DAX权威指南6:DAX 高级概念(扩展表)、DAX 计算常见优化
文章目录
- 十四、 DAX 高级概念
- 14.1 扩展表
- 14.1.1 扩展表的定义
- 14.1.2 表扩展与双向过滤
- 14.1.3 筛选上下文传播
- 14.1.4 RELATED 和 LOOKUPVALUE
- 14.1.5 扩展表结构在表定义时就已经确定
- 14.2 表筛选和列筛选
- 14.2.1 表筛选和列筛选
- 14.2.1.1 DAX筛选机制
- 14.2.2 ALL函数的真实含义
- 14.2.3 理解活动的关系
- 14.2.4 扩展表中的上下文转换
- 14.3 理解 ALLSELECTED 和阴影筛选上下文
- 14.3.1 阴影筛选上下文定义和ALLSELECTED的执行规则
- 14.3.2 示例解析
- 14.3.3 ALLSELECTED 的限制与最佳实践
- 14.4 理解ALL系列函数
- 14.4.2 作为表函数
- 14.4.3 作为CALCULATE 修饰符
- 14.5 理解数据沿袭
- 十六、DAX 计算常见优化
- 16.1 计算两个日期之间的工作日天数
- 16.1.1 基础实现
- 16.1.2 性能优化
- 16.1.2.1 分组计算
- 16.1.2.2 计算非工作日
- 16.1.2.3 预计算优化
- 16.2 同时显示预算和销售
- 16.2.1 基础实现
- 16.2.2 优化迭代基础
- 16.3 分析可比销售
- 16.3.1 业务背景
- 16.3.2 模型设计
- 16.3.3 计算同店销售额
- 16.3.4 使用DAX动态计算
- 16.4 高效排序
- 16.4.1 基于上下文转换进行计算
- 16.4.2 避免上下文转换
- 16.4.3 最优方式:使用 RANKX 函数
- 16.5 计算销售截止日期前一年的销售额
- 16.5.1 业务背景
- 16.5.2 修改 PY Sales 度量值
- 16.5.3 代码优化
全文参考《DAX 权威指南 第二版 学习指导》
十四、 DAX 高级概念
14.1 扩展表
14.1.1 扩展表的定义
第一个也是最重要的概念是扩展表。它不仅帮助我们更好地理解数据模型的结构,还能让我们更清晰地掌握筛选上下文的传播机制。
在 DAX 中,每个表都有一个匹配的扩展版本 。扩展表包含了原始表的所有列,以及从源表开始的多对一关系链一端的所有表的列,即表沿着关系中处于一端的方向展开。

模型中所有表及其对应的扩展表为:

-
扩展方向:扩展表沿着关系中处于"一端"的方向展开。
例如,在一个典型的数据模型中,
Sales表与Product表具有一对多关系,Sales表的扩展版本将包含Product表的所有列,但Product的扩展版本不会包含Sales的列。这意味着,当我们引用Sales表时,实际上引用的是它的扩展表,其中不仅有Sales表本身的列,还有与之相关联的Product表的列。 -
扩展深度:扩展不会在第一级停止,而是直到无法再扩展为止。
如果
Sales表通过Product表与Product Subcategory和Product Category表关联,那么Sales的扩展版本将包含这些表的所有列。此外,由于 Sales扩展版本也包含 Date ,所以Sales 的扩展版本包含整个数据模型 。 -
特殊关系处理:
- 双向过滤:上图中, Sales 和 Date 是双向过滤关系。双向过滤是通过关系过滤来实现的(15章会讲),而扩展表的过滤是基于表与表之间的关系链自动完成的,两者方式并不一样。Date 的扩展版本依然只包含 Date 本身 。
- 一对一关系:一对一关系的两个表就会互相扩展 ,可以把这两个表看作一个表,只是分成两组列 。
- 多对多关系:当关系的双方都是"多"时,扩展不会发生。多对多关系的过滤是通过特定的过滤器注入机制实现的,而不是通过扩展表的自动传播
14.1.2 表扩展与双向过滤
双向过滤是指两个表之间过滤条件可以双向传递,互相筛选对方。DAX引擎在表达式中注入过滤代码,使得双向过滤在行为上类似于双向展开。这意味着在大多数情况下,度量值的行为就像表在两个方向上都进行了扩展,但实际上,这并不是表扩展行为。下面将以下模型的所有关系都改成双向过滤 进行测试。

SUMMARIZE函数常用于对表进行分组。当基于一个表对另一个表进行分组时,必须使用扩展表的列。以下SUMMARIZE 语句是有效的:
-- Product表扩展到了Product Subcategory表,因此可以使用Product Subcategory中的Subcategory列。
EVALUATE
SUMMARIZE ('Product','Product Subcategory'[Subcategory]
)

如果尝试使用非扩展表的列进行分组则会报错:在输入表中找不到在“SUMMARIZE”函数中指定的列“Color”。
-- Product Subcategory的扩展表不包含Product[Color],因此会报错
EVALUATE
SUMMARIZE ('Product Subcategory','Product'[Color]
)
RELATED函数也是类似的行为,只能访问扩展表的列。如果尝试访问非扩展表的列,也会报错。
14.1.3 筛选上下文传播
扩展表清楚地解释了筛选上下文如何在DAX公式中工作。当我们对某个列应用筛选器时,筛选器会传播到包含该列的所有扩展表。例如,对Product[Color]的筛选会影响Sales表,因为Sales的扩展版本包含Product表的所有列。
RedSales :=
CALCULATE (SUM ( Sales[Quantity] ),'Product'[Color] = "Red"
)

此模型中,Color 上的过滤器还可以传播到 Date 表,这是通过双向过滤而非扩展表实现的。
14.1.4 RELATED 和 LOOKUPVALUE
在DAX中,RELATED关键字实际上只是访问扩展表相关列的一种方式,例如:
SUMX ( Sales, Sales[Quantity] * RELATED ( 'Product'[Unit Price] ) )
本例中,Unit Price列属于Sales的扩展表,RELATED允许通过指向Sales表的行上下文访问它。要注意的是:
- 扩展表结构在表定义时就已经确定,而不是在使用表时动态生成。
- RELATED 函数用于访问扩展表中的列。它依赖于扩展表的结构,并且只能访问当前上下文中的扩展列(依赖表扩展时的活动关系)。
- USERELATIONSHIP 函数用于激活非活动关系,但它不会改变扩展表的结构
基于以上内容,RELATED 函数在计算列中只能访问默认的活动关系。假设在 Sales 中添加一个计算列,计算发货日期所在的季度,以下代码是错的:
Sales[DeliveryQuarter] =
CALCULATE (RELATED ( 'Date'[Calendar Year Quarter] ),USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] )
)
-
CALCULATE 函数会删除行上下文,而 RELATED 函数需要行上下文才能正常工作。
-
RELATED 函数在计算列中只能访问默认的活动关系
RELATED 函数的行为完全依赖于扩展表的结构,而扩展表的结构是在表定义时确定的。在计算列中,行上下文是在表定义时自动生成的,始终使用默认关系展开表,所以RELATED 函数在计算列中只能访问默认的活动关系,即使使用 CALCULATE 和 USERELATIONSHIP也无法改变这一点。
要实现这一点,需要使用使用 LOOKUPVALUE 函数。LOOKUPVALUE 是一个搜索函数,用于根据一个或多个搜索条件,从目标表中检索值。它而不依赖于扩展表或默认关系,其语法为:
LOOKUPVALUE (<ResultColumn>, -- 返回的列<SearchColumn1>, -- 第一个搜索条件的列<SearchValue1>, -- 第一个搜索条件的值[<SearchColumn2>, -- 第二个搜索条件的列(可选)<SearchValue2>], -- 第二个搜索条件的值(可选)...[<AlternateResult>] -- 如果没有找到匹配项的默认值(可选)
)
如果找到匹配项,LOOKUPVALUE 返回 <ResultColumn> 中的值,否则返回 BLANK()。如果定义了<AlternateResult>,则在不匹配时返回此默认值。使用此函数改写上述代码:
Sales[DeliveryQuarter] =
LOOKUPVALUE ('Date'[Calendar Year Quarter], -- 返回的列'Date'[Date], -- 搜索条件的列Sales[Delivery Date] -- 搜索条件的值
)
LOOKUPVALUE具有以下特点:
- 忽略筛选上下文:在目标表上忽略行上下文和外部筛选上下文,但会考虑搜索列上的筛选上下文(当搜索列来自相关表时)。
- 不支持复杂条件:仅支持基于等值的简单查找,不支持直接使用比较运算符(如>,<等)或逻辑运算符(AND/OR)的复杂条件"。如需复杂逻辑,通常需要结合CALCULATE或其他函数实现。
- 独立于关系:LOOKUPVALUE可以不依赖数据模型中的关系进行查找,但也能利用现有关系(如果搜索列来自相关表)
- 当找到多个匹配行时返回错误,除非使用KEEPFILTERS
- 在计算列中使用时可避免某些筛选上下文问题,但在大表上使用时需注意性能影响
14.1.5 扩展表结构在表定义时就已经确定
EVALUATE
VAR SalesA =CALCULATETABLE ( Sales, USERELATIONSHIP ( Sales[Order Date], 'Date'[Date] ) )
VAR SalesB =CALCULATETABLE ( Sales, USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] ) )
RETURN
-- GENERATE逐年迭代日期表中的年份
-- 对每一年(CurrentYear),它会创建一行结果,包含两列:"Sales From A"和"Sales From B"GENERATE (VALUES ( 'Date'[Calendar Year] ),VAR CurrentYear = 'Date'[Calendar Year]RETURNROW ("Sales From A", COUNTROWS ( FILTER ( SalesA, RELATED ( 'Date'[Calendar Year] ) = CurrentYear ) ),"Sales From B", COUNTROWS ( FILTER ( SalesB, RELATED ( 'Date'[Calendar Year] ) = CurrentYear ) )))

