快速上手pytest
1. pytest的基础
1.1 什么是pytest
pytest 是 python 中的一个测试框架,用于编写简洁、可扩展的测试代码,帮助开发者验证结果是否与预期相符。
python 中有很多的测试框架,那我们为什么要学习 pytest 呢?
pytest 的优势:
- 不需要复杂的类继承(不像 unittest)
- 支持断言直接使用 python 的 assert 语句
- 提供丰富的插件生态(如生成 HTML 报告、并行测试等)
1.2 pytest的安装
pytest 属于 python 的第三方库(不属于标准库),所有在使用之前需要在 terminal 中进行安装
pip install pytest -i https://pypi.tuna.tsinghua.edu.cn/simple后面指定的是国内源下载,能够提高下载的速度
1.3 第一个测试例子
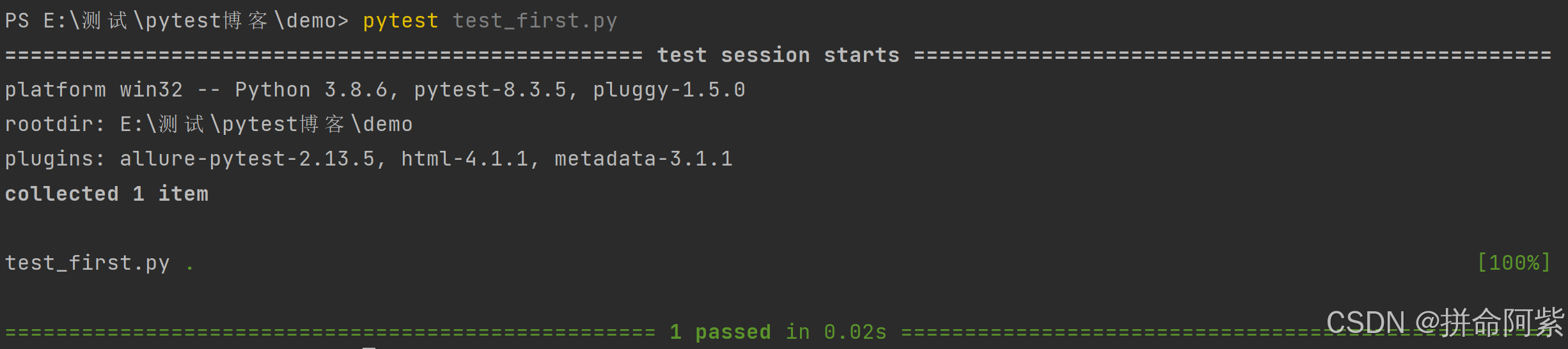
创建一个文件:test_first.py
python文件内容为:
def add(num1, num2):return num1 + num2def test_add():assert add(1, 2) == 3运行代码:pytest test_first.py
2. pytest的核心功能
2.1 测试发现规则
pytest 会自动发现以下的文件:
- 文件名以 test_ 开头 或 _test结尾(如 test_first.py 或 first_test.py)
- 类名以 Test 开头
- 函数名以 test_开头
文件名符合规则,是 pytest 处理文件的前提条件。类/函数符合规则,是执行具体测试的必要条件。
若文件名符合规则,类符合规则,类中的函数不符合规则,则会跳过类中的不符合规则的函数。除非在符合规则的函数里面调用不符合规则的函数。
符合规则的文件+类+不符合规则的函数 :
class TestAdd:def add(self):print(1 + 1)运行结果:

