北京通用人工智能研究院-通才智能体 LEO
北京通用人工智能研究院-通才智能体 LEO
为什么机器人需要理解空间关系?
近年来,多模态大语言模型(MLLMs)在视觉任务上取得了令人瞩目的进步。像GPT-4V、Claude和Gemini这样的模型可以理解图像内容并进行描述,仿佛它们真的"看懂"了图片。然而,这些模型面临一个重要的局限性——它们大多只能处理单一图像的空间理解,就像只能通过一张快照来理解世界,而无法整合多个视角或时间点的信息。
这种局限性严重阻碍了人工智能在机器人和自动驾驶等实际应用中的表现。试想,如果你让机器人"把餐桌上的盘子拿到厨房",它需要从多个角度理解餐桌和盘子的位置关系,然后规划一条路径,最后准确地抓取盘子。这不仅需要理解单帧图像中的空间关系,还需要整合多帧图像的信息,构建一个连贯的环境理解。
如何让AI理解多帧图像中的空间关系?
首先是深度感知(Depth Perception)。想象你正在观察一个房间——有些物体离你很近,有些则很远。人类可以轻松判断物体的远近,这种能力对于理解三维空间至关重要。
其次是视觉对应(Visual Correspondence)。当你从不同角度观察同一个物体时,尽管它在图像中的位置和外观可能变化,但你的大脑会自动识别这是同一个物体。这种能力让研究团队的模型能够在不同图像之间匹配重叠区域,建立一致的场景关联。
动态感知(Dynamic Perception)。这包括理解相机(或观察者)的移动和物体的移动。当你在房间里走动时,你能感知自己的移动方向和速度,同时也能察觉哪些物体保持静止,哪些在移动。
通过整合深度感知、视觉对应和动态感知,Multi-SpatialMLLM展示了在复杂空间任务上的强大能力,为人工智能在现实世界中的应用开辟了新的可能性。
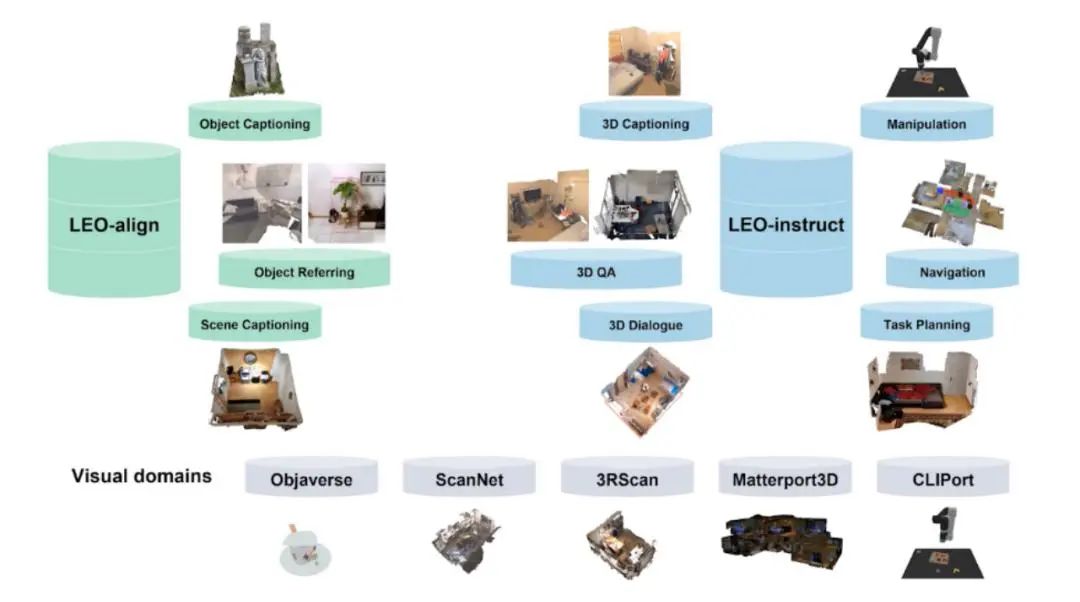
具身多任务多模态的通才智能体 LEO
北京通用人工智能研究院联合北京大学、卡耐基梅隆大学和清华大学的研究人员提出了首个三维世界中的具身多任务多模态的通才智能体 LEO。
通才智能体 LEO 以大语言模型为基础,可以完成感知(perception)、定位(grounding)、推理(reasoning)、规划(planning)和动作执行(acting)等任务。
LEO 的三维视觉语言理解、具身推理和动作执行能力在现实世界中有广泛的应用场景与巨大的应用价值。作为未来的家庭助理,LEO 可以与人交互,回答与场景相关的问题,例如根据用户喜好调整家居布局、帮助用户找到特定物品、为用户的各种问题提供建议。LEO 的导航能力可用于购物中心、办公楼中的智能引导,其操控能力可用于家居自动化任务,如打扫、整理或简单厨房任务,以及仓库和物流中心的物品整理和搬运。
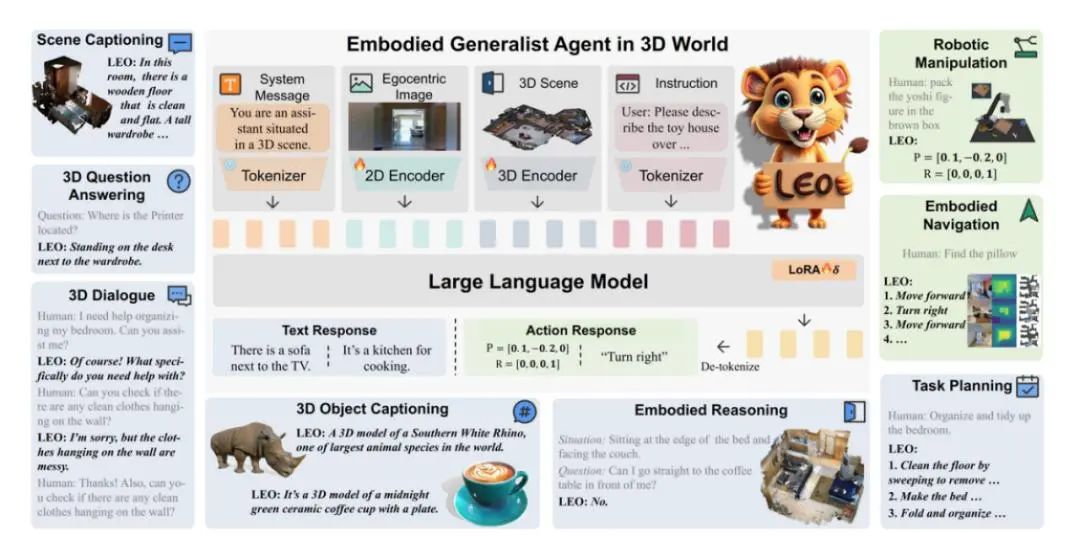
利用 PointNet++ 提取出场景点云中物体级别的特征,随后用空间编码器(Spatial Transformer)对空间位置关系进行建模,从而得到三维场景级别(scene-level)的特征
二维图像则经过预训练模型 OpenCLIP ConvNext 处理得到第一视角的视觉特征。二维和三维的视觉特征最后分别经过 projector 映射到文本空间中。
LLM 方面,采用 Vicuna-7B 作为预训练语言模型来处理 token 序列,训练中,利用 LoRA 方法来微调 LLM