- 定义扩展表:扩展表的结构在定义表时确定,因此 SalesA 和 SalesB 的扩展表结构不同
- SalesA 使用 Sales[Order Date] 和 Date[Date] 之间的关系。
- SalesB 使用 Sales[Delivery Date] 和 Date[Date] 之间的关系。
- 在同样的计算上下文中进行验证:使用GENERATE 函数用于生成一个表,其中包含每年的 SalesA 和 SalesB 的计数。
- 统一的 CurrentYear:CurrentYear 是从 Date[Calendar Year] 中提取的,确保了 Sales From A 和 Sales From B 的计算基于相同的年份。
- RELATED 函数的行为:RELATED 函数的行为依赖于扩展表的结构,因此在 SalesA 和 SalesB 的上下文中,RELATED 返回的结果不同。
- 明确的上下文:SalesA和SalesB的上下文在定义时确定(使用哪种h活动关系),整个计算上下文由GENERATE统一管理(计算基于相同的年份)。通过这种复杂的代码结构,避免了上下文转换,确保了 Sales From A 和 Sales From B 的计算结果可以准确对比。
正是因为扩展表在定义表的时候就确定了结构,所以即使使用同样的计算上下文,Sales From A 和 Sales From B的结果也不同。
- 在 SalesA 的上下文中,RELATED(‘Date’[Calendar Year]) 返回的是与 Order Date 相关联的年份。所以Sales From A 计算的是与 Order Date 相关联的每年的销售记录数。
- 在 SalesB 的上下文中,RELATED(‘Date’[Calendar Year]) 返回的是与 Delivery Date 相关联的年份,所以Sales From B 计算的是与 Delivery Date 相关联的每年的销售记录数。
14.2 表筛选和列筛选
14.2.1 表筛选和列筛选
14.2.1.1 DAX筛选机制
在 DAX 中,筛选表和筛选列之间有很大的区别,比如新手常常以为以下表达式结果是相同的:
CALCULATE ([Sales Amount],Sales[Quantity] > 1)CALCULATE ([Sales Amount],FILTER (Sales,Sales[Quantity] > 1)
)
两个表达式在很多场景下的结果可能相同,但计算方式完全不一样。DAX 的筛选机制 始终基于表,而不是直接操作列。因此任何列筛选都会被 DAX 引擎重写为 FILTER(ALL(column), condition)。所以CALCULATE ([Sales Amount],Sales[Quantity] > 1)实际上会被转换为:
CALCULATE([Sales Amount],FILTER(ALL(Sales[Quantity]), Sales[Quantity] > 1)
)
- ALL(Sales[Quantity]) 会移除该列上的现有筛选,确保计算不受外部上下文影响
- FILTER 生成一个临时表,只包含 Quantity > 1 的行。
虽然也是表筛选,但优化后仅处理单列(单列表,可看作列过滤)。所以以上两个表达式,区别为:
- 列过滤:表达式1是直接对表中的某一列进行筛选,通常用于简单的条件筛选(筛选出 Sales 表中 Quantity 大于 1 的行)。列过滤不涉及表的扩展或子集生成。
- 表过滤:表达式2则是使用FILTER 函数对整个表进行筛选,生成一个子集表,CALCULATE再基于这个子集表进行计算。由于表的扩展性,可能会引入额外的筛选效果。
为了演示它们的实际行为,我们在查询中包含了这两个定义:
EVALUATE
ADDCOLUMNS (VALUES ( 'Product'[Brand] ),"FilterCol", CALCULATE ( [Sales Amount], Sales[Quantity] > 1 ),"FilterTab", CALCULATE ( [Sales Amount], FILTER ( Sales, Sales[Quantity] > 1 ) )
)

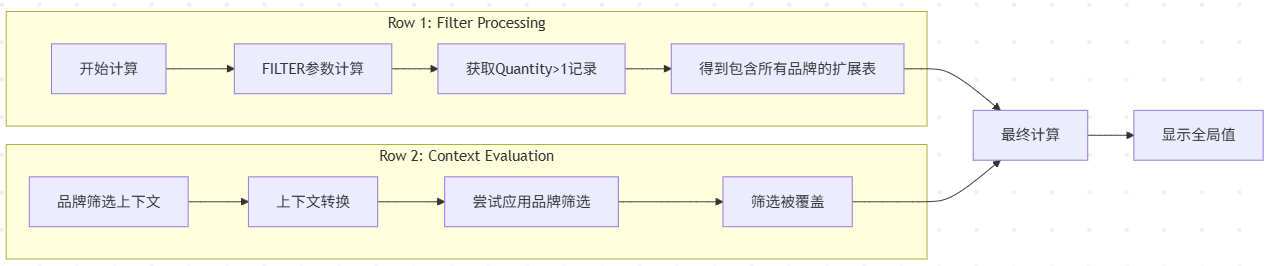
FilterCol 返回的值是符合预期的,而 FilterTab 返回的结果总是所有品牌的总销售额,这是因为FILTER 函数创建了一个新的筛选上下文,这个上下文会覆盖外部传递的品牌筛选上下文。
在DAX中,计算顺序遵循以下步骤:
- CALCULATE先计算它的所有筛选参数
- 然后执行行上下文到筛选上下文的转换
- 最后合并所有筛选器并执行计算
所以整个计算过程为:
- 创建行上下文:在ADDCOLUMNS迭代VALUES(‘Product’[Brand])时,为每一行创建的行上下文
- 计算筛选参数:FILTER 返回扩展表(含Product[Brand]
此时还没有发生上下文转换,FILTER(…) 在原始筛选上下文中计算,获取整个数据集中所有 Quantity > 1 的销售记录,结果是 Sales 表行的子集。在 DAX 中,表引用总是引用扩展的表(即表的扩展形态)。因为 Sales 与 Product 有关系,所以扩展的 Sales 表也包含整个 Product 表。那么,涉及到的所有列中,自然包括 Product[Brand] 列 (所有品牌)。
- 上下文转换:在CALCULATE开始执行时发生上下文转换,转换后的品牌筛选器会与CALCULATE的其他筛选参数合并
- 筛选器覆盖:当多个筛选器作用于同一列时,显式表筛选器(FILTER 结果)替换隐式筛选器(上下文转换),最后应用的筛选器具有更高优先级。
要使FILTER保留外部筛选,可以:
-
使用KEEPFILTERS保留外部筛选
CALCULATE([Sales Amount], KEEPFILTERS(FILTER(Sales, Sales[Quantity] > 1))) -
使用ALL限制清除范围
FILTER(ALL(Sales[Quantity]), Sales[Quantity] > 1)使用 ALL(Sales[Quantity]),可限制FILTER 只在 Sales[Quantity] 列上进行筛选,不会扩展到其他表,不会覆盖外层的 Product[Brand] 筛选器。
当需要同时保护多个列筛选时,以下写法在复杂模型中能精确控制筛选器影响范围,是DAX高级优化的关键技术之一:
FILTER(ALL(Sales[Quantity], Sales[Discount]), -- 明确指定要操作的列Sales[Quantity] > 1 && Sales[Discount] > 0 )此写法可看作增强版列筛选,可实现复杂筛选。但ALL() 会增加VertiPaq引擎的扫描开销,在大型模型中应谨慎使用。变量+SUMX模式可能更高效。
由于表的扩展,使用表过滤总是很有挑战性,可能会导致一些副作用 ;而且表过滤性能不如列过滤,所以黄金法则很简单:尽可能避免使用表过滤 。
14.2.2 ALL函数的真实含义
扩展表:在数据模型中,一个表通过关系自动扩展到所有相关表,所以对主表的操作会影响到所有扩展表中的列。ALL函数用于从表或列中删除筛选器时,不仅是清除主表,还会从所有相关表中移除筛选器。
例如一份报表需要显示子类别的销售额及其在所选产品类别中的占比,最直接的想法是使用ALL函数清除Product Subcategory表上的所有筛选,将其结果作为分母:
Pct :=
DIVIDE ([Sales Amount],CALCULATE ( [Sales Amount], ALL ( 'Product Subcategory' ) )
)
然而,这样做会同时清除扩展表Product表上的所有筛选,所以最终计算结果是所有产品的占比,而不是当前所选类别的占比:

解决方案有几种:
-
使用VALUES恢复筛选器: 函数作用于一个表或列时,用于返回当前筛选上下文中所有唯一值列表。当在CALCULATE中使用时,不是添加新筛选器,而是执行"筛选器还原"操作。
Pct Of Categories := DIVIDE ([Sales Amount],CALCULATE ([Sales Amount],ALL ( 'Product Subcategory' ),VALUES ( 'Product Category' )) )ALL('Product Subcategory')移除了Product Subcategory及其所有扩展表的筛选器,VALUES('Product Category')还原了'Product Category'表上的原始筛选,最终ALL+VALUES组合,实现了"在保持当前类别筛选的同时移除子类别筛选"的效果。实际执行时,DAX 引擎会先应用 VALUES,再应用 ALL,使产品类别的筛选不会被 ALL 意外移除。 -
使用ALLSELECTED:
ALLSELECTED()函数可用于清除当前可视化范围外的所有活动筛选上下文,只保留外部筛选(如切片器、页面筛选器),无需担心扩展表的影响。它简单但功能强大,但它也是一个复杂函数(引入阴影上下文),在复杂表达式中需谨慎使用。Pct Of Visual Total := DIVIDE ([Sales Amount],CALCULATE ([Sales Amount],ALLSELECTED ()) ) -
使用ALLEXCEPT:ALLEXCEPT允许指定保留的列或表。以下代码从Product Subcategory的扩展表中删除除Product Category外的所有筛选器。
Pct := DIVIDE ([Sales Amount],CALCULATE ([Sales Amount],ALLEXCEPT ('Product Subcategory','Product Category')) )
传统数据库使用规范化设计:Product->Product Category->Product Subcategory都是作为单独的表存在,通过外键关系与Product表连接在,这样会形成形成长链式扩展,可能导致很多问题。
如果使用适度的反规范化,比如将Category和Subcategory作为列直接存储在Product表中,只有Sales→Product的直接扩展,可以减少因复杂表关系导致的意外行为。比如此时使用ALL('Product'[Subcategory]),只会移除Subcategory列的筛选,不会影响Category列。
所以,良好的模型设计可以简化DAX编写:
- 分析型模型可以适当反规范化,这可以减少表间复杂关系
- 简单的模型结构使筛选上下文更易于理解和控制
- 在Power BI等分析场景中 ,查询性能和分析简便性通常比存储效率更重要
14.2.3 理解活动的关系
USERELATIONSHIP在表达式中,用于激活非活动关系进行临时计算。比如分别按订单日期和发货日期计算销售额:
DEFINE
MEASURE Sales[Amount] =
SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )MEASURE Sales[Delivered Amount] =
CALCULATE ([Sales Amount],USERELATIONSHIP ( 'Sales'[Delivery Date],'Date'[Date])
)EVALUATE
SUMMARIZECOLUMNS('Date'[Calendar Year],
"Sales Amount",[Sales Amount],
"Delivered Amount",[Delivered Amount])

USERELATIONSHIP作用范围仅限于它所在的 CALCULATETABLE/CALCULATE 内部,外层计算仍然使用模型默认的活动关系。所以以下代码计算的是两种关系结果的交集,由于同一行数据不能同时满足两个日期条件,所以最终结果是空值。
Delivered Amount =
CALCULATE ([Sales Amount], -- 外层使用默认的Order Date关系CALCULATETABLE (Sales, -- 内层使用Delivery Date关系USERELATIONSHIP ( Sales[Delivery Date], 'Date'[Date] ))
)
假设Sales 表只有两行,CALCULATETABLE 的结果是扩展 Sales 表,包括使用 Sales[Delivery Date] 关系的 Date[Date]:

外层过滤时恢复默认的活动关系(Date[Date] 和 Sales[Order Date] ),扩展的 Sales 表如下:

最后,只有 Sales[Order Date] 等于 Sales[Delivery Date] 的行才能通过筛选,没有这样的行,所以结果是空白:

14.2.4 扩展表中的上下文转换
扩展表也影响上下文转换。如果在迭代函数(如SELECTCOLUMNS 或 ADDCOLUMNS)中调用 CALCULATE,会发生上下文转换:当前行的值(行上下文)会转换为对表的筛选器(筛选上下文)。由于扩展表的存在,这种筛选会传递到相关表(如 Product → Product Subcategory → Product Category)。但上下文转换会显著增加计算成本,应当尽量避免。例如以下查询:
EVALUATE
SELECTCOLUMNS ('Product',"Product Key", 'Product'[ProductKey],"Product Name", 'Product'[Product Name],"Category RELATED", RELATED ( 'Product Category'[Category] ),"Category Context Transition",CALCULATE (SELECTEDVALUE ( 'Product Category'[Category] ))
)
ORDER BY [Product Key]
- SELECTCOLUMNS函数:用于从表中选择特定的列,并可以对这些列进行重命名。
- RELATED函数:直接利用行上下文,从相关表中获取值。
- SELECTEDVALUE函数:用于返回筛选上下文中的唯一值。如果筛选上下文中有多行,则返回错误。
这段代码使用两种方式获取关联表的值:
- CALCULATE + SELECTEDVALUE:通过上下文转换生成筛选上下文,利用扩展表的特性间接筛选关联表的值。由于上下文转换的存在,性能较差
- RELATED:直接在行上下文中通过关系获取关联表的值,无需转换上下文,性能更优

14.3 理解 ALLSELECTED 和阴影筛选上下文
14.3.1 阴影筛选上下文定义和ALLSELECTED的执行规则
ALLSELECTED 函数属于 DAX 中的 “ALL 系列” 函数,用于保留用户在可视化中的筛选条件(筛选器或切片器),而忽略当前可视化对象内部的筛选条件,最终根据用户选择,返回当前报表的可见值。比如以下代码可返回各个品牌在当前报表所选品牌中的占比:
Pct :=
DIVIDE ([Sales Amount],CALCULATE ( [Sales Amount], ALLSELECTED ( 'Product'[Brand] ) )
)

但是 DAX 引擎其实是没有“ 当前可视化 ” 概念的,那么DAX 如何知道切片器中选择了?答案是它不知道这些 ,而是在阴影筛选上下文(Shadow Filter Context)上进行操作。与其它 ALL 函数一样,ALLSELECTED 有两种使用方式,但它是唯一利用阴影筛选上下文的 DAX 函数。
-
用作表函数时,ALLSELECTED 返回上一个阴影筛选上下文中可见的值集
-- 示例:获取阴影上下文中可见的品牌 ALLSELECTED('Product'[Brand]) -
用做CALCULATE 修饰符时,还原参数列上的最后一个阴影筛选上下文(最内层)
-- 示例:在计算中还原品牌筛选 CALCULATE([Sales], ALLSELECTED('Product'[Brand]))
阴影筛选上下文由迭代器函数(如 ADDCOLUMNS, SUMMARIZE)在迭代前自动创建,存储迭代器要处理的值集(如矩阵中的所有品牌)。它一直处于休眠状态,仅能被 ALLSELECTED 激活。

-- 正常迭代显式筛选后的品牌
ADDCOLUMNS(VALUES('Product'[Brand]), -- 假设返回[A,B,C]"Sales", [Sales Amount] -- 行上下文依次处理 A → B → C,每次仅筛选单个品牌
)
ADDCOLUMNS(VALUES('Product'[Brand]), -- 阴影上下文存储[A,B,C]"Total", CALCULATE([Sales Amount],ALLSELECTED('Product'[Brand]) -- 激活阴影上下文,强制将品牌筛选改为[A,B,C])
)
当存在多层迭代时,ALLSELECTED 只激活最近一层的阴影上下文:
SUMX( -- 外层迭代VALUES('Category'),ADDCOLUMNS( -- 内层迭代VALUES('Brand'),"X", [Measure] -- 此处的ALLSELECTED只认Brand层)
)
14.3.2 示例解析
上一节的矩阵可视化对象,最接近的查询代码为:
DEFINEMEASURE Sales[Pct] =DIVIDE ([Sales Amount],CALCULATE ( [Sales Amount], ALLSELECTED ( 'Product'[Brand] ) ))EVALUATE
VAR Brands =FILTER (ALL ( 'Product'[Brand] ),'Product'[Brand]IN {"Adventure Works","Contoso","Fabrikam","Litware","Northwind Traders","Proseware"})
RETURNCALCULATETABLE (ADDCOLUMNS (VALUES ( 'Product'[Brand] ),"Sales_Amount", [Sales Amount],"Pct", [Pct]),Brands)
Power BI 中的所有可视化,以及一般情况下由任何客户端工具生成的大多数可视化,都生成相同类型的查询 。在这个查询中:
- 原始筛选:外层的 CALCULATETABLE 创建了一个包含 6 个特定品牌的筛选上下文
Brands。 - 调用原始筛选:VALUES 函数返回这 6 个品牌,传递给 ADDCOLUMNS 进行迭代
- 创建阴影筛选上下文:ADDCOLUMNS 作为一个迭代器,在开始迭代前会基于其输入表(这里是 VALUES 返回的品牌集合)创建一个阴影筛选上下文,包含这 6 个品牌。
- 上下文转换:在迭代过程中,进行上下文转换,将当前行上下文的值(当前品牌)转为筛选上下文
- 迭代计算:在转换后,迭代计算Sales Amount 和 Pct的值。此时还是常规筛选上下文(当前品牌)
- ALLSELECTED 还原阴影筛选上下文:当在计算 Pct 度量时调用了 ALLSELECTED函数。
ALLSELECTED('Product'[Brand])激活并还原了之前由 ADDCOLUMNS 创建的阴影筛选上下文VALUES ( 'Product'[Brand] ),使得计算基于所有选定的6个品牌而非当前单个品牌。

可以看到,查询过程的描述中并没有提及 Power BI 的可视化界面,最终生成的查询结果是一样的,只是缺少总计行。所以ALLSELECTED 的行为并不是直接基于可视化界面中的筛选器,而是基于 DAX 查询中生成的阴影筛选上下文。它的作用只是偶然或者说被设计成可以保留可视化筛选。
如果将上述代码迭代 VALUES(Product[Brand])改为 迭代 ALL(Product[Brand]),即:
RETURNCALCULATETABLE (ADDCOLUMNS (ALL ( 'Product'[Brand] ),"Sales_Amount", [Sales Amount],"Pct", [Pct]),Brands)
此时,由 ADDCOLUMNS 在迭代之前创建的阴影筛选上下文为ALL ( ‘Product’[Brand] ),即所有品牌。所以Pct 度量中ALLSELECTED 将复原阴影筛选上下文,从而使所有品牌可见。

14.3.3 ALLSELECTED 的限制与最佳实践
- 查询必须包含迭代器才能产生阴影筛选上下文,否则 ALLSELECTED 无法发挥作用。
- 如果 ALLSELECTED 之前存在多个迭代器,它只会还原最后一个阴影筛选上下文,这可能导致意外结果。
- 若传递给 ALLSELECTED 的列未被阴影筛选上下文过滤,则 ALLSELECTED 不会产生任何筛选效果。
ALLSELECTED 的最佳实践:
- 仅在可视化直接调用的度量中使用 ALLSELECTED,比如矩阵或表格
- 如果在一个度量中使用了 ALLSELECTED,那么这个度量不应该被其他度量调用。因为当 ALLSELECTED 被嵌套在度量调用链中时,它可能会还原一个与当前上下文不一致的阴影筛选上下文,造成筛选上下文混乱,导致计算结果不正确。
- 当需要保留前一个筛选上下文而非依赖阴影筛选上下文时,可考虑使用 KEEPFILTERS 修饰符。
- 当不使用参数时,还原所有列上的最后一个阴影筛选上下文。若列无阴影上下文 ,保持显式筛选不变。
比如上一节的查询,在内部创建了ALL ( 'Product'[Brand] )阴影筛选上下文之后,如果还想保留外部6个品牌的筛选,可以使用KEEPFILTERS:
RETURNCALCULATETABLE (ADDCOLUMNS (KEEPFILTERS (ALL ( 'Product'[Brand] )),"Sales_Amount", [Sales Amount],"Pct", [Pct]),Brands)
使用KEEPFILTERS之后,ADDCOLUMNS还是在所有品牌上迭代,但是KEEPFILTERS使得筛选上下文ALL ( ‘Product’[Brand] )不会覆盖外层的上下文Brands,即计算是在这6个品牌上进行计算的:

14.4 理解ALL系列函数
| 函数名称 | 表函数功能 | CALCULATE修饰符功能 |
|---|---|---|
| ALL | 返回列或表的所有不同值,忽略现有的任何筛选器。 | 移除列或扩展表的筛选器 |
| ALLEXCEPT | 返回表中列的所有不同值,但列出的列除外 | 移除扩展表筛选器,保留参数列的筛选器。 |
| ALLNOBLANKROW | 返回列或表的所有不同值,忽略因为无效关系添加的空白行。 | 移除列或扩展表筛选器,并添加一个删除空行的筛选器。 |
| ALLSELECTED | 返回最后一个阴影筛选上下文中列或表的不同值。 | 还原最后一个阴影筛选上下文的筛选器 |
| ALLCROSSFILTERED | 不能作为表函数使用。 | 其它ALL函数都是移除表或列上的直接筛选器 只有ALLCROSSFILTERED会移除通过关系传递的交叉筛选器 |
当用作CALCULATE 修饰符时:
ALL:应该叫做 REMOVEFILTER 函数,删除直接过滤器,但不移除交叉过滤器。操作在扩展表上进行,ALL (Sales) 会删除整个模型中的任何过滤器,无参数的 ALL 操作会从整个模型中删除所有过滤器。- 与
ALL / VALUES不同,ALLEXCEPT只删除过滤器,而 ALL 删除过滤器且 VALUES 通过强加新过滤器保留交叉过滤。 ALLNOBLANKROW将所有过滤器替换为只删除空行的新过滤器,所有列只过滤由于无效的关系产生的空值行,但本身是空值的行会保留ALLSELECTED还原每个列上的最后一个阴影筛选上下文。若多个列存在于不同阴影筛选上下文中,则对每个列使用最后一个阴影筛选上下文。ALLCROSSFILTERED:删除扩展表上的所有过滤器,以及因双向交叉过滤器设置的直接或间接连接到的扩展表,所交叉过滤的列和表上的所有过滤器。
14.4.2 作为表函数
ALL函数作为表函数时,结果仅包含基表列:
SUMX (ALL ( Sales ),Sales[Quantity] * Sales[Net Price]
)
但在上下文转换等计算中,DAX会自动使用扩展表(包含关联表的列) 。例如以下两个公式中,度量值引用都伴随隐式CALCULATE ,所以在迭代函数中都发生上下文转换。此处 ALL ( Sales )返回的是整个扩展表,两个公式都是在扩展表上计算。
FILTER (Sales,[Sales Amount] > 100 -- The context transition takes place-- over the expanded table
)
FILTER (ALL ( Sales ),-- ALL is a table function[Sales Amount] > 100 -- The context transition takes place-- over the expanded table anyway
)
14.4.3 作为CALCULATE 修饰符
在下面例子中,我们使用 ALL 作为 CALCULATE 修饰符,来删除 Sales 扩展版本中的任何过滤器:
CALCULATE ([Sales Amount],ALL ( Sales ) -- ALL is a CALCULATE modifier
)
但是在CALCULATE+FILTER+ALL结构中,嵌套在FILTER中里的LL仍表现为表函数,返回整个 Sales 扩展表:
CALCULATE ([Sales Amount],FILTER (ALL ( Sales ),Sales[Quantity] > 0) -- ALL is a table function-- The filter context receives the-- expanded table as a filter anyway
)
14.5 理解数据沿袭
我们在第 10 章 “ 使用筛选上下文 ” 中介绍了数据沿袭,并向读者展示了如何使用 TREATAS 控制数据沿袭 。在第 12 章 “ 使用表 ” 和第 13 章 “ 编写查询 ” 中,我们描述了某些表函数如何操作结果的数据沿袭 。本章节介绍数据沿袭的基本规则:
- 数据沿袭的唯一性:数据模型中表的每一列都有唯一的数据沿袭。
- 筛选上下文依赖:筛选上下文过滤模型时,当筛选上下文过滤模型时,它使用与筛选上下文中包含列相同的数据沿袭来过滤模型列。所以没有数据沿袭的表列是不能过滤的,除非使用TREATAS函数修改沿袭
- 表函数的数据沿袭规则不同:
- 分组列通常保留原始数据沿袭,新增的聚合计算列总是获得新沿袭
SUMMARIZE(Sales,'Product'[Color], -- 保留Product[Color]的原始沿袭"Total Sales", [Sales] -- 新计算列有新沿袭 )- ROW、ADDCOLUMNS、DATATABLE、GENERATESERIES创建的新列或表总是有新沿袭
- SELECTCOLUMNS创建的列如果是原列的引用则保留沿袭,如果是表表达式生成新列获得新沿袭
比如以下代码中,虽然C2列包含与Product[Color]相同的内容,但由于是通过ADDCOLUMNS创建的,它失去了原始沿袭,无法进行筛选。最终Sales Amount计算忽略了颜色筛选,返回了总计值。
DEFINEMEASURE Sales[Sales Amount] =SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )EVALUATE
VAR NonBlueColors =FILTER ( ALL ( 'Product'[Color] ), 'Product'[Color] <> "Blue" )
VAR AddC2 =ADDCOLUMNS ( NonBlueColors, "C2", 'Product'[Color] )
VAR SelectOnlyC2 =SELECTCOLUMNS ( AddC2, "C2", [C2] )
VAR Result =ADDCOLUMNS ( SelectOnlyC2, "Sales Amount", [Sales Amount] )
RETURNResult
ORDER BY [C2]
如果使用 TREATAS 修改数据沿袭,Sales Amount 就能够正确地按颜色分组计算。
DEFINEMEASURE Sales[Sales Amount] =SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )EVALUATE
VAR NonBlueColors =FILTER ( ALL ( 'Product'[Color] ), 'Product'[Color] <> "Blue" )
VAR AddC2 =ADDCOLUMNS ( NonBlueColors, "C2", 'Product'[Color] )
VAR SelectOnlyC2 =SELECTCOLUMNS ( AddC2, "C2", [C2] )
VAR TreatAsColor =TREATAS ( SelectOnlyC2, 'Product'[Color] )
VAR Result =ADDCOLUMNS ( TreatAsColor, "Sales Amount", [Sales Amount] )
RETURNResult
ORDER BY 'Product'[Color]

十六、DAX 计算常见优化
本章是关于DAX语言特性优化前的最后一章,会展示一些用DAX执行的计算示例来锻炼读者运用DAX语言思考的能力。本章会提供相同度量值的不同表达式,分析其复杂性,创造出相同度量值不同版本是性能优化中关键技能。如果是需要即用型案例,可在DAX patterns找到。
16.1 计算两个日期之间的工作日天数
假设我们有一个名为 Sales 的表,其中包含两个日期字段:Order Date(订单日期)和 Delivery Date(交货日期)。我们的目标是计算从订单日期到交货日期之间的工作日天数,并求出所有订单的平均工作日天数。
16.1.1 基础实现
-
直接减法:最直接的方法是使用简单的日期减法,例如,以下度量值计算了平均交付天数,但没有考虑工作日:
Avg Delivery := AVERAGEX (Sales,INT ( Sales[Delivery Date] - Sales[Order Date] + 1 ) ) -
考虑周末:DAX 没有直接的
NETWORKDAYS函数(类似于 Excel 中的函数),但可以通过组合多个函数来实现类似的效果。以下是一个考虑周末的实现:Avg Delivery WD := AVERAGEX (Sales,VAR RangeOfDates = -- DATESBETWEEN 函数生成从订单日期到交货日期之间的所有日期。DATESBETWEEN ( 'Date'[Date], Sales[Order Date], Sales[Delivery Date] )VAR WorkingDates = -- FILTER 函数排除周六(1)和周日(7)。FILTER ( RangeOfDates, NOT ( WEEKDAY ( 'Date'[Date] ) IN { 1, 7 } ) )VAR NumberOfWorkingDays = -- COUNTROWS 函数计算剩余的工作日天数。COUNTROWS ( WorkingDates )RETURNNumberOfWorkingDays ) -
考虑节假日:在
Date表中添加一个名为Is Holiday的列,表示某一天是否是节假日。Avg Delivery WD DT := AVERAGEX (Sales,VAR RangeOfDates =DATESBETWEEN ( 'Date'[Date], Sales[Order Date], Sales[Delivery Date] )VAR NumberOfWorkingDays =CALCULATE (COUNTROWS ( 'Date' ),RangeOfDates,NOT ( WEEKDAY ( 'Date'[Date] ) IN { 1, 7 } ),'Date'[Is Holiday] = 0)RETURNNumberOfWorkingDays )
这个版本的度量值通过以下方式改进了之前的实现:
- 使用
CALCULATE函数直接在Date表上进行计算,而不是生成临时表。 - 通过
Is Holiday列排除节假日。
16.1.2 性能优化
尽管上述实现已经考虑了周末和节假日,但性能仍有提升空间。特别是当 Sales 表很大时,为了优化性能,我们可以采用几种策略。
16.1.2.1 分组计算
对于 Order Date 和 Delivery Date 都相同的订单来说,其交付时间间隔是相同的,所以我们可以先按 Order Date 和 Delivery Date 对订单进行分组,然后计算每组的平均工作日天数,以减少 AVERAGEX 的迭代次数。
Avg Delivery WD WA :=
VAR NumOfAllOrders = COUNTROWS ( Sales )
-- 使用 SUMMARIZE 函数对订单按 Order Date 和 Delivery Date 进行分组。
VAR CombinationsOrderDeliveryDates = SUMMARIZE ( Sales, Sales[Order Date], Sales[Delivery Date] )VAR DeliveryWeightedByNumOfOrders =SUMX (CombinationsOrderDeliveryDates,VAR RangeOfDates = DATESBETWEEN ( 'Date'[Date], Sales[Order Date], Sales[Delivery Date] )VAR NumOfOrders = CALCULATE ( COUNTROWS ( Sales ) )VAR WorkingDays =CALCULATE (COUNTROWS ( 'Date' ),RangeOfDates,NOT ( WEEKDAY ( 'Date'[Date] ) IN { 1, 7 } ),'Date'[Is Holiday] = 0)VAR NumberOfWorkingDays = NumOfOrders * WorkingDaysRETURNNumberOfWorkingDays)-- 使用加权平均值计算平均工作日天数,以订单数量为权重。
VAR AverageWorkingDays =DIVIDE ( DeliveryWeightedByNumOfOrders, NumOfAllOrders )
RETURNAverageWorkingDays
代码复杂性与性能优化的权衡:这段代码复杂性增加,那是否要为了提高性能而使用更复杂的代码得视情况而定。在进行这种优化前,需要通过测试来验证优化是否真的有效。本例中,可通过执行特定的查询来评估迭代次数是否减少。
EVALUATE
{( COUNTROWS ( Sales ), COUNTROWS (SUMMARIZE (Sales,Sales[Order Date],Sales[Delivery Date])) )
}