符合规则的文件+类+函数:
class TestAdd:def test_add(self):print(1 + 1)运行结果:
2.2 运行测试的常用方式
运行所有的测试:pytest
运行指定文件:pytest 文件名(符合规则)
运行指定目录:pytest 目录/
运行包含关键字的测试:pytest -k "add" #运行名称关于add的测试
遇到错误时停止:pytest --pdb #进入调试模式
2.3 断言(assert)
直接使用 python 的 assert 语句。
断言的作用:判断实际结果是否与预期结果一致。
在 pytest 中运行测试时,控制台会通过特定符号直观反馈每个测试用例的执行结果。
以下是常见的符号及其含义:
| 符号 | 含义 | 触发场景 |
| . | 测试通过 | 断言成功且无异常 |
| F | 测试失败 | 断言失败(如 assert 1 == 2) |
| E | 代码错误 | 测试代码本身抛出异常(非断言失败) |
| s | 测试跳过 | 使用 @pytest.mark.skip 主动跳过测试 |
| x | 预期失败(XFAIL) | 测试标记为预期失败且确实失败 |
| X | 意外通过(XPASS) | 测试标记为预期失败但实际通过了 |
| w | 警告 | 代码触发了警告(如弃用函数) |
2.4 夹具(Fixture)
2.4.1 夹具的作用与使用
夹具的作用:为测试用例提供预置的环境和资源,避免重复写相同的准备代码,让测试更简洁、可维护。
- 数据库连接
- 临时文件
- 模拟对象
- 共享配置
举个例子:假设你要测试“煮不同口味的面条”
没有夹具:每次煮面都要自己拆包装、烧水、煮面、吃完洗碗......重复劳动。
有夹具:小助手自动帮你完成这些事:提前烧好一锅水(前置准备)、煮好面递给你(提供资源)、你吃完后,它自动洗碗(清理垃圾)。你只需要专注测试“面的味道”,其他杂活都交给它。
夹具的定义:用@pytest.fixture装饰器定义一个夹具
