NLP学习路线图(二十一): 词向量可视化与分析
在自然语言处理(NLP)的世界里,词向量(Word Embeddings)犹如一场静默的革命。它将原本离散、难以捉摸的词语,转化为稠密、富含语义的连续向量,为机器理解语言铺平了道路。然而,这些向量通常栖息在数百维的空间中,远超人类直观感知的范畴。词向量可视化 正是我们照亮这片高维黑暗、探索语言内在规律的关键工具。
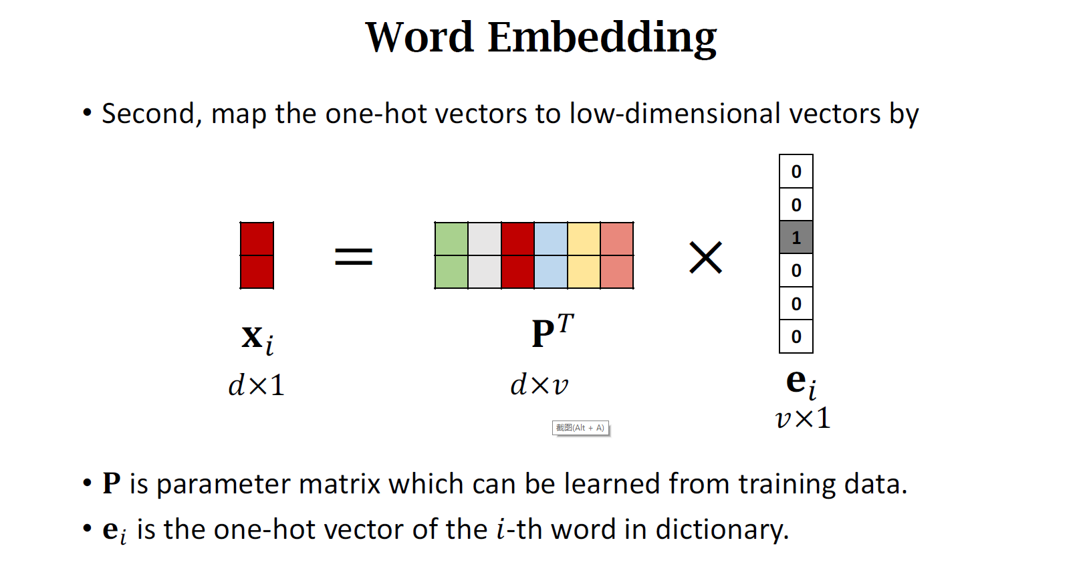
一、词向量基础:从离散符号到连续空间
在词向量出现之前,传统的文本表示方法如 One-Hot 编码存在致命缺陷:
-
维度灾难: 词汇表多大,维度就有多高,计算效率低下。
-
语义鸿沟: “猫”和“狗”的向量(如
[0,0,1,0,...]和[0,1,0,0,...])正交,无法体现它们都是宠物、哺乳动物的相似性。
词向量技术(如经典的 Word2Vec、GloVe,以及现代的上下文相关模型如 BERT 的嵌入层)通过神经网络或矩阵分解,将每个词映射到一个低维稠密向量空间(如50维、100维、300维)。其核心思想是:语义相似的词,其向量在空间中的距离(如余弦相似度)也相近。 词向量不仅捕获了语义相似性,还蕴含了丰富的语言规律:
-
语义相似性:
vec("king")≈vec("monarch") -
语义关系:
vec("king") - vec("man") + vec("woman") ≈ vec("queen") -
类比关系:
vec("Paris") - vec("France") ≈ vec("Berlin") - vec("Germany")
二、为何需要可视化高维词向量?
面对动辄几百维的数据点,人类的认知系统束手无策。可视化扮演了至关重要的角色:
-
直观验证: 检查训练好的词向量是否真的捕获了语义关系?相似词是否聚在一起?
