ThinkPrune:在RL中引入长度限制,在保持性能一致或略有提升下,显著提升推理效率
摘要:我们提出了THINKPRUNE,这是一种简单而有效的方法,用于缩短长思考型大语言模型(LLMs)的思考长度。这些模型被发现常常会产生低效且冗余的思考过程。现有的关于减少思考长度的初步探索主要集中在迫使思考过程提前结束,而不是让LLMs去优化和整合思考过程,因此到目前为止观察到的长度与性能之间的权衡是次优的。为了填补这一空白,THINKPRUNE提供了一个简单的解决方案,即通过强化学习(Reinforcement Learning, RL)持续训练长思考型LLMs,并附加一个标记限制,超出该限制的任何未完成的思考和答案都将被丢弃,从而得到零奖励。为了进一步保留模型性能,我们引入了一种迭代长度修剪方法,即进行多轮强化学习,每轮的标记限制都更加严格。我们观察到,THINKPRUNE实现了显著的性能与长度权衡——在AIME24数据集上,DeepSeek-R1-Distill-Qwen-1.5B的推理长度可以减少一半,而性能仅下降2%。我们还观察到,在修剪后,LLMs可以跳过不必要的步骤,同时保持核心推理过程的完整性。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 强化学习与长度限制
3.2 迭代修剪策略
四、实验结论
4.1 推理长度显著减少
4.2 性能保持或提升
4.3 推理行为优化
五、总结
一、背景动机
论文题目:ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
论文地址:https://arxiv.org/pdf/2504.1296
大模型(LLMs)通过强化学习进行推理扩展时,其在推理能力上取得了显著进展。然而,这些模型在推理过程中往往会产生大量的冗余和低效的推理步骤,导致推理链过长,增加了计算和内存开销。
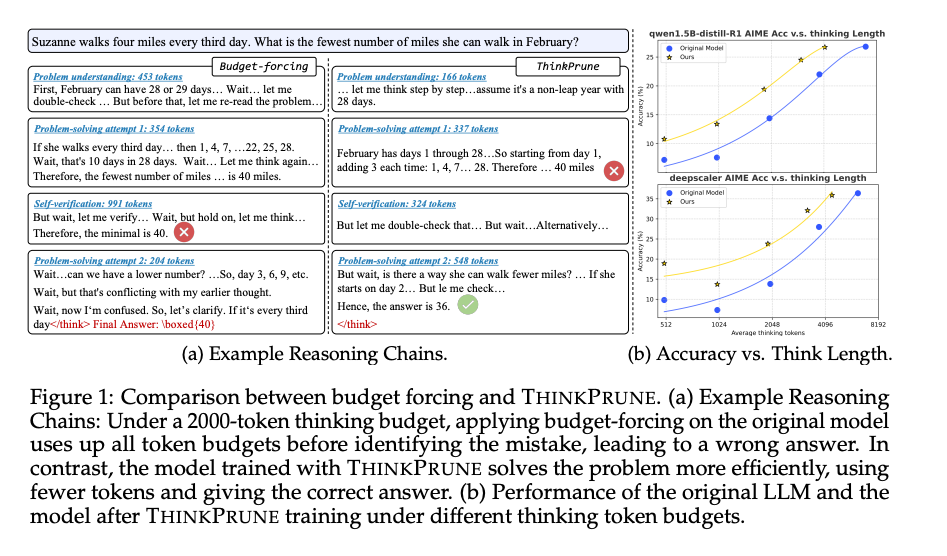
