大模型前处理-CPU
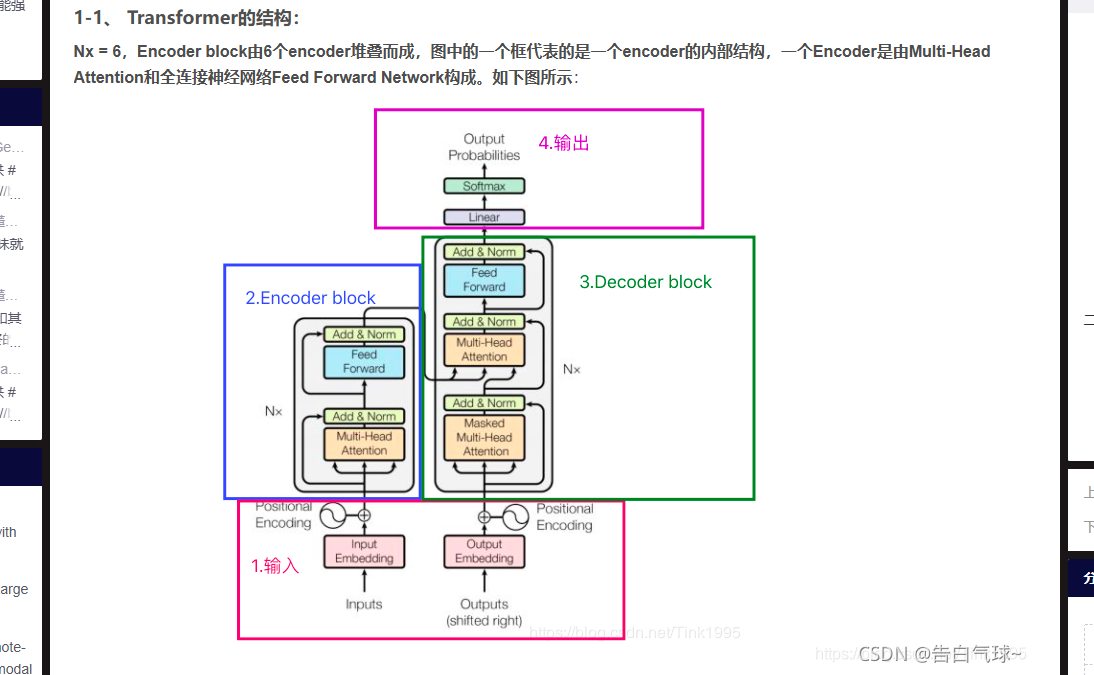
前处理包含哪些流程
- 分词 tokenization
- embedding
CPU可以做哪些优化
分词
分词在做什么?
什么是词元化?
词元化(Tokenization)是把一段自然语言文本拆分成更小的单元(称为“词元”,即 Token)的过程。词元可以是:
- 单词:例如,“I love NLP” 分成 ["I", "love", "NLP"]。
- 子词:例如,“loving” 分成 ["lov", "##ing"]。
- 字符:例如,“hello” 分成 ["h", "e", "l", "l", "o"]。
这些词元最终会被转换成数字表示(模型的输入),因为机器只能处理数字。
如何优化:CPU可选择高效的分词引擎&多线程
高效分词器:FlashTokenizer: 基于C++的高性能分词引擎,速度可以提升8-15倍-阿里云开发者社区
friso:git clone https://github.com/lionsoul2014/friso.git
项目首页 - manticoresearch:manticoresoftware/manticoresearch: 这是一个用于快速搜索和索引数据的搜索引擎。适合用于需要快速搜索和索引数据的场景。特点:易于使用,支持多种数据格式,具有高性能和可扩展性。 - GitCode
探秘高性能中文分词器——Jcseg-CSDN博客
tiktoken - 为OpenAI模型优化的高性能BPE分词器 - 懂AI
上面这个链接有多线程示例
分词器关注指标?对e2e的影响
Qwen是什么分词器;llama又是什么分词器;为什么说qwen的分词器在中文压缩上比llama更好;_qwen 分词器-CSDN博客
embedding 文本嵌入
embedding 在做啥?
