DPO 算法
一、算法 Pipeline 梳理
(一)DPO 的创新点
DPO 是一种基于人类反馈的强化学习(RLHF)方法的创新。传统的 RLHF 通过奖励模型和 KL 散度约束来优化策略,而 DPO 直接利用偏好数据进行最大似然优化,避免了复杂的强化学习过程和奖励模型的显式训练,简化了流程,提高了效率。
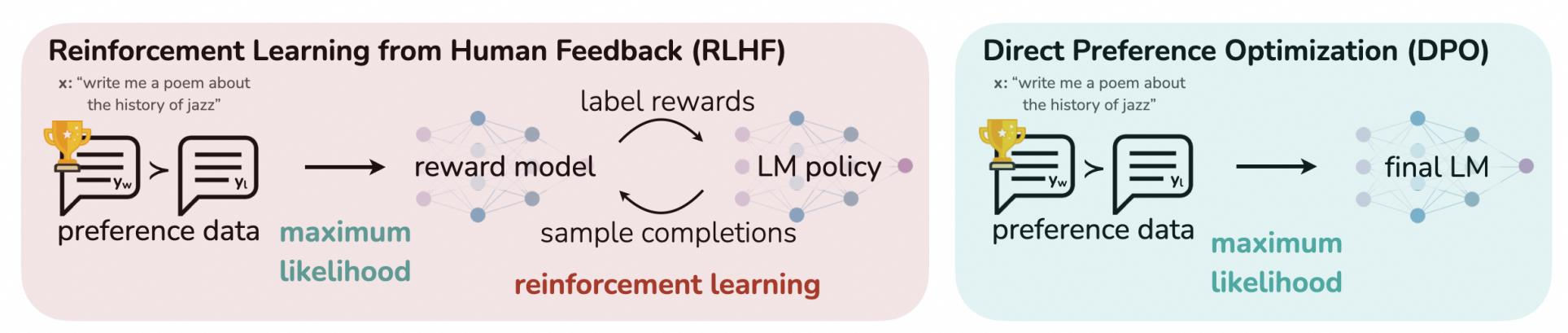
(二)RLHF 的目标函数
 (三)KL 散度回顾
(三)KL 散度回顾

DPO 是一种基于人类反馈的强化学习(RLHF)方法的创新。传统的 RLHF 通过奖励模型和 KL 散度约束来优化策略,而 DPO 直接利用偏好数据进行最大似然优化,避免了复杂的强化学习过程和奖励模型的显式训练,简化了流程,提高了效率。
(三)KL 散度回顾