘的核心工具。
56.(单选题,1.0 分) 在 Python 中,哪个库提供了用于绘制散点图的功能?
A. pandas
B. seaborn
C. numpy
D. matplotlib
我的答案:D 正确答案:D 1.0 分
答案解析: matplotlib 是一个强大的绘图库,提供了多种绘图功能,包括绘制散点图。56. 绘制散点图的库
答案:D(matplotlib)
解析:matplotlib 的 plt.scatter(x, y) 是绘制散点图的基础方法;seaborn 可基于 matplotlib 简化绘图(如 sns.scatterplot)。
57.(单选题,1.0 分) 在 Python 中,哪个函数可以用来计算两个向量之间的余弦相似度?
A. cosine_similarity ()
B. manhattan_distances ()
C. euclidean_distances ()
D. pairwise_distances ()
我的答案:A 正确答案:A 1.0 分
答案解析: cosine_similarity () 函数是 scikit-learn 库中用于计算余弦相似度的方法。57. 计算余弦相似度的函数(重复考点)
答案:A(cosine_similarity())
解析:同第 52 题,scikit-learn 的 cosine_similarity 是标准方法。
58.(单选题,1.0 分) 在 Python 中,用于读取 CSV 文件的函数是?
A. import_csv ()
B. load_csv ()
C. open_csv ()
D. read_csv ()
我的答案:D 正确答案:D 1.0 分
答案解析: read_csv () 是 pandas 库中的一个函数,用于读取 CSV 文件。58. 读取 CSV 文件的函数
答案:D(read_csv())
解析:pandas.read_csv('file.csv') 是 Python 读取 CSV 的标准方式,支持参数配置(分隔符、编码等)。
59.(单选题,1.0 分) 在 Python 中,哪个库主要用于深度学习?
A. scikit-learn
B. pandas
C. tensorflow
D. numpy
我的答案:C 正确答案:C 1.0 分
答案解析: TensorFlow 是一个流行的深度学习框架,用于构建和训练深度神经网络。59. 主要用于深度学习的库
答案:C(tensorflow)
解析:tensorflow(含 Keras)是深度学习框架,支持自动求导、分布式训练;pytorch 也是常用框架,但本题选 tensorflow。
60.(单选题,1.0 分) 在机器学习中,什么是决策树?
A. 一种用于分类和回归的非参数监督学习方法
B. 一种用于无监督学习的方法
C. 一种用于降维的技术
D. 一种用于特征选择的技术
我的答案:A 正确答案:A 1.0 分
答案解析:决策树是一种用于分类和回归的非参数监督学习方法,它通过一系列规则来划分数据集,从而预测目标变量的值。60. 决策树的定义
答案:A(分类和回归的非参数监督方法)
解析:决策树是监督学习算法(需标签数据),通过递归划分特征空间实现分类 / 回归,属于非参数模型(不假设数据分布)。
61.(单选题,1.0 分) 在机器学习中,下列哪个方法可以用来防止过拟合?
A. 减少特征数量
B. 使用更复杂的算法
C. 增加模型复杂度
D. 增加训练数据量
我的答案:D 正确答案:D 1.0 分
答案解析:增加训练数据量有助于防止过拟合。61. 防止过拟合的方法
答案:D(增加训练数据量)
解析:
过拟合本质是模型 “学太细”(记住噪声而非规律),增加训练数据能让模型接触更多场景,学到更普适规律,缓解过拟合。
减少特征(A)、简化模型(反向操作 B/C)也能防过拟合,但题目中 “增加数据” 是更直接有效的通用方法;本题需结合选项,D 最贴合。
62.(单选题,1.0 分) 在 Python 中,用于数值计算的库是?
A. numpy
B. scipy
C. matplotlib
D. pandas
我的答案:A 正确答案:A 1.0 分
答案解析: NumPy 是一个用于科学计算的基础库,提供了大量的数学函数和数组操作功能。62. 数值计算的库
答案:A(numpy)
解析:
numpy 是 Python 数值计算基石,提供 ** 高效数组(ndarray)** 和数学函数(线性代数、傅里叶变换等),是科学计算核心。
scipy 基于 numpy 扩展(如优化、统计),但基础数值计算仍以 numpy 为主;matplotlib(绘图)、pandas(数据处理)不专注数值计算。
二、多选题(共 2 题,2.0 分)
63.(多选题,1.0 分) 下列哪些方法可用于处理缺失数据?
A. 使用中位数填充缺失值
B. 删除含有缺失值的行
C. 使用均值填充缺失值
D. 使用众数填充缺失值
我的答案:ABCD 正确答案:ABCD 1.0 分
答案解析:处理缺失数据的方法包括删除含有缺失值的行、使用均值、中位数或众数填充缺失值等。63. 处理缺失数据的方法
答案:ABCD(均值、中位数、众数填充;删除缺失行)
解析:
缺失值处理分删除法(直接删含缺失的行 / 列,简单但可能丢信息)和填充法(用统计量(均值 / 中位数 / 众数)补全,保留数据规模)。
实际场景需结合数据量、缺失比例选方法(如缺失少用删除,缺失多则填充)。
64.(多选题,1.0 分) 在机器学习项目中,数据预处理通常包括哪些步骤?