大模型推理中的Embedding(Token级)
文本先通过分词器拆分成最小语言单位token,例如 :"unbelievable" → ["un", "believ", "able"]。
接着查询词表,每个token被映射成一个数字编号,比如:"un"→1087。
根据编号查询Embedding矩阵,快速取出对应的浮点数向量,例如:"un"→[0.24,-0.31,0.88,…, 0.05]。
生成Token级的Embedding,是大模型理解输入文本的第一步。
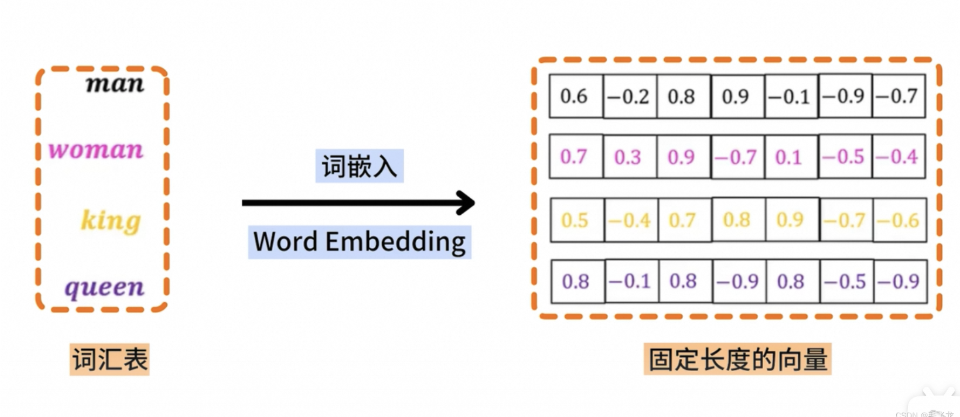

如何优化?
玩转RAG应用:如何选对Embedding模型?-腾讯云开发者社区-腾讯云
位置编码
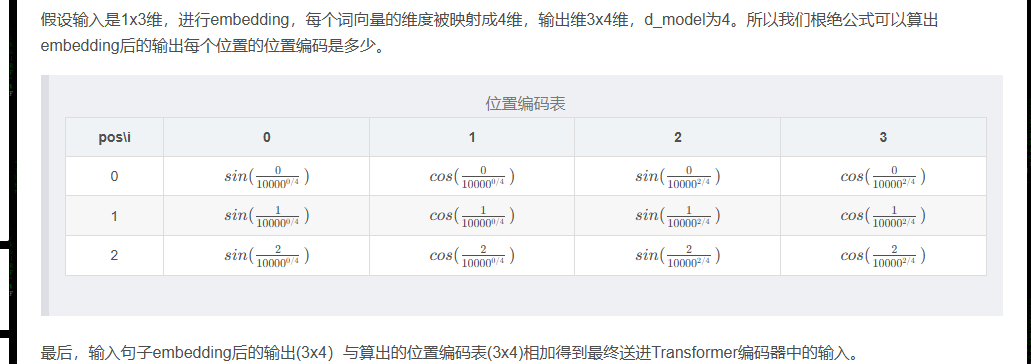
Transformer输入Embedding及位置编码详解_transformer embedding-CSDN博客
词向量之间需要有一个相对位置关系,如果全部不分序输入那处理肯定不方便,不同词之间组合意思也会发生变化,于是就要给词向量加位置信息。
Transformer的PE(position embedding),即位置编码理解-CSDN博客
Transformer中Position Embedding的原理与思考 | Erwin Feng Blog
看不懂
位置编码深度剖析:从正弦波到RoPE、ALiBi —— 让AI记住顺序的奥秘-CSDN博客
这篇可以
附录:
一文搞懂大模型的前处理_大模型处理-CSDN博客
AI大模型中BERT的Embedding到底是个什么?看完小白也懂了! - 知乎
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客