对抗攻击 Adversarial Attack
目录
对抗攻击的简介:
怎么攻击?
快速梯度符号法
白箱攻击和黑箱攻击:
攻击方式:
防御
被动防御
主动防御
对抗攻击的简介:
在输入的图片上加一点杂讯(一般人的肉眼看不见但是会影响机器)输入一只猫的图片,加一点杂讯后输入到“猫咪判别器里”,让判别器输出“不是猫”。
攻击大致分为两类,无目标地攻击:只要让输出的图片不是猫就算攻击成功,有目标的攻击:必须输出是狮子才算攻击成功。
怎么攻击?
无目标的攻击为输入x输出的y,离得正确的y*越远越好。
有目标的攻击为输入x输出的y,离得正确的y*越远且要离y目标越近越好。
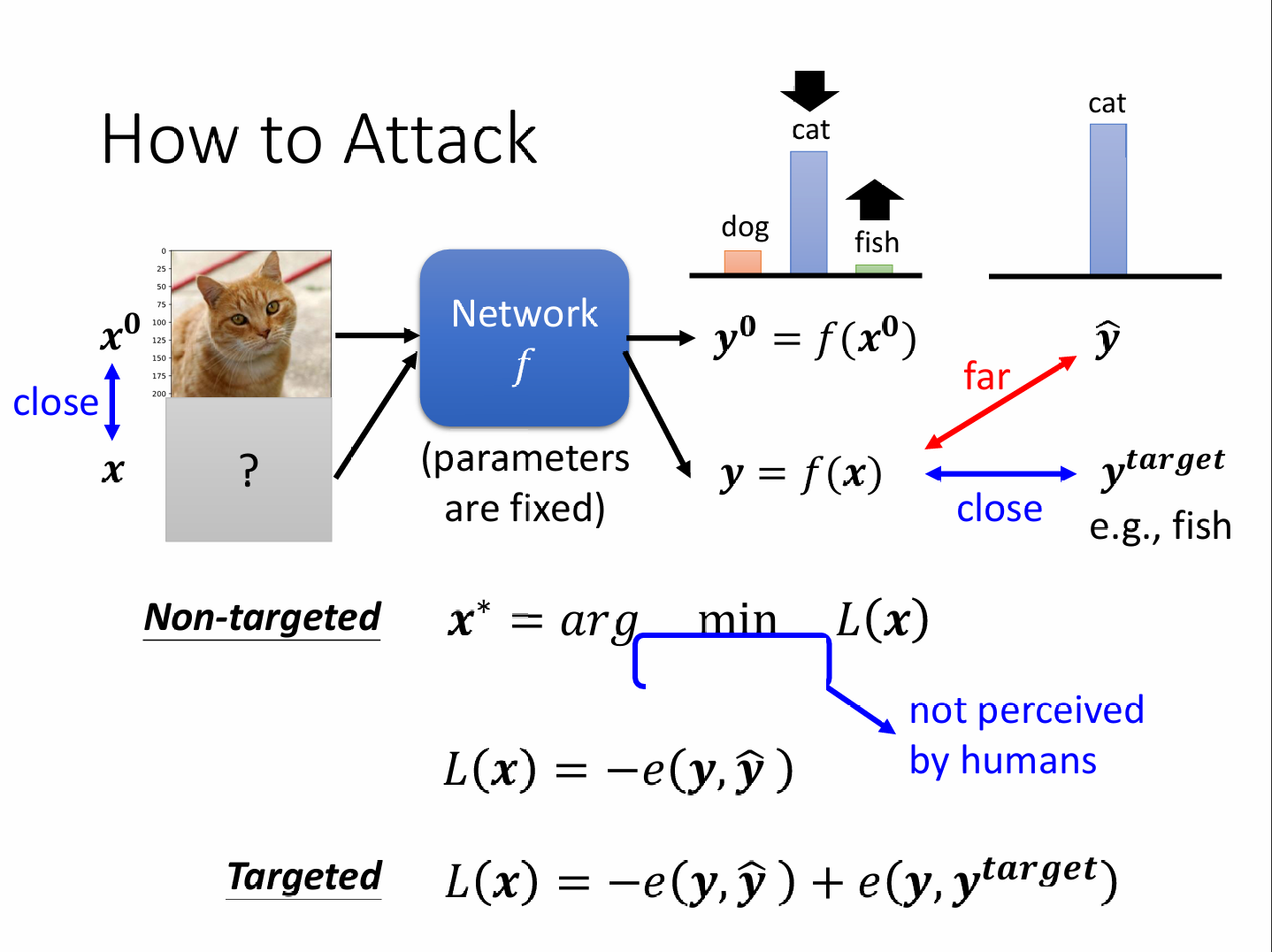
另外,我们还希望加了杂讯的图片与原来的图片越接近越好,用L2范数和L∞范数来表示差距,L2范数看修改的平均差距,L∞范数只看修改后的最大差距。
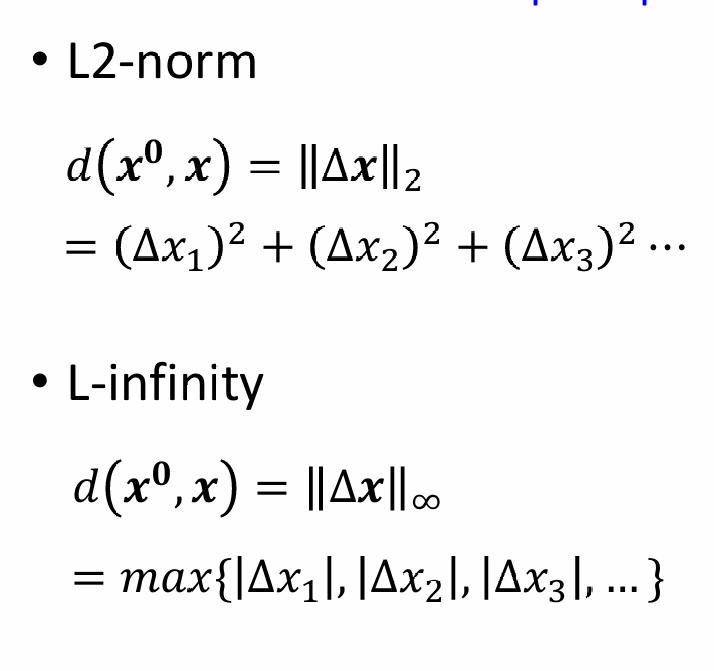
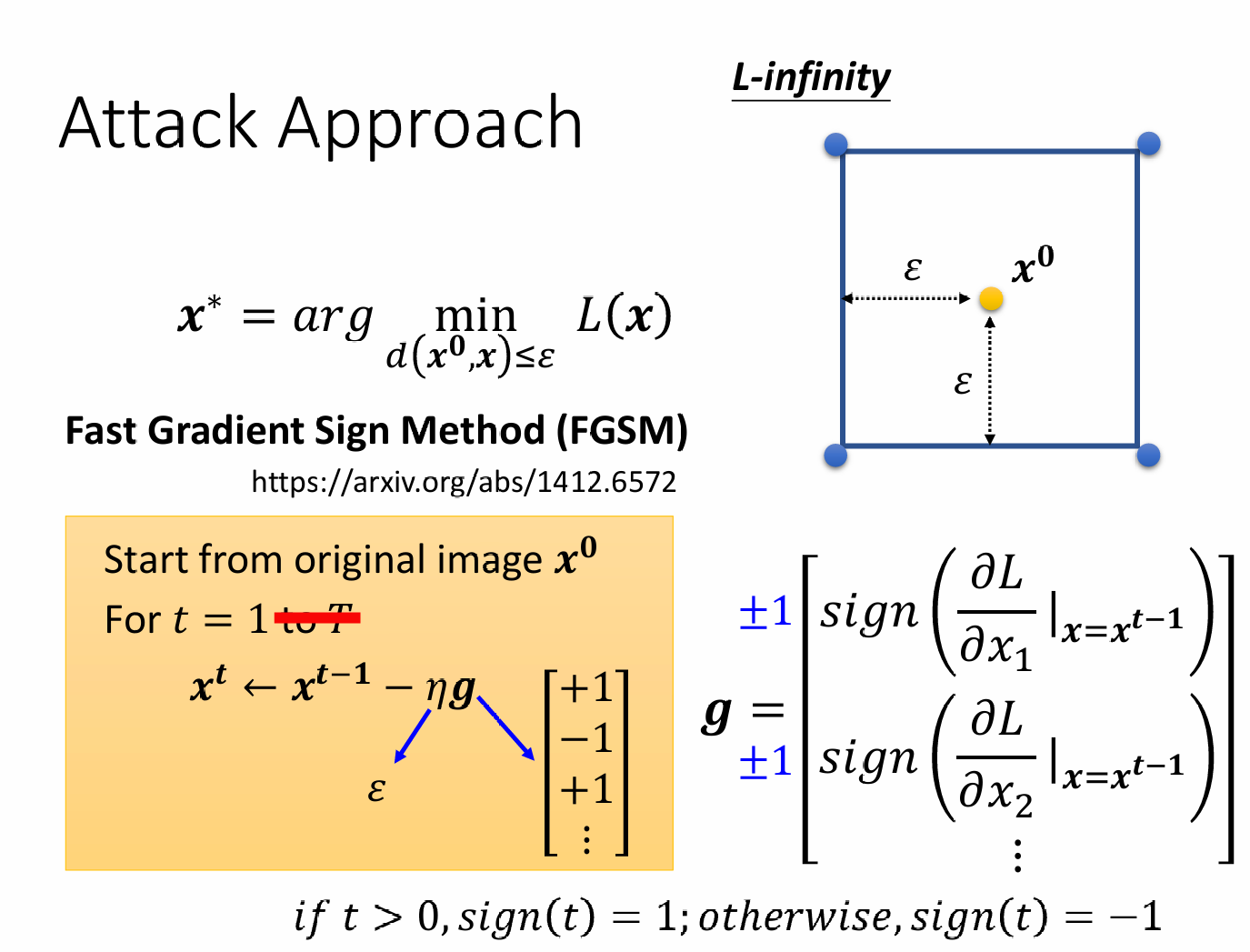
快速梯度符号法
不同于梯度下降需要更新多次参数,快速梯度下降只需要更新一次参数即可。
白箱攻击和黑箱攻击:
我们知道网络模型的具体参数,那么攻击就好了。
如果我们无法知道要攻击的模型的具体参数,但是我们知道它是用的什么样的数据集来训练的这个模型,那么我们可以用他的这些数据集来训练一个与他有相似功能的网络,称为代理网络 ,用代理网络模仿我们要攻击的对象。
我们不知道模型的参数,也不知道训练模型的数据集,那么我们可以用一系列自己的图片,喂给这个模型,然后保存输出,这样我们会得到一组关于这个模型的输入and输出对,用这些对去训练一个模型。
攻击方式:
最小可以做到单像素攻击,只改变图片里的一个像素,就可以导致模型的误判。
通用对抗攻击:找到一个攻击信号,这个信号可以攻击全部的图片。
对抗重编程:帮寄生者干活,比如一个model本来是动物识别,但是被寄生成了空间方块个数识别,用三个方块就输出“金鱼”,有四个方块就输出“食人鲨”。
模型开后门:在模型的训练资料里下毒,让模型看见训练资料的某个细节就出问题。
防御
被动防御
模型不动,在输入的前面加一个Filter滤波器,让原始图片平滑。Filter可以是:模糊化、压缩、用generator重新生成。
这种办法可能很有用,但是如果被别人知道了那就直接完了,比如说加一个模糊化的Filter,但是攻击者完全可以把这个滤波器看成为这个模型的第一层,直接攻击一整个。
主动防御
训练一个比较不会被攻破的模型,将训练数据里的每一张图片都拿出来进行攻击,攻击完之后再给这些被攻击过的图片标上正确的标签。也可以用资料增强,自己攻击自己的模型,然后找出有漏洞的资料并进行纠正。