写一个简单的代码(可能与实际业务不符),方便大家理解:
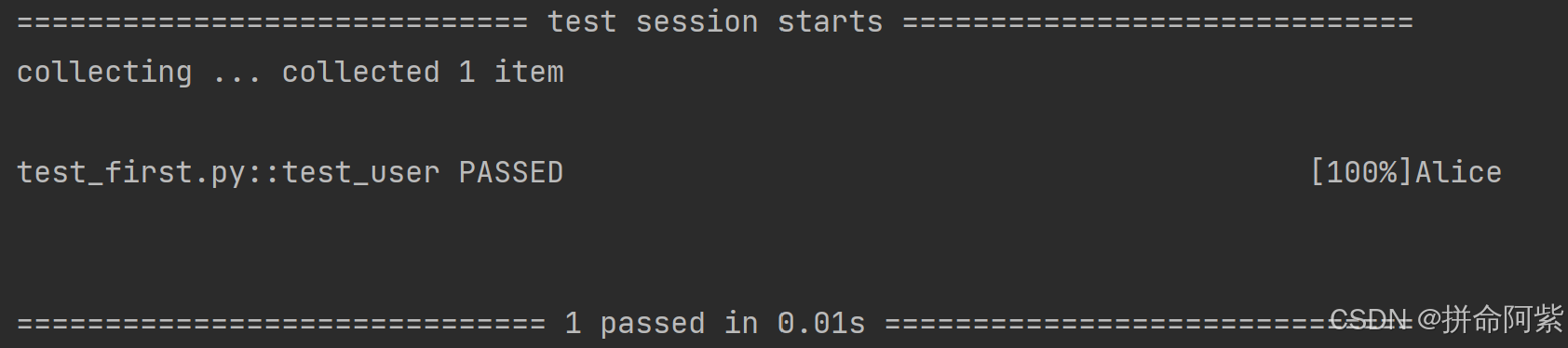
@pytest.fixture
def user():return "Alice"夹具的使用:在测试函数中将夹具作为参数传入即可使用
def test_user(user):print(user)运行结果:
2.4.2 夹具的作用范围(scope)
通过 scope 参数控制夹具的作用域:
- function(默认):每个测试函数执行一次
- class:每个测试类执行一次
- module:每个 python 文件执行一次
- session:整个 pytest 运行过程执行一次
大家看到上面的夹具作用域,可能就有点懵了。可能不明白什么叫做执行一次,接下来就给大家深入解析一下:
并不是说它们只能执行一次,而是说当设置不同的scope参数内容时,它们的作用域是不同的。
作用域为function的代码理解:
import pytestclass TestFruit:@pytest.fixture(scope="function")def ret_fruit(self):return {"A": "apple","P": "pear","W": "watermelon"}def test_fruit1(self, ret_fruit):ret_fruit["A"] = "avocado"print(ret_fruit)def test_fruit2(self, ret_fruit):print(ret_fruit)运行结果:

分析:
夹具作用域(scope="function"):
- 规则:夹具 ret_fruit 在 每个测试函数执行前初始化一次,每个测试函数获得独立的字典对象。
- 初始化:每个测试函数(如:test_fruit1、test_fruit2)执行前,都会调用一次 ret_fruit,生成新字典。
- 清理:每个测试函数结束后清理资源。
- 隔离性:每个测试函数操作的字典是完全独立的对象,互不干扰。