可以看到, Sales表有100231行,而订单日期和交货日期只有6073个不同的组合,所以此代码通过减少迭代次数,将性能提升了16倍。
16.1.2.2 计算非工作日
另一种优化方法是计算非工作日,因为非工作日的数量通常少于工作日的数量,所以会更高效。
- 计算两个日期之间的非工作日天数。
- 从总天数中减去非工作日天数,得到工作日天数。
Avg Delivery WD NWD :=
VAR NonWorkingDays =CALCULATETABLE (VALUES ( 'Date'[Date] ),WEEKDAY ( 'Date'[Date] ) IN { 1, 7 },ALL ( 'Date' ))
VAR NumOfAllOrders = COUNTROWS ( Sales )
VAR CombinationsOrderDeliveryDates = SUMMARIZE ( Sales, Sales[Order Date], Sales[Delivery Date] )VAR DeliveryWeightedByNumOfOrders =CALCULATE (SUMX (CombinationsOrderDeliveryDates,VAR NumOfOrders = CALCULATE ( COUNTROWS ( Sales ) )VAR NonWorkingDaysInPeriod =FILTER (NonWorkingDays,AND ( 'Date'[Date] >= Sales[Order Date], 'Date'[Date] <= Sales[Delivery Date] ))VAR NumberOfNonWorkingDays = COUNTROWS ( NonWorkingDaysInPeriod )VAR DeliveryWorkingDays = Sales[Delivery Date] - Sales[Order Date] - NumberOfNonWorkingDays + 1VAR NumberOfWorkingDays = NumOfOrders * DeliveryWorkingDaysRETURNNumberOfWorkingDays))VAR AverageWorkingDays = DIVIDE ( DeliveryWeightedByNumOfOrders, NumOfAllOrders )
RETURNAverageWorkingDays
在这段代码中,变量 NonWorkingDays 在 Date 表上调用了 ALL 函数,但在之前的类似筛选条件的表达式中没有出现ALL函数,是因为之前使用了DATESBETWEEN函数,它会忽略筛选上下文。对于以下度量值:
R NonWorkingDays =
CALCULATETABLE (VALUES ( 'Date'[Date] ),NOT ( WEEKDAY ( 'Date'[Date] ) IN { 1, 7 } )
)
虽然表面上看起来筛选条件中没有ALL,但实际上ALL是存在的。通过将紧凑的语法扩展为完整语法,ALL会显现出来:
VAR NonWorkingDays =
CALCULATETABLE (VALUES ( 'Date'[Date] ),FILTER (ALL ( 'Date'[Date] ),NOT (WEEKDAY ( 'Date'[Date] )IN {1,7}))
)
ALL函数作用在Date表中的Date列上,而Date表被标记为日期表,所以引擎会自动在整个Date表上添加ALL函数。
当在矩阵中使用时,Date表会被筛选得到一个较小的时间区间。如果订单日期不在这个选定的时间区间内,会导致计算结果不正确。因此,在使用非工作日构建表之前,需要去除Date表中的筛选上下文,ALL函数在这里起到了这个作用。
虽然可以通过这种方式编写代码,但为了避免度量值含糊不清且难以阅读,更倾向于使用更明确的表达方式来编写代码,使其更易于阅读。
如果数据模型中订单的持续时间比较短,此代码会比上一节的版本更慢,但如果持续时间明显延长时,此代码性能会更好。只有通过测试,才能得出最终的正确答案。
16.1.2.3 预计算优化
性能优化的最佳选择是预先计算该数值。无论哪种方法计算,订单日期和交货日期有6073 种不同组合是不变的。我们可以预先计算所有这些组合之间的工作日差异,并将结果存储在一个隐藏的表中。在查询时,只需简单查找即可。
-
创建隐藏表
WD Delta = ADDCOLUMNS (SUMMARIZE ( Sales, Sales[Order Date], Sales[Delivery Date] ),"Duration", [Avg Delivery WD WA] ) -
查询结果
Avg Delivery WD WA Precomp := VAR NumOfAllOrders = COUNTROWS ( Sales ) VAR CombinationsOrderDeliveryDates = SUMMARIZE ( Sales, Sales[Order Date], Sales[Delivery Date] ) VAR DeliveryWeightedByNumOfOrders =SUMX (CombinationsOrderDeliveryDates,VAR NumOfOrders = CALCULATE ( COUNTROWS ( Sales ) )VAR WorkingDays =LOOKUPVALUE ('WD Delta'[Duration],'WD Delta'[Order Date], Sales[Order Date],'WD Delta'[Delivery Date], Sales[Delivery Date])VAR NumberOfWorkingDays = NumOfOrders * WorkingDaysRETURNNumberOfWorkingDays) VAR AverageWorkingDays = DIVIDE ( DeliveryWeightedByNumOfOrders, NumOfAllOrders ) RETURNAverageWorkingDays
16.2 同时显示预算和销售
假设我们有一个数据模型,其中包含当年的预算信息和实际销售额。年初时,唯一可用的数据是预算数字。随着时间推移,实际销售数据逐渐产生。为了模拟这种场景,我们删除了 2009 年 8 月 15 日之后的所有销售数据,并创建了一个包含 2009 年全年每日预算的 Budget 表,数据结果如图所示:

销售截至到 8 月 15,而预算一直持续到年底。现在的需求是,结合实际销售数据和预算数据,预测年底的总销售额(实际销售额+剩余预算金额)。
预算数据是年初制定的计划销售额,用于预测未来可能的销售情况
16.2.1 基础实现
-
确定销售截止日期:Sales 表中最后一个销售日期即是销售截止日期,但不同的品牌销售截止日期不同:
LastDateWithSales := MAX ( 'Sales'[OrderDateKey] )
所以为了统一销售截止日期,需要在计算日期之前移除掉所有筛选器,因此,LastDateWithSales 的正确公式如下:LastDateWithSales := CALCULATE (MAX ( 'Sales'[OrderDateKey] ),ALL ( Sales ) -- 从 Sales 的扩展表中移除筛选器,忽略了任何来源于查询的筛选 ) -
计算预测销售额:对 LastDateWithSales 之前的日期使用 Sales Amount 计算销售,之后的日期使用 Budget Amt 计算预算,两者相加得到最终预测值。
Adjusted Budget := VAR LastDateWithSales =CALCULATE ( MAX ( Sales[OrderDateKey] ), ALL ( Sales ) ) VAR AdjustedBudget =SUMX ('Date',IF ( 'Date'[DateKey] <= LastDateWithSales, [Sales Amount], [Budget Amt] )) RETURNAdjustedBudget

16.2.2 优化迭代基础
SUMX 执行的外部迭代遍历 Date 表,一年中它迭代 365 次。每次迭代时,根据日期的值,它会扫描销售或预算表,执行上下文转换。实际上,本例中并不需要迭代日期,这么做的唯一原因是迭代使代码更直观易读。
我们可以将Date按销售截止日期进行分组,分别计算两组的数据(销售额和预算),最后相加即可。另外,对于截止日期前的销售额,用已有数据简单汇总即可。
Adjusted Budget Optimized :=
VAR LastDateWithSales =CALCULATE ( MAX ( Sales[OrderDateKey] ), ALL ( Sales ) )
VAR SalesAmount = [Sales Amount]
VAR BudgetAmount =CALCULATE ( [Budget Amt], KEEPFILTERS ( 'Date'[DateKey] > LastDateWithSales ) )
VAR AdjustedBudget = SalesAmount + BudgetAmount
RETURNAdjustedBudget
调整后的 Adjusted Budget Optimized 只需要分别扫描一次 Sales 表和 Budget 表,后者在 Date 表上有一个额外的筛选器。请注意,KEEPFILTERS 是必需的,否则,Date 表上的条件将覆盖当前上下文,导致不正确的结果。
与前面的示例一样,可以用不同的方式表达式获得相同结果,找到最佳方法需要经验和对引擎内在的充分理解。而实际上,在 DAX 表达式中简单考虑基数就可以大大优化模型性能。
16.3 分析可比销售
16.3.1 业务背景
本节将讲述一个广泛应用于业务计算中的具体案例。一家名为 Contoso 的跨国零售企业,旗下有多家商店分布在世界各地,每家商店包含多个部门,每个部门销售特定类别的商品。由于业务的动态性,一些部门可能会在某些年份开业、关闭或重新调整营业状态。
如果直接比较不同年份的销售数据,可能会因为门店的开业或关闭而产生误导性的结论,所以需要分析可比部门的销售行为。每个企业都有适合自身的可比概念。本案例的需求是比较在所有选定年份中始终营业的门店和类别的销售情况。

如上图报告所示,该报告分析了德国商店中 Aduio 类别三年销售情况。可以看到Berlin 商店在 2007 年关门了,Koln 的两家商店中有一家在 2008 年维修。为了计算结果的可比性,应该只分析始终营业的商店。
16.3.2 模型设计
为了实现这一目标,我们首先需要构建一个合适的数据模型。在这个案例中,我们引入了一个名为 StoresStatus 的表,用于存储每个商店在不同年份和类别下的营业状态(案例中仅显示“营业”状态,以提高可读性)。这种设计的好处是,它可以将复杂的业务逻辑与查询性能分离,使得后续的计算更加高效。
同类分析的规则很复杂并且要进行各种调整,所以最好将可比元素的状态存储在单独的表中。这样,业务逻辑中的任何复杂问题都不会影响查询性能,只会影响刷新“状态表”所需的时间。
不同年份,营业状态不同:

数据建模:

- StoreStatus 每一行记录了每个商店、每个产品类别在每个年份中营业状态——“营业”或“关店”。表格中没有空值,这对降低公式的复杂性非常重要。
- Date 表和 StoreStatus表 之间的关系是以 Year 为关键字的多对多的弱关系,交叉筛选方向指向 StoreStatus(用 Date 表来筛选 StoreStatus 表,而不是相反)
- 所有其他关系都是常规的一对多关系
16.3.3 计算同店销售额
-
确定始终营业的门店和类别:使用指定的类别和年份来筛选StoresStatus 表。如果筛选过后,所有被筛选行都处于营业状态,则该门店在整个所选时间段内都是营业的。
EVALUATE VAR StatusGranularity = -- 以商店名称和产品类别为分组依据,生成一个临时表 StatusGranularitySUMMARIZE ( Receipts, Store[Store Name], 'Product Category'[Category] ) VAR Result =FILTER ( -- FILTER 函数对 StatusGranularity 表进行筛选,条件是 CALCULATE 函数返回的结果等于 "Open"。StatusGranularity,CALCULATE (SELECTEDVALUE ( StoresStatus[Status] ),ALLSELECTED ( 'Date'[Calendar Year] )) = "Open") RETURNResult- SELECTEDVALUE 函数:用于返回一个列中的单一值(例如 “Open” 或 “Closed”)。如果该列中有多个不同的值(例如某些年份是 “Open”,某些年份是 “Closed”),则返回 BLANK
- CALCULATE 函数:在
ALLSELECTED('Date'[Calendar Year])筛选上下文中计算SELECTEDVALUE(StoresStatus[Status])的值
-
计算同店销售额:一旦确定了始终营业的门店和类别,我们可以使用这些筛选条件来计算同店销售额。
OpenStoresAmt := VAR StatusGranularity =SUMMARIZE ( Receipts, Store[Store Name], 'Product Category'[Category] ) VAR OpenStores =FILTER (StatusGranularity,CALCULATE (SELECTEDVALUE ( StoresStatus[Status] ),ALLSELECTED ( 'Date'[Calendar Year] )) = "Open") VAR AmountLikeForLike =CALCULATE ( [Amount], OpenStores ) RETURNAmountLikeForLike

16.3.4 使用DAX动态计算
上一节代码通过计算首先得到一个被筛选后的表,然后用它作为运算的限定条件,这是 DAX 中几个高级计算的基础,该方法主要用的是数据建模而不是 DAX。
除了使用一个附加表来存储商店的营业状态,还可以单独检查 Receipts表,根据销售情况进行推断。以下度量值在没有使用 StoresStatus 表的情况下实现 OpenStoresAmt 计算。要注意的是,如果有销售则商店肯定是营业的,反之则不然(可能正在营业但是还没有销售额)。
OpenStoresAmt Dynamic :=
VAR SelectedYears =CALCULATE (DISTINCTCOUNT ( 'Date'[Calendar Year] ),CROSSFILTER ( Receipts[SaleDateKey], 'Date'[DateKey], BOTH ),ALLSELECTED ())
VAR StatusGranularity =SUMMARIZE ( Receipts, Store[Store Name], 'Product Category'[Category] )
VAR OpenStores =FILTER (StatusGranularity,VAR YearsWithSales =CALCULATE (DISTINCTCOUNT ( 'Date'[Calendar Year] ),CROSSFILTER ( Receipts[SaleDateKey], 'Date'[DateKey], BOTH ),ALLSELECTED ( 'Date'[Calendar Year] ))RETURNYearsWithSales = SelectedYears)
VAR AmountLikeForLike =CALCULATE ( [Amount], OpenStores )
RETURNAmountLikeForLike
- 通过
CROSSFILTER函数将筛选上下文从Receipts表转移到Date表,确保只计算有销售记录的年份。 - 对于每一组商店和类别,通过 CALCULATE 函数计算有销售记录的年份数量 YearsWithSales。
- 如果 YearsWithSales 等于 SelectedYears,则说明该商店在所有选定年份中都有销售记录,因此可以认为其始终处于营业状态。
- 最后,使用筛选条件 OpenStores 计算同店销售额
两种方法的对比:
OpenStoresAmt:基于一个专门的StoresStatus表进行计算,该表存储了每个商店在不同年份和类别下的营业状态(营业或关店)。这种方法简单高效,因为可以直接利用StoresStatus表筛选出始终营业的商店。OpenStoresAmt Dynamic:不依赖预先构建的StoresStatus表,而是直接从Receipts表中动态计算商店的营业状态。这种方法更加灵活,但计算复杂度更高,因为需要扫描整个Receipts表来确定商店在哪些年份有销售记录。Receipts表通常包含大量的销售记录,因此扫描该表的性能开销较大。
16.4 高效排序
本案例是在 Contoso 数据库的Sales表中,创建一个计算列,用于对每个订单按客户编号,效果如下:

16.4.1 基于上下文转换进行计算
最直观的方式是,通过计算每个客户中小于或等于当前订单号的订单数量,来确定该订单的序号位置:
- 对每个订单(行上下文),获取它的 CustomerKey 和 Order Number;
- 筛选同一客户的所有订单(ALLEXCEPT 保留客户筛选上下文)
- 统计该客户中订单号 ≤ 当前订单号的订单数量,即为当前订单的序号(如果是客户的第一单,统计结果为1;第二单为2,依此类推)。
Sales[Order Position] =
VAR CurrentOrderNumber = Sales[Order Number] -- 当前订单号
VAR Position =CALCULATE (DISTINCTCOUNT ( Sales[Order Number] ), -- 统计筛选上下文中所有不同的订单的数量Sales[Order Number] <= CurrentOrderNumber, -- 筛选≤当前订单号的订单ALLEXCEPT (Sales,Sales[CustomerKey] -- 保留同一客户的上下文))
RETURNPosition
尽管这段代码逻辑简单,但实际运行效率非常低:
- 上下文转换开销:在 CALCULATE 函数中使用 DISTINCTCOUNT 时,会触发上下文转换,CALCULATE 内部需重新扫描整个表。
- O(n²) 复杂度:对Sales表的每一行,需扫描同一客户的所有订单,基数是Sales表行数的平方
- 重复计算:DISTINCTCOUNT 和筛选条件在每行重复执行,未利用缓存优化。
由于 Sales 表包含 100,000 行,因此总复杂度为100 亿,此计算列需要数小时才能计算出结果。在更大的数据集上,它会使任何服务器瘫痪。
16.4.2 避免上下文转换
在第 5 章“理解 CALCULATE 和 CALCULATETABLE ”中讨论了,一个好的开发人员应该尽量避免在大型表上使用上下文转换。另一种方法是,创建一个包含所有客户和订单号组合的表,然后在这个表上筛选计算符合条件的订单数(同一客户中小于当前订单号的订单数)。
Sales[Order Position] =
VAR CurrentCustomerKey = Sales[CustomerKey]
VAR CurrentOrderNumber = Sales[Order Number]
VAR CustomersOrders =ALL ( Sales[CustomerKey], Sales[Order Number] )
VAR PreviousOrdersCurrentCustomer =FILTER (CustomersOrders,AND (Sales[CustomerKey] = CurrentCustomerKey,Sales[Order Number] <= CurrentOrderNumber))
VAR Position =COUNTROWS ( PreviousOrdersCurrentCustomer )
RETURNPosition
这种方法的性能显著优于第一种方法。首先,CustomerKey 和 Order Number 的非重复组合数量为 26,000,远小于 100,000。其次,避免上下文转换,复杂度降低。
16.4.3 最优方式:使用 RANKX 函数
虽然上述优化方法已经显著提高了性能,但还可以进一步优化。DAX 提供了 RANKX 函数,它可以对表中的数值进行排序并返回其排名。实际上,订单的序列号与同一客户所有订单的升序排列值相同。以下是使用 RANKX 函数的 DAX 公式:
Sales[Order Position] =
VAR CurrentCustomerKey = Sales[CustomerKey]
VAR CustomersOrders =ALL ( Sales[CustomerKey], Sales[Order Number] )
VAR OrdersCurrentCustomer =FILTER ( CustomersOrders, Sales[CustomerKey] = CurrentCustomerKey )
VAR Position =RANKX (OrdersCurrentCustomer,Sales[Order Number],Sales[Order Number],ASC,DENSE)
RETURNPosition
RANKX 函数经过了高效的内部优化,即使在大型数据集上也能快速执行运算。对 DAX 新手来说,使用 RANKX 计算序列号可能并不容易想到,这就是我们列举这个例子的原因。
在演示数据库中,虽然最后两个公式之间的性能差异不大,但对查询计划的深入分析表明,使用
RANKX的版本效率最高。
16.5 计算销售截止日期前一年的销售额
16.5.1 业务背景
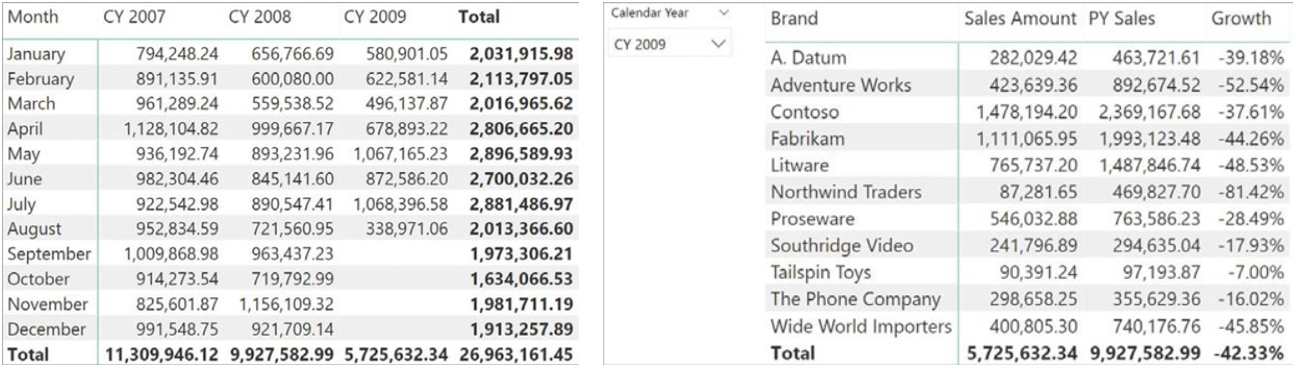
假设我们有一个销售数据库,将 2009 年 8 月 15 日之后的所有销售数据删除以模拟销售数据不完整的状态。此时,如果直接计算 2009 年与 2008 年的同比增长是不对的,因为没有考虑数据完整性,计算出来所有品牌的销售量都在急剧下降:
PY Sales :=
CALCULATE ( [Sales Amount], SAMEPERIODLASTYEAR ( 'Date'[Date] ) )Growth :=
DIVIDE ( [Sales Amount] - [PY Sales], [PY Sales] )
16.5.2 修改 PY Sales 度量值
为了准确计算截至最后销售日期的上一年销售额,有几种方法。第一种方法是修改 PY Sales 度量值,使其只考虑销售截止日期前一年的销售额。
PY Sales :=-- 计算销售截止日期
VAR LastDateInSales = CALCULATETABLE ( LASTDATE ( Sales[Order Date] ), ALL ( Sales ) )-- 时间智能函数只能在日期表上才能正常工作,所以需要将 LastDateInSales 与日期表中的日期建立虚拟关系
VAR LastDateInDate = TREATAS ( LastDateInSales, 'Date'[Date] )-- 计算上一年的对应日期
VAR PreviousYearLastDate = SAMEPERIODLASTYEAR ( LastDateInDate )-- 计算上一年的销售额,同时添加一个筛选条件,确保只计算上一年对应日期之前的销售额。
VAR PreviousYearSales =CALCULATE ([Sales Amount],SAMEPERIODLASTYEAR ( 'Date'[Date] ),'Date'[Date] <= PreviousYearLastDate)
RETURNPreviousYearSales

在上述代码中,TREATAS 函数的使用至关重要。因为 SAMEPERIODLASTYEAR 的结果是一个只包含输入列单列的表,如果输入列中缺少某些日期(例如周末没有销售),那么 SAMEPERIODLASTYEAR 可能会返回空值。
比如从 Sales 表中删除 2008 年 8 月15 的销售数据,那么 2009 年 8 月 15 日前一年的日期是 2008 年 8 月 15 日,这在 Sales[Order Date] 中不存在,SAMEPERIODLASTYEAR 返回一个空值,那么’Date’[Date] <= PreviousYearLastDate永远不会成立,PY Sales Wrong 度量值(只是删去了TREATAS那一步)始终返回空值。所以时间智能函数只能在日期表(包含完整日期周期,没有缺失)上才能正确计算。

16.5.3 代码优化
虽然上述方法可以解决问题,但它在每次计算时都需要重新计算最后销售日期并将其前移一年。这不仅效率低下,而且容易出错。一个更好的解决方案是,在数据模型中预先计算每个日期是否包含在比较条件中。为此,在 Date 表中创建一个新的计算列,判断给定日期是否在前一年可比日期范围内。
'Date'[IsComparable] =
VAR LastDateInSales = MAX ( Sales[Order Date] )
VAR LastMonthInSales = MONTH ( LastDateInSales )
VAR LastDayInSales = DAY ( LastDateInSales )
VAR LastDateCurrentYear = DATE ( YEAR ( 'Date'[Date] ), LastMonthInSales, LastDayInSales )
VAR DateIncludedInCompare = 'Date'[Date] <= LastDateCurrentYear
RETURNDateIncludedInCompare
一旦有了这个计算列,就可以简单地创建 PY Sales 度量值:
PY Sales :=
CALCULATE ([Sales Amount],SAMEPERIODLASTYEAR ( 'Date'[Date] ),'Date'[IsComparable] = TRUE
)
这种方法不仅代码更简洁,而且运行速度更快,因为它避免了在每次计算时重新计算复杂的逻辑。