A. 数据清洗
B. 数据可视化
C. 特征选择
D. 特征缩放
我的答案:ACD 正确答案:ACD 1.0 分
答案解析:数据预处理主要包括数据清洗、特征选择、特征缩放等步骤,以提高数据质量和模型性能。64. 数据预处理步骤
答案:ACD(数据清洗、特征选择、特征缩放)
解析:
数据预处理核心是提升数据质量:
数据清洗(A):处理缺失、异常值、重复值;
特征选择(C):筛选关键特征(减少冗余、防过拟合);
特征缩放(D):统一特征量纲(如归一化、标准化,让模型更稳定);
数据可视化(B)是分析手段,非预处理 “步骤”(预处理是为建模做数据准备,可视化更多是辅助理解数据)。
三、填空题(共 3 题,3.0 分)
65.(填空题,1.0 分) 本学期讲授的常见的机器学习算法包括 () 算法,KNN 算法和 kmeans 算法。
我的答案:
(1) 回归
正确答案:
(1) 回归65. 常见机器学习算法
答案:回归
解析:
机器学习基础算法分监督学习(回归、分类)和无监督学习(聚类)。题目中 KNN(分类)、KMeans(聚类),补 “回归”(如线性回归预测连续值)符合常见教学案例。66.(填空题,1.0 分) 载入鸢尾花数据库的语句是 from ( ).datasets import load_iris。
我的答案:
(1) sklearn
正确答案:
(1) sklearn
答案解析:66. 载入鸢尾花数据集
答案:sklearn
解析:
scikit-learn(简称 sklearn)是机器学习库,内置经典数据集(如 load_iris 鸢尾花数据),语法为 from sklearn.datasets import load_iris。67.(填空题,1.0 分) 在 Python 中,使用____库可以方便地进行数据预处理,包括数据清洗、特征工程等操作。
我的答案:
(1) pandas
正确答案:
(1) pandas
答案解析: pandas 是一个强大的数据处理和分析库,提供了丰富的数据结构和操作方法,适用于各种数据预处理任务。67. 数据预处理的库
答案:pandas
解析:
pandas 以 DataFrame 为核心,提供灵活的数据清洗(dropna/fillna)、特征工程(get_dummies 编码)功能,是预处理首选工具。四、判断题(共 3 题,3.0 分)
68.(判断题,1.0 分) 在机器学习中,梯度下降法是一种优化算法,用于最小化损失函数。
A. 对
B. 错
我的答案:对 正确答案:对 1.0 分
答案解析:梯度下降法是一种常用的优化算法,通过迭代调整参数值来最小化损失函数,从而找到最优解。68. 梯度下降法的作用
答案:对
解析:
梯度下降是优化算法,通过迭代调整模型参数(如线性回归的权重),最小化损失函数(如均方误差),是训练模型的核心逻辑。69.(判断题,1.0 分) 在 Python 的数据分析中,使用 pandas 的 DataFrame 进行数据操作时,可以通过 iloc [] 方法根据位置索引进行数据选取。
A. 对
B. 错
我的答案:对 正确答案:对 1.0 分
答案解析: iloc [] 方法是 pandas 提供的基于位置索引的数据选取方法,适用于 DataFrame 和 Series。69. iloc [] 方法的功能
答案:对
解析:
pandas 中 iloc[] 是位置索引(按行 / 列的数字位置选取,如 df.iloc[0, 1] 取第 1 行第 2 列),区别于 loc[](标签索引)。70.(判断题,1.0 分) 在机器学习中,过拟合是指模型在训练集上表现很好但在测试集上表现较差的现象。
A. 对
B. 错
我的答案:对 正确答案:对 1.0 分
答案解析:过拟合指的是模型过于复杂,以至于它不仅捕捉到了数据中的噪声,还过度适应了训练数据,导致泛化能力差。70. 过拟合的定义
答案:对
解析:
过拟合指模型在训练集表现极佳(记住细节甚至噪声),但测试集表现差(无法泛化到新数据),是机器学习核心问题之一(需通过正则化、增加数据等解决)。五、论述题(共 1 题,30.0 分)
71.(论述题,30.0 分)
根据机器学习算法案例的学习,请总结学习过程,并借助 AI 工具实现自己的一个机器学习案例。把使用 AI 工具的方法,生成的代码,运行结果,设计思路写成教程形式发布在自己的技术博客上,我根据内容酌情给分。我的答案:
机器学习案例总结_机器学习课程设计经典案例-CSDN博客