字典虽然是可变的,但 ret_fruit 夹具 每次返回一个新字典。所以在 test_fruit1 中修改字典,不会影响 test_fruit2,因为它们操作的是不同的对象。
作用域为 class 的代码理解:
import pytestclass TestFruit:@pytest.fixture(scope="class")def ret_fruit(self):return {"A": "apple","P": "pear","W": "watermelon"}def test_fruit1(self, ret_fruit):ret_fruit["A"] = "avocado"print(ret_fruit)def test_fruit2(self, ret_fruit):print(ret_fruit)运行结果:

分析:
夹具的作用域(scope="class"):
- 规则:夹具 ret_fruit 在测试类的 第一个测试方法执行前初始化一次,后续所有测试方法共享同一个对象。
- 初始化:在 TestFruit 类的第一个测试方法(如 test_fruit1)执行前生成字典。
- 清理:在 TestFruit 类的最后一个测试方法执行后清理。
- 共享性:类内的所有测试方法(如 test_fruit1 和 test_fruit2)共享同一个字典对象。
字典是可变对象,在 test_fruit1 中修改 ret_fruit["A"] = "avocado" 会直接影响 test_fruit2 中接收的 ret_fruit,因为 ret_fruit 是同一个字典的引用。
2.5 pytest的参数化
2.5.1 什么是参数化测试?
参数化测试:就是用不同测试数据,去反复运行同一个测试函数,避免重复写类似的测试代码。
举例说明:学过测试的小伙伴应该知道,当我们去测一个登录功能的时候,是会有很多条测试用例去测这个登录功能的。那我们进行登录自动化接口测试的时候,那么登录功能就会被抽象成一个函数,测这个功能的测试数据又有很多。如果每个情况都写一个测试函数,那么代码就会很冗余。参数化就可以让你用一个函数跑遍所有情况。