现有的减少推理长度的方法主要集中在强制推理过程提前退出(budget-forcing),而不是优化和整合推理过程。这种方法在预算较低时会导致显著的性能下降,因为模型无法完成其推理过程。
因此文章提出了ThinkPrune方案,即通过强化学习持续训练长思考型LLMs,并附加一个标记限制,超出该限制的任何未完成的思考和答案都将被丢弃,从而得到零奖励。
二、核心贡献
- THINKPRUNE 方法:提出了一种简单而有效的推理长度修剪策略,通过在强化学习训练中引入最大生成长度限制,迫使模型在有限的 token 数量内完成推理。
- 迭代修剪策略:为了更好地保持模型性能,THINKPRUNE 采用了迭代修剪方法,通过多轮强化学习逐步收紧长度限制。
- 推理行为分析:通过分析修剪后的推理链,发现模型能够跳过不必要的步骤,同时保持核心推理过程的完整性。
三、实现方法
3.1 强化学习与长度限制
ThinkPrune 的核心思想是通过强化学习(RL)训练模型,使其在有限的 token 数量内完成推理。
-
奖励函数设计
-
设定一个最大长度限制 L,如果模型生成的输出超过这个限制,超出部分将被丢弃,并且模型将获得零奖励。
-
-
系统提示
-
在训练中,为了明确告知模型长度限制,在每个训练样本中添加了一个系统提示。这个提示帮助模型理解其输出长度的限制。
-

3.2 迭代修剪策略
为了更好地保持模型性能,THINKPRUNE 采用了迭代修剪方法,逐步收紧长度限制。
-
长度限制调度:
-
设定一个目标长度限制 L∗,并设计一个长度调度表 L1>L2>⋯>L∗。
-
从 L1=4000 开始,逐步减少到 L2=3000,再到 L3=2000。
-
-
多轮强化学习:
-
在每一轮迭代中,使用当前的长度限制 Lt 进行强化学习训练。
-
从上一轮训练得到的模型 θt−1 开始,继续训练得到新的模型 θt。
-
这种逐步收紧长度限制的方法允许模型逐步适应更严格的长度限制,同时尽量减少性能损失。
-
-
停止准则:
-
在每一轮训练中,使用验证集(如 AIME22 和 AIME23 数据集)来选择最佳检查点。
-
允许模型在验证集上的性能相对下降不超过 10% 的 pass@1 准确率。