-
模型诊断: 发现潜在问题,如某些类别词语的异常聚集、模型对特定领域或偏见的编码。
-
探索性分析: 发现预料之外的语言模式、聚类或语义子空间结构。
-
教育与理解: 向学生或非技术人员直观展示词向量的工作原理和强大能力。
-
调试与改进: 指导模型的改进方向(如调整超参数、处理生僻词)。
三、核心武器:降维算法
将高维词向量投影到2D或3D空间,离不开强大的降维算法。它们旨在尽量保留高维空间中的关键结构(如距离、邻近关系)。
-
主成分分析 (PCA - Principal Component Analysis)
-
原理: 寻找数据中方差最大的方向(主成分),作为新的坐标轴。它保留的是全局的方差信息。
-
优点: 数学原理清晰,计算高效。
-
缺点: 对非线性结构捕捉能力差。在词向量可视化中,常常只能展示最显著的大类区分(如名词动词分开),细微的语义聚类效果不佳。
-
适用场景: 快速查看数据的主要分布趋势,作为初步分析。
-
-
t-分布随机邻域嵌入 (t-SNE - t-Distributed Stochastic Neighbor Embedding)
-
原理: 专注于保留局部邻域结构。它在高维空间计算点对之间的相似度(通常用条件概率表示),然后在低维空间尝试匹配这些相似度的分布(使用t分布处理长尾问题)。简单说,它努力让“邻居”在低维空间也保持“邻居”关系。
-
优点: 对揭示局部聚类结构效果极佳,能清晰展现语义相似的词簇。
-
缺点:
-
计算复杂度高,大数据集较慢。
-
超参数(困惑度
perplexity)对结果影响大,需要调整。 -
不保留全局结构:簇间距离、整体形状在低维图中可能没有意义。放大或缩小的簇不代表实际距离变化。
-
每次运行结果可能略有不同(随机初始化)。
-
-
适用场景: 探索词向量中的语义聚类、发现近义词群、分析特定领域词的分布。是当前词向量可视化最主流的工具。
-
-
均匀流形近似与投影 (UMAP - Uniform Manifold Approximation and Projection)
-
原理: 基于流形学习和拓扑数据分析理论。它先在高维空间构建一个表示数据点邻域关系的加权图,然后在低维空间优化一个相似的图结构。它同时兼顾了局部结构的精确性和全局结构的相对保持。
-
优点:
-
可视化效果通常优于t-SNE,聚类更紧凑,全局结构保持更好(簇间距离更有意义)。
-
运行速度显著快于 t-SNE,尤其适合大规模数据集。
-
超参数相对鲁棒。
-
-
缺点: 数学原理比PCA和t-SNE更复杂。
-
适用场景: 大规模词向量可视化、需要同时关注局部聚类和全局结构时。是t-SNE的有力替代者和升级选择。
-
如何选择?
-
快速概览或看主要方向:
PCA -
深入探索语义聚类和局部结构:
t-SNE或UMAP(优先推荐UMAP,因其速度和全局结构保持优势) -
大数据集:优先
UMAP
四、实践之旅:工具与案例
理论需要落地。让我们动手实现词向量可视化:
工具选择
-
Python 生态:
-
scikit-learn:提供PCA,TSNE(sklearn.manifold.TSNE),UMAP(umap-learn库需单独安装) 实现。 -
gensim:加载预训练词向量(如Word2Vec,GloVe格式)。 -
matplotlib/seaborn:绘图。 -
TensorFlow Projector:强大的交互式可视化工具(常与TensorBoard集成)。
-
-
专用工具:
TensorFlow Projector是一个独立在线工具,也常嵌入Jupyter Notebook。
案例演示:可视化中文财经新闻词向量
假设我们已用 Word2Vec 训练了一个基于中文财经新闻语料的词向量模型 (model.wv)。
import gensim
import numpy as np
from umap import UMAP
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import matplotlib.font_manager as fm# 1. 加载预训练模型 (示例路径)
model = gensim.models.Word2Vec.load('finance_news_word2vec.model')
word_vectors = model.wv# 2. 选择感兴趣的词语列表
target_words = [# 金融机构'银行', '证券', '保险', '基金', '信托', '券商', '交易所',# 金融操作'贷款', '存款', '投资', '融资', '理财', '结算', '支付', '转账', '赎回', '申购',# 市场与指标'股市', '债市', '汇率', '利率', '通胀', 'GDP', 'CPI', '指数', '牛市', '熊市',# 金融产品'股票', '债券', '期货', '期权', '外汇', '黄金', '原油',# 角色'投资者', '股东', '储户', '借款人', '分析师', '经纪人', '监管机构',# 公司相关'上市', '财报', '市值', '并购', '重组', '分红', '董事会',# 经济状况'增长', '衰退', '繁荣', '萧条', '风险', '稳定', '波动'
]# 3. 提取向量和对应词语
vecs = []
valid_words = []
for word in target_words:if word in word_vectors: # 确保词在词汇表中vecs.append(word_vectors[word])valid_words.append(word)
vecs = np.array(vecs)# 4. 降维 (这里展示UMAP, 可替换为PCA或TSNE)
# UMAP 降维
reducer = UMAP(n_components=2, random_state=42, n_neighbors=15, min_dist=0.1)
umap_embeddings = reducer.fit_transform(vecs)# PCA 降维 (对比)
pca = PCA(n_components=2)
pca_embeddings = pca.fit_transform(vecs)# 5. 可视化 (使用UMAP结果)
plt.figure(figsize=(14, 12))# 获取中文字体
font_path = 'SimHei.ttf' # 替换为你的中文字体文件路径
prop = fm.FontProperties(fname=font_path)# 绘制点
plt.scatter(umap_embeddings[:, 0], umap_embeddings[:, 1], alpha=0.6)# 添加标签
for i, word in enumerate(valid_words):plt.annotate(word, (umap_embeddings[i, 0], umap_embeddings[i, 1]),fontsize=9, fontproperties=prop, alpha=0.8)plt.title('中文财经新闻词向量可视化 (UMAP降维)', fontproperties=prop, fontsize=14)
plt.xlabel('UMAP Dimension 1', fontsize=12)
plt.ylabel('UMAP Dimension 2', fontsize=12)
plt.tight_layout()
plt.show()预期结果分析
运行上述代码,你将得到一张散点图。观察这张图,你能发现:
-
清晰的语义聚类:
-
金融机构簇: “银行”、“证券”、“保险”、“基金”、“信托”、“券商”很可能紧密聚集在一起。
-
金融操作簇: “贷款”、“存款”、“投资”、“融资”、“理财”、“支付”、“结算”、“转账”、“申购”、“赎回”形成另一个核心区域。
-
市场指标簇: “股市”、“债市”、“汇率”、“利率”、“通胀”、“GDP”、“CPI”、“指数”、“牛市”、“熊市”聚集,反映宏观经济和市场动态。
-
金融产品簇: “股票”、“债券”、“期货”、“期权”、“外汇”、“黄金”、“原油”构成投资标的物群体。
-
角色簇: “投资者”、“股东”、“储户”、“借款人”、“分析师”、“经纪人”、“监管机构”关联但又可能细分(如投资者/储户 vs 监管机构)。
-
公司活动簇: “上市”、“财报”、“市值”、“并购”、“重组”、“分红”、“董事会”围绕企业行为聚集。
-
经济状态簇: “增长”、“衰退”、“繁荣”、“萧条”、“风险”、“稳定”、“波动”描述宏观经济状况,可能分布在市场指标簇附近。
-
-
有意义的语义关系:
-
邻近性: “牛市”和“熊市”这对反义词会非常接近(它们描述的是同一事物的两种极端状态),同时都与“股市”、“指数”紧密关联。“贷款”和“存款”会靠近(银行业务核心),同时“贷款”可能靠近“借款人”、“融资”,“存款”靠近“储户”、“理财”。“汇率”可能同时与“外汇”、“支付”以及“进出口”(虽未列出,若有会靠近)相关。
-
类比关系: 虽然没有直接计算,但图中可能隐含
vec("股票") - vec("股市") + vec("债市") ≈ vec("债券")这样的关系模式(需要交互式工具精确测量向量差)。
-
-
领域特性体现: 财经语料训练的词向量,其聚类和关系紧密围绕金融概念展开,与通用语料训练的词向量结构会有显著不同。
交互式探索:TensorFlow Projector
对于更深入的分析,TensorFlow Projector 是利器:
-
准备数据: 保存词向量和词汇表为特定格式(如TSV)。
-
上传: 访问 Embedding projector - visualization of high-dimensional data 上传数据。
-
功能亮点:
-
动态降维: 实时切换PCA、t-SNE、UMAP,调整参数。
-
搜索与高亮: 搜索特定词并高亮其位置及最近邻。
-
向量运算: 直接在界面进行
vec("国王") - vec("男人") + vec("女人")运算,可视化结果向量指向的位置(理想情况是“女王”附近)。 -
区域选择: 框选特定区域,查看该区域包含哪些词。
-
定制视图: 根据词频、自定义元数据(如词性)着色。
-
五、深入分析维度:超越空间位置
可视化点图是起点,更深入的分析需要结合其他技术:
-
近邻分析 (Nearest Neighbors):
-
对于核心词(如“投资”),列出其向量空间中最邻近的K个词。检查这些邻居是否语义相关(如“理财”、“融资”、“股票”、“基金”、“组合”、“回报”、“风险”)。
-
分析邻居分布:是紧密的同义词群,还是松散的相关概念群?是否包含异常值(可能指示模型问题或有趣边缘语义)?
-
-
类比任务 (Analogy Task): 这是评估词向量质量的经典方法。
-
手动或使用标准数据集(如
questions-words.txt的中文版)测试A is to B as C is to ?问题。 -
计算
vec(B) - vec(A) + vec(C),在向量空间中查找与结果向量最接近的词D。 -
可视化:在Projector中执行此向量运算,观察结果向量是否指向预期的D词。例如,计算
vec("上海") - vec("中国") + vec("日本"),理想结果应接近vec("东京")。
-
-
聚类分析 (Clustering): 在原始高维空间或降维后的空间应用聚类算法(如K-Means, DBSCAN, HDBSCAN)。
-
目的: 自动发现词向量空间中的语义群落,可能揭示更细粒度的主题或子领域。
-
应用: 文档主题分类、关键词自动抽取、词典构建。
-
-
维度语义探索 (Exploring Dimensions):
-
虽然单个维度通常无明确语义,但某些方向可能代表特定属性。
-
方法: 寻找在特定维度上具有极端值(最高/最低)的词语,观察它们是否共享某种语义特征(如情感极性、性别倾向、领域特定属性)。
-
示例: 在情感分析模型中,可能发现一个维度强烈区分褒义词和贬义词。
-
六、洞见、挑战与展望
可视化带来的洞见
-
语义拓扑图: 词向量空间是语言语义关系的一种拓扑映射。可视化直观揭示了词语间的亲疏远近,构建出语言的“认知地图”。
-
偏见显影剂: 词向量会学习并放大训练数据中的社会偏见(如性别、种族、职业刻板印象)。可视化能清晰暴露这些问题:
-
vec("程序员") - vec("男人") + vec("女人") ≈ vec("家庭主妇")而非vec("女程序员")。 -
vec("医生")的最近邻可能多为男性名字/称谓,vec("护士")的最近邻则多为女性名字/称谓。
-
-
领域差异透镜: 比较不同语料(通用新闻 vs 医学文献 vs 社交媒体)训练的词向量可视化,能深刻理解语言在不同语境下的语义漂移和侧重。
挑战与局限
-
降维失真: PCA/t-SNE/UMAP都是信息有损压缩。低维投影必然扭曲高维空间的真实几何结构(距离、角度)。过度解读点之间的距离或簇的大小是常见错误。
-
上下文缺失(静态向量): Word2Vec、GloVe生成的是静态词向量(一个词一个固定向量),无法处理一词多义(Polysemy)。例如,“苹果”作为水果和作为公司,在高维空间中可能位于不同位置,但降维后可能重叠或混淆。上下文相关模型(如BERT)的向量可视化更复杂,通常需要先确定具体上下文。
-
可扩展性: 可视化数万、数十万词时,点会过度重叠,标签难以辨认,交互变得卡顿。
-
主观解读: 对可视化的解读具有一定主观性。同一个图,不同人可能看到不同的“模式”或“故事”。需要结合定量分析(近邻、类比得分)进行验证。
-
参数敏感性: t-SNE/UMAP的结果受参数(困惑度、n_neighbors, min_dist)影响较大,不同参数可能得到差异显著的图。
未来方向
-
上下文向量可视化: 如何有效可视化BERT等模型的上下文相关词向量?可能需要结合句子或文档的表示,或聚焦特定词在不同语境下的位置变化。
-
大规模交互可视化: 开发更高效算法和交互技术,支持百万级甚至更大词汇量的流畅探索。
-
可解释AI (XAI) 结合: 将词向量可视化与特征归因、注意力机制可视化等XAI技术结合,提供更全面的模型解释。
-
多维数据整合: 将词向量位置与词频、词性、情感得分、知识图谱信息等多维属性在同一个可视化界面中联动展示。
-
动态演变追踪: 可视化词向量语义随训练过程、随时间推移(如不同年份语料训练)或随新数据加入的演变过程。