2.5.2 参数化的使用
参数化的使用:@pytest.mark.parametrize("参数名", 参数值列表)
import pytestdef add(a, b):return a + b# 装饰器写法:@pytest.mark.parametrize("参数名", 参数值列表)
@pytest.mark.parametrize("a, b, expected", [(1, 2, 3), (2, 3, 5)])
def test_add(a, b, expected):assert add(a, b) == expected运行结果:
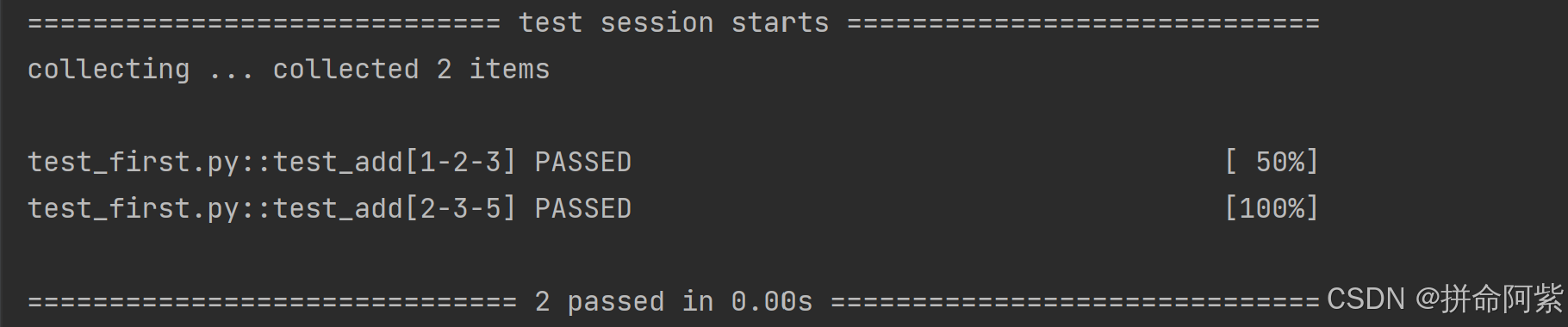
@pytest.mark.parametrize:这是 pytest 提供的参数化装饰器。
第一个参数:“参数名” 是字符串,多个参数用逗号隔开(如 "a, b, expected")。
第二个参数:是一个列表,列表中的每个元素是一组参数值(如 (1, 2, 3)对应一次测试)。
测试函数参数:参数名必须和装饰器中的参数名一一对应(如 a, b, expected)。
上述代码执行测试时,pytest会自动生成 2 个测试用例:
- 用 a = 1, b = 2, expected = 3 运行一次 test_add。
- 用 a = 2, b = 3, expected = 5 运行一次 test_add。
注意:实际中参数值列表部分,通常会采用调用其他函数(获取文件数据函数)获取对应的返回值,来获取参数值列表部分。这样就能够实现代码与数据的分离。
3. pytest的高级功能
3.1 标记(Mark)
3.1.1 跳过测试
跳过测试:@pytest.mark.skip 和 @pytest.mark.skipif
作用:在某些条件下跳过测试,避免执行不必要或暂时无法运行的测试。
直接跳过:
import pytest@pytest.mark.skip(reason="该功能尚未实现")