-
在满足上述条件的检查点中,选择平均输出长度最短的检查点作为下一轮训练的起点。
-
四、实验结论
4.1 推理长度显著减少
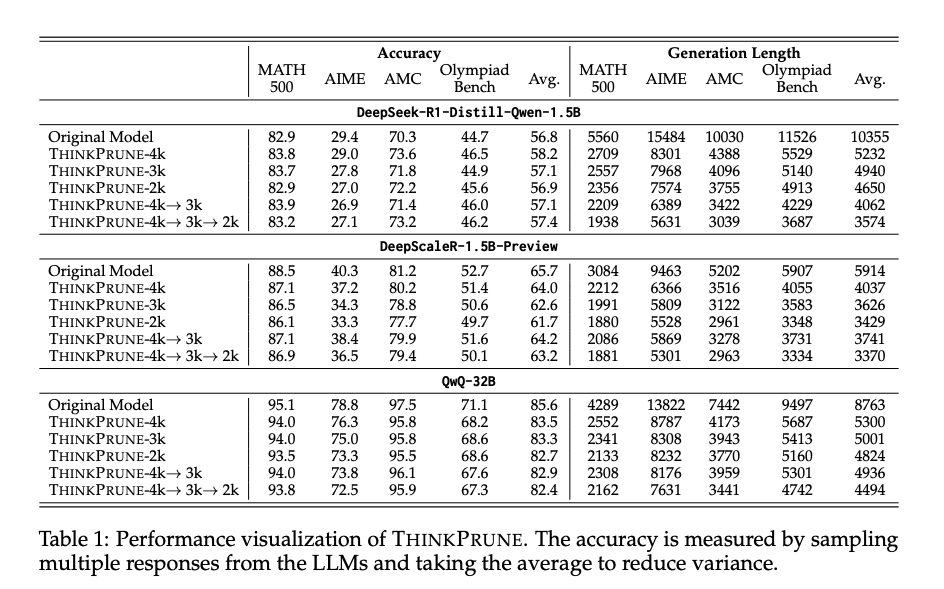
THINKPRUNE 在多个模型上实现了显著的推理长度减少。对于 DeepSeek-R1-Distill-Qwen-1.5B 模型,平均生成长度从 10,355 个 token 减少到 3,574 个 token。
4.2 性能保持或提升
尽管推理长度显著减少,但模型的平均准确率在多个数学基准测试中保持不变或有所提升。对于 DeepSeek-R1-Distill-Qwen-1.5B 模型,其原始模型平均准确率为 56.8%,经过 THINKPRUNE 修剪后,平均准确率提升到 57.4%,提升了 1.1%。
4.3 推理行为优化
-
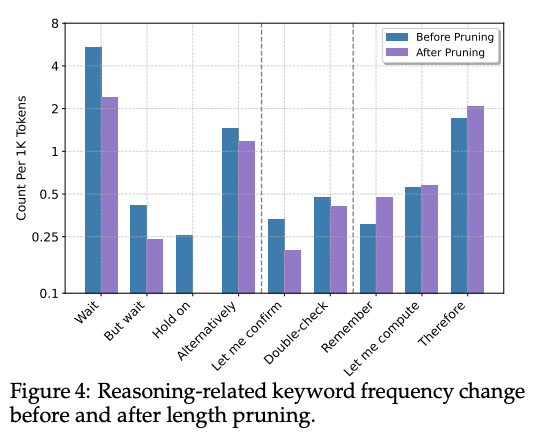
关键词频率变化
-
修剪后,模型减少了犹豫和自我纠正的步骤(如“Wait”、“But wait”等),同时保持了核心推理步骤(如“Computing or Simplifying Expressions”)的频率。
-
-
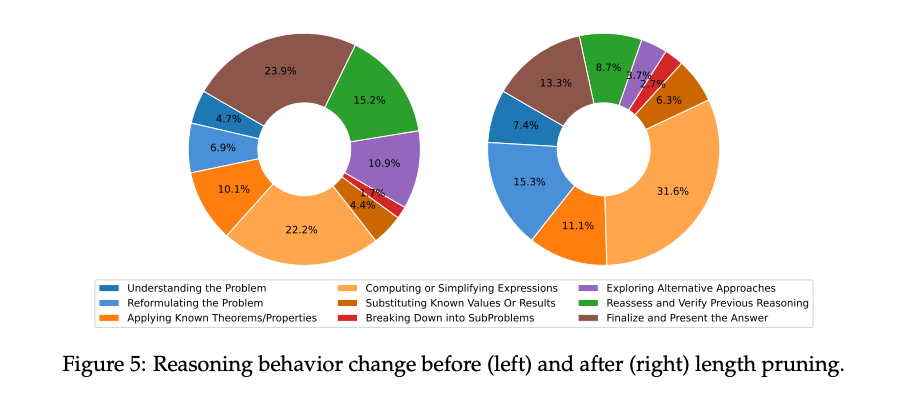
推理行为变化
-
通过 GPT-4o 分析推理链,发现修剪后模型减少了冗余步骤(如“Reassess and Verify Previous Reasoning”),同时增加了核心问题解决步骤(如“Applying Known Theorems/Properties”)的比例。
-
-
可读性评估
-
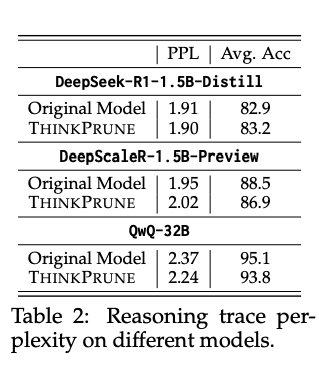
修剪后模型的推理链保持了良好的可读性,困惑度与原始模型相近。
-
五、总结
THINKPRUNE 提供了一种有效的方法来减少大型语言模型的推理长度,同时保持或提升性能。通过在强化学习中引入长度限制,并采用迭代修剪策略,THINKPRUNE 能够优化模型的推理过程,去除冗余步骤,提高推理效率。