【AI论文】VF-Eval:评估多模态大型语言模型(MLLM)在生成人工智能生成内容(AIGC)视频反馈方面的能力
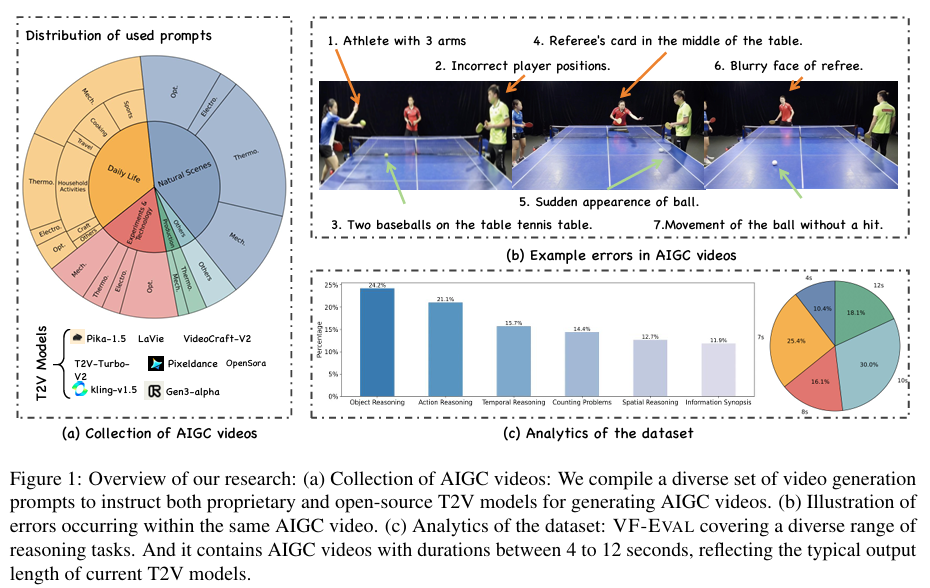
摘要:多模态大型语言模型(MLLMs)最近在视频问答领域得到了广泛研究。然而,现有的大多数评估都侧重于自然视频,而忽视了合成视频,例如人工智能生成的内容(AIGC)。与此同时,一些视频生成领域的研究工作依赖MLLMs来评估生成视频的质量,但MLLMs在解读AIGC视频方面的能力在很大程度上仍未得到充分探索。为了解决这一问题,我们提出了一个新的基准测试——VF-Eval,该基准引入了四个任务——连贯性验证、错误识别、错误类型检测和推理评估,以全面评估MLLMs在AIGC视频方面的能力。我们在VF-Eval上对13个前沿的MLLMs进行了评估,发现即使是表现最佳的模型GPT-4.1,也难以在所有任务上持续取得良好表现。这凸显了我们基准测试的挑战性。此外,为了探究VF-Eval在改进视频生成方面的实际应用,我们进行了一项名为RePrompt的实验,实验表明,使MLLMs更贴近人类反馈进行对齐,可以有利于视频生成。Huggingface链接:Paper page,论文链接:2505.23693
一、研究背景和目的
研究背景:
随着人工智能技术的飞速发展,多模态大型语言模型(Multimodal Large Language Models, MLLMs)在视频理解领域的应用日益广泛。这些模型能够处理并整合来自视觉和文本域的信息,为视频问答、视频内容分析等任务提供了强大的支持。然而,现有的MLLMs评估主要集中于自然视频,而对合成视频,特别是人工智能生成内容(AI-Generated Content, AIGC)视频的评估则相对匮乏。AIGC视频,如通过文本到视频(Text-to-Video, T2V)模型生成的视频,具有独特的纹理、动态光照效果和算法生成的角色等特征,这些特征与传统视频内容存在显著差异,给MLLMs的准确解读带来了新的挑战。
此外,尽管一些视频生成工作已经开始利用MLLMs来评估生成视频的质量,但MLLMs在解读AIGC视频方面的能力尚未得到充分探索。传统的视频质量评估方法,如基于计算机视觉的技术,虽然能够提供定量评分,但往往难以捕捉到与人类偏好不一致或需要改进的细微之处。因此,开发一种能够有效评估MLLMs在AIGC视频上生成反馈能力的基准测试显得尤为重要。
研究目的:
本研究旨在提出一个新的基准测试——VF-Eval,以全面评估MLLMs在生成AIGC视频反馈方面的能力。具体而言,我们希望通过以下四个任务来评估MLLMs的性能:
- 连贯性验证(Coherence Validation):检测AIGC视频与其生成提示之间的不一致性,并生成更合适的视频生成提示。
- 错误识别(Error Awareness):在包含自然视频和AIGC视频的集合中识别出AIGC视频中的错误。
- 错误类型检测(Error Type Detection):识别AIGC视频中可能存在的错误类型。
- 推理评估(Reasoning Evaluation):展示MLLMs在AIGC视频上的细粒度推理能力,包括空间和时间推理、动作和对象推理、计数问题和信息摘要等。
通过VF-Eval基准测试,我们希望能够揭示MLLMs在处理AIGC视频时的局限性,并为未来的模型改进提供指导。
二、研究方法
1. 数据集构建:
为了构建VF-Eval数据集,我们首先收集了大量由T2V模型生成的AIGC视频,这些视频涵盖了各种日常场景,确保了数据集的多样性和广泛性。我们使用了四种专有模型(Pika、Kling、Pixeldance、Gen-3)和一种开源模型(T2V-turbo-v2)来生成视频,并从现有数据集中收集了额外的AIGC视频,如Lavie和OpenSora。
在数据集构建过程中,我们设计了三种类型的问题来评估MLLMs的性能:
- 是非题(Yes-Or-No Questions):主要用于错误识别任务,要求模型判断视频中是否存在错误。
- 选择题(Multiple-choice Questions):用于错误类型检测任务,要求模型从多个选项中选择出视频中存在的错误类型。
- 开放题(Open-Ended Questions):用于连贯性验证和推理评估任务,要求模型对视频与提示之间的连贯性进行评估,并生成改进后的提示,或对视频进行细粒度的推理分析。
2. 评估指标:
对于每个任务,我们定义了相应的评估指标:
- 连贯性验证:使用LLM(如GPT-4.1-mini)对模型生成的答案与人类提供的正确答案进行比较,计算得分。
- 错误识别:计算模型正确识别出AIGC视频中错误的比例。
- 错误类型检测:同样计算模型正确选择出错误类型的比例。
- 推理评估:使用LLM对模型在开放题上的回答进行评分,评估其推理能力。
3. 实验设置:
我们在VF-Eval上评估了13个前沿的MLLMs,包括7个开源模型系列(如InternVL3、LLava-NeXT等)和2个专有模型系列(如GPT-4.1、GPT-4.1-mini等)。对于不支持视频输入的模型,我们根据其上下文窗口的最大图像数量提供了视觉输入。在评估过程中,我们使用了思维链(Chain-of-Thought, CoT)技术来引导模型生成详细的回答。
三、研究结果
1. 整体性能:
实验结果表明,即使是表现最佳的模型GPT-4.1,在VF-Eval的所有任务上也难以持续取得良好表现。这凸显了我们基准测试的挑战性。具体而言,MLLMs在连贯性验证和推理评估任务上的表现较差,这表明它们在理解AIGC视频的细微差别和进行复杂推理方面存在局限性。
2. 任务特定性能:
- 连贯性验证:MLLMs能够大致识别出视频与提示之间的不一致性,但往往难以生成更好的提示来改进视频生成。它们提供的提示通常是对原始提示的简单扩展,缺乏创新性。
- 错误识别:在错误识别任务上,MLLMs在“质量”方面的表现优于“常识和物理”方面。这可能是因为MLLMs缺乏视频质量评估的知识,难以检测到“常识和物理”方面的细微违规。
- 错误类型检测:MLLMs在该任务上的表现低于预期,尤其是在识别道德违规方面。这表明MLLMs在有效利用视觉输入和考虑视频中描绘的道德方面存在不足。
- 推理评估:在推理评估任务上,MLLMs在涉及AIGC视频的推理任务上往往表现不佳。由于AIGC视频中的模糊性、突然出现和消失等问题,MLLMs难以捕捉所有细节,并且视频中的异常结构和突然变化可能与它们的常识知识相矛盾。
3. 人类反馈对比:
通过RePrompt实验,我们发现将MLLMs的反馈与人类偏好更紧密地对齐可以潜在地提高AI生成内容的质量和连贯性。具体而言,使用人类修订后的提示重新生成的视频在主体一致性、背景一致性、审美质量和图像质量等方面均优于原始视频。
四、研究局限
1. 模型范围有限:
本研究仅考虑了文本到视频模型生成的AIGC视频,而未考虑从图像生成视频可能产生的其他类型的错误。未来的研究可以扩展到更广泛的视频生成模型和数据集。
2. RePrompt管道设计简单:
RePrompt管道的设计相对简单,仅融入了人类的文本反馈,并未包括错误案例的具体位置信息,这限制了反馈的粒度。未来的研究可以探索更复杂的反馈机制,以提高视频生成的质量。
3. 跨模态视频未包含:
我们的数据集未包含跨模态视频,而一些视频生成模型也提供音频信息。忽略多模态交互可能产生的更复杂场景是一个局限性。未来的研究可以考虑将音频信息纳入评估范围。
五、未来研究方向
1. 扩展模型范围:
未来的研究可以扩展到更广泛的视频生成模型和数据集,包括从图像生成视频的模型和跨模态视频生成模型。这将有助于更全面地评估MLLMs在AIGC视频上的性能。
2. 改进反馈机制:
探索更复杂的反馈机制,如结合计算机视觉技术和上下文学习,以提高反馈的精确度和粒度。例如,可以使用目标检测技术来定位视频中的错误区域,并提供更具体的反馈。
3. 强化多模态融合:
考虑到跨模态视频的重要性,未来的研究可以强化MLLMs在多模态融合方面的能力。通过整合视觉、文本和音频信息,MLLMs可以更全面地理解视频内容,并生成更准确的反馈。
4. 提升推理能力:
针对MLLMs在推理评估任务上的局限性,未来的研究可以致力于提升模型的推理能力。通过引入更先进的推理算法和训练策略,MLLMs可以更好地捕捉AIGC视频中的细微差别,并进行复杂的推理分析。
5. 探索实际应用:
除了评估MLLMs的性能外,未来的研究还可以探索VF-Eval基准测试在实际应用中的价值。例如,可以将VF-Eval应用于视频生成模型的训练过程中,作为损失函数的一部分来指导模型的优化方向。此外,还可以研究如何将VF-Eval与其他视频质量评估方法相结合,以提供更全面的视频质量评估解决方案。
综上所述,VF-Eval基准测试为评估MLLMs在生成AIGC视频反馈方面的能力提供了一个有效的工具。通过未来的研究和改进,我们有望进一步提升MLLMs在视频理解领域的性能,并推动AI生成内容质量的不断提升。