def test_feature_not_implemented():assert False # 不会执行运行结果:
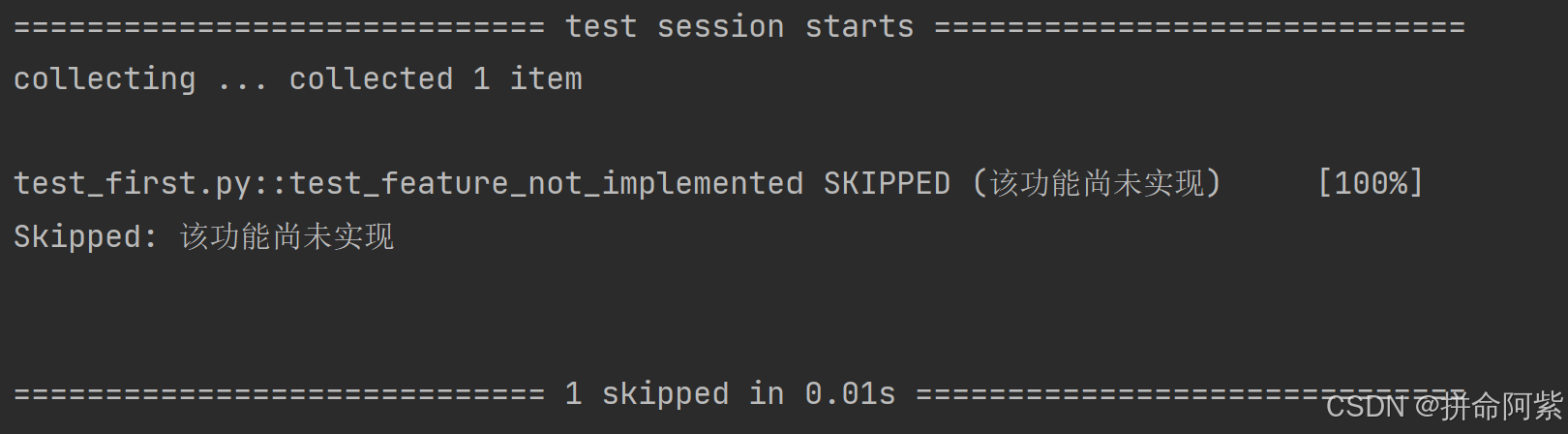
动态条件跳过:
import pytest@pytest.mark.skipif(1 == 1, reason="条件成立跳过")
def test_condition_skipping():pass运行结果:
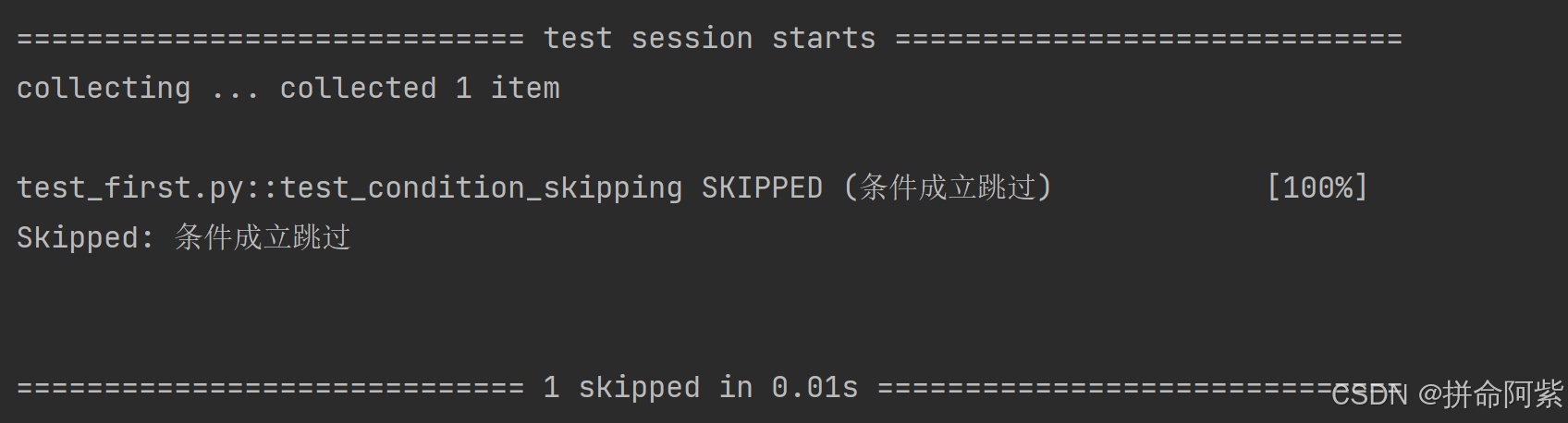
这个只有条件成立才会跳过,不成立则不会跳过。
3.1.2 预期失败
预期失败:@pytest.mark.xfail
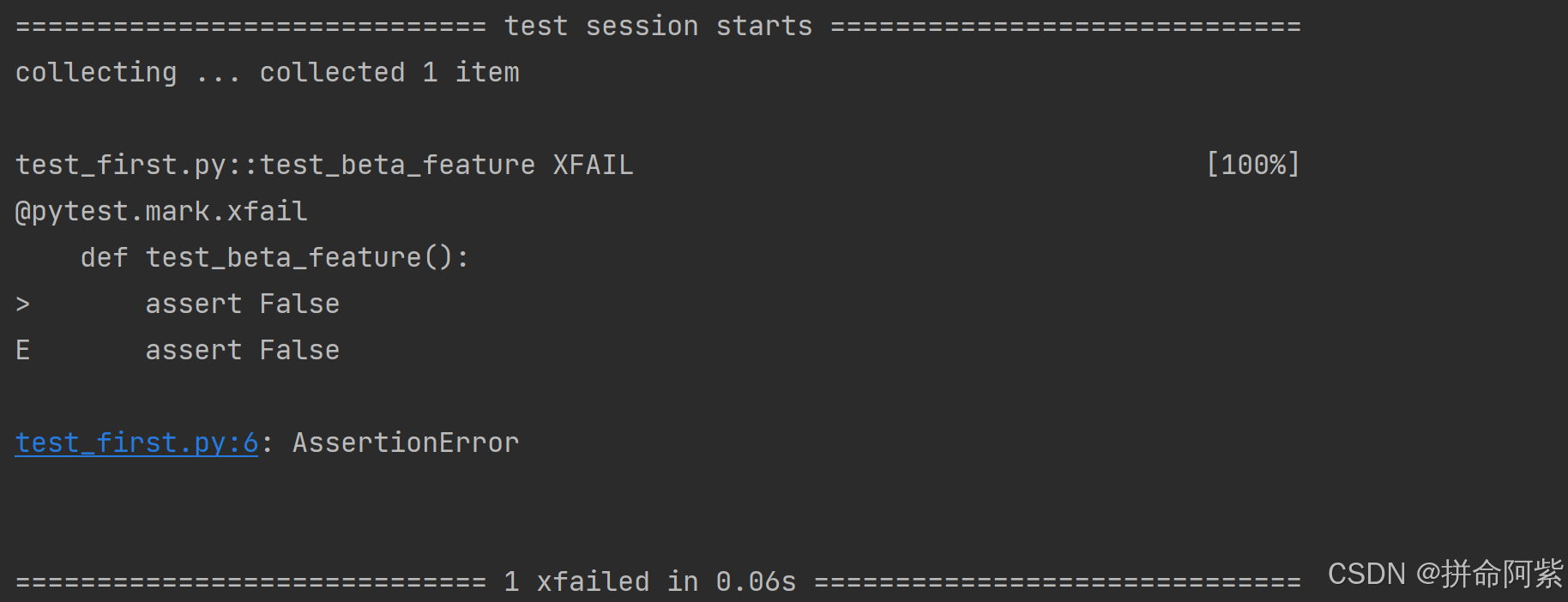
作用:标记已知会失败的测试,测试失败时不计入错误统计(显示为 xfailed)
import pytest@pytest.mark.xfail
def test_beta_feature():assert False运行结果:
3.2 异常测试
作用:验证代码是否抛出预期的异常类型和错误信息
基础异常断言:pytest.raises
import pytestdef test_divide_by_zero():with pytest.raises(ZeroDivisionError):10 / 0结果抛出 ZeroDivisionError,才能测试通过。
运行结果:

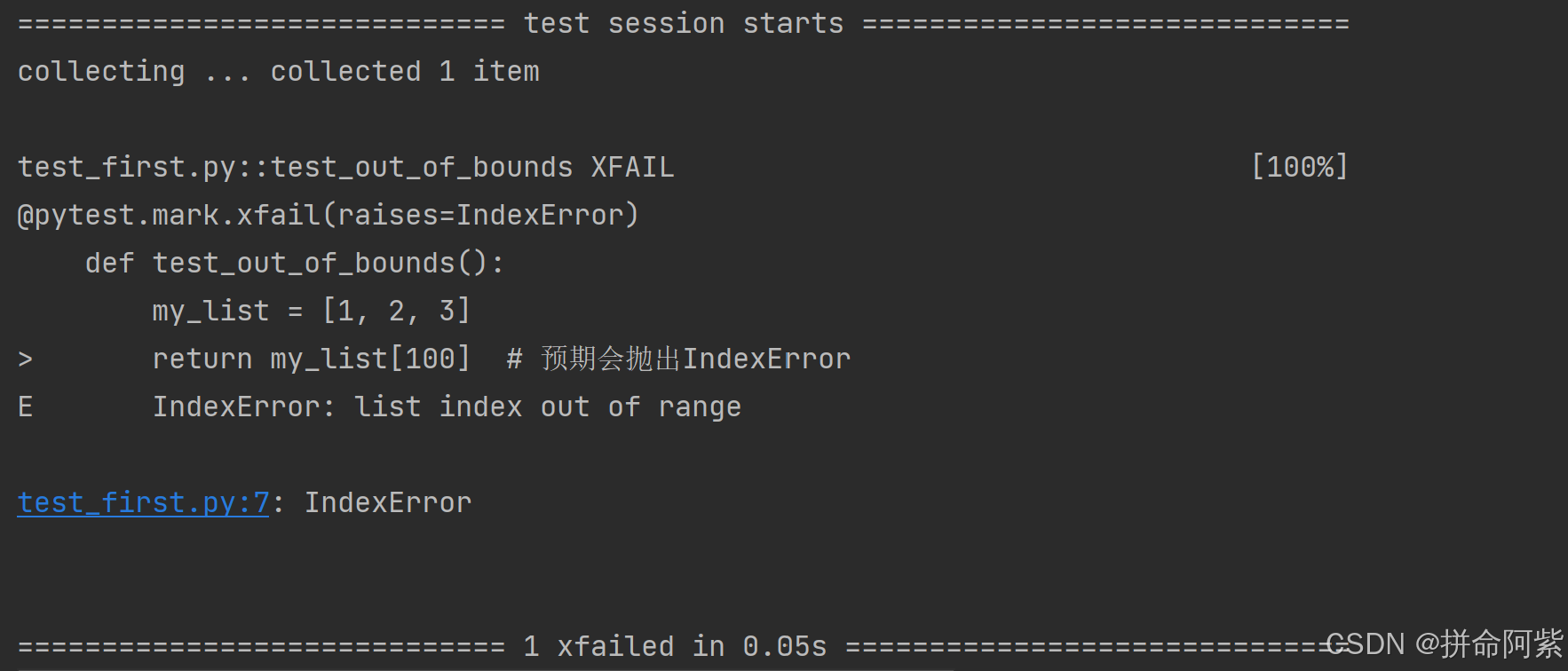
装饰器方式:@pytest.mark.xfail(raises=...)
适用于整个测试函数都预期抛出异常的场景:
import pytest@pytest.mark.xfail(raises=IndexError)
def test_out_of_bounds():my_list = [1, 2, 3]return my_list[100] # 预期会抛出IndexError运行结果: